Mean time to innocence: come dimostrare che non è colpa del WiFi
Il Mean time to innocence (MTTI) è la metrica fondamentale che definisce quanto tempo i team IT dedicano a dimostrare che un problema di rete non è colpa loro. Questa guida illustra una metodologia di osservabilità in cinque passaggi per eliminare il gioco del barile negli ambienti multi-tenant, sostituendo le accuse reciproche con prove condivise per ridurre il tempo medio di risoluzione (MTTR).
Ascolta questa guida
Visualizza trascrizione del podcast
📚 Parte della nostra serie principale: Multi-Tenant WiFi Guide →
Executive Summary
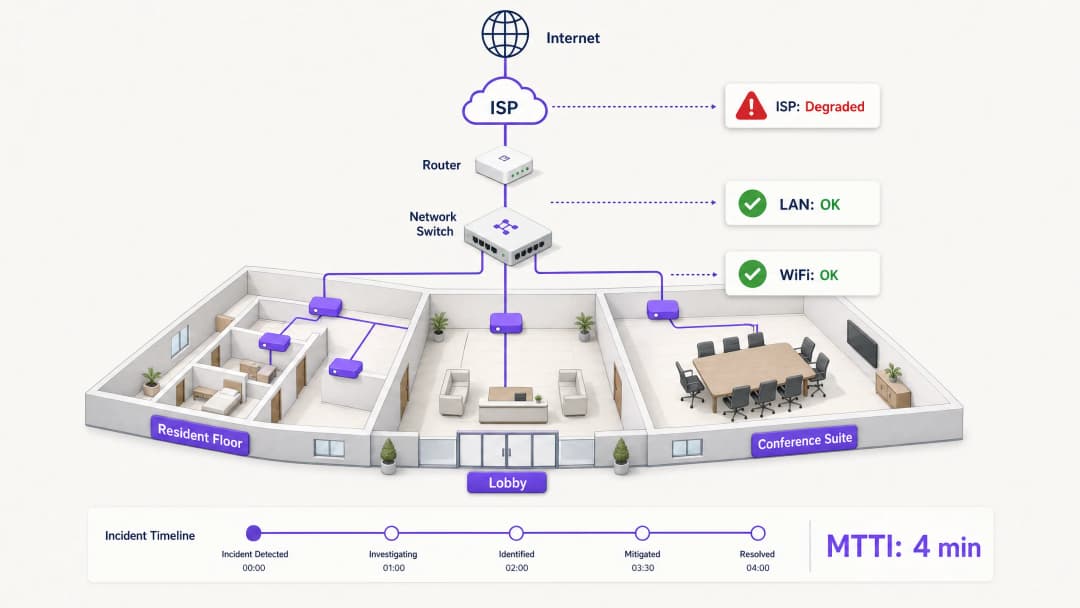
When connectivity drops in a multi-tenant environment, the WiFi gets blamed first. It is the visible edge of the network, the last hop before the device, and the easiest target for frustrated users. For IT managers, network architects, and venue operations directors, this creates a persistent operational tax: the time spent proving innocence.
Mean time to innocence (MTTI) measures the average elapsed time between an incident being reported and a team's ability to demonstrate that their domain is not the root cause. In complex environments like build-to-rent (BTR) blocks, hotels, or conference centres, the network is fragmented across property managers, managed WiFi providers, and internet service providers (ISPs). Without definitive telemetry, MTTI inflates mean time to resolution (MTTR) as teams argue over responsibility rather than fixing the fault.
This guide details a five-step observability methodology to systematically reduce MTTI. By deploying continuous synthetic checks, hop-by-hop path visibility, flow data analysis, topology mapping, and event correlation, you can replace adversarial finger-pointing with shared evidence. The goal is not to win the blame game faster, but to end it entirely.
