RADIUS सर्व्हर हाय अव्हेलेबिलिटी (High Availability): Active-Active विरुद्ध Active-Passive
RADIUS हाय अव्हेलेबिलिटी (high availability) आर्किटेक्चरचे मूल्यांकन करणाऱ्या IT मॅनेजर्स आणि नेटवर्क आर्किटेक्ट्ससाठी एक निश्चित तांत्रिक संदर्भ मार्गदर्शिका. हे Active-Active आणि Active-Passive डिप्लॉयमेंट्समधील फरक स्पष्ट करते, डेटाबेस रेप्लिकेशन आवश्यकतांचे तपशील देते आणि क्लाउड RADIUS एंटरप्राइझ ठिकाणांसाठी फेलओव्हर लॅटन्सी कशी कमी करते हे स्पष्ट करते.
🎧 हे मार्गदर्शक ऐका
ट्रान्सक्रिप्ट पहा

कार्यकारी सारांश (Executive Summary)
एंटरप्राइझ नेटवर्क्ससाठी, ऑथेंटिकेशन बायनरी असते: एकतर ते उत्तम प्रकारे कार्य करते किंवा व्यवसाय ऑपरेशन्स पूर्णपणे थांबतात. RADIUS (Remote Authentication Dial-In User Service) आधुनिक ठिकाणांवरील IEEE 802.1X, WPA3 एंटरप्राइझ आणि Guest WiFi डिप्लॉयमेंट्ससाठी महत्त्वपूर्ण गेटकीपर म्हणून काम करते. लोड अंतर्गत हळूहळू कार्यक्षमता कमी होणाऱ्या ॲप्लिकेशन सर्व्हिसेसच्या उलट, RADIUS बिघाडामुळे युजर्स, पॉइंट-ऑफ-सेल टर्मिनल्स आणि ऑपरेशनल डिव्हाइसेसना नेटवर्क ॲक्सेस मिळण्यापासून त्वरित रोखले जाते.
ही तांत्रिक संदर्भ मार्गदर्शिका हायली अव्हेलेबल RADIUS इन्फ्रास्ट्रक्चर तैनात करण्यासाठी आर्किटेक्चरल मॉडेल्सचे मूल्यांकन करते. विशेषतः, हे पारंपारिक Active-Passive कॉन्फिगरेशनची आधुनिक Active-Active क्लस्टर्सशी तुलना करते. Retail , Hospitality आणि स्टेडिअम्स सारख्या हाय-डेन्सिटी वातावरणाचे व्यवस्थापन करणाऱ्या IT मॅनेजर्स, नेटवर्क आर्किटेक्ट्स आणि व्हेन्यू ऑपरेशन्स डायरेक्टर्ससाठी, या फेलओव्हर स्ट्रॅटेजीज, लोड बॅलेंसिंग मेकॅनिक्स आणि डेटाबेस रेप्लिकेशन आवश्यकता समजून घेणे आवश्यक आहे.
शिवाय, ही मार्गदर्शिका क्लाउड RADIUS प्लॅटफॉर्म हाय अव्हेलेबिलिटीची गुंतागुंत कशी कमी करतात, रिडंडंट ऑन-प्रिमाइसेस इन्फ्रास्ट्रक्चर राखण्याच्या ऑपरेशनल ओझ्याशिवाय स्वयंचलित फेलओव्हर आणि इलॅस्टिक स्केलेबिलिटी कशी प्रदान करतात याचे परीक्षण करते. या वेंडर-न्यूट्रल सर्वोत्तम पद्धती लागू करून, इंजिनिअरिंग टीम्स असे ऑथेंटिकेशन आर्किटेक्चर डिझाइन करू शकतात जे सिंगल पॉइंट्स ऑफ फेल्युअर काढून टाकतात आणि कडक अपटाइम सर्व्हिस लेव्हल ॲग्रीमेंट्स (SLAs) पूर्ण करतात.
