Tiempo medio para la inocencia: cómo demostrar que no es el WiFi
El tiempo medio para la inocencia (MTTI) es la métrica crítica que define cuánto tiempo pasan los equipos de TI demostrando que un problema de red no es su culpa. Esta guía detalla una metodología de observabilidad de cinco pasos para eliminar el juego de culpas en entornos multi-tenant, reemplazando los señalamientos con evidencia compartida para reducir el tiempo medio de resolución (MTTR).
Escucha esta guía
Ver transcripción del podcast
📚 Part of our core series: WiFi multi-tenant: la guía completa →
Resumen ejecutivo
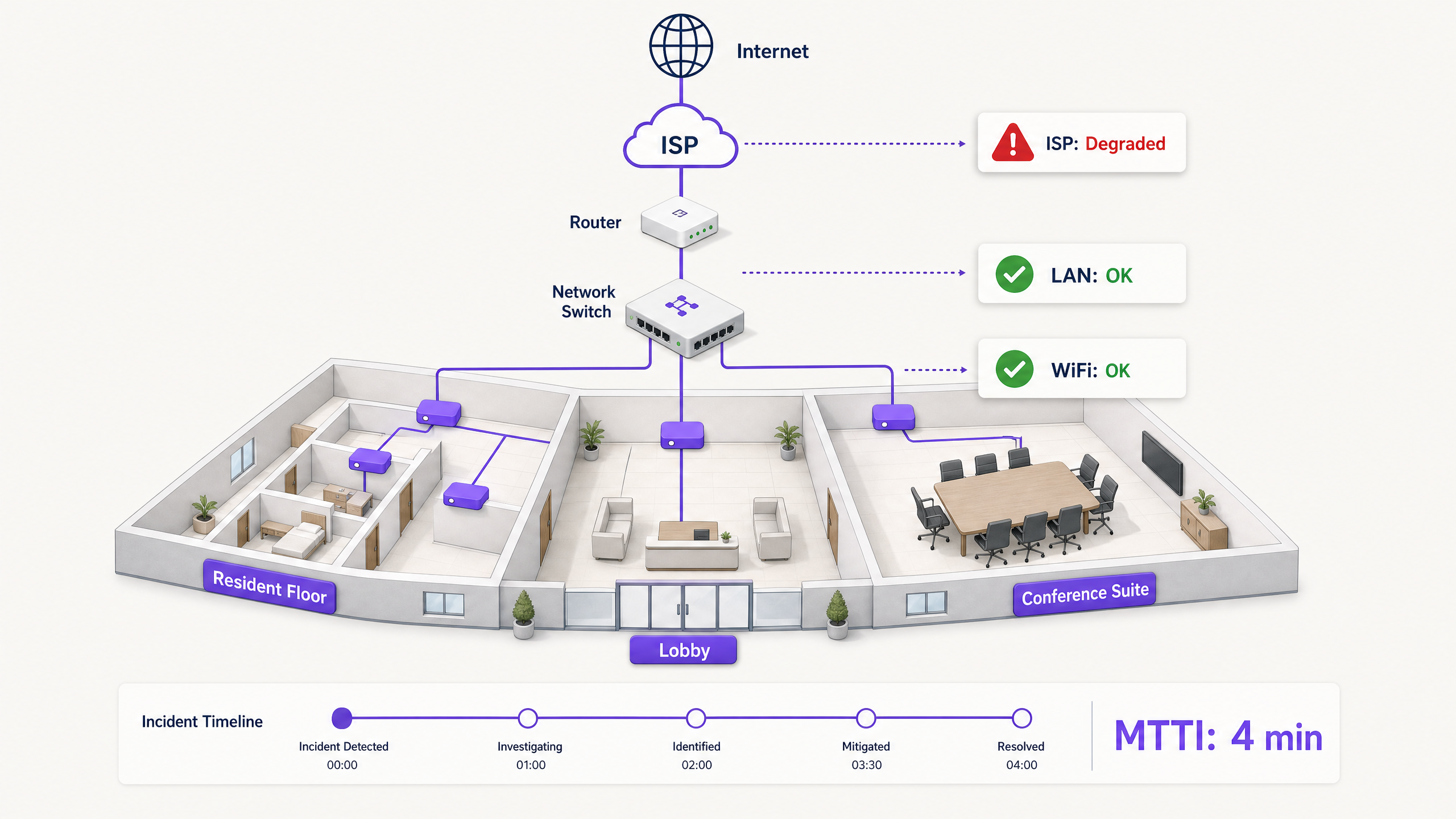
Cuando la conectividad cae en un entorno multi-tenant, el WiFi es el primer culpado. Es el extremo visible de la red, el último salto antes del dispositivo y el objetivo más fácil para los usuarios frustrados. Para los gerentes de TI, arquitectos de red y directores de operaciones de recintos, esto crea un impuesto operativo persistente: el tiempo dedicado a demostrar la inocencia.
