Alta Disponibilidade de Servidor RADIUS: Ativo-Ativo vs Ativo-Passivo
Um guia de referência técnica definitivo para gestores de TI e arquitetos de rede que avaliam arquiteturas de alta disponibilidade RADIUS. Contrasta implementações Ativo-Ativo e Ativo-Passivo, detalha requisitos de replicação de base de dados e explica como o Cloud RADIUS mitiga a latência de failover para recintos empresariais.
🎧 Ouça este Guia
Ver Transcrição

Sumário Executivo
Para redes empresariais, a autenticação é binária: ou funciona na perfeição ou as operações comerciais cessam por completo. O RADIUS (Remote Authentication Dial-In User Service) serve como o guardião crítico para implementações IEEE 802.1X, WPA3 enterprise e Guest WiFi em recintos modernos. Ao contrário dos serviços de aplicação que se degradam de forma graciosa sob carga, uma falha no RADIUS bloqueia imediatamente o acesso à rede de utilizadores, terminais de ponto de venda e dispositivos operacionais.
Este guia de referência técnica avalia os modelos arquitetónicos para a implementação de infraestrutura RADIUS de alta disponibilidade. Especificamente, contrasta as configurações tradicionais Ativo-Passivo com os clusters modernos Ativo-Ativo. Para gestores de TI, arquitetos de rede e diretores de operações de recintos que gerem ambientes de alta densidade como Retalho , Hotelaria e estádios, a compreensão destas estratégias de failover, mecânicas de balanceamento de carga e requisitos de replicação de base de dados é essencial.
Além disso, este guia examina como as plataformas Cloud RADIUS abstraem a complexidade da alta disponibilidade, fornecendo failover automático e escalabilidade elástica sem o fardo operacional de manter infraestrutura on-premise redundante. Ao aplicar estas boas práticas independentes de fornecedor, as equipas de engenharia podem projetar arquiteturas de autenticação que eliminam pontos únicos de falha e cumprem os rigorosos Acordos de Nível de Serviço (SLAs) de tempo de atividade.
Análise Técnica Profunda: Compreender a Arquitetura RADIUS
O RADIUS opera como um protocolo cliente-servidor sobre UDP, utilizando tipicamente a porta 1812 para autenticação e a porta 1813 para accounting, conforme definido no RFC 2865 e RFC 2866. A natureza stateless (sem estado) dos pedidos de autenticação UDP é uma vantagem estrutural para o design de alta disponibilidade. Como cada pacote Access-Request contém todas as credenciais e parâmetros necessários, qualquer servidor RADIUS dentro de um cluster pode processar qualquer pedido de forma independente, sem exigir uma sincronização de estado complexa para a fase de autenticação em si.
Arquitetura Ativo-Passivo
Numa implementação Ativo-Passivo (ou primário-secundário), um único servidor RADIUS processa todo o tráfego de autenticação e accounting de entrada. Um servidor secundário permanece online mas inativo, recebendo atualizações de replicação de base de dados, mas não respondendo ativamente aos Dispositivos de Acesso à Rede (NADs), tais como pontos de acesso, switches ou gateways VPN.
Quando o servidor primário falha, o NAD deteta o tempo de espera (timeout) e redireciona os pedidos subsequentes para o servidor secundário. O tempo de deteção de failover depende inteiramente dos temporizadores de configuração do NAD. Um NAD típico envia um pedido RADIUS e aguarda por um timeout de pacote predefinido (frequentemente dois segundos). Se não for recebida resposta, tenta novamente. Com uma configuração padrão de três tentativas por servidor, o NAD pode aguardar até seis segundos antes de declarar o servidor primário como inativo e efetuar o failover para o secundário. Em ambientes com três servidores configurados, esta janela de failover pode estender-se até dezoito segundos. Para um recinto de Hotelaria movimentado ou um ambiente de Retalho que processe transações, este atraso representa uma interrupção percetível do serviço.
Arquitetura Ativo-Ativo
Inversamente, uma arquitetura Ativo-Ativo distribui a carga de autenticação por vários servidores RADIUS operacionais simultaneamente. O tráfego é encaminhado para o cluster através de configuração round-robin nos NADs ou via um balanceador de carga dedicado.
