Alta disponibilità del server RADIUS: Active-Active vs Active-Passive
Una guida di riferimento tecnico definitiva per IT manager e architetti di rete che valutano le architetture ad alta disponibilità RADIUS. Mette a confronto le distribuzioni Active-Active e Active-Passive, dettaglia i requisiti di replica del database e spiega come Cloud RADIUS riduca la latenza di failover per le sedi aziendali.
🎧 Ascolta questa guida
Visualizza trascrizione

Sintesi operativa
Per le reti aziendali, l'autenticazione è binaria: o funziona perfettamente, o le operazioni aziendali si interrompono completamente. RADIUS (Remote Authentication Dial-In User Service) funge da gatekeeper critico per le implementazioni IEEE 802.1X, WPA3 enterprise e Guest WiFi nelle sedi moderne. A differenza dei servizi applicativi che degradano gradualmente sotto carico, un guasto RADIUS blocca immediatamente l'accesso alla rete a utenti, terminali point-of-sale e dispositivi operativi.
Questa guida di riferimento tecnico valuta i modelli architetturali per l'implementazione di un'infrastruttura RADIUS ad alta disponibilità. Nello specifico, mette a confronto le configurazioni Active-Passive tradizionali con i moderni cluster Active-Active. Per gli IT manager, gli architetti di rete e i direttori delle operazioni che gestiscono ambienti ad alta densità come Retail , Hospitality e stadi, la comprensione di queste strategie di failover, della meccanica di bilanciamento del carico e dei requisiti di replica del database è essenziale.
Inoltre, questa guida esamina come le piattaforme Cloud RADIUS astraggano la complessità dell'alta disponibilità, fornendo failover automatico e scalabilità elastica senza l'onere operativo di mantenere un'infrastruttura on-premise ridondante. Applicando queste best practice indipendenti dai fornitori, i team di ingegneria possono progettare architetture di autenticazione che eliminano i singoli punti di guasto e soddisfano rigorosi accordi sul livello di servizio (SLA) di uptime.
Approfondimento tecnico: comprendere l'architettura RADIUS
RADIUS opera come un protocollo client-server su UDP, utilizzando tipicamente la porta 1812 per l'autenticazione e la porta 1813 per l'accounting, come definito in RFC 2865 e RFC 2866. La natura stateless delle richieste di autenticazione UDP è un vantaggio strutturale per la progettazione dell'alta disponibilità. Poiché ogni pacchetto Access-Request contiene tutte le credenziali e i parametri necessari, qualsiasi server RADIUS all'interno di un cluster può elaborare qualsiasi richiesta in modo indipendente, senza richiedere una complessa sincronizzazione dello stato per la fase di autenticazione stessa.
Architettura Active-Passive
In una distribuzione Active-Passive (o primary-standby), un singolo server RADIUS elabora tutto il traffico di autenticazione e accounting in entrata. Un server secondario rimane online ma inattivo, ricevendo aggiornamenti di replica del database ma senza rispondere attivamente ai Network Access Devices (NAD) come access point, switch o gateway VPN.
Quando il server primario si guasta, il NAD rileva il timeout e reindirizza le richieste successive al server secondario. Il tempo di rilevamento del failover dipende interamente dai timer di configurazione del NAD. Un tipico NAD invia una richiesta RADIUS e attende un timeout di pacchetto predefinito (spesso due secondi). Se non riceve risposta, riprova. Con una configurazione standard di tre tentativi per server, il NAD può attendere fino a sei secondi prima di dichiarare il server primario inattivo e passare al secondario. In ambienti con tre server configurati, questa finestra di failover può estendersi fino a diciotto secondi. Per una sede Hospitality affollata o un ambiente Retail che elabora transazioni, questo ritardo rappresenta un'interruzione evidente del servizio.
Architettura Active-Active
Al contrario, un'architettura Active-Active distribuisce il carico di autenticazione su più server RADIUS operativi simultaneamente. Il traffico viene instradato al cluster tramite configurazione round-robin sui NAD o attraverso un bilanciatore di carico dedicato.
