Alta disponibilidad del servidor RADIUS: Activo-Activo vs. Activo-Pasivo
Una guía de referencia técnica definitiva para gerentes de TI y arquitectos de red que evalúan arquitecturas de alta disponibilidad RADIUS. Contrasta implementaciones Activo-Activo y Activo-Pasivo, detalla los requisitos de replicación de bases de datos y explica cómo Cloud RADIUS mitiga la latencia de failover para recintos empresariales.
🎧 Escucha esta guía
Ver transcripción

Resumen ejecutivo
Para las redes empresariales, la autenticación es binaria: funciona a la perfección o las operaciones comerciales se detienen por completo. RADIUS (Remote Authentication Dial-In User Service) actúa como el guardián crítico para implementaciones de IEEE 802.1X, WPA3 enterprise y Guest WiFi en recintos modernos. A diferencia de los servicios de aplicaciones que se degradan gradualmente bajo carga, una falla de RADIUS bloquea inmediatamente el acceso a la red de usuarios, terminales de punto de venta y dispositivos operativos.
Esta guía de referencia técnica evalúa los modelos arquitectónicos para implementar infraestructura RADIUS de alta disponibilidad. Específicamente, contrasta las configuraciones tradicionales Activo-Pasivo con los clusters modernos Activo-Activo. Para los gerentes de TI, arquitectos de red y directores de operaciones de recintos que gestionan entornos de alta densidad como Retail , Hospitality y estadios, comprender estas estrategias de failover, la mecánica de balanceo de carga y los requisitos de replicación de bases de datos es esencial.
Además, esta guía examina cómo las plataformas de Cloud RADIUS abstraen la complejidad de la alta disponibilidad, proporcionando failover automático y escalabilidad elástica sin la carga operativa de mantener una infraestructura redundante on-premise. Al aplicar estas mejores prácticas neutrales respecto al proveedor, los equipos de ingeniería pueden diseñar arquitecturas de autenticación que eliminen los puntos únicos de falla y cumplan con los estrictos Acuerdos de Nivel de Servicio (SLAs) de tiempo de actividad.
Inmersión técnica: Comprendiendo la arquitectura RADIUS
RADIUS opera como un protocolo cliente-servidor sobre UDP, utilizando típicamente el puerto 1812 para la autenticación y el puerto 1813 para el accounting, según lo definido en RFC 2865 y RFC 2866. La naturaleza sin estado (stateless) de las solicitudes de autenticación UDP es una ventaja estructural para el diseño de alta disponibilidad. Debido a que cada paquete Access-Request contiene todas las credenciales y parámetros necesarios, cualquier servidor RADIUS dentro de un cluster puede procesar cualquier solicitud de forma independiente, sin requerir una sincronización de estado compleja para la fase de autenticación en sí.
Arquitectura Activo-Pasivo
En una implementación Activo-Pasivo (o primario-standby), un único servidor RADIUS procesa todo el tráfico entrante de autenticación y accounting. Un servidor secundario permanece en línea pero inactivo, recibiendo actualizaciones de replicación de la base de datos pero sin responder activamente a los Dispositivos de Acceso a la Red (NADs), como puntos de acceso, switches o gateways VPN.
Cuando el servidor primario falla, el NAD detecta el tiempo de espera agotado y redirige las solicitudes posteriores al servidor secundario. El tiempo de detección de failover depende totalmente de los temporizadores de configuración del NAD. Un NAD típico envía una solicitud RADIUS y espera un tiempo de espera de paquete predeterminado (a menudo dos segundos). Si no recibe respuesta, reintenta. Con una configuración estándar de tres intentos por servidor, el NAD puede esperar hasta seis segundos antes de declarar muerto al servidor primario y realizar el failover al secundario. En entornos con tres servidores configurados, esta ventana de failover puede extenderse a dieciocho segundos. Para un recinto de Hospitality concurrido o un entorno de Retail que procesa transacciones, este retraso representa una interrupción notable del servicio.
Arquitectura Activo-Activo
Por el contrario, una arquitectura Activo-Activo distribuye la carga de autenticación entre múltiples servidores RADIUS operativos simultáneamente. El tráfico se enruta al cluster ya sea mediante una configuración round-robin en los NADs o a través de un balanceador de carga dedicado.