तांत्रिक सखोल माहिती: RADIUS आर्किटेक्चर समजून घेणे
RADIUS UDP वर क्लायंट-सर्व्हर प्रोटोकॉल म्हणून कार्य करते, सामान्यतः RFC 2865 आणि RFC 2866 मध्ये परिभाषित केल्यानुसार ऑथेंटिकेशनसाठी पोर्ट 1812 आणि अकाउंटिंगसाठी पोर्ट 1813 वापरते. UDP ऑथेंटिकेशन विनंत्यांचे स्टेटलेस स्वरूप हाय अव्हेलेबिलिटी डिझाइनसाठी एक स्ट्रक्चरल फायदा आहे. कारण प्रत्येक Access-Request पॅकेटमध्ये सर्व आवश्यक क्रेडेंशियल्स आणि पॅरामीटर्स असतात, क्लस्टरमधील कोणताही RADIUS सर्व्हर ऑथेंटिकेशन फेजसाठी जटिल स्टेट सिंक्रोनाइझेशनची आवश्यकता नसताना स्वतंत्रपणे कोणत्याही विनंतीवर प्रक्रिया करू शकतो.
Active-Passive आर्किटेक्चर
Active-Passive (किंवा प्रायमरी-स्टँडबाय) डिप्लॉयमेंटमध्ये, एकच RADIUS सर्व्हर सर्व इनकमिंग ऑथेंटिकेशन आणि अकाउंटिंग ट्रॅफिकवर प्रक्रिया करतो. दुय्यम सर्व्हर ऑनलाइन राहतो परंतु निष्क्रिय असतो, डेटाबेस रेप्लिकेशन अपडेट्स प्राप्त करतो परंतु ॲक्सेस पॉइंट्स, स्विचेस किंवा VPN गेटवेज सारख्या नेटवर्क ॲक्सेस डिव्हाइसेसना (NADs) सक्रियपणे प्रतिसाद देत नाही.
जेव्हा प्राथमिक सर्व्हर निकामी होतो, तेव्हा NAD टाइमआउट शोधतो आणि त्यानंतरच्या विनंत्या दुय्यम सर्व्हरकडे वळवतो. फेलओव्हर डिटेक्शन वेळ पूर्णपणे NAD च्या कॉन्फिगरेशन टाइमरवर अवलंबून असतो. एक सामान्य NAD RADIUS विनंती पाठवतो आणि डीफॉल्ट पॅकेट टाइमआउट (अनेकदा दोन सेकंद) साठी थांबतो. प्रतिसाद न मिळाल्यास, तो पुन्हा प्रयत्न करतो. प्रति सर्व्हर तीन प्रयत्नांच्या मानक कॉन्फिगरेशनसह, NAD प्राथमिक सर्व्हर बंद असल्याचे घोषित करण्यापूर्वी आणि दुय्यम सर्व्हरवर फेलओव्हर करण्यापूर्वी सहा सेकंदांपर्यंत प्रतीक्षा करू शकतो. तीन कॉन्फिगर केलेल्या सर्व्हर असलेल्या वातावरणात, ही फेलओव्हर विंडो अठरा सेकंदांपर्यंत वाढू शकते. व्यस्त Hospitality ठिकाण किंवा ट्रान्झॅक्शन्सवर प्रक्रिया करणाऱ्या Retail वातावरणासाठी, हा विलंब सेवेमध्ये लक्षणीय व्यत्यय दर्शवतो.
Active-Active आर्किटेक्चर
याउलट, Active-Active आर्किटेक्चर एकाच वेळी अनेक कार्यरत RADIUS सर्व्हरवर ऑथेंटिकेशन लोड वितरीत करते. ट्रॅफिक एकतर NADs वरील राउंड-रॉबिन कॉन्फिगरेशनद्वारे किंवा समर्पित लोड बॅलन्सरद्वारे क्लस्टरकडे वळवले जाते.
