RADIUS Server High Availability: Active-Active vs Active-Passive
Una guía de referencia técnica definitiva para directores de TI y arquitectos de red que evalúan arquitecturas de alta disponibilidad de RADIUS. Contrasta los despliegues Active-Active y Active-Passive, detalla los requisitos de replicación de bases de datos y explica cómo Cloud RADIUS mitiga la latencia de conmutación por error para recintos empresariales.
Escuchar esta guía
Ver transcripción del podcast
📚 Parte de nuestra serie principal: Enterprise WiFi Security Guide →

Resumen Ejecutivo
Para las redes empresariales, la autenticación es binaria: o funciona a la perfección o las operaciones comerciales se detienen por completo. RADIUS (Remote Authentication Dial-In User Service) actúa como el guardián crítico para IEEE 802.1X, WPA3 enterprise y despliegues de Guest WiFi en espacios modernos. A diferencia de los servicios de aplicaciones que se degradan de forma progresiva bajo carga, un fallo de RADIUS bloquea inmediatamente el acceso a la red a usuarios, terminales de punto de venta y dispositivos operativos.
Esta guía de referencia técnica evalúa los modelos de arquitectura para desplegar una infraestructura RADIUS de alta disponibilidad. En concreto, contrasta las configuraciones tradicionales Activo-Pasivo con los clústeres modernos Activo-Activo. Para los responsables de TI, arquitectos de red y directores de operaciones de recintos que gestionan entornos de alta densidad como Retail , Hospitality y estadios, es esencial comprender estas estrategias de failover, la mecánica de equilibrio de carga y los requisitos de replicación de bases de datos.
Además, esta guía examina cómo las plataformas Cloud RADIUS abstraen la complejidad de la alta disponibilidad, proporcionando failover automático y escalabilidad elástica sin la carga operativa de mantener una infraestructura local redundante. Al aplicar estas mejores prácticas independientes del proveedor, los equipos de ingeniería pueden diseñar arquitecturas de autenticación que eliminen los puntos únicos de fallo y cumplan con los estrictos Acuerdos de Nivel de Servicio (SLA) de tiempo de actividad.
Análisis Técnico Profundo: Comprensión de la Arquitectura RADIUS
RADIUS funciona como un protocolo cliente-servidor sobre UDP, utilizando normalmente el puerto 1812 para la autenticación y el puerto 1813 para la contabilidad (accounting), tal como se define en RFC 2865 y RFC 2866. La naturaleza sin estado (stateless) de las solicitudes de autenticación UDP es una ventaja estructural para el diseño de alta disponibilidad. Dado que cada paquete Access-Request contiene todas las credenciales y parámetros necesarios, cualquier servidor RADIUS dentro de un clúster puede procesar cualquier solicitud de forma independiente, sin requerir una sincronización de estado compleja para la fase de autenticación en sí.
Arquitectura Activo-Pasivo
En un despliegue Activo-Pasivo (o primario-secundario), un único servidor RADIUS procesa todo el tráfico entrante de autenticación y contabilidad. Un servidor secundario permanece en línea pero inactivo, recibiendo actualizaciones de replicación de la base de datos pero sin responder activamente a los Dispositivos de Acceso a la Red (NAD), como puntos de acceso, switches o pasarelas VPN.
Cuando el servidor principal falla, el NAD detecta el tiempo de espera agotado y redirige las solicitudes posteriores al servidor secundario. El tiempo de detección de conmutación por error depende completamente de los temporizadores de configuración del NAD. Un NAD típico envía una solicitud RADIUS y espera un tiempo de espera de paquete predeterminado (a menudo dos segundos). Si no recibe respuesta, lo reintenta. Con una configuración estándar de tres intentos por servidor, el NAD puede esperar hasta seis segundos antes de declarar inactivo el servidor principal y conmutar por error al secundario. En entornos con tres servidores configurados, esta ventana de conmutación por error puede extenderse hasta dieciocho segundos. Para un establecimiento de Hospitality concurrido o un entorno de Retail que procesa transacciones, este retraso representa una interrupción notable del servicio.
Arquitectura Activo-Activo
Por el contrario, una arquitectura Activo-Activo distribuye la carga de autenticación entre múltiples servidores RADIUS operativos simultáneamente. El tráfico se enruta al clúster mediante una configuración de tipo round-robin en los NAD o a través de un equilibrador de carga dedicado.
