Porque é que o Nosso WiFi de Convidados é Tão Lento? Diagnosticar o Congestionamento da Rede
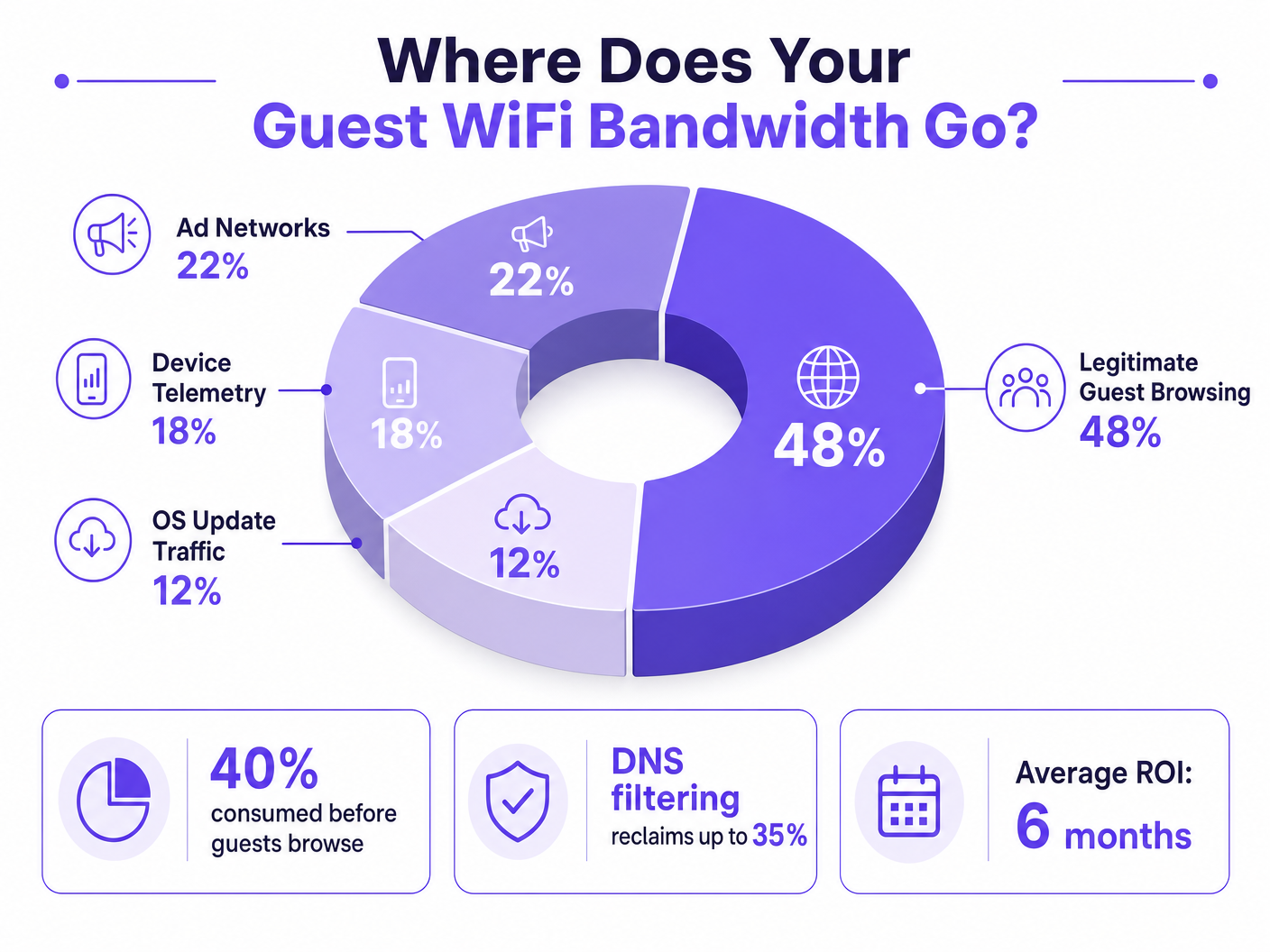
Este guia diagnostica os fatores ocultos do congestionamento do WiFi de convidados — telemetria em segundo plano, redes de anúncios programáticos e atualizações automáticas do SO — que, coletivamente, consomem até 40% da largura de banda WiFi pública antes mesmo de um convidado abrir um navegador. Fornece uma estrutura de implementação faseada e independente de fornecedor para filtragem de DNS e políticas de QoS que recuperam essa largura de banda, melhoram a experiência do convidado e proporcionam um ROI mensurável. Destinado a Diretores de TI e Gestores de Operações nos setores de hotelaria, retalho, eventos e ambientes do setor público.
