RADIUS Server High Availability: Active-Active vs Active-Passive
Una guida di riferimento tecnica definitiva per IT manager e network architect che valutano le architetture RADIUS ad alta disponibilità. Mette a confronto le distribuzioni Active-Active e Active-Passive, descrive in dettaglio i requisiti di replica del database e spiega come Cloud RADIUS riduca la latenza di failover per le sedi aziendali.
Ascolta questa guida
Visualizza trascrizione del podcast
📚 Parte della nostra serie principale: Enterprise WiFi Security Guide →

Executive Summary
Per le reti aziendali, l'autenticazione è binaria: o funziona perfettamente, o le attività aziendali si interrompono completamente. RADIUS (Remote Authentication Dial-In User Service) funge da gatekeeper critico per le implementazioni IEEE 802.1X, WPA3 enterprise e Guest WiFi in tutte le location moderne. A differenza dei servizi applicativi che degradano gradualmente sotto carico, un guasto di RADIUS blocca immediatamente l'accesso alla rete a utenti, terminali POS e dispositivi operativi.
Questa guida tecnica di riferimento valuta i modelli architetturali per l'implementazione di un'infrastruttura RADIUS ad alta disponibilità. In particolare, mette a confronto le tradizionali configurazioni Attivo-Passivo con i moderni cluster Attivo-Attivo. Per i responsabili IT, gli architetti di rete e i direttori operativi delle strutture che gestiscono ambienti ad alta densità come Retail , Hospitality e stadi, la comprensione di queste strategie di failover, delle dinamiche di bilanciamento del carico e dei requisiti di replica del database è fondamentale.
Inoltre, questa guida esamina come le piattaforme Cloud RADIUS astraggano la complessità dell'alta disponibilità, offrendo failover automatico e scalabilità elastica senza l'onere operativo di mantenere un'infrastruttura on-premise ridondante. Applicando queste best practice indipendenti dai fornitori, i team di ingegneria possono progettare architetture di autenticazione che eliminano i singoli punti di guasto e soddisfano rigorosi accordi sul livello del servizio (SLA) per il tempo di attività.
Technical Deep-Dive: Understanding RADIUS Architecture
RADIUS opera come protocollo client-server su UDP, utilizzando tipicamente la porta 1812 per l'autenticazione e la porta 1813 per l'accounting, come definito nelle specifiche RFC 2865 e RFC 2866. La natura stateless delle richieste di autenticazione UDP rappresenta un vantaggio strutturale per la progettazione dell'alta disponibilità. Poiché ogni pacchetto Access-Request contiene tutte le credenziali e i parametri necessari, qualsiasi server RADIUS all'interno di un cluster può elaborare autonomamente qualsiasi richiesta, senza richiedere una complessa sincronizzazione dello stato per la fase di autenticazione stessa.
Active-Passive Architecture
In un'implementazione Attivo-Passivo (o primary-standby), un singolo server RADIUS elabora tutto il traffico di autenticazione e accounting in entrata. Un server secondario rimane online ma inattivo, ricevendo gli aggiornamenti di replica del database ma senza rispondere attivamente ai Network Access Devices (NAD) come access point, switch o gateway VPN.
Quando il server primario si guasta, il NAD rileva il timeout e reindirizza le richieste successive al server secondario. Il tempo di rilevamento del failover dipende interamente dai timer di configurazione del NAD. Un NAD tipico invia una richiesta RADIUS e attende un timeout predefinito del pacchetto (spesso due secondi). Se non riceve risposta, riprova. Con una configurazione standard di tre tentativi per server, il NAD può attendere fino a sei secondi prima di dichiarare inattivo il server primario ed eseguire il failover sul secondario. In ambienti con tre server configurati, questa finestra di failover può estendersi fino a diciotto secondi. Per una struttura Hospitality trafficata o un ambiente Retail che elabora transazioni, questo ritardo rappresenta un'interruzione evidente del servizio.
Active-Active Architecture
Al contrario, un'architettura Attivo-Attivo distribuisce il carico di autenticazione su più server RADIUS operativi simultaneamente. Il traffico viene instradato al cluster tramite configurazione round-robin sui NAD o attraverso un bilanciatore di carico dedicato.
