निर्दोषत्व सिद्ध करण्याचा सरासरी वेळ (Mean time to innocence): ते WiFi मुळे नाही हे कसे सिद्ध करावे
Mean time to innocence (MTTI) हा एक महत्त्वपूर्ण मेट्रिक आहे जो हे परिभाषित करतो की IT टीम्स नेटवर्कची समस्या त्यांची चूक नाही हे सिद्ध करण्यासाठी किती वेळ घालवतात. हा मार्गदर्शक मल्टी-टेनंट (multi-tenant) वातावरणातील दोषारोप खेळ समाप्त करण्यासाठी पाच-चरणांच्या ऑब्झर्व्हेबिलिटी (observability) पद्धतीचा तपशील देतो, ज्यामुळे मीन टाईम टू रिझोल्यूशन (MTTR) कमी करण्यासाठी एकमेकांवर बोट दाखवण्याऐवजी सामायिक पुराव्यांचा वापर केला जाईल.
हे मार्गदर्शक ऐका
पॉडकास्ट ट्रान्सक्रिप्ट पहा
📚 Part of our core series: मल्टी-टेनंट WiFi: संपूर्ण मार्गदर्शक →
कार्यकारी सारांश (Executive Summary)
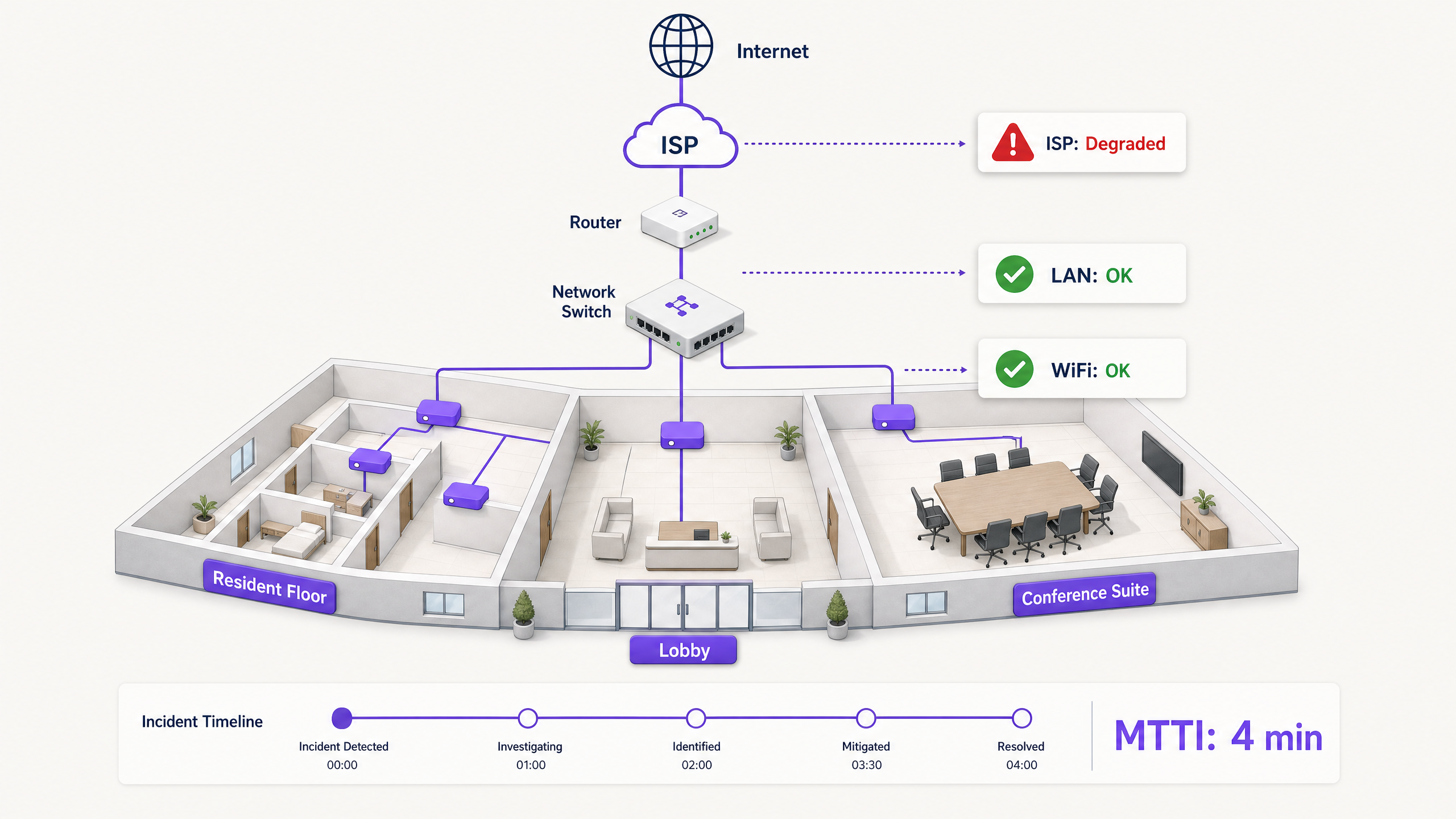
जेव्हा मल्टी-टेनंट वातावरणात कनेक्टिव्हिटी खंडित होते, तेव्हा सर्वात आधी WiFi ला दोष दिला जातो. हा नेटवर्कचा दृश्यमान भाग (visible edge) आहे, डिव्हाइसच्या आधीचा शेवटचा टप्पा (last hop) आहे आणि निराश वापरकर्त्यांसाठी सर्वात सोपे लक्ष्य आहे. IT व्यवस्थापक, नेटवर्क आर्किटेक्ट्स आणि व्हेन्यू ऑपरेशन्स डायरेक्टर्ससाठी, यामुळे एक सततचा ऑपरेशनल भार निर्माण होतो: स्वतःचे निर्दोषत्व सिद्ध करण्यासाठी लागणारा वेळ.
