Mean time to innocence: cómo demostrar que no es el WiFi
El Mean time to innocence (MTTI) es la métrica crítica que define cuánto tiempo pasan los equipos de TI demostrando que un problema de red no es su culpa. Esta guía detalla una metodología de observabilidad de cinco pasos para eliminar el juego de las culpas en entornos multi-tenant, reemplazando los señalamientos con evidencia compartida para reducir el tiempo medio de resolución (MTTR).
Escucha esta guía
Ver transcripción del podcast
📚 Parte de nuestra serie principal: Multi-Tenant WiFi Guide →
Executive Summary
When connectivity drops in a multi-tenant environment, the WiFi gets blamed first. It is the visible edge of the network, the last hop before the device, and the easiest target for frustrated users. For IT managers, network architects, and venue operations directors, this creates a persistent operational tax: the time spent proving innocence.
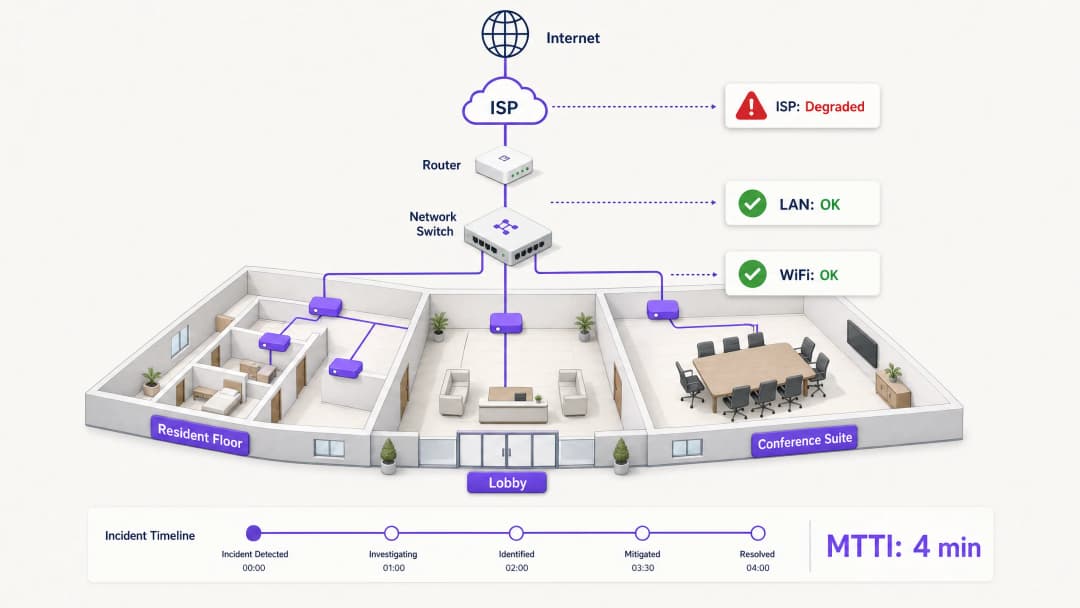
Mean time to innocence (MTTI) measures the average elapsed time between an incident being reported and a team's ability to demonstrate that their domain is not the root cause. In complex environments like build-to-rent (BTR) blocks, hotels, or conference centres, the network is fragmented across property managers, managed WiFi providers, and internet service providers (ISPs). Without definitive telemetry, MTTI inflates mean time to resolution (MTTR) as teams argue over responsibility rather than fixing the fault.
This guide details a five-step observability methodology to systematically reduce MTTI. By deploying continuous synthetic checks, hop-by-hop path visibility, flow data analysis, topology mapping, and event correlation, you can replace adversarial finger-pointing with shared evidence. The goal is not to win the blame game faster, but to end it entirely.
