RADIUS Server High Availability: Active-Active vs Active-Passive
A definitive technical reference guide for IT managers and network architects evaluating RADIUS high availability architectures. It contrasts Active-Active and Active-Passive deployments, details database replication requirements, and explains how Cloud RADIUS mitigates failover latency for enterprise venues.
🎧 Listen to this Guide
View Transcript

Executive Summary
For enterprise networks, authentication is binary: it either functions flawlessly, or business operations cease entirely. RADIUS (Remote Authentication Dial-In User Service) serves as the critical gatekeeper for IEEE 802.1X, WPA3 enterprise, and Guest WiFi deployments across modern venues. Unlike application services that degrade gracefully under load, a RADIUS failure immediately blocks users, point-of-sale terminals, and operational devices from network access.
This technical reference guide evaluates the architectural models for deploying highly available RADIUS infrastructure. Specifically, it contrasts traditional Active-Passive configurations with modern Active-Active clusters. For IT managers, network architects, and venue operations directors managing high-density environments like Retail , Hospitality , and stadiums, understanding these failover strategies, load balancing mechanics, and database replication requirements is essential.
Furthermore, this guide examines how Cloud RADIUS platforms abstract the complexity of high availability, providing automatic failover and elastic scalability without the operational burden of maintaining redundant on-premises infrastructure. By applying these vendor-neutral best practices, engineering teams can design authentication architectures that eliminate single points of failure and meet stringent uptime Service Level Agreements (SLAs).
Technical Deep-Dive: Understanding RADIUS Architecture
RADIUS operates as a client-server protocol over UDP, typically utilising port 1812 for authentication and port 1813 for accounting, as defined in RFC 2865 and RFC 2866. The stateless nature of UDP authentication requests is a structural advantage for high availability design. Because each Access-Request packet contains all necessary credentials and parameters, any RADIUS server within a cluster can process any request independently, without requiring complex state synchronisation for the authentication phase itself.
Active-Passive Architecture
In an Active-Passive (or primary-standby) deployment, a single RADIUS server processes all incoming authentication and accounting traffic. A secondary server remains online but idle, receiving database replication updates but not actively responding to Network Access Devices (NADs) such as access points, switches, or VPN gateways.