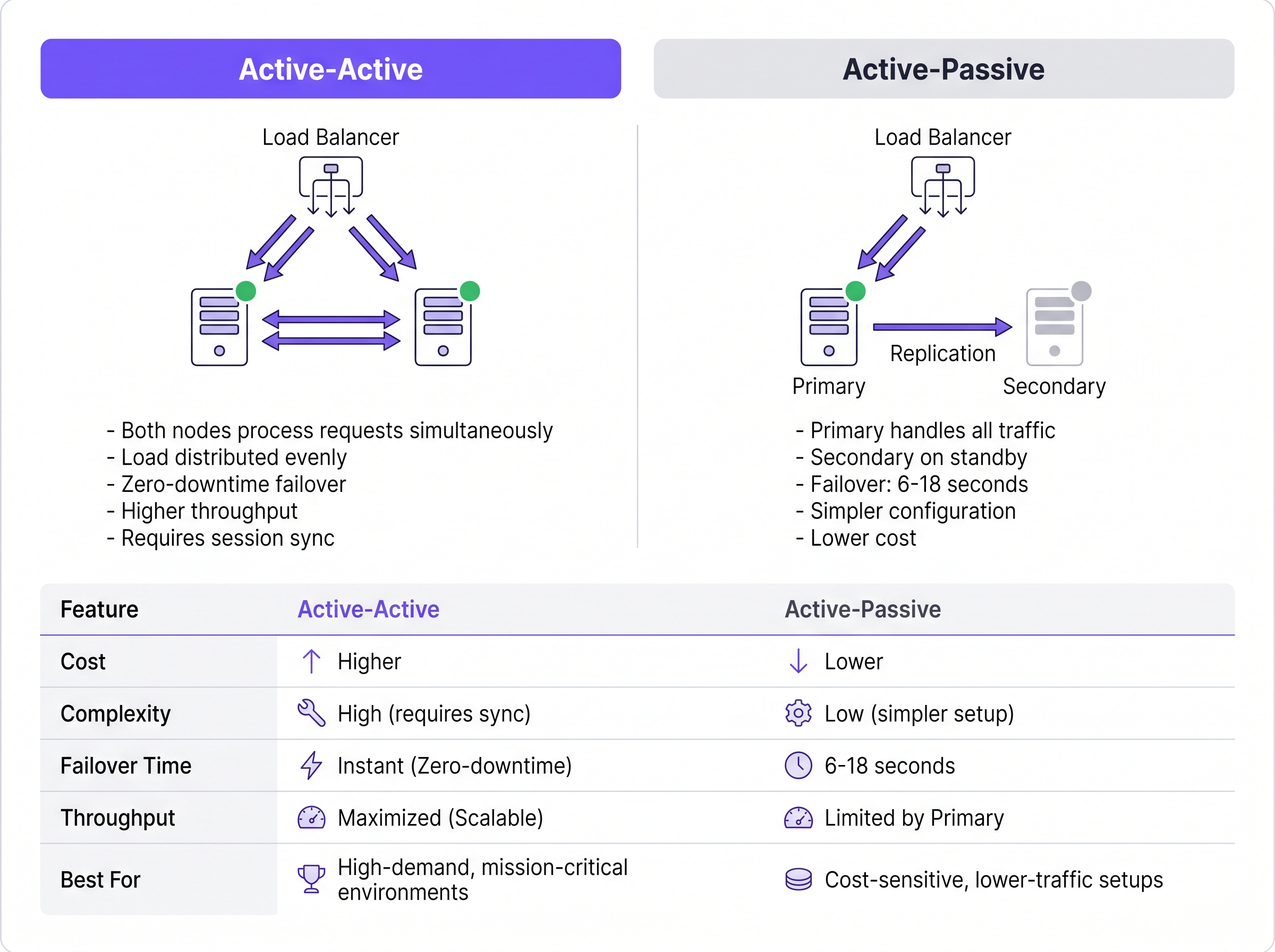
Questo modello elimina il ritardo nel rilevamento del failover inerente alle configurazioni Active-Passive. Se un nodo si guasta, il bilanciatore di carico (o i NAD che utilizzano il round-robin) smette semplicemente di instradare il traffico al server che non risponde, in genere entro uno o due secondi in base agli intervalli di controllo dello stato (health-check). I restanti nodi attivi assorbono istantaneamente il traffico. Inoltre, i cluster Active-Active scalano orizzontalmente; l'aggiunta di capacità per eventi ad alta densità richiede semplicemente il provisioning di nodi aggiuntivi al cluster.