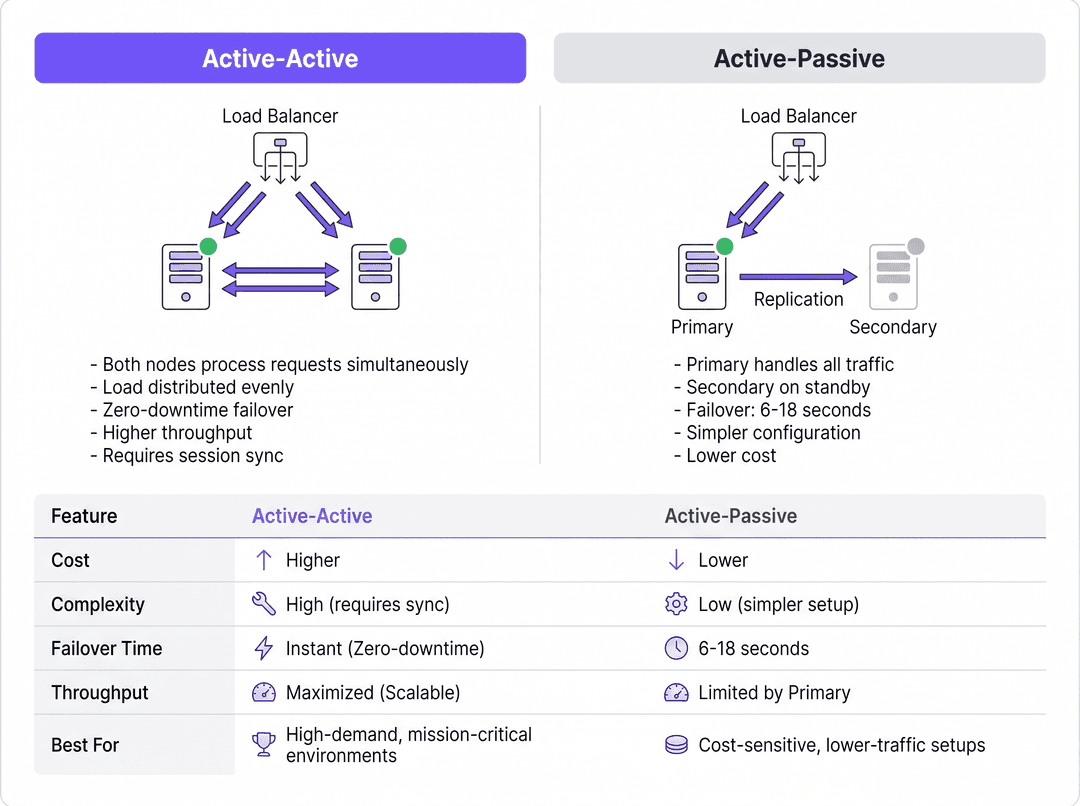
Questo modello elimina il ritardo nel rilevamento del failover intrinseco alle configurazioni Attivo-Passivo. Se un nodo si guasta, il bilanciatore di carico (o i NAD che utilizzano il round-robin) smette semplicemente di instradare il traffico verso il server che non risponde, in genere entro uno o due secondi in base agli intervalli di controllo dello stato (health-check). I restanti nodi attivi assorbono istantaneamente il traffico. Inoltre, i cluster Attivo-Attivo scalano orizzontalmente; per aggiungere capacità in occasione di eventi ad alta densità è sufficiente fornire nodi aggiuntivi al cluster.
The Database Replication Challenge
Mentre l'autenticazione RADIUS è stateless, l'accounting RADIUS è intrinsecamente stateful. Tiene traccia dell'avvio della sessione (Start), dell'utilizzo continuo (Interim-Update) e della chiusura (Stop). Per le strutture che utilizzano WiFi Analytics o sistemi di fatturazione, questi dati di accounting devono rimanere coerenti su tutti i nodi.
L'integrazione di un cluster RADIUS con un database replicato (come MySQL o MariaDB integrato con FreeRADIUS) è obbligatoria per garantire un'alta disponibilità robusta. Per le implementazioni Attivo-Attivo, è richiesta una replica sincrona multi-master, come Galera Cluster o MySQL NDB Cluster. La replica sincrona garantisce che un record di accounting venga registrato su tutti i nodi contemporaneamente, prevenendo la perdita di dati in caso di guasto di un nodo. La tradizionale replica asincrona, spesso utilizzata nelle configurazioni Attivo-Passivo, introduce un ritardo di replica. Se il nodo primario si guasta prima che il secondario riceva l'aggiornamento, i dati della sessione attiva vanno persi in modo permanente, il che può violare i framework di conformità come PCI DSS.