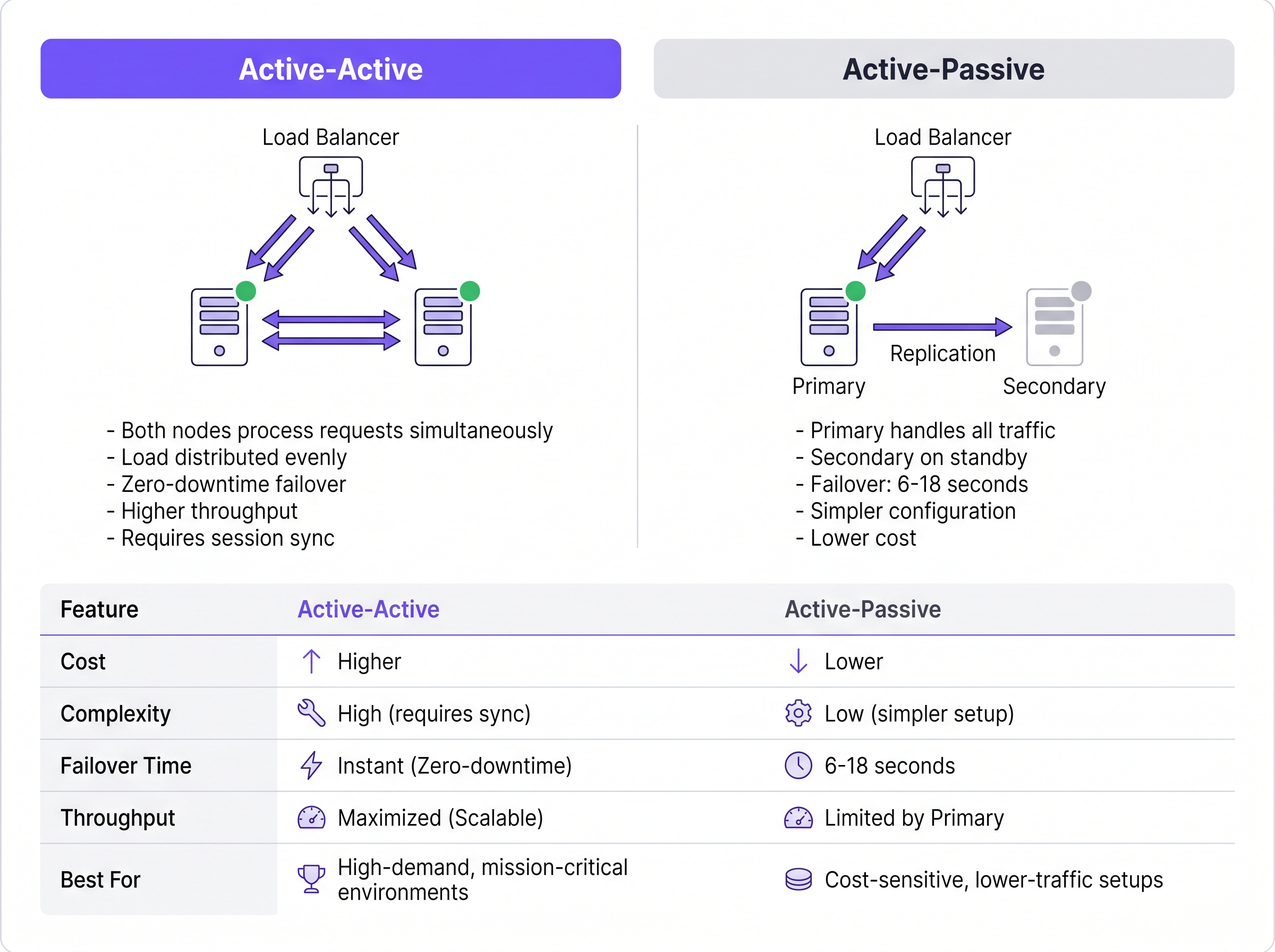
Este modelo elimina el retraso en la detección de failover inherente a las configuraciones Activo-Pasivo. Si un nodo falla, el balanceador de carga (o los NADs que usan round-robin) simplemente deja de enrutar tráfico al servidor que no responde, generalmente en uno o dos segundos según los intervalos de health-check. Los nodos activos restantes absorben el tráfico instantáneamente. Además, los clusters Activo-Activo se escalan horizontalmente; agregar capacidad para eventos de alta densidad simplemente requiere aprovisionar nodos adicionales al cluster.
