Las 10 principales causas de tiempos de espera de DHCP (DHCP Timeouts) en redes inalámbricas de alta densidad
Esta guía de referencia técnica autorizada identifica las diez principales causas de los tiempos de espera de DHCP en redes inalámbricas de alta densidad y proporciona estrategias de remediación prácticas y neutrales respecto al proveedor. Diseñada para líderes de TI sénior, arquitectos de redes y directores de operaciones de recintos, cubre principios de ingeniería a profundidad, flujos de trabajo de implementación paso a paso y resultados comerciales medibles. Aprenda a eliminar los cuellos de botella de conexión y optimice su infraestructura inalámbrica para ofrecer una conectividad sin interrupciones en entornos empresariales exigentes.
Escucha esta guía
Ver transcripción del podcast
Resumen Ejecutivo
En los entornos empresariales modernos —como hoteles de gran capacidad, centros comerciales, hubs de transporte y estadios— la conectividad inalámbrica es un motor de negocio fundamental. Sin embargo, la experiencia del huésped suele fallar en el primer paso de la incorporación a la red: la obtención de una dirección IP. En las redes WiFi de alta densidad, los tiempos de espera agotados (timeouts) de DHCP son una de las causas principales más comunes pero peor diagnosticadas del fallo de incorporación. Cuando cientos o miles de dispositivos intentan conectarse simultáneamente, las configuraciones tradicionales de DHCP fallan bajo la carga, dejando a los usuarios atrapados con un icono de carga giratorio o con una dirección de enlace local 169.254.x.x autoasignada.
Esta guía de referencia técnica autorizada analiza las diez causas principales de los timeouts de DHCP en redes WiFi de alta densidad. Va más allá de la teoría académica para ofrecer a los arquitectos de redes sénior, directores de tecnología (CTOs) y directores de operaciones de recintos estrategias de remediación inmediatas y prácticas. Al optimizar sistemáticamente los tamaños de ámbito de DHCP, reducir los tiempos de concesión (lease times), implementar configuraciones sólidas de Capa 2/3 y desplegar arquitecturas de servidor de alta disponibilidad, las organizaciones pueden reducir significativamente la latencia de conexión, eliminar la fricción de incorporación y proteger la reputación de su marca. La implementación de estas mejores prácticas se correlaciona directamente con una mejor satisfacción del huésped, una mayor interacción con productos principales como Guest WiFi y una captura de datos más rica a través de WiFi Analytics .
Análisis Técnico Detallado
Para diagnosticar y resolver los timeouts de DHCP, los ingenieros de redes deben comprender primero la mecánica precisa del saludo de cuatro vías de DHCP, comúnmente denominado proceso DORA (Discover, Offer, Request, Acknowledge) [1]. En entornos de alta densidad, este proceso es sumamente sensible a la pérdida de paquetes, la latencia y el agotamiento de recursos.
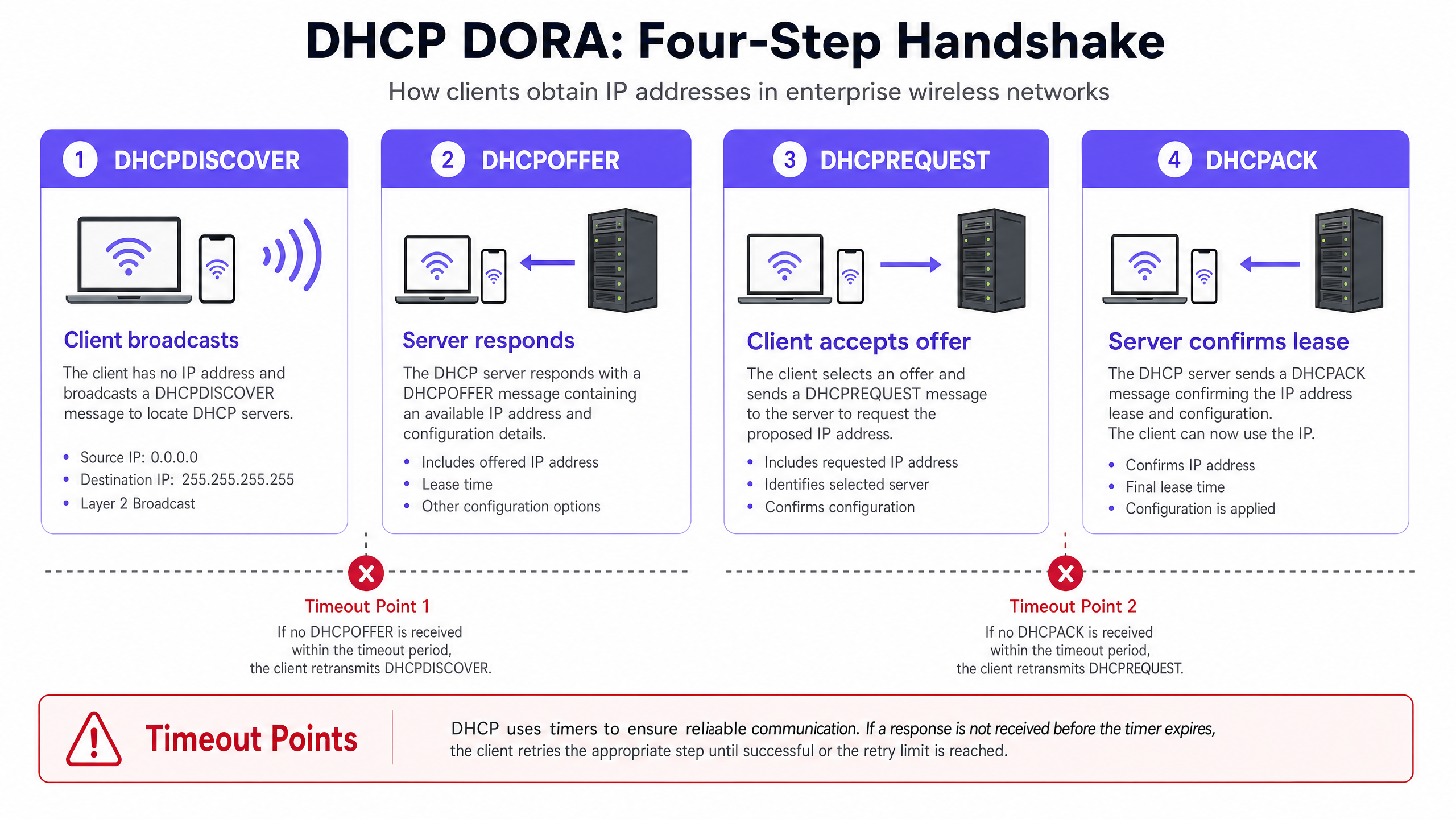
El Saludo DHCP (DORA) en WiFi de Alta Densidad
- DHCPDISCOVER (Broadcast): El cliente inalámbrico se asocia con el Punto de Acceso (AP) y transmite un paquete por difusión para localizar los servidores DHCP disponibles. En un dominio de difusión grande, este paquete se inunda en todos los puertos, consumiendo valioso tiempo de transmisión inalámbrica.
- DHCPOFFER (Unicast/Broadcast): Cada servidor DHCP activo que recibe el mensaje de descubrimiento reserva una dirección IP y envía una oferta al cliente, especificando los parámetros de concesión, la máscara de subred, la puerta de enlace predeterminada y los servidores DNS.
- DHCPREQUEST (Broadcast): El cliente selecciona una oferta (normalmente la primera recibida) y transmite una solicitud por difusión para aceptar esa dirección IP específica, rechazando implícitamente cualquier otra oferta.
- DHCPACK (Unicast/Broadcast): El servidor DHCP seleccionado registra la concesión en su base de datos y envía una confirmación al cliente, validando la asignación de la IP y la duración de la concesión. Luego, el cliente aplica esta configuración.
El impacto de la sobrecarga inalámbrica y la congestión del tiempo de aire (Airtime)
A diferencia de las redes cableadas donde las transmisiones de Capa 2 se gestionan por hardware a velocidades de gigabit, las redes inalámbricas transmiten tramas de broadcast y multicast a la tasa de datos obligatoria más baja (a menudo 1 Mbps, 6 Mbps o 11 Mbps, según la configuración del SSID) para asegurar que todos los clientes distantes puedan recibirlas [2]. En un SSID de alta densidad con miles de dispositivos activos, los paquetes DHCP de broadcast consumen una cantidad desproporcionada de tiempo de aire de RF, lo que provoca colisiones de paquetes, retransmisiones y eventuales tiempos de espera (timeouts). Un dispositivo cliente normalmente espera una respuesta DHCP dentro de 2 a 4 segundos; si la congestión del tiempo de aire retrasa cualquier paso del proceso DORA más allá de este intervalo, el cliente agota el tiempo de espera, interrumpe la asociación y vuelve a intentarlo, generando una carga en cascada en la red.