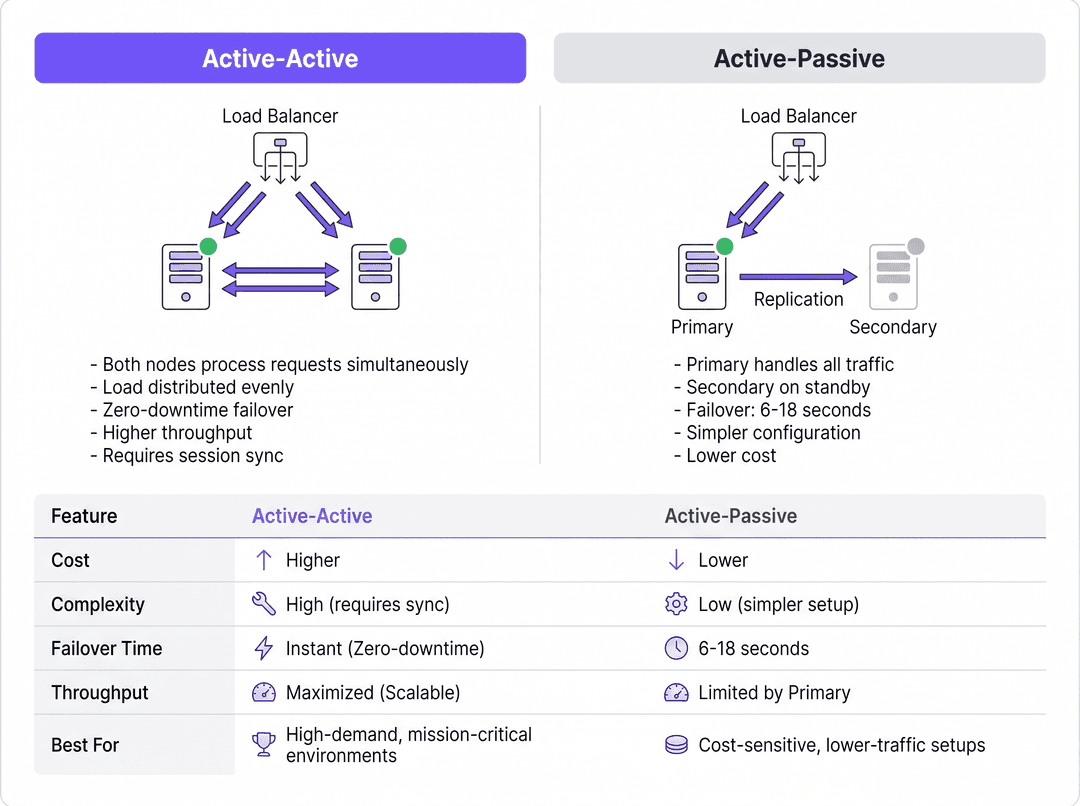
Este modelo elimina el retraso en la detección de conmutación por error inherente a las configuraciones Activo-Pasivo. Si un nodo falla, el equilibrador de carga (o los NAD que utilizan round-robin) simplemente deja de enrutar tráfico al servidor que no responde, normalmente en un plazo de uno a dos segundos según los intervalos de comprobación de estado. Los nodos activos restantes absorben el tráfico al instante. Además, los clústeres Activo-Activo se escalan horizontalmente; añadir capacidad para eventos de alta densidad simplemente requiere aprovisionar nodos adicionales en el clúster.
El desafío de la replicación de bases de datos
Aunque la autenticación RADIUS no tiene estado, el registro de conexiones (accounting) de RADIUS es inherentemente con estado. Realiza el seguimiento del inicio de la sesión (Start), el uso continuo (Interim-Update) y la finalización (Stop). Para los establecimientos que utilizan WiFi Analytics o sistemas de facturación, estos datos de contabilidad deben mantener la coherencia en todos los nodos.
Respaldar un clúster RADIUS con una base de datos replicada (como MySQL o MariaDB integrada con FreeRADIUS) es obligatorio para una alta disponibilidad sólida. Para despliegues Activo-Activo, se requiere una replicación síncrona multimaestro, como Galera Cluster o MySQL NDB Cluster. La replicación síncrona garantiza que un registro de contabilidad se confirme en todos los nodos simultáneamente, evitando la pérdida de datos si un nodo falla. La replicación asíncrona tradicional, utilizada a menudo en configuraciones Activo-Pasivo, introduce un retraso de replicación. Si el nodo principal falla antes de que el secundario reciba la actualización, los datos de la sesión activa se pierden de forma permanente, lo que puede vulnerar marcos de cumplimiento normativo como PCI DSS.
