মিন টাইম টু ইনোসেন্স: কীভাবে প্রমাণ করবেন যে এটি WiFi-এর সমস্যা নয়
মিন টাইম টু ইনোসেন্স (MTTI) হলো একটি গুরুত্বপূর্ণ মেট্রিক যা নির্ধারণ করে যে আইটি (IT) টিমগুলো একটি নেটওয়ার্ক সমস্যা তাদের নিজস্ব ভুল নয় তা প্রমাণ করতে কতটা সময় ব্যয় করে। এই নির্দেশিকাটি মাল্টি-টেন্যান্ট পরিবেশে দোষারোপের খেলা বন্ধ করতে একটি পাঁচ-ধাপের অবজারভেবিলিটি (observability) পদ্ধতির বিস্তারিত বর্ণনা করে, যা রেজোলিউশনের গড় সময় (MTTR) কমিয়ে আনার জন্য পারস্পরিক দোষারোপের পরিবর্তে যৌথ প্রমাণ উপস্থাপন করে।
এই গাইডটি শুনুন
পডকাস্ট ট্রান্সক্রিপ্ট দেখুন
📚 Part of our core series: মাল্টি-টেন্যান্ট WiFi: সম্পূর্ণ নির্দেশিকা →
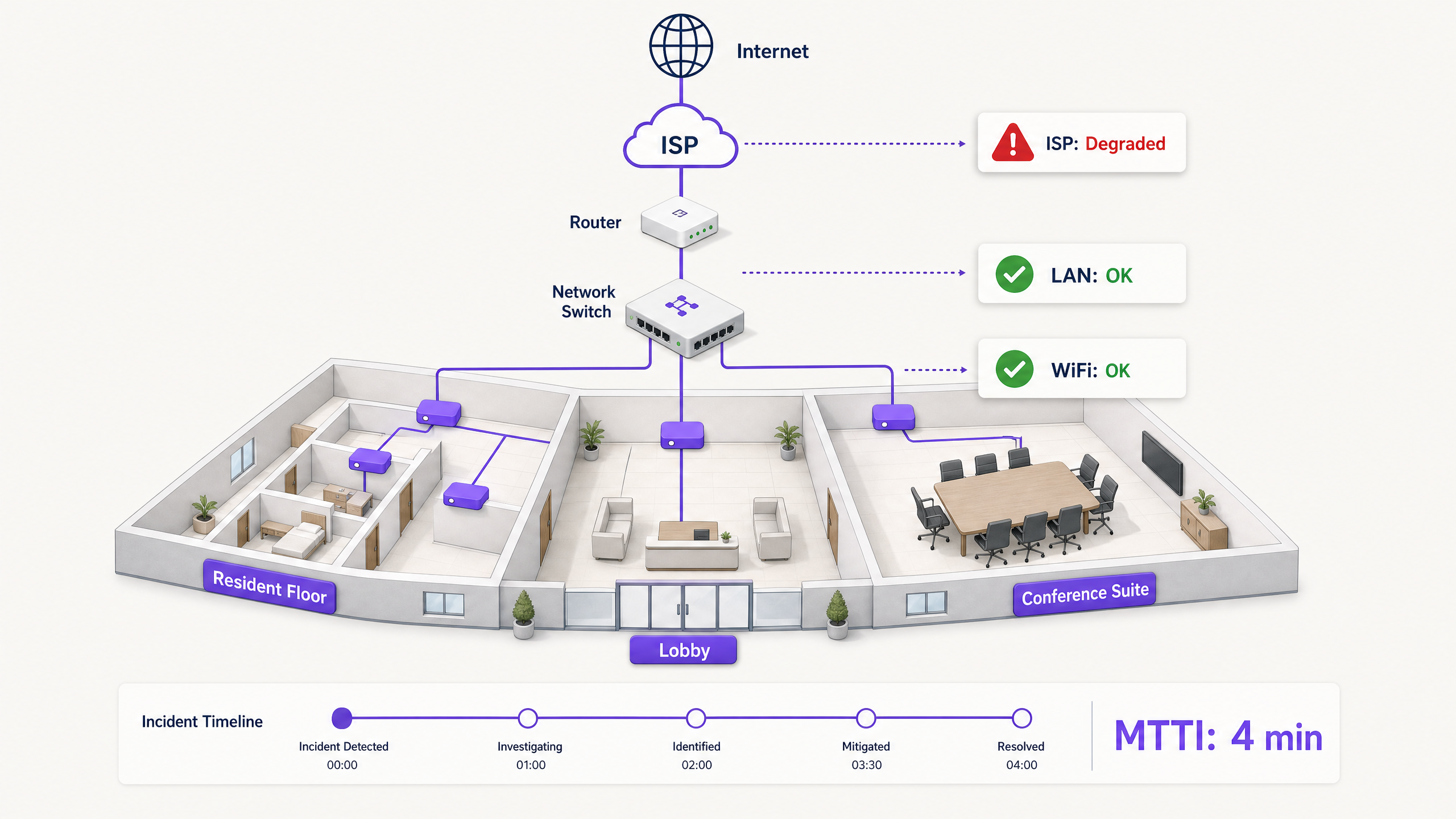
সারসংক্ষেপ
যখন কোনো মাল্টি-টেন্যান্ট পরিবেশে কানেক্টিভিটি বিচ্ছিন্ন হয়, তখন সবার আগে WiFi-কে দোষারোপ করা হয়। এটি নেটওয়ার্কের দৃশ্যমান প্রান্ত, ডিভাইসের আগের শেষ ধাপ (last hop) এবং হতাশ ব্যবহারকারীদের জন্য সবচেয়ে সহজ লক্ষ্য। আইটি ম্যানেজার, নেটওয়ার্ক আর্কিটেক্ট এবং ভেন্যু অপারেশন ডিরেক্টরদের জন্য এটি একটি স্থায়ী অপারেশনাল ট্যাক্স তৈরি করে: নির্দোষতা প্রমাণ করার জন্য ব্যয় করা সময়।
মিন টাইম টু ইনোসেন্স (MTTI) কোনো ঘটনার রিপোর্ট করা এবং একটি টিমের তাদের নিজস্ব ডোমেনটি মূল কারণ নয় তা প্রদর্শন করার ক্ষমতার মধ্যবর্তী গড় অতিবাহিত সময় পরিমাপ করে। বিল্ড-টু-রেন্ট (BTR) ব্লক, হোটেল বা কনফারেন্স সেন্টারের মতো জটিল পরিবেশে নেটওয়ার্কটি প্রোপার্টি ম্যানেজার, ম্যানেজড WiFi প্রোভাইডার এবং ইন্টারনেট সার্ভিস প্রোভাইডারদের (ISP) মধ্যে খণ্ডিত থাকে। নির্দিষ্ট টেলিমেট্রি ছাড়া, MTTI রেজোলিউশনের গড় সময়কে (MTTR) বাড়িয়ে দেয়, কারণ টিমগুলো ত্রুটি সংশোধন করার পরিবর্তে দায়িত্ব কার তা নিয়ে তর্ক করে।
এই নির্দেশিকাটি পদ্ধতিগতভাবে MTTI হ্রাস করার জন্য একটি পাঁচ-ধাপের অবজারভেবিলিটি পদ্ধতির বিস্তারিত বর্ণনা করে। অবিচ্ছিন্ন সিন্থেটিক চেক, হপ-বাই-হপ পাথ ভিজিবিলিটি, ফ্লো ডেটা বিশ্লেষণ, টপোলজি ম্যাপিং এবং ইভেন্ট কোরিলেশন প্রয়োগ করে, আপনি পারস্পরিক দোষারোপের পরিবর্তে যৌথ প্রমাণ উপস্থাপন করতে পারেন। লক্ষ্য দোষারোপের খেলায় দ্রুত জয়ী হওয়া নয়, বরং এটি সম্পূর্ণরূপে শেষ করা।
টেকনিক্যাল ডিপ-ডাইভ: MTTI-এর কার্যপ্রণালী
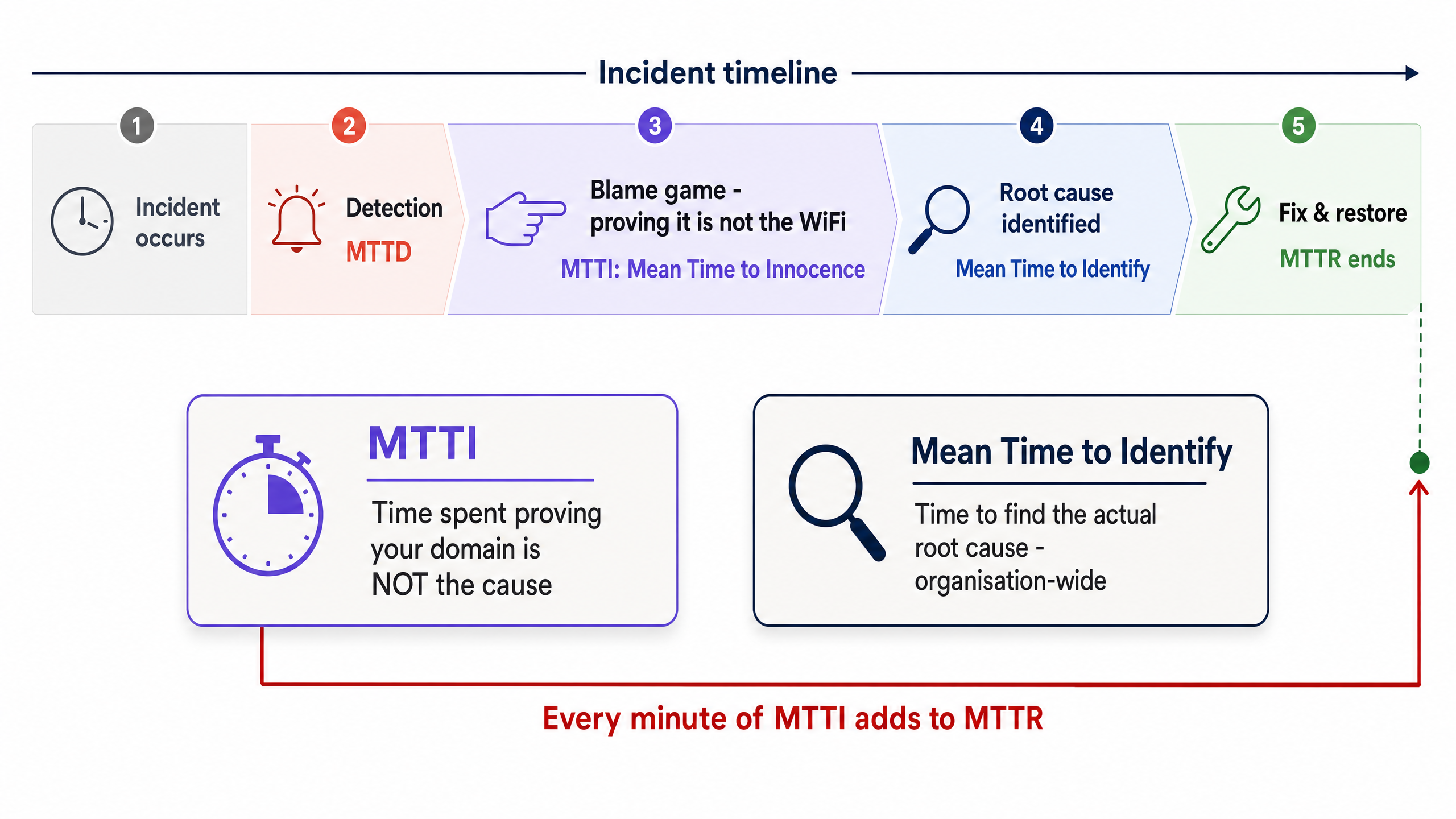
