Automazione della revoca dei certificati con OCSP e CRL in un ambiente NAC
Questa guida tecnica di riferimento fornisce ai responsabili IT e agli architetti di rete un'analisi dettagliata dell'automazione della revoca dei certificati in un ambiente Network Access Control (NAC). Esplora i compromessi architetturali tra OCSP e CRL, offre linee guida di implementazione indipendenti dai fornitori e delinea l'impatto aziendale dell'applicazione delle policy in tempo reale.
Ascolta questa guida
Visualizza trascrizione del podcast
Executive Summary
Per i direttori IT aziendali e gli architetti di rete che gestiscono ambienti ad alta densità, come le strutture del settore Hospitality , i punti vendita Retail e le installazioni nel settore pubblico, la gestione del ciclo di vita dei certificati rappresenta una frontiera di sicurezza fondamentale. Sebbene lo standard IEEE 802.1X offra un'autenticazione robusta per i dispositivi aziendali e BYOD, il meccanismo con cui viene revocata la fiducia viene spesso trascurato fino a quando non si verifica una violazione.
L'automazione della revoca dei certificati con l'Online Certificate Status Protocol (OCSP) e le Certificate Revocation Lists (CRL) all'interno di un ambiente Network Access Control (NAC) colma il divario tra la dismissione degli endpoint e l'applicazione delle policy di rete. Questa guida esplora i meccanismi architetturali della revoca automatizzata, confrontando le funzionalità in tempo reale di OCSP con la resilienza offline delle CRL.
Integrando la piattaforma di Mobile Device Management (MDM), la Certificate Authority (CA) e il motore di policy NAC, le organizzazioni possono ottenere un accesso alla rete zero-trust in cui ai dispositivi compromessi o dismessi viene istantaneamente negato l'accesso. Questo riferimento tecnico fornisce linee guida pratiche per l'implementazione, strategie di mitigazione del rischio ed esplora come questa postura di sicurezza rivolta al personale interno completi le infrastrutture rivolte al pubblico come le piattaforme Guest WiFi e WiFi Analytics di Purple.
Approfondimento Tecnico