Guía de implementación: Cloud frente a On-Premise
La decisión arquitectónica va más allá de cómo agrupar los servidores; implica dónde residen dichos servidores. Para los operadores multisitio, el retorno del tráfico de autenticación (backhauling) a un centro de datos local centralizado introduce latencia de WAN y crea un punto único de fallo en el enlace WAN.
Plataformas Cloud RADIUS
Los servicios Cloud RADIUS resuelven los desafíos de distribución geográfica al alojar la infraestructura de autenticación en múltiples zonas de disponibilidad globales. Cuando un usuario se conecta en una sucursal, la solicitud se enruta al nodo perimetral de la nube más cercano, minimizando la latencia.
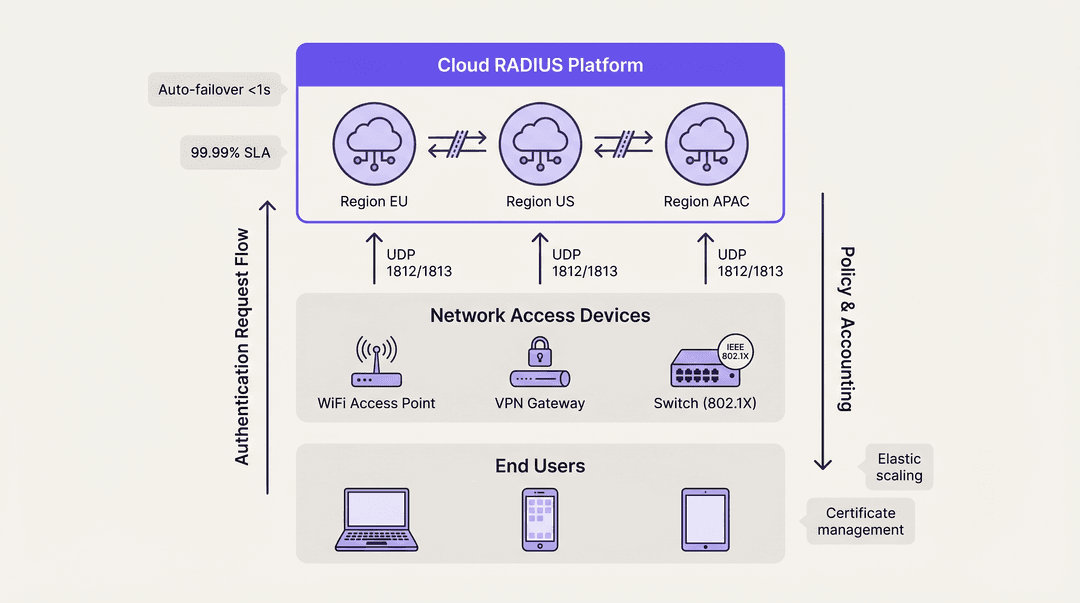
Las plataformas en la nube utilizan de forma inherente arquitecturas Activo-Activo. La conmutación por error entre zonas de disponibilidad se gestiona automáticamente mediante el equilibrio de carga interno del proveedor, abstrayendo por completo la complejidad para el equipo de ingeniería del cliente. Este modelo suele ofrecer SLA de tiempo de actividad del 99,99 % y elimina la necesidad de gestionar certificados manualmente, aplicar parches al sistema operativo y ajustar la replicación de bases de datos. Para las organizaciones que implementan Wayfinding o Sensors en campus distribuidos, la autenticación alojada en la nube garantiza una aplicación coherente de las políticas sin dependencias de hardware localizadas.
Consideraciones para la implementación local (On-Premise)
Las organizaciones que operan en sectores altamente regulados —como determinados entornos de Healthcare o gubernamentales— pueden requerir implementaciones locales debido a estrictos mandatos de soberanía de datos. En estos escenarios, implementar un clúster FreeRADIUS Activo-Activo con replicación síncrona de Galera proporciona el mayor nivel de resiliencia.
Sin embargo, los equipos de ingeniería deben tener en cuenta la sobrecarga operativa. La gestión de certificados TLS en múltiples nodos, la garantía de la coherencia de la configuración y la supervisión activa del estado de la replicación de la base de datos requieren recursos administrativos dedicados. Los equilibradores de carga de hardware deben configurarse específicamente para admitir tráfico UDP con las comprobaciones de estado de RADIUS adecuadas, ya que muchos equilibradores de carga estándar están optimizados únicamente para tráfico TCP HTTP/HTTPS.