Mean time to innocence (MTTI) हा एखाद्या घटनेची तक्रार नोंदवल्यापासून ते टीमने त्यांचे क्षेत्र (domain) या समस्येचे मूळ कारण नाही हे सिद्ध करेपर्यंत लागणाऱ्या सरासरी वेळेचे मोजमाप करतो. बिल्ड-टू-रेंट (BTR) ब्लॉक्स, हॉटेल्स किंवा कॉन्फरन्स सेंटर्स सारख्या गुंतागुंतीच्या वातावरणात, नेटवर्क हे प्रॉपर्टी मॅनेजर्स, मॅनेज्ड WiFi प्रदाते आणि इंटरनेट सर्व्हिस प्रदाते (ISPs) यांच्यात विभागलेले असते. निश्चित टेलिमेट्री (telemetry) शिवाय, MTTI मुळे मीन टाईम टू रिझोल्यूशन (MTTR) वाढतो, कारण टीम्स दोष दुरुस्त करण्याऐवजी जबाबदारी कोणाची यावर वाद घालत बसतात.
हा मार्गदर्शक पद्धतशीरपणे MTTI कमी करण्यासाठी पाच-चरणांच्या ऑब्झर्व्हेबिलिटी (observability) पद्धतीचा तपशील देतो. सतत सिंथेटिक तपासण्या (synthetic checks), टप्प्याटप्प्याने पाथ व्हिज्युअलायझेशन (hop-by-hop path visibility), फ्लो डेटा विश्लेषण, टोपोलॉजी मॅपिंग आणि इव्हेंट कोरिलेशन लागू करून, तुम्ही एकमेकांवर बोट दाखवण्याऐवजी सामायिक पुराव्यांचा वापर करू शकता. याचा उद्देश दोषारोपाचा खेळ वेगाने जिंकणे हा नसून, तो पूर्णपणे संपवणे हा आहे.
तांत्रिक सखोल विश्लेषण: MTTI ची कार्यपद्धती
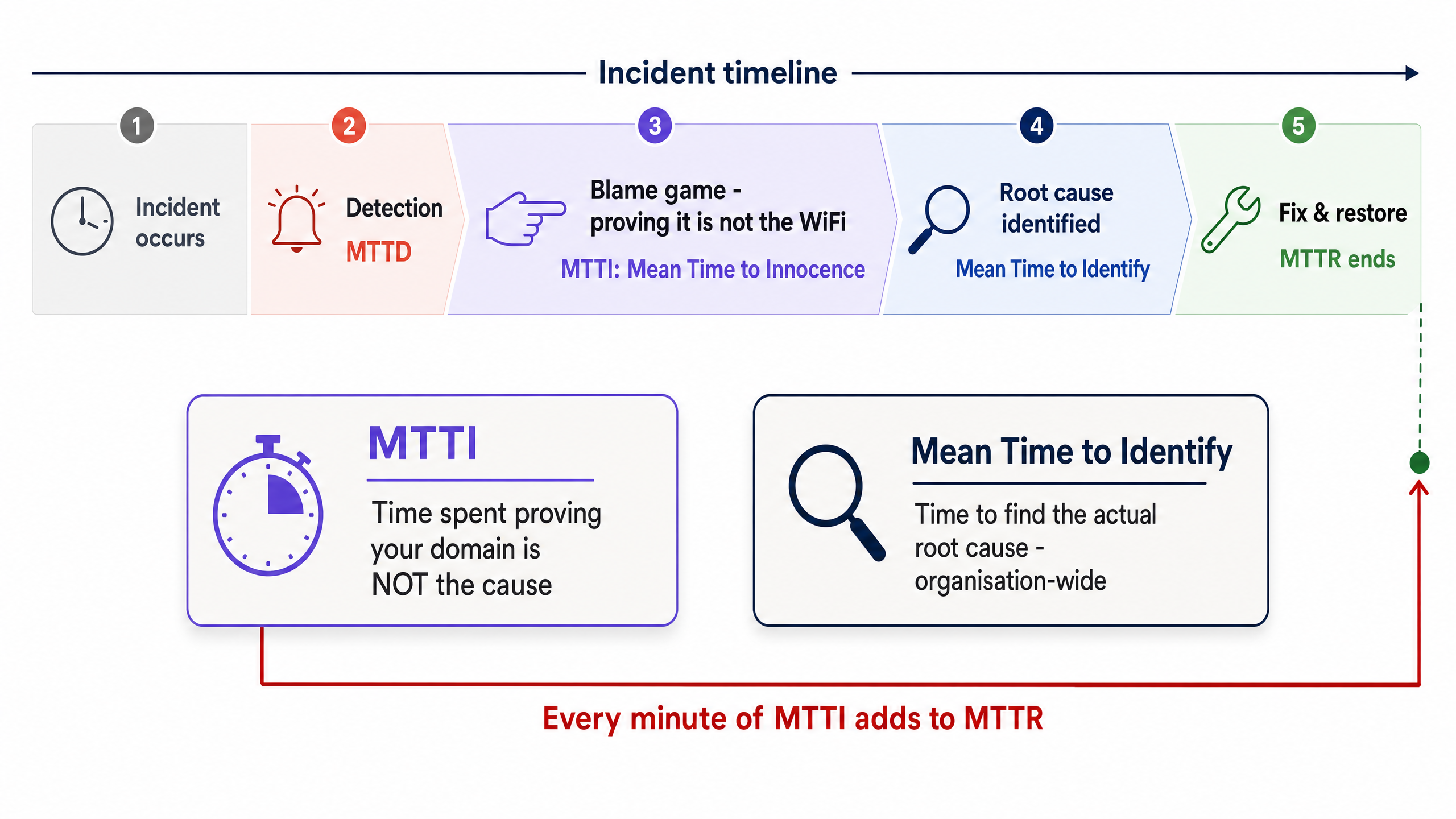
MTTI आणि मीन टाईम टू आयडेंटिफाय (Mean Time to Identify) मधील फरक
MTTI ला मीन टाईम टू आयडेंटिफाय (Mean Time to Identify) पासून वेगळे करणे अत्यंत आवश्यक आहे. मीन टाईम टू आयडेंटिफाय हा संपूर्ण संस्थेच्या पातळीवरील मेट्रिक आहे जो आउटेजचे (outage) मूळ कारण शोधण्यासाठी किती वेळ लागतो याचा मागोवा घेतो. तर MTTI हा एका विशिष्ट विभागापुरता (domain-specific) मर्यादित मेट्रिक आहे, जो एखाद्या टीमला ते दोषी नाहीत हे सिद्ध करण्यासाठी किती वेळ लागतो याचा मागोवा घेतो.