When the primary server fails, the NAD detects the timeout and redirects subsequent requests to the secondary server. The failover detection time is entirely dependent on the NAD's configuration timers. A typical NAD sends a RADIUS request and waits for a default packet timeout (often two seconds). If no response is received, it retries. With a standard configuration of three attempts per server, the NAD may wait up to six seconds before declaring the primary server dead and failing over to the secondary. In environments with three configured servers, this failover window can extend to eighteen seconds. For a busy Hospitality venue or a Retail environment processing transactions, this delay represents a noticeable disruption to service.
Active-Active Architecture
Conversely, an Active-Active architecture distributes the authentication load across multiple operational RADIUS servers simultaneously. Traffic is routed to the cluster either through round-robin configuration on the NADs or via a dedicated load balancer.
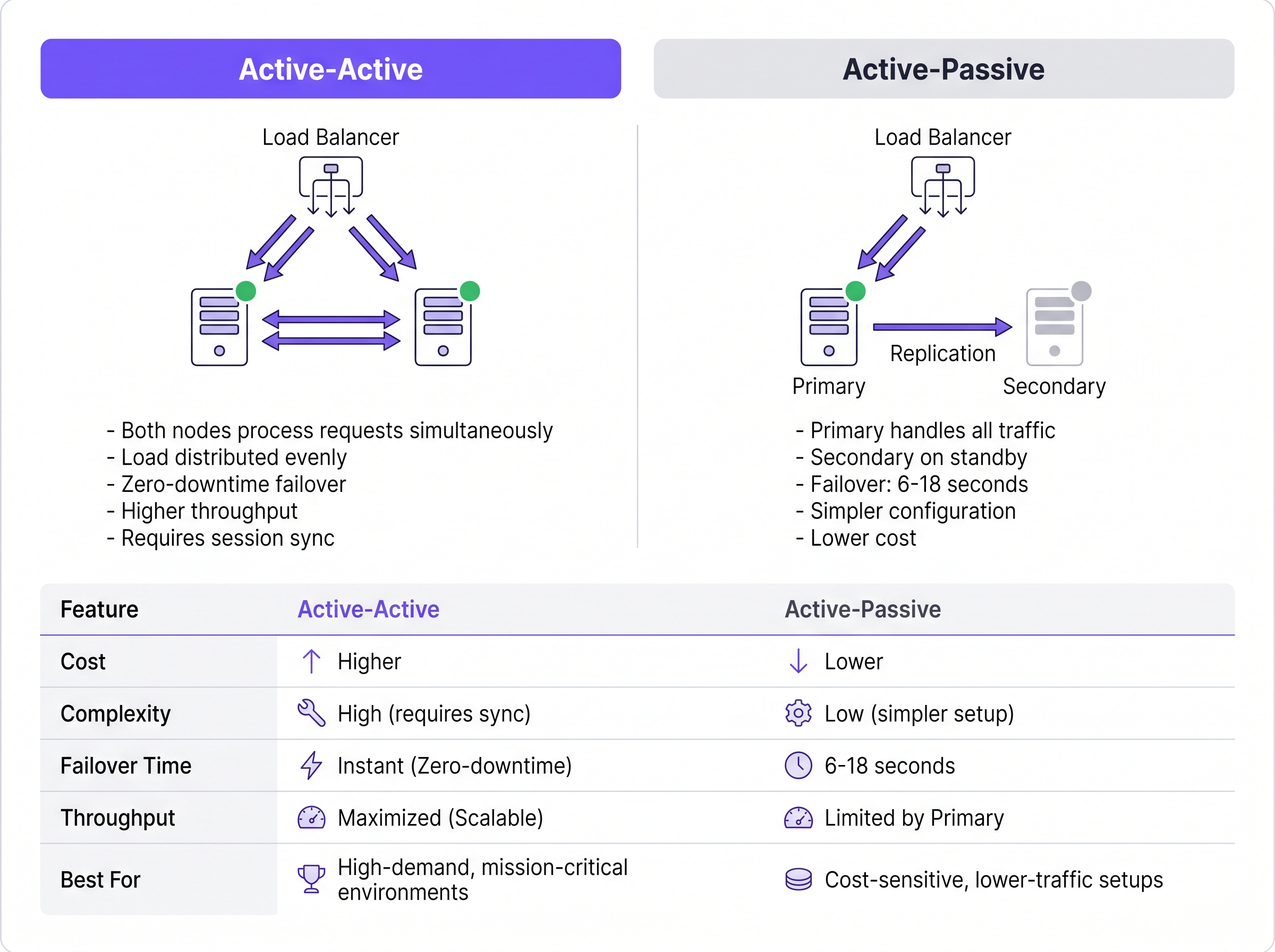
This model eliminates the failover detection delay inherent in Active-Passive setups. If a node fails, the load balancer (or the NADs using round-robin) simply ceases routing traffic to the unresponsive server, typically within one to two seconds based on health-check intervals. The remaining active nodes instantly absorb the traffic. Furthermore, Active-Active clusters scale horizontally; adding capacity for high-density events simply requires provisioning additional nodes to the cluster.
The Database Replication Challenge
While RADIUS authentication is stateless, RADIUS accounting is inherently stateful. It tracks session initiation (Start), ongoing usage (Interim-Update), and termination (Stop). For venues utilising WiFi Analytics or billing systems, this accounting data must remain consistent across all nodes.
Backing a RADIUS cluster with a replicated database (such as MySQL or MariaDB integrated with FreeRADIUS) is mandatory for robust high availability. For Active-Active deployments, synchronous multi-master replication—such as Galera Cluster or MySQL NDB Cluster—is required. Synchronous replication ensures that an accounting record is committed to all nodes simultaneously, preventing data loss if a node fails. Traditional asynchronous replication, often used in Active-Passive setups, introduces replication lag. If the primary node fails before the secondary receives the update, active session data is permanently lost, which can violate compliance frameworks like PCI DSS.
Implementation Guide: Cloud vs On-Premises
The architectural decision extends beyond how to cluster servers; it involves where those servers reside. For multi-site operators, backhauling authentication traffic to a centralised on-premises data centre introduces WAN latency and creates a single point of failure at the WAN link.
Cloud RADIUS Platforms
Cloud RADIUS services resolve geographic distribution challenges by hosting authentication infrastructure across multiple global availability zones. When a user connects at a branch location, the request is routed to the nearest cloud edge node, minimising latency.