MTTI এবং মিন টাইম টু আইডেন্টিফাই-এর মধ্যে পার্থক্য
MTTI-কে মিন টাইম টু আইডেন্টিফাই থেকে আলাদা করা অত্যন্ত গুরুত্বপূর্ণ। মিন টাইম টু আইডেন্টিফাই হলো একটি প্রতিষ্ঠান-ব্যাপী মেট্রিক যা কোনো বিভ্রাটের (outage) প্রকৃত মূল কারণ খুঁজে পেতে কতক্ষণ সময় লাগে তা ট্র্যাক করে। অন্যদিকে, MTTI হলো একটি সাইলো-ভিত্তিক, ডোমেন-নির্দিষ্ট মেট্রিক যা একটি টিম নিজেদের অপরাধী নয় তা প্রমাণ করতে কতক্ষণ সময় নেয় তা ট্র্যাক করে।
MTTI-এর প্রতিটি মিনিট সরাসরি MTTR-এর সাথে যুক্ত হয়। যদি একজন ম্যানেজড WiFi প্রোভাইডার সমস্যাটি ISP-এর সাথে সম্পর্কিত তা সিদ্ধান্ত নেওয়ার আগে অ্যাক্সেস পয়েন্ট (AP) এবং সুইচ লগগুলো ম্যানুয়ালি পরীক্ষা করতে ৪০ মিনিট সময় ব্যয় করে, তবে প্রকৃত সমাধান শুরু হওয়ার আগেই MTTR-এ একটি ৪০ মিনিটের বিলম্ব যুক্ত হয়ে যায়।
কেন WiFi-কে দোষারোপ করা হয়
৮০,০০০+ লাইভ ভেন্যু জুড়ে ৩৫০ মিলিয়ন অনন্য ব্যবহারকারীকে পরিষেবা দেওয়ার পরিবেশে, Purple বারবার একই প্যাটার্ন লক্ষ্য করে। তিনটি কাঠামোগত বাস্তবতার কারণে ডিফল্টরূপে WiFi লেয়ারকে দোষারোপ করা হয়:
- ভিজিবিলিটি বায়াস (Visibility bias): WiFi সিগন্যাল ইন্ডিকেটর হলো গড় ভেন্যু ব্যবহারকারীর কাছে উপলব্ধ একমাত্র নেটওয়ার্ক ডায়াগনস্টিক টুল।
- এজ প্রক্সিমিটি (Edge proximity): ক্লায়েন্ট ডিভাইসের শেষ ধাপ (final hop) হিসেবে, WiFi প্রতিটি আপস্ট্রিম ব্যর্থতার লক্ষণগুলো নিজের ওপর টেনে নেয়। ব্যবহারকারীর দৃষ্টিকোণ থেকে ISP-তে একটি DNS টাইমআউট এবং একটি AP ব্যর্থতা দেখতে হুবহু একই রকম লাগে।
- টেলিমেট্রি গ্যাপ (Telemetry gaps): ঐতিহাসিকভাবে, ওয়্যারলেস হেলথ প্রমাণ করার জন্য ম্যানুয়াল হস্তক্ষেপের প্রয়োজন হতো। আপনি যদি দুই মিনিটের কম সময়ের মধ্যে ওয়্যারলেস লেয়ারের একটি পরিষ্কার রিপোর্ট দেখাতে না পারেন, তবে আপনি আপনার যুক্তি প্রমাণ করতে পারবেন না।
মাল্টি-টেন্যান্ট জটিলতা
একটি সিঙ্গেল-টেন্যান্ট এন্টারপ্রাইজে, নেটওয়ার্ক টিমগুলো AP থেকে ফায়ারওয়াল পর্যন্ত পুরো স্ট্যাকের মালিকানা পায়। কিন্তু মাল্টি-টেন্যান্ট WiFi পরিবেশে, মালিকানা খণ্ডিত থাকে।
