¿Por qué nuestro WiFi de invitados es tan lento? Diagnóstico de la congestión de red
Esta guía diagnostica los factores ocultos de la congestión del WiFi de invitados (telemetría en segundo plano, redes de anuncios programáticos y actualizaciones automáticas del sistema operativo), que en conjunto consumen hasta el 40% del ancho de banda del WiFi público antes de que un invitado abra siquiera un navegador. Ofrece un marco de implementación por fases y neutro respecto al proveedor para filtrado DNS y políticas de QoS que recuperan ese ancho de banda, mejoran la experiencia del invitado y ofrecen un ROI medible. Dirigido a Directores de TI y Gerentes de Operaciones en los sectores de hospitalidad, retail, eventos y entornos del sector público.
Escucha esta guía
Ver transcripción del podcast
📚 Parte de nuestra serie principal: Guest WiFi Guide →
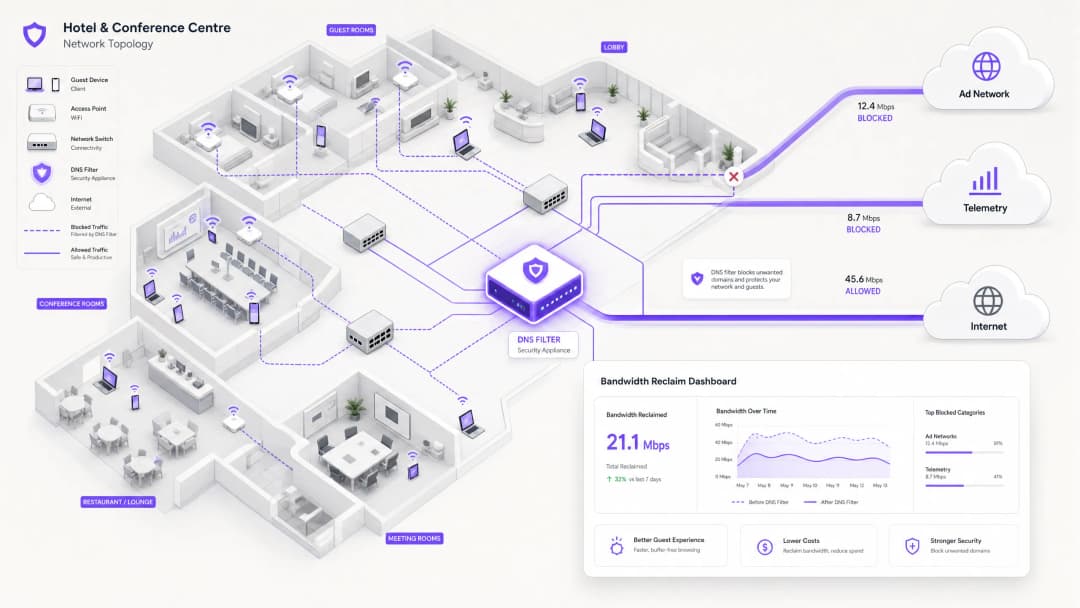
Executive Summary
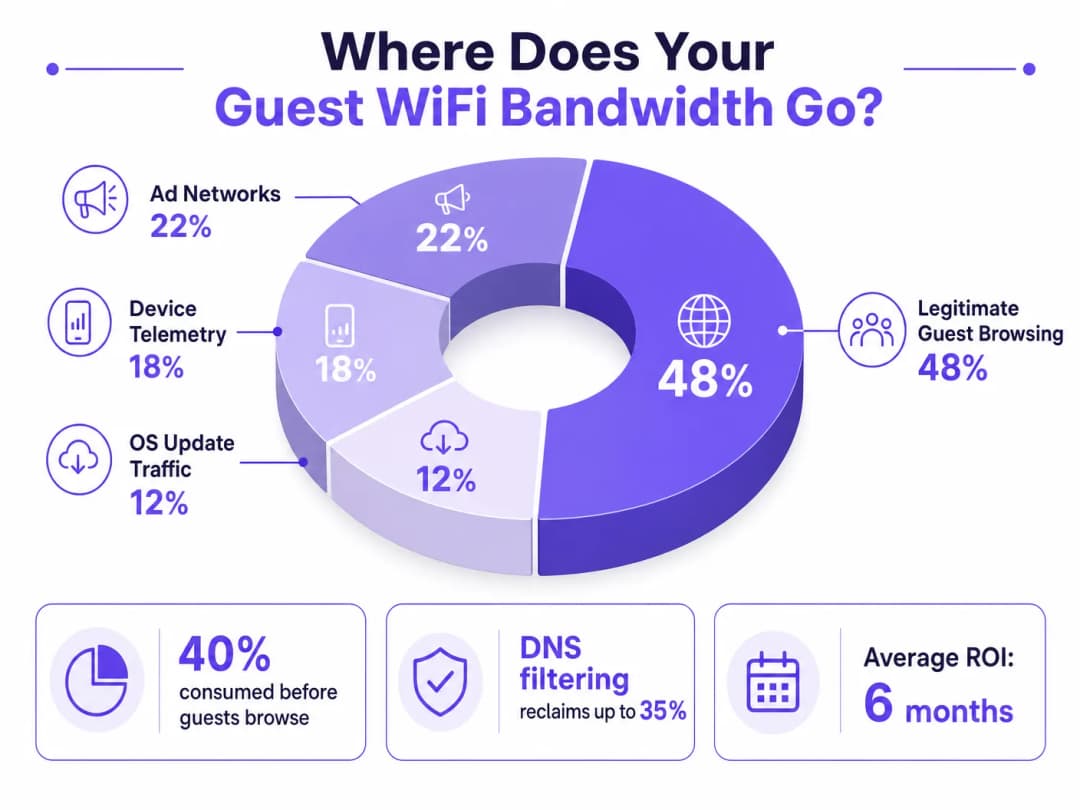
For IT Directors and Operations Managers overseeing high-density venues, ensuring a reliable Guest WiFi experience is a constant battle against network congestion. While legacy approaches focus on increasing overall bandwidth or deploying additional access points, the root cause of slow throughput often lies not in legitimate user traffic, but in the hidden layer of background data. In modern environments — from sprawling Hospitality complexes to high-footfall Retail spaces — up to 40% of public WiFi bandwidth is consumed by device telemetry, programmatic ad networks, and automated OS updates before a guest even opens a browser.
