Le 10 principali cause di timeout DHCP sulle reti wireless ad alta densità
Questa guida tecnica di riferimento identifica le dieci principali cause di timeout DHCP sulle reti wireless ad alta densità e fornisce strategie di risoluzione pratiche e indipendenti dai singoli vendor. Progettata per IT leader senior, architetti di rete e direttori delle operazioni delle location, copre principi ingegneristici approfonditi, workflow di implementazione passo-passo e risultati di business misurabili. Scopri come eliminare i colli di bottiglia della connessione e ottimizzare la tua infrastruttura wireless per offrire una connettività fluida negli ambienti aziendali più esigenti.
Ascolta questa guida
Visualizza trascrizione del podcast
Executive Summary
Nei moderni ambienti aziendali, come hotel ad alta capacità, centri commerciali, hub di trasporto e stadi, la connettività wireless è un fattore aziendale fondamentale. Tuttavia, l'esperienza degli ospiti spesso si interrompe proprio al primo passo dell'onboarding di rete: l'ottenimento di un indirizzo IP. Sulle reti wireless ad alta densità, i timeout DHCP (Dynamic Host Configuration Protocol) sono una delle cause principali di fallimento dell'onboarding più comuni ma spesso diagnosticate in modo errato. Quando centinaia o migliaia di dispositivi tentano di connettersi simultaneamente, le configurazioni DHCP tradizionali falliscono sotto il carico, lasciando gli utenti bloccati con una rotella di caricamento che gira o con un indirizzo link-local 169.254.x.x auto-assegnato.
Questa guida di riferimento tecnico autorevole esplora le prime dieci cause dei timeout DHCP sulle reti wireless ad alta densità. Supera la teoria accademica per fornire a senior network architect, CTO e direttori delle operazioni delle strutture strategie di risoluzione immediate e attuabili. Ottimizzando sistematicamente le dimensioni degli scope DHCP, riducendo i tempi di lease, implementando solide configurazioni Layer 2/3 e distribuendo architetture server ad alta disponibilità, le organizzazioni possono ridurre significativamente la latenza di connessione, eliminare gli ostacoli all'onboarding e proteggere la reputazione del proprio marchio. L'implementazione di queste best practice si correla direttamente con una migliore soddisfazione degli ospiti, un maggiore coinvolgimento con prodotti core come il Guest WiFi e una raccolta dati più ricca attraverso i WiFi Analytics .
Approfondimento Tecnico
Per diagnosticare e risolvere i timeout DHCP, gli ingegneri di rete devono innanzitutto comprendere i meccanismi precisi dell'handshake DHCP a quattro vie, comunemente noto come processo DORA (Discover, Offer, Request, Acknowledge) [1]. Negli ambienti ad alta densità, questo processo è estremamente sensibile alla perdita di pacchetti, alla latenza e all'esaurimento delle risorse.
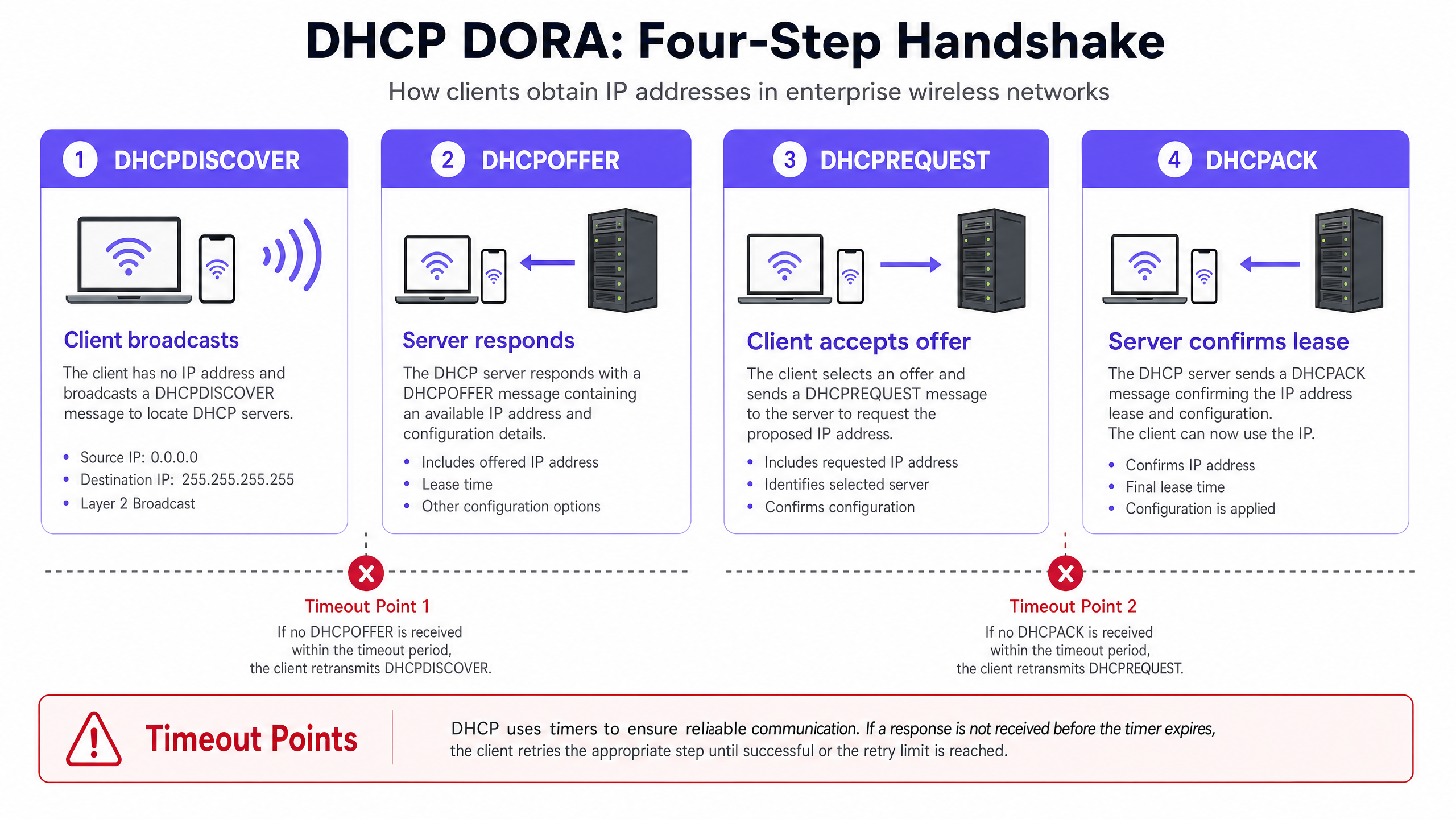
L'Handshake DHCP (DORA) nel Wireless ad Alta Densità
- DHCPDISCOVER (Broadcast): Il client wireless si associa all'Access Point (AP) e trasmette in broadcast un pacchetto per individuare i server DHCP disponibili. In un dominio di broadcast di grandi dimensioni, questo pacchetto viene inondato su tutte le porte, consumando prezioso tempo di trasmissione wireless.
- DHCPOFFER (Unicast/Broadcast): Ogni server DHCP attivo che riceve il messaggio di discover riserva un indirizzo IP e invia un'offerta al client, specificando i parametri di lease, la subnet mask, il gateway predefinito e i server DNS.
- DHCPREQUEST (Broadcast): Il client seleziona un'offerta (in genere la prima ricevuta) e trasmette in broadcast una richiesta per accettare quello specifico indirizzo IP, rifiutando implicitamente qualsiasi altra offerta.
- DHCPACK (Unicast/Broadcast): il server DHCP selezionato registra il lease nel proprio database e invia una conferma al client, convalidando l'assegnazione dell'IP e la durata del lease. Il client applica quindi questa configurazione.