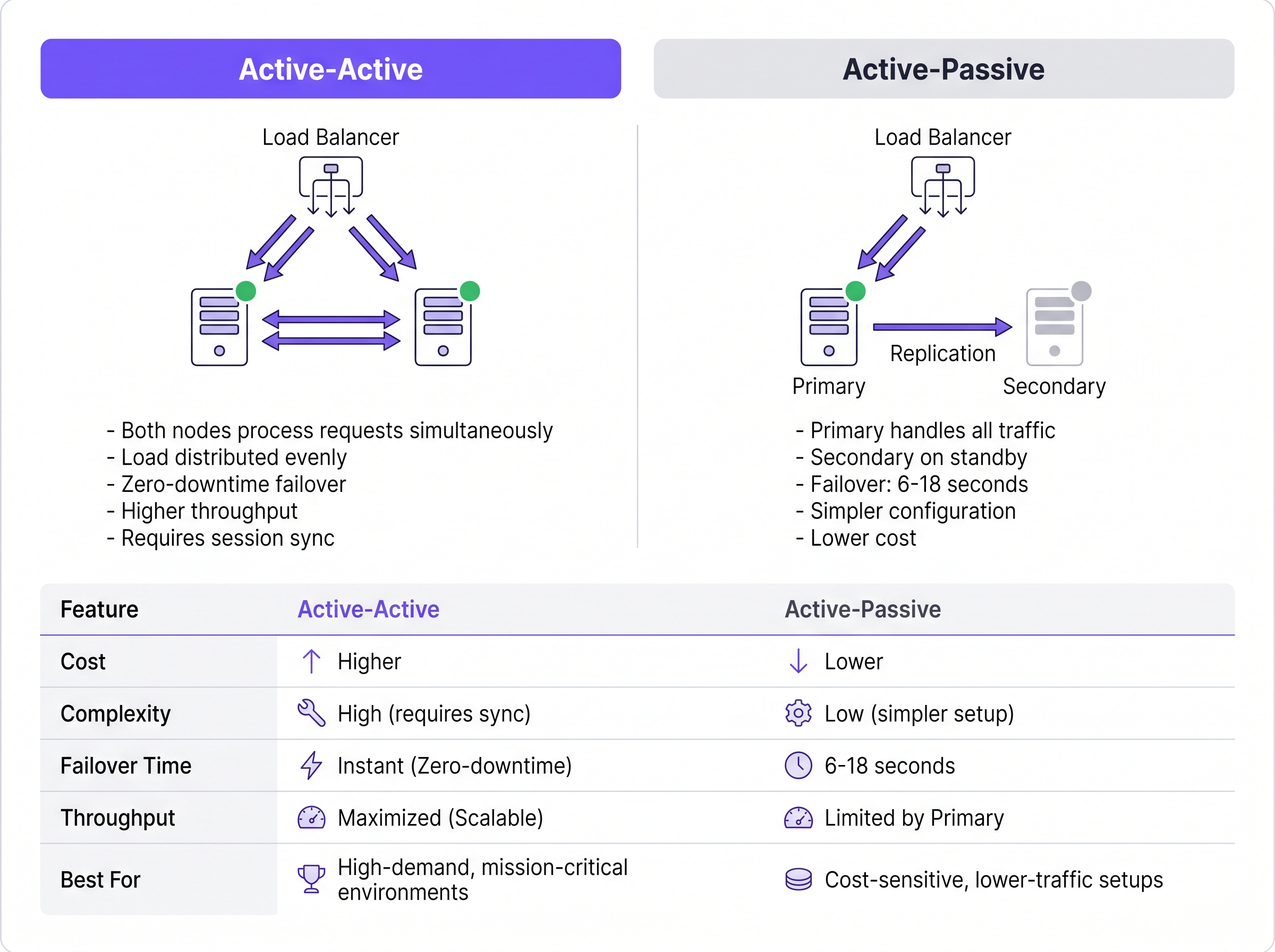
Este modelo elimina o atraso de deteção de failover inerente às configurações Ativo-Passivo. Se um nó falhar, o balanceador de carga (ou os NADs que utilizam round-robin) simplesmente deixa de encaminhar tráfego para o servidor que não responde, tipicamente dentro de um a dois segundos com base nos intervalos de verificação de estado (health-check). Os restantes nós ativos absorvem instantaneamente o tráfego. Além disso, os clusters Ativo-Ativo escalam horizontalmente; adicionar capacidade para eventos de alta densidade requer apenas o aprovisionamento de nós adicionais ao cluster.
