Top 10 Causes of DHCP Timeouts on High-Density Wireless Networks
This authoritative technical reference guide identifies the top ten causes of DHCP timeouts on high-density wireless networks and provides actionable, vendor-neutral remediation strategies. Designed for senior IT leaders, network architects, and venue operations directors, it covers deep-dive engineering principles, step-by-step implementation workflows, and measurable business outcomes. Learn how to eliminate connection bottlenecks and optimize your wireless infrastructure to deliver seamless connectivity in demanding enterprise environments.
Diesen Leitfaden anhören
Podcast-Transkript ansehen
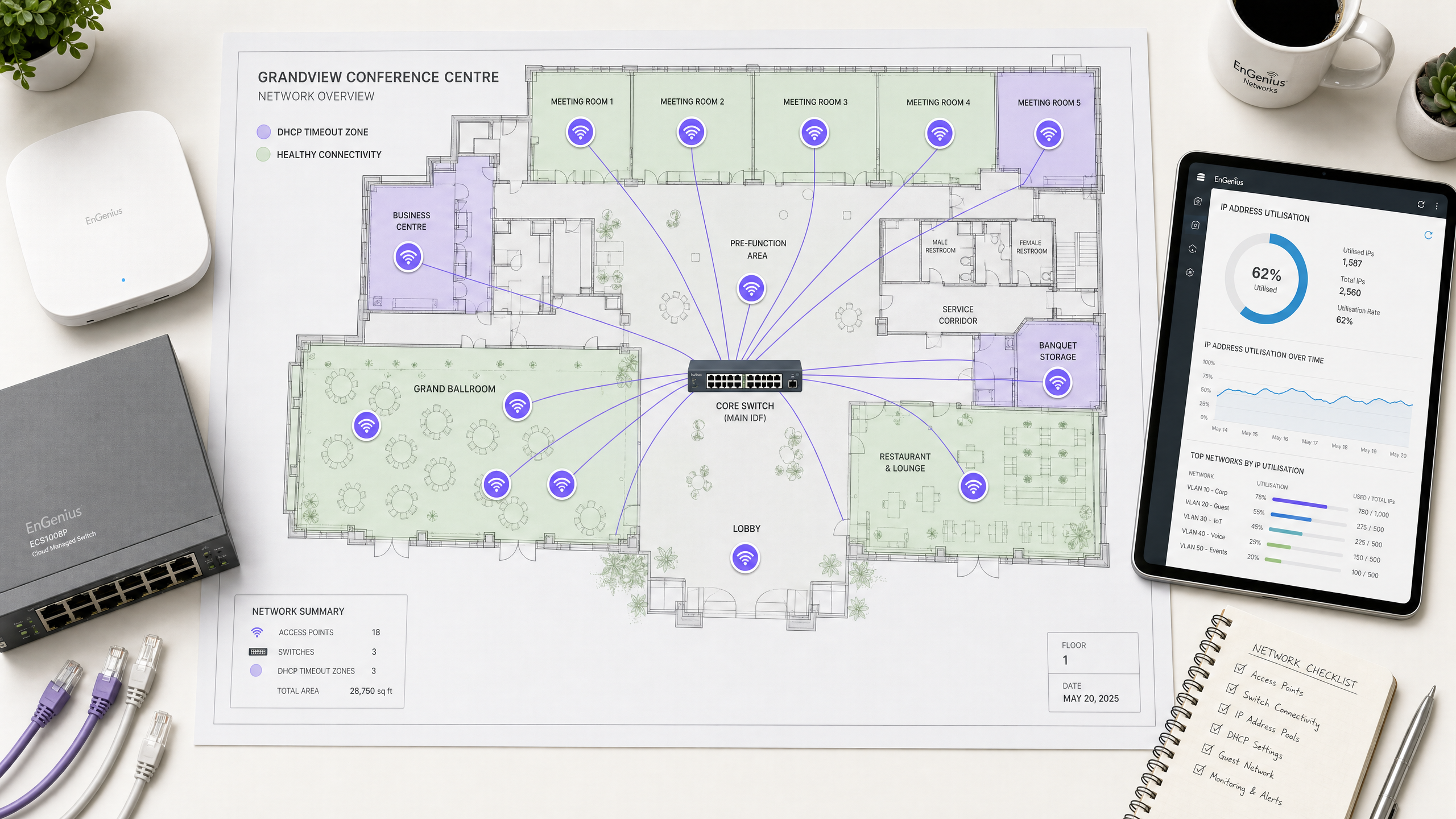
Management Summary
In modernen Enterprise-Umgebungen – wie stark frequentierten Hotels, Einkaufszentren, Verkehrsknotenpunkten und Stadien – ist die drahtlose Konnektivität ein grundlegender Business-Treiber. Die Guest Experience scheitert jedoch häufig bereits beim ersten Schritt des Onboardings: dem Bezug einer IP-Adresse. In High-Density-Netzwerken sind Dynamic Host Configuration Protocol (DHCP) Timeouts eine der häufigsten, aber am seltensten korrekt diagnostizierten Ursachen für fehlgeschlagene Verbindungen. Wenn Hunderte oder Tausende von Geräten gleichzeitig versuchen, eine Verbindung herzustellen, brechen herkömmliche DHCP-Konfigurationen unter der Last zusammen. Benutzer hängen dann in einer Ladeschleife fest oder erhalten eine selbst zugewiesene Link-Local-Adresse im Bereich 169.254.x.x.
Dieser technische Leitfaden untersucht die zehn häufigsten Ursachen für DHCP-Timeouts in High-Density-Netzwerken. Er verzichtet auf graue Theorie, um Netzwerkarchitekten, CTOs und Betriebsleitern direkt umsetzbare Lösungsstrategien an die Hand zu geben. Durch die systematische Optimierung von DHCP-Scope-Größen, die Verkürzung von Lease-Zeiten, die Implementierung robuster Layer-2/3-Konfigurationen und den Einsatz hochverfügbarer Server-Architekturen können Unternehmen Verbindungsverzögerungen erheblich reduzieren, Onboarding-Probleme beseitigen und ihre Markenreputation schützen. Die Umsetzung dieser Best Practices korreliert direkt mit einer verbesserten Gästezufriedenheit, einer höheren Interaktionsrate mit Kernprodukten wie Guest WiFi und einer präziseren Datenerfassung durch WiFi Analytics .
Technische Detailanalyse
Um DHCP-Timeouts zu diagnostizieren und zu beheben, müssen Netzwerkingenieure zunächst die genaue Funktionsweise des vierteiligen DHCP-Handshakes verstehen, der gemeinhin als DORA-Prozess (Discover, Offer, Request, Acknowledge) bezeichnet wird [1]. In High-Density-Umgebungen reagiert dieser Prozess äußerst empfindlich auf Paketverlust, Latenz und Ressourcenengpässe.