Implementation Guide: Cloud vs On-Premise
La decisione architetturale va oltre le modalità di clustering dei server; riguarda il luogo in cui tali server risiedono. Per gli operatori multi-sito, il backhauling del traffico di autenticazione verso un data center on-premise centralizzato introduce latenza WAN e crea un singolo punto di guasto sul collegamento WAN.
Cloud RADIUS Platforms
I servizi Cloud RADIUS risolvono le sfide di distribuzione geografica ospitando l'infrastruttura di autenticazione in più zone di disponibilità globali. Quando un utente si connette presso una filiale, la richiesta viene instradata al nodo edge cloud più vicino, riducendo al minimo la latenza.
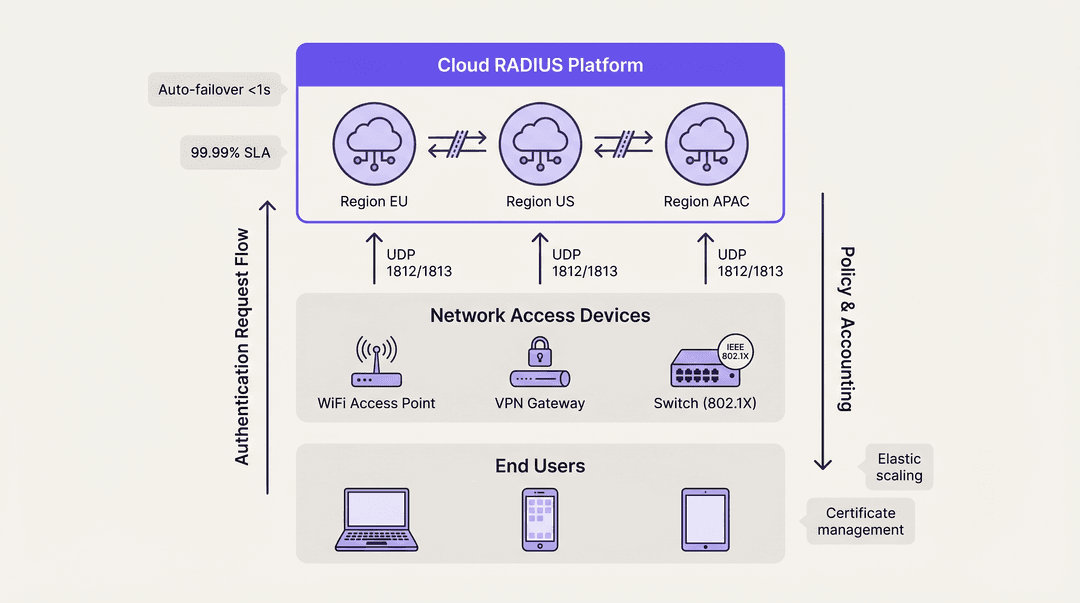
Le piattaforme cloud utilizzano intrinsecamente architetture Active-Active. Il failover tra le zone di disponibilità viene gestito automaticamente dal bilanciamento del carico interno del provider, eliminando completamente la complessità per il team di ingegneria del cliente. Questo modello offre in genere SLA di uptime del 99,99% ed elimina la necessità di gestione manuale dei certificati, patch del sistema operativo e ottimizzazione della replica del database. Per le organizzazioni che distribuiscono Wayfinding o Sensors in campus distribuiti, l'autenticazione ospitata nel cloud garantisce un'applicazione coerente delle policy senza dipendenze dall'hardware locale.
Considerazioni sulla Distribuzione On-Premise
Le organizzazioni che operano in settori altamente regolamentati, come specifici ambienti Healthcare o governativi, potrebbero richiedere distribuzioni on-premise a causa di rigidi mandati di sovranità dei dati. In questi scenari, la distribuzione di un cluster FreeRADIUS Active-Active con replica sincrona Galera fornisce il massimo livello di resilienza.
Tuttavia, i team di ingegneria devono tenere conto del sovraccarico operativo. La gestione dei certificati TLS su più nodi, la garanzia della coerenza della configurazione e il monitoraggio attivo dello stato della replica del database richiedono risorse amministrative dedicate. I bilanciatori di carico hardware devono essere configurati specificamente per supportare il traffico UDP con controlli di integrità RADIUS appropriati, poiché molti bilanciatori di carico standard sono ottimizzati esclusivamente per il traffico TCP HTTP/HTTPS.