El tiempo medio para la inocencia (MTTI) mide el tiempo promedio transcurrido entre el reporte de un incidente y la capacidad de un equipo para demostrar que su dominio no es la causa raíz. En entornos complejos como edificios de renta residencial (BTR), hoteles o centros de convenciones, la red está fragmentada entre administradores de propiedades, proveedores de WiFi gestionado y proveedores de servicios de internet (ISP). Sin una telemetría definitiva, el MTTI infla el tiempo medio de resolución (MTTR) mientras los equipos discuten sobre la responsabilidad en lugar de solucionar la falla.
Esta guía detalla una metodología de observabilidad de cinco pasos para reducir sistemáticamente el MTTI. Al implementar pruebas sintéticas continuas, visibilidad de ruta salto por salto, análisis de datos de flujo, mapeo de topología y correlación de eventos, puede reemplazar los señalamientos conflictivos con evidencia compartida. El objetivo no es ganar el juego de culpas más rápido, sino terminar con él por completo.
Análisis técnico profundo: La mecánica del MTTI
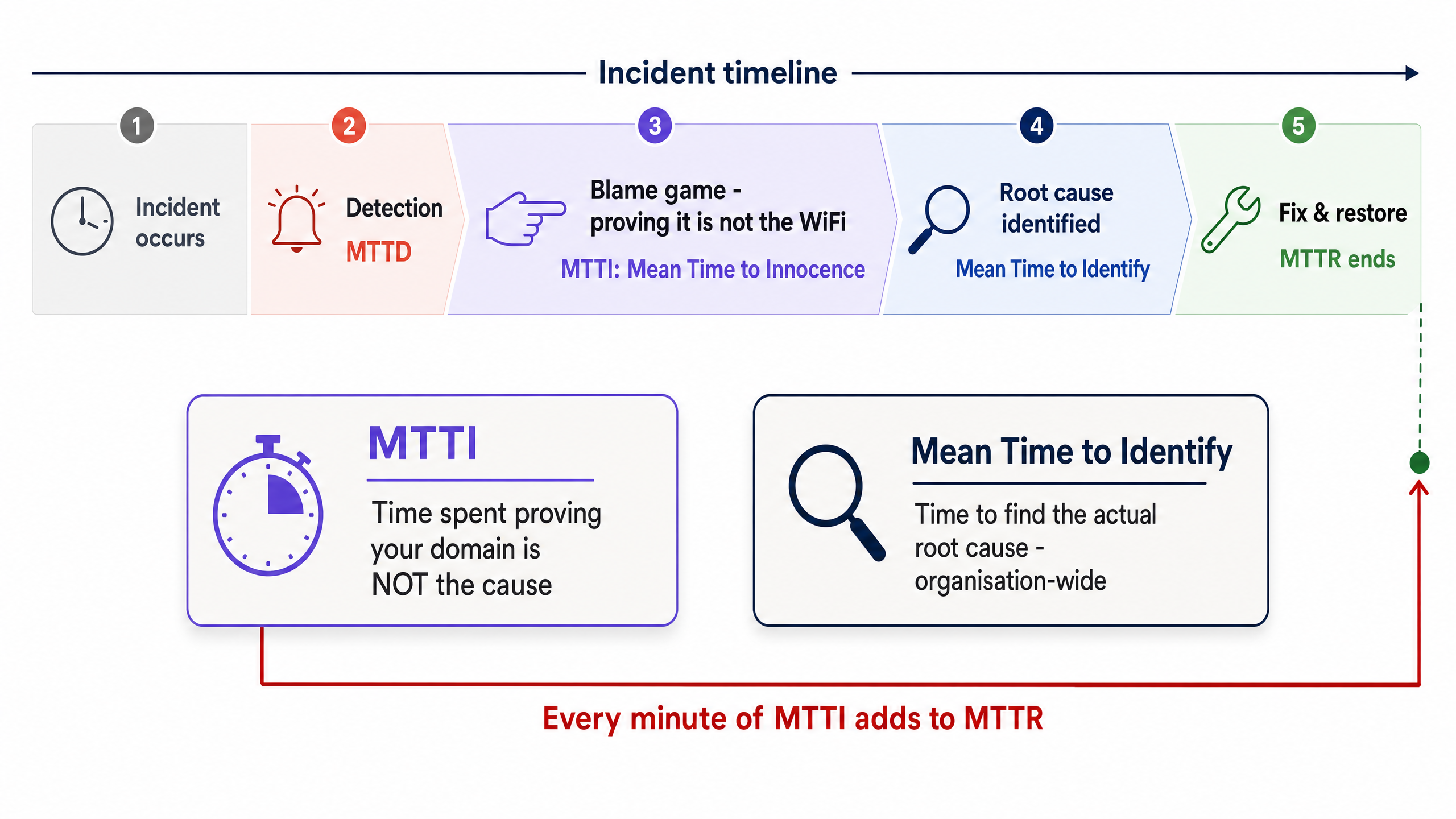
La distinción entre MTTI y el tiempo medio de identificación
Es vital separar el MTTI del tiempo medio de identificación. El tiempo medio de identificación es una métrica a nivel de toda la organización que rastrea cuánto tiempo se tarda en encontrar la causa raíz real de una interrupción. El MTTI es una métrica aislada y específica de un dominio que rastrea cuánto tiempo le toma a un equipo demostrar que no es el culpable.
Cada minuto de MTTI se suma directamente al MTTR. Si un proveedor de WiFi gestionado pasa 40 minutos revisando manualmente los puntos de acceso (AP) y los registros de los switches antes de concluir que el problema radica en el ISP, el MTTR tiene una penalización de 40 minutos integrada antes de que comience la remediación real.