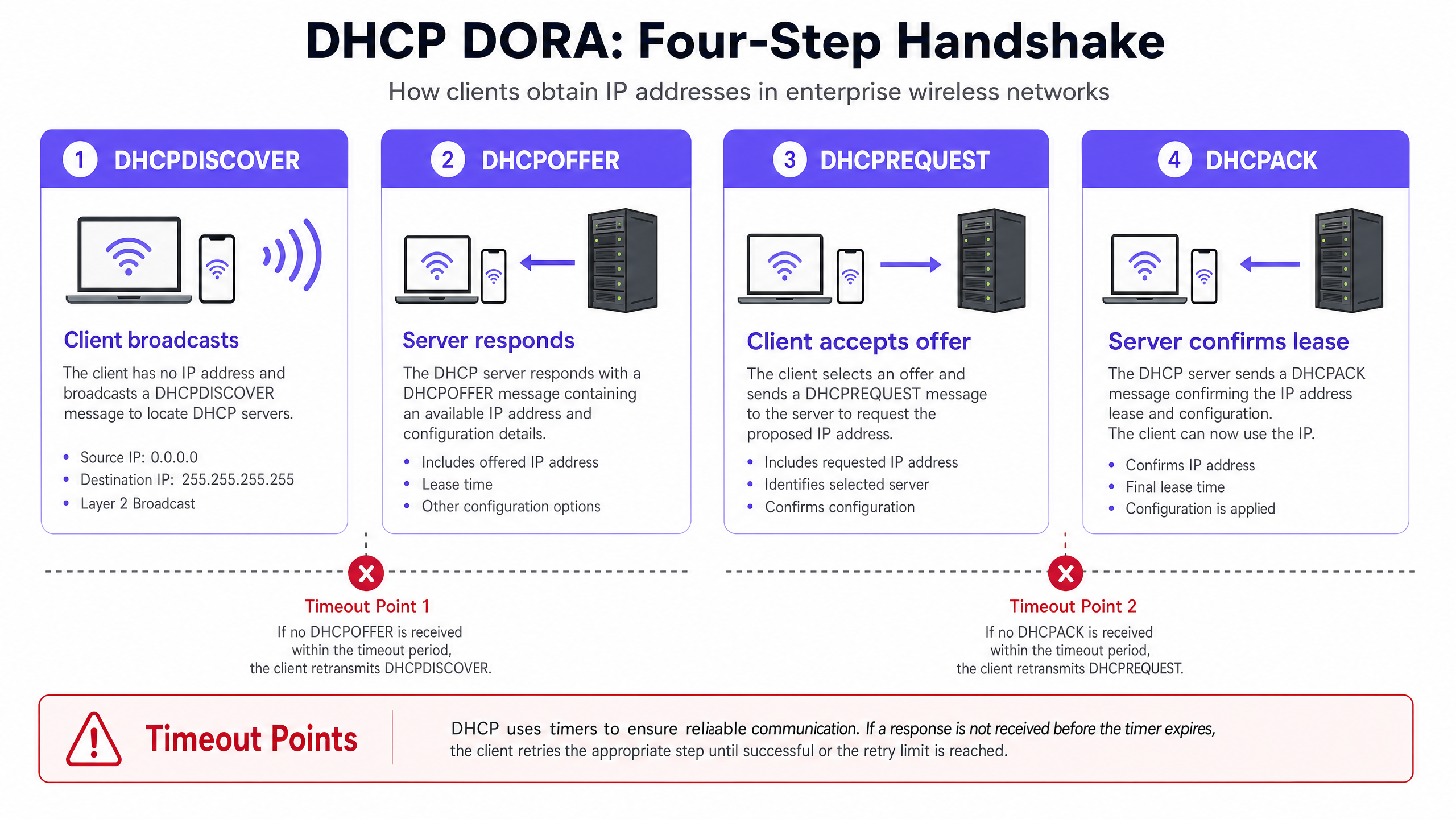
Der DHCP-Handshake (DORA) in High-Density-Wireless-Netzwerken
- DHCPDISCOVER (Broadcast): Der Wireless-Client verbindet sich mit dem Access Point (AP) und sendet ein Broadcast-Paket, um verfügbare DHCP-Server zu finden. In einer großen Broadcast-Domäne wird dieses Paket über alle Ports geflutet, was wertvolle WiFi-Sendezeit beansprucht.
- DHCPOFFER (Unicast/Broadcast): Jeder aktive DHCP-Server, der die Discover-Nachricht empfängt, reserviert eine IP-Adresse und sendet ein Angebot an den Client, das Lease-Parameter, Subnetzmaske, Standard-Gateway und DNS-Server enthält.
- DHCPREQUEST (Broadcast): Der Client wählt ein Angebot aus (in der Regel das zuerst empfangene) und sendet einen Broadcast-Request, um diese spezifische IP-Adresse zu akzeptieren, wodurch andere Angebote implizit abgelehnt werden.
- DHCPACK (Unicast/Broadcast): Der ausgewählte DHCP-Server trägt das Lease in seine Datenbank ein und sendet eine Bestätigung (Acknowledgement) an den Client, um die IP-Zuweisung und Lease-Dauer zu bestätigen. Der Client wendet diese Konfiguration anschließend an.
Die Auswirkungen von Wireless Overhead und Airtime-Überlastung
Im Gegensatz zu kabelgebundenen Netzwerken, in denen Layer-2-Broadcasts in Hardware mit Gigabit-Geschwindigkeit verarbeitet werden, übertragen kabellose Netzwerke Broadcast- und Multicast-Frames mit der niedrigsten obligatorischen Datenrate (häufig 1 Mbps, 6 Mbps oder 11 Mbps, je nach SSID-Konfiguration), um sicherzustellen, dass alle entfernten Clients sie empfangen können [2]. Auf einer hochverdichteten SSID mit Tausenden von aktiven Geräten verbrauchen Broadcast-DHCP-Pakete unverhältnismäßig viel RF-Airtime, was zu Paketkollisionen, erneuten Übertragungen und schließlich zu Timeouts führt. Ein Client-Gerät erwartet eine DHCP-Antwort in der Regel innerhalb von 2 bis 4 Sekunden; wenn eine Airtime-Überlastung einen Schritt des DORA-Prozesses über dieses Fenster hinaus verzögert, bricht der Client die Verbindung ab (Timeout), trennt die Zuordnung und versucht es erneut, was eine kaskadierende Last für das Netzwerk erzeugt.