MTTI चा प्रत्येक मिनिट थेट MTTR मध्ये जोडला जातो. जर एखादा मॅनेज्ड WiFi प्रदाता समस्येचे मूळ कारण ISP कडे आहे असा निष्कर्ष काढण्यापूर्वी ऍक्सेस पॉइंट्स (APs) आणि स्विच लॉग्स मॅन्युअली तपासण्यात ४० मिनिटे घालवत असेल, तर प्रत्यक्ष दुरुस्ती सुरू होण्यापूर्वीच MTTR मध्ये ४० मिनिटांचा अतिरिक्त वेळ जोडला जातो.
WiFi लाच का दोष दिला जातो
८०,०००+ लाइव्ह व्हेन्यूजमध्ये ३५ कोटींहून अधिक युनिक युजर्सना सेवा देणाऱ्या वातावरणात, Purple ला वारंवार हाच पॅटर्न पाहायला मिळतो. खालील तीन संरचनात्मक वास्तवांमुळे डीफॉल्टनुसार WiFi लेयरला दोष दिला जातो:
- व्हिज्युअलिटी बायस (Visibility bias): सरासरी व्हेन्यू युझरसाठी WiFi सिग्नल इंडिकेटर हे एकमेव उपलब्ध नेटवर्क डायग्नोस्टिक टूल असते.
- एज प्रॉक्सिमिटी (Edge proximity): क्लायंट डिव्हाइसचा शेवटचा टप्पा (final hop) असल्याने, WiFi वर प्रत्येक अपस्ट्रीम अपयशाचे (upstream failure) परिणाम दिसून येतात. युझरच्या दृष्टीकोनातून ISP कडील DNS टाईमआउट आणि AP चे अपयश हे दोन्ही सारखेच दिसतात.
- टेलिमेट्री गॅप्स (Telemetry gaps): ऐतिहासिकदृष्ट्या, वायरलेसची स्थिती चांगली असल्याचे सिद्ध करण्यासाठी मॅन्युअल हस्तक्षेपाची आवश्यकता असायची. जर तुम्ही दोन मिनिटांपेक्षा कमी वेळात वायरलेस लेयरची स्थिती उत्तम असल्याचे दाखवू शकला नाहीत, तर तुम्ही तुमचे मत सिद्ध करू शकत नाही.