Las 10 causas principales de los timeouts de DHCP
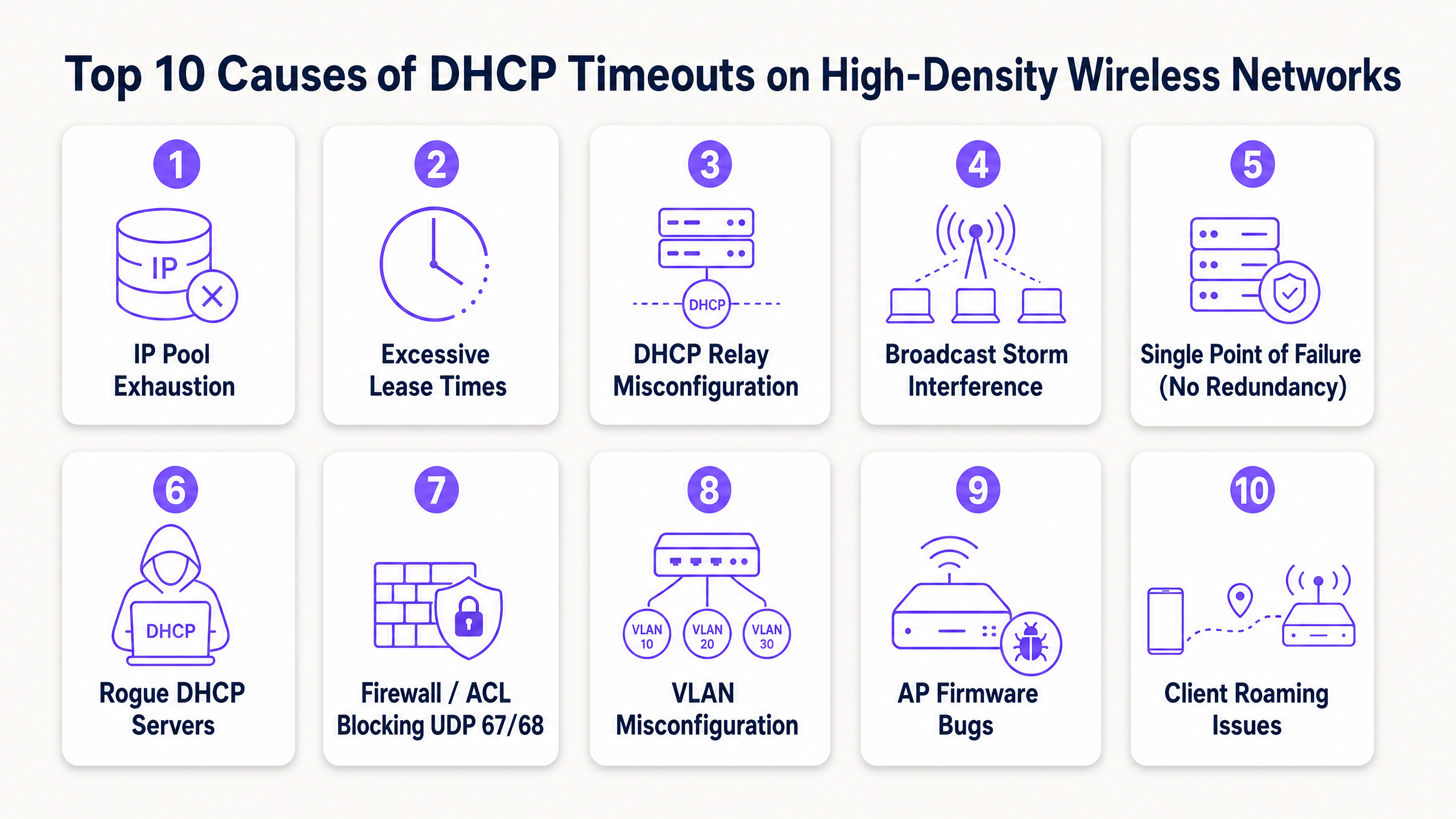
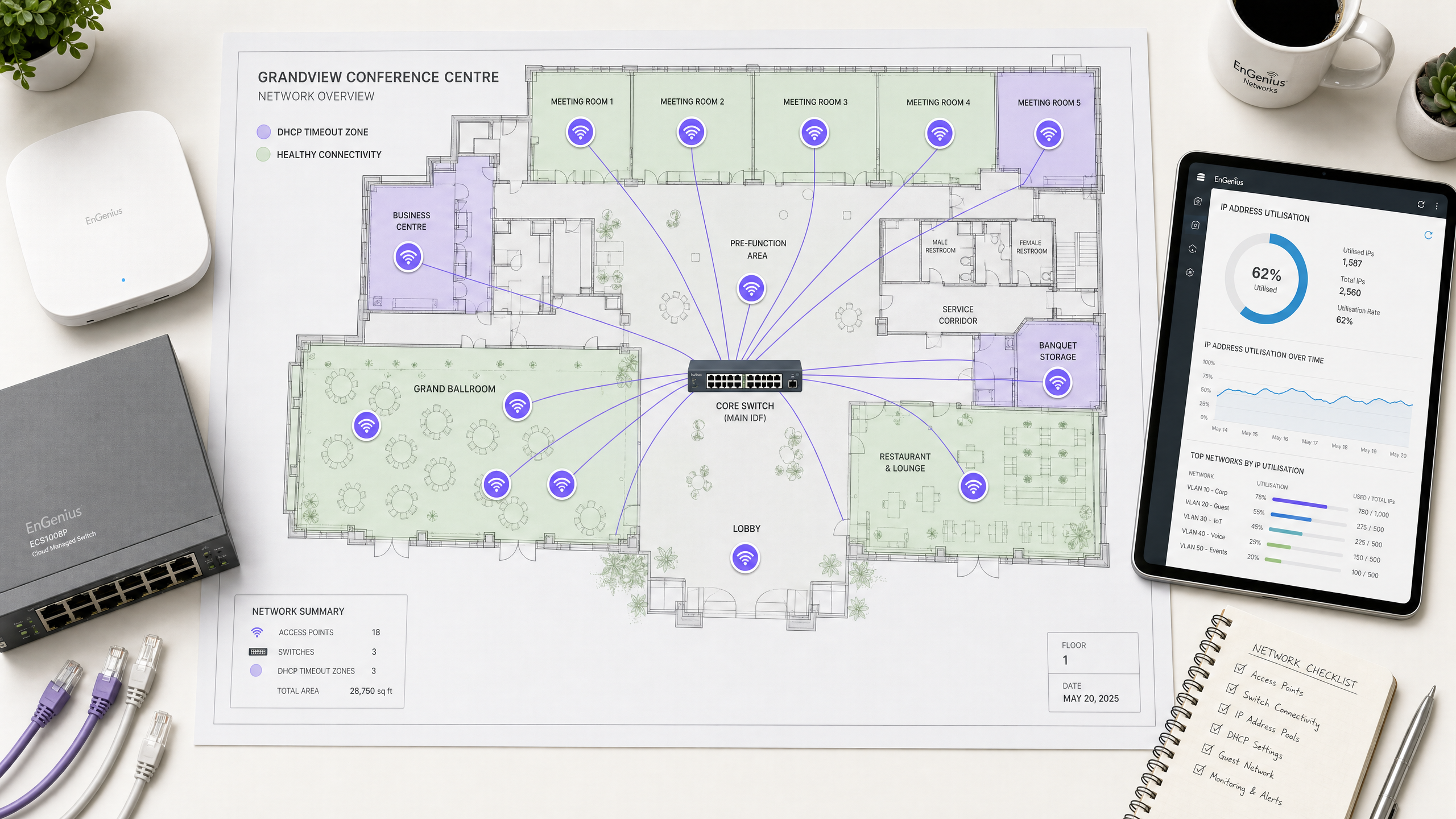
1. Agotamiento del pool de IP de DHCP
El mecanismo: El alcance del servidor DHCP es demasiado pequeño para el volumen de dispositivos transitorios. Cuando el pool está al 100% de su capacidad, el servidor ignora silenciosamente los nuevos paquetes DHCPDISCOVER porque no tiene direcciones que ofrecer.