Top 10 Ursachen für DHCP-Timeouts
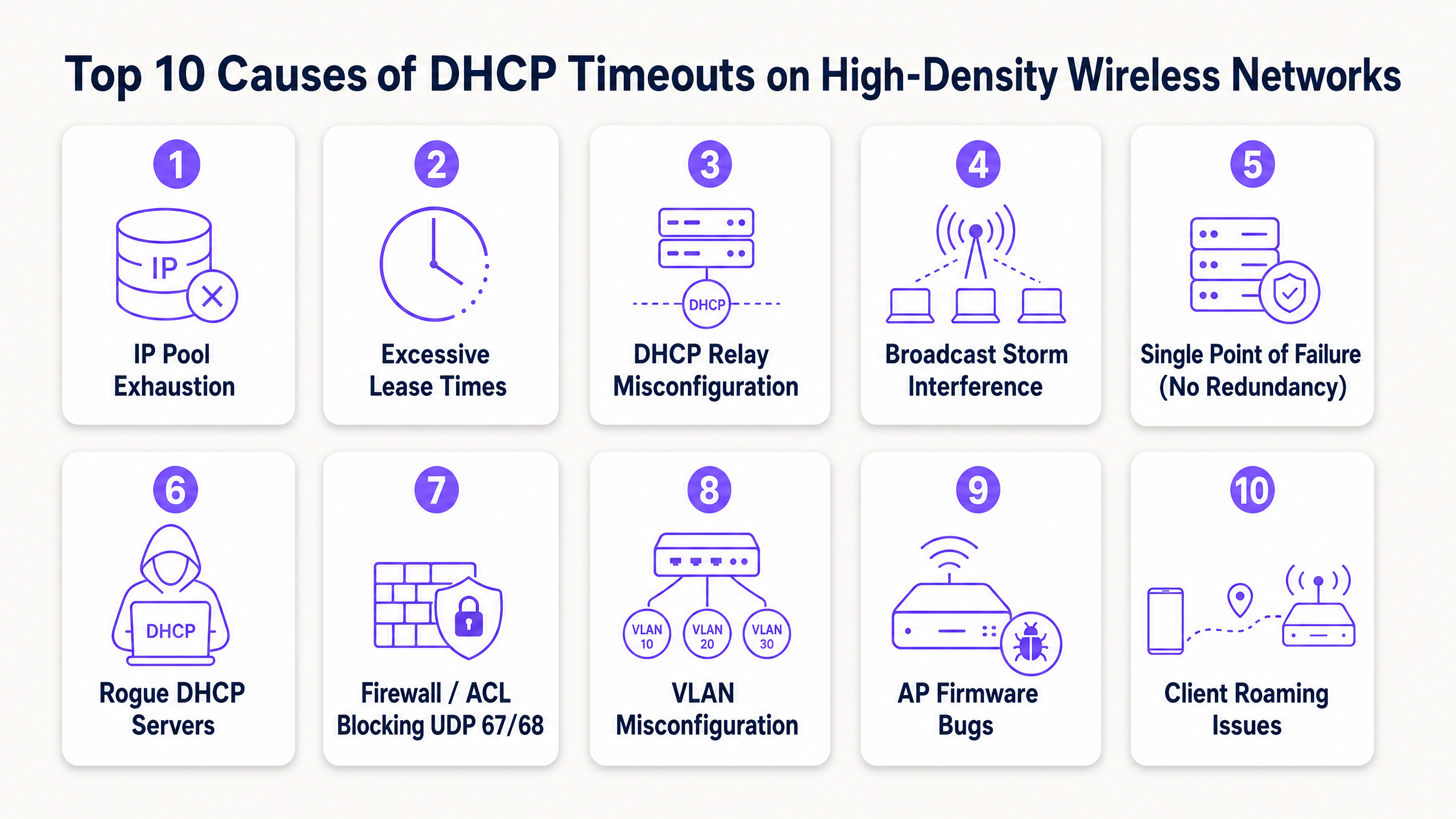
1. Erschöpfung des DHCP-IP-Pools
Der Mechanismus: Der Adressbereich des DHCP-Servers ist für die Anzahl der vorübergehend verbundenen Geräte zu klein. Wenn der Pool zu 100 % ausgelastet ist, ignoriert der Server neue DHCPDISCOVER-Pakete stillschweigend, da er keine Adressen anzubieten hat.
Der High-Density-Kontext: Ein Standard-Klasse-C-Subnetz (/24) bietet nur 254 nutzbare IP-Adressen. In einer Hotellobby, an einem Stadiontor oder in einem Konferenzplenum kann die Anzahl der gleichzeitigen Geräte diese Grenze innerhalb von Minuten leicht überschreiten. Verschärfend kommt hinzu, dass viele Nutzer mehrere verbundene Geräte (Smartphones, Smartwatches, Tablets, Laptops) mit sich führen, was den IP-Bedarf vervielfacht.
Behebung: Dimensionieren Sie Ihre Netzwerkbereiche mithilfe der CIDR-Notation (Classless Inter-Domain Routing) richtig. Migrieren Sie hochverdichtete Client-VLANs auf /22 (1.022 IPs) oder /21 (2.046 IPs) Subnetze. Stellen Sie sicher, dass Ihre Monitoring-Tools so konfiguriert sind, dass sie bei 80 % Pool-Auslastung warnen, um eine proaktive Bereichserweiterung vor Spitzenzeiten zu ermöglichen.
2. Zu lange Lease-Zeiten in Gastnetzwerken
Der Mechanismus: Die Lease-Zeit bestimmt, wie lange ein Client eine IP-Adresse behält, bevor er sie erneuern oder freigeben muss. Wenn die Lease-Zeit zu lang ist, behält der DHCP-Server die Adresse in seiner Datenbank. Dies verhindert, dass sie einem neuen Client zugewiesen wird, selbst wenn das ursprüngliche Gerät den Standort bereits verlassen hat.
Der High-Density-Kontext: Viele Standard-DHCP-Konfigurationen sehen eine Lease-Zeit von 24 Stunden oder 8 Tagen vor. In hochfrequentierten Umgebungen des öffentlichen Sektors oder des Gastgewerbes – wie einem Verkehrsknotenpunkt oder einem Einkaufszentrum – bleiben Gäste in der Regel weniger als zwei Stunden [3]. Bei einer 24-stündigen Lease-Zeit belegt ein Gast, der sich für 10 Minuten verbindet, eine IP-Adresse für einen ganzen Tag, was zu einer künstlichen Pool-Erschöpfung führt. Remediation: Align lease times with client dwell times. Implement a 30-to-60-minute lease time for guest networks. For corporate staff networks where devices remain connected for a full shift, use an 8-to-12-hour lease time. This ensures rapid reclamation of IP addresses from departed clients.
3. DHCP Relay Agent Misconfiguration
The Mechanism: Because DHCP discovery messages are Layer 2 broadcasts, they cannot cross router (Layer 3) boundaries. A DHCP Relay Agent (typically configured on a Layer 3 switch or security gateway using commands like Cisco's ip helper-address) must intercept these broadcasts and forward them as unicast packets to the central DHCP server [4]. If the relay agent is misconfigured, has the wrong helper IP, or is omitted from a newly created VLAN, DHCP traffic will be blocked.
The High-Density Context: High-density networks rely heavily on VLAN segmentation to limit broadcast domains. When deploying a new SSID or expanding a venue, engineers often create new client VLANs. If the relay agent configuration is not updated on the corresponding Layer 3 interfaces, clients on those VLANs will experience immediate DHCP timeouts.
Remediation: Establish strict configuration templates for all Layer 3 switches. Ensure that every client VLAN interface has a redundant pair of DHCP helper addresses pointing to your primary and secondary DHCP servers. Verify end-to-end routing between the relay interface IP (which the DHCP server uses to determine which subnet scope to assign) and the DHCP server itself.