मल्टी-टेनंटमधील गुंतागुंत
सिंगल-टेनंट एंटरप्राइझमध्ये, नेटवर्क टीम्सकडे AP पासून फायरवॉलपर्यंतच्या संपूर्ण स्टॅकची मालकी असते. मल्टी-टेनंट WiFi वातावरणात मात्र ही मालकी विभागलेली असते.
एक BTR रहिवासी प्रॉपर्टी मॅनेजरला पैसे देतो. प्रॉपर्टी मॅनेजर मॅनेज्ड WiFi प्रदात्याशी करार करतो. मॅनेज्ड WiFi प्रदाता थर्ड-पार्टी ISP सर्किटवर आणि बऱ्याचदा घरमालकाच्या इमारतीमधील वितरण नेटवर्कवर (distribution network) अवलंबून असतो. जेव्हा एखादा रहिवासी व्हिडिओ स्ट्रीम करू शकत नाही, तेव्हा प्रदात्याने त्वरित WiFi हार्डवेअरला (Cisco Meraki, HPE Aruba, Ruckus किंवा Juniper Mist) दोषमुक्त केले पाहिजे आणि दोष क्लायंट डिव्हाइस, बिल्डिंग स्विच किंवा ISP मध्ये आहे हे शोधून काढले पाहिजे. असे करण्यात अयशस्वी झाल्यास प्रदाता आणि प्रॉपर्टी मॅनेजर यांच्यातील व्यावसायिक संबंध खराब होतात.
अंमलबजावणी मार्गदर्शक: ५-चरणांची पद्धती
पद्धतशीरपणे MTTI कमी करण्यासाठी, ही पाच-स्तरीय ऑब्झर्व्हेबिलिटी (observability) आर्किटेक्चर लागू करा.
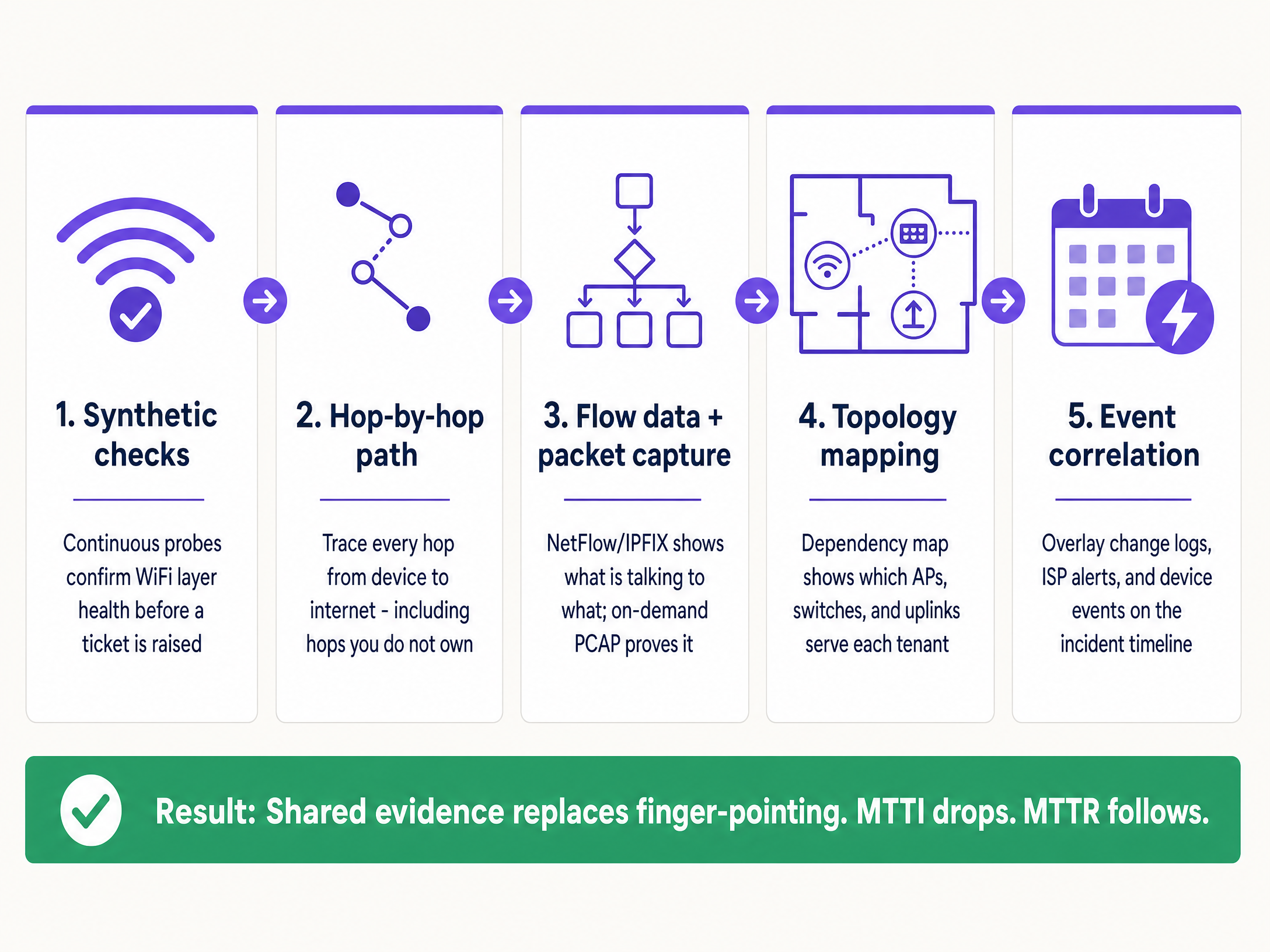
१. सतत सिंथेटिक तपासण्या (Continuous Synthetic Checks)
युझरने तक्रार करण्याची वाट पाहू नका. नेटवर्कच्या टोकापासून (network edge) युझरच्या वर्तनाचे सतत अनुकरण करणारे स्वयंचलित सिंथेटिक प्रोब्स (synthetic probes) तैनात करा.