একজন BTR বাসিন্দা প্রোপার্টি ম্যানেজারকে অর্থ প্রদান করেন। প্রোপার্টি ম্যানেজার একজন ম্যানেজড WiFi প্রোভাইডারের সাথে চুক্তি করেন। ম্যানেজড WiFi প্রোভাইডার একটি থার্ড-পার্টি ISP সার্কিট এবং প্রায়শই ল্যান্ডলর্ডের ইন-বিল্ডিং ডিস্ট্রিবিউশন নেটওয়ার্কের ওপর নির্ভর করে। যখন কোনো বাসিন্দা ভিডিও স্ট্রিম করতে পারেন না, তখন প্রোভাইডারকে অবশ্যই দ্রুত WiFi হার্ডওয়্যারকে (Cisco Meraki, HPE Aruba, Ruckus, বা Juniper Mist) নির্দোষ প্রমাণ করতে হবে এবং ত্রুটিটি ক্লায়েন্ট ডিভাইস, বিল্ডিং সুইচ বা ISP-তে চিহ্নিত করতে হবে। এটি করতে ব্যর্থ হলে প্রোভাইডার এবং প্রোপার্টি ম্যানেজারের মধ্যে বাণিজ্যিক সম্পর্ক ক্ষতিগ্রস্ত হয়।
ইমপ্লিমেন্টেশন গাইড: ৫-ধাপের পদ্ধতি
পদ্ধতিগতভাবে MTTI হ্রাস করতে, এই পাঁচ-স্তরের অবজারভেবিলিটি আর্কিটেকচারটি প্রয়োগ করুন।
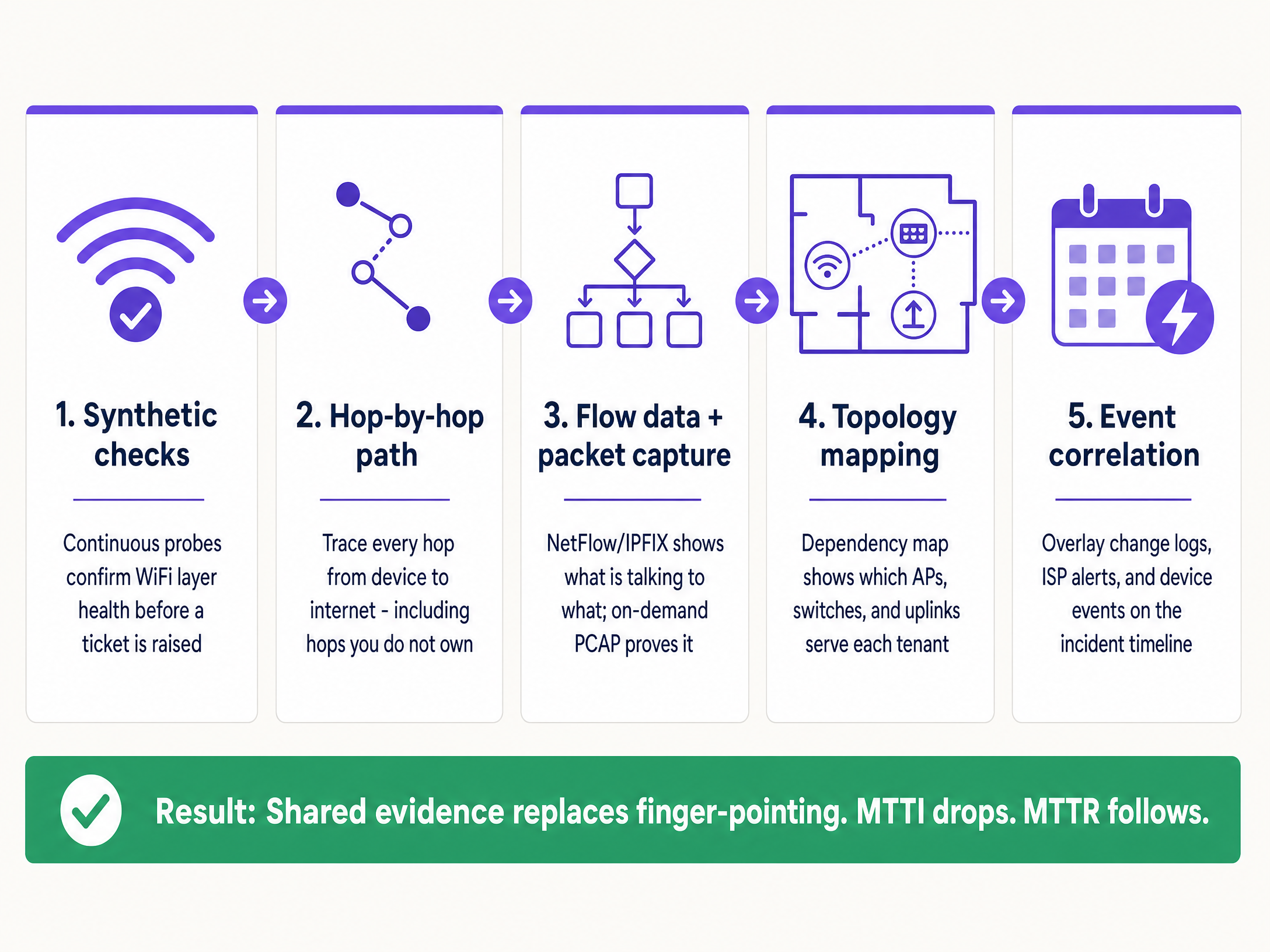
১. অবিচ্ছিন্ন সিন্থেটিক চেক (Continuous Synthetic Checks)
ব্যবহারকারীর অভিযোগ করার জন্য অপেক্ষা করবেন না। স্বয়ংক্রিয় সিন্থেটিক প্রোব স্থাপন করুন যা নেটওয়ার্কের প্রান্ত থেকে ক্রমাগত ব্যবহারকারীর আচরণ অনুকরণ করে।
- বাস্তবায়ন (Implementation): DHCP রেসপন্স, DNS রেজোলিউশন, HTTP রিচিবিলিটি এবং অথেন্টিকেশন ফ্লো (যেমন 802.1X বা Captive Portal লগইন)-এর জন্য নির্ধারিত পরীক্ষাগুলো চালানোর জন্য AP বা ডেডিকেটেড সেন্সর কনফিগার করুন।
- ফলাফল (Outcome): যখন কোনো টিকিট উত্থাপন করা হয়, আপনি প্রথমে সিন্থেটিক ড্যাশবোর্ড পরীক্ষা করবেন। অভিযোগের ঠিক একই সময়ে যদি প্রোবগুলো পরিষ্কার HTTP রিচিবিলিটি দেখায়, তবে আপনি অবিলম্বে WiFi লেয়ার এবং WAN সার্কিটকে নির্দোষ প্রমাণ করতে পারেন এবং নির্দিষ্ট ক্লায়েন্ট ডিভাইস বা টার্গেট অ্যাপ্লিকেশনের দিকে মনোযোগ দিতে পারেন।
২. হপ-বাই-হপ পাথ ভিজিবিলিটি (Hop-by-Hop Path Visibility)
আপনার হার্ডওয়্যার সচল আছে তা প্রমাণ করাই যথেষ্ট নয় যদি না আপনি প্রমাণ করতে পারেন যে ইন্টারনেটের পথটি পরিষ্কার আছে।
- বাস্তবায়ন (Implementation): অ্যাক্সেস লেয়ার থেকে LAN জুড়ে, ডিমার্কেশন পয়েন্টের মাধ্যমে এবং ISP নেটওয়ার্কে ট্রাফিক ট্র্যাক করতে পাথ ভিজ্যুয়ালাইজেশন টুল ব্যবহার করুন।
- ফলাফল (Outcome): যখন লেটেন্সি বৃদ্ধি পায়, তখন একটি পাথ ট্রেস ঠিক কোন নোডটি বিলম্বের সৃষ্টি করেছে তা প্রকাশ করে। যদি এক থেকে চার নম্বর হপ (আপনার ডোমেন) ২ মিলি-সেকেন্ড (2ms) লেটেন্সি দেখায় এবং পাঁচ নম্বর হপ (ISP এজ রাউটার) ১৫০ মিলি-সেকেন্ড (150ms) লেটেন্সি এবং ১২% প্যাকেট লস দেখায়, তবে আপনার কাছে ISP-কে দেওয়ার মতো সুনির্দিষ্ট প্রমাণ থাকবে।