L'impatto del sovraccarico wireless e della congestione del tempo di trasmissione (Airtime)
A differenza delle reti cablate in cui i broadcast di Livello 2 sono gestiti via hardware a velocità gigabit, le reti wireless trasmettono i frame broadcast e multicast alla tariffa dati minima obbligatoria (spesso 1 Mbps, 6 Mbps o 11 Mbps a seconda della configurazione dell'SSID) per garantire che tutti i client distanti possano riceverli [2]. Su un SSID ad alta densità con migliaia di dispositivi attivi, i pacchetti DHCP broadcast consumano una quantità sproporzionata di tempo di trasmissione RF, causando collisioni di pacchetti, ritrasmissioni e successivi timeout. Un dispositivo client si aspetta in genere una risposta DHCP entro 2-4 secondi; se la congestione dell'airtime ritarda una qualsiasi fase del processo DORA oltre questa finestra temporale, il client va in timeout, interrompe l'associazione e riprova, creando un carico a cascata sulla rete.
Le 10 principali cause dei timeout DHCP
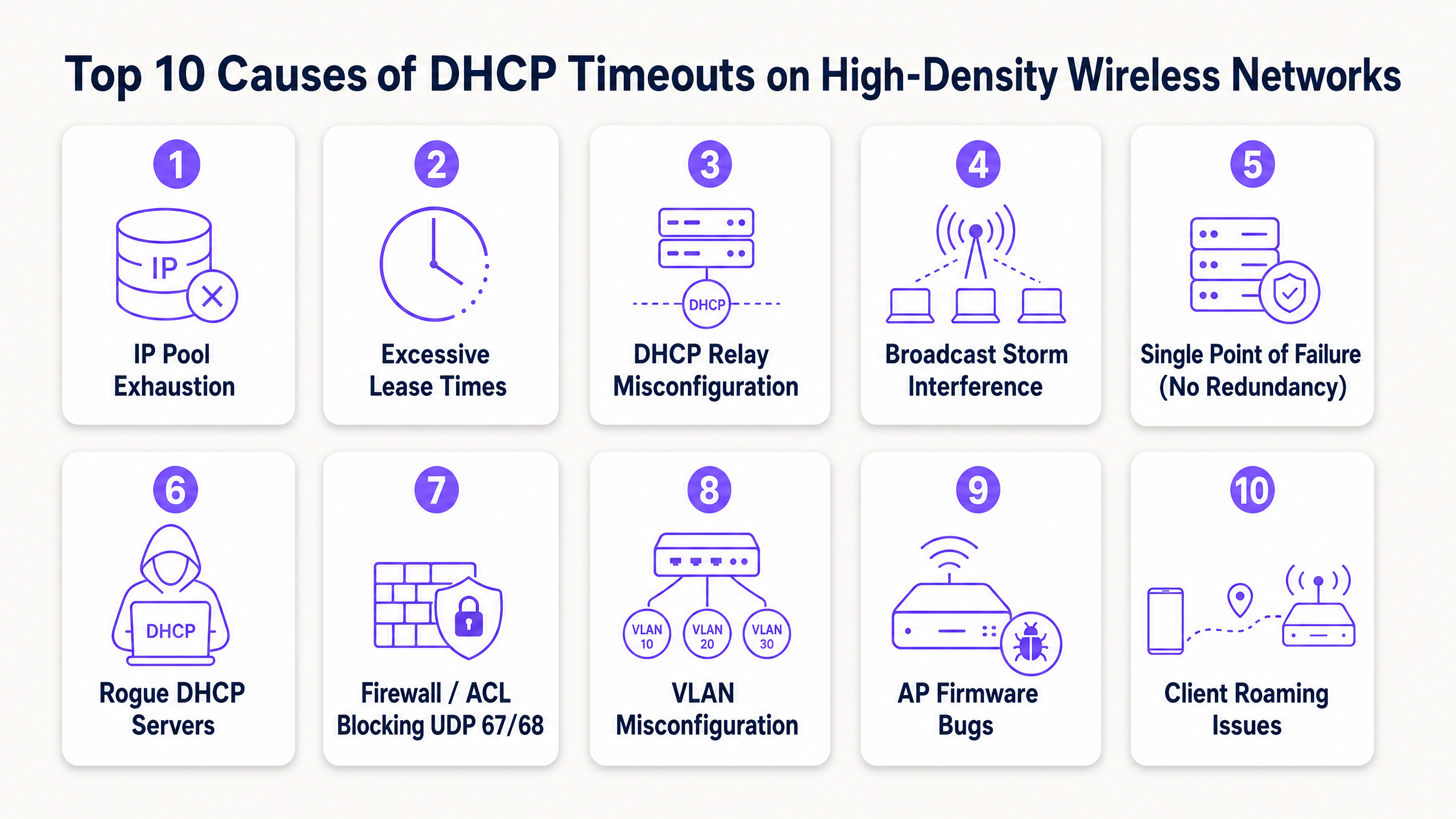
1. Esaurimento del pool di IP DHCP
Il meccanismo: l'ambito (scope) del server DHCP è troppo limitato per il volume di dispositivi transitori. Quando il pool è utilizzato al 100%, il server ignora silenziosamente i nuovi pacchetti DHCPDISCOVER poiché non ha indirizzi da offrire.
Il contesto ad alta densità: una subnet standard di Classe C (/24) fornisce solo 254 indirizzi IP utilizzabili. Nella hall di un hotel, ai varchi di uno stadio o nella sala plenaria di una conferenza, il numero di dispositivi simultanei può facilmente superare questo limite in pochi minuti. A peggiorare la situazione, molti utenti portano con sé più dispositivi connessi (telefoni, smartwatch, tablet, laptop), moltiplicando la richiesta di IP.
Risoluzione: ridimensiona correttamente gli ambiti di rete utilizzando la notazione CIDR (Classless Inter-Domain Routing). Passa le VLAN dei client ad alta densità a subnet /22 (1.022 IP) o /21 (2.046 IP). Assicurati che i tuoi strumenti di monitoraggio siano configurati per inviare avvisi all'80% di utilizzo del pool, in modo da consentire un'espansione proattiva dell'ambito prima degli eventi di picco.
2. Tempi di lease eccessivi sulle reti guest
Il meccanismo: il tempo di lease determina per quanto tempo un client conserva un indirizzo IP prima di doverlo rinnovare o rilasciare. Se il tempo di lease è troppo lungo, il server DHCP mantiene l'indirizzo nel proprio database, impedendone la riassegnazione a un nuovo client anche se il dispositivo originale ha lasciato la struttura.
Il contesto ad alta densità: molte configurazioni DHCP predefinite specificano un tempo di lease di 24 ore o 8 giorni. In ambienti pubblici o del settore hospitality ad alta rotazione, come un terminal dei trasporti o un centro commerciale, gli ospiti rimangono in genere per meno di due ore [3]. Con un lease di 24 ore, un ospite che si connette per 10 minuti consuma un indirizzo IP per un giorno intero, portando a un esaurimento artificiale del pool. Risoluzione: Allineare i tempi di lease con i tempi di permanenza dei client. Implementare un tempo di lease da 30 a 60 minuti per le reti guest. Per le reti del personale aziendale, in cui i dispositivi rimangono connessi per un intero turno, utilizzare un tempo di lease da 8 a 12 ore. Ciò garantisce il rapido recupero degli indirizzi IP dai client che hanno abbandonato la rete.
3. Errata configurazione del DHCP Relay Agent
Il meccanismo: Poiché i messaggi di DHCP discovery sono broadcast di Livello 2, non possono superare i confini del router (Livello 3). Un DHCP Relay Agent (solitamente configurato su uno switch di Livello 3 o su un gateway di sicurezza utilizzando comandi come ip helper-address di Cisco) deve intercettare questi broadcast e inoltrarli come pacchetti unicast al server DHCP centrale [4]. Se il relay agent è configurato in modo errato, presenta l'IP helper sbagliato o viene omesso da una VLAN appena creata, il traffico DHCP verrà bloccato.