Technical Deep-Dive: The Mechanics of MTTI
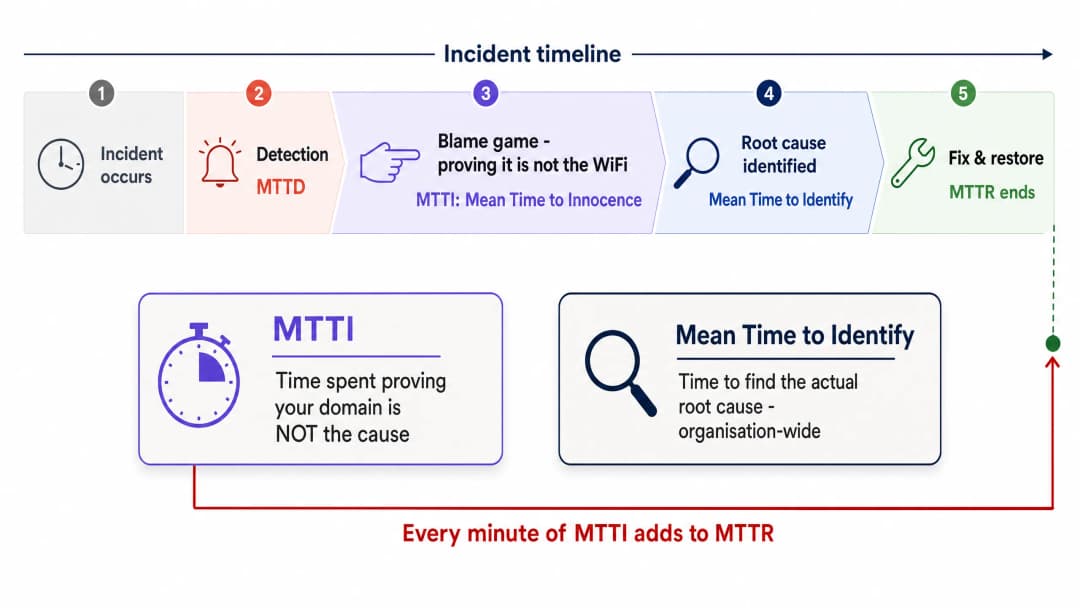
The Distinction Between MTTI and Mean Time to Identify
It is vital to separate MTTI from mean time to identify. Mean time to identify is an organisation-wide metric tracking how long it takes to find the actual root cause of an outage. MTTI is a siloed, domain-specific metric tracking how long it takes one team to prove they are not the culprit.
Every minute of MTTI adds directly to MTTR. If a managed WiFi provider spends 40 minutes manually checking access points (APs) and switch logs before concluding the issue lies with the ISP, the MTTR has a 40-minute penalty built in before the actual remediation even begins.
Why the WiFi Takes the Blame
In environments serving 350 million unique users across 80,000+ live venues, Purple sees the same pattern repeatedly. The WiFi layer is blamed by default due to three structural realities:
- Visibility bias: The WiFi signal indicator is the only network diagnostic tool available to the average venue user.
- Edge proximity: As the final hop to the client device, WiFi inherits the symptoms of every upstream failure. A DNS timeout at the ISP looks identical to an AP failure from the user's perspective.
- Telemetry gaps: Historically, proving wireless health required manual intervention. If you cannot show a clean bill of health for the wireless layer in under two minutes, you lose the narrative.
The Multi-Tenant Complication
In a single-tenant enterprise, network teams own the stack from the AP to the firewall. In Multi-Tenant WiFi environments, ownership is fractured.
A BTR resident pays the property manager. The property manager contracts a managed WiFi provider. The managed WiFi provider relies on a third-party ISP circuit and, often, the landlord's in-building distribution network. When a resident cannot stream video, the provider must rapidly exonerate the WiFi hardware (Cisco Meraki, HPE Aruba, Ruckus, or Juniper Mist) and isolate the fault to the client device, the building switch, or the ISP. Failure to do so damages the commercial relationship between the provider and the property manager.
Implementation Guide: The 5-Step Methodology
To systematically reduce MTTI, implement this five-layer observability architecture.