Por qué se culpa al WiFi
En entornos que atienden a 350 millones de usuarios únicos en más de 80,000 recintos activos, Purple observa el mismo patrón repetidamente. Se culpa a la capa de WiFi de forma predeterminada debido a tres realidades estructurales:
- Sesgo de visibilidad: El indicador de señal WiFi es la única herramienta de diagnóstico de red disponible para el usuario promedio del recinto.
- Proximidad del extremo: Como el último salto hacia el dispositivo del cliente, el WiFi hereda los síntomas de cada falla ascendente. Un tiempo de espera agotado de DNS en el ISP se ve idéntico a una falla de AP desde la perspectiva del usuario.
- Brechas de telemetría: Históricamente, demostrar el buen estado de la red inalámbrica requería intervención manual. Si no puede mostrar un estado de salud óptimo de la capa inalámbrica en menos de dos minutos, pierde el control de la situación.
La complicación multi-tenant
En una empresa single-tenant, los equipos de red son propietarios de toda la infraestructura, desde el AP hasta el firewall. En entornos de WiFi multi-tenant, la propiedad está fragmentada.
Un residente de BTR le paga al administrador de la propiedad. El administrador de la propiedad contrata a un proveedor de WiFi gestionado. El proveedor de WiFi gestionado depende de un circuito ISP de terceros y, a menudo, de la red de distribución interna del edificio del propietario. Cuando un residente no puede transmitir video, el proveedor debe exonerar rápidamente el hardware de WiFi (Cisco Meraki, HPE Aruba, Ruckus o Juniper Mist) y aislar la falla en el dispositivo del cliente, el switch del edificio o el ISP. No hacerlo daña la relación comercial entre el proveedor y el administrador de la propiedad.
Guía de implementación: La metodología de 5 pasos
Para reducir sistemáticamente el MTTI, implemente esta arquitectura de observabilidad de cinco capas.