This technical reference guide provides a definitive methodology for diagnosing this congestion and implementing strategic mitigation. By deploying network-level DNS filtering and Response Policy Zones (RPZ), enterprise network architects can reclaim significant bandwidth, reduce latency, and dramatically improve the end-user experience without incurring the capital expenditure of infrastructure upgrades. We will explore the technical architecture of these solutions, real-world implementation case studies, and the measurable ROI of reclaiming your network.
Technical Deep-Dive
The Anatomy of Background Congestion
When a guest device authenticates to a public network, it immediately initiates a barrage of background connections. These connections are primarily driven by three categories of traffic that, in aggregate, constitute what network engineers call the phantom load — bandwidth consumed by the network before any deliberate guest activity occurs.
1. Device Telemetry and Analytics
Modern operating systems (iOS, Android, Windows) and installed applications constantly transmit usage data, location metrics, crash reports, and behavioural analytics to remote servers. In a dense environment such as a Transport hub or conference centre, thousands of devices simultaneously transmitting small but frequent telemetry payloads can exhaust available wireless airtime and overwhelm NAT tables. A single iOS device can generate upwards of 200 distinct background DNS queries within the first 60 seconds of connecting to an unmetered network.
2. Programmatic Ad Networks
Many free applications rely on programmatic advertising ecosystems. The moment a device detects an unmetered WiFi connection, these apps begin pre-fetching video ads, high-resolution display banners, and tracking scripts from ad exchange platforms. This traffic is both high-bandwidth and latency-sensitive, and it will aggressively compete for airtime with legitimate guest browsing. Analysis of public venue networks consistently shows that programmatic ad traffic accounts for 15–22% of total WAN utilisation during peak hours.