4. Broadcast and Multicast Storms
The Mechanism: Excessive broadcast or multicast traffic on a VLAN saturates the wireless medium. Because wireless is a shared half-duplex medium, APs and clients must wait for the airwaves to be clear before transmitting. A broadcast storm—often caused by switching loops, failing network interface cards, or aggressive peer-to-peer protocols—fills the airtime, causing DHCP packets to be queued, delayed, or dropped.
The High-Density Context: In large, flat wireless networks without proper Layer 2 isolation, peer-to-peer broadcast traffic (such as Apple AirPlay, Google Chromecast, or Windows network discovery) is replicated by every AP on the VLAN. In a venue with 10,000 users, this background "chatter" can consume over 50% of the available wireless bandwidth, leaving insufficient airtime for critical DHCP handshake packets.
Remediation: Enable Client Isolation (also known as peer-to-peer blocking) on the wireless controller to prevent clients from communicating directly with one another. Configure Broadcast and Multicast Suppression on the APs and switches, limiting broadcast traffic to a small percentage of the link capacity (e.g., 100 packets per second). Where supported, enable DHCP Proxy on the APs to convert broadcast DHCP offers and acknowledgements into unicast frames directed specifically to the requesting client.
5. Single Point of Failure (Fehlende DHCP-Redundanz)
Der Mechanismus: Ein einzelner, nicht-redundanter DHCP-Server stellt eine kritische Schwachstelle dar. Wenn der Server abstürzt, System-Updates durchgeführt werden oder die Netzwerkverbindung unterbrochen wird, stoppt die Onboarding-Fähigkeit des gesamten Netzwerks sofort. Bestehende Leases bleiben aktiv, aber neue Clients können keine IP-Adresse abrufen und roamingfähige Clients können ihre Leases nicht erneuern.
Der High-Density-Kontext: High-Density-Veranstaltungsorte arbeiten unter strengen betrieblichen SLAs. Ein Stadion während eines Spiels oder ein Kongresszentrum während einer Keynote kann sich selbst eine fünfminütige DHCP-Ausfallzeit nicht leisten. Die Abhängigkeit von einem einzelnen Router oder einer einzelnen virtuellen Maschine zur Bewältigung von Tausenden von schnellen Lease-Anfragen ist eine hochriskante Architektur.
Abhilfe: Implementieren Sie DHCP in einer Hochverfügbarkeitskonfiguration. Nutzen Sie Windows Server DHCP Failover im Load-Balance-Modus (50/50-Aufteilung) oder Hot-Standby-Modus, oder implementieren Sie redundante Enterprise-Grade-DHCP-Appliances (wie Infoblox oder BlueCat) [5]. Stellen Sie sicher, dass Ihre DHCP-Server physisch oder logisch über verschiedene Hypervisoren und Netzwerkpfade verteilt sind, um Common-Mode-Ausfälle auszuschließen.
6. Rogue DHCP-Server
Der Mechanismus: Ein Rogue DHCP-Server ist ein unbefugtes, DHCP-aktiviertes Gerät, das mit dem Netzwerk verbunden ist. Es fängt DHCPDISCOVER-Broadcasts von Clients ab und antwortet mit eigenen DHCPOFFER-Paketen, wobei es oft falsche IP-Konfigurationen, falsche Standard-Gateways oder bösartige DNS-Server verteilt.
Der High-Density-Kontext: In großen Veranstaltungsorten, Einzelhandelsgeschäften oder Behörden sind physische Ethernet-Ports in öffentlichen Bereichen oft frei zugänglich, oder Benutzer bringen nicht autorisierte Geräte mit (wie Reiserouter für Endverbraucher oder virtuelle Maschinen mit Bridged-Networking) und schließen diese an die Wand an. Dies führt zu IP-Adresskonflikten, Routing-Black-Holes und schwerwiegenden Sicherheitsrisiken, einschließlich Man-in-the-Middle-Angriffen.
Abhilfe: Aktivieren Sie DHCP Snooping auf allen Access- und Distribution-Switches [6]. DHCP Snooping kennzeichnet Switch-Ports als "trusted" (mit legitimen DHCP-Servern oder Relay-Agents verbunden) oder "untrusted" (mit Clients verbunden). Der Switch verwirft automatisch jede DHCP-Server-Antwort (wie DHCPOFFER oder DHCPACK), die von einem nicht vertrauenswürdigen Port stammt, und neutralisiert so Rogue-Server sofort.
7. Firewalls, ACLs und Sicherheitsrichtlinien, die UDP 67/68 blockieren
Der Mechanismus: DHCP basiert auf dem UDP-Port 67 (serverseitiges Listening und clientseitiges Ziel) und dem UDP-Port 68 (clientseitiges Listening und serverseitiges Ziel). Wenn Netzwerk-Firewalls, Switch-Access-Control-Lists (ACLs) oder Endpoint-Sicherheitsrichtlinien diese Ports blockieren, kann der DORA-Handshake nicht abgeschlossen werden.
Der High-Density-Kontext: Die Härtung der Sicherheit hat bei Unternehmensnetzwerken höchste Priorität. Zu aggressive Sicherheitsrichtlinien blockieren jedoch oft unbeabsichtigt den DHCP-Verkehr. Beispielsweise könnte ein Administrator während einer Firewall-Migration oder einer Richtlinienaktualisierung den gesamten UDP-Verkehr auf einem Segment blockieren, ohne zu merken, dass er den DHCP-Pfad unterbrochen hat. Ebenso müssen Sicherheitsrichtlinien für Gast-VLANs die UDP-Ports 67 und 68 explizit zulassen, bevor der Datenverkehr an ein Captive Portal umgeleitet wird.
Fehlerbehebung: Überprüfen Sie alle ACLs und Firewall-Regeln auf dem Pfad zwischen den Wireless-Clients, den APs, den Layer-3-Switches und den DHCP-Servern. Stellen Sie sicher, dass die UDP-Ports 67 und 68 in beiden Richtungen explizit zulässig sind. Führen Sie bei der Fehlerbehebung eine Paketerfassung an der Netzwerkschnittstelle des DHCP-Servers durch, um zu bestätigen, dass DHCPDISCOVER-Pakete tatsächlich ankommen.
8. VLAN- und Trunking-Fehlkonfigurationen
Der Mechanismus: Wenn die SSID eines Clients einem bestimmten VLAN zugewiesen ist, dieses VLAN aber nicht korrekt über die gesamte Switching-Infrastruktur hinweg getaggt oder getrunkt ist, erreichen die DHCP-Broadcasts des Clients niemals das Standard-Gateway oder den DHCP-Relay-Agenten.
Der High-Density-Kontext: Drahtlose High-Density-Netzwerke nutzen die dynamische VLAN-Zuweisung oder Multi-VLAN-Pooling, um die Client-Last zu verteilen. Wenn an einem einzelnen Switch-Trunk-Port auf dem Pfad vom AP zum Core-Switch ein VLAN-Tag in der Liste der zulässigen VLANs fehlt, kommt es bei einer Teilmenge von Clients – genauer gesagt bei denjenigen, die diesem VLAN zugewiesen sind – zu sofortigen und anhaltenden DHCP-Timeouts, während andere Clients auf derselben SSID erfolgreich eine Verbindung herstellen. Dies führt zu sehr unregelmäßigen, schwer zu diagnostizierenden Fehlerbehebungsszenarien.