৩. ফ্লো ডেটা এবং অন-ডিমান্ড প্যাকেট ক্যাপচার (Flow Data and On-Demand Packet Capture)
যখন ব্যবহারকারীরা অ্যাপ্লিকেশন-নির্দিষ্ট ব্যর্থতার রিপোর্ট করেন, তখন আপনার কনভারসেশন-লেভেল ভিজিবিলিটি প্রয়োজন।
- বাস্তবায়ন (Implementation): আপনার কোর সুইচ বা ফায়ারওয়াল থেকে NetFlow বা IPFIX ডেটা এক্সপোর্ট করুন। নিশ্চিত করুন যে আপনার অ্যাক্সেস লেয়ার হার্ডওয়্যার সাইটে কোনো ইঞ্জিনিয়ারের উপস্থিতি ছাড়াই রিমোট, অন-ডিমান্ড প্যাকেট ক্যাপচার (PCAP) সমর্থন করে।
- ফলাফল (Outcome): ফ্লো ডেটা প্রমাণ করে যে কোনো নির্দিষ্ট পরিষেবার ট্রাফিক আপনার নেটওয়ার্ক থেকে সফলভাবে বের হচ্ছে কিনা। যদি তা হয়, তবে নেটওয়ার্কটি নির্দোষ। যদি dআরও গভীর ফরেনসিক প্রমাণের প্রয়োজন হলে, নির্দিষ্ট VLAN-এর উপর একটি টার্গেটেড PCAP, TCP রিট্রান্সমিশন বা সার্ভার-সাইড রিসেটের অনস্বীকার্য প্রমাণ প্রদান করে।
৪. টপোলজি এবং ডিপেন্ডেন্সি ম্যাপিং
একটি মাল্টি-টেন্যান্ট পরিবেশে, ব্লাস্ট রেডিয়াস (ক্ষতির পরিধি) আলাদা করা একটি ত্রুটি শ্রেণীবদ্ধ করার দ্রুততম উপায়।
- বাস্তবায়ন: প্রতিটি AP-কে তার সুইচ, আপলিঙ্ক এবং WAN সার্কিটের সাথে সংযুক্ত করে একটি লাইভ, গতিশীলভাবে আপডেট হওয়া ডিপেন্ডেন্সি ম্যাপ বজায় রাখুন, যা টেন্যান্ট VLAN-এর বিপরীতে ম্যাপ করা থাকবে।
- ফলাফল: যদি কোনো ত্রুটি একাধিক ফ্লোর জুড়ে থাকা AP-গুলোকে প্রভাবিত করে কিন্তু শুধুমাত্র একটি সুইচে হয়, তবে সমস্যাটি সুইচে। যদি এটি সমস্ত AP-কে প্রভাবিত করে কিন্তু শুধুমাত্র একজন টেন্যান্টের VLAN-কে প্রভাবিত করে, তবে এটি একটি লজিক্যাল কনফিগারেশন সমস্যা। দ্রুত স্কোপিং স্বাস্থ্যকর অবকাঠামো তদন্তে অযথা সময় নষ্ট হওয়া রোধ করে।
৫. ইভেন্ট কোরিলেশন
প্রসঙ্গ ছাড়া ডেটা তদন্তকে দীর্ঘায়িত করে।
- বাস্তবায়ন: চেঞ্জ লগ, ISP রক্ষণাবেক্ষণের অ্যালার্ট, হার্ডওয়্যার ফার্মওয়্যার আপডেট এবং ব্যবহারকারীর টিকিটগুলোকে একটি একক টাইমলাইন ভিউতে যুক্ত করুন।
- ফলাফল: অথেন্টিকেশন ব্যর্থতার বৃদ্ধির সাথে ১০ মিনিট আগে ঘটে যাওয়া একটি Microsoft Entra ID সার্টিফিকেট এক্সপায়ারেশন ইভেন্টকে ওভারলে করলে তাৎক্ষণিকভাবে মূল কারণ চিহ্নিত করা যায়, যা নেটওয়ার্ক হার্ডওয়্যারকে সম্পূর্ণরূপে এড়িয়ে যায়।
সেরা অনুশীলনসমূহ