Il contesto ad alta densità: Le reti ad alta densità si affidano fortemente alla segmentazione VLAN per limitare i domini di broadcast. Quando si distribuisce un nuovo SSID o si amplia una sede, i tecnici creano spesso nuove VLAN client. Se la configurazione del relay agent non viene aggiornata sulle corrispondenti interfacce di Livello 3, i client su quelle VLAN subiranno timeout DHCP immediati.
Risoluzione: Stabilire modelli di configurazione rigorosi per tutti gli switch di Livello 3. Assicurarsi che ogni interfaccia VLAN client disponga di una coppia ridondante di indirizzi DHCP helper che puntano ai server DHCP primario e secondario. Verificare il routing end-to-end tra l'IP dell'interfaccia di relay (che il server DHCP utilizza per determinare quale scope di sottorete assegnare) e il server DHCP stesso.
4. Storm di broadcast e multicast
Il meccanismo: Un traffico broadcast o multicast eccessivo su una VLAN satura il mezzo wireless. Poiché il wireless è un mezzo condiviso half-duplex, gli AP e i client devono attendere che le frequenze siano libere prima di trasmettere. Uno storm di broadcast, spesso causato da loop di commutazione, schede di rete guaste o protocolli peer-to-peer aggressivi, riempie il tempo di trasmissione, causando l'accodamento, il ritardo o la perdita dei pacchetti DHCP.
Il contesto ad alta densità: Nelle reti wireless ampie e piatte senza un adeguato isolamento di Livello 2, il traffico broadcast peer-to-peer (come Apple AirPlay, Google Chromecast o l'individuazione di rete di Windows) viene replicato da ogni AP sulla VLAN. In una sede con 10.000 utenti, questo "chiacchiericcio" di sottofondo può consumare oltre il 50% della larghezza di banda wireless disponibile, lasciando un tempo di trasmissione insufficiente per i pacchetti critici di handshake DHCP.
Risoluzione: Abilitare il Client Isolation (noto anche come blocco peer-to-peer) sul controller wireless per impedire ai client di comunicare direttamente tra loro. Configurare la Soppressione di broadcast e multicast sugli AP e sugli switch, limitando il traffico broadcast a una piccola percentuale della capacità del collegamento (ad esempio, 100 pacchetti al secondo). Laddove supportato, abilitare il DHCP Proxy sugli AP per convertire le offerte e i riconoscimenti DHCP broadcast in frame unicast diretti specificamente al client richiedente.
5. Single Point of Failure (Mancanza di ridondanza DHCP)
Il meccanismo: Un server DHCP singolo e non ridondato rappresenta una vulnerabilità critica. Se il server si arresta in modo anomalo, subisce aggiornamenti di sistema o perde la connettività di rete, la capacità di onboarding dell'intera rete si interrompe immediatamente. I lease esistenti rimangono attivi, ma nessun nuovo client può ottenere un indirizzo IP e i client in roaming non possono rinnovare i propri lease.
Il contesto ad alta densità: Le sedi ad alta densità operano nel rispetto di SLA operativi molto rigidi. Uno stadio durante una partita o un centro congressi durante un keynote non possono tollerare nemmeno cinque minuti di inattività del DHCP. Affidarsi a un singolo router o a una singola macchina virtuale per gestire migliaia di richieste rapide di lease è un'architettura ad alto rischio.
Risoluzione: Distribuisci il DHCP in una configurazione ad alta disponibilità. Utilizza il DHCP Failover di Windows Server in modalità Load Balance (suddivisione 50/50) o in modalità Hot Standby, oppure implementa appliance DHCP ridondanti di livello enterprise (come Infoblox o BlueCat) [5]. Assicurati che i server DHCP siano distribuiti fisicamente o logicamente su diversi hypervisor e percorsi di rete per eliminare i guasti di tipo common-mode.
6. Server DHCP non autorizzati (Rogue DHCP)
Il meccanismo: Un server DHCP rogue è un dispositivo non autorizzato abilitato al DHCP e connesso alla rete. Intercetta i broadcast DHCPDISCOVER dei client e risponde con i propri pacchetti DHCPOFFER, spesso distribuendo configurazioni IP errate, gateway predefiniti errati o server DNS dannosi.
Il contesto ad alta densità: In grandi sedi, punti vendita o uffici del settore pubblico, le porte ethernet fisiche sono spesso accessibili nelle aree pubbliche, oppure gli utenti possono portare dispositivi non autorizzati (come router di viaggio consumer o macchine virtuali con rete a ponte) e collegarli alla presa a muro. Ciò comporta conflitti di indirizzi IP, black hole di routing e gravi rischi per la sicurezza, inclusi gli attacchi man-in-the-middle.
Risoluzione: Abilita il DHCP Snooping su tutti gli switch di accesso e distribuzione [6]. Il DHCP snooping designa le porte dello switch come "attendibili" (connesse a server DHCP o agenti relay legittimi) o "non attendibili" (connesse ai client). Lo switch scarterà automaticamente qualsiasi risposta del server DHCP (come DHCPOFFER o DHCPACK) proveniente da una porta non attendibile, neutralizzando istantaneamente i server rogue.
7. Firewall, ACL e criteri di sicurezza che bloccano le porte UDP 67/68
Il meccanismo: Il DHCP si affida alla porta UDP 67 (ascolto lato server e destinazione lato client) e alla porta UDP 68 (ascolto lato client e destinazione lato server). Se i firewall di rete, le liste di controllo degli accessi (ACL) degli switch o i criteri di sicurezza degli endpoint bloccano queste porte, l'handshake DORA non può essere completato.
Il contesto ad alta densità: Il rafforzamento della sicurezza è una priorità per le reti aziendali. Tuttavia, policy di sicurezza eccessivamente aggressive spesso bloccano inavvertitamente il traffico DHCP. Ad esempio, durante la migrazione di un firewall o l'aggiornamento di una policy, un amministratore potrebbe bloccare tutto il traffico UDP su un segmento senza rendersi conto di aver interrotto il percorso DHCP. Allo stesso modo, le policy di sicurezza delle VLAN guest devono consentire esplicitamente le porte UDP 67 e 68 prima di reindirizzare il traffico verso un Captive Portal.
Risoluzione: Controllare tutte le ACL e le regole del firewall lungo il percorso tra i client wireless, gli AP, gli switch Layer 3 e i server DHCP. Assicurarsi che le porte UDP 67 e 68 siano esplicitamente consentite in entrambe le direzioni. Durante la risoluzione dei problemi, eseguire un'acquisizione di pacchetti sull'interfaccia di rete del server DHCP per confermare che i pacchetti DHCPDISCOVER stiano effettivamente arrivando.
8. Errori di configurazione di VLAN e Trunking
Il meccanismo: Se l'SSID di un client è mappato su una VLAN specifica, ma tale VLAN non è correttamente taggata o configurata in trunk end-to-end attraverso l'infrastruttura di switching, i broadcast DHCP del client non raggiungeranno mai il gateway predefinito o l'agente di relay DHCP.
Il contesto ad alta densità: Le reti wireless ad alta densità utilizzano l'assegnazione dinamica delle VLAN o il pooling multi-VLAN per distribuire il carico dei client. Se a una singola porta trunk dello switch lungo il percorso dall'AP allo switch core manca un tag VLAN nell'elenco dei consentiti, un sottoinsieme di client (nello specifico quelli assegnati a quella VLAN) subirà timeout DHCP immediati e persistenti, mentre altri client sullo stesso SSID si connetteranno correttamente. Ciò crea scenari di risoluzione dei problemi altamente intermittenti e difficili da diagnosticare.