Fehlerbehebung: Implementieren Sie automatisierte Tools zur Netzwerkverwaltung und -validierung. Verwenden Sie bei der Konfiguration von Switch-Trunk-Ports immer explizite Freigabelisten (z. B. switchport trunk allowed vlan 10,20,30), anstatt sich auf die Standardeinstellung „all“ zu verlassen, und stellen Sie sicher, dass das native VLAN auf beiden Seiten der Trunk-Verbindung übereinstimmt, um ein Abfließen von ungetaggtem Datenverkehr zu verhindern.
9. Fehler in der Access Point-Firmware und in Treibern
Der Mechanismus: Die Firmware des Access Points ist für das Bridging von drahtlosen 802.11-Frames auf das kabelgebundene 802.3-Ethernet-Netzwerk verantwortlich. Ein Softwarefehler im Wireless-Treiber oder in der Bridging-Engine des AP kann dazu führen, dass der AP DHCP-Pakete verwirft, insbesondere bei hoher CPU- oder Speicherauslastung.
Der High-Density-Kontext: High-Density-Netzwerke bringen AP-Hardware und -Software an ihre Grenzen. Ein Fehler, der bei einer geringen Last von 10 Clients unbemerkt bleibt, kann zu katastrophalen Ausfällen führen, wenn der AP 100 gleichzeitig aktive Clients bedienen muss. Beispielsweise führte ein dokumentierter Fehler Anfang 2026 bei bestimmten WiFi 7-APs dazu, dass der AP das dritte Paket des Handshakes (den DHCPREQUEST) unregelmäßig verwarf, was verhinderte, dass der Client jemals sein DHCPACK erhielt und das Onboarding abschließen konnte.
Abhilfe: Implementieren Sie eine strikte Lifecycle-Management-Richtlinie für die AP-Firmware. Vermeiden Sie es, brandneue Firmware-Releases direkt in Produktionsumgebungen bereitzustellen. Richten Sie eine Staging-Umgebung ein, die High-Density-Bedingungen simuliert, und verfolgen Sie die Versionshinweise der Hersteller sowie Community-Foren aufmerksam im Hinblick auf bekannte DHCP-bezogene Fehler. Wenn die Fehlerbehebung zeigt, dass DHCPDISCOVER-Pakete vom Client gesendet, aber nie am kabelgebundenen Uplink-Port des APs registriert werden, liegt der Verdacht nahe, dass ein AP-Bridging-Fehler vorliegt.
10. Aggressives Client-Roaming und Layer-3-Grenzen
Der Mechanismus: Wenn sich ein Wireless-Client von einem AP zu einem anderen bewegt (roamt), muss er seine Netzwerksitzung aufrechterhalten. Wenn das Roaming eine Layer-3-Grenze überschreitet (wodurch der Client in ein anderes Subnetz verschoben wird), muss der Client eine neue IP-Adresse beziehen. Wenn das Betriebssystem des Clients oder das Wireless-Netzwerk diesen Übergang nicht reibungslos bewältigt, versucht der Client, seine alte IP-Adresse im neuen Subnetz zu verwenden, was zu Verbindungs-Timeouts und Fehlern bei der DHCP-Neuverhandlung führt.
Der High-Density-Kontext: High-Density-Veranstaltungsorte erfordern Hunderte von APs, um eine ausreichende Abdeckung zu gewährleisten. Die Clients sind ständig in Bewegung – beispielsweise Hotelgäste, die von ihren Zimmern zur Konferenzhalle gehen, oder Einzelhandelskunden, die sich durch ein Einkaufszentrum bewegen [7]. Wenn die Netzwerkarchitektur verschiedene physische Bereiche des Standorts unterschiedlichen Subnetzen zuordnet, tritt eine große Anzahl von Layer-3-Roams auf, was den DHCP-Server mit schnellen Release- und Request-Ereignissen überlastet.
Abhilfe: Gestalten Sie High-Density-Wireless-Netzwerke mit einer flachen Layer-2-Architektur über die gesamte Client-SSID hinweg oder implementieren Sie Wireless-Controller-basiertes Tunneling (wie GRE oder CAPWAP) [8]. Das Tunneling stellt sicher, dass der Traffic eines Clients immer an seinen ursprünglichen Home-Controller und sein VLAN angebunden bleibt, unabhängig davon, zu welchem physischen AP er roamt. Dadurch werden Layer-3-Roaming-Ereignisse und der damit verbundene DHCP-Overhead vollständig eliminiert.
Implementierungsleitfaden
Um DHCP-Timeouts systematisch zu eliminieren, müssen Netzwerkarchitekten von der reaktiven Fehlerbehebung zu einer proaktiven, standardisierten Architektur übergehen. Folgen Sie dieser Schritt-für-Schritt-Anleitung, um Ihre DHCP-Infrastruktur abzusichern.
Schritt 1: Subnetz-Dimensionierung und CIDR-Architektur
Verwenden Sie niemals Standard-/24-Subnetze für High-Density-Gästemetze. Berechnen Sie Ihren IP-Bedarf basierend auf der Spitzenkapazität zuzüglich eines Puffers von 50 %, um Benutzer mit mehreren Geräten und temporäre Fluktuationen zu berücksichtigen.
| Subnetzmaske | CIDR | Verwendbare IP-Adressen | Bester Anwendungsfall |
|---|---|---|---|
255.255.255.0 |
/24 |
254 | Verwaltungspersonal, Drucker, Back-of-House-IoT |
255.255.254.0 |
/23 |
510 | Kleine Boutique-Hotels, lokale Einzelhandelsgeschäfte |
255.255.252.0 |
/22 |
1.022 | Große Hotels, hochfrequentierte Konferenzräume, Schulcampus |
255.255.248.0 |
/21 |
2.046 | Große Messehallen, Einkaufszentren, öffentliche Plätze |
255.255.240.0 |
/20 |
4.094 | Stadien, Arenen, riesige Kongresszentren |
Schritt 2: Optimierung der DHCP-Lease-Times
Konfigurieren Sie Ihren DHCP-Server so, dass er die Lease-Zeiten basierend auf dem Benutzerverhalten des jeweiligen Netzwerksegments anpasst:
Gast-WiFi SSID (Hohe Fluktuation) -> Lease-Zeit: 30 bis 60 Minuten
Mitarbeiter-SSID (Stabil) -> Lease-Zeit: 8 bis 12 Stunden
Veranstaltungsort-IoT & Infra. -> Lease-Zeit: 7 Tage (oder statische Reservierung)
Hinweis: Das Verkürzen der Lease-Zeiten erhöht die Häufigkeit von DHCP-Erneuerungsanfragen (die bei 50 % der Lease-Dauer auftreten, auch bekannt als T1) [9]. Stellen Sie sicher, dass Ihre DHCP-Server-Hardware über ausreichend CPU- und I/O-Leistung verfügt, um die erhöhte Anfragerate zu bewältigen.