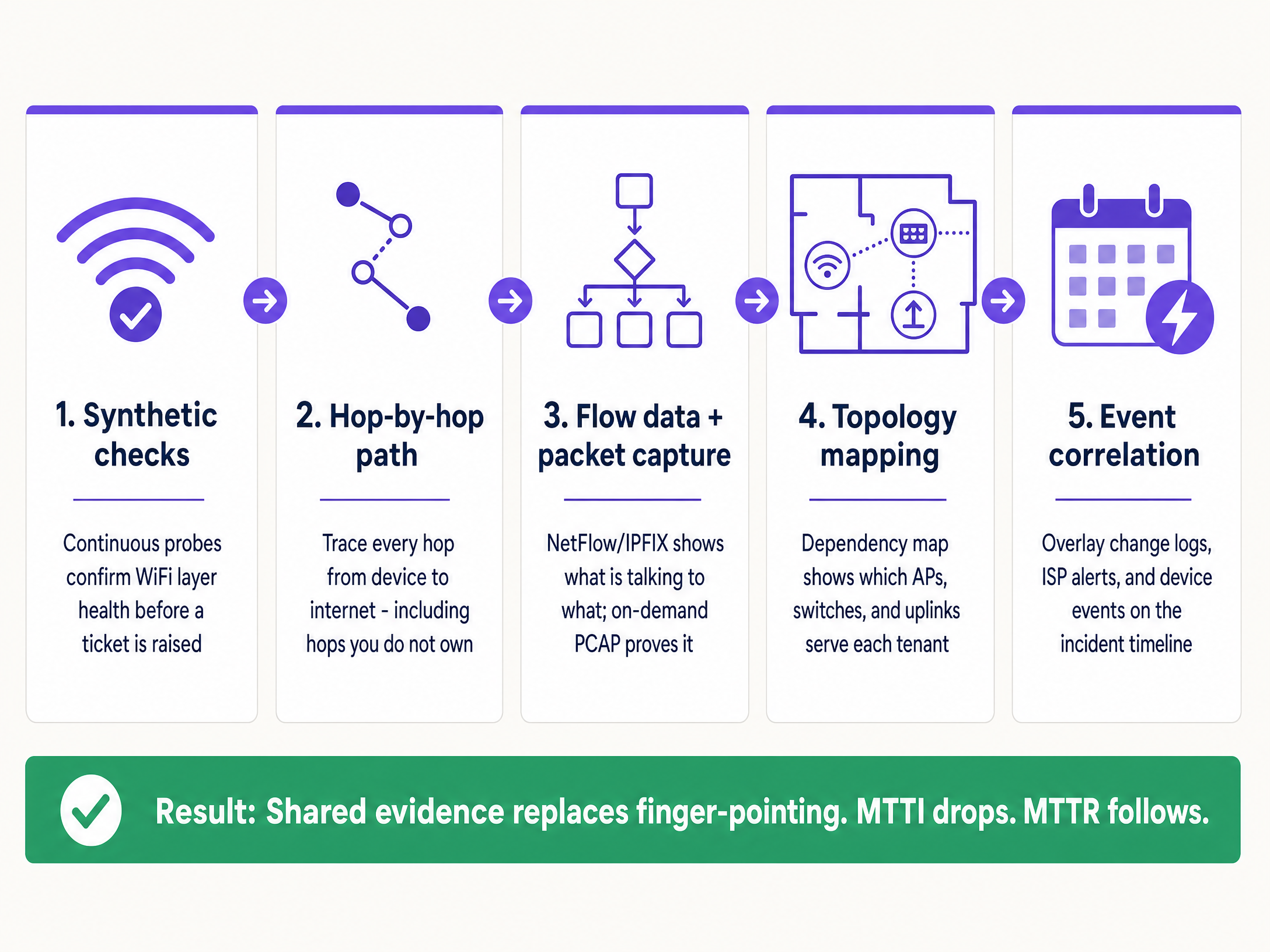
1. Pruebas sintéticas continuas
No espere a que un usuario se queje. Implemente sondas sintéticas automatizadas que emulen continuamente el comportamiento del usuario desde el extremo de la red.