Risoluzione: Implementare strumenti automatizzati di gestione e convalida della configurazione di rete. Quando si configurano le porte trunk dello switch, utilizzare sempre elenchi di consentiti espliciti (ad es. switchport trunk allowed vlan 10,20,30) anziché affidarsi alle configurazioni predefinite "all", e verificare che la VLAN nativa corrisponda su entrambe le estremità del collegamento trunk per prevenire perdite di traffico non taggato.
9. Bug del firmware dell'Access Point e dei driver
Il meccanismo: Il firmware dell'access point è responsabile del bridging dei frame wireless 802.11 sulla rete ethernet cablata 802.3. Un bug software nel driver wireless dell'AP o nel motore di bridging può causare la perdita di pacchetti DHCP da parte dell'AP, in particolare in condizioni di carico elevato di CPU o memoria.
Il contesto ad alta densità: Le reti ad alta densità spingono l'hardware e il software degli AP al limite. Un bug che rimane latente con un carico leggero di 10 client può causare guasti catastrofici quando l'AP gestisce 100 client attivi contemporaneamente. Ad esempio, un bug documentato all'inizio del 2026 su alcuni AP WiFi 7 causava la perdita intermittente da parte dell'AP del terzo pacchetto dell'handshake (il DHCPREQUEST), impedendo al client di ricevere il proprio DHCPACK e di completare l'onboarding.
Risoluzione: Mantenere una rigorosa politica di gestione del ciclo di vita per il firmware degli AP. Evitare di distribuire release di firmware "all'avanguardia" direttamente negli ambienti di produzione. Stabilire un ambiente di staging che imiti le condizioni ad alta densità e monitorare attentamente le note di rilascio dei fornitori e i forum della community per individuare bug noti relativi al DHCP. Se la risoluzione dei problemi rivela che i pacchetti DHCPDISCOVER vengono inviati dal client ma non vengono mai visualizzati sulla porta di uplink cablata dell'AP, sospettare un bug di bridging dell'AP.
10. Roaming aggressivo dei client e confini Layer 3
Il meccanismo: Quando un client wireless si sposta (roaming) da un AP all'altro, deve mantenere la propria sessione di rete. Se il roaming attraversa un confine Layer 3 (spostando il client su una subnet diversa), il client deve ottenere un nuovo indirizzo IP. Se il sistema operativo del client o la rete wireless non riescono a gestire questa transizione in modo fluido, il client tenterà di utilizzare il suo vecchio indirizzo IP sulla nuova subnet, causando timeout di connessione e fallimenti nella rinegoziazione DHCP.
Il contesto ad alta densità: Le sedi ad alta densità richiedono centinaia di AP per fornire una copertura adeguata. I client sono costantemente in movimento, ad esempio gli ospiti di un hotel che camminano dalle loro camere alla sala conferenze, o gli acquirenti che si spostano all'interno di un centro commerciale [7]. Se l'architettura di rete mappa diverse aree fisiche della sede su subnet diverse, si verificherà un volume elevato di roaming Layer 3, sovraccaricando il server DHCP con rapidi eventi di rilascio e richiesta.
Risoluzione: Progettare reti wireless ad alta densità utilizzando un'architettura Layer 2 piatta su tutto l'SSID del client, oppure implementare il tunnelling basato su controller wireless (come GRE o CAPWAP) [8]. Il tunnelling garantisce che il traffico di un client sia sempre ancorato al controller domestico e alla VLAN originali, indipendentemente dall'AP fisico su cui si sposta, eliminando completamente gli eventi di roaming Layer 3 e il relativo sovraccarico DHCP.
Guida all'implementazione
Per eliminare sistematicamente i timeout DHCP, gli architetti di rete devono passare da una risoluzione dei problemi reattiva a un'architettura standardizzata e proattiva. Seguire questa guida passo-passo per rafforzare l'infrastruttura DHCP.
Passaggio 1: Dimensionamento della subnet e architettura CIDR
Non utilizzare mai subnet /24 standard per reti guest ad alta densità. Calcolare i requisiti IP in base alla capacità di picco più un margine del 50% per accogliere utenti multi-dispositivo e il turnover temporaneo.
| Subnet Mask | CIDR | Indirizzi IP utilizzabili | Miglior caso d'uso |
|---|---|---|---|
255.255.255.0 |
/24 |
254 | Personale amministrativo, stampanti, IoT di back-of-house |
255.255.254.0 |
/23 |
510 | Piccoli boutique hotel, negozi al dettaglio localizzati |
255.255.252.0 |
/22 |
1.022 | Grandi hotel, sale conferenze ad alta densità, campus scolastici |
255.255.248.0 |
/21 |
2.046 | Grandi padiglioni espositivi, centri commerciali, piazze pubbliche |
255.255.240.0 |
/20 |
4.094 | Stadi, arene, enormi centri congressi |
Passaggio 2: Ottimizzazione dei tempi di lease DHCP
Configura il tuo server DHCP per applicare tempi di lease basati sul comportamento degli utenti del segmento di rete specifico:
Guest WiFi SSID (Elevato Churn) -> Tempo di Lease: da 30 a 60 Minuti
Corporate Staff SSID (Stabile) -> Tempo di Lease: da 8 a 12 Ore
Venue IoT & Infrastructure -> Tempo di Lease: 7 Giorni (o Riservazione Statica)
Nota: La riduzione dei tempi di lease aumenta la frequenza delle richieste di rinnovo DHCP (che avvengono al 50% della durata del lease, noto come T1) [9]. Assicurati che l'hardware del tuo server DHCP disponga di prestazioni CPU e I/O sufficienti per gestire la frequenza di richieste elevata.
Passaggio 3: Configurazione degli Agenti DHCP Relay sugli Switch Layer 3
Quando configuri gli agenti DHCP relay, specifica sempre indirizzi helper ridondanti che puntano a server DHCP indipendenti. Di seguito è riportato un modello di configurazione standard e indipendente dal fornitore per un'interfaccia switch Cisco iOS Layer 3:
interface Vlan30
description High_Density_Guest_WiFi
ip address 192.168.30.1 255.255.252.0
ip helper-address 10.10.10.10 # Server DHCP Primario
ip helper-address 10.10.10.11 # Server DHCP Secondario
ip dhcp relay information option # Inserisci l'Opzione 82 per il tracciamento della posizione
no shutdown
Passaggio 4: Rafforzare la Sicurezza Layer 2 con il DHCP Snooping
Previeni i server DHCP non autorizzati e mitiga gli attacchi di DHCP starvation abilitando il DHCP snooping su tutta la tua infrastruttura di switching. Di seguito è riportato un modello di configurazione per uno switch di accesso edge:
# Abilita il DHCP snooping a livello globale
ip dhcp snooping
# Abilita il DHCP snooping per VLAN client specifiche
ip dhcp snooping vlan 10,20,30
# Configura la porta di uplink verso lo switch core/server DHCP come TRUSTED
interface GigabitEthernet1/0/48
description UPLINK_TO_CORE
ip dhcp snooping trust
# Configura le porte rivolte verso i client come UNTRUSTED e limita la frequenza dei pacchetti DHCP per prevenire attacchi di starvation
interface range GigabitEthernet1/0/1 - 47
description CLIENT_ACCESS_PORTS
ip dhcp snooping limit rate 15
Best Practice
Per mantenere una rete wireless resiliente e ad alte prestazioni, integra queste best practice standard del settore nei tuoi manuali operativi:
1. Implementa l'Opzione DHCP 82 (Relay Agent Information Option)
L'Opzione DHCP 82 consente all'agente relay di inserire informazioni specifiche sul circuito (come l'ID della porta dello switch o l'indirizzo MAC dell'AP) nella richiesta DHCP prima di inoltrarla al server [10]. Ciò consente al server DHCP di applicare criteri di allocazione IP altamente granulari in base alla posizione fisica del client all'interno della struttura. Ad esempio, un hotel può assegnare pool IP o impostazioni DNS diversi ai client nel centro congressi rispetto a quelli nelle camere degli ospiti, ottimizzando l'utilizzo del pool.