- হার্ডওয়্যার স্ট্যাক স্ট্যান্ডার্ডাইজ করুন: ডিপ্লয়মেন্টগুলোকে ক্যানোনিকাল এন্টারপ্রাইজ ভেন্ডরদের (Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme, Fortinet) মধ্যে সীমাবদ্ধ রাখুন যা সিন্থেটিক টেস্টিং এবং রিমোট PCAP-এর জন্য API প্রদান করে।
- প্রমাণ স্বয়ংক্রিয় করুন: আপনার মনিটরিং প্ল্যাটফর্মটি এমনভাবে কনফিগার করুন যাতে ITSM টিকিট তৈরি হওয়ার সাথে সাথেই সিন্থেটিক টেস্টের ফলাফল এবং পাথ ট্রেসগুলো স্বয়ংক্রিয়ভাবে সংযুক্ত হয়ে যায়।
- ড্যাশবোর্ড শেয়ার করুন: প্রপার্টি ম্যানেজারদের একটি হাই-লেভেল হেলথ ড্যাশবোর্ডে রিড-অনলি অ্যাক্সেস প্রদান করুন। স্বচ্ছতা দোষারোপের খেলা বন্ধ করে।
- MTTI আনুষ্ঠানিকভাবে ট্র্যাক করুন: টিকিট তৈরি এবং আপনার টিম নির্দোষতার প্রমাণ দেওয়ার মধ্যবর্তী সময় পরিমাপ করুন। এটিকে MTTR-এর পাশাপাশি একটি প্রাথমিক KPI হিসেবে বিবেচনা করুন।
ট্রাবলশুটিং এবং ঝুঁকি প্রশমন
- ঝুঁকি: 'কোনো ত্রুটি পাওয়া যায়নি' লুপ: ব্যবহারকারীরা সমস্যার রিপোর্ট করছেন, কিন্তু সিন্থেটিক চেকগুলো সবুজ (সঠিক) দেখাচ্ছে।
- প্রশমন: সমস্যাটি সম্ভবত ডিভাইস-নির্দিষ্ট বা RF ইন্টারফারেন্স (কো-চ্যানেল ইন্টারফারেন্স বা শারীরিক বাধা) সম্পর্কিত। নির্দিষ্ট ডিভাইসের RSSI এবং রোমিং হিস্ট্রি পরীক্ষা করতে ক্লায়েন্ট-সাইড অ্যানালিটিক্স ব্যবহার করুন।
- ঝুঁকি: ISP অস্বীকার: আপনার প্রমাণ থাকা সত্ত্বেও ISP ত্রুটি স্বীকার করতে অস্বীকার করে।
- প্রশমন: হপ-বাই-হপ পাথ ট্রেস প্রদান করুন যা দেখায় ঠিক কোন IP অ্যাড্রেসে প্যাকেট লস শুরু হচ্ছে। আপনার ডিমার্কেশন পয়েন্ট থেকে ক্লিন ইগ্রেস প্রদর্শনকারী PCAP শেয়ার করুন। সঠিক ডেটা লেভেল ১ সাপোর্টকে অতিক্রম করে বিষয়টি উচ্চতর স্তরে নিয়ে যেতে বাধ্য করে।
- ঝুঁকি: Captive Portal ব্যর্থতা: পোর্টাল লোড হতে ব্যর্থ হলে ব্যবহারকারীরা WiFi-কে দোষারোপ করেন।
- প্রশমন: আইডেন্টিটি প্রোভাইডারকে আলাদা করুন। ইন্টিগ্রেশনের (Microsoft Entra ID, Okta, Google Workspace) স্ট্যাটাস পরীক্ষা করুন। যদি নেটওয়ার্ক প্রি-অথেন্টিকেশন ট্রাফিকের অনুমতি দেয় কিন্তু IdP টাইম আউট হয়, তবে নেটওয়ার্কটি নির্দোষ।
ROI এবং ব্যবসায়িক প্রভাব
MTTI হ্রাস করা কেবল ইঞ্জিনিয়ারিং সময় বাঁচানোর বাইরেও পরিমাপযোগ্য ব্যবসায়িক মূল্য প্রদান করে।
- হ্রাসকৃত MTTR: একটি ঘটনা থেকে ৪০ মিনিটের দোষারোপের পালা বাদ দিলে তা সরাসরি ডাউনটাইম হ্রাস করে, যা retail এবং hospitality পরিবেশে রাজস্ব রক্ষা করে।