La sfida della replica del database
Mentre l'autenticazione RADIUS è stateless, l'accounting RADIUS è intrinsecamente stateful. Tiene traccia dell'inizio della sessione (Start), dell'utilizzo in corso (Interim-Update) e della terminazione (Stop). Per le sedi che utilizzano WiFi Analytics o sistemi di fatturazione, questi dati di accounting devono rimanere coerenti su tutti i nodi.
Supportare un cluster RADIUS con un database replicato (come MySQL o MariaDB integrato con FreeRADIUS) è obbligatorio per una solida alta disponibilità. Per le distribuzioni Active-Active, è richiesta la replica multi-master sincrona, come Galera Cluster o MySQL NDB Cluster. La replica sincrona garantisce che un record di accounting venga salvato su tutti i nodi simultaneamente, prevenendo la perdita di dati in caso di guasto di un nodo. La tradizionale replica asincrona, spesso utilizzata nelle configurazioni Active-Passive, introduce un ritardo di replica. Se il nodo primario si guasta prima che il secondario riceva l'aggiornamento, i dati della sessione attiva vengono persi permanentemente, il che può violare i framework di conformità come PCI DSS.
Guida all'implementazione: Cloud vs On-Premise
La decisione architetturale va oltre il modo in cui raggruppare i server; riguarda il luogo in cui tali server risiedono. Per gli operatori multi-sito, il backhauling del traffico di autenticazione verso un data center on-premise centralizzato introduce latenza WAN e crea un singolo punto di guasto nel collegamento WAN.
Cloud RADIUS PlI servizi Cloud RADIUS risolvono le sfide della distribuzione geografica ospitando l'infrastruttura di autenticazione in più zone di disponibilità globali. Quando un utente si connette da una sede periferica, la richiesta viene instradata al nodo edge cloud più vicino, riducendo al minimo la latenza.
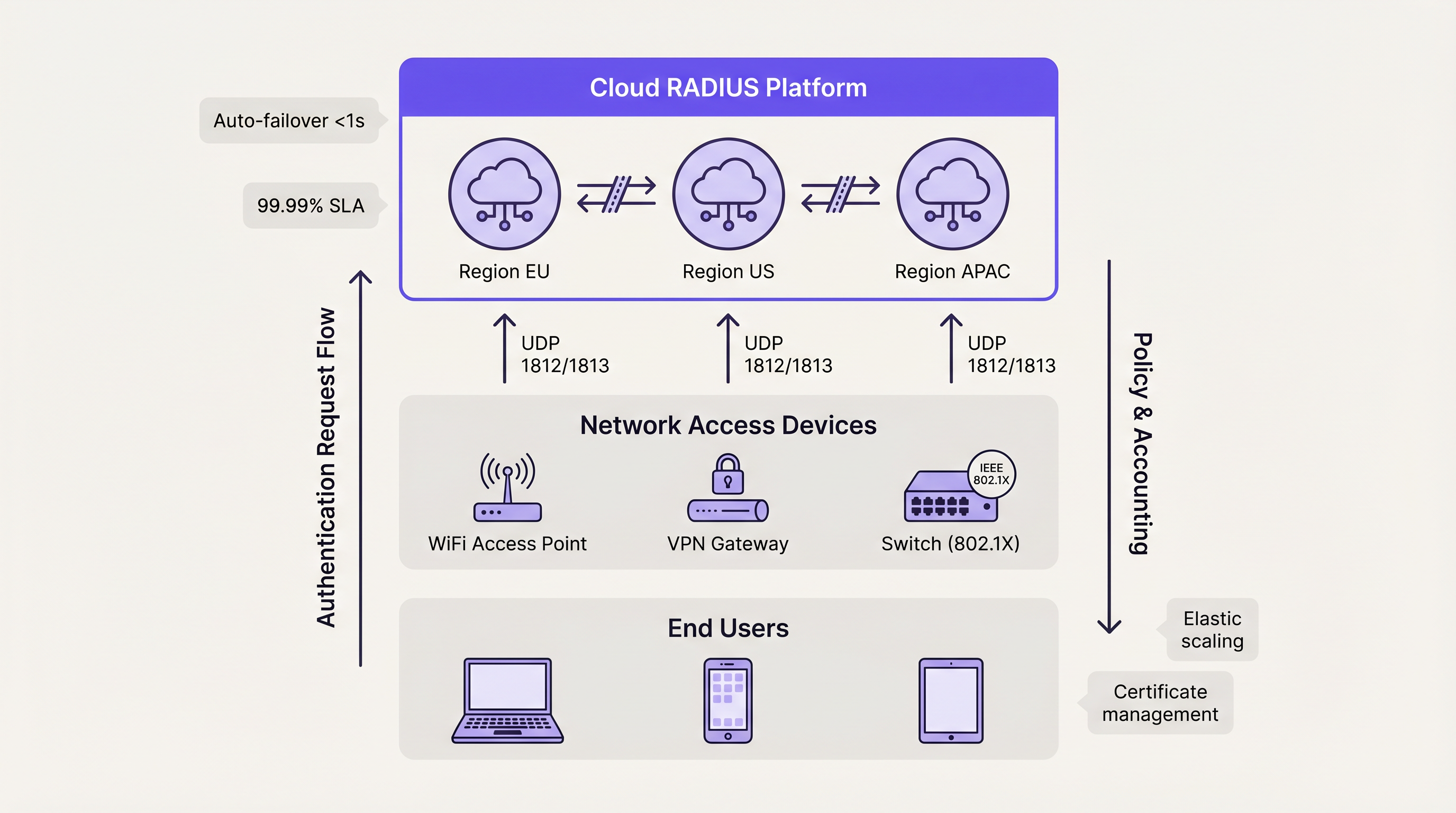
Le piattaforme cloud utilizzano intrinsecamente architetture Active-Active. Il failover tra le zone di disponibilità è gestito automaticamente dal bilanciamento del carico interno del provider, astraendo completamente la complessità per il team tecnico del cliente. Questo modello offre tipicamente SLA di uptime del 99,99% ed elimina la necessità di gestione manuale dei certificati, patching del sistema operativo e ottimizzazione della replica del database. Per le organizzazioni che distribuiscono Wayfinding o Sensors in campus distribuiti, l'autenticazione ospitata in cloud garantisce l'applicazione coerente delle policy senza dipendenze hardware localizzate.