O Desafio da Replicação de Base de Dados
Embora a autenticação RADIUS seja stateless, o accounting RADIUS é inerentemente stateful (com estado). Este monitoriza o início de sessão (Start), a utilização contínua (Interim-Update) e a terminação (Stop). Para recintos que utilizam WiFi Analytics ou sistemas de faturação, estes dados de accounting devem permanecer consistentes em todos os nós.
Suportar um cluster RADIUS com uma base de dados replicada (como MySQL ou MariaDB integrado com FreeRADIUS) é obrigatório para uma alta disponibilidade robusta. Para implementações Ativo-Ativo, é necessária uma replicação multi-master síncrona — como o Galera Cluster ou o MySQL NDB Cluster. A replicação síncrona garante que um registo de accounting é confirmado em todos os nós simultaneamente, prevenindo a perda de dados se um nó falhar. A replicação assíncrona tradicional, frequentemente utilizada em configurações Ativo-Passivo, introduz um atraso de replicação (lag). Se o nó primário falhar antes de o secundário receber a atualização, os dados da sessão ativa são perdidos permanentemente, o que pode violar estruturas de conformidade como o PCI DSS.
Guia de Implementação: Cloud vs On-Premise
A decisão arquitetónica vai além de como agrupar servidores em cluster; envolve o local onde esses servidores residem. Para operadores com vários locais (multi-site), o reencaminhamento (backhauling) do tráfego de autenticação para um centro de dados on-premise centralizado introduz latência de WAN e cria um ponto único de falha na ligação WAN.
Plataformas Cloud RADIUSOs serviços Cloud RADIUS resolvem desafios de distribuição geográfica ao alojar infraestruturas de autenticação em múltiplas zonas de disponibilidade globais. Quando um utilizador se liga numa sucursal, o pedido é encaminhado para o nó de extremidade (edge node) na cloud mais próximo, minimizando a latência.
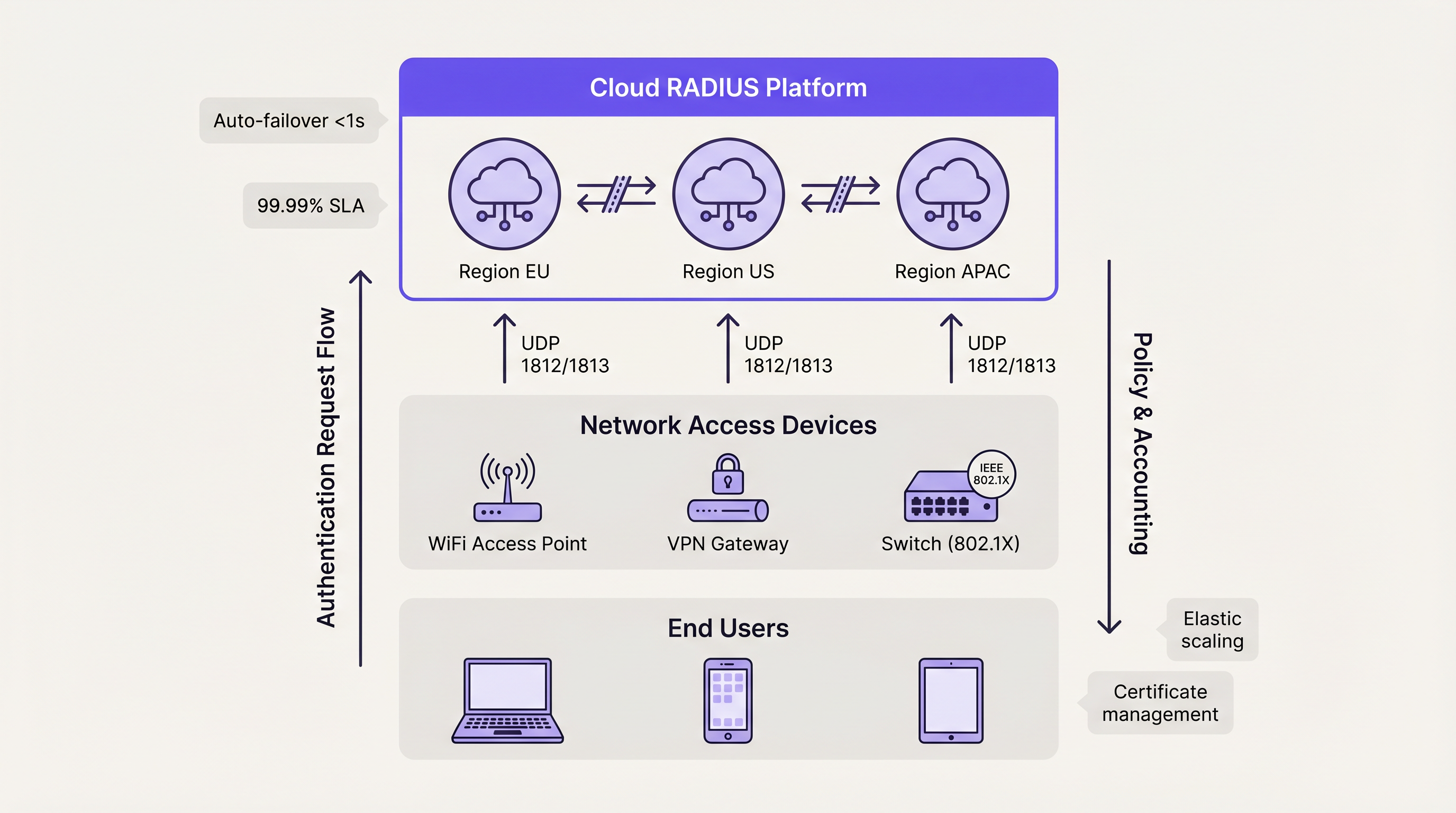
As plataformas cloud utilizam inerentemente arquiteturas Ativo-Ativo. O failover entre zonas de disponibilidade é gerido automaticamente pelo balanceamento de carga interno do fornecedor, abstraindo inteiramente a complexidade para a equipa de engenharia do cliente. Este modelo normalmente oferece SLAs de 99,99% de tempo de atividade e elimina a necessidade de gestão manual de certificados, correção (patching) do sistema operativo e ajuste da replicação da base de dados. Para organizações que implementam Wayfinding ou Sensores em campus distribuídos, a autenticação alojada na cloud garante a aplicação consistente de políticas sem dependências de hardware localizadas.