Buenas prácticas para la alta disponibilidad de RADIUS
- Distribuir en lugar de duplicar: Para implementaciones que superen los 500 usuarios concurrentes, priorice las arquitecturas Activo-Activo sobre las configuraciones Activo-Pasivo para maximizar el rendimiento y minimizar la latencia de conmutación por error.
- Implementar replicación síncrona: Proteja los datos de contabilidad con estado utilizando una replicación síncrona de base de datos multimaestro (por ejemplo, Galera Cluster) en lugar de modelos asíncronos de réplica primaria.
- Estandarizar la confianza de los certificados: En un clúster Activo-Activo, asegúrese de que todos los nodos presenten el mismo certificado de servidor o certificados de la misma cadena de Entidad de Certificación (CA). Las discrepancias provocarán que los saludos EAP-TLS y PEAP fallen durante la rotación de nodos.
- Ajustar los temporizadores NAD: optimice los temporizadores de reintento y tiempo de espera de RADIUS en sus dispositivos de acceso a la red (Network Access Devices). Un tiempo de espera de dos segundos con dos reintentos ofrece un equilibrio entre la detección rápida de fallos y la prevención de conmutaciones por error prematuras durante congestiones leves de la red.
- Probar escenarios de fallo: trate los nodos secundarios como sistemas de producción. Simule periódicamente fallos de nodos, desincronizaciones de bases de datos y caídas de enlaces WAN para validar que los mecanismos de conmutación por error automatizados funcionen según lo previsto.
Resolución de problemas y mitigación de riesgos
El modo de fallo más frecuente en la alta disponibilidad de RADIUS es la desviación de la configuración. En las configuraciones Activo-Pasivo, los administradores suelen actualizar las políticas o renovar los certificados en el nodo primario, pero descuidan el secundario. Cuando se produce un evento de conmutación por error, el nodo secundario rechaza el tráfico legítimo debido a credenciales caducadas o políticas desactualizadas.
Para mitigar este riesgo, implemente herramientas de gestión de configuración (como Ansible o Terraform) para implementar cambios de forma simétrica en todos los nodos. Para la gestión de certificados, utilice protocolos de renovación automatizados (como ACME) configurados para distribuir el certificado actualizado en todo el clúster de forma simultánea.
Otro riesgo importante es la configuración incorrecta del equilibrador de carga. Si un equilibrador de carga no realiza comprobaciones de estado a nivel de aplicación (específicamente verificando la capacidad de respuesta del puerto UDP 1812), puede seguir enrutando tráfico a un nodo donde el sistema operativo está funcionando pero el demonio RADIUS se ha caído. Asegúrese de que las comprobaciones de estado validen explícitamente la disponibilidad del servicio RADIUS.
ROI e impacto empresarial
El retorno de la inversión de una alta disponibilidad de RADIUS sólida se mide principalmente a través de la mitigación de riesgos y la eficiencia operativa. Las interrupciones de autenticación provocan pérdidas inmediatas de productividad para los empleados y graves daños a la reputación de los establecimientos abiertos al público.
Al pasar de implementaciones manuales de un solo servidor a arquitecturas automatizadas Activo-Activo (particularmente a través de Cloud RADIUS), las organizaciones recuperan importantes horas de ingeniería que antes se dedicaban al mantenimiento rutinario. Esta eficiencia operativa permite a los equipos de red centrarse en iniciativas estratégicas, como la implementación de The Core SD WAN Benefits for Modern Businesses o la optimización de la cobertura de alta densidad, en lugar de resolver fallos de autenticación de forma improvisada. En última instancia, una autenticación fiable es la capa fundamental sobre la que dependen todos los servicios de red posteriores.
Definiciones clave
Arquitectura Activo-Activo
Un diseño de alta disponibilidad en el que varios servidores RADIUS procesan solicitudes de autenticación de forma simultánea, distribuyendo la carga y ofreciendo una conmutación por error instantánea sin retrasos de detección.
Esencial para espacios de alta densidad (estadios, grandes superficies comerciales) donde un único servidor no puede gestionar los picos de autenticación.
Arquitectura Activo-Pasivo
Un modelo de redundancia en el que un servidor principal gestiona todo el tráfico y un servidor secundario permanece inactivo en espera hasta que el principal falla.
Adecuada para despliegues más pequeños y sensibles a los costes, pero introduce un retraso de conmutación por error de 6 a 18 segundos mientras el dispositivo de acceso a la red detecta el fallo.
