RADIUS-Server-Hochverfügbarkeit: Active-Active vs. Active-Passive
Ein definitiver technischer Leitfaden für IT-Manager und Netzwerkarchitekten zur Bewertung von RADIUS-Hochverfügbarkeitsarchitekturen. Er stellt Active-Active- und Active-Passive-Bereitstellungen gegenüber, detailliert die Anforderungen an die Datenbankreplikation und erklärt, wie Cloud RADIUS die Failover-Latenz für Unternehmensstandorte minimiert.
🎧 Diesen Leitfaden anhören
Transkript anzeigen

Management-Zusammenfassung
In Unternehmensnetzwerken ist die Authentifizierung binär: Entweder sie funktioniert einwandfrei, oder der Geschäftsbetrieb kommt vollständig zum Erliegen. RADIUS (Remote Authentication Dial-In User Service) fungiert als kritischer Gatekeeper für IEEE 802.1X, WPA3 Enterprise und Guest WiFi Bereitstellungen an modernen Standorten. Im Gegensatz zu Anwendungsdiensten, deren Leistung bei Last kontrolliert abnimmt, blockiert ein RADIUS-Ausfall sofort den Netzwerkzugriff für Benutzer, Point-of-Sale-Terminals und betriebliche Geräte.
Dieser technische Leitfaden bewertet die Architekturmodelle für die Bereitstellung hochverfügbarer RADIUS-Infrastrukturen. Insbesondere werden traditionelle Active-Passive-Konfigurationen modernen Active-Active-Clustern gegenübergestellt. Für IT-Manager, Netzwerkarchitekten und Betriebsleiter an Standorten mit hoher Dichte wie Retail , Hospitality und Stadien ist das Verständnis dieser Failover-Strategien, Load-Balancing-Mechanismen und Anforderungen an die Datenbankreplikation unerlässlich.
Darüber hinaus untersucht dieser Leitfaden, wie Cloud RADIUS-Plattformen die Komplexität der Hochverfügbarkeit abstrahieren und automatisches Failover sowie elastische Skalierbarkeit bieten, ohne den betrieblichen Aufwand für die Wartung redundanter On-Premise-Infrastrukturen. Durch die Anwendung dieser herstellerneutralen Best Practices können Engineering-Teams Authentifizierungsarchitekturen entwerfen, die Single Points of Failure eliminieren und strenge Service Level Agreements (SLAs) für die Betriebszeit erfüllen.
Technischer Deep-Dive: RADIUS-Architektur verstehen
RADIUS arbeitet als Client-Server-Protokoll über UDP und nutzt in der Regel Port 1812 für die Authentifizierung und Port 1813 für das Accounting, wie in RFC 2865 und RFC 2866 definiert. Die zustandslose Natur von UDP-Authentifizierungsanfragen ist ein struktureller Vorteil für das Hochverfügbarkeitsdesign. Da jedes Access-Request-Paket alle erforderlichen Anmeldedaten und Parameter enthält, kann jeder RADIUS-Server innerhalb eines Clusters jede Anfrage unabhängig verarbeiten, ohne dass eine komplexe Statussynchronisierung für die Authentifizierungsphase selbst erforderlich ist.
Active-Passive-Architektur
In einer Active-Passive-Bereitstellung (oder Primary-Standby) verarbeitet ein einzelner RADIUS-Server den gesamten eingehenden Authentifizierungs- und Accounting-Traffic. Ein sekundärer Server bleibt online, aber im Leerlauf; er erhält Datenbankreplikations-Updates, antwortet jedoch nicht aktiv auf Network Access Devices (NADs) wie Access Points, Switches oder VPN-Gateways.