Best Practice per l'Alta Affidabilità RADIUS
- Distribuire Piuttosto che Duplicare: Per distribuzioni che superano i 500 utenti simultanei, dare priorità alle architetture Active-Active rispetto alle configurazioni Active-Passive per massimizzare il throughput e ridurre al minimo la latenza di failover.
- Implementare la Replica Sincrona: Proteggere i dati di accounting stateful utilizzando la replica sincrona del database multi-master (ad es. Galera Cluster) anziché i modelli asincroni primario-replica.
- Standardizzare la Fiducia dei Certificati: In un cluster Active-Active, assicurarsi che tutti i nodi presentino lo stesso identico certificato server o certificati provenienti dalla stessa identica catena di Certification Authority (CA). Eventuali discrepanze causeranno il fallimento degli handshake EAP-TLS e PEAP durante la rotazione dei nodi.
- Sintonizzare i Timer NAD: Ottimizzare i timer di retry e timeout RADIUS sui Network Access Devices. Un timeout di due secondi con due tentativi offre un equilibrio tra il rilevamento rapido del failover e la prevenzione di failover prematuri durante lievi congestioni di rete.
- Testare gli Scenari di Guasto: Trattare i nodi secondari come sistemi di produzione. Simulare regolarmente guasti ai nodi, desincronizzazione del database e interruzioni del collegamento WAN per verificare che i meccanismi di failover automatizzati funzionino come previsto.
Risoluzione dei Problemi e Mitigazione dei Rischi
La modalità di guasto più comune nell'alta affidabilità RADIUS è la deriva della configurazione. Nelle configurazioni Active-Passive, gli amministratori aggiornano frequentemente le policy o rinnovano i certificati sul nodo primario ma trascurano il secondario. Quando si verifica un evento di failover, il nodo secondario rifiuta il traffico legittimo a causa di credenziali scadute o policy non aggiornate.
Per mitigare questo rischio, implementare strumenti di gestione della configurazione (come Ansible o Terraform) per distribuire le modifiche in modo simmetrico su tutti i nodi. Per la gestione dei certificati, utilizzare protocolli di rinnovo automatizzati (come ACME) configurati per distribuire contemporaneamente il certificato aggiornato a tutto il cluster.
Un altro rischio significativo è la configurazione errata del bilanciatore di carico. Se un bilanciatore di carico non esegue controlli di integrità a livello applicativo (verificando specificamente la reattività della porta UDP 1812), potrebbe continuare a instradare il traffico verso un nodo in cui il sistema operativo è in esecuzione ma il daemon RADIUS si è arrestato in modo anomalo. Assicurarsi che i controlli di integrità verifichino esplicitamente la disponibilità del servizio RADIUS.
ROI e Impatto sul Business
Il ritorno sull'investimento per una solida alta affidabilità RADIUS si misura principalmente attraverso la mitigazione del rischio e l'efficienza operativa. Le interruzioni dell'autenticazione si traducono in perdite immediate di produttività per i dipendenti e in gravi danni d'immagine per i luoghi aperti al pubblico.
Passando da distribuzioni manuali su server singolo ad architetture Active-Active automatizzate (in particolare tramite Cloud RADIUS), le organizzazioni recuperano ore preziose di ingegneria precedentemente dedicate alla manutenzione ordinaria. Questa efficienza operativa consente ai team di rete di concentrarsi su iniziative strategiche, come la distribuzione di The Core SD WAN Benefits for Modern Businesses o l'ottimizzazione della copertura ad alta densità, piuttosto che sulla risoluzione d'emergenza dei problemi di autenticazione. In definitiva, un'autenticazione affidabile è il livello fondamentale su cui dipendono tutti i servizi di rete successivi.
Definizioni chiave
Active-Active Architecture
Un design ad alta disponibilità in cui più server RADIUS elaborano simultaneamente le richieste di autenticazione, distribuendo il carico e fornendo un failover istantaneo senza ritardi di rilevamento.
Essenziale per sedi ad alta densità (stadi, grandi spazi commerciali) dove un singolo server non è in grado di gestire i picchi di autenticazione.
Active-Passive Architecture
Un modello di ridondanza in cui un server primario gestisce tutto il traffico e un server secondario rimane inattivo in standby fino a quando il primario non si guasta.