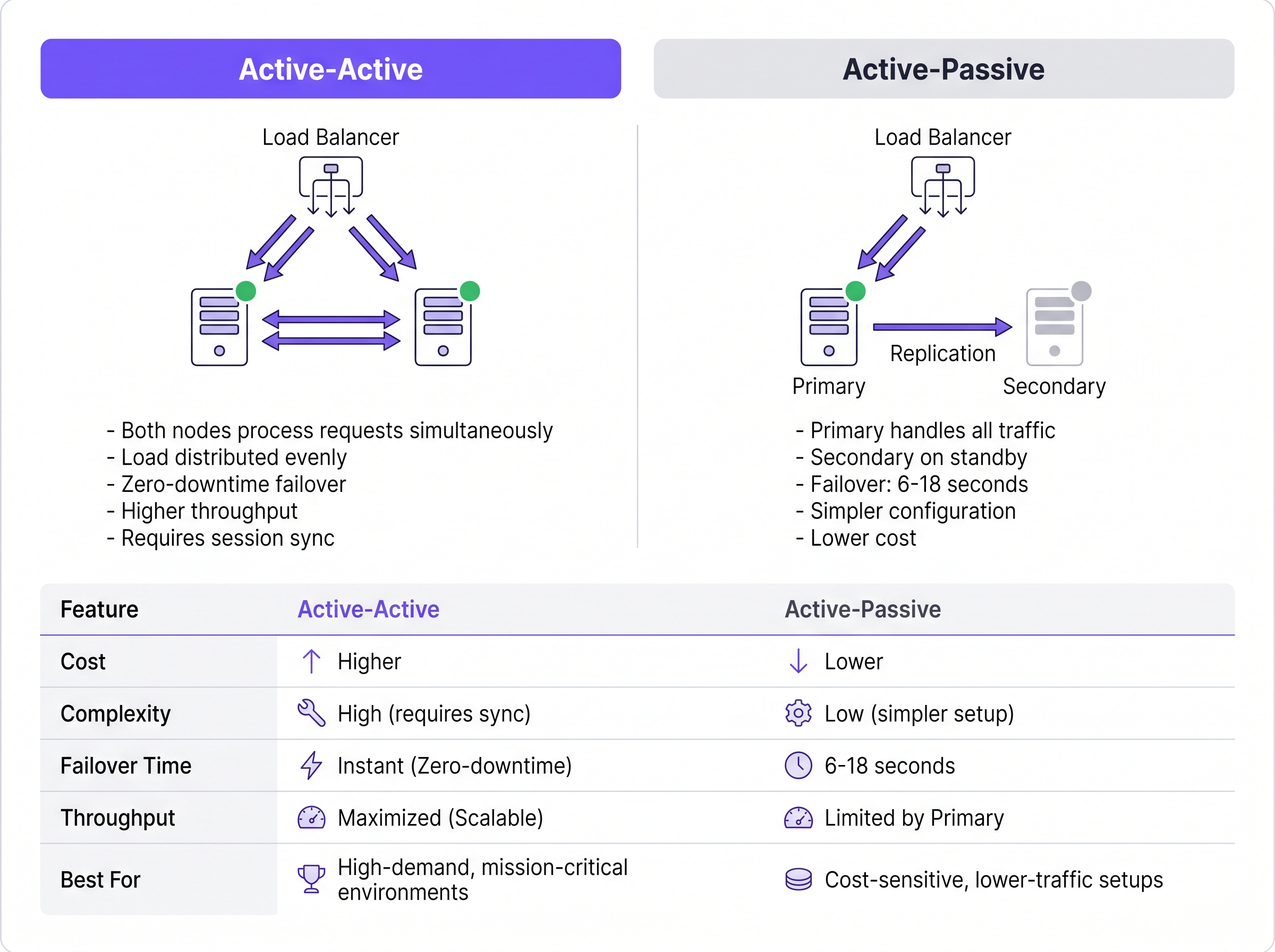
हे मॉडेल Active-Passive सेटअपमध्ये अंतर्निहित असलेला फेलओव्हर डिटेक्शन विलंब काढून टाकते. जर एखादा नोड निकामी झाला, तर लोड बॅलन्सर (किंवा राउंड-रॉबिन वापरणारे NADs) प्रतिसाद न देणाऱ्या सर्व्हरकडे ट्रॅफिक वळवणे थांबवतात, जे सहसा हेल्थ-चेक इंटरव्हल्सवर आधारित एक ते दोन सेकंदात घडते. उर्वरित सक्रिय नोड्स त्वरित ट्रॅफिक शोषून घेतात. शिवाय, Active-Active क्लस्टर्स हॉरिझॉन्टली स्केल होतात; हाय-डेन्सिटी इव्हेंट्ससाठी क्षमता वाढवण्यासाठी फक्त क्लस्टरमध्ये अतिरिक्त नोड्स प्रोव्हिजन करणे आवश्यक असते.
डेटाबेस रेप्लिकेशनचे आव्हान
RADIUS ऑथेंटिकेशन स्टेटलेस असले तरी, RADIUS अकाउंटिंग मूळतः स्टेटफुल आहे. हे सेशनची सुरुवात (Start), चालू वापर (Interim-Update) आणि समाप्ती (Stop) ट्रॅक करते. WiFi Analytics किंवा बिलिंग सिस्टम वापरणाऱ्या ठिकाणांसाठी, हा अकाउंटिंग डेटा सर्व नोड्सवर सुसंगत असणे आवश्यक आहे.