- Implementación: Configure los AP o sensores dedicados para ejecutar pruebas programadas de respuesta DHCP, resolución DNS, accesibilidad HTTP y flujos de autenticación (como 802.1X o inicios de sesión de Captive Portal).
- Resultado: Cuando se genera un ticket, primero revisa el panel sintético. Si las sondas muestran una accesibilidad HTTP limpia en el momento exacto de la queja, exonera inmediatamente la capa de WiFi y el circuito WAN, cambiando el enfoque hacia el dispositivo cliente específico o la aplicación de destino.
2. Visibilidad de ruta salto por salto
Demostrar que su hardware está en buen estado es insuficiente si no puede probar que la ruta a internet está despejada.
- Implementación: Utilice herramientas de visualización de rutas para rastrear el tráfico desde la capa de acceso a través de la LAN, pasando por el punto de demarcación y hacia la red del ISP.
- Resultado: Cuando la latencia aumenta, un rastreo de ruta revela exactamente qué nodo introdujo el retraso. Si los saltos del uno al cuatro (su dominio) muestran una latencia de 2 ms, y el salto cinco (el router de borde del ISP) muestra una latencia de 150 ms y un 12% de pérdida de paquetes, tiene una prueba definitiva para entregar al ISP.
3. Datos de flujo y captura de paquetes bajo demanda
Cuando los usuarios reportan fallas específicas de una aplicación, necesita visibilidad a nivel de conversación.
- Implementación: Exporte datos NetFlow o IPFIX desde sus switches principales o firewalls. Asegúrese de que el hardware de su capa de acceso admita la captura de paquetes (PCAP) remota y bajo demanda sin requerir un ingeniero en el sitio.
- Resultado: Los datos de flujo demuestran si el tráfico a un servicio específico está saliendo de su red de manera limpia. Si es así, la red es inocente. Si dSi se requiere una prueba forense más profunda, un PCAP dirigido en la VLAN específica proporciona evidencia innegable de retransmisiones TCP o restablecimientos del lado del servidor.
4. Topology and Dependency Mapping
En un entorno multi-tenant, aislar el radio de impacto es la forma más rápida de categorizar una falla.
- Implementación: Mantenga un mapa de dependencias en vivo y actualizado dinámicamente que vincule cada AP con su switch, uplink y circuito WAN, mapeado con las VLAN de los inquilinos.
- Resultado: Si una falla afecta a los AP en varios pisos pero solo en un único switch, el problema es el switch. Si afecta a todos los AP pero solo a la VLAN de un inquilino, se trata de un problema de configuración lógica. La delimitación rápida del alcance evita perder tiempo investigando infraestructura en buen estado.
5. Correlación de eventos
Los datos sin contexto prolongan las investigaciones.
- Implementación: Integre los registros de cambios, alertas de mantenimiento del ISP, actualizaciones de firmware de hardware y tickets de soporte de los usuarios en una sola vista de línea de tiempo.
- Resultado: Superponer un pico en las fallas de autenticación con un evento de vencimiento de certificado de Microsoft Entra ID que ocurrió 10 minutos antes identifica de inmediato la causa raíz, omitiendo por completo el hardware de red.
Mejores prácticas
- Estandarice el stack de hardware: Limite las implementaciones a proveedores empresariales reconocidos (Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme, Fortinet) que expongan API para pruebas sintéticas y PCAP remoto.
- Automatice la evidencia: Configure su plataforma de monitoreo para adjuntar automáticamente los resultados de las pruebas sintéticas y los rastreos de ruta a los tickets de ITSM en el momento en que se crean.
- Comparta el dashboard: Proporcione a los administradores de la propiedad acceso de solo lectura a un dashboard de estado de alto nivel. La transparencia evita el juego de culpas.
- Monitoree el MTTI formalmente: Mida el tiempo entre la creación del ticket y el momento en que su equipo proporciona evidencia de inocencia. Trátelo como un KPI principal junto con el MTTR.
Resolución de problemas y mitigación de riesgos
- Riesgo: El bucle de 'falla no encontrada': Los usuarios reportan problemas, pero las comprobaciones sintéticas se muestran en verde.