3. Automated OS and Application Updates
Without proper traffic shaping, devices will attempt to download large OS patches and application updates as soon as they detect an unmetered WiFi connection. A single iOS major update can be 3–5 GB. In a 500-device environment, a simultaneous update trigger — common when a new OS version is released — can saturate even a 1 Gbps WAN link within minutes.
Why Traditional Approaches Fall Short
The conventional response to guest WiFi congestion is to increase WAN bandwidth or deploy additional access points. While both measures have their place, neither addresses the phantom load. Adding more bandwidth simply provides more capacity for background traffic to consume. Deep Packet Inspection (DPI), the other traditional tool, is increasingly ineffective: the widespread adoption of TLS 1.3 and end-to-end encryption means that the majority of traffic payloads are opaque to inspection engines. You cannot throttle what you cannot classify.
For a broader discussion of how wireless frequencies interact with high-density deployments, see our guide on Wi-Fi Frequencies: A Guide to Wi-Fi Frequencies in 2026 .
DNS Filtering: The Efficient Countermeasure
The modern, scalable solution is DNS filtering at the network edge. Rather than inspecting traffic payloads, DNS filtering operates at the resolution layer — preventing connections from being established in the first place.
When a device requests access to a known ad network or telemetry domain, the DNS resolver checks the request against a Response Policy Zone (RPZ). If the domain appears in the blocklist, the resolver returns an NXDOMAIN (Non-Existent Domain) response, or sinkholes the traffic to a local null IP address. The connection is terminated before the TCP handshake occurs, preserving both wireless airtime and WAN bandwidth. This approach is computationally inexpensive, scales linearly with resolver capacity, and is unaffected by payload encryption.

The Security Dimension
DNS filtering delivers a significant secondary benefit: security. By blocking known malware Command and Control (C2) domains, phishing infrastructure, and exploit kit delivery networks at the DNS layer, the guest network becomes substantially more defensible. This is directly relevant to compliance obligations under frameworks such as PCI DSS (which requires network segmentation and monitoring for cardholder data environments) and GDPR (which mandates appropriate technical measures to protect personal data). For a detailed treatment of audit trail requirements in this context, see Explain what is audit trail for IT Security in 2026 .
For organisations managing educational environments where ad blocking also serves a safeguarding function, the principles covered in Minimising Student Distractions with Network-Level Ad Blocking are directly applicable.
Implementation Guide
Deploying a robust DNS filtering architecture requires careful planning to avoid disrupting legitimate guest services. The implementation should follow a phased approach.
Phase 1: Baseline Assessment and Visibility
Before implementing any blocks, establish a baseline of current traffic patterns. Utilise WiFi Analytics to identify the top bandwidth-consuming domains and categories over a representative 7–14 day period. This audit phase is critical for understanding the specific traffic profile of your venue and for building the business case for the investment. Key metrics to capture include:
| Metric | Target Baseline | Notes |
|---|---|---|
| Top 20 DNS domains by query volume | Full list | Identify telemetry and ad domains |
| WAN utilisation by category | % split | Quantify the phantom load |
| Peak concurrent device count | Number | Size resolver infrastructure |
| DNS query failure rate | < 0.1% | Establish pre-deployment benchmark |
Phase 2: Staged RPZ Deployment
Begin by deploying the RPZ in log-only mode. This allows you to verify the accuracy of your blocklists without impacting the user experience. Focus on high-confidence categories first:
- Known Malware and C2 Domains: Immediate security benefit with near-zero risk of false positives. Use threat intelligence feeds from reputable providers.
- High-Bandwidth Programmatic Ad Networks: Target the major video ad exchange platforms. These are well-documented and unlikely to host legitimate content.
- Aggressive Telemetry Endpoints: Block non-essential tracking domains. Maintain a careful allow-list for domains required for captive portal authentication flows.
Once log-only mode confirms acceptable false positive rates (target < 0.5% of queries), move to enforcement mode.