Wenn der primäre Server ausfällt, erkennt das NAD den Timeout und leitet nachfolgende Anfragen an den sekundären Server um. Die Zeit für die Failover-Erkennung hängt vollständig von den Konfigurationstimern des NAD ab. Ein typisches NAD sendet eine RADIUS-Anfrage und wartet auf einen Standard-Paket-Timeout (oft zwei Sekunden). Wenn keine Antwort erfolgt, wird der Versuch wiederholt. Bei einer Standardkonfiguration von drei Versuchen pro Server kann das NAD bis zu sechs Sekunden warten, bevor es den primären Server für ausgefallen erklärt und auf den sekundären umschaltet. In Umgebungen mit drei konfigurierten Servern kann sich dieses Failover-Fenster auf achtzehn Sekunden verlängern. Für einen belebten Hospitality -Standort oder eine Retail -Umgebung, in der Transaktionen verarbeitet werden, stellt diese Verzögerung eine spürbare Dienstunterbrechung dar.
Active-Active-Architektur
Im Gegensatz dazu verteilt eine Active-Active-Architektur die Authentifizierungslast gleichzeitig auf mehrere betriebsbereite RADIUS-Server. Der Traffic wird entweder über Round-Robin-Konfigurationen auf den NADs oder über einen dedizierten Load Balancer an den Cluster geleitet.
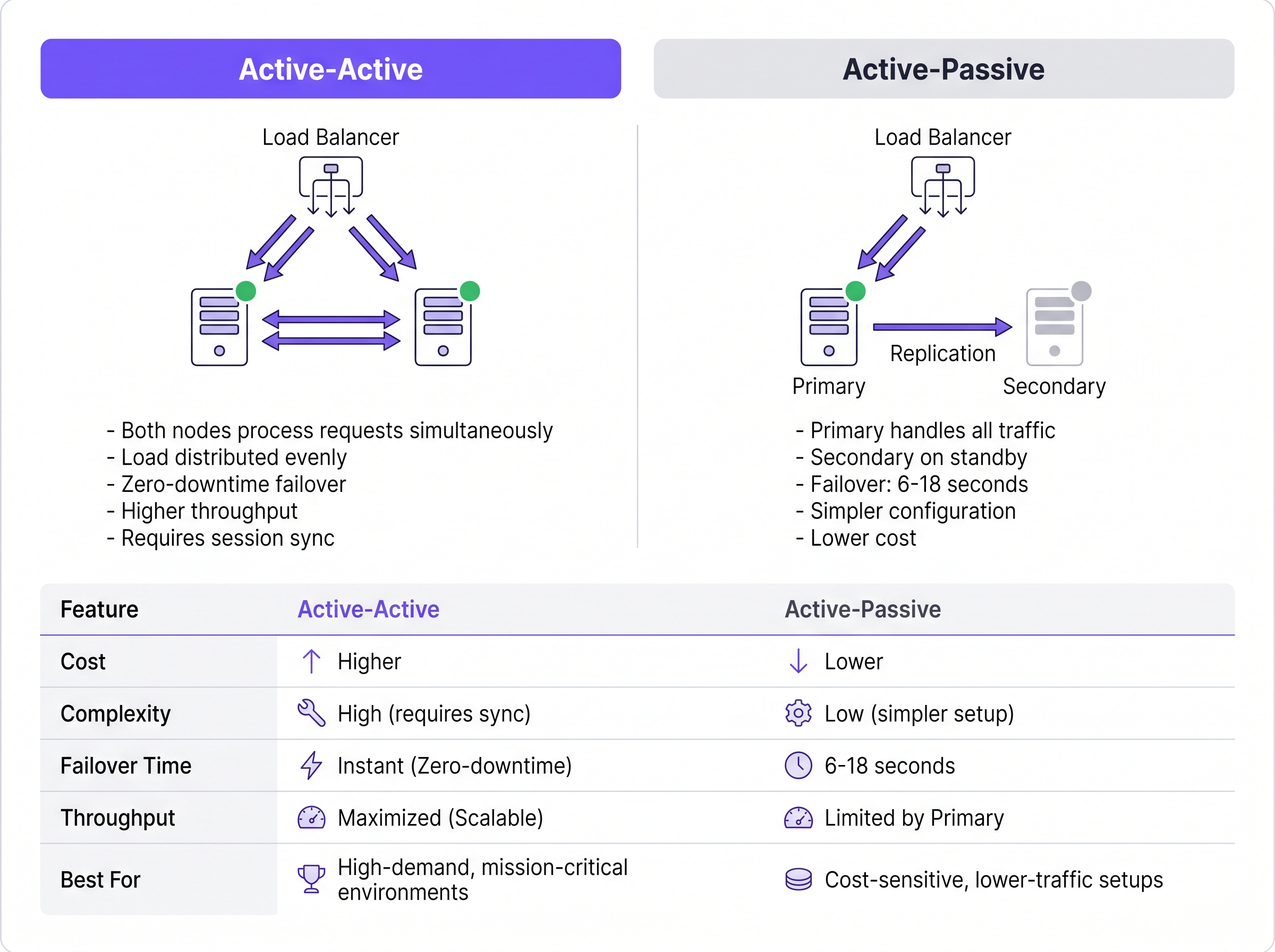
Dieses Modell eliminiert die Verzögerung bei der Failover-Erkennung, die Active-Passive-Setups eigen ist. Wenn ein Knoten ausfällt, stellt der Load Balancer (oder die NADs mittels Round-Robin) die Weiterleitung des Traffics an den nicht reagierenden Server einfach ein, in der Regel innerhalb von ein bis zwei Sekunden basierend auf Health-Check-Intervallen. Die verbleibenden aktiven Knoten übernehmen sofort den Traffic. Darüber hinaus lassen sich Active-Active-Cluster horizontal skalieren; um Kapazität für Veranstaltungen mit hoher Dichte hinzuzufügen, müssen lediglich zusätzliche Knoten im Cluster bereitgestellt werden.
Die Herausforderung der Datenbankreplikation