Ouça este guia
Ver transcrição do podcast
Executive Summary
Para Diretores de TI e Gestores de Operações que supervisionam locais de alta densidade, garantir uma experiência Guest WiFi fiável é uma batalha constante contra o congestionamento da rede. Embora as abordagens legadas se concentrem em aumentar a largura de banda geral ou implementar pontos de acesso adicionais, a causa raiz do baixo débito muitas vezes não reside no tráfego legítimo do utilizador, mas na camada oculta de dados em segundo plano. Em ambientes modernos — desde complexos de Hospitality expansivos a espaços de Retail com grande afluência — até 40% da largura de banda WiFi pública é consumida por telemetria de dispositivos, redes de anúncios programáticos e atualizações automáticas do SO antes mesmo de um convidado abrir um navegador.
Este guia de referência técnica fornece uma metodologia definitiva para diagnosticar este congestionamento e implementar mitigação estratégica. Ao implementar filtragem de DNS ao nível da rede e Zonas de Política de Resposta (RPZ), os arquitetos de rede empresariais podem recuperar uma largura de banda significativa, reduzir a latência e melhorar drasticamente a experiência do utilizador final sem incorrer em despesas de capital para atualizações de infraestrutura. Exploraremos a arquitetura técnica destas soluções, estudos de caso de implementação no mundo real e o ROI mensurável da recuperação da sua rede.
Technical Deep-Dive
The Anatomy of Background Congestion
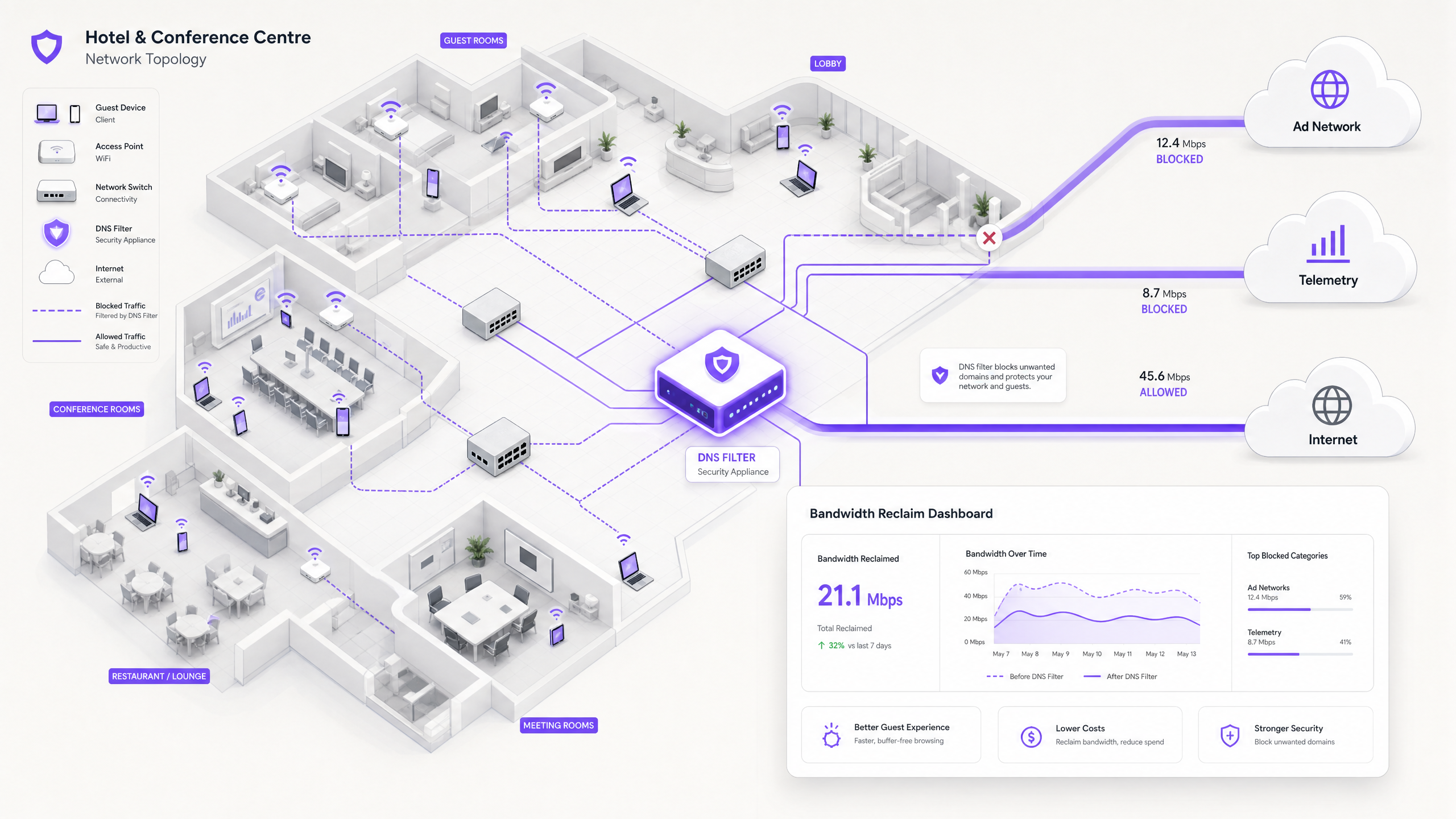
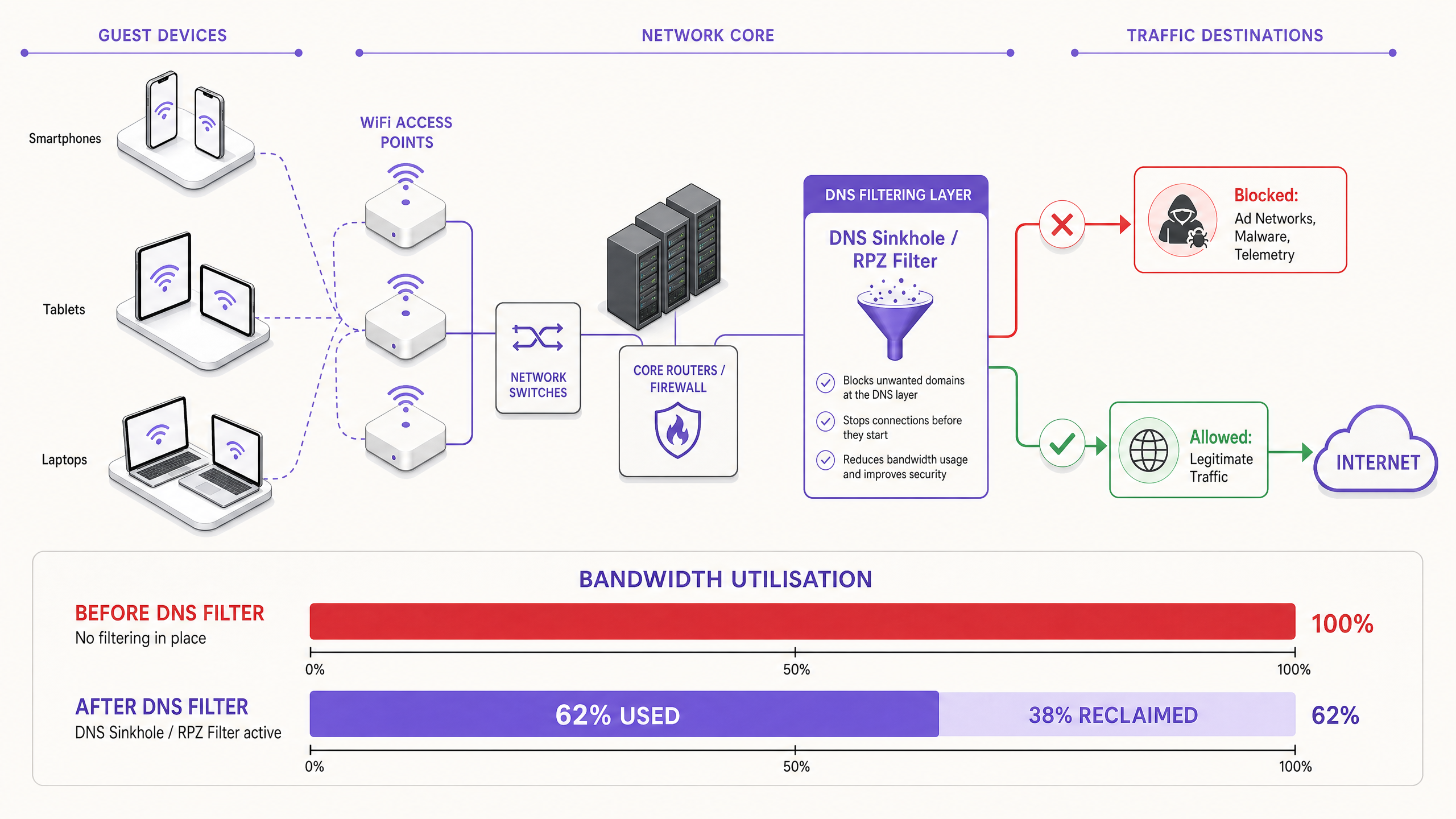
Quando um dispositivo de convidado se autentica numa rede pública, inicia imediatamente uma série de ligações em segundo plano. Estas ligações são impulsionadas principalmente por três categorias de tráfego que, no seu conjunto, constituem o que os engenheiros de rede chamam de carga fantasma — largura de banda consumida pela rede antes de qualquer atividade deliberada do convidado ocorrer.