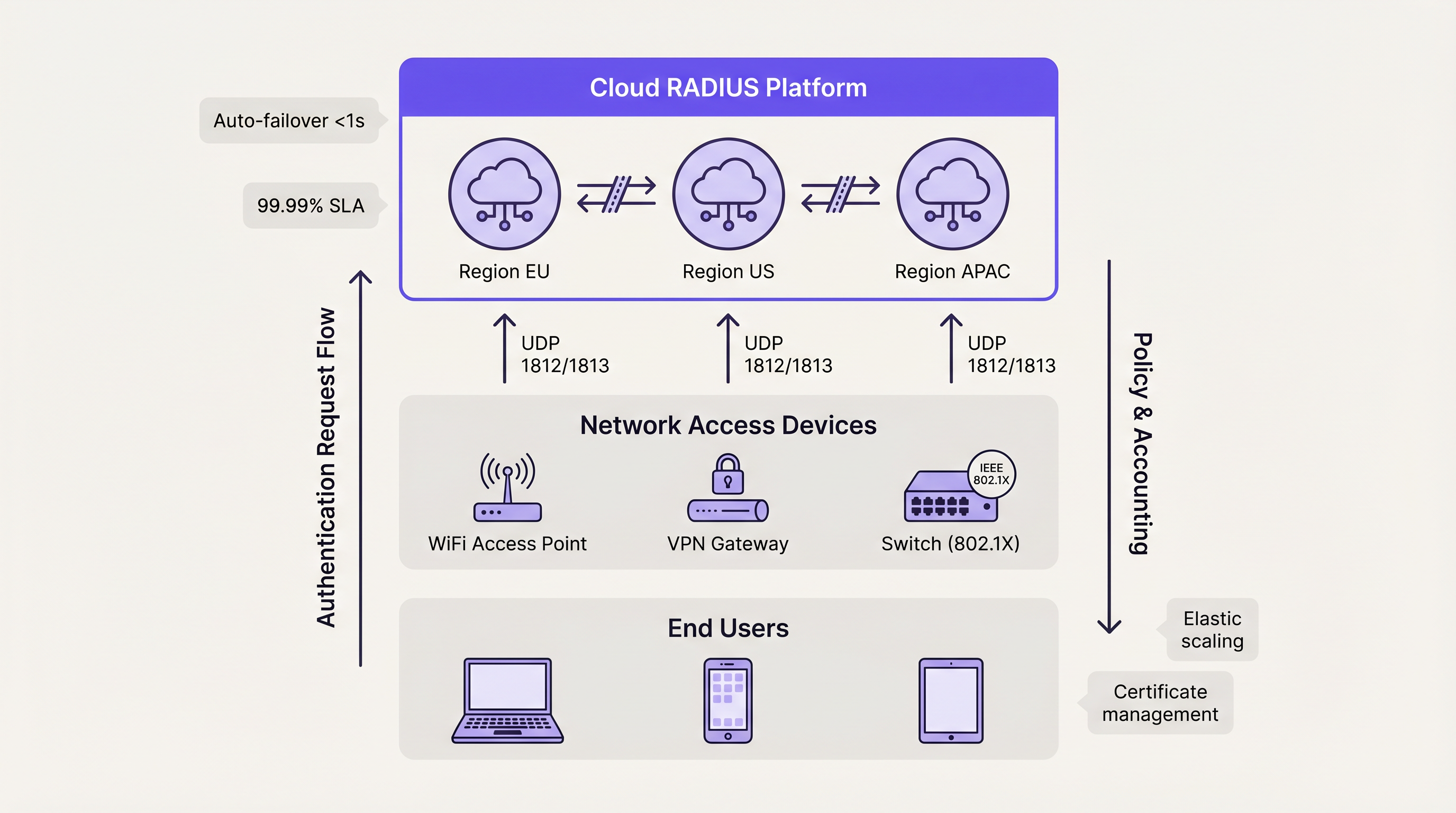
Cloud platforms inherently utilise Active-Active architectures. Failover between availability zones is handled automatically by the provider's internal load balancing, entirely abstracting the complexity from the customer's engineering team. This model typically delivers 99.99% uptime SLAs and eliminates the need for manual certificate management, operating system patching, and database replication tuning. For organisations deploying Wayfinding or Sensors across distributed campuses, cloud-hosted authentication ensures consistent policy enforcement without localised hardware dependencies.
On-Premises Deployment Considerations
Organisations operating in highly regulated sectors—such as specific Healthcare or government environments—may require on-premises deployments due to strict data sovereignty mandates. In these scenarios, deploying an Active-Active FreeRADIUS cluster with Galera synchronous replication provides the highest level of resilience.