Während die RADIUS-Authentifizierung zustandslos ist, ist das RADIUS-Accounting von Natur aus zustandsbehaftet. Es verfolgt den Sitzungsbeginn (Start), die laufende Nutzung (Interim-Update) und die Beendigung (Stop). Für Standorte, die WiFi Analytics oder Abrechnungssysteme nutzen, müssen diese Accounting-Daten über alle Knoten hinweg konsistent bleiben.
Die Unterstützung eines RADIUS-Clusters durch eine replizierte Datenbank (wie MySQL oder MariaDB integriert mit FreeRADIUS) ist für eine robuste Hochverfügbarkeit zwingend erforderlich. Für Active-Active-Bereitstellungen ist eine synchrone Multi-Master-Replikation – wie Galera Cluster oder MySQL NDB Cluster – erforderlich. Die synchrone Replikation stellt sicher, dass ein Accounting-Datensatz gleichzeitig auf allen Knoten festgeschrieben wird, was Datenverlust bei einem Knotenausfall verhindert. Die traditionelle asynchrone Replikation, die häufig in Active-Passive-Setups verwendet wird, führt zu Replikationsverzögerungen. Wenn der primäre Knoten ausfällt, bevor der sekundäre das Update erhält, gehen aktive Sitzungsdaten dauerhaft verloren, was gegen Compliance-Frameworks wie PCI DSS verstoßen kann.
Implementierungsleitfaden: Cloud vs. On-Premise
Die architektonische Entscheidung geht darüber hinaus, wie Server geclustert werden; sie betrifft auch den Standort dieser Server. Für Betreiber mehrerer Standorte führt das Backhauling des Authentifizierungs-Traffics zu einem zentralisierten On-Premise-Rechenzentrum zu WAN-Latenzen und schafft einen Single Point of Failure an der WAN-Verbindung.
Cloud RADIUS Plattformen
Cloud RADIUS-Dienste lösen Herausforderungen bei der geografischen Verteilung, indem sie die Authentifizierungsinfrastruktur über mehrere globale Verfügbarkeitszonen hinweg hosten. Wenn sich ein Benutzer an einem Zweigstellenstandort verbindet, wird die Anfrage zum nächstgelegenen Cloud-Edge-Knoten geleitet, was die Latenz minimiert.