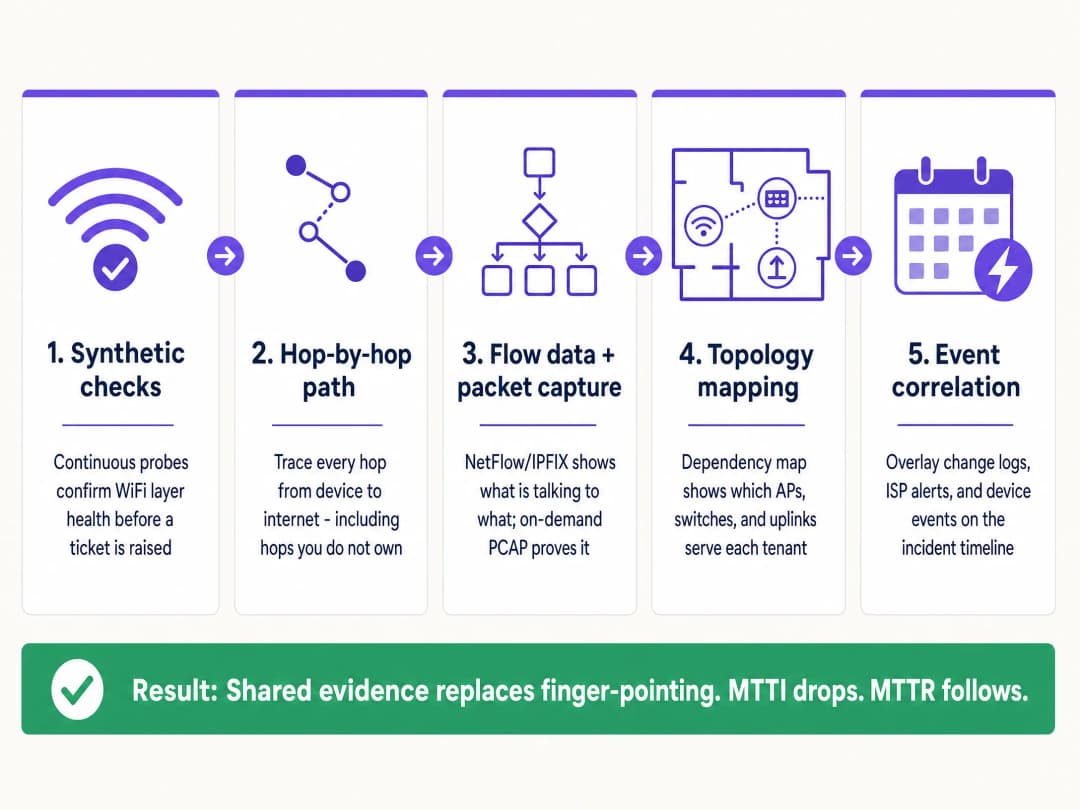
1. Continuous Synthetic Checks
Do not wait for a user to complain. Deploy automated synthetic probes that continuously emulate user behaviour from the network edge.
- Implementation: Configure APs or dedicated sensors to run scheduled tests for DHCP response, DNS resolution, HTTP reachability, and authentication flows (such as 802.1X or Captive Portal logins).
- Outcome: When a ticket is raised, you check the synthetic dashboard first. If the probes show clean HTTP reachability at the exact time of the complaint, you immediately exonerate the WiFi layer and the WAN circuit, shifting focus to the specific client device or the target application.
2. Hop-by-Hop Path Visibility
Proving your hardware is healthy is insufficient if you cannot prove the path to the internet is clear.
- Implementation: Use path visualisation tools to trace traffic from the access layer across the LAN, through the demarcation point, and into the ISP network.
- Outcome: When latency spikes, a path trace reveals exactly which node introduced the delay. If hops one through four (your domain) show 2ms latency, and hop five (the ISP edge router) shows 150ms latency and 12% packet loss, you have definitive proof to hand to the ISP.
3. Flow Data and On-Demand Packet Capture
When users report application-specific failures, you need conversation-level visibility.
- Implementation: Export NetFlow or IPFIX data from your core switches or firewalls. Ensure your access layer hardware supports remote, on-demand packet capture (PCAP) without requiring an engineer on site.