मजबूत हाय अव्हेलेबिलिटीसाठी रेप्लिकेटेड डेटाबेससह (जसे की FreeRADIUS सह एकत्रित MySQL किंवा MariaDB) RADIUS क्लस्टरला बॅकअप देणे अनिवार्य आहे. Active-Active डिप्लॉयमेंट्ससाठी, सिंक्रोनस मल्टी-मास्टर रेप्लिकेशन—जसे की Galera Cluster किंवा MySQL NDB Cluster—आवश्यक आहे. सिंक्रोनस रेप्लिकेशन हे सुनिश्चित करते की अकाउंटिंग रेकॉर्ड एकाच वेळी सर्व नोड्सवर कमिट केला जातो, ज्यामुळे एखादा नोड निकामी झाल्यास डेटा गमावण्यापासून बचाव होतो. पारंपारिक असिंक्रोनस रेप्लिकेशन, जे सहसा Active-Passive सेटअपमध्ये वापरले जाते, रेप्लिकेशन लॅग निर्माण करते. जर दुय्यम नोडला अपडेट मिळण्यापूर्वी प्राथमिक नोड निकामी झाला, तर सक्रिय सेशन डेटा कायमचा गमावला जातो, जे PCI DSS सारख्या कंप्लायन्स फ्रेमवर्क्सचे उल्लंघन करू शकते.
अंमलबजावणी मार्गदर्शिका: क्लाउड विरुद्ध ऑन-प्रिमाइसेस
आर्किटेक्चरल निर्णय केवळ सर्व्हर कसे क्लस्टर करायचे यापलीकडे जातो; त्यामध्ये ते सर्व्हर कोठे आहेत याचा समावेश होतो. मल्टी-साइट ऑपरेटर्ससाठी, ऑथेंटिकेशन ट्रॅफिकला केंद्रीकृत ऑन-प्रिमाइसेस डेटा सेंटरकडे बॅकहॉल केल्याने WAN लॅटन्सी येते आणि WAN लिंकवर सिंगल पॉइंट ऑफ फेल्युअर तयार होतो.
क्लाउड RADIUS Plक्लाउड RADIUS सेवा एकाधिक जागतिक उपलब्धता झोनमध्ये ऑथेंटिकेशन इन्फ्रास्ट्रक्चर होस्ट करून भौगोलिक वितरण आव्हाने सोडवतात. जेव्हा एखादा वापरकर्ता ब्रँच लोकेशनवर कनेक्ट होतो, तेव्हा विनंती जवळच्या क्लाउड एज नोडवर पाठवली जाते, ज्यामुळे लॅटन्सी कमी होते.
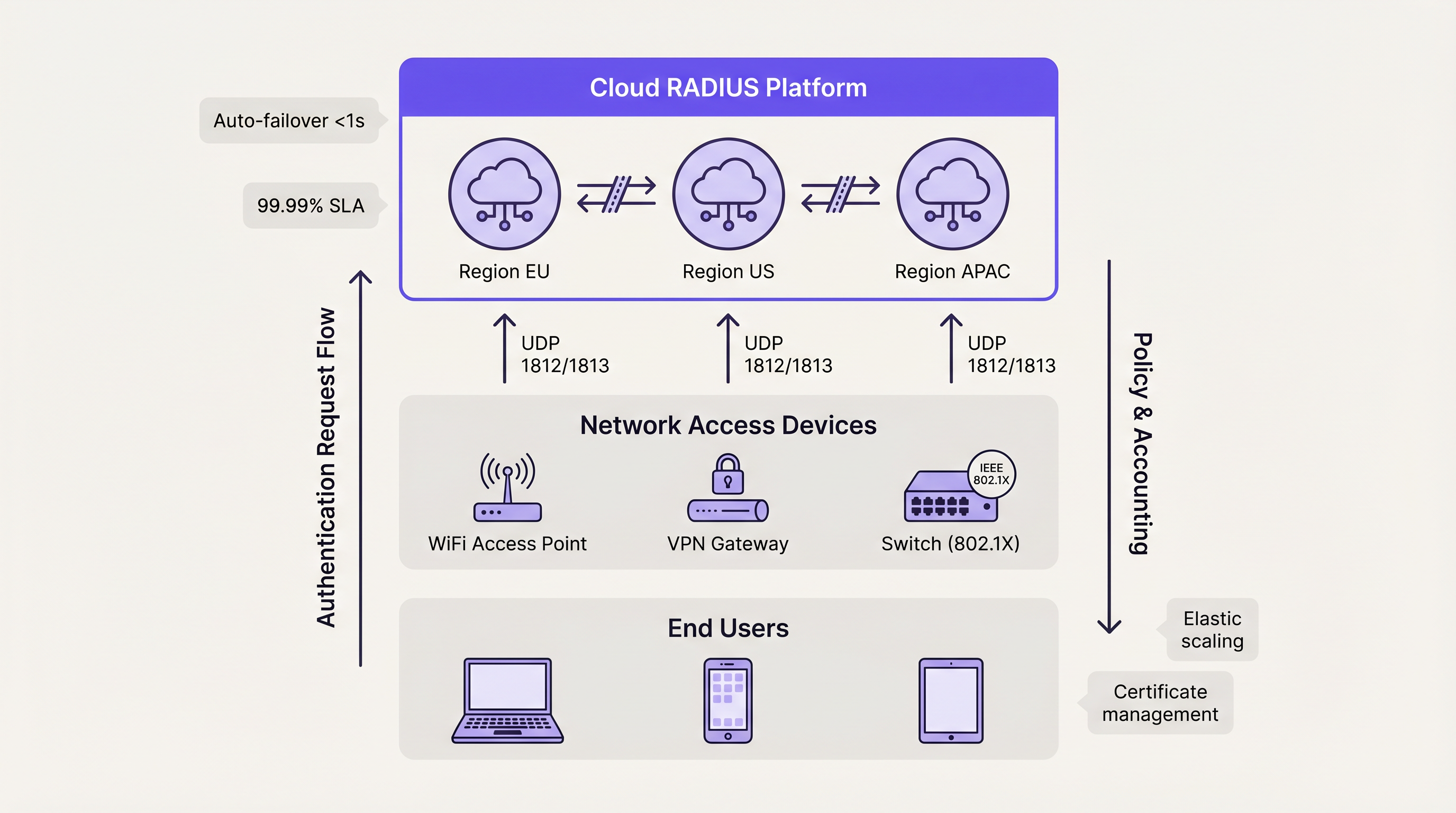