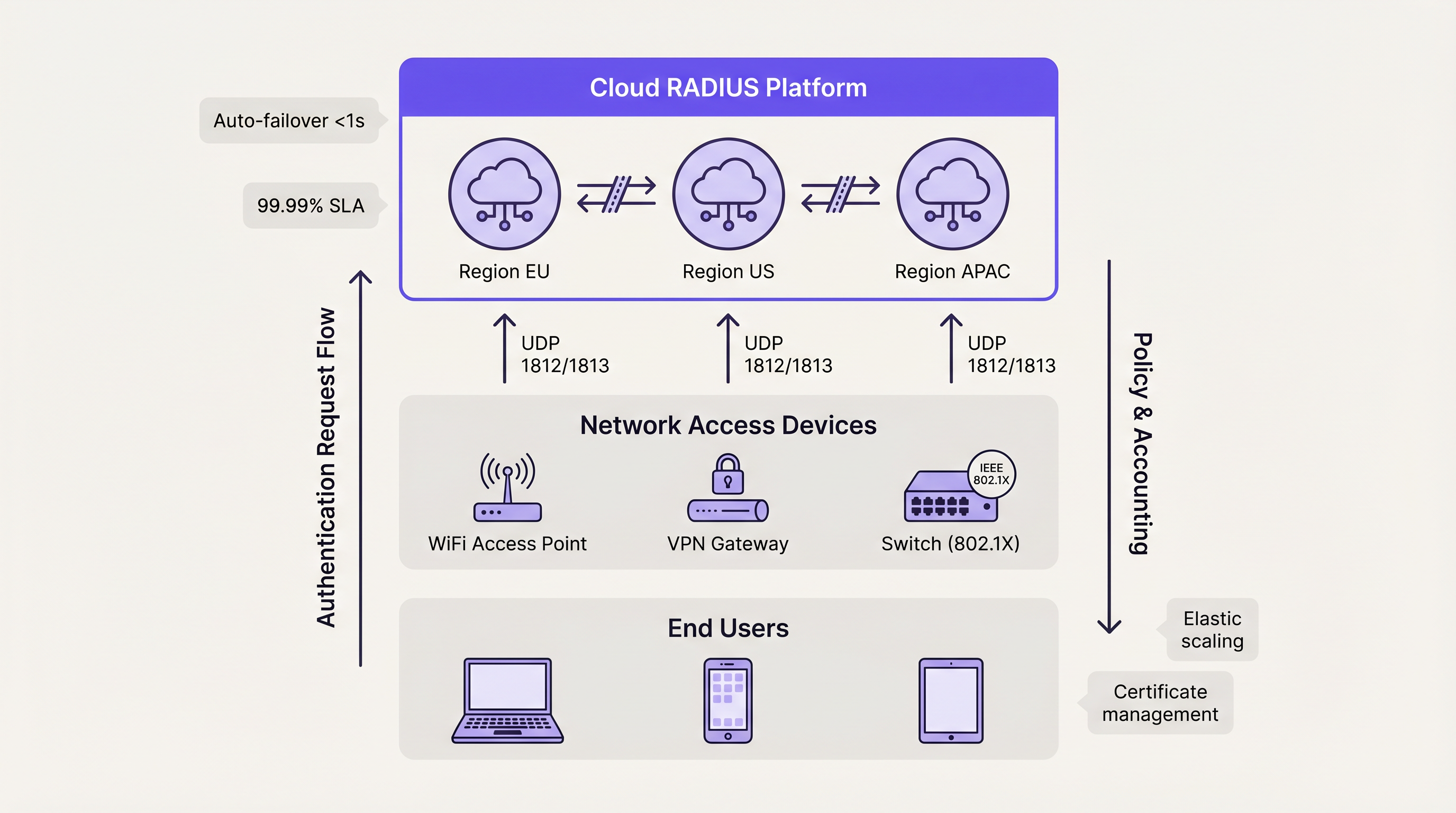
Cloud-Plattformen nutzen von Natur aus Aktiv-Aktiv-Architekturen. Das Failover zwischen Verfügbarkeitszonen wird automatisch durch das interne Load Balancing des Anbieters abgewickelt, wodurch die Komplexität vollständig vom Engineering-Team des Kunden abstrahiert wird. Dieses Modell bietet in der Regel SLAs mit 99,99 % Uptime und macht manuelle Zertifikatsverwaltung, Betriebssystem-Patching und die Abstimmung der Datenbankreplikation überflüssig. Für Unternehmen, die Wayfinding oder Sensors über verteilte Campus-Standorte hinweg einsetzen, gewährleistet die Cloud-gehostete Authentifizierung eine konsistente Richtliniendurchsetzung ohne Abhängigkeiten von lokaler Hardware.