Schritt 3: Konfiguration von DHCP-Relay-Agents auf Layer-3-Switchen
Geben Sie bei der Konfiguration von DHCP-Relay-Agents immer redundante Helper-Adressen an, die auf unabhängige DHCP-Server verweisen. Unten finden Sie eine standardmäßige, herstellerunabhängige Konfigurationsvorlage für ein Cisco-iOS-Layer-3-Switch-Interface:
interface Vlan30
description High_Density_Guest_WiFi
ip address 192.168.30.1 255.255.252.0
ip helper-address 10.10.10.10 # Primärer DHCP-Server
ip helper-address 10.10.10.11 # Sekundärer DHCP-Server
ip dhcp relay information option # Option 82 für Standortverfolgung einfügen
no shutdown
Schritt 4: Härtung der Layer-2-Sicherheit mit DHCP Snooping
Verhindern Sie rogue DHCP-Server und mindern Sie DHCP-Starvation-Angriffe ab, indem Sie DHCP Snooping in Ihrer gesamten Switching-Infrastruktur aktivieren. Unten finden Sie eine Konfigurationsvorlage für einen Edge-Access-Switch:
# DHCP Snooping global aktivieren
ip dhcp snooping
# DHCP Snooping für spezifische Client-VLANs aktivieren
ip dhcp snooping vlan 10,20,30
# Uplink-Port zum Core-Switch/DHCP-Server als TRUSTED konfigurieren
interface GigabitEthernet1/0/48
description UPLINK_TO_CORE
ip dhcp snooping trust
# Client-seitige Ports als UNTRUSTED konfigurieren und DHCP-Paketrate begrenzen, um Starvation-Angriffe zu verhindern
interface range GigabitEthernet1/0/1 - 47
description CLIENT_ACCESS_PORTS
ip dhcp snooping limit rate 15
Best Practices
Um ein stabiles, leistungsstarkes drahtloses Netzwerk aufrechtzuerhalten, integrieren Sie diese branchenüblichen Best Practices in Ihre Betriebshandbücher:
1. Implementieren Sie DHCP Option 82 (Relay Agent Information Option)
DHCP Option 82 ermöglicht es dem Relay-Agenten, schaltungsspezifische Informationen (wie die Switch-Port-ID oder die AP-MAC-Adresse) in die DHCP-Anfrage einzufügen, bevor diese an den Server weitergeleitet wird [10]. Dies ermöglicht es dem DHCP-Server, hochgradig granulare IP-Zuweisungsrichtlinien basierend auf dem physischen Standort des Clients innerhalb des Veranstaltungsorts durchzusetzen. Beispielsweise kann ein Hotel Clients im Konferenzzentrum andere IP-Pools oder DNS-Einstellungen zuweisen als Clients in den Gästezimmern, was die Pool-Nutzung optimiert.
2. ARP- und DHCP-Broadcast-zu-Unicast-Konvertierung aktivieren
Konfigurieren Sie Ihren Wireless LAN Controller (WLC) oder Ihre Cloud-verwalteten APs so, dass Layer-2-Broadcast-ARP- und DHCP-Pakete abgefangen und vor der Übertragung über die Luft in Unicast-Frames konvertiert werden. Da Unicast-Frames mit der maximal unterstützten Datenrate des Clients übertragen werden (und nicht mit der niedrigsten vorgeschriebenen Broadcast-Rate), reduziert diese einfache Konfigurationsänderung den RF-Sendezeitverbrauch drastisch und verbessert die DHCP-Zuverlässigkeit in Umgebungen mit hoher Dichte.
3. Etablieren Sie eine proaktive DHCP-Überwachung und -Alarmierung
Warten Sie nicht darauf, dass Benutzer Verbindungsfehler melden. Konfigurieren Sie Ihr Network Management System (NMS) oder Ihre Tools zur Überwachung des DHCP-Servers, um wichtige Kennzahlen zu verfolgen und sofortige Alarme auszulösen:
- Pool-Auslastung: Lösen Sie bei 75 % Auslastung eine Warnung und bei 85 % einen kritischen Alarm aus.
- DHCP-Anforderungsrate: Überwachen Sie plötzliche Spitzen bei den Anforderungen, die auf einen Broadcast-Storm, eine Roaming-Schleife oder einen DHCP-Starvation-Angriff hindeuten können.
- Verteilung des Lease-Ablaufs: Stellen Sie sicher, dass Leases reibungslos ablaufen und die Datenbank IP-Adressen aktiv zurückfordert.
Fehlerbehebung & Risikominderung
Wenn ein DHCP-Timeout vermutet wird, folgen Sie diesem systematischen Diagnose-Workflow, um die Fehlerquelle schnell zu isolieren und Betriebsunterbrechungen zu minimieren.
[Client assoziiert mit AP]
│
▼
[Pakete auf Client erfassen] ───► Wird DHCPDISCOVER gesendet?
│ ├── NEIN: Client OS/Treiber-Problem.
│ └── JA
▼
[Pakete auf Switch erfassen] ───► Kommt DHCPDISCOVER am Switch an?
│ ├── NEIN: AP-Bridging/VLAN-Tagging-Problem.
│ └── JA
▼
[Pakete auf Server erfassen] ───► Kommt DHCPDISCOVER am Server an?
│ ├── NEIN: Relay-Agent / Routing / Firewall-Problem.
│ └── JA
▼
[Server-Logs prüfen] ───────────► Wird DHCPOFFER gesendet?
├── NEIN: Pool erschöpft / Bereich inaktiv.
└── JA: Rückweg blockiert (VLAN/Routing).
Wichtige Befehle zur Fehlerbehebung
Um den DHCP-Status zu überprüfen und Fehler auf aktiven Netzwerkgeräten zu diagnostizieren, verwenden Sie die folgenden Befehle:
Cisco IOS (DHCP-Server oder Relay)
# DHCP-Pool-Auslastung und freie Adressen anzeigen
show ip dhcp pool
# Aktive IP-Adressbindungen anzeigen
show ip dhcp binding
# DHCP-Serverstatistiken überwachen (Anzahl der Discover, Request, Ack)
show ip dhcp server statistics
# DHCP-Konfliktdatenbank anzeigen (IPs, die aufgrund von Konflikten als fehlerhaft markiert sind)
show ip dhcp conflict
Linux (DHCP-Server oder Client)
# Live-DHCP-Client-Lease-Anforderungen auf einem Linux-Client anzeigen
sudo dhclient -v wlan0
# DHCP-Datenverkehr (UDP-Ports 67 und 68) auf einer bestimmten Schnittstelle erfassen
sudo tcpdump -i eth0 -n -vv 'udp and (port 67 or port 68)'
# dnsmasq DHCP-Lease-Datenbank prüfen
cat /var/lib/misc/dnsmasq.leases
Windows (DHCP-Client)
# Release current IP address
ipconfig /release
# Renew IP address (initiates a new DHCP handshake)
ipconfig /renew
ROI & Business Impact
Die Investition in eine hochgradig resiliente, gut strukturierte DHCP-Infrastruktur ist nicht nur eine technische Notwendigkeit – sie ist ein entscheidender Business-Enabler, der sich direkt auf das Betriebsergebnis und die betriebliche Effizienz auswirkt.