क्लाउड प्लॅटफॉर्म्स नैसर्गिकरित्या ॲक्टिव्ह-ॲक्टिव्ह आर्किटेक्चर वापरतात. उपलब्धता झोनमधील फेलओव्हर प्रदात्याच्या अंतर्गत लोड बॅलेंसिंगद्वारे स्वयंचलितपणे हाताळले जाते, ज्यामुळे ग्राहकाच्या इंजिनिअरिंग टीमची गुंतागुंत पूर्णपणे दूर होते. हे मॉडेल सामान्यतः 99.99% अपटाइम SLA प्रदान करते आणि मॅन्युअल सर्टिफिकेट मॅनेजमेंट, ऑपरेटिंग सिस्टम पॅचिंग आणि डेटाबेस रेप्लिकेशन ट्यूनिंगची आवश्यकता काढून टाकते. वितरित कॅम्पसमध्ये Wayfinding किंवा Sensors तैनात करणाऱ्या संस्थांसाठी, क्लाउड-होस्ट केलेले ऑथेंटिकेशन स्थानिक हार्डवेअर अवलंबनाशिवाय सुसंगत पॉलिसी अंमलबजावणी सुनिश्चित करते.
ऑन-प्रिमाइसेस डिप्लॉयमेंटसाठी विचारात घेण्यासारख्या गोष्टी
अत्यंत नियमन केलेल्या क्षेत्रांमध्ये कार्यरत असलेल्या संस्थांना—जसे की विशिष्ट हेल्थकेयर किंवा सरकारी वातावरण—कठोर डेटा सार्वभौमत्व नियमांमुळे ऑन-प्रिमाइसेस डिप्लॉयमेंटची आवश्यकता असू शकते. या परिस्थितींमध्ये, Galera सिंक्रोनस रेप्लिकेशनसह ॲक्टिव्ह-ॲक्टिव्ह FreeRADIUS क्लस्टर तैनात करणे सर्वोच्च पातळीची लवचिकता प्रदान करते.
तथापि, इंजिनिअरिंग टीम्सनी ऑपरेशनल ओव्हरहेडचा विचार करणे आवश्यक आहे. एकाधिक नोड्सवर TLS सर्टिफिकेट्स व्यवस्थापित करणे, कॉन्फिगरेशन सुसंगतता सुनिश्चित करणे आणि डेटाबेस रेप्लिकेशन हेल्थचे सक्रियपणे निरीक्षण करणे यासाठी समर्पित प्रशासकीय संसाधनांची आवश्यकता असते. हार्डवेअर लोड बॅलेंसर्स विशेषतः योग्य RADIUS हेल्थ चेकसह UDP ट्रॅफिकला सपोर्ट करण्यासाठी कॉन्फिगर केलेले असणे आवश्यक आहे, कारण अनेक मानक लोड बॅलेंसर्स केवळ TCP HTTP/HTTPS ट्रॅफिकसाठी ऑप्टिमाइझ केलेले असतात.