In qualsiasi rete aziendale che sfrutti lo standard IEEE 802.1X con EAP-TLS, i dispositivi si autenticano utilizzando certificati digitali anziché credenziali condivise. Questo approccio è fondamentale per le moderne architetture di sicurezza, fornendo un'identità associata al dispositivo che si integra perfettamente con le piattaforme MDM tramite protocolli come SCEP (per ulteriori approfondimenti, consultare The Role of SCEP and NAC in Modern MDM Infrastructure ). Tuttavia, i certificati hanno un ciclo di vita definito. Quando un dispositivo viene smarrito, un utente viene licenziato o una chiave privata viene compromessa, all'infrastruttura di rete deve essere esplicitamente ordinato di smettere di considerare attendibile quel certificato.
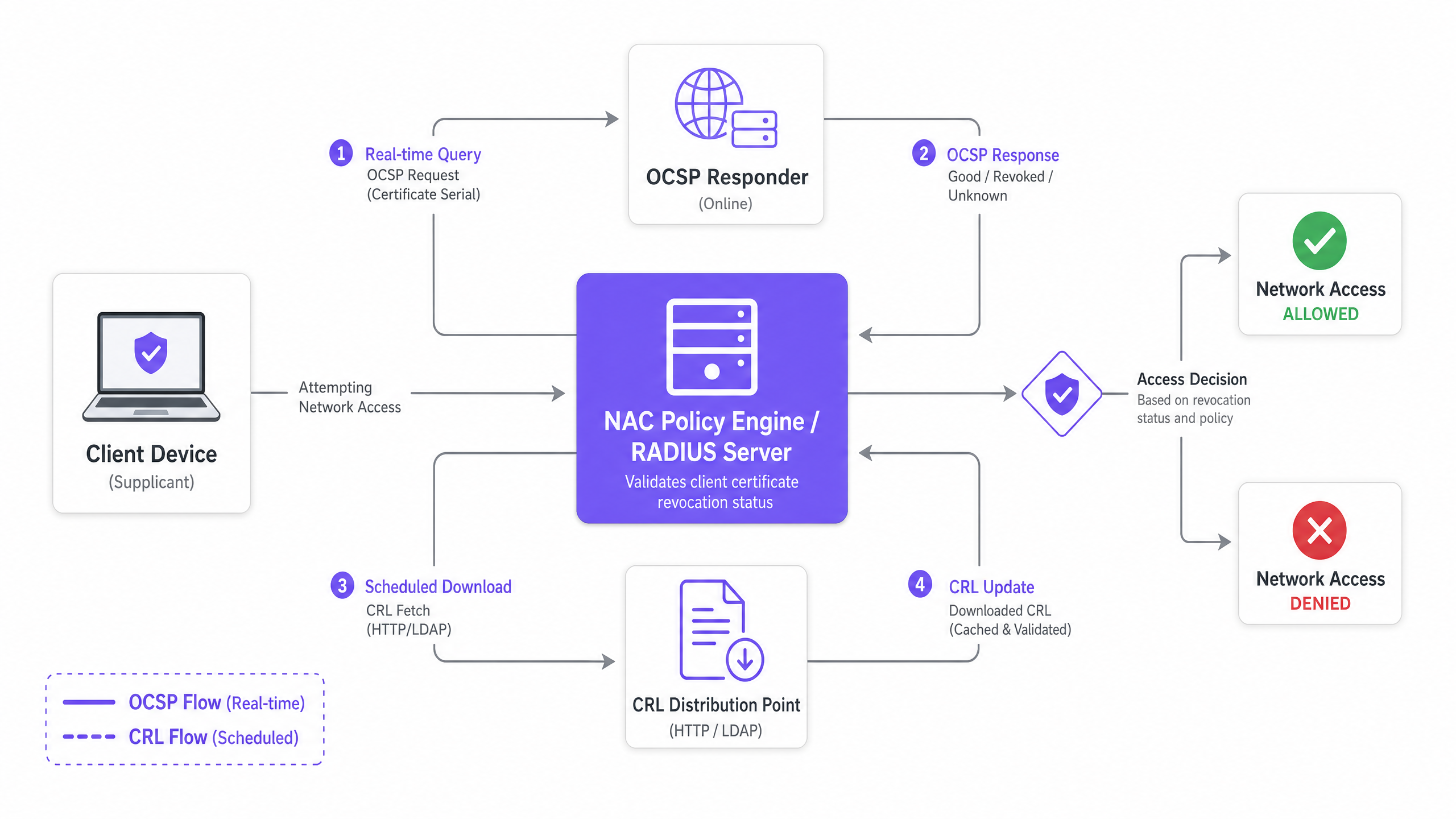
Questa istruzione di revoca viene recapitata tramite due meccanismi principali: CRL e OCSP.
Architettura delle Certificate Revocation List (CRL)
Una CRL è un file firmato digitalmente e pubblicato dalla Certificate Authority contenente i numeri di serie di tutti i certificati revocati che non sono ancora scaduti. Il motore di policy NAC (che funge da server RADIUS) scarica periodicamente questo elenco da un CRL Distribution Point (CDP) tramite HTTP o LDAP.
Durante l'handshake EAP-TLS, il server RADIUS confronta il numero di serie del certificato client in entrata con la sua CRL memorizzata nella cache locale. Se il numero di serie è presente, l'autenticazione viene rifiutata.
Caratteristiche Architetturali:
- Resilienza Offline: Poiché il server RADIUS memorizza nella cache la CRL, la verifica della revoca continua anche se la CA o il CDP diventano irraggiungibili.
- Latenza: Il principale svantaggio è la latenza tra la revoca e l'applicazione. Se un certificato viene revocato alle 09:00 e l'intervallo di aggiornamento della CRL è di 24 ore, il dispositivo compromesso mantiene l'accesso alla rete fino al download successivo.
- Sovraccarico di Throughput: In ambienti con decine di migliaia di certificati, i file CRL possono crescere fino a diversi megabyte, creando un sovraccarico di larghezza di banda durante i cicli di aggiornamento.
Architettura Online Certificate Status Protocol (OCSP)
L'OCSP risolve i limiti di latenza della CRL consentendo la verifica della revoca in tempo reale. Invece di scaricare un elenco completo, il server RADIUS invia una query mirata contenente il numero di serie del certificato a un OCSP Responder. Il responder restituisce uno stato firmato: Good, Revoked o Unknown.
Caratteristiche Architetturali:
- Applicazione in Tempo Reale: Le decisioni di revoca si propagano istantaneamente. Una volta che la CA aggiorna l'OCSP Responder, il successivo tentativo di autenticazione da parte del dispositivo compromesso fallirà.
