Temps moyen d'innocence : comment prouver que le WiFi n'est pas en cause
Le temps moyen d'innocence (MTTI) est la métrique critique qui définit le temps passé par les équipes informatiques à prouver qu'un problème réseau n'est pas de leur faute. Ce guide détaille une méthodologie d'observabilité en cinq étapes pour éliminer le jeu des reproches dans les environnements multi-tenant, en remplaçant les accusations par des preuves partagées afin de réduire le temps moyen de résolution (MTTR).
Écouter ce guide
Voir la transcription du podcast
📚 Fait partie de notre série principale : Multi-Tenant WiFi Guide →
Executive Summary
When connectivity drops in a multi-tenant environment, the WiFi gets blamed first. It is the visible edge of the network, the last hop before the device, and the easiest target for frustrated users. For IT managers, network architects, and venue operations directors, this creates a persistent operational tax: the time spent proving innocence.
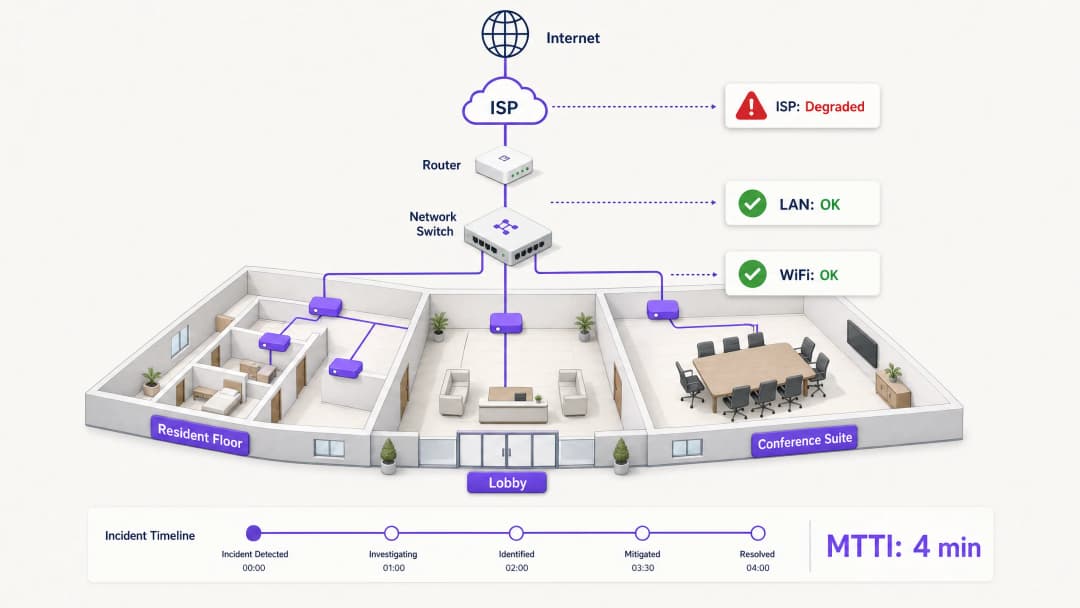
Mean time to innocence (MTTI) measures the average elapsed time between an incident being reported and a team's ability to demonstrate that their domain is not the root cause. In complex environments like build-to-rent (BTR) blocks, hotels, or conference centres, the network is fragmented across property managers, managed WiFi providers, and internet service providers (ISPs). Without definitive telemetry, MTTI inflates mean time to resolution (MTTR) as teams argue over responsibility rather than fixing the fault.
This guide details a five-step observability methodology to systematically reduce MTTI. By deploying continuous synthetic checks, hop-by-hop path visibility, flow data analysis, topology mapping, and event correlation, you can replace adversarial finger-pointing with shared evidence. The goal is not to win the blame game faster, but to end it entirely.