RADIUS हाय अव्हेलेबिलिटीसाठी सर्वोत्तम पद्धती
- ड्युप्लिकेट करण्याऐवजी वितरित करा: 500 पेक्षा जास्त समवर्ती वापरकर्त्यांच्या डिप्लॉयमेंटसाठी, थ्रूपुट वाढवण्यासाठी आणि फेलओव्हर लॅटन्सी कमी करण्यासाठी ॲक्टिव्ह-पॅसिव्ह सेटअपपेक्षा ॲक्टिव्ह-ॲक्टिव्ह आर्किटेक्चरला प्राधान्य द्या.
- सिंक्रोनस रेप्लिकेशन लागू करा: असिंक्रोनस प्रायमरी-रेप्लिका मॉडेल्सऐवजी सिंक्रोनस मल्टी-मास्टर डेटाबेस रेप्लिकेशन (उदा. Galera Cluster) वापरून स्टेटफुल अकाउंटिंग डेटा सुरक्षित करा.
- सर्टिफिकेट ट्रस्टचे मानकीकरण करा: ॲक्टिव्ह-ॲक्टिव्ह क्लस्टरमध्ये, सर्व नोड्स समान सर्व्हर सर्टिफिकेट किंवा अगदी त्याच सर्टिफिकेट अथॉरिटी (CA) चेनमधील सर्टिफिकेट्स सादर करत असल्याची खात्री करा. विसंगतीमुळे नोड रोटेशन दरम्यान EAP-TLS आणि PEAP हँडशेक अयशस्वी होतील.
- NAD टाइमर्स ट्यून करा: तुमच्या नेटवर्क ॲक्सेस डिव्हाइसेसवर RADIUS रिट्राय आणि टाइमआउट टाइमर्स ऑप्टिमाइझ करा. दोन रिट्रायसह दोन-सेकंद टाइमआउट जलद फेलओव्हर शोधणे आणि किरकोळ नेटवर्क कंजेशन दरम्यान अकाली फेलओव्हर रोखणे यामध्ये संतुलन प्रदान करते.
- बिघाड परिस्थितींची चाचणी करा: दुय्यम नोड्सना प्रोडक्शन सिस्टम्सप्रमाणे समजा. स्वयंचलित फेलओव्हर यंत्रणा डिझाइन केल्याप्रमाणे कार्य करतात हे सत्यापित करण्यासाठी नियमितपणे नोड बिघाड, डेटाबेस डीसिंक्रोनाइझेशन आणि WAN लिंक ड्रॉप्सचे सिम्युलेशन करा.
ट्रबलशूटिंग आणि जोखीम कमी करणे
RADIUS हाय अव्हेलेबिलिटीमध्ये सर्वात प्रचलित बिघाड मोड म्हणजे कॉन्फिगरेशन ड्रिफ्ट. ॲक्टिव्ह-पॅसिव्ह सेटअपमध्ये, प्रशासक वारंवार प्रायमरी नोडवर पॉलिसी अपडेट करतात किंवा सर्टिफिकेट्स रिन्यू करतात परंतु दुय्यम नोडकडे दुर्लक्ष करतात. जेव्हा फेलओव्हर इव्हेंट घडतो, तेव्हा दुय्यम नोड कालबाह्य क्रेडेंशियल्स किंवा जुन्या पॉलिसींमुळे कायदेशीर ट्रॅफिक नाकारतो.
ही जोखीम कमी करण्यासाठी, सर्व नोड्सवर सममितीयपणे बदल तैनात करण्यासाठी कॉन्फिगरेशन मॅनेजमेंट टूल्स (जसे की Ansible किंवा Terraform) लागू करा. सर्टिफिकेट मॅनेजमेंटसाठी, संपूर्ण क्लस्टरमध्ये अपडेट केलेले सर्टिफिकेट एकाच वेळी वितरित करण्यासाठी कॉन्फिगर केलेले स्वयंचलित रिन्यूअल प्रोटोकॉल (जसे की ACME) वापरा.