- Dipendenza dalla Disponibilità: Il motore dei criteri NAC si affida alla disponibilità elevata dell'OCSP Responder. Se il responder è irraggiungibile, l'amministratore di rete deve definire una policy di failover: "fail open" (consente l'accesso, compromettendo la sicurezza) o "fail closed" (nega l'accesso, compromettendo la disponibilità).
- OCSP Stapling: Per mitigare i problemi di carico e privacy, l'OCSP Stapling consente al dispositivo client di recuperare la risposta OCSP firmata e di allegarla all'handshake TLS, sebbene il supporto del supplicant vari.
Integrazione con Piattaforme Guest e Analytics
Mentre OCSP e CRL gestiscono i rigorosi requisiti di sicurezza del personale e dei dispositivi aziendali, le reti aperte al pubblico richiedono architetture diverse. Per i luoghi pubblici, l'integrazione di un robusto NAC per il personale con una piattaforma pubblica dedicata come Purple garantisce una copertura completa. La piattaforma di Purple gestisce l'autenticazione tramite Captive Portal, l'accettazione dei termini di servizio e l'acquisizione dei dati per il segmento pubblico, mentre l'infrastruttura di rete sottostante (spesso gli stessi access point fisici e switch) applica 802.1X e OCSP per gli SSID aziendali. Comprendere l'ambiente radio è fondamentale per entrambi i segmenti; fare riferimento a Wi Fi Frequencies: A Guide to Wi-Fi Frequencies in 2026 per la pianificazione dello spettro.
Guida all'Implementazione
La distribuzione della revoca automatizzata dei certificati richiede il coordinamento tra i domini PKI, MDM e NAC. Seguire questi passaggi di implementazione indipendenti dal fornitore per stabilire una pipeline di revoca resiliente.
Passaggio 1: Definire il Trigger di Revoca
L'automazione inizia a livello di gestione degli endpoint. Configura la tua piattaforma MDM (ad es. Microsoft Intune, Jamf Pro) per attivare una chiamata API di revoca alla tua Autorità di Certificazione (CA) quando si verificano condizioni specifiche:
- Dispositivo rimosso dal MDM
- Dispositivo contrassegnato come non conforme
- Account utente disabilitato nel servizio di directory
Passaggio 2: Configurare l'infrastruttura di revoca
Per le distribuzioni CRL:
- Configura la CA per pubblicare la CRL su un CDP ad alta disponibilità (ad es. un server web interno con bilanciamento del carico).
- Imposta l'intervallo di pubblicazione della CRL in base alla tua tolleranza al rischio (ad es. ogni 4 ore).
- Configura il server RADIUS per recuperare la CRL a un intervallo leggermente inferiore rispetto a quello di pubblicazione per garantire che la cache sia sempre aggiornata.
Per le distribuzioni OCSP:
- Distribuisci almeno due OCSP Responder dietro un bilanciatore di carico per garantire l'alta disponibilità.
- Configura la CA per inviare immediatamente gli aggiornamenti di revoca agli OCSP Responder.
- Configura il server RADIUS per interrogare l'IP virtuale OCSP bilanciato durante l'autenticazione EAP-TLS.
Passaggio 3: Stabilire la policy di fallback
Non affidarti a un singolo meccanismo. Configura il tuo server RADIUS per utilizzare OCSP come controllo di revoca primario, con un fallback a una CRL memorizzata nella cache locale se l'OCSP Responder non è raggiungibile. Ciò fornisce un'applicazione in tempo reale in condizioni normali e resilienza offline durante le interruzioni dell'infrastruttura.
Passaggio 4: Definire il comportamento in caso di errore
Se sia l'OCSP che la CRL memorizzata nella cache non sono disponibili, il server RADIUS deve decidere come gestire la richiesta di autenticazione.
- Ambienti ad alta sicurezza (ad es. Sanità ): Configura "fail closed". Nega l'accesso per impedire la connessione di dispositivi potenzialmente compromessi.
- Ambienti standard (ad es. hub di Trasporto ): Configura "fail open" con avvisi. Consenti l'accesso per mantenere la continuità operativa, ma genera un avviso ad alta priorità per il SOC.

Best Practice
- Implementare le Delta CRL: Se ti affidi alle CRL in un ambiente di grandi dimensioni, implementa le Delta CRL. Questi file contengono solo le modifiche di revoca avvenute dall'ultima pubblicazione della Base CRL completa, riducendo significativamente le dimensioni del download e il consumo di banda.
- Monitorare la latenza OCSP: Le query OCSP avvengono in linea durante l'handshake EAP-TLS. Se l'OCSP Responder impiega 500 ms per rispondere, l'autenticazione subisce un ritardo di 500 ms. Monitora la latenza del responder e scala orizzontalmente se i tempi di risposta peggiorano.