Considerazioni sulla Distribuzione On-Premise
Le organizzazioni che operano in settori altamente regolamentati, come specifici ambienti Sanità o governativi, potrebbero richiedere distribuzioni on-premise a causa di rigidi mandati sulla sovranità dei dati. In questi scenari, la distribuzione di un cluster FreeRADIUS Active-Active con replica sincrona Galera offre il massimo livello di resilienza.
Tuttavia, i team tecnici devono tenere conto del sovraccarico operativo. La gestione dei certificati TLS su più nodi, la garanzia della coerenza della configurazione e il monitoraggio attivo dello stato della replica del database richiedono risorse amministrative dedicate. I bilanciatori di carico hardware devono essere configurati specificamente per supportare il traffico UDP con opportuni health check RADIUS, poiché molti bilanciatori di carico standard sono ottimizzati esclusivamente per il traffico TCP HTTP/HTTPS traffic.
Best Practice per l'Alta Affidabilità RADIUS
- Distribuire Piuttosto che Duplicare: Per distribuzioni che superano i 500 utenti simultanei, dare priorità alle architetture Active-Active rispetto alle configurazioni Active-Passive per massimizzare il throughput e ridurre al minimo la latenza di failover.
- Implementare la Replica Sincrona: Proteggere i dati di accounting stateful utilizzando la replica sincrona del database multi-master (ad esempio, Galera Cluster) anziché i modelli asincroni primario-replica.
- Standardizzare il Trust dei Certificati: In un cluster Active-Active, assicurarsi che tutti i nodi presentino lo stesso certificato server o certificati della stessa catena di Certificate Authority (CA). Eventuali discrepanze causeranno il fallimento degli handshake EAP-TLS e PEAP durante la rotazione dei nodi.
- Ottimizzare i Timer NAD: Ottimizzare i timer di retry e timeout RADIUS sui Network Access Devices. Un timeout di due secondi con due tentativi offre un equilibrio tra il rilevamento rapido del failover e la prevenzione di failover prematuri durante lievi congestioni di rete.
- Testare gli Scenari di Guasto: Trattare i nodi secondari come sistemi di produzione. Simulare regolarmente guasti ai nodi, desincronizzazione del database e cadute del collegamento WAN per convalidare che i meccanismi di failover automatico funzionino come previsto.