Adatto per distribuzioni più piccole e attente ai costi, ma introduce un ritardo di failover di 6-18 secondi mentre il network access device rileva il guasto.
Synchronous Replication
Un metodo di replica del database in cui i dati vengono scritti simultaneamente su tutti i nodi di un cluster prima che la transazione sia considerata completata.
Obbligatorio per i database di accounting RADIUS Active-Active (come Galera Cluster) per prevenire la perdita di dati e garantire la conformità.
Asynchronous Replication
Un metodo di replica del database in cui il nodo primario registra i dati e successivamente li copia sui nodi secondari, introducendo un leggero ritardo (lag).
Spesso utilizzato nelle configurazioni Active-Passive, ma comporta il rischio di perdere i record di accounting recenti se il nodo primario si guasta improvvisamente.
Network Access Device (NAD)
Il componente hardware (come un punto di accesso WiFi, uno switch o un gateway VPN) che richiede l'autenticazione al server RADIUS per conto dell'utente.
I timer interni di retry e timeout del NAD determinano la rapidità con cui si verifica un failover Active-Passive.
Stateless Protocol
Un protocollo di comunicazione che tratta ogni richiesta come una transazione indipendente, non correlata a nessuna richiesta precedente.
L'autenticazione RADIUS su UDP è stateless, consentendo ai bilanciatori di carico di instradare qualsiasi richiesta a qualsiasi server attivo in modo trasparente.
Configuration Drift
Il fenomeno per cui i server secondari o di backup non sono più sincronizzati con il server primario per quanto riguarda policy, aggiornamenti o certificati nel corso del tempo.
La causa principale di errore nelle distribuzioni RADIUS Active-Passive quando il nodo secondario è costretto a subentrare.
Cloud RADIUS
Un servizio di autenticazione gestito ospitato su un'infrastruttura cloud distribuita a livello globale, che fornisce ridondanza Active-Active integrata e scalabilità automatica.
Sostituisce la necessità per i team IT di creare, aggiornare e monitorare manualmente server RADIUS on-premise ridondanti.
Esempi pratici
Un gruppo alberghiero europeo gestisce 45 strutture in sei paesi. Attualmente esegue macchine virtuali FreeRADIUS indipendenti in ogni struttura. Un recente certificato TLS scaduto in una sede ha causato un'interruzione completa del WiFi per gli ospiti durante un'importante conferenza. Come dovrebbero riprogettare la loro architettura di autenticazione per prevenire interruzioni localizzate e ridurre i costi di manutenzione?
Il gruppo alberghiero dovrebbe migrare da istanze FreeRADIUS localizzate a nodo singolo a una piattaforma Cloud RADIUS centralizzata che utilizza un'architettura Active-Active. Sfruttando un cloud provider con nodi edge distribuiti geograficamente, le richieste di autenticazione da ciascuna struttura vengono instradate al nodo regionale più vicino, riducendo al minimo la latenza. La gestione centralizzata delle policy consente al team IT di definire le regole di autenticazione una sola volta e di applicarle a livello globale. Il cloud provider gestisce automaticamente la rotazione dei certificati TLS, l'applicazione delle patch del sistema operativo e la replica del database.
Uno stadio sportivo nazionale si sta preparando per un evento da 60.000 partecipanti. La loro attuale configurazione RADIUS è di tipo Active-Passive. Durante i test di carico, il server primario si è saturato elaborando 8.000 richieste di autenticazione al minuto all'apertura dei cancelli, causando gravi ritardi di connessione, mentre il server secondario è rimasto completamente inattivo. Come possono ottimizzare questa distribuzione?
Il team di ingegneria di rete deve convertire la distribuzione da Active-Passive ad Active-Active. In primo luogo, dovrebbero riconfigurare i Network Access Devices (NAD) dello stadio per utilizzare il bilanciamento del carico round-robin su entrambi i server RADIUS, raddoppiando istantaneamente la capacità di elaborazione delle autenticazioni. In secondo luogo, dovrebbero predisporre un terzo nodo RADIUS per fornire il margine necessario per i picchi di traffico. Infine, per garantire che i dati di accounting rimangano coerenti su tutti e tre i nodi attivi, devono implementare una soluzione di replica sincrona del database multi-master, come Galera Cluster.
Domande di esercitazione
Q1. Il tuo cliente retail aziendale richiede una soluzione RADIUS ad alta disponibilità per i suoi terminali point-of-sale. Ha severi requisiti di conformità PCI DSS che impongono che nessun dato di sessione di accounting vada perso durante un failover del server. Quale strategia di replica del database devi implementare per il backend RADIUS?