2. Abilita la Conversione da Broadcast a Unicast per ARP e DHCP
Configura il tuo controller LAN wireless (WLC) o gli AP gestiti in cloud per intercettare i pacchetti broadcast ARP e DHCP di Livello 2 e convertirli in frame unicast prima di trasmetterli via etere. Poiché i frame unicast vengono trasmessi alla massima velocità di trasmissione dati supportata dal client (anziché alla tariffa broadcast obbligatoria più bassa), questa semplice modifica della configurazione riduce drasticamente il consumo di tempo di trasmissione RF e migliora l'affidabilità del DHCP in ambienti ad alta densità.
3. Stabilisci un Monitoraggio e un Sistema di Allerta DHCP Proattivi
Non aspettare che gli utenti segnalino problemi di connessione. Configura il tuo Network Management System (NMS) o gli strumenti di monitoraggio del server DHCP per tracciare le metriche chiave e attivare avvisi immediati:
- Utilizzo del Pool: Attiva un avviso di avvertimento al 75% di utilizzo e un avviso critico all'85%.
- Frequenza delle Richieste DHCP: Monitora picchi improvvisi di richieste, che possono indicare una tempesta di broadcast, un loop di roaming o un attacco di DHCP starvation.
- Distribuzione della Scadenza dei Lease: Assicurati che i lease scadano in modo regolare e che il database stia recuperando attivamente gli indirizzi IP.
Risoluzione dei Problemi e Mitigazione dei Rischi
Quando si sospetta un timeout DHCP, segui questo flusso di lavoro diagnostico sistematico per isolare rapidamente il punto di errore e ridurre al minimo l'interruzione dell'attività aziendale.
[Il Client si associa all'AP]
│
▼
[Cattura Pacchetti sul Client] ───► Il DHCPDISCOVER viene inviato?
│ ├── NO: Problema del driver/OS del client.
│ └── SÌ
▼
[Cattura Pacchetti sullo Switch] ───► Il DHCPDISCOVER arriva allo Switch?
│ ├── NO: Problema di bridging AP/tagging VLAN.
│ └── SÌ
▼
[Cattura Pacchetti sul Server] ───► Il DHCPDISCOVER arriva al Server?
│ ├── NO: Problema di Relay Agent / Routing / Firewall.
│ └── SÌ
▼
[Controlla i Log del Server] ───────────► Il DHCPOFFER viene inviato?
├── NO: Pool esaurito / Scope non attivo.
└── SÌ: Percorso di ritorno bloccato (VLAN/Routing).
Comandi Chiave per la Risoluzione dei Problemi
Per verificare lo stato del DHCP e diagnosticare i guasti sulle apparecchiature di rete attive, utilizza i seguenti comandi:
Cisco IOS (Server DHCP o Relay)
# Visualizza l'utilizzo del pool DHCP e gli indirizzi liberi
show ip dhcp pool
# Visualizza i binding degli indirizzi IP attivi
show ip dhcp binding
# Monitora le statistiche del server DHCP (conteggi di discover, request, ack)
show ip dhcp server statistics
# Visualizza il database dei conflitti DHCP (IP contrassegnati come non validi a causa di conflitti)
show ip dhcp conflict
Linux (Server o Client DHCP)
# Visualizza le richieste di lease del client DHCP in tempo reale su un client Linux
sudo dhclient -v wlan0
# Cattura il traffico DHCP (porte UDP 67 e 68) su un'interfaccia specifica
sudo tcpdump -i eth0 -n -vv 'udp and (port 67 or port 68)'
# Controlla il database dei lease DHCP di dnsmasq
cat /var/lib/misc/dnsmasq.leases
Windows (Client DHCP)
# Rilascia l'indirizzo IP corrente
ipconfig /release
# Rinnova l'indirizzo IP (avvia un nuovo handshake DHCP)
ipconfig /renew
ROI e impatto aziendale
Investire in un'infrastruttura DHCP altamente resiliente e ben progettata non è solo una necessità tecnica, ma un fattore abilitante fondamentale per il business che influisce direttamente sui profitti e sull'efficienza operativa.
Quantificare il valore aziendale di un onboarding senza interruzioni
- Miglioramento della guest experience e della fedeltà al brand: Nei settori dell'ospitalità e degli eventi, la connettività wireless è uno dei principali fattori di soddisfazione degli ospiti. Un ospite che riscontra attriti durante l'onboarding è molto propenso a lasciare recensioni negative, con un impatto diretto sulle prenotazioni. L'eliminazione dei timeout DHCP garantisce una prima impressione senza attriti.
- Massimizzazione del ROI del marketing tramite Guest WiFi: Per i punti vendita e i luoghi di intrattenimento, il Guest WiFi è un potente canale di marketing. Garantendo un tasso di successo dell'onboarding del 100%, i team di marketing possono acquisire più dati di prima parte (come e-mail, dati demografici e modelli di traffico pedonale) attraverso WiFi Analytics , guidando campagne di coinvolgimento altamente mirate e aumentando il valore del ciclo di vita del cliente.
- Riduzione dei costi di supporto IT: I ticket relativi al DHCP ("Impossibile connettersi al WiFi", "Errore indirizzo IP") sono tra le richieste più frequenti e dispendiose in termini di tempo per gli helpdesk IT. Implementando la ridondanza DHCP, dimensionando correttamente i pool e distribuendo il DHCP snooping, le organizzazioni possono ridurre i ticket di supporto relativi al wireless fino al 40%, consentendo al personale IT di concentrarsi su iniziative strategiche anziché sulla risoluzione di problemi di base.
- Garantire la conformità normativa e la sicurezza: L'implementazione del DHCP snooping e la mitigazione dei server DHCP non autorizzati supportano direttamente la conformità con i principali standard di sicurezza, come PCI DSS (per gli ambienti di pagamento al dettaglio) e GDPR (mettendo in sicurezza le reti di dati degli ospiti). Un'architettura DHCP sicura e ben documentata riduce il rischio di costose violazioni dei dati e sanzioni normative.
Tabella riassuntiva dell'impatto aziendale
| Metrica | Prima dell'ottimizzazione | Dopo l'ottimizzazione | Impatto aziendale |
|---|---|---|---|
| Tasso di timeout DHCP | 8,5% (Nelle ore di punta) | < 0,1% | Onboarding degli utenti senza interruzioni, eliminazione dei reclami di connessione |
| Tempo medio di risoluzione (MTTR) | 45 minuti | < 5 minuti | Risoluzione rapida dei problemi grazie alla mappatura documentata di VLAN/scope |
| Tasso di opt-in al Guest WiFi | 62% | 88% | Maggiore crescita del database di marketing, acquisizione di dati più ricchi |
| Volume dei ticket di supporto IT | Alto (errori DHCP/IP) | Trascurabile | Riduzione del 40% dei ticket di helpdesk relativi al wireless |
Riferimenti
- IETF RFC 2131 - Dynamic Host Configuration Protocol
- IEEE 802.11-2020 - Wireless LAN Medium Access Control and Physical Layer Specifications
- Ottimizzazione dei tempi di lease DHCP WiFi per i dispositivi mobili
- IETF RFC 3046 - DHCP Relay Agent Information Option
- IETF RFC 8156 - DHCPv4 Failover Protocol
- Cisco Systems - Configurazione del DHCP Snooping
- Perché il WiFi degli stadi si blocca (e come risolvere)
- HPE Aruba Networking - Guida alla progettazione e all'implementazione del Wi-Fi in grandi spazi pubblici
- Come risolvere i problemi DHCP sulle reti WiFi
- IETF RFC 3993 - Subscriber-ID Sub-Option for DHCP Relay Agent Information Option
Definizioni chiave
DHCP (Dynamic Host Configuration Protocol)
Un protocollo di gestione di rete utilizzato sulle reti IP (Internet Protocol) in base al quale un server DHCP assegna dinamicamente un indirizzo IP e altri parametri di configurazione di rete a ciascun dispositivo su una rete, consentendo loro di comunicare con altre reti IP.