- Mitigación: Es probable que el problema sea específico del dispositivo o esté relacionado con la interferencia de RF (interferencia de co-canal u obstrucción física). Utilice analíticas del lado del cliente para verificar el RSSI y el historial de roaming del dispositivo específico.
- Riesgo: Negación del ISP: El ISP se niega a aceptar la falla a pesar de su evidencia.
- Mitigación: Proporcione rastreos de ruta salto por salto que muestren la dirección IP exacta donde comienza la pérdida de paquetes. Comparta los PCAP que demuestren una salida limpia desde su punto de demarcación. Los datos objetivos obligan a escalar el problema más allá del soporte de Nivel 1.
- Riesgo: Fallas del Captive Portal: Los usuarios culpan al WiFi cuando el portal no carga.
- Mitigación: Aísle al proveedor de identidad. Verifique el estado de la integración (Microsoft Entra ID, Okta, Google Workspace). Si la red permite el tráfico de preautenticación pero el IdP agota el tiempo de espera, la red es inocente.
ROI e impacto comercial
Reducir el MTTI ofrece un valor comercial medible que va más allá de simplemente ahorrar horas de ingeniería.
- MTTR reducido: Eliminar 40 minutos de señalamientos mutuos en un incidente reduce directamente el tiempo de inactividad, protegiendo los ingresos en entornos de retail y hospitality .
- Cumplimiento de SLA: Una exoneración más rápida evita que se apliquen penalizaciones injustas al proveedor de WiFi administrado cuando la falla radica en el ISP o en la infraestructura del edificio.
- Retención de clientes: En el sector de WiFi multi-tenant, los administradores de propiedades renuevan contratos con proveedores que ofrecen transparencia y respuestas rápidas. La evidencia compartida genera confianza; los argumentos defensivos la destruyen.
- Optimización de recursos: Los ingenieros de red de Nivel 3, altamente calificados, dedican su tiempo a diseñar soluciones en lugar de demostrar manualmente que la red funciona correctamente.
Definiciones clave
Mean Time to Innocence (MTTI)
The average time required for a specific IT team to prove, using objective data, that their domain or infrastructure is not the root cause of a reported incident.
Critical for managed WiFi providers who must defend their service against property managers and ISPs.
Mean Time to Identify
The organisation-wide metric tracking the total time elapsed from incident detection to the discovery of the actual root cause.
MTTI is a subset of this metric. Reducing MTTI directly reduces the overall time to identify.
Synthetic Checks
Automated, continuous tests that emulate user traffic (e.g., DNS lookups, HTTP requests) to proactively monitor network health.
Used to prove the WiFi layer was functioning correctly at the exact moment a user complained.
Hop-by-Hop Path Visibility
Telemetry that traces network traffic node-by-node from the client to the destination, measuring latency and loss at each specific router or switch.
Essential for proving a fault lies in an ISP network or a landlord's distribution switch, rather than the managed WiFi hardware.
Flow Data (NetFlow/IPFIX)
Network protocol data that provides a summary of traffic conversations, showing source, destination, protocol, and volume.
Used to prove that specific application traffic is successfully leaving the local network.
On-Demand Packet Capture (PCAP)
The ability to remotely record raw network traffic from an access point or switch for forensic analysis.
The ultimate proof used to demonstrate server-side errors or client device misbehaviour.
Blast Radius
The scope of impact of a specific incident (e.g., one user, one AP, one switch, one tenant, or the entire building).
Determining the blast radius via topology mapping is the fastest way to exclude healthy infrastructure from an investigation.
Event Correlation
The practice of overlaying different data streams (logs, alerts, updates) on a single timeline to identify cause and effect.
Used to prove that a network outage was caused by a third-party change, such as an unannounced ISP maintenance window.
Ejemplos resueltos
A 350-room hotel reports that in-room WiFi is slow across the entire property. The front desk blames the managed WiFi provider. How do you exonerate the network and find the root cause?
- Check the synthetic probes: DNS and HTTP reachability tests show the APs have a clean connection to the internet. 2. Review the topology map: The issue affects all APs across all switches, ruling out edge hardware. 3. Execute a path trace: The trace shows 2ms latency within the hotel LAN, but 180ms latency at the third hop (the ISP's aggregation router). 4. Export the evidence: Send the path trace screenshot to the hotel manager and the ISP.