Überlegungen zur On-Premise-Bereitstellung
Unternehmen in stark regulierten Sektoren – wie etwa im Gesundheitswesen oder in Regierungsumgebungen – benötigen aufgrund strenger Mandate zur Datensouveränität möglicherweise On-Premise-Bereitstellungen. In diesen Szenarien bietet die Bereitstellung eines Aktiv-Aktiv-FreeRADIUS-Clusters mit synchroner Galera-Replikation das höchste Maß an Resilienz.
Engineering-Teams müssen jedoch den betrieblichen Aufwand berücksichtigen. Die Verwaltung von TLS-Zertifikaten über mehrere Knoten hinweg, die Gewährleistung der Konfigurationskonsistenz und die aktive Überwachung des Zustands der Datenbankreplikation erfordern dedizierte administrative Ressourcen. Hardware-Load-Balancer müssen speziell für die Unterstützung von UDP-Traffic mit entsprechenden RADIUS-Health-Checks konfiguriert werden, da viele Standard-Load-Balancer ausschließlich für TCP-HTTP/HTTPS-Traffic optimiert sind.
Best Practices für RADIUS-Hochverfügbarkeit
- Verteilen statt Duplizieren: Priorisieren Sie bei Bereitstellungen mit mehr als 500 gleichzeitigen Benutzern Aktiv-Aktiv-Architekturen gegenüber Aktiv-Passiv-Setups, um den Durchsatz zu maximieren und die Failover-Latenz zu minimieren.
- Synchrone Replikation implementieren: Schützen Sie zustandsbehaftete Accounting-Daten durch die Nutzung synchroner Multi-Master-Datenbankreplikation (z. B. Galera Cluster) anstelle von asynchronen Primär-Replika-Modellen.
- Zertifikatsvertrauen standardisieren: Stellen Sie in einem Aktiv-Aktiv-Cluster sicher, dass alle Knoten das identische Serverzertifikat oder Zertifikate aus exakt derselben Certificate Authority (CA)-Kette vorweisen. Diskrepanzen führen dazu, dass EAP-TLS- und PEAP-Handshakes während der Knotenrotation fehlschlagen.
- NAD-Timer abstimmen: Optimieren Sie die RADIUS-Retry- und Timeout-Timer auf Ihren Network Access Devices. Ein Timeout von zwei Sekunden mit zwei Wiederholungsversuchen bietet ein Gleichgewicht zwischen schneller Failover-Erkennung und der Vermeidung vorzeitiger Failover bei geringfügigen Netzwerküberlastungen.
- Ausfallszenarien testen: Behandeln Sie sekundäre Knoten wie Produktionssysteme. Simulieren Sie regelmäßig Knotenausfälle, Datenbank-Desynchronisationen und WAN-Verbindungsabbrüche, um zu validieren, dass automatisierte Failover-Mechanismen wie geplant funktionieren.
Fehlerbehebung & Risikominderung
Der häufigste Fehlermodus bei der RADIUS-Hochverfügbarkeit ist der Konfigurationsdrift. In Aktiv-Passiv-Setups aktualisieren Administratoren häufig Richtlinien oder erneuern Zertifikate auf dem primären Knoten, vernachlässigen jedoch den sekundären. Tritt ein Failover-Ereignis ein, lehnt der sekundäre Knoten legitimen Traffic aufgrund abgelaufener Anmeldedaten oder veralteter Richtlinien ab.
Um dieses Risiko zu mindern, implementieren Sie Konfigurationsmanagement-Tools (wie Ansible oder Terraform), um Änderungen symmetrisch über alle Knoten hinweg bereitzustellen. Nutzen Sie für die Zertifikatsverwaltung automatisierte Erneuerungsprotokolle (wie ACME), die so konfiguriert sind, dass sie das aktualisierte Zertifikat gleichzeitig im gesamten Cluster verteilen.