Technical Deep-Dive: The Mechanics of MTTI
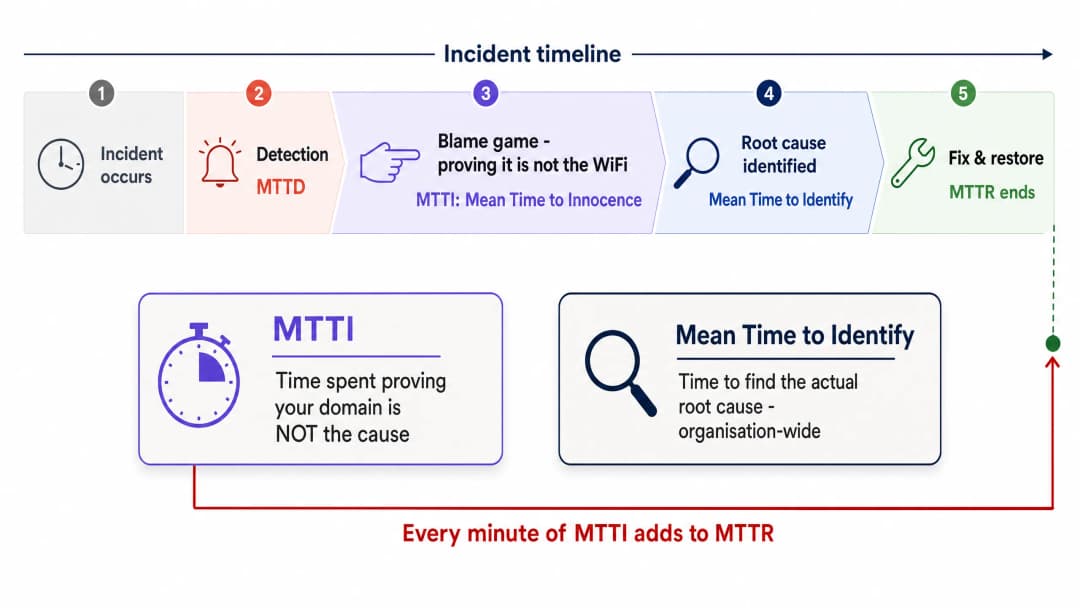
The Distinction Between MTTI and Mean Time to Identify
It is vital to separate MTTI from mean time to identify. Mean time to identify is an organisation-wide metric tracking how long it takes to find the actual root cause of an outage. MTTI is a siloed, domain-specific metric tracking how long it takes one team to prove they are not the culprit.
Every minute of MTTI adds directly to MTTR. If a managed WiFi provider spends 40 minutes manually checking access points (APs) and switch logs before concluding the issue lies with the ISP, the MTTR has a 40-minute penalty built in before the actual remediation even begins.
Why the WiFi Takes the Blame
In environments serving 350 million unique users across 80,000+ live venues, Purple sees the same pattern repeatedly. The WiFi layer is blamed by default due to three structural realities:
- Visibility bias: The WiFi signal indicator is the only network diagnostic tool available to the average venue user.
- Edge proximity: As the final hop to the client device, WiFi inherits the symptoms of every upstream failure. A DNS timeout at the ISP looks identical to an AP failure from the user's perspective.
- Telemetry gaps: Historically, proving wireless health required manual intervention. If you cannot show a clean bill of health for the wireless layer in under two minutes, you lose the narrative.
The Multi-Tenant Complication
In a single-tenant enterprise, network teams own the stack from the AP to the firewall. In Multi-Tenant WiFi environments, ownership is fractured.
A BTR resident pays the property manager. The property manager contracts a managed WiFi provider. The managed WiFi provider relies on a third-party ISP circuit and, often, the landlord's in-building distribution network. When a resident cannot stream video, the provider must rapidly exonerate the WiFi hardware (Cisco Meraki, HPE Aruba, Ruckus, or Juniper Mist) and isolate the fault to the client device, the building switch, or the ISP. Failure to do so damages the commercial relationship between the provider and the property manager.
Implementation Guide: The 5-Step Methodology
To systematically reduce MTTI, implement this five-layer observability architecture.