- अंमलबजावणी: DHCP प्रतिसाद, DNS रिझोल्यूशन, HTTP रीचेबिलिटी आणि ऑथेंटिकेशन फ्लो (जसे की 802.1X किंवा Captive Portal लॉगिन) साठी शेड्युल केलेल्या चाचण्या चालवण्यासाठी APs किंवा समर्पित सेन्सर्स कॉन्फिगर करा.
- परिणाम: जेव्हा एखादी तक्रार (ticket) नोंदवली जाते, तेव्हा तुम्ही आधी सिंथेटिक डॅशबोर्ड तपासा. जर प्रोब्स तक्रारीच्या अचूक वेळी सुरळीत HTTP रीचेबिलिटी दाखवत असतील, तर तुम्ही त्वरित WiFi लेयर आणि WAN सर्किटला दोषमुक्त करता आणि तुमचे लक्ष विशिष्ट क्लायंट डिव्हाइस किंवा लक्ष्यित ॲप्लिकेशनवर केंद्रित करता.
२. टप्प्याटप्प्याने पाथ व्हिज्युअलिटी (Hop-by-Hop Path Visibility)
तुमचे हार्डवेअर व्यवस्थित काम करत आहे हे सिद्ध करणे पुरेसे नाही, जर तुम्ही इंटरनेटचा मार्ग मोकळा आहे हे सिद्ध करू शकत नसाल.
- अंमलबजावणी: ॲक्सेस लेयरपासून LAN वरून, डिमार्केशन पॉईंटद्वारे आणि ISP नेटवर्कमध्ये ट्रॅफिकचा मागोवा घेण्यासाठी पाथ व्हिज्युअलायझेशन टूल्सचा वापर करा.
- परिणाम: जेव्हा लेटन्सी (latency) वाढते, तेव्हा पाथ ट्रेस नेमक्या कोणत्या नोडमुळे उशीर झाला हे दर्शवतो. जर पहिल्या चार टप्प्यांमध्ये (तुमचे क्षेत्र) २ms लेटन्सी दिसत असेल आणि पाचव्या टप्प्यात (ISP एज राउटर) १५०ms लेटन्सी आणि १२% पॅकेट लॉस दिसत असेल, तर तुमच्याकडे ISP ला देण्यासाठी ठोस पुरावा असतो.
३. फ्लो डेटा आणि ऑन-डिमांड पॅकेट कॅप्चर (Flow Data and On-Demand Packet Capture)
जेव्हा युझर्स विशिष्ट ॲप्लिकेशनमधील बिघाडाची तक्रार करतात, तेव्हा तुम्हाला संभाषण-स्तरीय व्हिज्युअलिटी (conversation-level visibility) आवश्यक असते.
- अंमलबजावणी: तुमच्या कोर स्विचेस किंवा फायरवॉल्समधून NetFlow किंवा IPFIX डेटा एक्सपोर्ट करा. तुमच्या ॲक्सेस लेयर हार्डवेअरमध्ये ऑन-साइट इंजिनिअरची आवश्यकता नसताना रिमोट, ऑन-डिमांड पॅकेट कॅप्चर (PCAP) चे समर्थन असल्याची खात्री करा.
- परिणाम: फ्लो डेटा हे सिद्ध करतो की एखाद्या विशिष्ट सेवेसाठी जाणारे ट्रॅफिक तुमच्या नेटवर्कमधून सुरळीतपणे बाहेर पडत आहे की नाही. जर ते जात असेल, तर नेटवर्क निर्दोष आहे. जर dअधिक सखोल फॉरेन्सिक पुराव्याची आवश्यकता असल्यास, विशिष्ट VLAN वरील लक्ष्यित PCAP हे TCP रीट्रांसमिशन किंवा सर्व्हर-साइड रीसेटचे निर्विवाद पुरावे प्रदान करते.