- SLA কমপ্লায়েন্স: দ্রুত নির্দোষতা প্রমাণ করা ম্যানেজড WiFi প্রোভাইডারের বিরুদ্ধে অন্যায্য জরিমানা আরোপ করা রোধ করে যখন ত্রুটিটি ISP বা বিল্ডিং অবকাঠামোর সাথে সম্পর্কিত থাকে।
- ক্লায়েন্ট রিটেনশন: মাল্টি-টেন্যান্ট WiFi সেক্টরে, প্রপার্টি ম্যানেজাররা সেইসব প্রোভাইডারদের সাথে চুক্তি নবায়ন করেন যারা স্বচ্ছতা এবং দ্রুত উত্তর প্রদান করে। শেয়ার করা প্রমাণ বিশ্বাস তৈরি করে; আত্মরক্ষামূলক যুক্তি তা ধ্বংস করে।
- রিসোর্স অপ্টিমাইজেশন: উচ্চ বেতনভোগী লেভেল ৩ নেটওয়ার্ক ইঞ্জিনিয়াররা নেটওয়ার্ক সঠিকভাবে কাজ করছে কিনা তা ম্যানুয়ালি প্রমাণ করার পরিবর্তে সমাধান তৈরিতে তাদের সময় ব্যয় করেন।
মূল সংজ্ঞাসমূহ
Mean Time to Innocence (MTTI)
The average time required for a specific IT team to prove, using objective data, that their domain or infrastructure is not the root cause of a reported incident.
Critical for managed WiFi providers who must defend their service against property managers and ISPs.
Mean Time to Identify
The organisation-wide metric tracking the total time elapsed from incident detection to the discovery of the actual root cause.
MTTI is a subset of this metric. Reducing MTTI directly reduces the overall time to identify.
Synthetic Checks
Automated, continuous tests that emulate user traffic (e.g., DNS lookups, HTTP requests) to proactively monitor network health.
Used to prove the WiFi layer was functioning correctly at the exact moment a user complained.
Hop-by-Hop Path Visibility
Telemetry that traces network traffic node-by-node from the client to the destination, measuring latency and loss at each specific router or switch.
Essential for proving a fault lies in an ISP network or a landlord's distribution switch, rather than the managed WiFi hardware.
Flow Data (NetFlow/IPFIX)
Network protocol data that provides a summary of traffic conversations, showing source, destination, protocol, and volume.
Used to prove that specific application traffic is successfully leaving the local network.
On-Demand Packet Capture (PCAP)