1. Telemetria e Análise de Dispositivos
Sistemas operativos modernos (iOS, Android, Windows) e aplicações instaladas transmitem constantemente dados de utilização, métricas de localização, relatórios de falhas e análises comportamentais para servidores remotos. Num ambiente denso, como um centro de Transport ou um centro de conferências, milhares de dispositivos a transmitir simultaneamente pequenas, mas frequentes, cargas de telemetria podem esgotar o tempo de antena sem fios disponível e sobrecarregar as tabelas NAT. Um único dispositivo iOS pode gerar mais de 200 consultas DNS distintas em segundo plano nos primeiros 60 segundos de ligação a uma rede não-medida.
2. Redes de Anúncios Programáticos
Muitas aplicações gratuitas dependem de ecossistemas de publicidade programática. No momento em que um dispositivo deteta uma ligação WiFi não-medida, estas aplicações começam a pré-carregar anúncios de vídeo, banners de alta resolução e scripts de rastreamento de plataformas de troca de anúncios. Este tráfego é de alta largura de banda e sensível à latência, e competirá agressivamente pelo tempo de antena com a navegação legítima do convidado. A análise de redes de locais públicos mostra consistentemente que o tráfego de anúncios programáticos representa 15–22% da utilização total da WAN durante as horas de pico.
3. Atualizações Automáticas de SO e Aplicações
Sem uma modelagem de tráfego adequada, os dispositivos tentarão descarregar grandes patches de SO e atualizações de aplicações assim que detetarem uma ligação WiFi não-medida. Uma única atualização principal do iOS pode ter 3–5 GB. Num ambiente com 500 dispositivos, um gatilho de atualização simultâneo — comum quando uma nova versão do SO é lançada — pode saturar até mesmo uma ligação WAN de 1 Gbps em minutos.
Why Traditional Approaches Fall Short
A resposta convencional ao congestionamento do WiFi de convidados é aumentar a largura de banda da WAN ou implementar pontos de acesso adicionais. Embora ambas as medidas tenham o seu lugar, nenhuma aborda a carga fantasma. Adicionar mais largura de banda simplesmente fornece mais capacidade para o tráfego em segundo plano consumir. A Inspeção Profunda de Pacotes (DPI), a outra ferramenta tradicional, é cada vez mais ineficaz: a adoção generalizada de TLS 1.3 e a encriptação de ponta a ponta significam que a maioria das cargas de tráfego são opacas para os motores de inspeção. Não se pode limitar o que não se pode classificar.
Para uma discussão mais ampla sobre como as frequências sem fios interagem com implementações de alta densidade, consulte o nosso guia sobre Wi-Fi Frequencies: A Guide to Wi-Fi Frequencies in 2026 .
DNS Filtering: The Efficient Countermeasure
A solução moderna e escalável é a filtragem de DNS na extremidade da rede. Em vez de inspecionar as cargas de tráfego, a filtragem de DNS opera na camada de resolução — impedindo que as ligações sejam estabelecidas em primeiro lugar.
Quando um dispositivo solicita acesso a uma rede de anúncios conhecida ou a um domínio de telemetria, o resolvedor de DNS verifica o pedido em relação a uma Zona de Política de Resposta (RPZ). Se o domínio aparecer na lista de bloqueio, o resolvedor retorna uma resposta NXDOMAIN (Domínio Não Existente), ou direciona o tráfego para um endereço IP nulo local. A ligação é terminada antes que o handshake TCP ocorra, preservando tanto o tempo de antena sem fios quanto a largura de banda da WAN. Esta abordagem é computacionalmente barata, escala linearmente com a capacidade do resolvedor e não é afetada pela encriptação da carga útil.
The Security Dimension
A filtragem de DNS oferece um benefício secundário significativo: segurança. Ao bloquear domínios de Comando e Controlo (C2) de malware conhecidos, infraestruturas de phishing e redes de entrega de kits de exploração na camada de DNS, a rede de convidados torna-se substancialmente mais defensível. Isto é diretamente relevante para as obrigações de conformidade sob estruturas como PCI DSS (que exige segmentação e monitorização de rede para ambientes de dados de titulares de cartões) e GDPR (que exige medidas técnicas apropriadas para proteger dados pessoais). Para um tratamento detalhado dos requisitos de trilha de auditoria neste contexto, consulte Explicar o que é trilha de auditoria para segurança de TI em 2026 .
Para organizações que gerem ambientes educacionais onde o bloqueio de anúncios também serve uma função de salvaguarda, os princípios abordados em Minimizar Distrações de Estudantes com Bloqueio de Anúncios ao Nível da Rede são diretamente aplicáveis.