- Certificati a breve durata: Valuta la possibilità di ridurre i periodi di validità dei certificati (ad es. da 1 anno a 7 giorni) tramite il rinnovo automatico SCEP/EST. I certificati a breve durata scadono naturalmente in fretta, riducendo la dipendenza da una solida infrastruttura di revoca.
- Allineamento con la strategia di rete globale: Assicurati che l'implementazione del NAC sia allineata con l'architettura della tua rete geografica. Per approfondimenti sulla progettazione delle moderne WAN, consulta SD WAN vs MPLS: La guida 2026 per le reti aziendali .
Risoluzione dei problemi e mitigazione dei rischi
La modalità di guasto più comune nella revoca automatizzata è l'interruzione del flusso tra CA e NAC, che si traduce in un evento "fail closed" che blocca gli utenti legittimi.
Rischio: Interruzione del risponditore OCSP Mitigazione: Distribuisci i risponditori in un cluster active-active su più domini di errore. Implementa controlli di integrità completi sul bilanciatore di carico per verificare la capacità del risponditore di interrogare il database della CA, e non solo la disponibilità della porta TCP 80.
Rischio: Cache CRL obsoleta Mitigazione: I server RADIUS potrebbero non riuscire a scaricare l'ultima CRL a causa di partizioni di rete o interruzioni del CDP. Implementa un monitoraggio che invii un avviso se la CRL memorizzata nella cache locale è più vecchia dell'intervallo di pubblicazione definito.
Rischio: Revoca MDM incompleta Mitigazione: Se l'MDM non riesce ad avviare la chiamata di revoca alla CA, il certificato rimane valido. Implementa uno script di riconciliazione che confronti periodicamente l'elenco dei dispositivi attivi dell'MDM con l'elenco dei certificati validi della CA, revocando automaticamente eventuali discrepanze.
ROI e impatto aziendale
L'automazione della revoca dei certificati trasforma la sicurezza da un processo reattivo e manuale a un meccanismo di difesa proattivo e automatizzato.
- Riduzione del rischio: Eliminando la finestra di esposizione tra la compromissione del dispositivo e l'isolamento dalla rete, le organizzazioni riducono significativamente il rischio di movimenti laterali ed esfiltrazione di dati. Questo è fondamentale per mantenere la conformità con framework come PCI DSS e GDPR.
- Efficienza operativa: L'automazione del flusso di revoca elimina la necessità per il personale dell'helpdesk di aggiornare manualmente le configurazioni RADIUS o i database delle CA quando un dipendente lascia l'azienda, risparmiando centinaia di ore all'anno nelle grandi imprese.
- Strategia di accesso unificata: Un ambiente NAC robusto per i dispositivi aziendali consente ai team IT di implementare con sicurezza servizi paralleli, come il WiFi per gli ospiti basato su analisi di Purple o i servizi basati sulla posizione (vedi BLE Low Energy spiegato per le aziende ), sapendo che l'infrastruttura principale è sicura.
Ascolta il nostro briefing tecnico su questo argomento qui sotto:
Definizioni chiave
EAP-TLS (Extensible Authentication Protocol - Transport Layer Security)
Lo standard più sicuro per l'autenticazione di rete 802.1X, che richiede sia al client che al server di presentare certificati digitali per dimostrare la propria identità.
I team IT implementano EAP-TLS per eliminare i rischi associati all'autenticazione basata su password, garantendo che solo i dispositivi gestiti e dotati di certificato possano connettersi alla rete aziendale.
OCSP (Online Certificate Status Protocol)
Un protocollo internet utilizzato per ottenere in tempo reale lo stato di revoca di un certificato digitale X.509.
Cruciale per gli ambienti che richiedono l'applicazione immediata delle policy di accesso, ad esempio quando un dipendente viene licenziato e il suo dispositivo deve essere disconnesso istantaneamente.
CRL (Certificate Revocation List)
Un elenco firmato digitalmente e pubblicato periodicamente contenente i numeri di serie dei certificati che sono stati revocati dall'Autorità di Certificazione emittente.
Utilizzato come meccanismo di revoca primario in reti offline o isolate (air-gapped), o come meccanismo di fallback altamente resiliente per OCSP.
OCSP Stapling
Un meccanismo in cui il dispositivo client recupera la propria risposta OCSP e la "unisce" (staples) all'handshake TLS, presentandola al server RADIUS.