Quantifizierung des Geschäftswerts eines nahtlosen Onboardings
- Verbessertes Gästeerlebnis und Markenloyalität: Im Gastgewerbe und in der Veranstaltungsbranche ist die drahtlose Konnektivität ein Haupttreiber für die Gästezufriedenheit. Ein Gast, der auf Probleme beim Onboarding stößt, hinterlässt mit hoher Wahrscheinlichkeit negative Bewertungen, was sich direkt auf die Buchungsraten auswirkt. Die Eliminierung von DHCP-Timeouts sorgt für einen reibungslosen ersten Eindruck.
- Maximierung des ROI von Guest WiFi Marketing: Für Einzelhandels- und Unterhaltungsstandorte ist Guest WiFi ein leistungsstarker Marketingkanal. Durch die Gewährleistung einer 100 % erfolgreichen Onboarding-Rate können Marketingteams mehr First-Party-Daten (wie E-Mails, Demografie und Besucherströme) über WiFi Analytics erfassen, was hochgradig zielgerichtete Kampagnen ermöglicht und den Customer Lifetime Value steigert.
- Reduzierung des IT-Support-Overheads: DHCP-bezogene Tickets („Verbindung zum WiFi nicht möglich“, „IP-Adressen-Fehler“) gehören zu den häufigsten und zeitaufwendigsten Anfragen an IT-Helpdesks. Durch die Implementierung von DHCP-Redundanz, die richtige Dimensionierung von Pools und den Einsatz von DHCP-Snooping können Unternehmen drahtlosbezogene Support-Tickets um bis zu 40 % reduzieren. So kann sich das IT-Personal auf strategische Initiativen anstatt auf grundlegende Fehlerbehebung konzentrieren.
- Sicherstellung der Einhaltung gesetzlicher Vorschriften und der Sicherheit: Die Implementierung von DHCP-Snooping und die Eindämmung von Rogue-DHCP-Servern unterstützen direkt die Einhaltung wichtiger Sicherheitsstandards wie PCI DSS (für Zahlungsumgebungen im Einzelhandel) und GDPR (durch die Absicherung von Gästedatennetzen). Eine sichere, gut dokumentierte DHCP-Architektur minimiert das Risiko kostspieliger Datenpannen und behördlicher Geldstrafen.
Business Impact Summary Table
| Metrik | Vor der Optimierung | Nach der Optimierung | Business Impact |
|---|---|---|---|
| DHCP-Timeout-Rate | 8,5 % (Während der Hauptverkehrszeiten) | < 0,1 % | Nahtloses Onboarding der Nutzer, Eliminierung von Verbindungsbeschwerden |
| Mittlere Zeit bis zur Lösung (MTTR) | 45 Minuten | < 5 Minuten | Schnelle Fehlerbehebung durch dokumentiertes VLAN/Scope-Mapping |
| Guest WiFi Opt-In-Rate | 62 % | 88 % | Erhöhtes Wachstum der Marketing-Datenbank, reichhaltigere Datenerfassung |
| IT-Support-Ticket-Volumen | Hoch (DHCP/IP-Fehler) | Vernachlässigbar | 40 % Reduzierung der helpdesk-Tickets im Bereich Wireless |
References
- IETF RFC 2131 - Dynamic Host Configuration Protocol
- IEEE 802.11-2020 - Wireless LAN Medium Access Control and Physical Layer Specifications
- Optimierung der WiFi-DHCP-Lease-Zeiten für mobile Geräte
- IETF RFC 3046 - DHCP-Relay-Agent-Informationsoption
- IETF RFC 8156 - DHCPv4-Failover-Protokoll
- Cisco Systems - Konfiguration von DHCP Snooping
- Warum Stadion-WiFi ins Stocken gerät (und wie man es behebt)
- HPE Aruba Networking - Wi-Fi-Design- und Bereitstellungshandbuch für große öffentliche Veranstaltungsorte
- Fehlerbehebung bei DHCP-Problemen in WiFi-Netzwerken
- IETF RFC 3993 - Subscriber-ID-Unteroption für DHCP-Relay-Agent-Informationsoption
Schlüsseldefinitionen
DHCP (Dynamic Host Configuration Protocol)
Ein Netzwerkverwaltungsprotokoll zur Verwendung in Internet-Protokoll-Netzwerken (IP-Netzwerken), bei dem ein DHCP-Server jedem Gerät in einem Netzwerk dynamisch eine IP-Adresse und andere Netzwerkkonfigurationsparameter zuweist, sodass diese mit anderen IP-Netzwerken kommunizieren können.
DHCP ist der entscheidende erste Schritt beim Onboarding im Wireless-Netzwerk. Schlägt dieser fehl, können Clients auf keinerlei Netzwerkressourcen zugreifen, einschließlich der Gast-Portale.
DORA-Prozess
Die standardmäßige vierteilige Nachrichtensequenz, die zwischen einem DHCP-Client und einem DHCP-Server ausgetauscht wird, um das Leasing einer IP-Adresse auszuhandeln: DHCPDISCOVER, DHCPOFFER, DHCPREQUEST und DHCPACK.
Das Verständnis der DORA-Sequenz ist entscheidend für die Diagnose, an welcher Stelle ein DHCP-Handshake während der Netzwerk-Fehlerbehebung fehlschlägt.
DHCP Relay Agent
Jeder Host oder jedes Netzwerkgerät (typischerweise ein Layer-3-Switch oder Router), das DHCP-Pakete zwischen Clients und Servern weiterleitet, wenn sich diese in unterschiedlichen Subnetzen oder VLANs befinden.
Relay Agents sind in segmentierten Unternehmensnetzwerken erforderlich, um DHCP-Dienste zu zentralisieren und zu verhindern, dass Broadcast-Traffic Router-Grenzen überschreitet.
DHCP Snooping
Eine in Managed Switches integrierte Layer-2-Sicherheitsfunktion, die nicht vertrauenswürdige DHCP-Nachrichten filtert und eine Bindungsdatenbank vertrauenswürdiger MAC-zu-IP-Zuordnungen aufbaut.
DHCP Snooping ist die primäre Verteidigung gegen unbefugte DHCP-Server und Man-in-the-Middle-Angriffe in Wireless-Netzwerken von Unternehmen.
Erschöpfung des IP-Pools
Ein Zustand, der eintritt, wenn alle verfügbaren IP-Adressen innerhalb des konfigurierten Bereichs eines DHCP-Servers vergeben wurden, sodass für neue Clients keine Adressen mehr zur Verfügung stehen.
Die Erschöpfung des IP-Pools ist die Hauptursache für DHCP-Timeouts an Standorten mit hoher Benutzerdichte. Sie wird durch die Anpassung der Scope-Größen oder die Verkürzung der Lease-Zeiten behoben.