Guia de Implementação
Implementar uma arquitetura robusta de filtragem de DNS requer um planeamento cuidadoso para evitar a interrupção de serviços legítimos para convidados. A implementação deve seguir uma abordagem faseada.
Fase 1: Avaliação da Linha de Base e Visibilidade
Antes de implementar quaisquer bloqueios, estabeleça uma linha de base dos padrões de tráfego atuais. Utilize WiFi Analytics para identificar os domínios e categorias que mais consomem largura de banda durante um período representativo de 7 a 14 dias. Esta fase de auditoria é crítica para compreender o perfil de tráfego específico do seu local e para construir o caso de negócio para o investimento. As métricas chave a capturar incluem:
| Métrica | Linha de Base Alvo | Notas |
|---|---|---|
| Top 20 domínios DNS por volume de consulta | Lista completa | Identificar telemetria e domínios de anúncios |
| Utilização da WAN por categoria | % de divisão | Quantificar a carga fantasma |
| Contagem máxima de dispositivos concorrentes | Número | Dimensionar a infraestrutura do resolvedor |
| Taxa de falha de consulta DNS | < 0.1% | Estabelecer benchmark pré-implementação |
Fase 2: Implementação Faseada de RPZ
Comece por implementar o RPZ em modo apenas de registo. Isto permite-lhe verificar a precisão das suas listas de bloqueio sem impactar a experiência do utilizador. Concentre-se primeiro nas categorias de alta confiança:
- Malware Conhecido e Domínios C2: Benefício de segurança imediato com risco quase nulo de falsos positivos. Utilize feeds de inteligência de ameaças de fornecedores reputados.
- Redes de Anúncios Programáticos de Alta Largura de Banda: Direcione as principais plataformas de troca de anúncios de vídeo. Estas são bem documentadas e é improvável que alojem conteúdo legítimo.
- Endpoints de Telemetria Agressivos: Bloqueie domínios de rastreamento não essenciais. Mantenha uma lista de permissões cuidadosa para domínios necessários para fluxos de autenticação de captive portal.
Assim que o modo apenas de registo confirmar taxas de falsos positivos aceitáveis (alvo < 0.5% das consultas), passe para o modo de aplicação.
Fase 3: Modelagem de Tráfego e Integração de QoS
Para tráfego que não pode ser bloqueado diretamente (por exemplo, atualizações de SO da Apple, Microsoft e Google), implemente políticas de Quality of Service (QoS). Limite a taxa dos servidores de atualização a um teto definido — tipicamente 10–15% da capacidade total da WAN — garantindo que o tráfego interativo de convidados (navegação web, VoIP, videoconferência) recebe prioridade na fila. Isto é particularmente importante para ambientes de Saúde onde o pessoal clínico pode partilhar um segmento de rede com convidados.
Para orientação sobre a otimização de ambientes de rede mais amplos, incluindo implementações em escritórios e de uso misto, consulte Wi-Fi de Escritório: Otimize a Sua Rede Wi-Fi de Escritório Moderna .
Melhores Práticas
Manter Listas de Permissões Explícitas para Serviços Críticos. Garanta que os domínios essenciais para a autenticação do captive portal, gateways de pagamento (conformidade com PCI DSS) e operações centrais do local são explicitamente permitidos. Uma lista de bloqueio mal configurada que interrompa o fluxo de login gerará uma carga de suporte imediata e significativa.
Comunicar a Política Transparentemente. Os seus Termos de Serviço devem indicar que o tráfego de rede é gerido para garantir uma experiência de alta qualidade para todos os utilizadores. Esta é tanto uma melhor prática legal sob o GDPR quanto uma medida razoável de definição de expectativas para os convidados.
Automatizar Atualizações de Listas de Bloqueio. O panorama das redes de anúncios e domínios de telemetria muda constantemente. Os feeds de inteligência de ameaças e as listas RPZ devem ser atualizados dinamicamente — idealmente num ciclo inferior a 24 horas — para permanecerem eficazes.
Abordar a Evasão de DNS Proativamente. Implemente regras de firewall para intercetar e redirecionar todo o tráfego de saída da porta 53 (UDP e TCP) para o resolvedor local. Isto impede que os clientes contornem a filtragem ao codificar servidores DNS externos.
Planear para DNS over HTTPS (DoH). À medida que a adoção de DoH aumenta, os clientes podem encaminhar consultas DNS sobre HTTPS para contornar completamente os resolvedores locais. Avalie se deve bloquear provedores DoH conhecidos (por exemplo, dns.google, cloudflare-dns.com) ou implementar um proxy DoH transparente que aplique a política local.