Replicación síncrona
Un método de replicación de bases de datos en el que los datos se escriben en todos los nodos de un clúster simultáneamente antes de que la transacción se considere completada.
Obligatoria para las bases de datos de contabilidad RADIUS Activo-Activo (como Galera Cluster) para evitar la pérdida de datos y garantizar el cumplimiento normativo.
Replicación asíncrona
Un método de replicación de bases de datos en el que el nodo principal registra los datos y posteriormente los copia en los nodos secundarios, lo que introduce un ligero retraso (latencia).
Se utiliza a menudo en configuraciones Activo-Pasivo, pero conlleva el riesgo de perder registros de contabilidad recientes si el nodo principal falla de forma repentina.
Dispositivo de acceso a la red (NAD)
El componente de hardware (como un punto de acceso WiFi, un conmutador o una pasarela VPN) que solicita la autenticación al servidor RADIUS en nombre del usuario.
Los temporizadores internos de reintento y de tiempo de espera del NAD dictan la rapidez con la que se produce una conmutación por error Activo-Pasivo.
Protocolo sin estado
Un protocolo de comunicación que trata cada solicitud como una transacción independiente, sin relación con ninguna solicitud anterior.
La autenticación RADIUS sobre UDP no tiene estado, lo que permite a los equilibradores de carga enrutar cualquier solicitud a cualquier servidor activo de forma fluida.
Desviación de la configuración
El fenómeno por el cual los servidores secundarios o de respaldo se desincronizan con el tiempo respecto al servidor principal en lo que respecta a políticas, actualizaciones o certificados.
La causa principal de fallos en los despliegues RADIUS Activo-Pasivo cuando el nodo secundario se ve obligado a asumir el control.
Cloud RADIUS
Un servicio de autenticación gestionado y alojado en una infraestructura en la nube distribuida globalmente, que proporciona redundancia Activo-Activo integrada y escalado automático.
Elimina la necesidad de que los equipos de TI tengan que compilar, parchear y supervisar manualmente servidores RADIUS locales redundantes.
Ejemplos prácticos
Un grupo hotelero europeo gestiona 45 propiedades en seis países. Actualmente ejecutan máquinas virtuales FreeRADIUS independientes en cada propiedad. Un certificado TLS caducado recientemente en una de las ubicaciones provocó una interrupción completa del WiFi para huéspedes durante una conferencia importante. ¿Cómo deberían rediseñar su arquitectura de autenticación para evitar interrupciones localizadas y reducir los costes de mantenimiento?
El grupo hotelero debería migrar de instancias FreeRADIUS localizadas de un solo nodo a una plataforma Cloud RADIUS centralizada que utilice una arquitectura Active-Active. Al aprovechar un proveedor de nube con nodos perimetrales distribuidos geográficamente, las solicitudes de autenticación de cada propiedad se enrutan al nodo regional más cercano, minimizando la latencia. La gestión centralizada de políticas permite al equipo de TI definir las reglas de autenticación una sola vez y aplicarlas globalmente. El proveedor de nube gestiona automáticamente la rotación de certificados TLS, el parcheo del sistema operativo y la replicación de la base de datos.
Un estadio deportivo nacional se está preparando para un evento de 60.000 asistentes. Su configuración actual de RADIUS es una configuración Active-Passive. Durante las pruebas de carga, el servidor primario se saturó procesando 8.000 solicitudes de autenticación por minuto cuando se abrieron las puertas, lo que provocó graves retrasos en la conexión, mientras que el servidor secundario permaneció completamente inactivo. ¿Cómo pueden optimizar este despliegue?
El equipo de ingeniería de red debe convertir el despliegue de Active-Passive a Active-Active. En primer lugar, deben reconfigurar los Dispositivos de Acceso a la Red (NAD) del estadio para utilizar un equilibrio de carga round-robin entre ambos servidores RADIUS, duplicando instantáneamente su rendimiento de autenticación. En segundo lugar, deben aprovisionar un tercer nodo RADIUS para proporcionar el margen necesario para los picos de demanda. Por último, para garantizar que los datos de contabilidad sigan siendo coherentes en los tres nodos activos, deben implementar una solución de replicación de base de datos multi-maestro síncrona, como Galera Cluster.
Preguntas de práctica
Q1. Su cliente de comercio minorista empresarial requiere una solución RADIUS de alta disponibilidad para sus terminales de punto de venta. Tienen requisitos estrictos de cumplimiento de PCI DSS que dictan que no se puede perder absolutamente ningún dato de sesión de contabilidad (accounting) durante una conmutación por error del servidor. ¿Qué estrategia de replicación de base de datos debe implementar para el backend de RADIUS?