Suggerimento: Considera la differenza tra la scrittura simultanea dei dati e la copia dei dati a posteriori.
Visualizza risposta modello
È necessario implementare la replica sincrona (come un Galera Cluster o un MySQL NDB Cluster). La replica sincrona garantisce che il record di accounting venga registrato su tutti i nodi contemporaneamente prima di confermare la transazione. Se si utilizzasse la replica asincrona, un guasto al nodo potrebbe causare la perdita delle transazioni recenti che non erano ancora state copiate nel database secondario, violando il severo requisito di conformità.
Q2. La rete di un campus universitario utilizza una configurazione RADIUS Active-Passive. Gli studenti si lamentano del fatto che, quando il server primario è in manutenzione, i loro laptop impiegano quasi 20 secondi per connettersi al WiFi. Gli access point sono configurati con un timeout RADIUS di 3 secondi e 5 tentativi. Come puoi ridurre il ritardo di failover senza modificare l'architettura del server?
Suggerimento: Calcola il tempo massimo di attesa in base ai timer del NAD prima che tenti di connettersi al server secondario.
Visualizza risposta modello
Dovresti regolare i timer sui Network Access Devices (access point). Attualmente, l'AP attende 3 secondi ed esegue 5 tentativi, con un conseguente ritardo di 18 secondi (3 secondi × 6 tentativi totali) prima di passare al server passivo. Riducendo la configurazione a un timeout di 2 secondi e 2 tentativi, il tempo di rilevamento del failover scende a 6 secondi, migliorando significativamente l'esperienza utente durante le finestre di manutenzione.
Q3. Stai migrando una rete aziendale multi-sito da un server RADIUS on-premise Active-Passive a una piattaforma Cloud RADIUS Active-Active. Durante la fase pilota, i dispositivi si autenticano correttamente con il Cloud Node A, ma quando il bilanciatore di carico li instrada al Cloud Node B, gli handshake EAP-TLS falliscono. Qual è l'errore di configurazione più probabile?
Suggerimento: Considera cosa verifica il dispositivo client quando stabilisce un tunnel EAP sicuro con un nuovo server.
Visualizza risposta modello
Il problema più probabile è una mancata corrispondenza del Certificate Trust. In un cluster Active-Active, tutti i nodi RADIUS devono presentare lo stesso identico certificato server (o certificati emessi dalla stessa identica catena di CA attendibili). Se il Cloud Node B presenta un certificato diverso che i dispositivi client non considerano attendibile, l'handshake EAP-TLS verrà rifiutato dal client, causando il fallimento dell'autenticazione nonostante il corretto funzionamento del server.
Continua a leggere questa serie
Configuring RADIUS Authentication for Guest and Staff WiFi Networks
Questa guida di riferimento tecnica descrive l'architettura, la configurazione e l'implementazione dell'autenticazione RADIUS per le reti WiFi aziendali per ospiti e personale. Fornisce ai network architect e ai manager IT i protocolli esatti, gli standard di sicurezza e le metodologie di risoluzione dei problemi necessari per creare sistemi di controllo degli accessi wireless sicuri e scalabili.
Passpoint and OpenRoaming: Complete Guide
Questa guida di riferimento tecnico fornisce un'analisi completa dei framework Passpoint (Hotspot 2.0) e WBA OpenRoaming all'interno delle reti WiFi aziendali. Descrive in dettaglio i protocolli di autenticazione sottostanti, i componenti architetturali e le strategie di implementazione necessarie per stabilire una connettività guest sicura e senza attriti. I progettisti di rete e i responsabili IT impareranno a progettare, implementare e risolvere i problemi di questi standard per eliminare le barriere di accesso manuale mantenendo al contempo una sicurezza di livello enterprise.
Come Implementare SCEP per il Secure BYOD e l'Iscrizione di Rete nell'Istruzione Superiore
Questa guida tecnica fornisce ad architetti di rete e responsabili IT un modello indipendente dal fornitore per implementare la registrazione dei certificati basata su SCEP per proteggere le reti dei campus universitari. Descrive in dettaglio come migrare dal protocollo PEAP basato su password a 802.1X EAP-TLS, automatizzare l'onboarding dei dispositivi BYOD e applicare una robusta segmentazione VLAN.