दुसरी महत्त्वाची जोखीम म्हणजे लोड बॅलेंसरचे चुकीचे कॉन्फिगरेशन. जर लोड बॅलेंसर ॲप्लिकेशन-लेयर हेल्थ चेक करत नसेल (विशेषतः UDP पोर्ट 1812 रिस्पॉन्सिव्हनेसची पडताळणी करणे), तर तो अशा नोडवर ट्रॅफिक पाठवणे सुरू ठेवू शकतो जिथे ऑपरेटिंग सिस्टम चालू आहे परंतु RADIUS डिमन क्रॅश झाला आहे. हेल्थ चेक स्पष्टपणे RADIUS सेवा उपलब्धता सत्यापित करतात याची खात्री करा.
ROI आणि व्यावसायिक प्रभाव
मजबूत RADIUS हाय अव्हेलेबिलिटीसाठी गुंतवणुकीवरील परतावा (ROI) प्रामुख्याने जोखीम कमी करणे आणि ऑपरेशनल कार्यक्षमतेद्वारे मोजला जातो. ऑथेंटिकेशन आउटेजमुळे कर्मचाऱ्यांच्या उत्पादकतेचे त्वरित नुकसान होते आणि सार्वजनिक ठिकाणांसाठी गंभीर प्रतिष्ठेचे नुकसान होते.
मॅन्युअल, सिंगल-सर्व्हर डिप्लॉयमेंटकडून स्वयंचलित, ॲक्टिव्ह-ॲक्टिव्ह आर्किटेक्चरकडे (विशेषतः क्लाउड RADIUS द्वारे) वळल्यामुळे, संस्था पूर्वी नियमित देखभालीसाठी समर्पित असलेले महत्त्वपूर्ण इंजिनिअरिंग तास वाचवू शकतात. ही ऑपरेशनल कार्यक्षमता नेटवर्क टीम्सना ऑथेंटिकेशन बिघाड दुरुस्त करण्याऐवजी धोरणात्मक उपक्रमांवर लक्ष केंद्रित करण्यास अनुमती देते, जसे की आधुनिक व्यवसायांसाठी मुख्य SD WAN फायदे तैनात करणे किंवा हाय-डेन्सिटी कव्हरेज ऑप्टिमाइझ करणे. शेवटी, विश्वसनीय ऑथेंटिकेशन हा पायाभूत स्तर आहे ज्यावर त्यानंतरच्या सर्व नेटवर्क सेवा अवलंबून असतात.
महत्त्वाच्या संज्ञा आणि व्याख्या
Active-Active Architecture
A high availability design where multiple RADIUS servers process authentication requests simultaneously, distributing the load and providing instant failover without detection delays.
Essential for high-density venues (stadiums, large retail) where a single server cannot handle peak authentication surges.
Active-Passive Architecture
A redundancy model where a primary server handles all traffic, and a secondary server remains idle on standby until the primary fails.
Suitable for smaller, cost-sensitive deployments, but introduces a 6-18 second failover delay while the network access device detects the failure.
Synchronous Replication
A database replication method where data is written to all nodes in a cluster simultaneously before the transaction is considered complete.
Mandatory for Active-Active RADIUS accounting databases (like Galera Cluster) to prevent data loss and ensure compliance.
Asynchronous Replication
A database replication method where the primary node records the data and later copies it to secondary nodes, introducing a slight delay (lag).
Often used in Active-Passive setups but carries the risk of losing recent accounting records if the primary node fails abruptly.
Network Access Device (NAD)
The hardware component (such as a WiFi access point, switch, or VPN gateway) that requests authentication from the RADIUS server on behalf of the user.
The NAD's internal retry and timeout timers dictate how quickly an Active-Passive failover occurs.
Stateless Protocol
A communications protocol that treats each request as an independent transaction, unrelated to any previous request.
RADIUS authentication over UDP is stateless, allowing load balancers to route any request to any active server seamlessly.
Configuration Drift
The phenomenon where secondary or backup servers become out of sync with the primary server regarding policies, updates, or certificates over time.
The leading cause of failure in Active-Passive RADIUS deployments when the secondary node is forced to take over.
Cloud RADIUS
A managed authentication service hosted across globally distributed cloud infrastructure, providing built-in Active-Active redundancy and automatic scaling.
Replaces the need for IT teams to manually build, patch, and monitor redundant on-premise RADIUS servers.