Sugerencia: Considere la diferencia entre que los datos se escriban simultáneamente y que se copien a posteriori.
Ver respuesta modelo
Debe implementar una replicación síncrona (como un clúster Galera o un clúster MySQL NDB). La replicación síncrona garantiza que el registro de contabilidad se confirme en todos los nodos simultáneamente antes de reconocer la transacción. Si utilizara una replicación asíncrona, el fallo de un nodo podría provocar la pérdida de transacciones recientes que aún no se hubieran copiado en la base de datos secundaria, lo que violaría el estricto requisito de cumplimiento.
Q2. La red de un campus universitario utiliza una configuración RADIUS Activo-Pasivo. Los estudiantes se quejan de que cuando el servidor principal se somete a mantenimiento, sus portátiles tardan casi 20 segundos en conectarse al WiFi. Los puntos de acceso están configurados con un tiempo de espera de RADIUS de 3 segundos y 5 reintentos. ¿Cómo puede reducir el retraso de la conmutación por error sin cambiar la arquitectura del servidor?
Sugerencia: Calcule el tiempo de espera máximo en función de los temporizadores del NAD antes de que intente conectarse al servidor secundario.
Ver respuesta modelo
Debe ajustar los temporizadores en los dispositivos de acceso a la red (puntos de acceso). Actualmente, el punto de acceso espera 3 segundos y reintenta 5 veces, lo que resulta en un retraso de 18 segundos (3 segundos × 6 intentos totales) antes de pasar al servidor pasivo. Al reducir la configuración a un tiempo de espera de 2 segundos y 2 reintentos, el tiempo de detección de conmutación por error se reduce a 6 segundos, lo que mejora significativamente la experiencia del usuario durante las ventanas de mantenimiento.
Q3. Está migrando una red corporativa multisitio de un servidor RADIUS local Activo-Pasivo a una plataforma Cloud RADIUS Activo-Activo. Durante la fase piloto, los dispositivos se autentican correctamente en el Nodo Cloud A, pero cuando el equilibrador de carga los dirige al Nodo Cloud B, los apretones de manos (handshakes) EAP-TLS fallan. ¿Cuál es el error de configuración más probable?
Sugerencia: Considere qué verifica el dispositivo cliente al establecer un túnel EAP seguro con un nuevo servidor.
Ver respuesta modelo
El problema más probable es una discrepancia en la confianza del certificado. En un clúster Activo-Activo, todos los nodos RADIUS deben presentar exactamente el mismo certificado de servidor (o certificados emitidos exactamente por la misma cadena de CA de confianza). Si el Nodo Cloud B presenta un certificado diferente en el que los dispositivos cliente no confían, el cliente rechazará el apretón de manos EAP-TLS, lo que provocará que la autenticación falle a pesar de que el servidor funcione correctamente.
Continúe leyendo esta serie
Configuring RADIUS Authentication for Guest and Staff WiFi Networks
Esta guía de referencia técnica describe la arquitectura, configuración y despliegue de la autenticación RADIUS para redes WiFi empresariales de invitados y de personal. Proporciona a los arquitectos de redes y responsables de TI los protocolos exactos, los estándares de seguridad y las metodologías de resolución de problemas necesarios para crear sistemas de control de acceso inalámbrico seguros y escalables.
Passpoint y OpenRoaming: Guía completa
Esta guía de referencia técnica proporciona un análisis exhaustivo de los frameworks Passpoint (Hotspot 2.0) y WBA OpenRoaming dentro de las redes WiFi empresariales. Detalla los protocolos de autenticación subyacentes, los componentes arquitectónicos y las estrategias de despliegue necesarias para establecer una conectividad de invitados segura y sin fricciones. Los arquitectos de redes y los líderes de TI aprenderán a diseñar, implementar y solucionar problemas de estos estándares para eliminar las barreras de inicio de sesión manual mientras mantienen una seguridad de nivel empresarial.
Cómo implementar SCEP para un BYOD seguro y registro de red en educación superior
Esta guía técnica proporciona a arquitectos de red y directores de TI un plan de acción independiente del proveedor para desplegar el registro de certificados basado en SCEP para proteger las redes de campus de educación superior. Detalla cómo migrar de PEAP basado en contraseñas a 802.1X EAP-TLS, automatizar la incorporación de BYOD y aplicar una segmentación robusta de VLAN.