Il DHCP è il primo passo fondamentale per l'onboarding wireless; se fallisce, i client non possono accedere a nessuna risorsa di rete, inclusi i portali per gli ospiti.
Processo DORA
La sequenza standard di quattro passaggi di messaggi scambiati tra un client DHCP e un server per negoziare il lease di un indirizzo IP: DHCPDISCOVER, DHCPOFFER, DHCPREQUEST e DHCPACK.
La comprensione della sequenza DORA è essenziale per diagnosticare il punto in cui un handshake DHCP sta fallendo durante la risoluzione dei problemi di rete.
DHCP Relay Agent
Qualsiasi host o dispositivo di rete (in genere uno switch o un router Layer 3) che inoltra i pacchetti DHCP tra client e server quando risiedono su subnet o VLAN diverse.
Gli agenti di relay sono necessari nelle reti aziendali segmentate per centralizzare i servizi DHCP ed evitare che il traffico broadcast superi i confini del router.
DHCP Snooping
Una funzionalità di sicurezza Layer 2 integrata negli switch gestiti che filtra i messaggi DHCP non attendibili e crea un database di binding di mappature attendibili da MAC a IP.
Il DHCP snooping è la difesa principale contro i server DHCP non autorizzati e gli attacchi man-in-the-middle sulle reti wireless aziendali.
Esaurimento del Pool IP
Una condizione che si verifica quando tutti gli indirizzi IP disponibili all'interno dello scope configurato di un server DHCP sono stati assegnati, non lasciando alcun indirizzo disponibile per i nuovi client.
L'esaurimento del pool è la causa principale dei timeout DHCP nei luoghi ad alta densità e si risolve dimensionando correttamente gli scope o riducendo i tempi di lease.
DHCP Lease Time
La durata di tempo per cui un server DHCP alloca un indirizzo IP a uno specifico dispositivo client prima che il client debba richiedere il rinnovo del lease.
L'ottimizzazione dei tempi di lease in base al comportamento degli utenti (brevi per le reti ospiti, più lunghi per il personale) è fondamentale per mantenere l'efficienza del pool IP.
Rogue DHCP Server
Un server DHCP non autorizzato collegato a una rete, che distribuisce configurazioni IP non valide o dannose ai client, causando problemi di connettività e vulnerabilità di sicurezza.
I server non autorizzati sono comuni nei luoghi pubblici aperti e vengono neutralizzati abilitando il DHCP snooping sugli switch di accesso.
Soppressione del Broadcast
Una tecnica di configurazione di rete che limita la velocità del traffico broadcast e multicast su una VLAN o una porta dello switch per prevenire la congestione della rete e le tempeste di broadcast.
La soppressione del broadcast è fondamentale nelle reti wireless ad alta densità per proteggere il tempo di trasmissione RF e garantire che i pacchetti DHCP critici non subiscano ritardi.
Esempi pratici
Un centro congressi ad alta densità con una sala plenaria principale progettata per ospitare 2.500 partecipanti riscontra enormi fallimenti di onboarding WiFi durante il discorso di apertura. I partecipanti riferiscono che i loro dispositivi rimangono bloccati su "Acquisizione indirizzo IP" per diversi minuti, e coloro che riescono a connettersi vengono frequentemente disconnessi quando si spostano tra la sala plenaria e l'area espositiva. L'attuale configurazione di rete utilizza una singola VLAN client mappata su una subnet standard `/24` con un tempo di lease DHCP di 24 ore, servita da un singolo router core. Come dovrebbe essere riprogettata questa rete per eliminare questi problemi?
Per risolvere questi problemi di onboarding, l'architettura di rete deve essere riprogettata per gestire il comportamento dei client transitori ad alta densità. Seguire questo flusso di lavoro di risoluzione in più fasi:
Espandere lo spazio degli indirizzi IP (Dimensionamento della subnet): Sostituire la subnet standard
/24(che fornisce solo 254 indirizzi IP) con una subnet/21(che fornisce 2.046 indirizzi IP utilizzabili) o implementare un pool multi-VLAN. Ciò garantisce che il pool IP sia sufficientemente dimensionato per gestire 2.500 partecipanti simultanei, molti dei quali avranno con sé più dispositivi connessi (media di 1,5 dispositivi per partecipante = 3.750 IP richiesti). Se si utilizza una singola subnet piatta/20(4.094 IP), questa ospiterà facilmente l'intera capacità dell'evento.Ottimizzare i tempi di lease DHCP: Ridurre il tempo di lease DHCP da 24 ore a 45 minuti sulla rete wireless guest. Poiché i partecipanti alla conferenza sono altamente transitori e si spostano dentro e fuori dalla sala plenaria, un tempo di lease breve garantisce che gli indirizzi IP vengano rapidamente recuperati dai dispositivi che hanno lasciato l'area, prevenendo l'esaurimento artificiale del pool.
Distribuire server DHCP ridondanti: Eliminare il singolo punto di errore distribuendo una coppia di server DHCP ridondanti. Configurare il failover DHCP di Windows Server in modalità Load Balance (suddivisione 50/50) su due macchine virtuali indipendenti, oppure utilizzare un'appliance DHCP dedicata ad alta disponibilità. Ciò garantisce che se un server o un percorso di rete si guasta, il server rimanente possa gestire l'intero carico di richieste.
Implementare la soppressione del broadcast di Layer 2 e il DHCP Proxy: Abilitare la soppressione del broadcast sul controller wireless, limitando il traffico di broadcast a 100 pacchetti al secondo. Abilitare il DHCP Proxy sugli access point per convertire i messaggi broadcast
DHCPOFFEReDHCPACKin frame unicast. Ciò riduce drasticamente il consumo di tempo di trasmissione wireless e previene le collisioni di pacchetti.Configurare DHCP Snooping e validazione ARP: Abilitare il DHCP snooping su tutti gli switch di accesso per proteggere la rete da server DHCP non autorizzati e prevenire attacchi di DHCP starvation. Limitare la frequenza dei pacchetti DHCP sulle porte rivolte ai client a 15 pacchetti al secondo.
Un hotel di lusso con 500 camere sta distribuendo un nuovo SSID guest in tutta la proprietà. Il team di rete ha creato una nuova VLAN guest (VLAN 50) e configurato un server DHCP Windows centrale con un corrispondente ambito `/22`. Tuttavia, durante i test, i dispositivi associati all'SSID guest nelle camere dell'hotel non riescono a ottenere un indirizzo IP e vanno in timeout, mentre i dispositivi collegati direttamente alle porte cablate negli uffici amministrativi (VLAN 10) ottengono gli indirizzi IP istantaneamente. Qual è la causa più probabile di questo problema e come dovrebbe essere diagnosticato e risolto?