Technical Deep-Dive: The Mechanics of MTTI
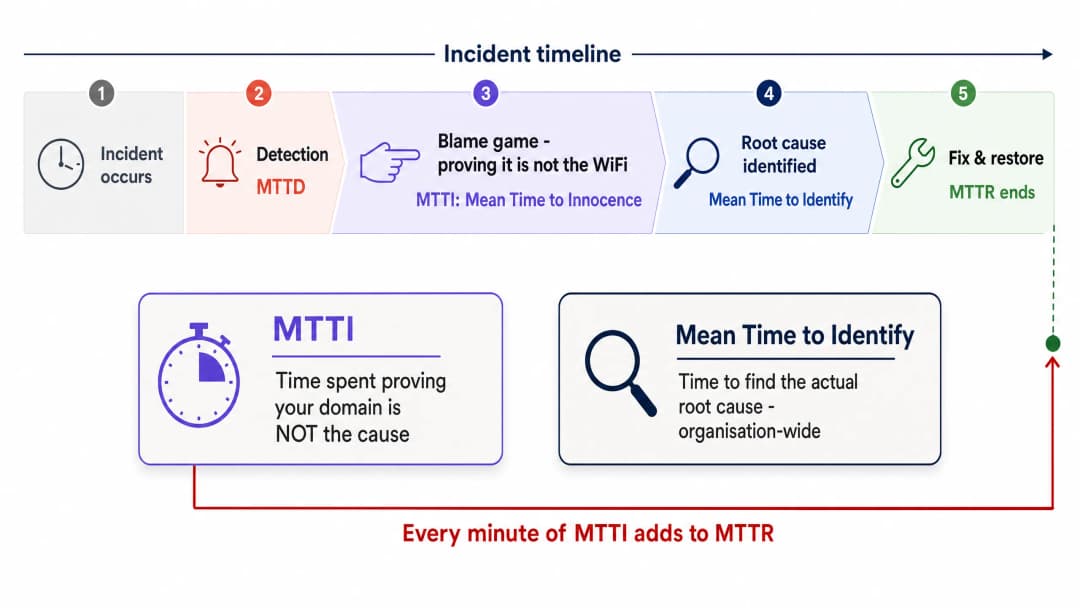
The Distinction Between MTTI and Mean Time to Identify
It is vital to separate MTTI from mean time to identify. Mean time to identify is an organisation-wide metric tracking how long it takes to find the actual root cause of an outage. MTTI is a siloed, domain-specific metric tracking how long it takes one team to prove they are not the culprit.
Every minute of MTTI adds directly to MTTR. If a managed WiFi provider spends 40 minutes manually checking access points (APs) and switch logs before concluding the issue lies with the ISP, the MTTR has a 40-minute penalty built in before the actual remediation even begins.
Why the WiFi Takes the Blame
In environments serving 350 million unique users across 80,000+ live venues, Purple sees the same pattern repeatedly. The WiFi layer is blamed by default due to three structural realities:
- Visibility bias: The WiFi signal indicator is the only network diagnostic tool available to the average venue user.
- Edge proximity: As the final hop to the client device, WiFi inherits the symptoms of every upstream failure. A DNS timeout at the ISP looks identical to an AP failure from the user's perspective.
- Telemetry gaps: Historically, proving wireless health required manual intervention. If you cannot show a clean bill of health for the wireless layer in under two minutes, you lose the narrative.
The Multi-Tenant Complication
In a single-tenant enterprise, network teams own the stack from the AP to the firewall. In Multi-Tenant WiFi environments, ownership is fractured.
A BTR resident pays the property manager. The property manager contracts a managed WiFi provider. The managed WiFi provider relies on a third-party ISP circuit and, often, the landlord's in-building distribution network. When a resident cannot stream video, the provider must rapidly exonerate the WiFi hardware (Cisco Meraki, HPE Aruba, Ruckus, or Juniper Mist) and isolate the fault to the client device, the building switch, or the ISP. Failure to do so damages the commercial relationship between the provider and the property manager.
Implementation Guide: The 5-Step Methodology
To systematically reduce MTTI, implement this five-layer observability architecture.