Considerações de Implementação On-Premise
Organizações que operam em setores altamente regulamentados — como ambientes específicos de Saúde ou governamentais — podem exigir implementações on-premise devido a mandatos rigorosos de soberania de dados. Nestes cenários, a implementação de um cluster FreeRADIUS Ativo-Ativo com replicação síncrona Galera proporciona o nível mais elevado de resiliência.
No entanto, as equipas de engenharia devem ter em conta a sobrecarga operacional. A gestão de certificados TLS em múltiplos nós, a garantia da consistência da configuração e a monitorização ativa do estado da replicação da base de dados requerem recursos administrativos dedicados. Os balanceadores de carga de hardware devem ser configurados especificamente para suportar tráfego UDP com verificações de estado (health checks) RADIUS apropriadas, uma vez que muitos balanceadores de carga padrão são otimizados apenas para tráfego TCP HTTP/HTTPS.
Melhores Práticas para Alta Disponibilidade RADIUS
- Distribuir em vez de Duplicar: Para implementações que excedam 500 utilizadores simultâneos, priorize arquiteturas Ativo-Ativo em vez de configurações Ativo-Passivo para maximizar o throughput e minimizar a latência de failover.
- Implementar Replicação Síncrona: Proteja os dados de accounting stateful utilizando replicação de base de dados multi-master síncrona (ex: Galera Cluster) em vez de modelos primário-réplica assíncronos.
- Padronizar a Confiança de Certificados: Num cluster Ativo-Ativo, garanta que todos os nós apresentam o certificado de servidor idêntico ou certificados da mesma cadeia de Autoridade de Certificação (CA). As discrepâncias farão com que os handshakes EAP-TLS e PEAP falhem durante a rotação de nós.
- Ajustar Temporizadores NAD: Otimize os temporizadores de repetição (retry) e timeout de RADIUS nos seus Dispositivos de Acesso à Rede (NAD). Um timeout de dois segundos com duas repetições proporciona um equilíbrio entre a deteção rápida de failover e a prevenção de failover prematuro durante pequenos congestionamentos de rede.