Risoluzione dei Problemi e Mitigazione dei Rischi
La modalità di guasto più comune nell'alta affidabilità RADIUS è il configuration drift. Nelle configurazioni Active-Passive, gli amministratori aggiornano frequentemente le policy o rinnovano i certificati sul nodo primario ma trascurano il secondario. Quando si verifica un evento di failover, il nodo secondario rifiuta il traffico legittimo a causa di credenziali scadute o policy non aggiornate.
Per mitigare questo rischio, implementare strumenti di gestione della configurazione (come Ansible o Terraform) per distribuire le modifiche in modo simmetrico su tutti i nodi. Per la gestione dei certificati, utilizzare protocolli di rinnovo automatico (come ACME) configurati per distribuire il certificato aggiornato contemporaneamente su tutto il cluster.
Un altro rischio significativo è la configurazione errata del bilanciatore di carico. Se un bilanciatore di carico non esegue health check a livello applicativo (nello specifico verificando la reattività della porta UDP 1812), potrebbe continuare a instradare il traffico verso un nodo in cui il sistema operativo è in esecuzione ma il demone RADIUS è andato in crash. Assicurarsi che gli health check convalidino esplicitamente la disponibilità del servizio RADIUS.
ROI e Impatto sul Business
Il ritorno sull'investimento per una solida alta affidabilità RADIUS si misura principalmente attraverso la mitigazione del rischio e l'efficienza operativa. Le interruzioni dell'autenticazione comportano perdite immediate di produttività per i dipendenti e gravi danni alla reputazione per i luoghi aperti al pubblico.
Passando da distribuzioni manuali su server singolo ad architetture Active-Active automatizzate (in particolare tramite Cloud RADIUS), le organizzazioni recuperano ore preziose di ingegneria precedentemente dedicate alla manutenzione ordinaria. Questa efficienza operativa consente ai team di rete di concentrarsi su iniziative strategiche, come la distribuzione di I vantaggi principali della SD WAN per le aziende moderne o l'ottimizzazione della copertura ad alta densità, invece di gestire le emergenze legate ai guasti di autenticazione. In definitiva, un'autenticazione affidabile è il livello fondamentale da cui dipendono tutti i successivi servizi di rete.
Termini chiave e definizioni
Active-Active Architecture
A high availability design where multiple RADIUS servers process authentication requests simultaneously, distributing the load and providing instant failover without detection delays.
Essential for high-density venues (stadiums, large retail) where a single server cannot handle peak authentication surges.
Active-Passive Architecture
A redundancy model where a primary server handles all traffic, and a secondary server remains idle on standby until the primary fails.
Suitable for smaller, cost-sensitive deployments, but introduces a 6-18 second failover delay while the network access device detects the failure.
Synchronous Replication
A database replication method where data is written to all nodes in a cluster simultaneously before the transaction is considered complete.
Mandatory for Active-Active RADIUS accounting databases (like Galera Cluster) to prevent data loss and ensure compliance.
Asynchronous Replication
A database replication method where the primary node records the data and later copies it to secondary nodes, introducing a slight delay (lag).
Often used in Active-Passive setups but carries the risk of losing recent accounting records if the primary node fails abruptly.
Network Access Device (NAD)
The hardware component (such as a WiFi access point, switch, or VPN gateway) that requests authentication from the RADIUS server on behalf of the user.
The NAD's internal retry and timeout timers dictate how quickly an Active-Passive failover occurs.
Stateless Protocol
A communications protocol that treats each request as an independent transaction, unrelated to any previous request.
RADIUS authentication over UDP is stateless, allowing load balancers to route any request to any active server seamlessly.
Configuration Drift
The phenomenon where secondary or backup servers become out of sync with the primary server regarding policies, updates, or certificates over time.
The leading cause of failure in Active-Passive RADIUS deployments when the secondary node is forced to take over.
Cloud RADIUS
A managed authentication service hosted across globally distributed cloud infrastructure, providing built-in Active-Active redundancy and automatic scaling.
Replaces the need for IT teams to manually build, patch, and monitor redundant on-premise RADIUS servers.
Casi di studio
A European hotel group manages 45 properties across six countries. They currently run independent FreeRADIUS virtual machines at each property. A recent expired TLS certificate at one location caused a complete guest WiFi outage during a major conference. How should they redesign their authentication architecture to prevent localized outages and reduce maintenance overhead?