A national retailer reports point-of-sale (POS) terminals in one region are dropping connections to the payment processor. The network team is blamed for a firewall or routing misconfiguration.
- Isolate the blast radius: Confirm only POS terminals (specific VLAN) are affected; guest WiFi and back-office systems are healthy. 2. Analyse flow data: NetFlow confirms traffic destined for the payment processor's IP range is successfully leaving the store routers. 3. Capture packets: An on-demand PCAP on the POS VLAN reveals the payment processor's server is sending TCP resets (RST). 4. Share the PCAP with the payment processor's support team.
Preguntas de práctica
Q1. A tenant in a coworking space complains they cannot access their corporate VPN. Other tenants are browsing the internet without issue. What is the most efficient way to prove the WiFi network is not at fault?
Sugerencia: Consider the blast radius and the specific type of traffic failing.
Ver respuesta modelo
First, use the topology map to confirm the blast radius is limited to one user or one specific service, ruling out a general AP or switch failure. Second, analyse flow data (NetFlow/IPFIX) for that client's IP address. If the flow data shows the VPN traffic (e.g., UDP 500 or TCP 443) is leaving the network cleanly, the WiFi and LAN are innocent. The issue is either the client's VPN configuration or the corporate firewall blocking the connection.
Q2. Your monitoring dashboard shows an AP has gone offline, but the property manager insists the WiFi is broken because the ISP is down. How do you prove the issue is internal power, not the ISP?
Sugerencia: Look for correlation between infrastructure state and external events.
Ver respuesta modelo
Use event correlation and topology mapping. If the topology map shows only one AP is offline while others on the same switch are functioning, the ISP circuit is clearly active. Event correlation might show a PoE (Power over Ethernet) failure log from the switch port connected to that specific AP. This proves the issue is local hardware or cabling, not the WAN circuit.
Q3. A stadium operations director claims the WiFi failed during halftime because ticket scanners stopped working. You need to exonerate the network in under two minutes. What telemetry do you use?
Sugerencia: You need historical proof of health at the exact moment of the reported failure.
Ver respuesta modelo
Pull the historical data from the continuous synthetic checks. Show the operations director the dashboard confirming that during the exact 15-minute halftime window, the APs were successfully resolving DNS and reaching the ticketing server's IP address with low latency. This immediately proves the wireless network was healthy and shifts the investigation to the ticketing application servers, which likely buckled under the sudden load.
Continúe leyendo esta serie
La guía empresarial de SCEP: Implementación de Simple Certificate Enrollment Protocol para la seguridad automatizada de WiFi en campus
Esta guía de referencia técnica proporciona un diseño arquitectónico definitivo y una estrategia de implementación paso a paso para la implementación de certificados de WiFi empresariales mediante SCEP. Cubre las diferencias críticas entre SCEP y PKCS, la secuencia de implementación exacta requerida para el éxito y estrategias de mitigación de riesgos del mundo real para líderes de TI.
¿Por qué no se conecta mi WiFi de invitados? Resolución de problemas de Captive Portal
Esta guía de referencia técnica autorizada explica la mecánica subyacente de la detección de Captive Portal y detalla los seis modos de falla principales que impiden que el WiFi de invitados se conecte. Proporciona a los gerentes de TI y arquitectos de red un marco de trabajo práctico para la resolución de problemas para resolver conflictos de redirección HTTP, DNS y desafíos de aleatorización de direcciones MAC.
Cómo implementar SCEP para la inscripción automatizada de certificados WiFi
Esta guía explica cómo implementar SCEP (Simple Certificate Enrollment Protocol) para la inscripción automatizada de certificados WiFi en entornos empresariales. Cubre el diseño arquitectónico completo, desde el diseño de PKI y la integración de MDM hasta la secuencia de implementación obligatoria de tres pasos, y muestra a los administradores de TI y arquitectos de red cómo eliminar las credenciales compartidas, automatizar la gestión del ciclo de vida de los certificados y cumplir con los requisitos de PCI DSS y GDPR a escala.