केस स्टडीज
A European hotel group manages 45 properties across six countries. They currently run independent FreeRADIUS virtual machines at each property. A recent expired TLS certificate at one location caused a complete guest WiFi outage during a major conference. How should they redesign their authentication architecture to prevent localized outages and reduce maintenance overhead?
The hotel group should migrate from localized, single-node FreeRADIUS instances to a centralized Cloud RADIUS platform utilizing an Active-Active architecture. By leveraging a cloud provider with geographically distributed edge nodes, authentication requests from each property are routed to the nearest regional node, minimizing latency. Centralized policy management allows the IT team to define authentication rules once and apply them globally. The cloud provider automatically handles TLS certificate rotation, operating system patching, and database replication.
A national sports stadium is preparing for a 60,000-attendee event. Their current RADIUS setup is an Active-Passive configuration. During load testing, the primary server became saturated processing 8,000 authentication requests per minute when the gates opened, causing severe connection delays, while the secondary server remained completely idle. How can they optimize this deployment?
The network engineering team must convert the deployment from Active-Passive to Active-Active. First, they should reconfigure the stadium's Network Access Devices (NADs) to utilize round-robin load balancing across both RADIUS servers, instantly doubling their authentication throughput. Second, they should provision a third RADIUS node to provide necessary headroom for peak surges. Finally, to ensure accounting data remains consistent across all three active nodes, they must implement a synchronous multi-master database replication solution, such as Galera Cluster.
परिस्थिती विश्लेषण
Q1. Your enterprise retail client requires a highly available RADIUS solution for their point-of-sale terminals. They have strict PCI DSS compliance requirements dictating that absolutely no accounting session data can be lost during a server failover. Which database replication strategy must you implement for the RADIUS backend?
💡 संकेत:Consider the difference between data being written simultaneously versus data being copied after the fact.
शिफारस केलेला दृष्टिकोन दाखवा
You must implement Synchronous Replication (such as a Galera Cluster or MySQL NDB Cluster). Synchronous replication ensures that the accounting record is committed to all nodes simultaneously before acknowledging the transaction. If you used Asynchronous replication, a node failure could result in the loss of recent transactions that had not yet been copied to the secondary database, violating the strict compliance requirement.
Q2. A university campus network uses an Active-Passive RADIUS setup. Students complain that when the primary server undergoes maintenance, it takes nearly 20 seconds for their laptops to connect to the WiFi. The access points are configured with a 3-second RADIUS timeout and 5 retries. How can you reduce the failover delay without changing the server architecture?
💡 संकेत:Calculate the maximum wait time based on the NAD timers before it attempts the secondary server.
शिफारस केलेला दृष्टिकोन दाखवा
You should tune the timers on the Network Access Devices (access points). Currently, the AP waits 3 seconds and retries 5 times, resulting in an 18-second delay (3 seconds × 6 total attempts) before failing over to the passive server. By reducing the configuration to a 2-second timeout and 2 retries, the failover detection time drops to 6 seconds, significantly improving the user experience during maintenance windows.
Q3. You are migrating a multi-site corporate network from an Active-Passive on-premise RADIUS server to an Active-Active Cloud RADIUS platform. During the pilot phase, devices successfully authenticate against Cloud Node A, but when the load balancer routes them to Cloud Node B, the EAP-TLS handshakes fail. What is the most likely configuration error?
💡 संकेत:Consider what the client device verifies when establishing a secure EAP tunnel with a new server.
शिफारस केलेला दृष्टिकोन दाखवा
The most likely issue is a Certificate Trust mismatch. In an Active-Active cluster, all RADIUS nodes must present the exact same server certificate (or certificates issued by the exact same trusted CA chain). If Cloud Node B is presenting a different certificate that the client devices do not trust, the EAP-TLS handshake will be rejected by the client, causing authentication to fail despite the server functioning correctly.
महत्त्वाचे निष्कर्ष
- ✓RADIUS high availability is critical because authentication failures immediately block all network access for users and devices.
- ✓Active-Passive setups are simpler but introduce a 6-18 second failover delay dictated by the Network Access Device's retry timers.
- ✓Active-Active architectures process requests simultaneously, providing instant failover and horizontal scalability for high-density environments.
- ✓While RADIUS authentication is stateless, accounting is stateful and requires synchronous database replication (like Galera) to prevent data loss.
- ✓Cloud RADIUS platforms abstract HA complexity by providing globally distributed, automatically scaling Active-Active infrastructure.
- ✓Configuration drift and mismatched TLS certificates are the most common causes of failure during RADIUS failover events.