4. टोपोलॉजी आणि डिपेंडन्सी मॅपिंग
मल्टी-टेनंट वातावरणात, ब्लास्ट रेडियस (प्रभाव क्षेत्र) वेगळे करणे हा दोषाचे वर्गीकरण करण्याचा सर्वात वेगवान मार्ग आहे.
- अमलबजावणी: प्रत्येक AP ला त्याच्या स्विच, अपलिंक आणि WAN सर्किटशी जोडणारा आणि टेनंट VLAN शी मॅप केलेला थेट, डायनॅमिकली अपडेट केलेला डिपेंडन्सी मॅप ठेवा.
- परिणाम: जर एखाद्या दोषाचा परिणाम अनेक मजल्यांवरील AP वर होत असेल परंतु केवळ एकाच स्विचवर होत असेल, तर समस्या स्विचमध्ये आहे. जर त्याचा परिणाम सर्व AP वर होत असेल परंतु केवळ एका टेनंटच्या VLAN वर होत असेल, तर ती लॉजिकल कॉन्फिगरेशनची समस्या आहे. जलद व्याप्ती शोधल्यामुळे निरोगी इन्फ्रास्ट्रक्चरची तपासणी करण्यात वाया जाणारे प्रयत्न वाचतात.
5. इव्हेंट कोरिलेशन (इव्हेंट परस्परसंबंध)
संदर्भाशिवाय डेटा असल्यास तपास लांबणीवर पडतो.
- अमलबजावणी: चेंज लॉग्स, ISP मेंटेनन्स अलर्ट, हार्डवेअर फर्मवेअर अपडेट्स आणि युझर तिकिटे एकाच टाइमलाइन व्ह्यूमध्ये फीड करा.
- परिणाम: ऑथेंटिकेशन अयशस्वी होण्यातील वाढ आणि १० मिनिटांपूर्वी घडलेली Microsoft Entra ID सर्टिफिकेट एक्स्पायरी इव्हेंट एकाच वेळी पडताळून पाहिल्यास मूळ कारण त्वरित समजते, ज्यामुळे नेटवर्क हार्डवेअरची तपासणी करण्याची अजिबात गरज उरत नाही.
सर्वोत्तम पद्धती
- हार्डवेअर स्टॅकचे मानकीकरण करा: उपयोजन (deployments) केवळ मान्यताप्राप्त एंटरप्राइझ विक्रेत्यांपुरते (Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme, Fortinet) मर्यादित ठेवा जे सिंथेटिक टेस्टिंग आणि रिमोट PCAP साठी API उपलब्ध करून देतात.
- पुराव्याचे ऑटोमेशन करा: तुमची मॉनिटरिंग प्लॅटफॉर्म अशा प्रकारे कॉन्फिगर करा जेणेकरून तिकीट तयार होताच सिंथेटिक चाचणीचे निकाल आणि पाथ ट्रेसेस स्वयंचलितपणे ITSM तिकिटांना जोडले जातील.
- डॅशबोर्ड शेअर करा: प्रॉपर्टी मॅनेजर्सना हाय-लेव्हल हेल्थ डॅशबोर्डवर रीड-ओन्ली ॲक्सेस द्या. पारदर्शकतेमुळे एकमेकांवर दोषारोप करणे टाळता येते.
- MTTI चा औपचारिकपणे मागोवा घ्या: तिकीट तयार झाल्यापासून ते तुमच्या टीमने नेटवर्क निर्दोष असल्याचा पुरावा देईपर्यंतचा वेळ मोजा. MTTR सोबतच याला प्राथमिक KPI म्हणून गृहीत धरा.
ट्रबलशूटिंग आणि जोखीम निवारण
- जोखीम: 'No Fault Found' लूप: युझर्स समस्यांची तक्रार करतात, परंतु सिंथेटिक तपासण्या ग्रीन (यशस्वी) दर्शवतात.
- निवारण: ही समस्या यांत्रिकदृष्ट्या डिव्हाइस-विशिष्ट किंवा RF इंटरफेरन्सशी (को-चॅनेल इंटरफेरन्स किंवा भौतिक अडथळा) संबंधित असू शकते. विशिष्ट डिव्हाइसचा RSSI आणि रोमिंग इतिहास तपासण्यासाठी क्लायंट-साइड ॲनालिटिक्स वापरा.
- जोखीम: ISP नकार: तुमच्या पुराव्या असूनही ISP दोष स्वीकारण्यास नकार देतो.
- निवारण: पॅकेट लॉस नेमका कोणत्या IP ॲड्रेसवर सुरू होतो हे दर्शवणारे हॉप-बाय-हॉप पाथ ट्रेसेस प्रदान करा. तुमच्या डिमार्केशन पॉईंटवरून क्लीन इग्रेस (clean egress) दर्शवणारे PCAPs शेअर करा. ठोस डेटा असल्यास त्यांना लेव्हल १ सपोर्टच्या पुढे एस्केलेशन करणे भाग पडते.