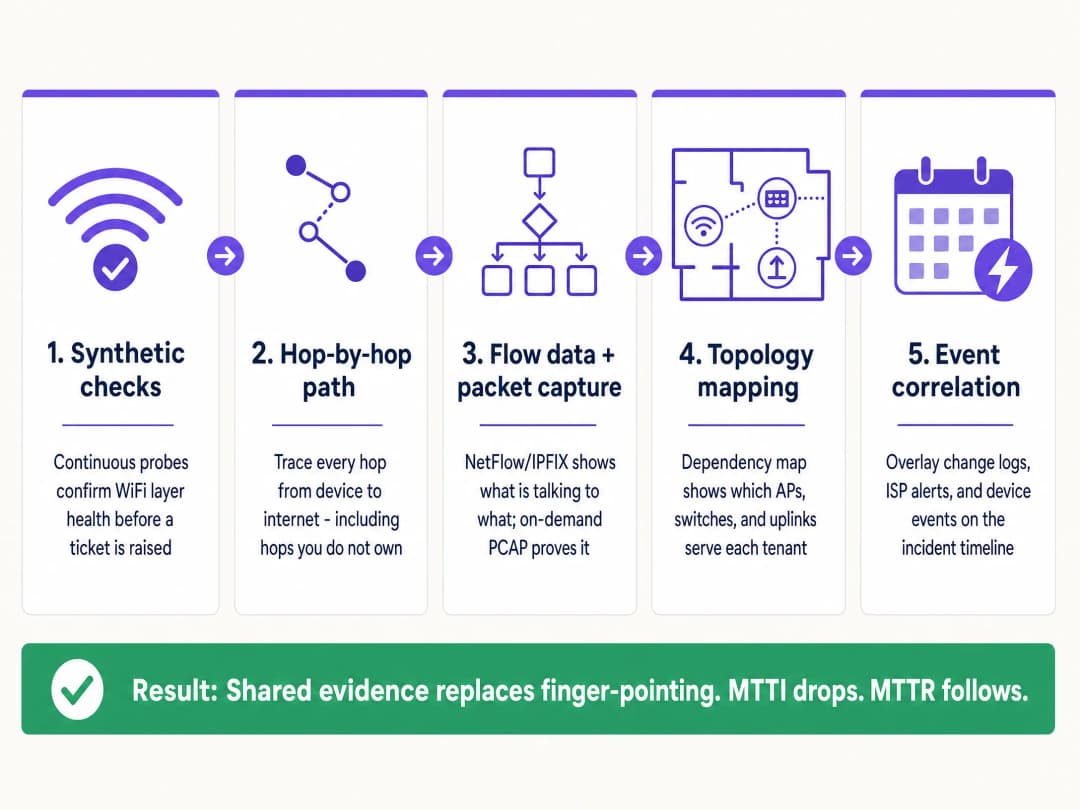
1. Continuous Synthetic Checks
Do not wait for a user to complain. Deploy automated synthetic probes that continuously emulate user behaviour from the network edge.
- Implementation: Configure APs or dedicated sensors to run scheduled tests for DHCP response, DNS resolution, HTTP reachability, and authentication flows (such as 802.1X or Captive Portal logins).
- Outcome: When a ticket is raised, you check the synthetic dashboard first. If the probes show clean HTTP reachability at the exact time of the complaint, you immediately exonerate the WiFi layer and the WAN circuit, shifting focus to the specific client device or the target application.
2. Hop-by-Hop Path Visibility
Proving your hardware is healthy is insufficient if you cannot prove the path to the internet is clear.
- Implementation: Use path visualisation tools to trace traffic from the access layer across the LAN, through the demarcation point, and into the ISP network.
- Outcome: When latency spikes, a path trace reveals exactly which node introduced the delay. If hops one through four (your domain) show 2ms latency, and hop five (the ISP edge router) shows 150ms latency and 12% packet loss, you have definitive proof to hand to the ISP.
3. Flow Data and On-Demand Packet Capture
When users report application-specific failures, you need conversation-level visibility.