Ein weiteres erhebliches Risiko ist die Fehlkonfiguration des Load Balancers. Wenn ein Load Balancer keine Health-Checks auf Anwendungsebene durchführt (insbesondere die Überprüfung der Reaktionsfähigkeit von UDP-Port 1812), leitet er möglicherweise weiterhin Traffic an einen Knoten weiter, auf dem das Betriebssystem läuft, der RADIUS-Daemon jedoch abgestürzt ist. Stellen Sie sicher, dass Health-Checks explizit die Verfügbarkeit des RADIUS-Dienstes validieren.
ROI & geschäftliche Auswirkungen
Der Return on Investment für eine robuste RADIUS-Hochverfügbarkeit bemisst sich primär an der Risikominderung und der betrieblichen Effizienz. Authentifizierungsausfälle führen zu sofortigen Produktivitätsverlusten für Mitarbeiter und schweren Reputationsschäden für öffentlich zugängliche Standorte.
Durch den Übergang von manuellen Einzelserver-Bereitstellungen zu automatisierten Aktiv-Aktiv-Architekturen (insbesondere über Cloud RADIUS) gewinnen Unternehmen erhebliche Engineering-Stunden zurück, die zuvor für routinemäßige Wartungsarbeiten aufgewendet wurden. Diese betriebliche Effizienz ermöglicht es Netzwerk-Teams, sich auf strategische Initiativen zu konzentrieren, wie die Bereitstellung von Die zentralen SD-WAN-Vorteile für moderne Unternehmen oder die Optimierung der High-Density-Abdeckung, anstatt Authentifizierungsfehler zu beheben. Letztendlich ist eine zuverlässige Authentifizierung die grundlegende Schicht, von der alle nachfolgenden Netzdienste abhängen.
Schlüsselbegriffe & Definitionen
Active-Active Architecture
A high availability design where multiple RADIUS servers process authentication requests simultaneously, distributing the load and providing instant failover without detection delays.
Essential for high-density venues (stadiums, large retail) where a single server cannot handle peak authentication surges.
Active-Passive Architecture
A redundancy model where a primary server handles all traffic, and a secondary server remains idle on standby until the primary fails.
Suitable for smaller, cost-sensitive deployments, but introduces a 6-18 second failover delay while the network access device detects the failure.
Synchronous Replication
A database replication method where data is written to all nodes in a cluster simultaneously before the transaction is considered complete.
Mandatory for Active-Active RADIUS accounting databases (like Galera Cluster) to prevent data loss and ensure compliance.
Asynchronous Replication
A database replication method where the primary node records the data and later copies it to secondary nodes, introducing a slight delay (lag).
Often used in Active-Passive setups but carries the risk of losing recent accounting records if the primary node fails abruptly.
Network Access Device (NAD)
The hardware component (such as a WiFi access point, switch, or VPN gateway) that requests authentication from the RADIUS server on behalf of the user.
The NAD's internal retry and timeout timers dictate how quickly an Active-Passive failover occurs.
Stateless Protocol
A communications protocol that treats each request as an independent transaction, unrelated to any previous request.
RADIUS authentication over UDP is stateless, allowing load balancers to route any request to any active server seamlessly.
Configuration Drift
The phenomenon where secondary or backup servers become out of sync with the primary server regarding policies, updates, or certificates over time.
The leading cause of failure in Active-Passive RADIUS deployments when the secondary node is forced to take over.
Cloud RADIUS
A managed authentication service hosted across globally distributed cloud infrastructure, providing built-in Active-Active redundancy and automatic scaling.
Replaces the need for IT teams to manually build, patch, and monitor redundant on-premise RADIUS servers.
Fallstudien
A European hotel group manages 45 properties across six countries. They currently run independent FreeRADIUS virtual machines at each property. A recent expired TLS certificate at one location caused a complete guest WiFi outage during a major conference. How should they redesign their authentication architecture to prevent localized outages and reduce maintenance overhead?