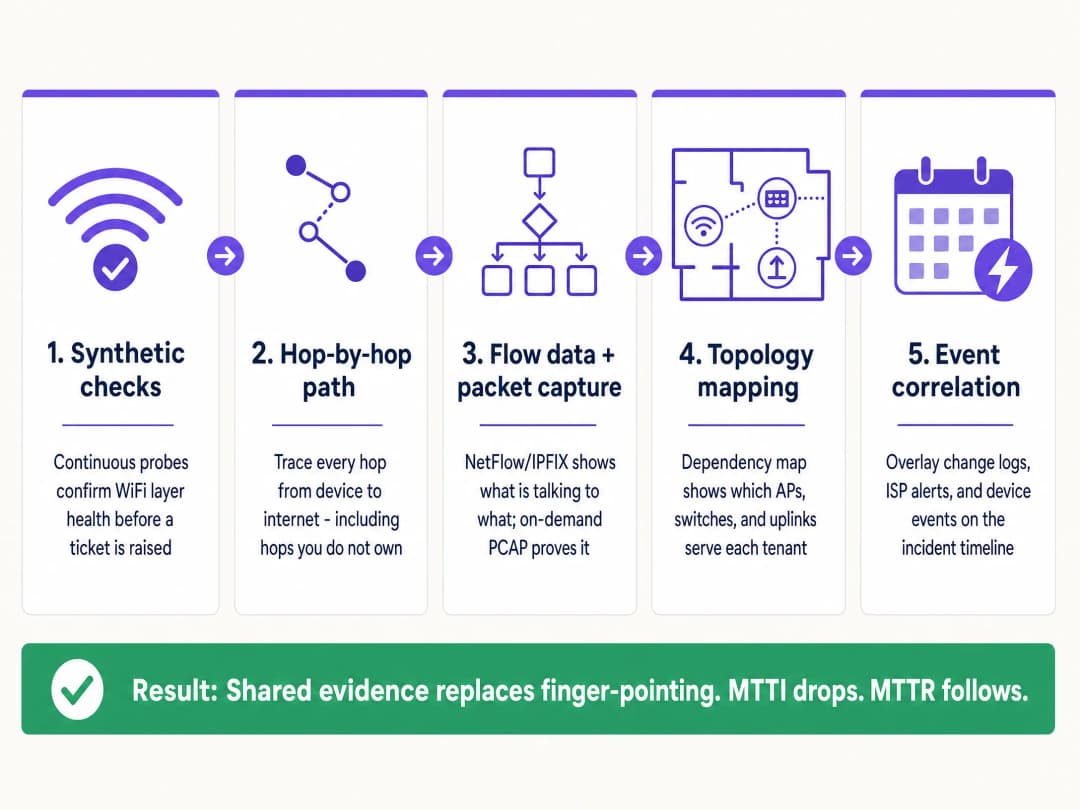
1. Continuous Synthetic Checks
Do not wait for a user to complain. Deploy automated synthetic probes that continuously emulate user behaviour from the network edge.
- Implementation: Configure APs or dedicated sensors to run scheduled tests for DHCP response, DNS resolution, HTTP reachability, and authentication flows (such as 802.1X or Captive Portal logins).
- Outcome: When a ticket is raised, you check the synthetic dashboard first. If the probes show clean HTTP reachability at the exact time of the complaint, you immediately exonerate the WiFi layer and the WAN circuit, shifting focus to the specific client device or the target application.
2. Hop-by-Hop Path Visibility
Proving your hardware is healthy is insufficient if you cannot prove the path to the internet is clear.
- Implementation: Use path visualisation tools to trace traffic from the access layer across the LAN, through the demarcation point, and into the ISP network.
- Outcome: When latency spikes, a path trace reveals exactly which node introduced the delay. If hops one through four (your domain) show 2ms latency, and hop five (the ISP edge router) shows 150ms latency and 12% packet loss, you have definitive proof to hand to the ISP.
3. Flow Data and On-Demand Packet Capture
When users report application-specific failures, you need conversation-level visibility.
- Implementation: Export NetFlow or IPFIX data from your core switches or firewalls. Ensure your access layer hardware supports remote, on-demand packet capture (PCAP) without requiring an engineer on site.