Riduce il carico sul server RADIUS e sull'OCSP Responder, e migliora la privacy impedendo alla CA di vedere esattamente quando e dove un dispositivo si sta autenticando.
Delta CRL
Un elenco di revoca più piccolo contenente solo i certificati revocati dall'ultima pubblicazione della CRL Base completa.
Essenziale per le grandi distribuzioni al fine di prevenire la congestione della rete, poiché le CRL complete possono diventare enormi e consumare una larghezza di banda significativa durante i cicli di aggiornamento.
CDP (CRL Distribution Point)
La posizione, in genere un URL HTTP o LDAP, in cui l'Autorità di Certificazione pubblica la CRL affinché i client e i server RADIUS possano scaricarla.
I team IT devono garantire che il CDP sia altamente disponibile e raggiungibile da tutti i motori di policy NAC; se il CDP si interrompe, i server RADIUS non possono aggiornare le proprie cache.
Fail Open / Fail Closed
La decisione di policy che stabilisce cosa accade quando l'infrastruttura di revoca (OCSP o CDP) non è raggiungibile. Fail Open consente l'accesso; Fail Closed nega l'accesso.
Una decisione aziendale critica che bilancia il livello di sicurezza con il tempo di attività operativa. Richiede l'approvazione sia delle operazioni IT che del CISO.
SCEP (Simple Certificate Enrollment Protocol)
Un protocollo utilizzato dalle piattaforme MDM per automatizzare l'emissione di certificati digitali ai dispositivi gestiti senza l'intervento dell'utente.
Il punto di partenza del ciclo di vita automatizzato. SCEP emette il certificato e l'MDM successivamente attiva la CA per revocarlo quando il dispositivo viene dismesso.
Esempi pratici
Una rete ospedaliera da 500 posti letto sta migrando da un sistema 802.1X basato su credenziali a un sistema EAP-TLS basato su certificati per tutti i dispositivi IoT medici e i laptop del personale. Il CISO impone che, in caso di furto di un dispositivo, il suo accesso alla rete debba essere interrotto entro 5 minuti. Il team di rete è preoccupato per il carico del server RADIUS qualora debba interrogare costantemente servizi esterni. Come dovrebbe essere progettata l'architettura di revoca?
L'ospedale deve implementare OCSP per soddisfare l'SLA di revoca di 5 minuti, poiché gli intervalli di aggiornamento delle CRL non possono soddisfare in modo affidabile questo obiettivo senza causare un grave sovraccarico di rete. Per rispondere alle preoccupazioni del team di rete relative al carico, l'architettura dovrebbe implementare gli OCSP Responder localmente all'interno del data center dell'ospedale, posizionati vicino ai server RADIUS per ridurre al minimo la latenza. I server RADIUS devono essere configurati per interrogare il VIP OCSP locale. Per garantire la resilienza, i server RADIUS devono essere configurati con un fallback su una CRL memorizzata nella cache locale, aggiornata ogni ora. La policy di errore deve essere impostata su "fail closed" a causa dei severi requisiti di conformità dell'ambiente sanitario.
Una catena di vendita al dettaglio globale con 1.200 negozi utilizza SCEP per fornire certificati ai tablet dei punti vendita (POS). I negozi hanno una larghezza di banda WAN limitata. Il direttore IT desidera implementare la revoca dei certificati, ma teme che il download di file CRL di grandi dimensioni su 1.200 server RADIUS di filiale saturi i collegamenti WAN. Qual è la strategia di implementazione ottimale?
La catena di vendita al dettaglio dovrebbe implementare un approccio ibrido utilizzando Delta CRL e OCSP Stapling. In primo luogo, la CA dovrebbe essere configurata per pubblicare una CRL di base settimanalmente e una Delta CRL (contenente solo le revoche recenti) ogni 4 ore. I server RADIUS delle filiali scaricheranno solo le piccole Delta CRL durante il giorno, riducendo al minimo l'impatto sulla WAN. In alternativa, se i supplicant EAP dei tablet POS lo supportano, dovrebbe essere abilitato l'OCSP Stapling. Questo sposta l'onere di recuperare la risposta OCSP dal server RADIUS della filiale al tablet stesso, che può recuperare la risposta direttamente dalla CA centrale tramite HTTPS standard, bypassando completamente il sovraccarico di elaborazione del server RADIUS.