Il fatto che i client cablati sulla VLAN 10 ottengano gli indirizzi IP mentre i client wireless sulla VLAN 50 vadano in timeout indica che il problema è specifico del percorso o della configurazione della VLAN 50. La causa più probabile è un DHCP Relay Agent (IP Helper) mancante o configurato in modo errato sull'interfaccia dello switch Layer 3 per la VLAN 50, oppure un tag VLAN mancante lungo il percorso trunk tra gli Access Point e lo switch core. Seguire questo flusso di lavoro di diagnosi e risoluzione:
Verificare la configurazione del DHCP Relay Agent: Accedere allo switch Layer 3 core (o gateway) e ispezionare la configurazione per l'interfaccia VLAN 50. Assicurarsi che il comando
ip helper-addresssia presente e punti all'indirizzo IP corretto del server DHCP Windows. Se il comando manca, lo switch non inoltrerà i pacchetti broadcastDHCPDISCOVERdel client al server DHCP.Controllare il trunking VLAN end-to-end: Verificare che la VLAN 50 sia taggata su tutte le porte dello switch lungo il percorso dagli AP allo switch core. Utilizzare comandi come
show interfaces trunksugli switch Cisco per confermare che la VLAN 50 sia consentita e attiva su tutti i collegamenti trunk. Se la VLAN 50 manca anche da una sola porta trunk, i broadcast DHCP dei client verranno scartati prima di raggiungere lo switch Layer 3.Eseguire catture di pacchetti: Per isolare il punto di errore, eseguire catture di pacchetti simultanee in tre posizioni:
- Sul client wireless (utilizzando Wireshark o strumenti nativi del sistema operativo) per confermare che i broadcast
DHCPDISCOVERvengano inviati. - Sull'interfaccia dello switch Layer 3 per la VLAN 50 per confermare che lo switch riceva i broadcast.
- Sull'interfaccia di rete del server DHCP per confermare che i pacchetti DHCP unicast inoltrati stiano arrivando.
- Sul client wireless (utilizzando Wireshark o strumenti nativi del sistema operativo) per confermare che i broadcast
Verificare l'attivazione dell'ambito del server DHCP: Assicurarsi che l'ambito DHCP per la subnet della VLAN 50 (ad esempio, 192.168.50.0/22) sia completamente creato, attivato e disponga di un intervallo attivo di indirizzi IP che non sia in conflitto con alcuna assegnazione statica.
Applicare la correzione della configurazione: Sul terzo switch Layer 3 core, applicare la corretta configurazione dell'indirizzo helper:
interface Vlan50 description Guest_WiFi_VLAN ip address 192.168.50.1 255.255.252.0 ip helper-address 10.10.10.10 # IP del server DHCP Windows no shutdown
Un grande centro commerciale con oltre 150 negozi al dettaglio riscontra interruzioni della connessione WiFi altamente intermittenti. Il team IT riferisce che alcuni clienti si connettono istantaneamente e navigano senza problemi, mentre altri nella stessa posizione rimangono bloccati su "Acquisizione indirizzo IP" o ricevono un avviso "Nessuna connessione Internet". Un esame dei log del server DHCP mostra migliaia di lease attivi, ma anche un volume elevato di errori "Conflitto DHCP" e diversi casi in cui il server risponde ai client con un `DHCPNAK` (Negative Acknowledgement). Come dovrebbe essere analizzato e risolto questo problema?
La presenza di errori "Conflitto DHCP" e risposte DHCPNAK nei log del server suggerisce fortemente la presenza di un server DHCP non autorizzato sulla rete o un conflitto di indirizzi IP causato da assegnazioni statiche all'interno dell'intervallo DHCP. Seguire questo flusso di lavoro sistematico di indagine e risoluzione:
Isolare e rilevare il server DHCP non autorizzato: Utilizzare i log del database di DHCP snooping sugli switch di accesso per identificare l'attività di server DHCP non autorizzati. Eseguire il seguente comando sugli switch core e di accesso per visualizzare eventuali conflitti rilevati o pacchetti DHCP non attendibili:
show ip dhcp snooping database show ip dhcp conflictIl database dei conflitti elencherà gli indirizzi MAC dei dispositivi che hanno risposto ai probe ARP per gli IP che il server DHCP stava tentando di assegnare, o i dispositivi che stanno distribuendo attivamente lease non autorizzati.
Abilitare il DHCP Snooping a livello globale e sulle VLAN client: Per neutralizzare immediatamente qualsiasi server DHCP non autorizzato, abilitare il DHCP snooping su tutti gli switch. Configurare tutte le porte rivolte ai client come non attendibili e considerare attendibili solo le porte specifiche collegate ai server DHCP legittimi o ai collegamenti trunk core. Ciò garantisce che eventuali pacchetti
DHCPOFFERoDHCPACKnon autorizzati vengano scartati sulla porta dello switch prima che possano raggiungere altri client.Configurare l'ispezione ARP (DAI): Per impedire ai client di utilizzare indirizzi IP contraffatti o causare conflitti IP, abilitare la Dynamic ARP Inspection (DAI) sulle VLAN client. DAI utilizza il database di associazione del DHCP snooping per convalidare i pacchetti ARP, scartando tutti i pacchetti con mappature MAC-to-IP non valide:
ip arp inspection vlan 10,20,30Escludere gli IP statici dal pool DHCP: Assicurarsi che tutti gli indirizzi IP statici assegnati ai dispositivi dell'infrastruttura (come stampanti, AP o segnaletica digitale) siano esplicitamente esclusi dall'intervallo dell'ambito DHCP sul server per evitare che il server offra accidentalmente tali IP ai client.
Distribuire Port Security e 802.1X: Per le porte cablate nei negozi al dettaglio o nelle aree pubbliche, implementare la Port Security per limitare il numero di indirizzi MAC consentiti su una porta, oppure distribuire l'autenticazione 802.1X per impedire a dispositivi non autorizzati di connettersi alla struttura di rete fisica.
Domande di esercitazione
Q1. Un IT Manager di un grande centro commerciale nota che durante le ore di punta dello shopping natalizio, le connessioni WiFi degli ospiti falliscono frequentemente. Il registro del server DHCP è inondato di errori "DHCP Scope Full". L'attuale VLAN guest è configurata con una subnet mask `/23` e un tempo di lease predefinito di 24 ore. Quali sono le due modifiche di configurazione più immediate ed efficaci che il manager dovrebbe implementare per risolvere questo problema, e perché?
Suggerimento: Considera la relazione tra le dimensioni della subnet, il tempo di permanenza dei client e il recupero degli indirizzi IP.
Visualizza risposta modello
Il manager dovrebbe implementare le seguenti due modifiche immediate alla configurazione:
Ridurre il tempo di lease DHCP: Ridurre il tempo di lease da 24 ore a 30 o 45 minuti. Poiché i visitatori del centro commerciale sono altamente transitori (il tempo di permanenza tipico è di 1-2 ore), un lease di 24 ore fa sì che il server DHCP mantenga occupati gli indirizzi IP molto tempo dopo la partenza degli ospiti. Riducendo il tempo di lease si garantisce che gli indirizzi IP vengano rapidamente recuperati e resi disponibili per i nuovi clienti, moltiplicando efficacemente la capacità del pool esistente senza modificare la struttura della subnet.
Espandere lo scope della subnet (dimensionamento CIDR): Espandere la subnet della VLAN guest da una
/23(che fornisce 510 indirizzi IP utilizzabili) a una/21(che fornisce 2.046 indirizzi IP utilizzabili) o a una/20(che fornisce 4.094 indirizzi IP utilizzabili). Una subnet/23è decisamente troppo piccola per un grande centro commerciale durante le ore di punta, soprattutto considerando che molti clienti portano con sé più dispositivi connessi (telefoni, wearable, tablet). L'espansione dello scope garantisce la disponibilità di un numero sufficiente di indirizzi IP per gestire il carico massimo di dispositivi simultanei.
Queste due modifiche lavorano in sinergia: l'espansione della subnet aumenta la capacità assoluta del pool, mentre la riduzione del tempo di lease garantisce la massima efficienza nel riutilizzo degli indirizzi, eliminando completamente gli errori "DHCP Scope Full".
Q2. Un ingegnere di rete sta risolvendo i problemi di un SSID guest appena distribuito in un hotel. I client wireless si associano correttamente all'AP ma non riescono a ottenere un indirizzo IP, andando in timeout dopo diversi secondi. Un'acquisizione di pacchetti sulla porta dello switch collegata all'AP mostra i broadcast `DHCPDISCOVER` che entrano nello switch, ma un'acquisizione sull'interfaccia di rete del server DHCP centrale non mostra pacchetti in arrivo dalla subnet guest dell'hotel. Il server DHCP si trova su una subnet diversa (10.10.10.0/24) rispetto ai client wireless guest (192.168.50.0/22). Quale configurazione manca, su quale dispositivo deve essere applicata e qual è il comando esatto per applicarla?