Phase 3: Traffic Shaping and QoS Integration
For traffic that cannot be outright blocked (e.g., OS updates from Apple, Microsoft, and Google), implement Quality of Service (QoS) policies. Rate-limit update servers to a defined ceiling — typically 10–15% of total WAN capacity — ensuring that interactive guest traffic (web browsing, VoIP, video conferencing) receives priority queuing. This is particularly important for Healthcare environments where clinical staff may share a network segment with guests.
For guidance on optimising broader network environments, including office and mixed-use deployments, see Office Wi-Fi: Optimize Your Modern Office Wi-Fi Network .
Best Practices
Maintain Explicit Allow-lists for Critical Services. Ensure that domains essential for captive portal authentication, payment gateways (PCI DSS compliance), and core venue operations are explicitly permitted. A misconfigured blocklist that breaks the login flow will generate immediate and significant support load.
Communicate the Policy Transparently. Your Terms of Service should state that network traffic is managed to ensure a high-quality experience for all users. This is both a legal best practice under GDPR and a reasonable expectation-setting measure for guests.
Automate Blocklist Updates. The landscape of ad networks and telemetry domains shifts constantly. Threat intelligence feeds and RPZ lists must be updated dynamically — ideally on a sub-24-hour cycle — to remain effective.
Address DNS Evasion Proactively. Implement firewall rules to intercept and redirect all outbound port 53 (UDP and TCP) traffic to the local resolver. This prevents clients from bypassing filtering by hardcoding external DNS servers.
Plan for DNS over HTTPS (DoH). As DoH adoption increases, clients may route DNS queries over HTTPS to bypass local resolvers entirely. Evaluate whether to block known DoH providers (e.g., dns.google, cloudflare-dns.com) or to deploy a transparent DoH proxy that enforces local policy.
Align with IEEE 802.1X and WPA3. Ensure that your DNS filtering architecture is compatible with your authentication framework. In environments using IEEE 802.1X with RADIUS-based authentication, DNS filtering policies can be applied per VLAN or per user group, enabling granular control.
Troubleshooting & Risk Mitigation
Common Failure Modes
| Failure Mode | Symptom | Mitigation |
|---|---|---|
| Over-blocking (CDN collision) | Broken webpages, missing images | Granular blocklists; rapid allow-listing process |
| DNS evasion (hardcoded resolvers) | Filtering bypassed by specific apps | Firewall redirect rules for port 53 |
| DoH bypass | Filtering bypassed by modern browsers | Block known DoH providers or deploy DoH proxy |
| Resolver performance bottleneck | Increased DNS latency across all clients | Scale resolver infrastructure; implement anycast |
| Captive portal breakage | Guests cannot authenticate | Explicit allow-list for portal domains and OS detection endpoints |
| Stale blocklists | New ad domains not blocked | Automate feed updates; monitor query logs for new high-volume domains |
Security Incident Response
If a guest device is identified as communicating with a known malware C2 domain (visible in DNS query logs), the RPZ will automatically block further communication. Ensure your incident response process includes a workflow for reviewing these events, as they may indicate a compromised device that requires isolation from the guest VLAN.
ROI & Business Impact
Implementing network-level DNS filtering delivers measurable, quantifiable business outcomes across multiple dimensions.
Bandwidth Reclamation and CapEx Deferral. Venues typically reclaim 20–40% of their total WAN bandwidth. This directly translates to cost savings by deferring the need for expensive circuit upgrades. For a venue currently paying for a 500 Mbps leased line, reclaiming 30% of capacity is equivalent to gaining 150 Mbps of effective throughput at zero additional cost.
Improved Guest Satisfaction and NPS. By eliminating background congestion, the perceived speed and reliability of the Guest WiFi improves dramatically. Reduced latency and consistent throughput lead to higher Net Promoter Scores and fewer operational support escalations.
Enhanced Security and Compliance Posture. Blocking malware and phishing domains at the DNS layer significantly reduces the risk of a security breach originating from the guest network. This directly supports compliance with PCI DSS network segmentation requirements and GDPR's obligation to implement appropriate technical security measures.