- Outcome: Flow data proves whether traffic to a specific service is leaving your network cleanly. If it is, the network is innocent. If deeper forensic proof is required, a targeted PCAP on the specific VLAN provides undeniable evidence of TCP retransmissions or server-side resets.
4. Topology and Dependency Mapping
In a multi-tenant environment, isolating the blast radius is the fastest way to categorise a fault.
- Implementation: Maintain a live, dynamically updated dependency map linking every AP to its switch, uplink, and WAN circuit, mapped against tenant VLANs.
- Outcome: If a fault affects APs across multiple floors but only on a single switch, the issue is the switch. If it affects all APs but only one tenant's VLAN, it is a logical configuration issue. Rapid scoping prevents wasted effort investigating healthy infrastructure.
5. Event Correlation
Data without context prolongs investigations.
- Implementation: Feed change logs, ISP maintenance alerts, hardware firmware updates, and user tickets into a single timeline view.
- Outcome: Overlaying a spike in authentication failures with a Microsoft Entra ID certificate expiration event that occurred 10 minutes prior immediately identifies the root cause, bypassing the network hardware entirely.
Best Practices
- Standardise the Hardware Stack: Limit deployments to canonical enterprise vendors (Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme, Fortinet) that expose APIs for synthetic testing and remote PCAP.
- Automate the Evidence: Configure your monitoring platform to automatically attach synthetic test results and path traces to ITSM tickets the moment they are created.
- Share the Dashboard: Provide property managers with read-only access to a high-level health dashboard. Transparency preempts the blame game.
- Track MTTI Formally: Measure the time between ticket creation and the moment your team provides evidence of innocence. Treat it as a primary KPI alongside MTTR.
Troubleshooting & Risk Mitigation
- Risk: The 'No Fault Found' Loop: Users report issues, but synthetic checks show green.
- Mitigation: The issue is likely device-specific or related to RF interference (co-channel interference or physical obstruction). Use client-side analytics to check the specific device's RSSI and roaming history.
- Risk: ISP Denial: The ISP refuses to accept the fault despite your evidence.
- Mitigation: Provide hop-by-hop path traces showing the exact IP address where packet loss begins. Share PCAPs demonstrating clean egress from your demarcation point. Hard data forces escalation past Level 1 support.
- Risk: Captive Portal Failures: Users blame the WiFi when the portal fails to load.
- Mitigation: Isolate the identity provider. Check the status of the integration (Microsoft Entra ID, Okta, Google Workspace). If the network allows pre-authentication traffic but the IdP times out, the network is innocent.
ROI & Business Impact
Reducing MTTI delivers measurable business value beyond simply saving engineering hours.
- Reduced MTTR: Stripping 40 minutes of finger-pointing from an incident directly reduces downtime, protecting revenue in retail and hospitality environments.
- SLA Compliance: Faster exoneration prevents unfair penalties being levied against the managed WiFi provider when the fault lies with the ISP or the building infrastructure.
- Client Retention: In the Multi-Tenant WiFi sector, property managers renew contracts with providers who offer transparency and rapid answers. Shared evidence builds trust; defensive arguments destroy it.
- Resource Optimisation: Highly paid Level 3 network engineers spend their time engineering solutions, rather than manually proving the network is functioning correctly.
Définitions clés
Temps moyen d'innocence (MTTI)
Temps moyen nécessaire à une équipe informatique spécifique pour prouver, à l'aide de données objectives, que son domaine ou son infrastructure n'est pas la cause racine d'un incident signalé.
Crucial pour les fournisseurs de WiFi géré qui doivent défendre leur service face aux gestionnaires immobiliers et aux FAI.
Temps moyen d'identification
Métrique globale de l'organisation mesurant le temps total écoulé entre la détection d'un incident et la découverte de sa cause racine réelle.
Le MTTI est un sous-ensemble de cette métrique. Réduire le MTTI réduit directement le temps global d'identification.
Contrôles synthétiques
Tests automatisés et continus qui simulent le trafic utilisateur (ex. requêtes DNS, requêtes HTTP) pour surveiller de manière proactive la santé du réseau.