The ability to remotely record raw network traffic from an access point or switch for forensic analysis.
The ultimate proof used to demonstrate server-side errors or client device misbehaviour.
Blast Radius
The scope of impact of a specific incident (e.g., one user, one AP, one switch, one tenant, or the entire building).
Determining the blast radius via topology mapping is the fastest way to exclude healthy infrastructure from an investigation.
Event Correlation
The practice of overlaying different data streams (logs, alerts, updates) on a single timeline to identify cause and effect.
Used to prove that a network outage was caused by a third-party change, such as an unannounced ISP maintenance window.
সমাধানকৃত উদাহরণসমূহ
A 350-room hotel reports that in-room WiFi is slow across the entire property. The front desk blames the managed WiFi provider. How do you exonerate the network and find the root cause?
- Check the synthetic probes: DNS and HTTP reachability tests show the APs have a clean connection to the internet. 2. Review the topology map: The issue affects all APs across all switches, ruling out edge hardware. 3. Execute a path trace: The trace shows 2ms latency within the hotel LAN, but 180ms latency at the third hop (the ISP's aggregation router). 4. Export the evidence: Send the path trace screenshot to the hotel manager and the ISP.
A national retailer reports point-of-sale (POS) terminals in one region are dropping connections to the payment processor. The network team is blamed for a firewall or routing misconfiguration.
- Isolate the blast radius: Confirm only POS terminals (specific VLAN) are affected; guest WiFi and back-office systems are healthy. 2. Analyse flow data: NetFlow confirms traffic destined for the payment processor's IP range is successfully leaving the store routers. 3. Capture packets: An on-demand PCAP on the POS VLAN reveals the payment processor's server is sending TCP resets (RST). 4. Share the PCAP with the payment processor's support team.