Operational Efficiency. Automated DNS filtering reduces the manual workload on network operations teams. Rather than reactively responding to congestion events, the network proactively manages its own traffic profile.
| Outcome | Typical Range | Measurement Method |
|---|---|---|
| Bandwidth reclaimed | 20–40% of WAN capacity | Before/after WAN utilisation monitoring |
| DNS query block rate | 15–35% of all queries | Resolver query logs |
| Guest satisfaction improvement | +8–15 NPS points | Post-stay/post-visit surveys |
| CapEx deferral | 1–3 years on circuit upgrade | Cost modelling |
| Security incident reduction | 40–60% fewer C2 detections | SIEM correlation |
By treating the network not just as a pipe, but as an intelligent, filtered gateway, IT leaders can deliver a superior, secure, and cost-effective connectivity experience — one that scales with venue growth without proportional infrastructure investment.
Definiciones clave
Zona de política de respuesta (RPZ)
Un mecanismo en los servidores DNS que permite la modificación de las respuestas de DNS en función de una política definida. Cuando un dominio consultado coincide con una entrada en la RPZ, el resolutor puede devolver una respuesta sintética (por ejemplo, NXDOMAIN o una IP de sinkhole) en lugar de la respuesta real.
El mecanismo técnico principal para implementar el filtrado de DNS en toda la red. Los equipos de TI configuran las RPZ en sus resolutores internos para bloquear redes de anuncios, dominios de malware y endpoints de telemetría sin requerir software en el lado del cliente.
Inspección profunda de paquetes (DPI)
Una forma de filtrado de paquetes de red que examina la carga útil de datos de un paquete a medida que pasa por un punto de inspección, buscando el incumplimiento de protocolos, contenido específico o criterios definidos.
Utilizada tradicionalmente para la clasificación y el modelado de tráfico. Cada vez más limitada por la adopción generalizada del cifrado de extremo a extremo TLS 1.3, que hace que las cargas de pago sean opacas. El filtrado de DNS es la alternativa preferida para entornos de tráfico cifrado.
NXDOMAIN
Un código de respuesta de DNS (RCODE 3) que indica que el nombre de dominio consultado no existe en el espacio de nombres de DNS.
Devuelto por un resolutor de filtrado de DNS para bloquear intencionalmente una conexión a un dominio no deseado. La aplicación cliente recibe esta respuesta y abandona el intento de conexión, evitando que se consuma ancho de banda.
DNS sobre HTTPS (DoH)
Un protocolo para realizar la resolución de DNS a través del protocolo HTTPS (RFC 8484), cifrando las consultas y respuestas de DNS entre el cliente y un resolutor compatible con DoH.
Puede eludir el filtrado de DNS de la red local si los clientes están configurados para usar proveedores de DoH externos. Los administradores de red deben implementar reglas de firewall o redirigir el tráfico DoH a través de un proxy para hacer cumplir las políticas de RPZ locales.
Calidad de Servicio (QoS)
Un conjunto de mecanismos de red que controlan la priorización del tráfico, la limitación de velocidad y la asignación de colas para garantizar el rendimiento de las aplicaciones críticas.
Se utiliza junto con el filtrado de DNS para gestionar el tráfico legítimo pero de gran ancho de banda (por ejemplo, actualizaciones del sistema operativo) que no se puede bloquear. QoS garantiza que el tráfico interactivo de los invitados reciba prioridad sobre las transferencias masivas en segundo plano.
Telemetría
La recopilación y transmisión automatizada de datos operativos desde los dispositivos a servidores remotos para su monitoreo, análisis y diagnóstico.
En el contexto de WiFi para invitados, la telemetría de dispositivos de sistemas operativos móviles y aplicaciones puede consumir silenciosamente entre el 15 y el 20% del ancho de banda disponible. Es un objetivo principal para el filtrado de DNS en implementaciones de redes públicas.
Sinkholing de DNS
Una técnica en la que se configura un servidor DNS para devolver una dirección IP falsa (normalmente una dirección nula local) para dominios específicos, redirigiendo el tráfico lejos de su destino original.