Suggerimento: Poiché il server DHCP si trova su una subnet diversa rispetto ai client, un dispositivo Layer 3 deve inoltrare il traffico broadcast.
Visualizza risposta modello
La configurazione mancante è il DHCP Relay Agent (IP Helper). Poiché i messaggi di discovery DHCP sono broadcast di Layer 2, non possono attraversare il router o il confine di Layer 3 tra la subnet guest del client (192.168.50.0/22) e la subnet del server DHCP (10.10.10.0/24). Senza un relay agent, lo switch o il router scarteranno i pacchetti broadcast, impedendo loro di raggiungere il server.
Questa configurazione deve essere applicata sullo Switch Layer 3 o Security Gateway che funge da gateway predefinito per la VLAN wireless guest (VLAN 50).
Ipotizzando uno switch Cisco IOS Layer 3, l'ingegnere deve applicare il comando ip helper-address all'interfaccia VLAN 50, puntando all'indirizzo IP del server DHCP centrale (es. 10.10.10.10):
interface Vlan50
description Guest_WiFi_Gateway
ip address 192.168.50.1 255.255.252.0
ip helper-address 10.10.10.10
no shutdown
Questo comando indica allo switch di intercettare i broadcast DHCP sulla VLAN 50, convertirli in pacchetti unicast di Layer 3 con un IP di origine del gateway della VLAN 50 (192.168.50.1) e inoltrarli direttamente al server DHCP all'indirizzo 10.10.10.10. Il server utilizzerà quindi l'IP del gateway per selezionare lo scope corretto e restituire un'offerta.
Q3. L'architetto di rete di uno stadio sta progettando una rete wireless per supportare 50.000 fan simultanei. Per ridurre al minimo il traffico broadcast e il consumo di tempo di trasmissione RF, l'architetto desidera implementare la soppressione del broadcast e convertire i broadcast DHCP in unicast. Tuttavia, alcuni ingegneri junior esprimono il timore che la conversione dei broadcast DHCP in unicast possa compromettere il protocollo DHCP, poiché i client non dispongono ancora di un indirizzo IP per ricevere pacchetti unicast. In che modo l'architetto dovrebbe spiegare il meccanismo tecnico della conversione da broadcast a unicast per rispondere a questi dubbi?
Suggerimento: Considera come l'Access Point effettua il bridging dei frame di Layer 2 e come l'indirizzo MAC del client viene utilizzato nell'intestazione 802.11.
Visualizza risposta modello
L'architetto dovrebbe spiegare che la conversione dei broadcast DHCP in unicast non compromette il protocollo DHCP perché l'Access Point (AP) opera a Layer 2 e può indirizzare i frame direttamente all'indirizzo MAC fisico del client, anche se il client non ha ancora un indirizzo IP.
Ecco il meccanismo tecnico:
L'indirizzo MAC del client è noto: Durante la fase iniziale di associazione, il client stabilisce una connessione sicura di Layer 2 con l'AP. L'AP conosce l'indirizzo MAC univoco del client e lo associa a una specifica porta virtuale e interfaccia radio.
L'AP intercetta il broadcast: Quando il server DHCP invia un
DHCPOFFERo unDHCPACKcome broadcast di Layer 2 (MAC di destinazioneFF:FF:FF:FF:FF:FF), l'AP intercetta questo pacchetto sulla sua interfaccia cablata.Conversione in unicast: Invece di trasmettere il pacchetto via etere come frame broadcast (il che costringerebbe tutti i client sul canale a svegliarsi e a elaborarlo alla velocità di trasmissione dati minima obbligatoria), l'AP modifica l'intestazione MAC 802.11. Cambia l'indirizzo MAC di destinazione dall'indirizzo broadcast all'indirizzo MAC unicast del client specifico (che ha estratto dal campo dell'indirizzo hardware del client del pacchetto DHCP,
chaddr).Trasmissione ad alta velocità: Poiché il frame è ora un frame unicast, l'AP può trasmetterlo utilizzando la massima velocità di trasmissione dati supportata dal client (utilizzando beamforming, MIMO e modulazione di ordine superiore come QAM). Beneficia inoltre dei riconoscimenti (ACK) di Layer 2 802.11, garantendo una consegna affidabile.
Elaborazione del client: La scheda wireless del client riceve il frame unicast, riconosce il proprio indirizzo MAC nell'intestazione 802.11 e passa il payload (l'offerta o l'ack DHCP) allo stack di rete. Il sistema operativo del client elabora normalmente il payload DHCP, del tutto ignaro del fatto che il frame sia stato convertito da broadcast a unicast via etere.
Questa spiegazione dimostra che la conversione da broadcast a unicast è un'ottimizzazione di Layer 2 che sfrutta il livello MAC 802.11 per proteggere il tempo di trasmissione RF, senza alterare il payload del protocollo DHCP di Layer 3.
Continua a leggere questa serie
Utilizzo di Packet Capture (PCAP) per diagnosticare le prestazioni WiFi lente
Questa guida di riferimento tecnico fornisce a IT manager, architetti di rete e direttori operativi delle strutture una metodologia strutturata a livello di pacchetto per diagnosticare e risolvere le prestazioni WiFi aziendali lente utilizzando l'analisi Packet Capture (PCAP). Analizzando i frame 802.11 grezzi — inclusi i tassi di ritrasmissione, l'utilizzo dell'airtime e i metadati del livello fisico — i team possono isolare con precisione i colli di bottiglia a livello RF dai problemi cablati o applicativi. Applicabile a strutture ad alta densità tra cui hotel, catene di vendita al dettaglio, stadi e centri congressi, questa guida offre flussi di lavoro diagnostici pratici, casi di studio reali e passaggi di remediation della configurazione per recuperare la capacità di rete e proteggere l'esperienza degli ospiti.
Risoluzione dei problemi di autenticazione 802.1X (RADIUS/EAP)
Questa guida fornisce un riferimento completo e pratico per IT manager, architetti di rete e direttori delle operazioni delle sedi sulla diagnosi e la risoluzione dei problemi di autenticazione 802.1X nell'infrastruttura RADIUS ed EAP. Copre l'intera catena di autenticazione — dall'errata configurazione del supplicant e la scadenza dei certificati fino alla mancata corrispondenza del shared secret RADIUS e alla frammentazione del transito di rete — con casi di studio reali provenienti dai settori dell'ospitalità e del retail. I team responsabili della conformità PCI DSS, delle distribuzioni WPA3-Enterprise e del controllo degli accessi di rete multi-sito troveranno framework diagnostici strutturati, checklist di implementazione e strategie di mitigazione del rischio direttamente applicabili alle loro operazioni.
Come identificare e risolvere l'interferenza co-canale (CCI)
L'interferenza co-canale (CCI) è la causa principale del degrado del throughput e dell'aumento della latenza nelle distribuzioni WiFi aziendali ad alta densità, e si verifica quando più access point condividono lo stesso canale di frequenza e sono costretti alla contesa CSMA/CA. Questa guida fornisce ad architetti di rete, responsabili IT e direttori operativi delle strutture un framework strutturato e indipendente dal fornitore per identificare la CCI attraverso la diagnostica e l'analisi RF, e risolverla tramite la pianificazione dei canali, l'ottimizzazione della potenza di trasmissione, la gestione della velocità dei dati e il posizionamento fisico degli AP. Risolvere la CCI è un prerequisito fondamentale per offrire un guest WiFi affidabile, connettività operativa e un ROI misurabile in hotel, catene di vendita al dettaglio, stadi e strutture del settore pubblico.