El contexto de alta densidad: Una subred Clase C estándar (/24) proporciona solo 254 direcciones IP utilizables. En el lobby de un hotel, la puerta de un estadio o una sala plenaria de conferencias, el número de dispositivos concurrentes puede superar fácilmente este límite en cuestión de minutos. Para empeorar las cosas, muchos usuarios llevan consigo múltiples dispositivos conectados (teléfonos, relojes inteligentes, tablets, laptops), multiplicando la demanda de IP.
Mitigación: Ajuste el tamaño de los alcances de su red utilizando la notación de enrutamiento entre dominios sin clases (CIDR). Transicione las VLAN de clientes de alta densidad a subredes /22 (1,022 IPs) o /21 (2,046 IPs). Asegúrese de que sus herramientas de monitoreo estén configuradas para alertar al 80% de utilización del pool para permitir una expansión proactiva del alcance antes de los eventos de máxima demanda.
2. Tiempos de concesión excesivos en redes de invitados
El mecanismo: El tiempo de concesión (lease time) determina cuánto tiempo conserva un cliente una dirección IP antes de tener que renovarla o liberarla. Si el tiempo de concesión es demasiado largo, el servidor DHCP retiene la dirección en su base de datos, lo que impide que se reasigne a un nuevo cliente, incluso si el dispositivo original ya se retiró del lugar.
El contexto de alta densidad: Muchas configuraciones predeterminadas de DHCP especifican un tiempo de concesión de 24 horas o de 8 días. En entornos de alta rotación del sector público o de hospitalidad —como una terminal de transporte o un centro comercial— los invitados suelen quedarse por menos de dos horas [3]. Con una concesión de 24 horas, un invitado que se conecta durante 10 minutos consume una dirección IP durante todo un día, lo que provoca un agotamiento artificial del pool. Remediación: Alinee los tiempos de concesión con los tiempos de permanencia de los clientes. Implemente un tiempo de concesión de 30 a 60 minutos para las redes de invitados. Para redes de personal corporativo donde los dispositivos permanecen conectados durante un turno completo, use un tiempo de concesión de 8 a 12 horas. Esto garantiza la rápida recuperación de direcciones IP de los clientes que se han retirado.
3. Configuración incorrecta del agente de retransmisión DHCP
El mecanismo: Debido a que los mensajes de descubrimiento DHCP son transmisiones (broadcasts) de Capa 2, no pueden cruzar los límites del router (Capa 3). Un agente de retransmisión DHCP (generalmente configurado en un switch de Capa 3 o gateway de seguridad usando comandos como ip helper-address de Cisco) debe interceptar estas transmisiones y reenviarlas como paquetes de unidifusión (unicast) al servidor DHCP central [4]. Si el agente de retransmisión está mal configurado, tiene una IP de ayuda (helper IP) incorrecta o se omite en una VLAN recién creada, el tráfico DHCP se bloqueará.
El contexto de alta densidad: Las redes de alta densidad dependen en gran medida de la segmentación de VLAN para limitar los dominios de transmisión. Al implementar un nuevo SSID o expandir un recinto, los ingenieros a menudo crean nuevas VLAN de clientes. Si la configuración del agente de retransmisión no se actualiza en las interfaces de Capa 3 correspondientes, los clientes en esas VLAN experimentarán tiempos de espera de DHCP (timeouts) inmediatos.
Remediación: Establezca plantillas de configuración estrictas para todos los switches de Capa 3. Asegúrese de que cada interfaz de VLAN de cliente tenga un par redundante de direcciones de ayuda DHCP que apunten a sus servidores DHCP primario y secundario. Verifique el enrutamiento de extremo a extremo entre la IP de la interfaz de retransmisión (que el servidor DHCP utiliza para determinar qué ámbito de subred asignar) y el propio servidor DHCP.
4. Tormentas de broadcast y multicast
El mecanismo: El exceso de tráfico de broadcast o multicast en una VLAN satura el medio inalámbrico. Debido a que el medio inalámbrico es un medio compartido de medio dúplex (half-duplex), los AP y los clientes deben esperar a que el canal esté libre antes de transmitir. Una tormenta de broadcast —a menudo causada por bucles de conmutación, tarjetas de interfaz de red defectuosas o protocolos peer-to-peer agresivos— llena el tiempo de aire, lo que provoca que los paquetes DHCP se encolen, retrasen o descarten.
El contexto de alta densidad: En redes inalámbricas grandes y planas sin un aislamiento de Capa 2 adecuado, el tráfico de broadcast peer-to-peer (como Apple AirPlay, Google Chromecast o el descubrimiento de redes de Windows) es replicado por cada AP en la VLAN. En un recinto con 10,000 usuarios, esta "charla" de fondo puede consumir más del 50% del ancho de banda inalámbrico disponible, dejando un tiempo de aire insuficiente para los paquetes críticos de saludo (handshake) de DHCP.
Remediación: Habilite Client Isolation (también conocido como bloqueo peer-to-peer) en el controlador inalámbrico para evitar que los clientes se comuniquen directamente entre sí. Configure la Supresión de broadcast y multicast en los AP y switches, limitando el tráfico de broadcast a un pequeño porcentaje de la capacidad del enlace (por ejemplo, 100 paquetes por segundo). Donde sea compatible, habilite DHCP Proxy en los AP para convertir las ofertas y confirmaciones de DHCP de tipo broadcast en tramas unicast dirigidas específicamente al cliente que realiza la solicitud.
5. Punto único de falla (Falta de redundancia DHCP)
El mecanismo: Un único servidor DHCP no redundante representa una vulnerabilidad crítica. Si el servidor se cae, se somete a actualizaciones del sistema o pierde la conectividad de red, la capacidad de incorporación de toda la red se detiene de inmediato. Las concesiones existentes permanecen activas, pero ningún cliente nuevo puede obtener una dirección IP y los clientes en roaming no pueden renovar sus concesiones.
El contexto de alta densidad: Los entornos de alta densidad operan bajo estrictos SLA operativos. Un estadio durante un partido o un centro de convenciones durante una conferencia no pueden tolerar ni cinco minutos de inactividad de DHCP. Depender de un solo router o de una sola máquina virtual para manejar miles de solicitudes rápidas de concesión es una arquitectura de alto riesgo.
Remediación: Implemente DHCP en una configuración de alta disponibilidad. Utilice Windows Server DHCP Failover en modo de equilibrio de carga (división 50/50) o en modo de espera activa (Hot Standby), o implemente dispositivos DHCP redundantes de clase empresarial (como Infoblox o BlueCat) [5]. Asegúrese de que sus servidores DHCP estén distribuidos física o lógicamente en diferentes hipervisores y rutas de red para eliminar fallas de modo común.
6. Servidores DHCP no autorizados (Rogue DHCP)
El mecanismo: Un servidor DHCP no autorizado es un dispositivo con DHCP habilitado no autorizado que está conectado a la red. Intercepta las transmisiones DHCPDISCOVER de los clientes y responde con sus propios paquetes DHCPOFFER, entregando a menudo configuraciones IP incorrectas, puertas de enlace predeterminadas erróneas o servidores DNS maliciosos.
El contexto de alta densidad: En recintos grandes, tiendas minoristas u oficinas del sector público, los puertos ethernet físicos suelen estar accesibles en áreas públicas, o los usuarios pueden traer dispositivos no autorizados (como routers de viaje de consumo o máquinas virtuales con redes en puente) y conectarlos a la pared. Esto provoca conflictos de direcciones IP, agujeros negros de enrutamiento y graves riesgos de seguridad, incluidos los ataques de intermediario (man-in-the-middle).
Remediación: Habilite DHCP Snooping en todos los switches de acceso y distribución [6]. DHCP snooping designa los puertos del switch como "confiables" (conectados a servidores DHCP legítimos o agentes de retransmisión) o "no confiables" (conectados a clientes). El switch descartará automáticamente cualquier respuesta del servidor DHCP (como DHCPOFFER o DHCPACK) que se origine en un puerto no confiable, neutralizando los servidores no autorizados de forma instantánea.