Se utiliza para neutralizar el tráfico C2 de malware y bloquear de forma agresiva las redes de anuncios de gran ancho de banda. Es más definitivo que las respuestas NXDOMAIN, ya que permite al servidor sinkhole registrar los intentos de conexión para el análisis de seguridad.
Equidad de tiempo de aire (Airtime Fairness)
Una función de red inalámbrica que asigna el mismo acceso al medio inalámbrico a todos los clientes conectados, independientemente de sus velocidades de datos individuales.
Crítico en entornos de alta densidad. Sin la equidad de tiempo de aire, un solo dispositivo lento (por ejemplo, un cliente 802.11g antiguo) puede consumir de manera desproporcionada el tiempo de aire, degradando el rendimiento para todos los demás clientes. El tráfico de telemetría en segundo plano de muchos dispositivos agrava este efecto.
Carga fantasma (Phantom Load)
Ancho de banda consumido por procesos automatizados en segundo plano en dispositivos conectados antes de que ocurra cualquier actividad deliberada del usuario.
El término colectivo para la telemetría, la precarga de redes de anuncios y el tráfico de actualización del sistema operativo. Comprender y cuantificar la carga fantasma es el primer paso en cualquier diagnóstico de congestión de WiFi para invitados.
Ejemplos resueltos
Un hotel resort de 400 habitaciones está experimentando una congestión de red severa todas las noches entre las 7:00 PM y las 10:00 PM. El enlace WAN de 1 Gbps está saturado y los huéspedes se quejan de un streaming lento y llamadas VoIP caídas. El Director de TI necesita identificar la causa raíz e implementar una solución sin actualizar el circuito.
Paso 1 — Análisis de Tráfico: Desplegar un analizador de flujo de red (NetFlow/IPFIX) en el router principal y ejecutarlo durante 5 días abarcando períodos pico y fuera de pico. Correlacionar con los registros de consultas DNS del sistema de resolución existente. El análisis revela que el 35% del tráfico nocturno se destina a redes de anuncios de video programáticos conocidos (DoubleClick, AppNexus) y servidores de actualizaciones automáticas de aplicaciones (Apple Software Update, Google Play). La navegación legítima de los huéspedes representa solo el 52% del tráfico total.
Paso 2 — Despliegue de Filtrado DNS: Configurar el firewall principal para redirigir todas las consultas DNS de la VLAN de huéspedes (puerto UDP/TCP 53) a un sistema de resolución local con RPZ habilitado. Importar una lista de bloqueo curada que cubra las redes de anuncios y dominios de telemetría identificados. Ejecutar en modo de solo registro durante 48 horas para validar las tasas de falsos positivos.
Paso 3 — Aplicación de Políticas: Después de validar una tasa de falsos positivos por debajo del 0.3%, cambiar al modo de aplicación. Simultáneamente, implementar una política de QoS que limite la velocidad de los servidores de actualización de Apple y Google a un límite combinado de 80 Mbps durante la ventana de 6 PM a 11 PM.
Paso 4 — Validación: Monitorear la utilización de WAN durante los siguientes 7 días. La utilización pico disminuye del 98% al 61%, resolviendo las quejas de los huéspedes. El hotel pospone una actualización de circuito planificada por un tiempo estimado de 18 meses.
Un gran centro de conferencias alberga una cumbre tecnológica con 5,000 asistentes. Durante la conferencia principal, la red WiFi queda completamente inutilizable. El análisis posterior al incidente muestra que miles de dispositivos intentaron descargar simultáneamente una actualización importante de iOS que se lanzó esa mañana.
Mitigación Inmediata (Día del Evento): El equipo de operaciones de red identifica el pico mediante el monitoreo de consultas DNS en tiempo real. Inmediatamente aplican un agujero negro (sinkhole) a los dominios específicos de actualización de software de Apple (mesu.apple.com, appldnld.apple.com, updates.cdn-apple.com) a nivel de DNS. En 4 minutos, la utilización de WAN disminuye del 99% al 68% y la red se estabiliza.