Domande di esercitazione
Q1. La tua organizzazione sta distribuendo 802.1X in 50 filiali remote. I collegamenti WAN verso il data center centrale sono altamente congestionati e perdono frequentemente pacchetti. È necessario implementare la revoca dei certificati per i laptop aziendali delle filiali. Quale architettura dovresti scegliere?
Suggerimento: Considera l'impatto della perdita di pacchetti sui protocolli in tempo reale rispetto alla resilienza dei dati memorizzati nella cache.
Visualizza risposta modello
Dovresti implementare un'architettura basata su CRL, in particolare utilizzando CRL Base e Delta. Poiché i collegamenti WAN sono congestionati e inaffidabili, le query OCSP in tempo reale andranno frequentemente in timeout, causando ritardi o fallimenti dell'autenticazione. Configurando i server RADIUS delle filiali per scaricare e memorizzare nella cache le CRL Delta durante le ore non di punta, il server RADIUS locale può eseguire istantaneamente i controlli di revoca sulla propria cache, anche se il collegamento WAN si interrompe completamente durante il tentativo di autenticazione.
Q2. Un audit di sicurezza rivela che quando il risponditore OCSP primario va offline per manutenzione, tutti gli utenti aziendali vengono completamente bloccati fuori dalla rete WiFi. L'azienda richiede che la manutenzione non influisca sulla connettività degli utenti, ma il CISO rifiuta di modificare la policy in 'Fail Open'. Come risolvi questo problema?
Suggerimento: Se non puoi modificare la policy di errore, devi modificare la disponibilità del servizio.
Visualizza risposta modello
È necessario implementare l'alta affidabilità per il servizio OCSP. Distribuisci almeno un risponditore OCSP aggiuntivo e posizionali entrambi dietro un bilanciatore di carico. Configura il server RADIUS per interrogare l'IP virtuale (VIP) del bilanciatore di carico. Durante la manutenzione, puoi svuotare le connessioni dal risponditore primario, metterlo offline e il bilanciatore di carico reindirizzerà senza problemi tutte le query OCSP al risponditore secondario, soddisfacendo sia i requisiti di uptime dell'azienda sia il mandato 'Fail Closed' del CISO.
Q3. Hai configurato il tuo MDM per revocare automaticamente i certificati quando un dispositivo viene contrassegnato come 'smarrito'. Testi il sistema contrassegnando un iPad di prova come smarrito. L'MDM conferma la revoca, ma 10 minuti dopo l'iPad si connette correttamente al WiFi aziendale. Il server RADIUS è configurato per utilizzare una CRL pubblicata ogni 24 ore. Qual è la causa principale e come si risolve?
Suggerimento: Traccia la cronologia dei dati di revoca dalla CA al motore di applicazione del server RADIUS.
Visualizza risposta modello
La causa principale è la latenza nel ciclo di pubblicazione e aggiornamento della CRL. Sebbene l'MDM abbia comunicato con successo alla CA di revocare il certificato, la CA non pubblicherà lo stato aggiornato sul punto di distribuzione della CRL fino al ciclo successivo di 24 ore, e il server RADIUS non lo scaricherà fino alla scadenza della propria cache. Per risolvere questo problema, devi migrare a OCSP per il controllo in tempo reale o ridurre drasticamente gli intervalli di pubblicazione e download della CRL (ad esempio, a 1 ora) per soddisfare i tempi di applicazione richiesti.
Continua a leggere questa serie
Hotel Guest WiFi Management: Integrating PMS, Portals, and Brand Standards
Questa guida tecnica descrive in dettaglio come progettare reti WiFi per hotel di livello enterprise, concentrandosi sulla segmentazione VLAN, sull'integrazione PMS per la gestione automatizzata delle sessioni e sull'ottimizzazione del Captive Portal per l'acquisizione di dati conforme al GDPR.
Come configurare il Guest WiFi: una guida alla configurazione aziendale sicura
Questa guida autorevole fornisce ai leader IT e agli architetti di rete un modello definitivo per implementare un Guest WiFi aziendale sicuro. Copre l'architettura essenziale, la migrazione a WPA3, la segmentazione VLAN e l'integrazione del Captive Portal per proteggere i sistemi interni acquisendo al contempo dati di prima parte conformi.
Gestione della larghezza di banda per il WiFi del personale: Shaping, QoS e riduzione del traffico
Questa guida illustra metodi pratici per gestire la larghezza di banda per il WiFi del personale nelle sedi aziendali. Copre il traffic shaping, l'implementazione del QoS e come l'implementazione di Purple Shield riduca il carico di rete senza richiedere aggiornamenti dell'infrastruttura.