- Implementation: Export NetFlow or IPFIX data from your core switches or firewalls. Ensure your access layer hardware supports remote, on-demand packet capture (PCAP) without requiring an engineer on site.
- Outcome: Flow data proves whether traffic to a specific service is leaving your network cleanly. If it is, the network is innocent. If deeper forensic proof is required, a targeted PCAP on the specific VLAN provides undeniable evidence of TCP retransmissions or server-side resets.
4. Topology and Dependency Mapping
In a multi-tenant environment, isolating the blast radius is the fastest way to categorise a fault.
- Implementation: Maintain a live, dynamically updated dependency map linking every AP to its switch, uplink, and WAN circuit, mapped against tenant VLANs.
- Outcome: If a fault affects APs across multiple floors but only on a single switch, the issue is the switch. If it affects all APs but only one tenant's VLAN, it is a logical configuration issue. Rapid scoping prevents wasted effort investigating healthy infrastructure.
5. Event Correlation
Data without context prolongs investigations.
- Implementation: Feed change logs, ISP maintenance alerts, hardware firmware updates, and user tickets into a single timeline view.
- Outcome: Overlaying a spike in authentication failures with a Microsoft Entra ID certificate expiration event that occurred 10 minutes prior immediately identifies the root cause, bypassing the network hardware entirely.
Best Practices
- Standardise the Hardware Stack: Limit deployments to canonical enterprise vendors (Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme, Fortinet) that expose APIs for synthetic testing and remote PCAP.
- Automate the Evidence: Configure your monitoring platform to automatically attach synthetic test results and path traces to ITSM tickets the moment they are created.
- Share the Dashboard: Provide property managers with read-only access to a high-level health dashboard. Transparency preempts the blame game.
- Track MTTI Formally: Measure the time between ticket creation and the moment your team provides evidence of innocence. Treat it as a primary KPI alongside MTTR.
Troubleshooting & Risk Mitigation
- Risk: The 'No Fault Found' Loop: Users report issues, but synthetic checks show green.
- Mitigation: The issue is likely device-specific or related to RF interference (co-channel interference or physical obstruction). Use client-side analytics to check the specific device's RSSI and roaming history.
- Risk: ISP Denial: The ISP refuses to accept the fault despite your evidence.
- Mitigation: Provide hop-by-hop path traces showing the exact IP address where packet loss begins. Share PCAPs demonstrating clean egress from your demarcation point. Hard data forces escalation past Level 1 support.
- Risk: Captive Portal Failures: Users blame the WiFi when the portal fails to load.
- Mitigation: Isolate the identity provider. Check the status of the integration (Microsoft Entra ID, Okta, Google Workspace). If the network allows pre-authentication traffic but the IdP times out, the network is innocent.
ROI & Business Impact
Reducing MTTI delivers measurable business value beyond simply saving engineering hours.
- Reduced MTTR: Stripping 40 minutes of finger-pointing from an incident directly reduces downtime, protecting revenue in retail and hospitality environments.
- SLA Compliance: Faster exoneration prevents unfair penalties being levied against the managed WiFi provider when the fault lies with the ISP or the building infrastructure.
- Client Retention: In the Multi-Tenant WiFi sector, property managers renew contracts with providers who offer transparency and rapid answers. Shared evidence builds trust; defensive arguments destroy it.
- Resource Optimisation: Highly paid Level 3 network engineers spend their time engineering solutions, rather than manually proving the network is functioning correctly.
Definiciones clave
Mean Time to Innocence (MTTI)
El tiempo promedio requerido para que un equipo de TI específico demuestre, utilizando datos objetivos, que su dominio o infraestructura no es la causa raíz de un incidente reportado.
Crítico para los proveedores de WiFi gestionado que deben defender su servicio frente a los administradores de la propiedad y los ISP.
Mean Time to Identify
La métrica a nivel organizacional que rastrea el tiempo total transcurrido desde la detección del incidente hasta el descubrimiento de la causa raíz real.
El MTTI es un subconjunto de esta métrica. Reducir el MTTI reduce directamente el tiempo total de identificación.