Solución a Corto Plazo (Mismo Evento): Se aplica una política de QoS para limitar la velocidad de todo el tráfico de actualización restante a 50 Mbps durante la duración del evento.
Estrategia a Largo Plazo (Post-Evento): El equipo de red implementa una política de QoS dinámica que se activa automáticamente cuando la utilización total de WAN supera el 75%, limitando los servidores de actualización conocidos al 10% de la capacidad total. Se crea una lista de verificación previa al evento que incluye el bloqueo temporal (sinkhole) de los principales dominios de actualización durante las 2 horas previas y posteriores a las sesiones de alto perfil. El equipo también se suscribe a los canales de notificación de lanzamientos de actualizaciones de Apple y Microsoft para anticipar futuros picos de tráfico.
Preguntas de práctica
Q1. Usted es el Gerente de TI de una cadena de retail nacional. Después de implementar una solución de filtrado DNS en 50 tiendas, varios gerentes de tienda informan que la página de inicio de sesión del Captive Portal no se carga para los invitados. El equipo de soporte está recibiendo un alto volumen de llamadas. ¿Cuál es la causa más probable y cuál es el paso de remediación inmediato?
Sugerencia: Considere la cadena de dependencias completa de un flujo de autenticación de un Captive Portal moderno, incluyendo los mecanismos de detección de Captive Portal a nivel de sistema operativo.
Ver respuesta modelo
La causa más probable es un bloqueo excesivo. El filtro DNS está bloqueando un dominio requerido para que funcione el Captive Portal. Los sistemas operativos móviles modernos utilizan dominios específicos para detectar Captive Portals (por ejemplo, captive.apple.com para iOS, connectivitycheck.gstatic.com para Android). Si estos están bloqueados, el sistema operativo no activará el navegador del Captive Portal y el invitado no verá ninguna pantalla de inicio de sesión. Además, el portal en sí puede depender de una CDN o de un proveedor de autenticación de terceros (por ejemplo, inicio de sesión social a través de Facebook o Google) cuyos dominios están bloqueados inadvertidamente.
Remediación inmediata: Revise los registros de consultas DNS para identificar respuestas NXDOMAIN originadas en la subred de invitados durante la fase de autenticación. Identifique todos los dominios bloqueados que se consultan antes de un inicio de sesión exitoso. Agregue estos dominios a la lista de permitidos global. Implemente una plantilla estándar de lista de permitidos para implementaciones de Captive Portal que incluya todos los endpoints principales de detección de sistemas operativos y los dominios de proveedores de autenticación comunes.
Q2. Un arquitecto de red de un estadio nota que, a pesar de implementar un filtrado DNS agresivo, la utilización de la WAN sigue siendo críticamente alta durante los partidos. Una investigación más profunda revela un alto volumen sostenido de tráfico en el puerto UDP 443 que no se correlaciona con ningún dominio bloqueado en los registros DNS. ¿Qué está sucediendo y cómo debe abordarse?
Sugerencia: Considere los protocolos de transporte modernos y cómo interactúan con los controles a nivel de DNS.
Ver respuesta modelo
El alto volumen de tráfico UDP 443 indica el uso de QUIC (HTTP/3). QUIC es un protocolo de transporte basado en UDP utilizado por las principales plataformas (Google, Meta, YouTube) que evade los proxies tradicionales basados en TCP y los motores DPI. De manera más crítica, los clientes que usan QUIC también pueden estar utilizando DNS sobre HTTPS (DoH) para resolver dominios, evadiendo por completo el resolutor RPZ local y haciendo que el filtrado DNS sea ineficaz para esos clientes.