7. Firewalls, ACL y políticas de seguridad que bloquean UDP 67/68
El mecanismo: DHCP depende del puerto UDP 67 (escucha del lado del servidor y destino del lado del cliente) y del puerto UDP 68 (escucha del lado del cliente y destino del lado del servidor). Si los firewalls de red, las listas de control de acceso (ACL) de los switches o las políticas de seguridad de los endpoints bloquean estos puertos, el protocolo de enlace DORA no se podrá completar. El contexto de alta densidad: El endurecimiento de la seguridad es una prioridad para las redes empresariales. Sin embargo, las políticas de seguridad demasiado agresivas a menudo bloquean inadvertidamente el tráfico DHCP. Por ejemplo, durante una migración de firewall o una actualización de políticas, un administrador podría bloquear todo el tráfico UDP en un segmento sin darse cuenta de que ha interrumpido la ruta de DHCP. De manera similar, las políticas de seguridad de la VLAN de invitados deben permitir explícitamente UDP 67 y 68 antes de redirigir el tráfico a un captive portal.
Remediación: Audite todas las ACL y reglas de firewall a lo largo de la ruta entre los clientes inalámbricos, los AP, los switches de Capa 3 y los servidores DHCP. Asegúrese de que los puertos UDP 67 y 68 estén permitidos explícitamente en ambas direcciones. Al realizar la resolución de problemas, realice una captura de paquetes en la interfaz de red del servidor DHCP para confirmar que los paquetes DHCPDISCOVER realmente estén llegando.
8. Errores de configuración de VLAN y trunking
El mecanismo: Si el SSID de un cliente se asocia a una VLAN específica, pero esa VLAN no está correctamente etiquetada o configurada en trunking de extremo a extremo a través de la infraestructura de switching, las transmisiones DHCP del cliente nunca llegarán a la puerta de enlace predeterminada ni al agente de retransmisión DHCP.
El contexto de alta densidad: Las redes inalámbricas de alta densidad utilizan la asignación dinámica de VLAN o la agrupación multi-VLAN para distribuir la carga de los clientes. Si a un solo puerto troncal del switch a lo largo de la ruta desde el AP hasta el switch principal (core) le falta una etiqueta VLAN en su lista permitida, un subconjunto de clientes —específicamente aquellos asignados a esa VLAN— experimentará tiempos de espera de DHCP inmediatos y persistentes, mientras que otros clientes en el mismo SSID se conectarán correctamente. Esto crea escenarios de resolución de problemas altamente intermitentes y difíciles de diagnosticar.
Remediación: Implemente herramientas de validación y gestión automatizada de la configuración de red. Al configurar puertos troncales de switch, utilice siempre listas permitidas explícitas (por ejemplo, switchport trunk allowed vlan 10,20,30) en lugar de depender de las configuraciones predeterminadas "all", y verifique que la VLAN nativa coincida en ambos extremos del enlace troncal para evitar filtraciones de tráfico no etiquetado.
9. Errores de firmware y controladores de puntos de acceso (AP)
El mecanismo: El firmware del punto de acceso es responsable de puentear las tramas inalámbricas 802.11 a la red Ethernet cableada 802.3. Un error de software en el controlador inalámbrico o en el motor de puenteo del AP puede causar que el AP descarte paquetes DHCP, particularmente bajo una alta carga de CPU o memoria.
El contexto de alta densidad: Las redes de alta densidad llevan el hardware y el software del AP a sus límites. Un error que permanece inactivo bajo una carga ligera de 10 clientes puede desencadenar fallas catastróficas cuando el AP maneja 100 clientes activos concurrentes. Por ejemplo, un error documentado a principios de 2026 en ciertos AP WiFi 7 causó que el AP descartara intermitentemente el tercer paquete del saludo de conexión (el DHCPREQUEST), evitando que el cliente recibiera su DHCPACK y completara el proceso de incorporación (onboarding).
Remediación: Mantenga una política rigurosa de gestión del ciclo de vida para el firmware del AP. Evite implementar versiones de firmware "de vanguardia" directamente en entornos de producción. Establezca un entorno de prueba que imite condiciones de alta densidad y supervise de cerca las notas de versión del fabricante y los foros de la comunidad para detectar errores conocidos relacionados con DHCP. Si la resolución de problemas revela que el cliente envía paquetes DHCPDISCOVER pero nunca se ven en el puerto de enlace ascendente cableado del AP, sospeche de un error de puente del AP.
10. Roaming Agresivo del Cliente y Límites de Capa 3
El Mecanismo: Cuando un cliente inalámbrico se mueve (hace roaming) de un AP a otro, debe mantener su sesión de red. Si el roaming cruza un límite de Capa 3 (moviendo al cliente a una subred diferente), el cliente debe obtener una nueva dirección IP. Si el sistema operativo del cliente o la red inalámbrica no logran manejar esta transición sin problemas, el cliente intentará usar su dirección IP anterior en la nueva subred, lo que provocará tiempos de espera de conexión y fallas en la renegociación de DHCP.
El Contexto de Alta Densidad: Los recintos de alta densidad requieren cientos de AP para proporcionar una cobertura adecuada. Los clientes están en constante movimiento; por ejemplo, los huéspedes de un hotel que caminan desde sus habitaciones hasta la sala de conferencias, o los compradores que se desplazan por un centro comercial [7]. Si la arquitectura de la red mapea diferentes áreas físicas del recinto a diferentes subredes, ocurrirá un gran volumen de roams de Capa 3, saturando al servidor DHCP con eventos rápidos de liberación y solicitud.
Remediación: Diseñe redes inalámbricas de alta densidad utilizando una arquitectura plana de Capa 2 en todo el SSID del cliente, o implemente túneles basados en controladores inalámbricos (como GRE o CAPWAP) [8]. El uso de túneles garantiza que el tráfico de un cliente siempre esté anclado a su controlador de origen y VLAN original, independientemente de a qué AP físico se mueva, eliminando por completo los eventos de roaming de Capa 3 y la sobrecarga de DHCP asociada.
Guía de Implementación
Para eliminar sistemáticamente los tiempos de espera de DHCP, los arquitectos de red deben pasar de una resolución de problemas reactiva a una arquitectura proactiva y estandarizada. Siga esta guía de implementación paso a paso para fortalecer su infraestructura DHCP.
Paso 1: Dimensionamiento de Subredes y Arquitectura CIDR
Nunca use subredes /24 estándar para redes de invitados de alta densidad. Calcule sus requisitos de IP en función de la capacidad máxima más un margen del 50% para dar cabida a usuarios con múltiples dispositivos y a la rotación transitoria.
| Máscara de Subred | CIDR | Direcciones IP Usables | Mejor Caso de Uso |
|---|---|---|---|
255.255.255.0 |
/24 |
254 | Personal administrativo, impresoras, IoT interno |
255.255.254.0 |
/23 |
510 | Hoteles boutique pequeños, tiendas minoristas localizadas |
255.255.252.0 |
/22 |
1,022 | Hoteles grandes, salas de conferencias de alta densidad, campus escolares |
255.255.248.0 |
/21 |
2,046 | Grandes salas de exposiciones, centros comerciales, plazas públicas |
255.255.240.0 |
/20 |
4,094 | Estadios, arenas, centros de convenciones masivos |
Paso 2: Optimización de los Tiempos de Concesión de DHCP
Configure su servidor DHCP para aplicar tiempos de concesión basados en el comportamiento de los usuarios de cada segmento de red específico:
Guest WiFi SSID (Alta Rotación) -> Tiempo de concesión: 30 a 60 Minutos
Corporate Staff SSID (Estable) -> Tiempo de concesión: 8 a 12 Horas
Venue IoT & Infraestructura -> Tiempo de concesión: 7 Días (o Reservación Estática)
Nota: Reducir los tiempos de concesión aumenta la frecuencia de las solicitudes de renovación de DHCP (que ocurren al 50% de la duración de la concesión, conocido como T1) [9]. Asegúrese de que el hardware de su servidor DHCP tenga suficiente rendimiento de CPU y E/S para manejar la elevada tasa de solicitudes.