- Testar Cenários de Falha: Trate os nós secundários como sistemas de produção. Simule regularmente falhas de nós, dessincronização de bases de dados e quedas de links WAN para validar que os mecanismos de failover automatizados funcionam conforme projetado.
Resolução de Problemas e Mitigação de Riscos
O modo de falha mais prevalente na alta disponibilidade RADIUS é o desvio de configuração (configuration drift). Em configurações Ativo-Passivo, os administradores atualizam frequentemente as políticas ou renovam certificados no nó primário, mas negligenciam o secundário. Quando ocorre um evento de failover, o nó secundário rejeita tráfego legítimo devido a credenciais expiradas ou políticas desatualizadas.
Para mitigar este risco, implemente ferramentas de gestão de configuração (como Ansible ou Terraform) para implementar alterações simetricamente em todos os nós. Para a gestão de certificados, utilize protocolos de renovação automatizados (como ACME) configurados para distribuir o certificado atualizado por todo o cluster simultaneamente.
Outro risco significativo é a configuração incorreta do balanceador de carga. Se um balanceador de carga não realizar verificações de estado na camada de aplicação (especificamente verificando a capacidade de resposta da porta UDP 1812), pode continuar a encaminhar tráfego para um nó onde o sistema operativo está a funcionar, mas o daemon RADIUS falhou. Garanta que as verificações de estado validam explicitamente a disponibilidade do serviço RADIUS.
ROI e Impacto no Negócio
O retorno sobre o investimento para uma alta disponibilidade RADIUS robusta é medido principalmente através da mitigação de riscos e da eficiência operacional. As interrupções de autenticação resultam em perdas imediatas de produtividade para os funcionários e danos graves na reputação de locais abertos ao público.
Ao transitar de implementações manuais de servidor único para arquiteturas Ativo-Ativo automatizadas (particularmente via Cloud RADIUS), as organizações recuperam horas de engenharia significativas anteriormente dedicadas à manutenção de rotina. Esta eficiência operacional permite que as equipas de rede se foquem em iniciativas estratégicas, como a implementação de Os Principais Benefícios de SD WAN para Empresas Modernas ou a otimização da cobertura de alta densidade, em vez de combater falhas de autenticação. Em última análise, a autenticação fiável é a camada fundamental da qual dependem todos os serviços de rede subsequentes.
Termos-Chave e Definições
Active-Active Architecture
A high availability design where multiple RADIUS servers process authentication requests simultaneously, distributing the load and providing instant failover without detection delays.
Essential for high-density venues (stadiums, large retail) where a single server cannot handle peak authentication surges.
Active-Passive Architecture
A redundancy model where a primary server handles all traffic, and a secondary server remains idle on standby until the primary fails.
Suitable for smaller, cost-sensitive deployments, but introduces a 6-18 second failover delay while the network access device detects the failure.
Synchronous Replication
A database replication method where data is written to all nodes in a cluster simultaneously before the transaction is considered complete.
Mandatory for Active-Active RADIUS accounting databases (like Galera Cluster) to prevent data loss and ensure compliance.
Asynchronous Replication
A database replication method where the primary node records the data and later copies it to secondary nodes, introducing a slight delay (lag).
Often used in Active-Passive setups but carries the risk of losing recent accounting records if the primary node fails abruptly.
Network Access Device (NAD)
The hardware component (such as a WiFi access point, switch, or VPN gateway) that requests authentication from the RADIUS server on behalf of the user.
The NAD's internal retry and timeout timers dictate how quickly an Active-Passive failover occurs.
Stateless Protocol
A communications protocol that treats each request as an independent transaction, unrelated to any previous request.
RADIUS authentication over UDP is stateless, allowing load balancers to route any request to any active server seamlessly.
Configuration Drift
The phenomenon where secondary or backup servers become out of sync with the primary server regarding policies, updates, or certificates over time.
The leading cause of failure in Active-Passive RADIUS deployments when the secondary node is forced to take over.
Cloud RADIUS
A managed authentication service hosted across globally distributed cloud infrastructure, providing built-in Active-Active redundancy and automatic scaling.
Replaces the need for IT teams to manually build, patch, and monitor redundant on-premise RADIUS servers.