Alinhar com IEEE 802.1X e WPA3. Garanta que a sua arquitetura de filtragem de DNS é compatível com a sua estrutura de autenticação. Em ambientes que utilizam IEEE 802.1X com autenticação baseada em RADIUS, as políticas de filtragem de DNS podem ser aplicadas por VLAN ou por grupo de utilizadores, permitindo um controlo granular.
Resolução de Problemas e Mitigação de Riscos
Modos de Falha Comuns
| Modo de Falha | Sintoma | Mitigação |
|---|---|---|
| Bloqueio excessivo (colisão de CDN) | Páginas web quebradas, imagens em falta | Listas de bloqueio granulares; processo rápido de permissão |
| Evasão de DNS (resolvedores codificados) | Filtragem contornada por aplicações específicas | Regras de redirecionamento de firewall para a porta 53 |
| Bypass de DoH | Filtragem contornada por navegadores modernos | Bloquear provedores DoH conhecidos ou implementar proxy DoH |
| Gargalo de desempenho do resolvedor | Aumento da latência de DNS em todos os clientes | Dimensionar a infraestrutura do resolvedor; implementar anycast |
| Quebra do captive portal | Convidados não conseguem autenticar | Lista de permissões explícita para domínios do portal e endpoints de deteção de SO |
| Listas de bloqueio desatualizadas | Novos domínios de anúncios não bloqueados | Automatizar atualizações de feeds; monitorizar registos de consultas para novos domínios de alto volume |
Resposta a Incidentes de Segurança
Se um dispositivo de convidado for identificado como comunicando com um domínio C2 de malware conhecido (visível nos registos de consulta DNS), o RPZ bloqueará automaticamente a comunicação futura. Certifique-se de que o seu processo de resposta a incidentes inclui um fluxo de trabalho para rever estes eventos, uma vez que podem indicar um dispositivo comprometido que requer isolamento da VLAN de convidados.
ROI e Impacto no Negócio
A implementação de filtragem DNS ao nível da rede proporciona resultados de negócio mensuráveis e quantificáveis em múltiplas dimensões.
Recuperação de Largura de Banda e Adiamento de CapEx. Os locais normalmente recuperam 20–40% da sua largura de banda WAN total. Isto traduz-se diretamente em poupanças de custos ao adiar a necessidade de atualizações de circuitos dispendiosas. Para um local que atualmente paga por uma linha alugada de 500 Mbps, recuperar 30% da capacidade é equivalente a ganhar 150 Mbps de débito efetivo sem custos adicionais.
Melhoria da Satisfação dos Convidados e NPS. Ao eliminar o congestionamento de fundo, a velocidade percebida e a fiabilidade do Guest WiFi melhoram drasticamente. A latência reduzida e o débito consistente levam a Net Promoter Scores mais elevados e a menos escalonamentos de suporte operacional.
Postura de Segurança e Conformidade Reforçada. O bloqueio de malware e domínios de phishing na camada DNS reduz significativamente o risco de uma violação de segurança originada na rede de convidados. Isto apoia diretamente a conformidade com os requisitos de segmentação de rede PCI DSS e a obrigação do GDPR de implementar medidas de segurança técnicas apropriadas.
Eficiência Operacional. A filtragem DNS automatizada reduz a carga de trabalho manual das equipas de operações de rede. Em vez de responder reativamente a eventos de congestionamento, a rede gere proativamente o seu próprio perfil de tráfego.
| Resultado | Intervalo Típico | Método de Medição |
|---|---|---|
| Largura de banda recuperada | 20–40% da capacidade WAN | Monitorização da utilização WAN antes/depois |
| Taxa de bloqueio de consultas DNS | 15–35% de todas as consultas | Registos de consultas do resolvedor |
| Melhoria da satisfação dos convidados | +8–15 pontos NPS | Inquéritos pós-estadia/pós-visita |
| Adiamento de CapEx | 1–3 anos na atualização de circuitos | Modelação de custos |
| Redução de incidentes de segurança | 40–60% menos deteções C2 | Correlação SIEM |
Ao tratar a rede não apenas como um canal, mas como um gateway inteligente e filtrado, os líderes de TI podem oferecer uma experiência de conectividade superior, segura e económica — uma que escala com o crescimento do local sem investimento proporcional em infraestrutura.
Definições Principais
Response Policy Zone (RPZ)
A mechanism in DNS servers that allows the modification of DNS responses based on a defined policy. When a queried domain matches an entry in the RPZ, the resolver can return a synthetic response (e.g., NXDOMAIN or a sinkhole IP) instead of the real answer.
The primary technical mechanism for implementing network-wide DNS filtering. IT teams configure RPZs on their internal resolvers to block ad networks, malware domains, and telemetry endpoints without requiring client-side software.