El desafío de la replicación de bases de datos
Si bien la autenticación RADIUS es stateless, el accounting de RADIUS es inherentemente stateful. Rastrea el inicio de la sesión (Start), el uso continuo (Interim-Update) y la terminación (Stop). Para los recintos que utilizan WiFi Analytics o sistemas de facturación, estos datos de accounting deben permanecer consistentes en todos los nodos.
Respaldar un cluster RADIUS con una base de datos replicada (como MySQL o MariaDB integrada con FreeRADIUS) es obligatorio para una alta disponibilidad robusta. Para implementaciones Activo-Activo, se requiere una replicación multi-maestro síncrona, como Galera Cluster o MySQL NDB Cluster. La replicación síncrona garantiza que un registro de accounting se confirme en todos los nodos simultáneamente, evitando la pérdida de datos si un nodo falla. La replicación asíncrona tradicional, utilizada a menudo en configuraciones Activo-Pasivo, introduce un retraso de replicación. Si el nodo primario falla antes de que el secundario reciba la actualización, los datos de la sesión activa se pierden permanentemente, lo que puede violar marcos de cumplimiento como PCI DSS.
Guía de implementación: Cloud vs. On-Premise
La decisión arquitectónica va más allá de cómo agrupar los servidores; implica dónde residen esos servidores. Para los operadores de múltiples sitios, el backhauling del tráfico de autenticación a un centro de datos on-premise centralizado introduce latencia de WAN y crea un punto único de falla en el enlace WAN.
Cloud RADIUS PlLos servicios de Cloud RADIUS resuelven los desafíos de distribución geográfica al alojar la infraestructura de autenticación en múltiples zonas de disponibilidad global. Cuando un usuario se conecta en una sucursal, la solicitud se dirige al nodo de borde de nube más cercano, minimizando la latencia.
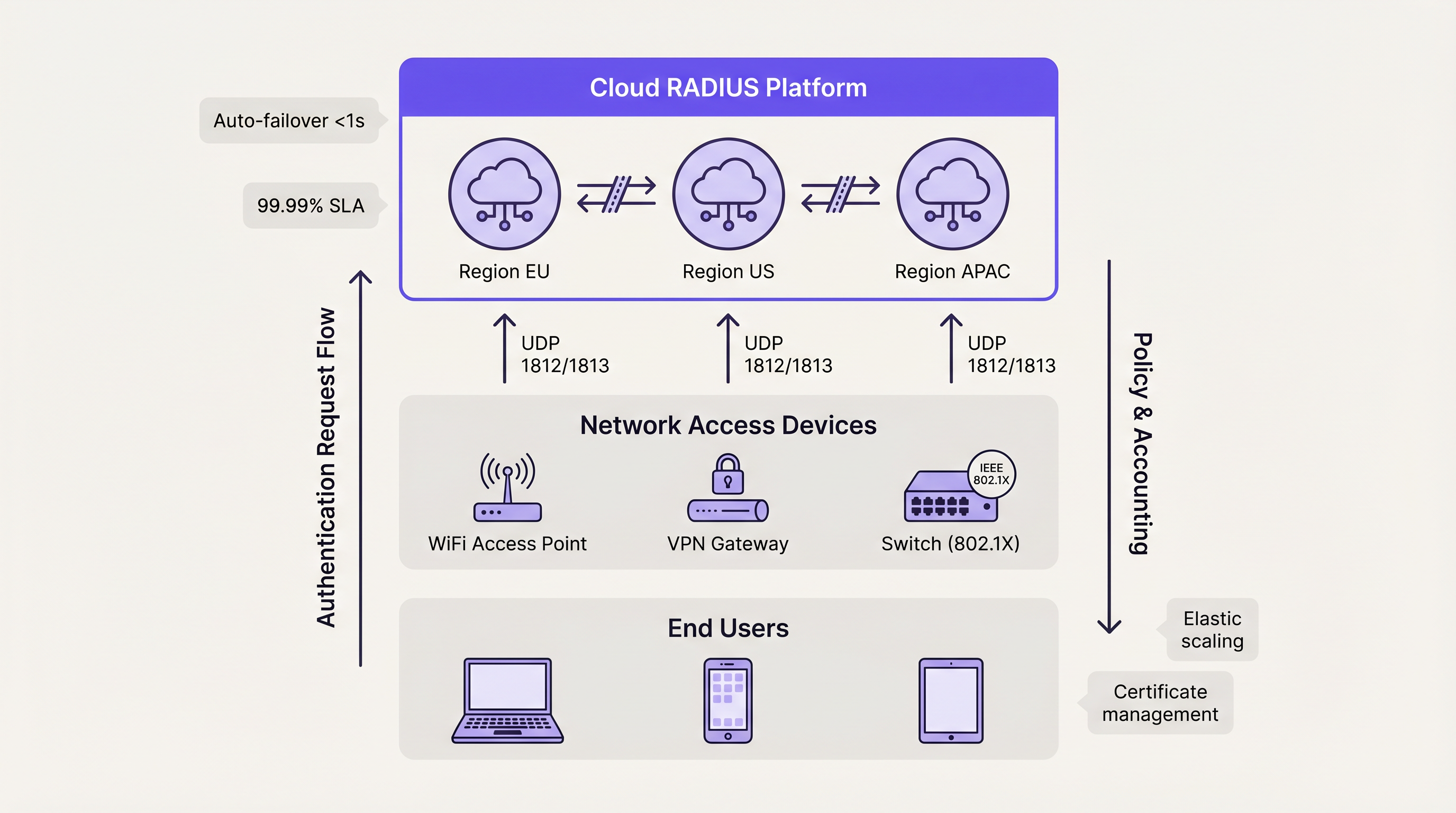
Las plataformas de nube utilizan intrínsecamente arquitecturas Activo-Activo. El failover entre zonas de disponibilidad se gestiona automáticamente mediante el equilibrado de carga interno del proveedor, abstrayendo por completo la complejidad para el equipo de ingeniería del cliente. Este modelo suele ofrecer SLAs de tiempo de actividad del 99.99% y elimina la necesidad de la gestión manual de certificados, el parcheo del sistema operativo y el ajuste de la replicación de la base de datos. Para las organizaciones que implementan Wayfinding o Sensors en campus distribuidos, la autenticación alojada en la nube garantiza una aplicación de políticas coherente sin dependencias de hardware localizadas.