Synthetic Checks
Pruebas continuas y automatizadas que emulan el tráfico de los usuarios (por ejemplo, búsquedas de DNS, solicitudes HTTP) para monitorear de manera proactiva la salud de la red.
Se utilizan para demostrar que la capa de WiFi funcionaba correctamente en el momento exacto en que un usuario se quejó.
Hop-by-Hop Path Visibility
Telemetría que rastrea el tráfico de la red nodo por nodo desde el cliente hasta el destino, midiendo la latencia y la pérdida en cada router o switch específico.
Esencial para demostrar que una falla radica en la red de un ISP o en el switch de distribución de un propietario, y no en el hardware del WiFi gestionado.
Flow Data (NetFlow/IPFIX)
Datos de protocolo de red que proporcionan un resumen de las conversaciones de tráfico, mostrando origen, destino, protocolo y volumen.
Se utiliza para demostrar que el tráfico de una aplicación específica está saliendo con éxito de la red local.
On-Demand Packet Capture (PCAP)
La capacidad de registrar de forma remota el tráfico de red sin procesar desde un punto de acceso o switch para el análisis forense.
La prueba definitiva utilizada para demostrar errores del lado del servidor o un mal comportamiento del dispositivo del cliente.
Blast Radius
El alcance del impacto de un incidente específico (por ejemplo, un usuario, un AP, un switch, un inquilino o todo el edificio).
Determinar el blast radius mediante el mapeo de topología es la forma más rápida de excluir la infraestructura en buen estado de una investigación.
Event Correlation
La práctica de superponer diferentes flujos de datos (registros, alertas, actualizaciones) en una sola línea de tiempo para identificar causa y efecto.
Se utiliza para demostrar que una interrupción de la red fue causada por un cambio de un tercero, como una ventana de mantenimiento de ISP no anunciada.
Ejemplos resueltos
Un hotel de 350 habitaciones reporta que el WiFi en las habitaciones es lento en toda la propiedad. La recepción culpa al proveedor de WiFi gestionado. ¿Cómo exonera a la red y encuentra la causa raíz?
- Verifique las sondas sintéticas: las pruebas de legibilidad DNS y HTTP muestran que los AP tienen una conexión limpia a internet. 2. Revise el mapa de topología: el problema afecta a todos los AP en todos los switches, lo que descarta el hardware de borde. 3. Ejecute una traza de ruta: la traza muestra una latencia de 2 ms dentro de la LAN del hotel, pero una latencia de 180 ms en el tercer salto (el router de agregación del ISP). 4. Exporte la evidencia: envíe la captura de pantalla de la traza de ruta al gerente del hotel y al ISP.
Un minorista nacional reporta que las terminales de punto de venta (POS) en una región están perdiendo conexiones con el procesador de pagos. Se culpa al equipo de red por una desconfiguración del firewall o del enrutamiento.
- Aísle el radio de impacto: confirme que sólo las terminales POS (VLAN específica) se ven afectadas; el WiFi de invitados y los sistemas de back-office están sanos. 2. Analice los datos de flujo: NetFlow confirma que el tráfico con destino al rango de IP del procesador de pagos está saliendo con éxito de los routers de las tiendas. 3. Capture paquetes: un PCAP bajo demanda en la VLAN de POS revela que el servidor del procesador de pagos está enviando reinicios TCP (RST). 4. Comparta el PCAP con el equipo de soporte del procesador de pagos.
Preguntas de práctica
Q1. Un inquilino en un espacio de coworking se queja de que no puede acceder a su VPN corporativa. Otros inquilinos están navegando por internet sin problemas. ¿Cuál es la forma más eficiente de demostrar que la red WiFi no tiene la culpa?
Sugerencia: Considera el radio de impacto y el tipo específico de tráfico que está fallando.