- जोखीम: Captive Portal अपयश: जेव्हा पोर्टल लोड होण्यात अपयशी ठरते, तेव्हा युझर्स WiFi ला दोष देतात.
- निवारण: आयडेंटिटी प्रोव्हाइडर वेगळा करा. इंटिग्रेशनची स्थिती तपासा (Microsoft Entra ID, Okta, Google Workspace). जर नेटवर्क प्री-ऑथेंटिकेशन ट्रॅफिकला अनुमती देत असेल परंतु IdP टाईम आऊट होत असेल, तर नेटवर्क निर्दोष आहे.
ROI आणि व्यावसायिक प्रभाव
MTTI कमी केल्याने केवळ इंजिनिअरिंगचे तास वाचवण्यापलीकडे मोजता येण्याजोगा व्यावसायिक फायदा मिळतो.
- कमी झालेला MTTR: एखाद्या घटनेतील ४० मिनिटांचे दोषारोप टाळल्याने थेट डाउनटाइम कमी होतो, ज्यामुळे retail आणि hospitality वातावरणातील महसुलाचे संरक्षण होते.
- SLA अनुपालन: जेव्हा दोष ISP किंवा इमारतीच्या इन्फ्रास्ट्रक्चरमध्ये असतो, तेव्हा जलद निर्दोषत्व सिद्ध झाल्यामुळे मॅनेज्ड WiFi प्रोव्हाइडरवर अन्यायकारक दंड आकारला जाणे टळते.
- क्लायंट टिकवून ठेवणे: मल्टी-टेनंट WiFi क्षेत्रात, प्रॉपर्टी मॅनेजर्स अशा प्रोव्हाइडर्ससोबत करारांचे नूतनीकरण करतात जे पारदर्शकता आणि जलद उत्तरे देतात. शेअर केलेले पुरावे विश्वास निर्माण करतात; बचावात्मक युक्तिवाद तो नष्ट करतात.
- संसाधनांचे ऑप्टिमायझेशन: जास्त पगार असलेले लेव्हल ३ नेटवर्क इंजिनिअर्स नेटवर्क योग्यरित्या काम करत असल्याचे मॅन्युअली सिद्ध करण्याऐवजी त्यांचा वेळ सोल्यूशन्स डिझाइन करण्यात घालवतात.
महत्वाच्या व्याख्या
Mean Time to Innocence (MTTI)
The average time required for a specific IT team to prove, using objective data, that their domain or infrastructure is not the root cause of a reported incident.
Critical for managed WiFi providers who must defend their service against property managers and ISPs.
Mean Time to Identify
The organisation-wide metric tracking the total time elapsed from incident detection to the discovery of the actual root cause.
MTTI is a subset of this metric. Reducing MTTI directly reduces the overall time to identify.
Synthetic Checks
Automated, continuous tests that emulate user traffic (e.g., DNS lookups, HTTP requests) to proactively monitor network health.
Used to prove the WiFi layer was functioning correctly at the exact moment a user complained.
Hop-by-Hop Path Visibility
Telemetry that traces network traffic node-by-node from the client to the destination, measuring latency and loss at each specific router or switch.
Essential for proving a fault lies in an ISP network or a landlord's distribution switch, rather than the managed WiFi hardware.
Flow Data (NetFlow/IPFIX)
Network protocol data that provides a summary of traffic conversations, showing source, destination, protocol, and volume.
Used to prove that specific application traffic is successfully leaving the local network.
On-Demand Packet Capture (PCAP)
The ability to remotely record raw network traffic from an access point or switch for forensic analysis.
The ultimate proof used to demonstrate server-side errors or client device misbehaviour.
Blast Radius
The scope of impact of a specific incident (e.g., one user, one AP, one switch, one tenant, or the entire building).
Determining the blast radius via topology mapping is the fastest way to exclude healthy infrastructure from an investigation.
Event Correlation
The practice of overlaying different data streams (logs, alerts, updates) on a single timeline to identify cause and effect.
Used to prove that a network outage was caused by a third-party change, such as an unannounced ISP maintenance window.
सोडवलेली उदाहरणे
A 350-room hotel reports that in-room WiFi is slow across the entire property. The front desk blames the managed WiFi provider. How do you exonerate the network and find the root cause?
- Check the synthetic probes: DNS and HTTP reachability tests show the APs have a clean connection to the internet. 2. Review the topology map: The issue affects all APs across all switches, ruling out edge hardware. 3. Execute a path trace: The trace shows 2ms latency within the hotel LAN, but 180ms latency at the third hop (the ISP's aggregation router). 4. Export the evidence: Send the path trace screenshot to the hotel manager and the ISP.
A national retailer reports point-of-sale (POS) terminals in one region are dropping connections to the payment processor. The network team is blamed for a firewall or routing misconfiguration.