Paso 3: Configuración de Agentes de Retransmisión (Relay) DHCP en Switches de Capa 3
Al configurar agentes de retransmisión DHCP, especifique siempre direcciones helper redundantes que apunten a servidores DHCP independientes. A continuación, se presenta una plantilla de configuración estándar y neutral para una interfaz de switch Cisco IOS de Capa 3:
interface Vlan30
description High_Density_Guest_WiFi
ip address 192.168.30.1 255.255.252.0
ip helper-address 10.10.10.10 # Servidor DHCP Primario
ip helper-address 10.10.10.11 # Servidor DHCP Secundario
ip dhcp relay information option # Insertar Opción 82 para rastreo de ubicación
no shutdown
Paso 4: Robustecimiento de la Seguridad de Capa 2 con DHCP Snooping
Evite servidores DHCP no autorizados y mitigue los ataques de agotamiento de DHCP habilitando DHCP snooping en toda su estructura de switches. A continuación, se presenta una plantilla de configuración para un switch de acceso perimetral:
# Habilitar DHCP snooping globalmente
ip dhcp snooping
# Habilitar DHCP snooping para VLANs de clientes específicas
ip dhcp snooping vlan 10,20,30
# Configurar el puerto de enlace ascendente (uplink) al switch principal/servidor DHCP como CONFIABLE (TRUSTED)
interface GigabitEthernet1/0/48
description UPLINK_TO_CORE
ip dhcp snooping trust
# Configurar los puertos orientados al cliente como NO CONFIABLES (UNTRUSTED) y limitar la tasa de paquetes DHCP para evitar ataques de agotamiento
interface range GigabitEthernet1/0/1 - 47
description CLIENT_ACCESS_PORTS
ip dhcp snooping limit rate 15
Mejores Prácticas
Para mantener una red inalámbrica resiliente y de alto rendimiento, incorpore estas mejores prácticas estándar de la industria en sus manuales de procedimientos operativos:
1. Implementar la Opción 82 de DHCP (Opción de Información del Agente de Retransmisión)
La Opción 82 de DHCP permite al agente de retransmisión insertar información específica del circuito (como el ID del puerto del switch o la dirección MAC del AP) en la solicitud DHCP antes de reenviarla al servidor [10]. Esto permite que el servidor DHCP aplique políticas de asignación de IP altamente granulares basadas en la ubicación física del cliente dentro del recinto. Por ejemplo, un hotel puede asignar diferentes pools de IP o configuraciones de DNS a los clientes en el centro de convenciones en comparación con aquellos en las habitaciones de huéspedes, optimizando la utilización del pool.
2. Habilitar la Conversión de ARP y DHCP de Broadcast a Unicast
Configure su controlador de LAN inalámbrica (WLC) o sus AP administrados en la nube para interceptar paquetes broadcast ARP y DHCP de Capa 2 y convertirlos en tramas unicast antes de transmitirlos por el aire. Debido a que las tramas unicast se transmiten a la velocidad de datos máxima compatible del cliente (en lugar de la velocidad de broadcast obligatoria más baja), este simple cambio de configuración reduce drásticamente el consumo de tiempo de aire de RF y mejora la confiabilidad de DHCP en entornos de alta densidad.
3. Establezca Monitoreo y Alertas Proactivas de DHCP
No espere a que los usuarios reporten fallas de conexión. Configure su Sistema de Gestión de Red (NMS) o las herramientas de monitoreo del servidor DHCP para rastrear métricas clave e iniciar alertas inmediatas:
- Utilización del Pool: Inicie una alerta de advertencia al 75% de utilización y una alerta crítica al 85%.
- Tasa de Solicitudes DHCP: Monitoree picos repentinos en las solicitudes, lo que puede indicar una tormenta de broadcast, un bucle de roaming o un ataque de agotamiento de DHCP.
- Distribución de Expiración de Concesiones: Asegúrese de que las concesiones expiren sin problemas y que la base de datos esté reclamando activamente las direcciones IP.
Solución de Problemas y Mitigación de Riesgos
Cuando se sospeche de un tiempo de espera agotado (timeout) de DHCP, siga este flujo de diagnóstico sistemático para aislar rápidamente el punto de falla y minimizar la interrupción del negocio.
[El Cliente se Asocia al AP]
│
▼
[Capturar Paquetes en el Cliente] ───► ¿Se envía DHCPDISCOVER?
│ ├── NO: Problema de OS/Driver del cliente.
│ └── SÍ
▼
[Capturar Paquetes en el Switch] ───► ¿Llega DHCPDISCOVER al Switch?
│ ├── NO: Problema de Bridging del AP/Etiquetado VLAN.
│ └── SÍ
▼
[Capturar Paquetes en el Servidor] ──► ¿Llega DHCPDISCOVER al Servidor?
│ ├── NO: Problema de Agente de Retransmisión / Enrutamiento / Firewall.
│ └── SÍ
▼
[Revisar Logs del Servidor] ─────────► ¿Se envía DHCPOFFER?
├── NO: Pool Agotado / Ámbito Inactivo.
└── SÍ: Ruta de retorno bloqueada (VLAN/Enrutamiento).
Comandos Clave para la Solución de Problemas
Para verificar el estado de DHCP y diagnosticar fallas en equipos de red activos, use los siguientes comandos:
Cisco IOS (Servidor DHCP o Retransmisión)
# Ver la utilización del pool DHCP y direcciones libres
show ip dhcp pool
# Ver las asociaciones de direcciones IP activas
show ip dhcp binding
# Monitorear estadísticas del servidor DHCP (conteos de discover, request, ack)
show ip dhcp server statistics
# Ver la base de datos de conflictos de DHCP (IPs marcadas como no válidas debido a conflictos)
show ip dhcp conflict
Linux (Servidor o Cliente DHCP)
# Ver solicitudes de concesión de clientes DHCP en vivo en un cliente Linux
sudo dhclient -v wlan0
# Capturar tráfico DHCP (puertos UDP 67 y 68) en una interfaz específica
sudo tcpdump -i eth0 -n -vv 'udp and (port 67 or port 68)'
# Revisar la base de datos de concesiones DHCP de dnsmasq
cat /var/lib/misc/dnsmasq.leases
Windows (Cliente DHCP)
# Liberar dirección IP actual
ipconfig /release
# Renovar dirección IP (inicia un nuevo protocolo de enlace DHCP)
ipconfig /renew
ROI e impacto empresarial
Invertir en una infraestructura DHCP altamente resiliente y bien estructurada no es solo una necesidad técnica: es un habilitador empresarial crítico que impacta directamente en los resultados financieros y la eficiencia operativa.
Cuantificar el valor empresarial de un acceso sin fricciones
- Experiencia del huésped mejorada y lealtad a la marca: En las industrias de la hospitalidad y eventos, la conectividad inalámbrica es un factor clave para la satisfacción de los huéspedes. Un huésped que experimenta fricciones al conectarse tiene una alta probabilidad de dejar reseñas negativas, lo que afecta directamente las tasas de reserva. Eliminar los tiempos de espera de DHCP garantiza una primera impresión sin fricciones.
- Maximizar el ROI del marketing de WiFi para huéspedes: Para los sectores de retail y entretenimiento, el WiFi para huéspedes es un canal de marketing muy potente. Al garantizar una tasa de conexión exitosa del 100%, los equipos de marketing pueden recopilar más datos de primera mano (como correos electrónicos, datos demográficos y patrones de tráfico peatonal) a través de WiFi Analytics , lo que impulsa campañas de participación altamente dirigidas y aumenta el valor de vida del cliente.
- Reducción de los costos de soporte de TI: Los tickets relacionados con DHCP ("No se puede conectar al WiFi", "Error de dirección IP") se encuentran entre las solicitudes más frecuentes y que más tiempo consumen para las mesas de ayuda de TI. Al implementar la redundancia de DHCP, dimensionar correctamente los grupos y desplegar el DHCP snooping, las organizaciones pueden reducir los tickets de soporte relacionados con la red inalámbrica hasta en un 40%, lo que permite al personal de TI enfocarse en iniciativas estratégicas en lugar de la resolución de problemas básicos.
- Garantizar el cumplimiento regulatorio y la seguridad: La implementación de DHCP snooping y la mitigación de servidores DHCP no autorizados respaldan directamente el cumplimiento de estándares de seguridad clave, como PCI DSS (para entornos de pago de retail) y GDPR (al proteger las redes de datos de los huéspedes). Una arquitectura DHCP segura y bien documentada mitiga el riesgo de costosas brechas de datos y multas regulatorias.