Consideraciones de implementación On-Premise
Las organizaciones que operan en sectores altamente regulados —como entornos específicos de Salud o gubernamentales— pueden requerir implementaciones on-premise debido a los estrictos mandatos de soberanía de datos. En estos escenarios, implementar un clúster FreeRADIUS Activo-Activo con replicación síncrona de Galera proporciona el nivel más alto de resiliencia.
Sin embargo, los equipos de ingeniería deben tener en cuenta la carga operativa. La gestión de certificados TLS en múltiples nodos, la garantía de la consistencia de la configuración y el monitoreo activo del estado de la replicación de la base de datos requieren recursos administrativos dedicados. Los equilibradores de carga de hardware deben configurarse específicamente para admitir tráfico UDP con los health checks de RADIUS adecuados, ya que muchos equilibradores de carga estándar están optimizados únicamente para tráfico TCP HTTP/HTTPS.
Mejores prácticas para la alta disponibilidad de RADIUS
- Distribuir en lugar de duplicar: Para implementaciones que superen los 500 usuarios concurrentes, priorice las arquitecturas Activo-Activo sobre las configuraciones Activo-Pasivo para maximizar el rendimiento y minimizar la latencia de failover.
- Implementar replicación síncrona: Proteja los datos de contabilidad con estado utilizando la replicación de base de datos multimaestro síncrona (por ejemplo, Galera Cluster) en lugar de modelos asíncronos de réplica primaria.
- Estandarizar la confianza de los certificados: En un clúster Activo-Activo, asegúrese de que todos los nodos presenten el certificado de servidor idéntico o certificados de la misma cadena de Autoridad de Certificación (CA). Las discrepancias causarán que los handshakes EAP-TLS y PEAP fallen durante la rotación de nodos.
- Ajustar los temporizadores NAD: Optimice los temporizadores de reintento y tiempo de espera de RADIUS en sus Dispositivos de Acceso a la Red (NAD). Un tiempo de espera de dos segundos con dos reintentos proporciona un equilibrio entre la detección rápida de failover y la prevención de failover prematuro durante una congestión de red menor.