- Outcome: Flow data proves whether traffic to a specific service is leaving your network cleanly. If it is, the network is innocent. If deeper forensic proof is required, a targeted PCAP on the specific VLAN provides undeniable evidence of TCP retransmissions or server-side resets.
4. Topology and Dependency Mapping
In a multi-tenant environment, isolating the blast radius is the fastest way to categorise a fault.
- Implementation: Maintain a live, dynamically updated dependency map linking every AP to its switch, uplink, and WAN circuit, mapped against tenant VLANs.
- Outcome: If a fault affects APs across multiple floors but only on a single switch, the issue is the switch. If it affects all APs but only one tenant's VLAN, it is a logical configuration issue. Rapid scoping prevents wasted effort investigating healthy infrastructure.
5. Event Correlation
Data without context prolongs investigations.
- Implementation: Feed change logs, ISP maintenance alerts, hardware firmware updates, and user tickets into a single timeline view.
- Outcome: Overlaying a spike in authentication failures with a Microsoft Entra ID certificate expiration event that occurred 10 minutes prior immediately identifies the root cause, bypassing the network hardware entirely.
Best Practices
- Standardise the Hardware Stack: Limit deployments to canonical enterprise vendors (Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme, Fortinet) that expose APIs for synthetic testing and remote PCAP.
- Automate the Evidence: Configure your monitoring platform to automatically attach synthetic test results and path traces to ITSM tickets the moment they are created.
- Share the Dashboard: Provide property managers with read-only access to a high-level health dashboard. Transparency preempts the blame game.
- Track MTTI Formally: Measure the time between ticket creation and the moment your team provides evidence of innocence. Treat it as a primary KPI alongside MTTR.
Troubleshooting & Risk Mitigation
- Risk: The 'No Fault Found' Loop: Users report issues, but synthetic checks show green.
- Mitigation: The issue is likely device-specific or related to RF interference (co-channel interference or physical obstruction). Use client-side analytics to check the specific device's RSSI and roaming history.
- Risk: ISP Denial: The ISP refuses to accept the fault despite your evidence.
- Mitigation: Provide hop-by-hop path traces showing the exact IP address where packet loss begins. Share PCAPs demonstrating clean egress from your demarcation point. Hard data forces escalation past Level 1 support.
- Risk: Captive Portal Failures: Users blame the WiFi when the portal fails to load.
- Mitigation: Isolate the identity provider. Check the status of the integration (Microsoft Entra ID, Okta, Google Workspace). If the network allows pre-authentication traffic but the IdP times out, the network is innocent.
ROI & Business Impact
Reducing MTTI delivers measurable business value beyond simply saving engineering hours.
- Reduced MTTR: Stripping 40 minutes of finger-pointing from an incident directly reduces downtime, protecting revenue in retail and hospitality environments.
- SLA Compliance: Faster exoneration prevents unfair penalties being levied against the managed WiFi provider when the fault lies with the ISP or the building infrastructure.
- Client Retention: In the Multi-Tenant WiFi sector, property managers renew contracts with providers who offer transparency and rapid answers. Shared evidence builds trust; defensive arguments destroy it.
- Resource Optimisation: Highly paid Level 3 network engineers spend their time engineering solutions, rather than manually proving the network is functioning correctly.
Definizioni chiave
Mean Time to Innocence (MTTI)
Il tempo medio necessario a un team IT specifico per dimostrare, utilizzando dati oggettivi, che il proprio dominio o la propria infrastruttura non costituisce la causa principale di un incidente segnalato.
Cruciale per i provider di WiFi gestiti che devono difendere il proprio servizio nei confronti di property manager e ISP.
Mean Time to Identify
La metrica a livello aziendale che monitora il tempo totale trascorso dal rilevamento dell'incidente alla scoperta della reale causa principale.
L'MTTI è un sottoinsieme di questa metrica. Ridurre l'MTTI riduce direttamente il tempo complessivo di identificazione.
Synthetic Checks
Test automatizzati e continui che emulano il traffico degli utenti (es. query DNS, richieste HTTP) per monitorare proattivamente lo stato di salute della rete.