Utilisés pour prouver que la couche WiFi fonctionnait correctement au moment précis où un utilisateur s'est plaint.
Visibilité du chemin saut par saut
Télémétrie qui trace le trafic réseau nœud par nœud, du client à la destination, en mesurant la latence et la perte au niveau de chaque routeur ou commutateur spécifique.
Essentielle pour prouver qu'un défaut provient du réseau d'un FAI ou du commutateur de distribution d'un propriétaire, plutôt que du matériel WiFi géré.
Données de flux (NetFlow/IPFIX)
Données de protocole réseau qui fournissent un résumé des conversations de trafic, indiquant la source, la destination, le protocole et le volume.
Utilisées pour prouver que le trafic d'une application spécifique quitte correctement le réseau local.
Capture de paquets à la demande (PCAP)
Capacité d'enregistrer à distance le trafic réseau brut depuis un point d'accès ou un commutateur à des fins d'analyse technique.
La preuve ultime utilisée pour démontrer des erreurs côté serveur ou un dysfonctionnement de l'appareil client.
Rayon d'impact
La portée de l'impact d'un incident spécifique (ex. un utilisateur, un AP, un commutateur, un locataire ou l'ensemble du bâtiment).
Déterminer le rayon d'impact via la cartographie de la topologie est le moyen le plus rapide d'exclure les infrastructures saines d'une enquête.
Corrélation d'événements
Pratique consistant à superposer différents flux de données (journaux, alertes, mises à jour) sur une chronologie unique pour identifier les causes et les effets.
Utilisée pour prouver qu'une panne réseau a été causée par une modification tierce, telle qu'une fenêtre de maintenance non annoncée d'un FAI.
Exemples concrets
Un hôtel de 350 chambres signale que le WiFi dans les chambres est lent dans tout l'établissement. La réception rejette la faute sur le fournisseur de WiFi géré. Comment disculper le réseau et trouver la cause racine ?
- Vérifier les sondes synthétiques : les tests de résolubilité DNS et d'accessibilité HTTP montrent que les AP ont une connexion propre à Internet. 2. Examiner la carte de topologie : le problème affecte tous les AP sur l'ensemble des commutateurs, ce qui exclut le matériel d'accès. 3. Exécuter un tracé de chemin : le tracé montre une latence de 2 ms au sein du LAN de l'hôtel, mais de 180 ms au troisième saut (le routeur d'agrégation du FAI). 4. Exporter les preuves : envoyer la capture d'écran du tracé de chemin au directeur de l'hôtel et au FAI.
Un détaillant national signale que les terminaux de point de vente (POS) d'une région perdent leurs connexions avec le processeur de paiement. L'équipe réseau est accusée d'une mauvaise configuration du pare-feu ou du routage.
- Isoler le rayon d'impact : confirmer que seuls les terminaux POS (VLAN spécifique) sont affectés ; le WiFi invités et les systèmes de back-office fonctionnent correctement. 2. Analyser les données de flux : NetFlow confirme que le trafic destiné à la plage IP du processeur de paiement quitte correctement les routeurs du magasin. 3. Capturer les paquets : un PCAP à la demande sur le VLAN POS révèle que le serveur du processeur de paiement envoie des réinitialisations TCP (RST). 4. Partager le PCAP avec l'équipe d'assistance du processeur de paiement.
Questions d'entraînement
Q1. Un locataire d'un espace de coworking se plaint de ne pas pouvoir accéder au VPN de son entreprise. Les autres locataires naviguent sur Internet sans problème. Quel est le moyen le plus efficace de prouver que le réseau WiFi n'est pas en cause ?
Conseil : Prenez en compte le rayon d'impact et le type spécifique de trafic en échec.