Ver respuesta modelo
Primero, utiliza el mapa de topología para confirmar que el radio de impacto se limita a un usuario o a un servicio específico, descartando una falla general del AP o del switch. Segundo, analiza los datos de flujo (NetFlow/IPFIX) para la dirección IP de ese cliente. Si los datos de flujo muestran que el tráfico de la VPN (por ejemplo, UDP 500 o TCP 443) está saliendo de la red limpiamente, la WiFi y la LAN están libres de culpa. El problema es la configuración de la VPN del cliente o el firewall corporativo que bloquea la conexión.
Q2. Tu tablero de monitoreo muestra que un AP se ha desconectado, pero el administrador de la propiedad insiste en que la WiFi no funciona porque el ISP está caído. ¿Cómo demuestras que el problema es de energía interna y no del ISP?
Sugerencia: Busca correlación entre el estado de la infraestructura y eventos externos.
Ver respuesta modelo
Utiliza la correlación de eventos y el mapeo de topología. Si el mapa de topología muestra que solo un AP está fuera de línea mientras que otros en el mismo switch están funcionando, el circuito del ISP está claramente activo. La correlación de eventos podría mostrar un registro de falla de PoE (Power over Ethernet) del puerto del switch conectado a ese AP específico. Esto demuestra que el problema es del hardware local o del cableado, no del circuito WAN.
Q3. Un director de operaciones de un estadio afirma que la WiFi falló durante el medio tiempo porque las lectoras de boletos dejaron de funcionar. Necesitas exculpar a la red en menos de dos minutos. ¿Qué telemetría utilizas?
Sugerencia: Necesitas pruebas históricas del estado de salud en el momento exacto de la falla reportada.
Ver respuesta modelo
Extrae los datos históricos de las pruebas sintéticas continuas. Muestra al director de operaciones el tablero que confirma que durante la ventana exacta de 15 minutos del medio tiempo, los APs estuvieron resolviendo DNS con éxito y alcanzando la dirección IP del servidor de boletaje con baja latencia. Esto demuestra inmediatamente que la red inalámbrica estaba saludable y desplaza la investigación hacia los servidores de la aplicación de boletaje, que probablemente colapsaron bajo la carga repentina.
Continúe leyendo esta serie
Diseño de redes WiFi para edificios de oficinas multi-inquilino
Esta guía proporciona a directores de TI, arquitectos de redes y directores de tecnología un plan de diseño neutral respecto al proveedor para diseñar redes WiFi escalables, seguras y aisladas en edificios de oficinas multi-inquilino. Abarca la segmentación de VLAN bajo IEEE 802.1Q, la asignación dinámica de VLAN mediante 802.1X y RADIUS, la planificación de RF para entornos de alta densidad y las consideraciones de cumplimiento bajo GDPR y PCI-DSS. Los operadores de recintos y los administradores de edificios encontrarán directrices de arquitectura prácticas, casos de estudio del mundo real y errores de configuración que se deben evitar antes del despliegue.
Requisitos legales y de cumplimiento para infraestructura de WiFi compartido
Esta guía de referencia técnica autorizada describe los requisitos legales, regulatorios y de arquitectura críticos para implementar y administrar infraestructura de WiFi compartido. Proporciona a los gerentes de TI, arquitectos de red y operadores de recintos marcos de trabajo prácticos para garantizar una sólida protección de datos, un estricto cumplimiento de la seguridad de los pagos y un aislamiento de inquilinos de alto rendimiento utilizando estándares empresariales.
Gestión de ancho de banda y Calidad de Servicio (QoS) en espacios de co-working
Una guía de referencia técnica autorizada para administradores de TI, arquitectos de red y directores de operaciones de espacios sobre la implementación de marcos de referencia robustos de gestión de ancho de banda y Calidad de Servicio (QoS) en entornos de co-working. Esta guía detalla la segmentación de red, la priorización de tráfico, las configuraciones independientes del proveedor y las métricas de ROI del mundo real para ofrecer conectividad de nivel empresarial. Cubre los estándares IEEE 802.11e/WMM, diseño de VLAN, limitación de velocidad por usuario y estrategias de resolución de problemas con resultados de negocio medibles.