Utilizzati per dimostrare che il livello WiFi funzionava correttamente nell'esatto momento in cui un utente ha inviato una segnalazione.
Hop-by-Hop Path Visibility
Telemetria che traccia il traffico di rete nodo per nodo dal client alla destinazione, misurando la latenza e la perdita di pacchetti su ogni specifico router o switch.
Essenziale per dimostrare che un guasto risiede nella rete di un ISP o nello switch di distribuzione del proprietario dell'immobile, piuttosto che nell'hardware WiFi gestito.
Flow Data (NetFlow/IPFIX)
Dati del protocollo di rete che forniscono un riepilogo delle conversazioni di traffico, mostrando origine, destinazione, protocollo e volume.
Utilizzato per dimostrare che il traffico di un'applicazione specifica sta lasciando con successo la rete locale.
On-Demand Packet Capture (PCAP)
La capacità di registrare in modalità remota il traffico di rete grezzo da un access point o switch per l'analisi forense.
La prova definitiva utilizzata per dimostrare errori lato server o comportamenti anomali del dispositivo client.
Blast Radius
La portata dell'impatto di uno specifico incidente (es. un singolo utente, un AP, uno switch, un tenant o l'intero edificio).
Determinare il blast radius tramite la mappatura della topologia è il modo più rapido per escludere l'infrastruttura sana da un'indagine.
Event Correlation
La pratica di sovrapporre diversi flussi di dati (log, avvisi, aggiornamenti) su un'unica timeline per identificare causa ed effetto.
Utilizzata per dimostrare che un'interruzione di rete è stata causata da una modifica di terze parti, come una finestra di manutenzione non annunciata dell'ISP.
Esempi pratici
Un hotel da 350 camere segnala che il WiFi in camera è lento in tutta la struttura. La reception incolpa il provider del WiFi gestito. Come si scagiona la rete e come si individua la causa principale?
- Verificare i probe sintetici: i test di raggiungibilità DNS e HTTP mostrano che gli AP hanno una connessione pulita a Internet. 2. Esaminare la mappa della topologia: il problema interessa tutti gli AP su tutti gli switch, escludendo l'hardware di rete perimetrale. 3. Eseguire un tracciamento del percorso: il tracciamento mostra una latenza di 2 ms all'interno della LAN dell'hotel, ma di 180 ms al terzo hop (il router di aggregazione dell'ISP). 4. Esportare le prove: inviare lo screenshot del tracciamento del percorso al direttore dell'hotel e all'ISP.
Un rivenditore nazionale segnala che i terminali dei punti vendita (POS) in una determinata area geografica perdono la connessione con il processore di pagamento. Il team di rete viene accusato di un'errata configurazione del firewall o del routing.
- Isolare il raggio d'azione dell'impatto: confermare che solo i terminali POS (VLAN specifica) sono interessati, mentre il WiFi ospiti e i sistemi di back-office funzionano correttamente. 2. Analizzare i dati di flusso: NetFlow conferma che il traffico destinato all'intervallo IP del processore di pagamento esce correttamente dai router del punto vendita. 3. Acquisire i pacchetti: un PCAP on-demand sulla VLAN del POS rivela che il server del processore di pagamento sta inviando dei reset TCP (RST). 4. Condividere il PCAP con il team di supporto del processore di pagamento.
Domande di esercitazione
Q1. Un tenant in uno spazio di coworking si lamenta di non riuscire ad accedere alla VPN aziendale. Gli altri tenant navigano su internet senza problemi. Qual è il modo più efficiente per dimostrare che la rete WiFi non è la causa del problema?
Suggerimento: Considera il raggio di impatto (blast radius) e il tipo specifico di traffico interessato dall'interruzione.