অনুশীলনী প্রশ্নসমূহ
Q1. A tenant in a coworking space complains they cannot access their corporate VPN. Other tenants are browsing the internet without issue. What is the most efficient way to prove the WiFi network is not at fault?
ইঙ্গিত: Consider the blast radius and the specific type of traffic failing.
মডেল উত্তর দেখুন
First, use the topology map to confirm the blast radius is limited to one user or one specific service, ruling out a general AP or switch failure. Second, analyse flow data (NetFlow/IPFIX) for that client's IP address. If the flow data shows the VPN traffic (e.g., UDP 500 or TCP 443) is leaving the network cleanly, the WiFi and LAN are innocent. The issue is either the client's VPN configuration or the corporate firewall blocking the connection.
Q2. Your monitoring dashboard shows an AP has gone offline, but the property manager insists the WiFi is broken because the ISP is down. How do you prove the issue is internal power, not the ISP?
ইঙ্গিত: Look for correlation between infrastructure state and external events.
মডেল উত্তর দেখুন
Use event correlation and topology mapping. If the topology map shows only one AP is offline while others on the same switch are functioning, the ISP circuit is clearly active. Event correlation might show a PoE (Power over Ethernet) failure log from the switch port connected to that specific AP. This proves the issue is local hardware or cabling, not the WAN circuit.
Q3. A stadium operations director claims the WiFi failed during halftime because ticket scanners stopped working. You need to exonerate the network in under two minutes. What telemetry do you use?
ইঙ্গিত: You need historical proof of health at the exact moment of the reported failure.
মডেল উত্তর দেখুন
Pull the historical data from the continuous synthetic checks. Show the operations director the dashboard confirming that during the exact 15-minute halftime window, the APs were successfully resolving DNS and reaching the ticketing server's IP address with low latency. This immediately proves the wireless network was healthy and shifts the investigation to the ticketing application servers, which likely buckled under the sudden load.
এই সিরিজে পড়া চালিয়ে যান
SCEP-এর জন্য এন্টারপ্রাইজ গাইড: স্বয়ংক্রিয় ক্যাম্পাস WiFi সুরক্ষার জন্য সিম্পল সার্টিফিকেট এনরোলমেন্ট প্রোটোকল স্থাপন করা
এই টেকনিক্যাল রেফারেন্স গাইডটি SCEP ব্যবহার করে এন্টারপ্রাইজ WiFi সার্টিফিকেট স্থাপনের জন্য একটি সুনির্দিষ্ট আর্কিটেকচারাল ব্লুপ্রিন্ট এবং ধাপে ধাপে বাস্তবায়ন কৌশল প্রদান করে। এটি SCEP এবং PKCS-এর মধ্যে গুরুত্বপূর্ণ পার্থক্য, সফলতার জন্য প্রয়োজনীয় সঠিক স্থাপনার ক্রম এবং আইটি লিডারদের জন্য বাস্তব-জগতের ঝুঁকি প্রশমন কৌশলগুলো কভার করে।
কেন আমার গেস্ট WiFi কানেক্ট হচ্ছে না? Captive Portal-এর সমস্যা সমাধান করা
এই নির্ভরযোগ্য প্রযুক্তিগত রেফারেন্স নির্দেশিকাটি Captive Portal সনাক্তকরণের অন্তর্নিহিত মেকানিজম ব্যাখ্যা করে এবং গেস্ট WiFi কানেক্ট হতে বাধা দেওয়া ছয়টি প্রাথমিক ফেইলিউর মোড বিস্তারিতভাবে আলোচনা করে। এটি আইটি ম্যানেজার এবং নেটওয়ার্ক আর্কিটেক্টদের HTTP রিডাইরেক্ট সমস্যা, DNS দ্বন্দ্ব এবং MAC র্যান্ডমাইজেশন চ্যালেঞ্জগুলি সমাধান করার জন্য একটি ব্যবহারিক ট্রাবলশুটিং ফ্রেমওয়ার্ক প্রদান করে।
স্বয়ংক্রিয় WiFi সার্টিফিকেট এনরোলমেন্টের জন্য কীভাবে SCEP বাস্তবায়ন করবেন
এই নির্দেশিকাটি ব্যাখ্যা করে যে কীভাবে এন্টারপ্রাইজ ভেন্যু জুড়ে স্বয়ংক্রিয় WiFi সার্টিফিকেট এনরোলমেন্টের জন্য SCEP (Simple Certificate Enrollment Protocol) বাস্তবায়ন করা যায়। এটি সম্পূর্ণ আর্কিটেকচারাল ব্লুপ্রিন্ট কভার করে - PKI ডিজাইন এবং MDM ইন্টিগ্রেশন থেকে শুরু করে বাধ্যতামূলক তিন-ধাপের ডেপ্লয়মেন্ট সিকোয়েন্স পর্যন্ত - এবং IT ম্যানেজার ও নেটওয়ার্ক আর্কিটেক্টদের দেখায় কীভাবে শেয়ার্ড ক্রেডেনশিয়াল দূর করা যায়, সার্টিফিকেট লাইফসাইকেল ম্যানেজমেন্ট স্বয়ংক্রিয় করা যায় এবং স্কেলে PCI DSS এবং GDPR প্রয়োজনীয়তা পূরণ করা যায়।