The hotel group should migrate from localized, single-node FreeRADIUS instances to a centralized Cloud RADIUS platform utilizing an Active-Active architecture. By leveraging a cloud provider with geographically distributed edge nodes, authentication requests from each property are routed to the nearest regional node, minimizing latency. Centralized policy management allows the IT team to define authentication rules once and apply them globally. The cloud provider automatically handles TLS certificate rotation, operating system patching, and database replication.
A national sports stadium is preparing for a 60,000-attendee event. Their current RADIUS setup is an Active-Passive configuration. During load testing, the primary server became saturated processing 8,000 authentication requests per minute when the gates opened, causing severe connection delays, while the secondary server remained completely idle. How can they optimize this deployment?
The network engineering team must convert the deployment from Active-Passive to Active-Active. First, they should reconfigure the stadium's Network Access Devices (NADs) to utilize round-robin load balancing across both RADIUS servers, instantly doubling their authentication throughput. Second, they should provision a third RADIUS node to provide necessary headroom for peak surges. Finally, to ensure accounting data remains consistent across all three active nodes, they must implement a synchronous multi-master database replication solution, such as Galera Cluster.
Szenarioanalyse
Q1. Your enterprise retail client requires a highly available RADIUS solution for their point-of-sale terminals. They have strict PCI DSS compliance requirements dictating that absolutely no accounting session data can be lost during a server failover. Which database replication strategy must you implement for the RADIUS backend?
💡 Hinweis:Consider the difference between data being written simultaneously versus data being copied after the fact.
Empfohlenen Ansatz anzeigen
You must implement Synchronous Replication (such as a Galera Cluster or MySQL NDB Cluster). Synchronous replication ensures that the accounting record is committed to all nodes simultaneously before acknowledging the transaction. If you used Asynchronous replication, a node failure could result in the loss of recent transactions that had not yet been copied to the secondary database, violating the strict compliance requirement.
Q2. A university campus network uses an Active-Passive RADIUS setup. Students complain that when the primary server undergoes maintenance, it takes nearly 20 seconds for their laptops to connect to the WiFi. The access points are configured with a 3-second RADIUS timeout and 5 retries. How can you reduce the failover delay without changing the server architecture?
💡 Hinweis:Calculate the maximum wait time based on the NAD timers before it attempts the secondary server.
Empfohlenen Ansatz anzeigen
You should tune the timers on the Network Access Devices (access points). Currently, the AP waits 3 seconds and retries 5 times, resulting in an 18-second delay (3 seconds × 6 total attempts) before failing over to the passive server. By reducing the configuration to a 2-second timeout and 2 retries, the failover detection time drops to 6 seconds, significantly improving the user experience during maintenance windows.
Q3. You are migrating a multi-site corporate network from an Active-Passive on-premise RADIUS server to an Active-Active Cloud RADIUS platform. During the pilot phase, devices successfully authenticate against Cloud Node A, but when the load balancer routes them to Cloud Node B, the EAP-TLS handshakes fail. What is the most likely configuration error?
💡 Hinweis:Consider what the client device verifies when establishing a secure EAP tunnel with a new server.
Empfohlenen Ansatz anzeigen
The most likely issue is a Certificate Trust mismatch. In an Active-Active cluster, all RADIUS nodes must present the exact same server certificate (or certificates issued by the exact same trusted CA chain). If Cloud Node B is presenting a different certificate that the client devices do not trust, the EAP-TLS handshake will be rejected by the client, causing authentication to fail despite the server functioning correctly.
Wichtigste Erkenntnisse
- ✓RADIUS high availability is critical because authentication failures immediately block all network access for users and devices.
- ✓Active-Passive setups are simpler but introduce a 6-18 second failover delay dictated by the Network Access Device's retry timers.
- ✓Active-Active architectures process requests simultaneously, providing instant failover and horizontal scalability for high-density environments.
- ✓While RADIUS authentication is stateless, accounting is stateful and requires synchronous database replication (like Galera) to prevent data loss.
- ✓Cloud RADIUS platforms abstract HA complexity by providing globally distributed, automatically scaling Active-Active infrastructure.
- ✓Configuration drift and mismatched TLS certificates are the most common causes of failure during RADIUS failover events.