- Probar escenarios de falla: Trate los nodos secundarios como sistemas de producción. Simule regularmente fallas de nodos, desincronización de bases de datos y caídas de enlaces WAN para validar que los mecanismos de failover automatizados funcionen según lo diseñado.
Resolución de problemas y mitigación de riesgos
El modo de falla más frecuente en la alta disponibilidad de RADIUS es la deriva de configuración (configuration drift). En las configuraciones Activo-Pasivo, los administradores actualizan con frecuencia las políticas o renuevan los certificados en el nodo primario, pero descuidan el secundario. Cuando ocurre un evento de failover, el nodo secundario rechaza el tráfico legítimo debido a credenciales caducadas o políticas desactualizadas.
Para mitigar este riesgo, implemente herramientas de gestión de configuración (como Ansible o Terraform) para desplegar cambios de forma simétrica en todos los nodos. Para la gestión de certificados, utilice protocolos de renovación automatizados (como ACME) configurados para distribuir el certificado actualizado en todo el clúster simultáneamente.
Otro riesgo significativo es la configuración incorrecta del equilibrador de carga. Si un equilibrador de carga no realiza health checks de capa de aplicación (específicamente verificando la respuesta del puerto UDP 1812), puede continuar dirigiendo el tráfico a un nodo donde el sistema operativo está funcionando pero el demonio RADIUS se ha bloqueado. Asegúrese de que los health checks validen explícitamente la disponibilidad del servicio RADIUS.
ROI e impacto empresarial
El retorno de la inversión para una alta disponibilidad de RADIUS robusta se mide principalmente a través de la mitigación de riesgos y la eficiencia operativa. Las interrupciones de autenticación resultan en pérdidas inmediatas de productividad para los empleados y graves daños a la reputación de los lugares abiertos al público.
Al pasar de implementaciones manuales de un solo servidor a arquitecturas automatizadas Activo-Activo (particularmente a través de Cloud RADIUS), las organizaciones recuperan horas de ingeniería significativas dedicadas anteriormente al mantenimiento de rutina. Esta eficiencia operativa permite a los equipos de red centrarse en iniciativas estratégicas, como la implementación de Los beneficios principales de SD WAN para las empresas modernas o la optimización de la cobertura de alta densidad, en lugar de apagar incendios por fallas de autenticación. En última instancia, la autenticación confiable es la capa fundamental de la que dependen todos los servicios de red posteriores.
Términos clave y definiciones
Active-Active Architecture
A high availability design where multiple RADIUS servers process authentication requests simultaneously, distributing the load and providing instant failover without detection delays.
Essential for high-density venues (stadiums, large retail) where a single server cannot handle peak authentication surges.
Active-Passive Architecture
A redundancy model where a primary server handles all traffic, and a secondary server remains idle on standby until the primary fails.
Suitable for smaller, cost-sensitive deployments, but introduces a 6-18 second failover delay while the network access device detects the failure.
Synchronous Replication
A database replication method where data is written to all nodes in a cluster simultaneously before the transaction is considered complete.
Mandatory for Active-Active RADIUS accounting databases (like Galera Cluster) to prevent data loss and ensure compliance.
Asynchronous Replication
A database replication method where the primary node records the data and later copies it to secondary nodes, introducing a slight delay (lag).
Often used in Active-Passive setups but carries the risk of losing recent accounting records if the primary node fails abruptly.
Network Access Device (NAD)
The hardware component (such as a WiFi access point, switch, or VPN gateway) that requests authentication from the RADIUS server on behalf of the user.
The NAD's internal retry and timeout timers dictate how quickly an Active-Passive failover occurs.
Stateless Protocol
A communications protocol that treats each request as an independent transaction, unrelated to any previous request.
RADIUS authentication over UDP is stateless, allowing load balancers to route any request to any active server seamlessly.
Configuration Drift
The phenomenon where secondary or backup servers become out of sync with the primary server regarding policies, updates, or certificates over time.
The leading cause of failure in Active-Passive RADIUS deployments when the secondary node is forced to take over.
Cloud RADIUS
A managed authentication service hosted across globally distributed cloud infrastructure, providing built-in Active-Active redundancy and automatic scaling.
Replaces the need for IT teams to manually build, patch, and monitor redundant on-premise RADIUS servers.