However, engineering teams must account for the operational overhead. Managing TLS certificates across multiple nodes, ensuring configuration consistency, and actively monitoring database replication health require dedicated administrative resources. Hardware load balancers must be specifically configured to support UDP traffic with appropriate RADIUS health checks, as many standard load balancers are optimised solely for TCP HTTP/HTTPS traffic.
Best Practices for RADIUS High Availability
- Distribute Rather Than Duplicate: For deployments exceeding 500 concurrent users, prioritise Active-Active architectures over Active-Passive setups to maximise throughput and minimise failover latency.
- Implement Synchronous Replication: Protect stateful accounting data by utilising synchronous multi-master database replication (e.g., Galera Cluster) rather than asynchronous primary-replica models.
- Standardise Certificate Trust: In an Active-Active cluster, ensure all nodes present the identical server certificate or certificates from the exact same Certificate Authority (CA) chain. Discrepancies will cause EAP-TLS and PEAP handshakes to fail during node rotation.
- Tune NAD Timers: Optimise the RADIUS retry and timeout timers on your Network Access Devices. A two-second timeout with two retries provides a balance between rapid failover detection and preventing premature failover during minor network congestion.
- Test Failure Scenarios: Treat secondary nodes as production systems. Regularly simulate node failures, database desynchronisation, and WAN link drops to validate that automated failover mechanisms function as designed.
Troubleshooting & Risk Mitigation
The most prevalent failure mode in RADIUS high availability is configuration drift. In Active-Passive setups, administrators frequently update policies or renew certificates on the primary node but neglect the secondary. When a failover event occurs, the secondary node rejects legitimate traffic due to expired credentials or outdated policies.
To mitigate this risk, implement configuration management tools (such as Ansible or Terraform) to deploy changes symmetrically across all nodes. For certificate management, utilise automated renewal protocols (like ACME) configured to distribute the updated certificate cluster-wide simultaneously.
Another significant risk is load balancer misconfiguration. If a load balancer does not perform application-layer health checks (specifically verifying UDP port 1812 responsiveness), it may continue routing traffic to a node where the operating system is running but the RADIUS daemon has crashed. Ensure health checks explicitly validate RADIUS service availability.
ROI & Business Impact
The return on investment for robust RADIUS high availability is measured primarily through risk mitigation and operational efficiency. Authentication outages result in immediate productivity losses for employees and severe reputational damage for public-facing venues.
By transitioning from manual, single-server deployments to automated, Active-Active architectures (particularly via Cloud RADIUS), organisations reclaim significant engineering hours previously dedicated to routine maintenance. This operational efficiency allows network teams to focus on strategic initiatives, such as deploying The Core SD WAN Benefits for Modern Businesses or optimising high-density coverage, rather than firefighting authentication failures. Ultimately, reliable authentication is the foundational layer upon which all subsequent network services depend.
Key Terms & Definitions
Active-Active Architecture
A high availability design where multiple RADIUS servers process authentication requests simultaneously, distributing the load and providing instant failover without detection delays.
Essential for high-density venues (stadiums, large retail) where a single server cannot handle peak authentication surges.
Active-Passive Architecture
A redundancy model where a primary server handles all traffic, and a secondary server remains idle on standby until the primary fails.
Suitable for smaller, cost-sensitive deployments, but introduces a 6-18 second failover delay while the network access device detects the failure.
Synchronous Replication
A database replication method where data is written to all nodes in a cluster simultaneously before the transaction is considered complete.
Mandatory for Active-Active RADIUS accounting databases (like Galera Cluster) to prevent data loss and ensure compliance.
Asynchronous Replication
A database replication method where the primary node records the data and later copies it to secondary nodes, introducing a slight delay (lag).
Often used in Active-Passive setups but carries the risk of losing recent accounting records if the primary node fails abruptly.
Network Access Device (NAD)
The hardware component (such as a WiFi access point, switch, or VPN gateway) that requests authentication from the RADIUS server on behalf of the user.
The NAD's internal retry and timeout timers dictate how quickly an Active-Passive failover occurs.
Stateless Protocol
A communications protocol that treats each request as an independent transaction, unrelated to any previous request.
RADIUS authentication over UDP is stateless, allowing load balancers to route any request to any active server seamlessly.
Configuration Drift
The phenomenon where secondary or backup servers become out of sync with the primary server regarding policies, updates, or certificates over time.
The leading cause of failure in Active-Passive RADIUS deployments when the secondary node is forced to take over.
Cloud RADIUS
A managed authentication service hosted across globally distributed cloud infrastructure, providing built-in Active-Active redundancy and automatic scaling.