Deep Packet Inspection (DPI)
A form of network packet filtering that examines the data payload of a packet as it passes an inspection point, searching for protocol non-compliance, specific content, or defined criteria.
Traditionally used for traffic classification and shaping. Increasingly limited by the widespread adoption of TLS 1.3 end-to-end encryption, which renders payloads opaque. DNS filtering is the preferred alternative for encrypted traffic environments.
NXDOMAIN
A DNS response code (RCODE 3) indicating that the queried domain name does not exist in the DNS namespace.
Returned by a filtering DNS resolver to intentionally block a connection to an unwanted domain. The client application receives this response and abandons the connection attempt, preventing any bandwidth from being consumed.
DNS over HTTPS (DoH)
A protocol for performing DNS resolution via the HTTPS protocol (RFC 8484), encrypting DNS queries and responses between the client and a DoH-capable resolver.
Can bypass local network DNS filtering if clients are configured to use external DoH providers. Network administrators must implement firewall rules or proxy DoH traffic to enforce local RPZ policies.
Quality of Service (QoS)
A set of network mechanisms that control traffic prioritisation, rate-limiting, and queuing to ensure the performance of critical applications.
Used alongside DNS filtering to manage legitimate but high-bandwidth traffic (e.g., OS updates) that cannot be blocked. QoS ensures that interactive guest traffic receives priority over background bulk transfers.
Telemetry
The automated collection and transmission of operational data from devices to remote servers for monitoring, analytics, and diagnostics.
In the context of guest WiFi, device telemetry from mobile operating systems and applications can silently consume 15–20% of available bandwidth. It is a primary target for DNS filtering in public network deployments.
DNS Sinkholing
A technique in which a DNS server is configured to return a false IP address (typically a local null address) for specific domains, redirecting traffic away from its intended destination.
Used to neutralise malware C2 traffic and aggressively block high-bandwidth ad networks. More definitive than NXDOMAIN responses, as it allows the sinkhole server to log connection attempts for security analysis.
Airtime Fairness
A wireless network feature that allocates equal access to the wireless medium across all connected clients, regardless of their individual data rates.
Critical in high-density environments. Without airtime fairness, a single slow device (e.g., an older 802.11g client) can disproportionately consume airtime, degrading throughput for all other clients. Background telemetry traffic from many devices exacerbates this effect.
Phantom Load
Bandwidth consumed by automated background processes on connected devices before any deliberate user activity occurs.
The collective term for telemetry, ad network pre-fetching, and OS update traffic. Understanding and quantifying the phantom load is the first step in any guest WiFi congestion diagnosis.
Exemplos Práticos
A 400-room resort hotel is experiencing severe network congestion every evening between 7:00 PM and 10:00 PM. The 1 Gbps WAN link is saturated, and guests are complaining about slow streaming and dropped VoIP calls. The IT Director needs to identify the root cause and implement a solution without upgrading the circuit.
Step 1 — Traffic Analysis: Deploy a network flow analyser (NetFlow/IPFIX) on the core router and run it for 5 days across peak and off-peak periods. Correlate with DNS query logs from the existing resolver. The analysis reveals that 35% of evening traffic is destined for known programmatic video ad networks (DoubleClick, AppNexus) and automated app update servers (Apple Software Update, Google Play). Legitimate guest browsing accounts for only 52% of total traffic.
Step 2 — DNS Filtering Deployment: Configure the core firewall to redirect all guest VLAN DNS queries (UDP/TCP port 53) to a locally hosted RPZ-enabled resolver. Import a curated blocklist covering the identified ad networks and telemetry domains. Run in log-only mode for 48 hours to validate false positive rates.
Step 3 — Policy Enforcement: After validating a false positive rate below 0.3%, switch to enforcement mode. Simultaneously, implement a QoS policy that rate-limits Apple and Google update servers to a combined ceiling of 80 Mbps during the 6 PM–11 PM window.
Step 4 — Validation: Monitor WAN utilisation over the following 7 days. Peak utilisation drops from 98% to 61%, resolving guest complaints. The hotel defers a planned circuit upgrade by an estimated 18 months.
A large conference centre is hosting a technology summit with 5,000 attendees. During the keynote, the WiFi network becomes completely unusable. Post-incident analysis shows that thousands of devices simultaneously attempted to download a major iOS update that was released that morning.
Immediate Mitigation (Day of Event): The network operations team identifies the surge via real-time DNS query monitoring. They immediately sinkhole the specific Apple software update domains (mesu.apple.com, appldnld.apple.com, updates.cdn-apple.com) at the DNS layer. Within 4 minutes, WAN utilisation drops from 99% to 68%, and the network stabilises.