Tabla de resumen de impacto empresarial
| Métrica | Antes de la optimización | Después de la optimización | Impacto empresarial |
|---|---|---|---|
| Tasa de tiempo de espera de DHCP | 8.5% (Durante horas pico) | < 0.1% | Conexión de usuarios sin fricciones, eliminación de quejas de conexión |
| Tiempo medio de resolución (MTTR) | 45 minutos | < 5 minutos | Resolución rápida de problemas mediante un mapeo documentado de VLAN/alcance |
| Tasa de suscripción al WiFi de huéspedes | 62% | 88% | Mayor crecimiento de la base de datos de marketing, recopilación de datos más completa |
| Volumen de tickets de soporte de TI | Alto (Errores de DHCP/IP) | Insignificante | Reducción del 40% en tickets de soporte técnico relacionados con la red inalámbrica |
Referencias
- IETF RFC 2131 - Dynamic Host Configuration Protocol
- IEEE 802.11-2020 - Wireless LAN Medium Access Control and Physical Layer Specifications
- Optimización de tiempos de arrendamiento de DHCP de WiFi para dispositivos móviles
- IETF RFC 3046 - Opción de información del agente de retransmisión DHCP
- IETF RFC 8156 - Protocolo de conmutación por error DHCPv4
- Cisco Systems - Configuración de DHCP Snooping
- Por qué el WiFi de los estadios se ralentiza (y cómo solucionarlo)
- HPE Aruba Networking - Guía de diseño e implementación de Wi-Fi en grandes recintos públicos
- Cómo solucionar problemas de DHCP en redes WiFi
- IETF RFC 3993 - Subopción Subscriber-ID para la opción de información del agente de retransmisión DHCP
Definiciones clave
DHCP (Dynamic Host Configuration Protocol)
Un protocolo de gestión de red utilizado en redes de protocolo de Internet (IP) mediante el cual un servidor DHCP asigna de forma dinámica una dirección IP y otros parámetros de configuración de red a cada dispositivo en una red para que puedan comunicarse con otras redes IP.
DHCP es el primer paso crítico en la incorporación inalámbrica; si falla, los clientes no pueden acceder a ningún recurso de red, incluidos los portales de invitados.
Proceso DORA
La secuencia estándar de cuatro pasos de mensajes intercambiados entre un cliente y un servidor DHCP para negociar el arrendamiento de una dirección IP: DHCPDISCOVER, DHCPOFFER, DHCPREQUEST y DHCPACK.
Comprender la secuencia DORA es esencial para diagnosticar en qué punto está fallando el protocolo de enlace DHCP durante la solución de problemas de red.
Agente de Relay DHCP
Cualquier host o dispositivo de red (normalmente un switch de Capa 3 o un router) que reenvíe paquetes DHCP entre clientes y servidores cuando se encuentran en diferentes subredes o VLAN.
Se requieren agentes de relay en redes empresariales segmentadas para centralizar los servicios DHCP y evitar que el tráfico de difusión cruce los límites del router.
DHCP Snooping
Una función de seguridad de Capa 2 integrada en los switches gestionados que filtra los mensajes DHCP no confiables y crea una base de datos de vinculación de asignaciones MAC a IP confiables.
DHCP snooping es la defensa principal contra servidores DHCP no autorizados y ataques de intermediario (man-in-the-middle) en redes inalámbricas empresariales.
Agotamiento del Pool de IP
Una condición que ocurre cuando se han arrendado todas las direcciones IP disponibles dentro del ámbito configurado de un servidor DHCP, lo que deja sin direcciones disponibles para nuevos clientes.
El agotamiento del pool es la causa principal de los tiempos de espera de DHCP en entornos de alta densidad y se resuelve ajustando el tamaño de los ámbitos o reduciendo los tiempos de arrendamiento.
Tiempo de Arrendamiento DHCP (Lease Time)
La duración de tiempo por la cual un servidor DHCP asigna una dirección IP a un dispositivo cliente específico antes de que el cliente deba solicitar una renovación de arrendamiento.
Optimizar los tiempos de arrendamiento en función del comportamiento del usuario (cortos para redes de invitados, más largos para el personal) es fundamental para mantener la eficiencia del pool de IP.
Servidor DHCP No Autorizado (Rogue)
Un servidor DHCP no autorizado conectado a una red, que entrega configuraciones IP no válidas o maliciosas a los clientes, lo que genera problemas de conectividad y vulnerabilidades de seguridad.
Los servidores no autorizados son comunes en espacios públicos abiertos y se neutralizan habilitando DHCP snooping en los switches de acceso.
Supresión de Difusión (Broadcast)
Una técnica de configuración de red que limita la tasa de tráfico de difusión (broadcast) y multidifusión (multicast) en una VLAN o puerto de switch para evitar la congestión de la red y las tormentas de difusión.
La supresión de difusión es fundamental en redes inalámbricas de alta densidad para proteger el tiempo de aire de RF y garantizar que los paquetes DHCP críticos no se retrasen.
Ejemplos resueltos
Un centro de conferencias de alta densidad con una sala plenaria principal diseñada para albergar a 2,500 asistentes está experimentando fallas masivas de incorporación a la red WiFi durante el discurso de apertura. Los asistentes informan que sus dispositivos se quedan atascados en 'Obteniendo dirección IP' durante varios minutos, y aquellos que logran conectarse se desconectan con frecuencia al moverse entre la sala plenaria y el área de exhibición. La configuración de red actual utiliza una sola VLAN de cliente asignada a una subred estándar `/24` con un tiempo de concesión de DHCP de 24 horas, servida por un único router central. ¿Cómo se debería rediseñar esta red para eliminar estas fallas?
Para resolver estas fallas de incorporación, la arquitectura de red debe rediseñarse para manejar el comportamiento transitorio de clientes de alta densidad. Siga este flujo de trabajo de remediación de varios pasos:
Expandir el espacio de direcciones IP (dimensionamiento de subred): Reemplace la subred estándar
/24(que solo proporciona 254 direcciones IP) por una subred/21(que proporciona 2,046 direcciones IP utilizables) o implemente un grupo multi-VLAN. Esto garantiza que el grupo de direcciones IP tenga el tamaño suficiente para manejar a 2,500 asistentes simultáneos, muchos de los cuales llevarán múltiples dispositivos conectados (un promedio de 1.5 dispositivos por asistente = 3,750 IP requeridas). Si se utiliza una sola subred plana/20(4,094 IP), se adaptará fácilmente a la capacidad total del evento.Optimizar los tiempos de concesión de DHCP: Reduzca el tiempo de concesión de DHCP de 24 horas a 45 minutos en la red inalámbrica de invitados. Dado que los asistentes a la conferencia son altamente transitorios y entran y salen de la sala plenaria, un tiempo de concesión corto garantiza que las direcciones IP se recuperen rápidamente de los dispositivos que han abandonado el área, evitando el agotamiento artificial del grupo.
Implementar servidores DHCP redundantes: Elimine el punto único de falla implementando un par de servidores DHCP redundantes. Configure la conmutación por error de DHCP de Windows Server en modo de equilibrio de carga (división 50/50) en dos máquinas virtuales independientes, o utilice un dispositivo DHCP dedicado de alta disponibilidad. Esto garantiza que si un servidor o ruta de red falla, el servidor restante pueda manejar toda la carga de solicitudes.
Implementar supresión de difusión de Capa 2 y Proxy DHCP: Habilite la supresión de difusión (broadcast suppression) en el controlador inalámbrico, limitando el tráfico de difusión a 100 paquetes por segundo. Habilite el Proxy DHCP en los puntos de acceso para convertir los mensajes de difusión
DHCPOFFERyDHCPACKen tramas de unidifusión (unicast). Esto reduce drásticamente el consumo de tiempo de aire inalámbrico y evita las colisiones de paquetes.Configurar DHCP Snooping y validación ARP: Habilite el DHCP snooping en todos los switches de acceso para proteger la red de servidores DHCP no autorizados y evitar ataques de agotamiento de DHCP. Limite la tasa de paquetes DHCP en los puertos orientados al cliente a 15 paquetes por segundo.
Un hotel de lujo de 500 habitaciones está desplegando una nueva SSID de invitados en toda su propiedad. El equipo de red creó una nueva VLAN de invitados (VLAN 50) y configuró un servidor DHCP central de Windows con un ámbito `/22` correspondiente. Sin embargo, durante las pruebas, los dispositivos asociados con la SSID de invitados en las habitaciones del hotel no logran obtener una dirección IP y agotan el tiempo de espera, mientras que los dispositivos conectados directamente a los puertos cableados en las oficinas administrativas (VLAN 10) obtienen direcciones IP al instante. ¿Cuál es la causa más probable de este problema, y cómo debería diagnosticarse y resolverse?