Replaces the need for IT teams to manually build, patch, and monitor redundant on-premise RADIUS servers.
Case Studies
A European hotel group manages 45 properties across six countries. They currently run independent FreeRADIUS virtual machines at each property. A recent expired TLS certificate at one location caused a complete guest WiFi outage during a major conference. How should they redesign their authentication architecture to prevent localized outages and reduce maintenance overhead?
The hotel group should migrate from localized, single-node FreeRADIUS instances to a centralized Cloud RADIUS platform utilizing an Active-Active architecture. By leveraging a cloud provider with geographically distributed edge nodes, authentication requests from each property are routed to the nearest regional node, minimizing latency. Centralized policy management allows the IT team to define authentication rules once and apply them globally. The cloud provider automatically handles TLS certificate rotation, operating system patching, and database replication.
A national sports stadium is preparing for a 60,000-attendee event. Their current RADIUS setup is an Active-Passive configuration. During load testing, the primary server became saturated processing 8,000 authentication requests per minute when the gates opened, causing severe connection delays, while the secondary server remained completely idle. How can they optimize this deployment?
The network engineering team must convert the deployment from Active-Passive to Active-Active. First, they should reconfigure the stadium's Network Access Devices (NADs) to utilize round-robin load balancing across both RADIUS servers, instantly doubling their authentication throughput. Second, they should provision a third RADIUS node to provide necessary headroom for peak surges. Finally, to ensure accounting data remains consistent across all three active nodes, they must implement a synchronous multi-master database replication solution, such as Galera Cluster.
Scenario Analysis
Q1. Your enterprise retail client requires a highly available RADIUS solution for their point-of-sale terminals. They have strict PCI DSS compliance requirements dictating that absolutely no accounting session data can be lost during a server failover. Which database replication strategy must you implement for the RADIUS backend?
💡 Hint:Consider the difference between data being written simultaneously versus data being copied after the fact.
Show Recommended Approach
You must implement Synchronous Replication (such as a Galera Cluster or MySQL NDB Cluster). Synchronous replication ensures that the accounting record is committed to all nodes simultaneously before acknowledging the transaction. If you used Asynchronous replication, a node failure could result in the loss of recent transactions that had not yet been copied to the secondary database, violating the strict compliance requirement.
Q2. A university campus network uses an Active-Passive RADIUS setup. Students complain that when the primary server undergoes maintenance, it takes nearly 20 seconds for their laptops to connect to the WiFi. The access points are configured with a 3-second RADIUS timeout and 5 retries. How can you reduce the failover delay without changing the server architecture?
💡 Hint:Calculate the maximum wait time based on the NAD timers before it attempts the secondary server.
Show Recommended Approach
You should tune the timers on the Network Access Devices (access points). Currently, the AP waits 3 seconds and retries 5 times, resulting in an 18-second delay (3 seconds × 6 total attempts) before failing over to the passive server. By reducing the configuration to a 2-second timeout and 2 retries, the failover detection time drops to 6 seconds, significantly improving the user experience during maintenance windows.
Q3. You are migrating a multi-site corporate network from an Active-Passive on-premise RADIUS server to an Active-Active Cloud RADIUS platform. During the pilot phase, devices successfully authenticate against Cloud Node A, but when the load balancer routes them to Cloud Node B, the EAP-TLS handshakes fail. What is the most likely configuration error?
💡 Hint:Consider what the client device verifies when establishing a secure EAP tunnel with a new server.
Show Recommended Approach
The most likely issue is a Certificate Trust mismatch. In an Active-Active cluster, all RADIUS nodes must present the exact same server certificate (or certificates issued by the exact same trusted CA chain). If Cloud Node B is presenting a different certificate that the client devices do not trust, the EAP-TLS handshake will be rejected by the client, causing authentication to fail despite the server functioning correctly.
Key Takeaways
- ✓RADIUS high availability is critical because authentication failures immediately block all network access for users and devices.
- ✓Active-Passive setups are simpler but introduce a 6-18 second failover delay dictated by the Network Access Device's retry timers.
- ✓Active-Active architectures process requests simultaneously, providing instant failover and horizontal scalability for high-density environments.
- ✓While RADIUS authentication is stateless, accounting is stateful and requires synchronous database replication (like Galera) to prevent data loss.
- ✓Cloud RADIUS platforms abstract HA complexity by providing globally distributed, automatically scaling Active-Active infrastructure.
- ✓Configuration drift and mismatched TLS certificates are the most common causes of failure during RADIUS failover events.