- Isolate the blast radius: Confirm only POS terminals (specific VLAN) are affected; guest WiFi and back-office systems are healthy. 2. Analyse flow data: NetFlow confirms traffic destined for the payment processor's IP range is successfully leaving the store routers. 3. Capture packets: An on-demand PCAP on the POS VLAN reveals the payment processor's server is sending TCP resets (RST). 4. Share the PCAP with the payment processor's support team.
सराव प्रश्न
Q1. A tenant in a coworking space complains they cannot access their corporate VPN. Other tenants are browsing the internet without issue. What is the most efficient way to prove the WiFi network is not at fault?
टीप: Consider the blast radius and the specific type of traffic failing.
नमुना उत्तर पहा
First, use the topology map to confirm the blast radius is limited to one user or one specific service, ruling out a general AP or switch failure. Second, analyse flow data (NetFlow/IPFIX) for that client's IP address. If the flow data shows the VPN traffic (e.g., UDP 500 or TCP 443) is leaving the network cleanly, the WiFi and LAN are innocent. The issue is either the client's VPN configuration or the corporate firewall blocking the connection.
Q2. Your monitoring dashboard shows an AP has gone offline, but the property manager insists the WiFi is broken because the ISP is down. How do you prove the issue is internal power, not the ISP?
टीप: Look for correlation between infrastructure state and external events.
नमुना उत्तर पहा
Use event correlation and topology mapping. If the topology map shows only one AP is offline while others on the same switch are functioning, the ISP circuit is clearly active. Event correlation might show a PoE (Power over Ethernet) failure log from the switch port connected to that specific AP. This proves the issue is local hardware or cabling, not the WAN circuit.
Q3. A stadium operations director claims the WiFi failed during halftime because ticket scanners stopped working. You need to exonerate the network in under two minutes. What telemetry do you use?
टीप: You need historical proof of health at the exact moment of the reported failure.
नमुना उत्तर पहा
Pull the historical data from the continuous synthetic checks. Show the operations director the dashboard confirming that during the exact 15-minute halftime window, the APs were successfully resolving DNS and reaching the ticketing server's IP address with low latency. This immediately proves the wireless network was healthy and shifts the investigation to the ticketing application servers, which likely buckled under the sudden load.
या मालिकेमध्ये पुढे वाचा
SCEP साठी एंटरप्राइझ मार्गदर्शिका: स्वयंचलित कॅम्पस WiFi सुरक्षेसाठी सिम्पल सर्टिफिकेट एनरोलमेंट प्रोटोकॉल उपयोजित करणे
हे तांत्रिक संदर्भ मार्गदर्शक SCEP चा वापर करून एंटरप्राइझ WiFi प्रमाणपत्र उपयोजनासाठी एक निश्चित आर्किटेक्चरल ब्ल्यूप्रिंट आणि टप्प्याटप्प्याने अंमलबजावणीची रणनीती प्रदान करते. यामध्ये SCEP आणि PKCS मधील महत्त्वपूर्ण फरक, यशस्वीतेसाठी आवश्यक असलेला अचूक उपयोजन क्रम आणि IT नेत्यांसाठी वास्तविक-जगातील जोखीम कमी करण्याच्या धोरणांचा समावेश आहे.
माझा Guest WiFi का कनेक्ट होत नाही आहे? Captive Portal च्या समस्यांचे निवारण
हे अधिकृत तांत्रिक संदर्भ मार्गदर्शक Captive Portal शोधण्याच्या (detection) मूळ कार्यपद्धतीचे स्पष्टीकरण देते आणि guest WiFi कनेक्ट होण्यापासून रोखणाऱ्या सहा मुख्य बिघाड पद्धतींचा (failure modes) तपशील देते. हे IT व्यवस्थापक आणि नेटवर्क आर्किटेक्ट्सना HTTP रिडायरेक्ट समस्या, DNS संघर्ष आणि MAC रँडमायझेशन आव्हाने सोडवण्यासाठी एक व्यावहारिक ट्रबलशूटिंग फ्रेमवर्क प्रदान करते.
स्वयंचलित WiFi प्रमाणपत्र नोंदणीसाठी SCEP कसे लागू करावे
हे मार्गदर्शक एंटरप्राइझ ठिकाणांवर स्वयंचलित WiFi प्रमाणपत्र नोंदणीसाठी SCEP (सिंपल सर्टिफिकेट एनरोलमेंट प्रोटोकॉल) कसे लागू करावे हे स्पष्ट करते. यामध्ये PKI डिझाइन आणि MDM एकत्रीकरणापासून ते अनिवार्य तीन-चरण उपयोजन क्रमापर्यंत संपूर्ण आर्किटेक्चरल ब्ल्यूप्रिंट समाविष्ट आहे - आणि IT व्यवस्थापक आणि नेटवर्क आर्किटेक्ट्सना सामायिक क्रेडेंशियल्स कसे काढून टाकायचे, प्रमाणपत्र जीवनचक्र व्यवस्थापन स्वयंचलित कसे करायचे आणि मोठ्या प्रमाणावर PCI DSS आणि GDPR आवश्यकता कशा पूर्ण करायच्या हे दाखवते.