El hecho de que los clientes cableados en la VLAN 10 estén obteniendo direcciones IP mientras que los clientes inalámbricos en la VLAN 50 agotan el tiempo de espera indica que el problema es específico de la ruta o de la configuración de la VLAN 50. La causa más probable es la falta de un Agente de Retransmisión DHCP (IP Helper) o su configuración incorrecta en la interfaz del switch de Capa 3 para la VLAN 50, o la falta de una etiqueta de VLAN a lo largo de la ruta de enlace troncal entre los Access Points y el switch central. Siga este flujo de trabajo de diagnóstico y resolución:
Verificar la Configuración del Agente de Retransmisión DHCP: Inicie sesión en el switch central de Capa 3 (o gateway) e inspeccione la configuración para la interfaz VLAN 50. Asegúrese de que el comando
ip helper-addressesté presente y apunte a la dirección IP correcta del servidor DHCP de Windows. Si falta el comando, el switch no reenviará los paquetes broadcastDHCPDISCOVERdel cliente al servidor DHCP.Verificar el Enlace Troncal de VLAN de Extremo a Extremo: Verifique que la VLAN 50 esté etiquetada en todos los puertos de switch a lo largo de la ruta desde los APs hasta el switch central. Use comandos como
show interfaces trunken switches Cisco para confirmar que la VLAN 50 esté permitida y activa en todos los enlaces troncales. Si falta la VLAN 50 en un solo puerto troncal, los broadcasts de DHCP de los clientes se descartarán antes de llegar al switch de Capa 3.Realizar Capturas de Paquetes: Para aislar el punto de fallo, realice capturas de paquetes simultáneas en tres ubicaciones:
- En el cliente inalámbrico (usando Wireshark o herramientas nativas del SO) para confirmar que se están enviando los broadcasts
DHCPDISCOVER. - En la interfaz del switch de Capa 3 para la VLAN 50 para confirmar que el switch está recibiendo los broadcasts.
- En la interfaz de red del servidor DHCP para confirmar que están llegando los paquetes DHCP unicast reenviados.
- En el cliente inalámbrico (usando Wireshark o herramientas nativas del SO) para confirmar que se están enviando los broadcasts
Verificar la Activación del Ámbito en el Servidor DHCP: Asegúrese de que el ámbito DHCP para la subred VLAN 50 (por ejemplo, 192.168.50.0/22) esté completamente creado, activado y tenga un rango activo de direcciones IP que no entre en conflicto con ninguna asignación estática.
Aplicar la Corrección de Configuración: En el switch central de Capa 3, aplique la configuración correcta de la dirección helper:
interface Vlan50 description Guest_WiFi_VLAN ip address 192.168.50.1 255.255.252.0 ip helper-address 10.10.10.10 # Windows DHCP Server IP no shutdown
Un centro comercial grande con más de 150 tiendas minoristas está experimentando caídas de conexión de WiFi altamente intermitentes. El equipo de TI informa que algunos compradores se conectan instantáneamente y navegan sin problemas, mientras que otros en la misma ubicación se quedan atascados en 'Obteniendo dirección IP' o reciben una advertencia de 'Sin conexión a Internet'. Una revisión de los registros del servidor DHCP muestra miles de concesiones activas, pero también un alto volumen de errores de 'Conflicto de DHCP' y varios casos en los que el servidor responde a los clientes con un `DHCPNAK` (acuse de recibo negativo). ¿Cómo se debe investigar y resolver este problema?
La presencia de errores de 'Conflicto de DHCP' y respuestas DHCPNAK en los registros del servidor sugiere fuertemente la presencia de un servidor DHCP no autorizado (rogue) en la red o un conflicto de dirección IP causado por asignaciones estáticas dentro del rango de DHCP. Siga este flujo de trabajo sistemático de investigación y remediación:
Aislar y detectar el servidor DHCP no autorizado: Use los registros de la base de datos de DHCP snooping en sus switches de acceso para identificar la actividad de servidores DHCP no autorizados. Ejecute el siguiente comando en sus switches principales (core) y de acceso para ver cualquier conflicto detectado o paquetes DHCP no confiables:
show ip dhcp snooping database show ip dhcp conflictLa base de datos de conflictos enumerará las direcciones MAC de los dispositivos que han respondido a los sondeos ARP para las IP que el servidor DHCP intentaba asignar, o los dispositivos que están distribuyendo activamente concesiones no autorizadas.
Habilitar DHCP Snooping de forma global y en las VLAN de clientes: Para neutralizar de inmediato cualquier servidor DHCP no autorizado, habilite DHCP snooping en todos los switches. Configure todos los puertos orientados a los clientes como no confiables (untrusted) y solo confíe en los puertos específicos conectados a sus servidores DHCP legítimos o enlaces troncales principales. Esto garantiza que cualquier paquete
DHCPOFFERoDHCPACKno autorizado se descarte en el puerto del switch antes de que pueda llegar a otros clientes.Configurar la inspección ARP dinámica (DAI): Para evitar que los clientes usen direcciones IP falsificadas (spoofed) o causen conflictos de IP, habilite Dynamic ARP Inspection (DAI) en las VLAN de los clientes. DAI utiliza la base de datos de vinculación de DHCP snooping para validar los paquetes ARP, descartando cualquier paquete con asignaciones de MAC a IP no válidas:
ip arp inspection vlan 10,20,30Excluir IPs estáticas del pool de DHCP: Asegúrese de que cualquier dirección IP estática asignada a dispositivos de infraestructura (como impresoras, AP o señalización digital) esté explícitamente excluida del rango de alcance de DHCP en el servidor para evitar que este ofrezca accidentalmente esas IP a los clientes.
Implementar seguridad de puertos (Port Security) y 802.1X: Para los puertos cableados en tiendas minoristas o áreas públicas, implemente Port Security para limitar la cantidad de direcciones MAC permitidas en un puerto, o implemente la autenticación 802.1X para evitar que dispositivos no autorizados se conecten a la estructura de la red física.
Preguntas de práctica
Q1. Un administrador de TI en un gran centro comercial nota que durante las horas pico de compras navideñas, las conexiones WiFi de invitados fallan con frecuencia. El registro del servidor DHCP está inundado de errores de "Ámbito DHCP lleno". La VLAN de invitados actual está configurada con una máscara de subred `/23` y un tiempo de arrendamiento predeterminado de 24 horas. ¿Cuáles son los dos cambios de configuración más inmediatos y efectivos que el administrador debería implementar para resolver este problema y por qué?
Sugerencia: Considere la relación entre el tamaño de la subred, el tiempo de permanencia del cliente y la recuperación de direcciones IP.
Ver respuesta modelo
El administrador debe implementar los siguientes dos cambios de configuración inmediatos:
Reducir el DHCP Lease Time: Disminuir el tiempo de concesión de 24 horas a 30 o 45 minutos. Dado que los visitantes de un centro comercial son muy transitorios (el tiempo de permanencia típico es de 1 a 2 horas), una concesión de 24 horas hace que el servidor DHCP retenga las direcciones IP mucho después de que los clientes se hayan retirado. Reducir el tiempo de concesión garantiza que las direcciones IP se recuperen rápidamente y se pongan a disposición de nuevos compradores, multiplicando eficazmente la capacidad del pool existente sin cambiar la estructura de la subred.
Expandir el alcance de la subred (dimensionamiento CIDR): Expandir la subred de la VLAN de invitados de un
/23(que proporciona 510 direcciones IP utilizables) a un/21(que proporciona 2,046 direcciones IP utilizables) o un/20(que proporciona 4,094 direcciones IP utilizables). Una subred/23es demasiado pequeña para un centro comercial grande durante las horas pico, especialmente si se tiene en cuenta que muchos compradores llevan múltiples dispositivos conectados (teléfonos, wearables, tablets). Expandir el alcance garantiza que haya suficientes direcciones IP disponibles para soportar la carga máxima de dispositivos simultáneos.
Estos dos cambios funcionan en conjunto: la expansión de la subred aumenta la capacidad absoluta del pool, mientras que la reducción del lease time garantiza la máxima eficiencia en la reutilización de direcciones, eliminando por completo los errores de 'DHCP Scope Full'.