Para abordar esto: Primero, implemente reglas de firewall para bloquear el tráfico DoH saliente hacia proveedores de DoH públicos conocidos (Google, Cloudflare, NextDNS) en el puerto TCP/UDP 443 por IP de destino, obligando a los clientes a recurrir al resolutor local. Segundo, evalúe bloquear por completo el puerto UDP 443 saliente (o limitar su velocidad de manera agresiva) para obligar a los clientes QUIC a recurrir a HTTP/2 basado en TCP, el cual está sujeto a las políticas de gestión de tráfico existentes. Tercero, revise si se puede implementar un proxy DoH transparente para interceptar e inspeccionar las consultas DoH mientras se aplican las políticas RPZ locales.
Q3. Usted está diseñando una política de QoS para la red WiFi de invitados de un gran hospital público. La red se comparte entre dispositivos de entretenimiento de pacientes, dispositivos personales de visitantes y un pequeño número de personal clínico que utiliza softphones VoIP en sus dispositivos móviles personales. Priorice los siguientes tipos de tráfico: VoIP (SIP/RTP), Navegación Web de Invitados (HTTP/HTTPS), Actualizaciones de Windows/iOS y Streaming de Video (Netflix/YouTube).
Sugerencia: Considere tanto la sensibilidad a la latencia como el impacto comercial/clínico de cada tipo de tráfico. Considere también el contexto regulatorio de un entorno de atención médica.
Ver respuesta modelo
Prioridad 1 — VoIP (SIP/RTP): Cola de prioridad estricta (Expedited Forwarding, DSCP EF). VoIP es altamente sensible a la latencia (objetivo < 150 ms unidireccional) y al jitter (objetivo < 30 ms). Una pérdida de paquetes superior al 1% causa una degradación audible. En un contexto clínico, una llamada caída podría tener implicaciones para la seguridad del paciente.
Prioridad 2 — Navegación Web de Invitados (HTTP/HTTPS): Assured Forwarding (AF31). Este es el caso de uso principal esperado tanto para pacientes como para visitantes. Requiere una capacidad de respuesta razonable, pero tolera una latencia moderada.
Prioridad 3 — Streaming de Video (Netflix/YouTube): Velocidad limitada por cliente (por ejemplo, límite de 3 a 5 Mbps) con Assured Forwarding (AF21). Aunque es importante para la experiencia del paciente durante estancias largas, el streaming sin límite saturará el enlace. Un límite por cliente garantiza un acceso equitativo. Considere políticas de horario que flexibilicen los límites durante las horas de menor actividad.
Prioridad 4 — Actualizaciones de OS/Apps (Clase Scavenger, DSCP CS1): La prioridad más baja, cola de mejor esfuerzo, con un límite de velocidad agregado (por ejemplo, 50 Mbps en total para todo el tráfico de actualización). Estas son tareas en segundo plano sin sensibilidad a la latencia. Solo deben consumir la capacidad sobrante. En un entorno de atención médica, considere también si la red de invitados está completamente aislada de los sistemas clínicos; de lo contrario, la gestión del tráfico de actualización se convierte en un problema de seguridad además de uno de ancho de banda.
Continúe leyendo esta serie
Cisco Catalyst WLC y WiFi de invitados: configuración de Captive Portal con Purple
Cómo funciona un controlador de LAN inalámbrica Cisco Catalyst 9800 (IOS-XE) con el WiFi de invitados de Purple: autenticación web externa, RADIUS y un walled garden, con un enlace a la guía de configuración paso a paso de Purple para la configuración exacta.
La guía empresarial para configurar WiFi de invitados: seguridad, segmentación y velocidad
Esta guía técnica empresarial proporciona instrucciones prácticas para gerentes de TI y arquitectos de red sobre cómo implementar un WiFi de invitados seguro y segmentado. Cubre la arquitectura de VLAN, el cifrado WPA3, la autenticación 802.1X, el cumplimiento de PCI DSS y GDPR, y la integración de la capa de Captive Portal de Purple, que es independiente del hardware.
WiFi para personal vs. WiFi para invitados: mejores prácticas para la segmentación de redes corporativas
Una guía técnica completa para líderes de TI sobre la segmentación de redes WiFi para personal e invitados. Cubre la arquitectura VLAN, la autenticación 802.1X, las políticas de firewall y el impacto empresarial del diseño de redes seguras.