Casos de éxito
A European hotel group manages 45 properties across six countries. They currently run independent FreeRADIUS virtual machines at each property. A recent expired TLS certificate at one location caused a complete guest WiFi outage during a major conference. How should they redesign their authentication architecture to prevent localized outages and reduce maintenance overhead?
The hotel group should migrate from localized, single-node FreeRADIUS instances to a centralized Cloud RADIUS platform utilizing an Active-Active architecture. By leveraging a cloud provider with geographically distributed edge nodes, authentication requests from each property are routed to the nearest regional node, minimizing latency. Centralized policy management allows the IT team to define authentication rules once and apply them globally. The cloud provider automatically handles TLS certificate rotation, operating system patching, and database replication.
A national sports stadium is preparing for a 60,000-attendee event. Their current RADIUS setup is an Active-Passive configuration. During load testing, the primary server became saturated processing 8,000 authentication requests per minute when the gates opened, causing severe connection delays, while the secondary server remained completely idle. How can they optimize this deployment?
The network engineering team must convert the deployment from Active-Passive to Active-Active. First, they should reconfigure the stadium's Network Access Devices (NADs) to utilize round-robin load balancing across both RADIUS servers, instantly doubling their authentication throughput. Second, they should provision a third RADIUS node to provide necessary headroom for peak surges. Finally, to ensure accounting data remains consistent across all three active nodes, they must implement a synchronous multi-master database replication solution, such as Galera Cluster.
Análisis de escenarios
Q1. Your enterprise retail client requires a highly available RADIUS solution for their point-of-sale terminals. They have strict PCI DSS compliance requirements dictating that absolutely no accounting session data can be lost during a server failover. Which database replication strategy must you implement for the RADIUS backend?
💡 Sugerencia:Consider the difference between data being written simultaneously versus data being copied after the fact.
Mostrar enfoque recomendado
You must implement Synchronous Replication (such as a Galera Cluster or MySQL NDB Cluster). Synchronous replication ensures that the accounting record is committed to all nodes simultaneously before acknowledging the transaction. If you used Asynchronous replication, a node failure could result in the loss of recent transactions that had not yet been copied to the secondary database, violating the strict compliance requirement.
Q2. A university campus network uses an Active-Passive RADIUS setup. Students complain that when the primary server undergoes maintenance, it takes nearly 20 seconds for their laptops to connect to the WiFi. The access points are configured with a 3-second RADIUS timeout and 5 retries. How can you reduce the failover delay without changing the server architecture?
💡 Sugerencia:Calculate the maximum wait time based on the NAD timers before it attempts the secondary server.
Mostrar enfoque recomendado
You should tune the timers on the Network Access Devices (access points). Currently, the AP waits 3 seconds and retries 5 times, resulting in an 18-second delay (3 seconds × 6 total attempts) before failing over to the passive server. By reducing the configuration to a 2-second timeout and 2 retries, the failover detection time drops to 6 seconds, significantly improving the user experience during maintenance windows.
Q3. You are migrating a multi-site corporate network from an Active-Passive on-premise RADIUS server to an Active-Active Cloud RADIUS platform. During the pilot phase, devices successfully authenticate against Cloud Node A, but when the load balancer routes them to Cloud Node B, the EAP-TLS handshakes fail. What is the most likely configuration error?
💡 Sugerencia:Consider what the client device verifies when establishing a secure EAP tunnel with a new server.
Mostrar enfoque recomendado
The most likely issue is a Certificate Trust mismatch. In an Active-Active cluster, all RADIUS nodes must present the exact same server certificate (or certificates issued by the exact same trusted CA chain). If Cloud Node B is presenting a different certificate that the client devices do not trust, the EAP-TLS handshake will be rejected by the client, causing authentication to fail despite the server functioning correctly.
Conclusiones clave
- ✓RADIUS high availability is critical because authentication failures immediately block all network access for users and devices.
- ✓Active-Passive setups are simpler but introduce a 6-18 second failover delay dictated by the Network Access Device's retry timers.
- ✓Active-Active architectures process requests simultaneously, providing instant failover and horizontal scalability for high-density environments.
- ✓While RADIUS authentication is stateless, accounting is stateful and requires synchronous database replication (like Galera) to prevent data loss.
- ✓Cloud RADIUS platforms abstract HA complexity by providing globally distributed, automatically scaling Active-Active infrastructure.
- ✓Configuration drift and mismatched TLS certificates are the most common causes of failure during RADIUS failover events.