The hotel group should migrate from localized, single-node FreeRADIUS instances to a centralized Cloud RADIUS platform utilizing an Active-Active architecture. By leveraging a cloud provider with geographically distributed edge nodes, authentication requests from each property are routed to the nearest regional node, minimizing latency. Centralized policy management allows the IT team to define authentication rules once and apply them globally. The cloud provider automatically handles TLS certificate rotation, operating system patching, and database replication.
A national sports stadium is preparing for a 60,000-attendee event. Their current RADIUS setup is an Active-Passive configuration. During load testing, the primary server became saturated processing 8,000 authentication requests per minute when the gates opened, causing severe connection delays, while the secondary server remained completely idle. How can they optimize this deployment?
The network engineering team must convert the deployment from Active-Passive to Active-Active. First, they should reconfigure the stadium's Network Access Devices (NADs) to utilize round-robin load balancing across both RADIUS servers, instantly doubling their authentication throughput. Second, they should provision a third RADIUS node to provide necessary headroom for peak surges. Finally, to ensure accounting data remains consistent across all three active nodes, they must implement a synchronous multi-master database replication solution, such as Galera Cluster.
Analisi degli scenari
Q1. Your enterprise retail client requires a highly available RADIUS solution for their point-of-sale terminals. They have strict PCI DSS compliance requirements dictating that absolutely no accounting session data can be lost during a server failover. Which database replication strategy must you implement for the RADIUS backend?
💡 Suggerimento:Consider the difference between data being written simultaneously versus data being copied after the fact.
Mostra l'approccio consigliato
You must implement Synchronous Replication (such as a Galera Cluster or MySQL NDB Cluster). Synchronous replication ensures that the accounting record is committed to all nodes simultaneously before acknowledging the transaction. If you used Asynchronous replication, a node failure could result in the loss of recent transactions that had not yet been copied to the secondary database, violating the strict compliance requirement.
Q2. A university campus network uses an Active-Passive RADIUS setup. Students complain that when the primary server undergoes maintenance, it takes nearly 20 seconds for their laptops to connect to the WiFi. The access points are configured with a 3-second RADIUS timeout and 5 retries. How can you reduce the failover delay without changing the server architecture?
💡 Suggerimento:Calculate the maximum wait time based on the NAD timers before it attempts the secondary server.
Mostra l'approccio consigliato
You should tune the timers on the Network Access Devices (access points). Currently, the AP waits 3 seconds and retries 5 times, resulting in an 18-second delay (3 seconds × 6 total attempts) before failing over to the passive server. By reducing the configuration to a 2-second timeout and 2 retries, the failover detection time drops to 6 seconds, significantly improving the user experience during maintenance windows.
Q3. You are migrating a multi-site corporate network from an Active-Passive on-premise RADIUS server to an Active-Active Cloud RADIUS platform. During the pilot phase, devices successfully authenticate against Cloud Node A, but when the load balancer routes them to Cloud Node B, the EAP-TLS handshakes fail. What is the most likely configuration error?
💡 Suggerimento:Consider what the client device verifies when establishing a secure EAP tunnel with a new server.
Mostra l'approccio consigliato
The most likely issue is a Certificate Trust mismatch. In an Active-Active cluster, all RADIUS nodes must present the exact same server certificate (or certificates issued by the exact same trusted CA chain). If Cloud Node B is presenting a different certificate that the client devices do not trust, the EAP-TLS handshake will be rejected by the client, causing authentication to fail despite the server functioning correctly.
Punti chiave
- ✓RADIUS high availability is critical because authentication failures immediately block all network access for users and devices.
- ✓Active-Passive setups are simpler but introduce a 6-18 second failover delay dictated by the Network Access Device's retry timers.
- ✓Active-Active architectures process requests simultaneously, providing instant failover and horizontal scalability for high-density environments.
- ✓While RADIUS authentication is stateless, accounting is stateful and requires synchronous database replication (like Galera) to prevent data loss.
- ✓Cloud RADIUS platforms abstract HA complexity by providing globally distributed, automatically scaling Active-Active infrastructure.
- ✓Configuration drift and mismatched TLS certificates are the most common causes of failure during RADIUS failover events.