Visualizza risposta modello
In primo luogo, utilizza la mappa della topologia per confermare che il raggio di impatto è limitato a un singolo utente o a un servizio specifico, escludendo così un guasto generale dell'AP o dello switch. In secondo luogo, analizza i dati di flusso (NetFlow/IPFIX) per l'indirizzo IP di quel client. Se i dati di flusso mostrano che il traffico VPN (ad es. UDP 500 o TCP 443) esce correttamente dalla rete, il WiFi e la LAN non hanno colpe. Il problema risiede nella configurazione della VPN del client o nel firewall aziendale che blocca la connessione.
Q2. Il tuo pannello di monitoraggio mostra che un AP è andato offline, ma il gestore della struttura insiste che il WiFi non funziona a causa di un disservizio dell'ISP. Come dimostri che il problema è l'alimentazione interna e non l'ISP?
Suggerimento: Cerca una correlazione tra lo stato dell'infrastruttura ed eventi esterni.
Visualizza risposta modello
Utilizza la correlazione degli eventi e la mappatura della topologia. Se la mappa mostra che un solo AP è offline mentre gli altri sullo stesso switch funzionano regolarmente, il circuito dell'ISP è chiaramente attivo. La correlazione degli eventi potrebbe mostrare un log di errore PoE (Power over Ethernet) dalla porta dello switch collegata a quel footprint specifico dell'AP. Questo prova che il problema riguarda l'hardware locale o il cablaggio, non il circuito WAN.
Q3. Un direttore delle operazioni di uno stadio sostiene che il WiFi ha smesso di funzionare durante l'intervallo perché i lettori di biglietti hanno smesso di rispondere. Devi scagionare la rete in meno di due minuti. Quale telemetria utilizzi?
Suggerimento: Hai bisogno di una prova storica dello stato di salute della rete nell'esatto momento del disservizio segnalato.
Visualizza risposta modello
Estrai i dati storici dai test sintetici continui. Mostra al direttore delle operazioni la dashboard che conferma come, esattamente durante la finestra di 15 minuti dell'intervallo, gli AP stessero risolvendo correttamente il DNS e raggiungendo l'indirizzo IP del server di biglietteria con una bassa latenza. Questo dimostra immediatamente che la rete wireless era integra, spostando l'indagine sui server dell'applicazione di biglietteria, che probabilmente sono andati in sovraccarico a causa del picco improvviso.
Continua a leggere questa serie
Progettazione di reti WiFi per edifici per uffici multi-tenant
Questa guida fornisce a responsabili IT, architetti di rete e CTO un modello indipendente dal fornitore per la progettazione di reti WiFi scalabili, sicure e isolate in edifici per uffici multi-tenant. Copre la segmentazione VLAN in conformità a IEEE 802.1Q, l'assegnazione dinamica delle VLAN tramite 802.1X e RADIUS, la pianificazione RF per ambienti ad alta densità e le considerazioni di conformità ai sensi di GDPR e PCI DSS. Gli operatori delle strutture e i gestori degli edifici troveranno linee guida sull'architettura pratiche, casi di studio reali ed errori di configurazione da evitare prima della distribuzione.
Requisiti legali e di conformità per l'infrastruttura WiFi condivisa
Questa guida tecnica di riferimento delinea i requisiti legali, normativi e architetturali critici per l'implementazione e la gestione di un'infrastruttura WiFi condivisa. Fornisce a IT manager, architetti di rete e gestori di sedi operative framework pratici per garantire una solida protezione dei dati, una rigorosa conformità alla sicurezza dei pagamenti e un isolamento dei tenant ad alte prestazioni utilizzando standard aziendali.
Gestione della larghezza di banda e Quality of Service (QoS) negli spazi di co-working
Una guida di riferimento tecnico autorevole per IT manager, network architect e direttori delle operazioni della struttura sull'implementazione di solidi framework di gestione della larghezza di banda e Quality of Service (QoS) negli ambienti di co-working. Questa guida illustra dettagliatamente la segmentazione della rete, la prioritizzazione del traffico, le configurazioni neutrali rispetto ai vendor e le metriche di ROI reali per fornire connettività di livello enterprise. Copre gli standard IEEE 802.11e/WMM, la progettazione delle VLAN, la limitazione della tariffa per utente e le strategie di risoluzione dei problemi con risultati aziendali misurabili.