Q2. Un ingeniero de redes está solucionando problemas en un SSID de invitados recién implementado en un hotel. Los clientes inalámbricos se asocian al AP correctamente pero no logran obtener una dirección IP, experimentando un tiempo de espera agotado después de varios segundos. Una captura de paquetes en el puerto del switch conectado al AP muestra transmisiones `DHCPDISCOVER` ingresando al switch, pero una captura en la interfaz de red del servidor DHCP central muestra que no entran paquetes desde la subred de invitados del hotel. El servidor DHCP se encuentra en una subred diferente (10.10.10.0/24) que la de los clientes inalámbricos de invitados (192.168.50.0/22). ¿Qué configuración falta, en qué dispositivo se debe aplicar y cuál es el comando exacto para aplicarla?
Sugerencia: Dado que el servidor DHCP está en una subred diferente a la de los clientes, un dispositivo de Capa 3 debe reenviar el tráfico de difusión.
Ver respuesta modelo
La configuración que falta es el DHCP Relay Agent (IP Helper). Debido a que los mensajes de descubrimiento de DHCP son difusiones de Capa 2, no pueden cruzar el router o el límite de Capa 3 entre la subred de invitados del cliente (192.168.50.0/22) y la subred del servidor DHCP (10.10.10.0/24). Sin un agente de retransmisión, el switch o router descartará los paquetes de difusión, evitando que lleguen al servidor.
Esta configuración debe aplicarse en el Switch de Capa 3 o Gateway de Seguridad que actúa como puerta de enlace predeterminada para la VLAN inalámbrica de invitados (VLAN 50).
Asumiendo un switch Cisco IOS de Capa 3, el ingeniero debe aplicar el comando ip helper-address a la interfaz VLAN 50, apuntando a la dirección IP del servidor DHCP central (por ejemplo, 10.10.10.10):
interface Vlan50
description Guest_WiFi_Gateway
ip address 192.168.50.1 255.255.252.0
ip helper-address 10.10.10.10
no shutdown
Este comando le indica al switch que intercepte las difusiones de DHCP en la VLAN 50, las convierta en paquetes de unidifusión de Capa 3 con una IP de origen del gateway de la VLAN 50 (192.168.50.1) y las reenvíe directamente al servidor DHCP en la dirección 10.10.10.10. Luego, el servidor utilizará la IP del gateway para seleccionar el alcance correcto y devolver una oferta.
Q3. El arquitecto de red de un estadio está diseñando una red inalámbrica para soportar a 50,000 aficionados simultáneos. Para minimizar el tráfico de difusión y el consumo de tiempo de aire de RF, el arquitecto desea implementar la supresión de difusiones y convertir las difusiones de DHCP a unidifusión. Sin embargo, algunos ingenieros júnior expresan su preocupación de que la conversión de difusiones de DHCP a unidifusión rompa el protocolo DHCP, ya que los clientes aún no tienen una dirección IP para recibir paquetes de unidifusión. ¿Cómo debería explicar el arquitecto el mecanismo técnico de la conversión de difusión a unidifusión para abordar estas preocupaciones?
Sugerencia: Considere cómo el Access Point realiza el puente de las tramas de Capa 2 y cómo se utiliza la dirección MAC del cliente en la cabecera 802.11.
Ver respuesta modelo
El arquitecto debe explicar que convertir las transmisiones de difusión (broadcast) de DHCP a unicast no rompe el protocolo DHCP porque el Access Point (AP) opera en la Capa 2 y puede dirigir las tramas directamente a la dirección MAC física del cliente, incluso si el cliente aún no tiene una dirección IP.
Este es el mecanismo técnico:
La dirección MAC del cliente es conocida: Durante la fase de asociación inicial, el cliente establece una conexión segura de Capa 2 con el AP. El AP conoce la dirección MAC única del cliente y la asocia con un puerto virtual y una interfaz de radio específicos.
El AP intercepta la transmisión: Cuando el servidor DHCP envía un
DHCPOFFERoDHCPACKcomo una transmisión de Capa 2 (dirección MAC de destinoFF:FF:FF:FF:FF:FF), el AP intercepta este paquete en su interfaz cableada.Conversión a Unicast: En lugar de transmitir el paquete por el aire como una trama de difusión (lo que obligaría a todos los clientes en el canal a despertarse y procesarlo a la tasa de datos obligatoria más baja), el AP modifica el encabezado MAC 802.11. Cambia la dirección MAC de destino de la dirección de difusión a la dirección MAC unicast del cliente específico (la cual extrajo del campo de dirección de hardware del cliente del paquete DHCP,
chaddr).Transmisión de alta velocidad: Debido a que la trama ahora es una trama unicast, el AP puede transmitirla utilizando la tasa de datos máxima admitida por el cliente (utilizando beamforming, MIMO y modulación de alto orden como QAM). También se beneficia de los acuses de recibo (ACK) de la Capa 2 de 802.11, lo que garantiza una entrega confiable.
Procesamiento del cliente: La tarjeta inalámbrica del cliente recibe la trama unicast, reconoce su propia dirección MAC en el encabezado 802.11 y pasa la carga útil (la oferta o el ack de DHCP) a la pila de red. El sistema operativo del cliente procesa la carga útil de DHCP normalmente, sin enterarse de que la trama se convirtió de difusión a unicast por el aire.
Esta explicación demuestra que la conversión de difusión a unicast es una optimización de Capa 2 que aprovecha la capa MAC 802.11 para proteger el tiempo de aire de RF, sin alterar la carga útil del protocolo DHCP de Capa 3.
Continúe leyendo esta serie
Uso de la captura de paquetes (PCAP) para diagnosticar el bajo rendimiento de WiFi
Esta guía de referencia técnica proporciona a los gerentes de TI, arquitectos de red y directores de operaciones de recintos una metodología estructurada a nivel de paquetes para diagnosticar y resolver el bajo rendimiento de WiFi empresarial mediante el análisis de captura de paquetes (PCAP). Al diseccionar tramas 802.11 sin procesar —incluidas las tasas de retransmisión, la utilización del tiempo de aire y los metadatos de la capa física—, los equipos pueden aislar con precisión los cuellos de botella de la capa de RF de los problemas de la red cableada o de las aplicaciones. Aplicable en recintos de alta densidad, como hoteles, cadenas de retail, estadios y centros de conferencias, esta guía ofrece flujos de trabajo de diagnóstico prácticos, casos de estudio del mundo real y pasos de remediación de configuración para recuperar la capacidad de la red y proteger la experiencia del huésped.
Resolución de problemas de fallas de autenticación 802.1X (RADIUS/EAP)
Esta guía proporciona una referencia completa y práctica para gerentes de TI, arquitectos de red y directores de operaciones de instalaciones sobre el diagnóstico y la resolución de fallas de autenticación 802.1X en infraestructuras RADIUS y EAP. Cubre toda la cadena de autenticación, desde la configuración incorrecta del suplicante y la expiración de certificados hasta discrepancias en el secreto compartido de RADIUS y la fragmentación en el tránsito de red, con casos de estudio reales de entornos de hospitalidad y retail. Los equipos responsables del cumplimiento de PCI DSS, implementaciones de WPA3-Enterprise y control de acceso a la red multisitio encontrarán marcos de diagnóstico estructurados, listas de verificación de implementación y estrategias de mitigación de riesgos directamente aplicables a sus operaciones.
Cómo identificar y resolver la interferencia de cocanal (CCI)
La interferencia de cocanal (CCI) es la causa principal de la degradación del rendimiento y la latencia elevada en implementaciones de WiFi empresariales de alta densidad, y ocurre cuando múltiples puntos de acceso comparten el mismo canal de frecuencia y se ven obligados a entrar en contienda CSMA/CA. Esta guía proporciona a los arquitectos de red, gerentes de TI y directores de operaciones de recintos un marco estructurado e independiente del proveedor para identificar la CCI a través de diagnósticos y analíticas de RF, y resolverla mediante la planificación de canales, la optimización de la potencia de transmisión, la gestión de tasas de datos y la ubicación física de los puntos de acceso. Dominar la resolución de la CCI es un requisito previo para ofrecer un WiFi de invitados confiable, conectividad operativa y un ROI medible en hoteles, cadenas de retail, estadios y de instalaciones del sector público.