Voir la réponse type
Tout d'abord, utilisez la carte de topologie pour confirmer que le rayon d'impact est limité à un seul utilisateur ou à un service spécifique, ce qui exclut une panne générale d'AP ou de commutateur. Deuxièmement, analysez les données de flux (NetFlow/IPFIX) pour l'adresse IP de ce client. Si les données de flux montrent que le trafic VPN (par exemple, UDP 500 ou TCP 443) quitte proprement le réseau, le WiFi et le LAN sont hors de cause. Le problème provient soit de la configuration VPN du client, soit du pare-feu de l'entreprise qui bloque la connexion.
Q2. Votre tableau de bord de surveillance indique qu'un AP est hors ligne, mais le gestionnaire immobilier insiste sur le fait que le WiFi est en panne parce que le FAI est défaillant. Comment prouvez-vous que le problème est lié à l'alimentation interne et non au FAI ?
Conseil : Recherchez une corrélation entre l'état de l'infrastructure et les événements externes.
Voir la réponse type
Utilisez la corrélation d'événements et la cartographie de la topologie. Si la carte de topologie montre qu'un seul AP est hors ligne alors que les autres sur le même commutateur fonctionnent, le circuit du FAI est clairement actif. La corrélation d'événements pourrait révéler un journal d'échec PoE (Power over Ethernet) sur le port du commutateur connecté à cet AP spécifique. Cela prouve que le problème provient du matériel ou du câblage local, et non du circuit WAN.
Q3. Le directeur des opérations d'un stade affirme que le WiFi a échoué pendant la mi-temps car les scanners de billets ont cessé de fonctionner. Vous devez disculper le réseau en moins de deux minutes. Quelle télémétrie utilisez-vous ?
Conseil : Vous avez besoin d'une preuve historique de bon fonctionnement au moment exact de la panne signalée.
Voir la réponse type
Extrayez les données historiques des contrôles synthétiques continus. Montrez au directeur des opérations le tableau de bord confirmant que, pendant la fenêtre précise de 15 minutes de la mi-temps, les AP résolvaient correctement le DNS et atteignaient l'adresse IP du serveur de billetterie avec une faible latence. Cela prouve immédiatement que le réseau sans fil était sain et déplace l'enquête vers les serveurs d'applications de billetterie, qui ont probablement cédé sous la charge soudaine.
Continuer la lecture de cette série
Conception de réseaux WiFi pour les immeubles de bureaux multi-locataires
Ce guide fournit aux responsables informatiques, architectes réseau et CTO un plan indépendant des fournisseurs pour concevoir des réseaux WiFi évolutifs, sécurisés et isolés dans les immeubles de bureaux multi-locataires. Il traite de la segmentation VLAN sous IEEE 802.1Q, de l'attribution dynamique de VLAN via 802.1X et RADIUS, de la planification RF pour les environnements à haute densité et des considérations de conformité dans le cadre du GDPR et du PCI DSS. Les exploitants de sites et gestionnaires d'immeubles y trouveront des conseils d'architecture concrets, des études de cas réels et des pièges de configuration à éviter avant le déploiement.
Exigences légales et de conformité pour l'infrastructure WiFi partagée
Ce guide de référence technique fait autorité et présente les exigences légales, réglementaires et architecturales essentielles pour le déploiement et la gestion d'une infrastructure WiFi partagée. Il fournit aux responsables informatiques, aux architectes réseau et aux exploitants de sites des cadres exploitables pour garantir une protection robuste des données, une conformité stricte en matière de sécurité des paiements et une isolation performante des locataires selon les normes de l'entreprise.
Gestion de la bande passante et qualité de service (QoS) dans les espaces de co-working
Un guide de référence technique faisant autorité pour les responsables IT, les architectes réseau et les directeurs d'exploitation de sites sur la mise en œuvre de cadres robustes de gestion de la bande passante et de qualité de service (QoS) dans les environnements de co-working. Ce guide détaille la segmentation du réseau, la priorisation du trafic, les configurations indépendantes des fournisseurs et les indicateurs de ROI réels pour offrir une connectivité de classe entreprise. Il couvre les normes IEEE 802.11e/WMM, la conception de VLAN, la limitation du débit par utilisateur et les stratégies de dépannage avec des résultats commerciaux mesurables.