Estudos de Caso
A European hotel group manages 45 properties across six countries. They currently run independent FreeRADIUS virtual machines at each property. A recent expired TLS certificate at one location caused a complete guest WiFi outage during a major conference. How should they redesign their authentication architecture to prevent localized outages and reduce maintenance overhead?
The hotel group should migrate from localized, single-node FreeRADIUS instances to a centralized Cloud RADIUS platform utilizing an Active-Active architecture. By leveraging a cloud provider with geographically distributed edge nodes, authentication requests from each property are routed to the nearest regional node, minimizing latency. Centralized policy management allows the IT team to define authentication rules once and apply them globally. The cloud provider automatically handles TLS certificate rotation, operating system patching, and database replication.
A national sports stadium is preparing for a 60,000-attendee event. Their current RADIUS setup is an Active-Passive configuration. During load testing, the primary server became saturated processing 8,000 authentication requests per minute when the gates opened, causing severe connection delays, while the secondary server remained completely idle. How can they optimize this deployment?
The network engineering team must convert the deployment from Active-Passive to Active-Active. First, they should reconfigure the stadium's Network Access Devices (NADs) to utilize round-robin load balancing across both RADIUS servers, instantly doubling their authentication throughput. Second, they should provision a third RADIUS node to provide necessary headroom for peak surges. Finally, to ensure accounting data remains consistent across all three active nodes, they must implement a synchronous multi-master database replication solution, such as Galera Cluster.
Análise de Cenários
Q1. Your enterprise retail client requires a highly available RADIUS solution for their point-of-sale terminals. They have strict PCI DSS compliance requirements dictating that absolutely no accounting session data can be lost during a server failover. Which database replication strategy must you implement for the RADIUS backend?
💡 Dica:Consider the difference between data being written simultaneously versus data being copied after the fact.
Mostrar Abordagem Recomendada
You must implement Synchronous Replication (such as a Galera Cluster or MySQL NDB Cluster). Synchronous replication ensures that the accounting record is committed to all nodes simultaneously before acknowledging the transaction. If you used Asynchronous replication, a node failure could result in the loss of recent transactions that had not yet been copied to the secondary database, violating the strict compliance requirement.
Q2. A university campus network uses an Active-Passive RADIUS setup. Students complain that when the primary server undergoes maintenance, it takes nearly 20 seconds for their laptops to connect to the WiFi. The access points are configured with a 3-second RADIUS timeout and 5 retries. How can you reduce the failover delay without changing the server architecture?
💡 Dica:Calculate the maximum wait time based on the NAD timers before it attempts the secondary server.
Mostrar Abordagem Recomendada
You should tune the timers on the Network Access Devices (access points). Currently, the AP waits 3 seconds and retries 5 times, resulting in an 18-second delay (3 seconds × 6 total attempts) before failing over to the passive server. By reducing the configuration to a 2-second timeout and 2 retries, the failover detection time drops to 6 seconds, significantly improving the user experience during maintenance windows.
Q3. You are migrating a multi-site corporate network from an Active-Passive on-premise RADIUS server to an Active-Active Cloud RADIUS platform. During the pilot phase, devices successfully authenticate against Cloud Node A, but when the load balancer routes them to Cloud Node B, the EAP-TLS handshakes fail. What is the most likely configuration error?
💡 Dica:Consider what the client device verifies when establishing a secure EAP tunnel with a new server.
Mostrar Abordagem Recomendada
The most likely issue is a Certificate Trust mismatch. In an Active-Active cluster, all RADIUS nodes must present the exact same server certificate (or certificates issued by the exact same trusted CA chain). If Cloud Node B is presenting a different certificate that the client devices do not trust, the EAP-TLS handshake will be rejected by the client, causing authentication to fail despite the server functioning correctly.
Principais Conclusões
- ✓RADIUS high availability is critical because authentication failures immediately block all network access for users and devices.
- ✓Active-Passive setups are simpler but introduce a 6-18 second failover delay dictated by the Network Access Device's retry timers.
- ✓Active-Active architectures process requests simultaneously, providing instant failover and horizontal scalability for high-density environments.
- ✓While RADIUS authentication is stateless, accounting is stateful and requires synchronous database replication (like Galera) to prevent data loss.
- ✓Cloud RADIUS platforms abstract HA complexity by providing globally distributed, automatically scaling Active-Active infrastructure.
- ✓Configuration drift and mismatched TLS certificates are the most common causes of failure during RADIUS failover events.