Short-Term Fix (Same Event): A QoS policy is applied to rate-limit all remaining update traffic to 50 Mbps for the duration of the event.
Long-Term Strategy (Post-Event): The network team implements a dynamic QoS policy that automatically activates when total WAN utilisation exceeds 75%, throttling known update servers to 10% of total capacity. A pre-event checklist is created that includes temporarily sinkholes of major update domains during the 2 hours before and after high-profile sessions. The team also subscribes to Apple's and Microsoft's update release notification feeds to anticipate future surge events.
Perguntas de Prática
Q1. You are the IT Manager for a national retail chain. After deploying a DNS filtering solution across 50 stores, several store managers report that the captive portal login page is failing to load for guests. The support team is receiving high call volumes. What is the most likely cause, and what is the immediate remediation step?
Dica: Consider the full dependency chain of a modern captive portal authentication flow, including OS-level captive portal detection mechanisms.
Ver resposta modelo
The most likely cause is over-blocking. The DNS filter is blocking a domain required for the captive portal to function. Modern mobile operating systems use specific domains to detect captive portals (e.g., captive.apple.com for iOS, connectivitycheck.gstatic.com for Android). If these are blocked, the OS will not trigger the captive portal browser, and the guest will see no login prompt. Additionally, the portal itself may depend on a CDN or third-party authentication provider (e.g., social login via Facebook or Google) whose domains are inadvertently blocked.
Immediate remediation: Review the DNS query logs for NXDOMAIN responses originating from the guest subnet during the authentication phase. Identify all blocked domains that are queried before a successful login. Add these domains to the global allow-list. Implement a standard allow-list template for captive portal deployments that includes all major OS detection endpoints and common authentication provider domains.
Q2. A stadium network architect notices that despite implementing aggressive DNS filtering, WAN utilisation remains critically high during matches. Further investigation reveals a sustained high volume of UDP port 443 traffic that does not correlate with any blocked domains in the DNS logs. What is happening, and how should it be addressed?
Dica: Consider modern transport protocols and how they interact with DNS-layer controls.
Ver resposta modelo
The high volume of UDP 443 traffic indicates the use of QUIC (HTTP/3). QUIC is a UDP-based transport protocol used by major platforms (Google, Meta, YouTube) that bypasses traditional TCP-based proxies and DPI engines. More critically, clients using QUIC may also be using DNS over HTTPS (DoH) to resolve domains, completely bypassing the local RPZ resolver and rendering DNS filtering ineffective for those clients.
To address this: First, implement firewall rules to block outbound DoH traffic to known public DoH providers (Google, Cloudflare, NextDNS) on TCP/UDP port 443 by destination IP, forcing clients to fall back to the local resolver. Second, evaluate blocking outbound UDP 443 entirely (or rate-limiting it aggressively) to force QUIC clients to fall back to TCP-based HTTP/2, which is subject to existing traffic management policies. Third, review whether a transparent DoH proxy can be deployed to intercept and inspect DoH queries while enforcing local RPZ policies.
Q3. You are designing a QoS policy for a large public hospital's guest WiFi network. The network is shared between patient entertainment devices, visitor personal devices, and a small number of clinical staff using VoIP softphones on their personal mobiles. Prioritise the following traffic types: VoIP (SIP/RTP), Guest Web Browsing (HTTP/HTTPS), Windows/iOS Updates, and Streaming Video (Netflix/YouTube).
Dica: Consider both latency sensitivity and the business/clinical impact of each traffic type. Also consider the regulatory context of a healthcare environment.
Ver resposta modelo
Priority 1 — VoIP (SIP/RTP): Strict Priority Queuing (Expedited Forwarding, DSCP EF). VoIP is highly sensitive to latency (target < 150ms one-way) and jitter (target < 30ms). Packet loss above 1% causes audible degradation. In a clinical context, a dropped call could have patient safety implications.
Priority 2 — Guest Web Browsing (HTTP/HTTPS): Assured Forwarding (AF31). This is the primary expected use case for both patients and visitors. It requires reasonable responsiveness but is tolerant of moderate latency.
Priority 3 — Streaming Video (Netflix/YouTube): Rate-limited per client (e.g., 3–5 Mbps cap) with Assured Forwarding (AF21). While important for patient experience during long stays, uncapped streaming will saturate the link. A per-client cap ensures equitable access. Consider time-of-day policies that relax limits during off-peak hours.
Priority 4 — OS/App Updates (Scavenger Class, DSCP CS1): Lowest priority, best-effort queuing, with an aggregate rate limit (e.g., 50 Mbps total across all update traffic). These are background tasks with no latency sensitivity. They should only consume spare capacity. In a healthcare environment, also consider whether the guest network is fully isolated from clinical systems — if not, update traffic management becomes a security concern as well as a bandwidth one.