DHCP Lease Time
Die Zeitspanne, für die ein DHCP-Server einer bestimmten Client-Schnittstelle eine IP-Adresse zuweist, bevor der Client eine Verlängerung des Leases anfordern muss.
Die Optimierung der Lease-Zeiten basierend auf dem Nutzerverhalten (kurz für Gastnetzwerke, länger für Mitarbeiter) ist entscheidend, um die Effizienz des IP-Pools aufrechtzuerhalten.
Rogue DHCP Server
Ein nicht autorisierter DHCP-Server, der mit einem Netzwerk verbunden ist und ungültige oder schädliche IP-Konfigurationen an Clients verteilt, was zu Konnektivitätsproblemen und Sicherheitsrisiken führt.
Rogue-Server kommen häufig an offenen, öffentlichen Standorten vor und werden durch die Aktivierung von DHCP Snooping auf den Access-Switches neutralisiert.
Broadcast-Unterdrückung
Eine Netzwerkkonfigurationstechnik, die die Rate des Broadcast- und Multicast-Traffics auf einem VLAN- oder Switch-Port begrenzt, um Netzwerküberlastungen und Broadcast-Stürme zu verhindern.
Die Broadcast-Unterdrückung ist in Wireless-Netzwerken mit hoher Dichte von entscheidender Bedeutung, um die RF-Sendezeit zu schonen und sicherzustellen, dass kritische DHCP-Pakete nicht verzögert werden.
Ausgearbeitete Beispiele
A high-density conference centre with a main plenary hall designed to seat 2,500 attendees is experiencing massive WiFi onboarding failures during the opening keynote. Attendees report that their devices are stuck on 'Obtaining IP address' for several minutes, and those who do connect are frequently disconnected when moving between the plenary hall and the exhibition area. The current network configuration uses a single client VLAN mapped to a standard `/24` subnet with a 24-hour DHCP lease time, served by a single core router. How should this network be re-architected to eliminate these failures?
To resolve these onboarding failures, the network architecture must be redesigned to handle high-density transient client behavior. Follow this multi-step remediation workflow:
Expand the IP Address Space (Subnet Sizing): Replace the standard
/24subnet (which only provides 254 IP addresses) with a/21subnet (providing 2,046 usable IP addresses) or implement a multi-VLAN pool. This ensures that the IP pool is sufficiently sized to handle 2,500 concurrent attendees, many of whom will carry multiple connected devices (average of 1.5 devices per attendee = 3,750 required IPs). If a single flat/20subnet (4,094 IPs) is used, it will easily accommodate the entire event capacity.Optimize DHCP Lease Times: Reduce the DHCP lease time from 24 hours to 45 minutes on the guest wireless network. Since conference attendees are highly transient and move in and out of the plenary hall, a short lease time ensures that IP addresses are rapidly reclaimed from devices that have left the area, preventing artificial pool exhaustion.
Deploy Redundant DHCP Servers: Eliminate the single point of failure by deploying a redundant DHCP server pair. Configure Windows Server DHCP Failover in Load Balance mode (50/50 split) across two independent virtual machines, or use a dedicated high-availability DHCP appliance. This ensures that if one server or network path fails, the remaining server can handle the entire request load.
Implement Layer 2 Broadcast Suppression and DHCP Proxy: Enable broadcast suppression on the wireless controller, limiting broadcast traffic to 100 packets per second. Enable DHCP Proxy on the access points to convert broadcast
DHCPOFFERandDHCPACKmessages into unicast frames. This drastically reduces wireless airtime consumption and prevents packet collisions.Configure DHCP Snooping and ARP Validation: Enable DHCP snooping on all access switches to protect the network from rogue DHCP servers and prevent DHCP starvation attacks. Limit the DHCP packet rate on client-facing ports to 15 packets per second.
A 500-room luxury hotel is deploying a new guest SSID across its entire property. The network team has created a new guest VLAN (VLAN 50) and configured a central Windows DHCP server with a corresponding `/22` scope. However, during testing, devices associated with the guest SSID in the hotel rooms are failing to obtain an IP address and are timing out, whereas devices connected directly to the wired ports in the administrative offices (VLAN 10) are obtaining IP addresses instantly. What is the most likely cause of this issue, and how should it be diagnosed and resolved?
The fact that wired clients on VLAN 10 are obtaining IP addresses while wireless clients on VLAN 50 are timing out indicates that the issue is specific to VLAN 50's path or configuration. The most likely cause is a missing or misconfigured DHCP Relay Agent (IP Helper) on the Layer 3 switch interface for VLAN 50, or a missing VLAN tag along the trunk path between the Access Points and the core switch. Follow this diagnostic and resolution workflow:
Verify DHCP Relay Agent Configuration: Log in to the core Layer 3 switch (or gateway) and inspect the configuration for the VLAN 50 interface. Ensure that the
ip helper-addresscommand is present and points to the correct IP address of the Windows DHCP server. If the command is missing, the switch will not forward the client's broadcastDHCPDISCOVERpackets to the DHCP server.Check VLAN Trunking End-to-End: Verify that VLAN 50 is tagged on all switch ports along the path from the APs to the core switch. Use commands like
show interfaces trunkon Cisco switches to confirm that VLAN 50 is allowed and active on all trunk links. If VLAN 50 is missing from even a single trunk port, client DHCP broadcasts will be dropped before reaching the Layer 3 switch.Perform Packet Captures: To isolate the failure point, perform simultaneous packet captures at three locations:
- On the wireless client (using Wireshark or native OS tools) to confirm that
DHCPDISCOVERbroadcasts are being sent. - On the Layer 3 switch interface for VLAN 50 to confirm that the switch is receiving the broadcasts.
- On the DHCP server's network interface to confirm that the forwarded unicast DHCP packets are arriving.
- On the wireless client (using Wireshark or native OS tools) to confirm that
Verify DHCP Server Scope Activation: Ensure that the DHCP scope for the VLAN 50 subnet (e.g., 192.168.50.0/22) is fully created, activated, and has an active range of IP addresses that does not conflict with any static assignments.
Apply the Configuration Fix: On the core Layer 3 switch, apply the correct helper address configuration:
interface Vlan50 description Guest_WiFi_VLAN ip address 192.168.50.1 255.255.252.0 ip helper-address 10.10.10.10 # Windows DHCP Server IP no shutdown
A large shopping mall with over 150 retail stores is experiencing highly intermittent WiFi connection drops. The IT team reports that some shoppers connect instantly and browse without issue, while others in the same location are stuck on 'Obtaining IP address' or receive a 'No Internet Connection' warning. A review of the DHCP server logs shows thousands of active leases, but also a high volume of 'DHCP Conflict' errors and several instances where the server is responding to clients with a `DHCPNAK` (Negative Acknowledgement). How should this issue be investigated and resolved?
The presence of 'DHCP Conflict' errors and DHCPNAK responses in the server logs strongly suggests the presence of a rogue DHCP server on the network or an IP address conflict caused by static assignments within the DHCP range. Follow this systematic investigation and remediation workflow:
Isolate and Detect the Rogue DHCP Server: Use DHCP snooping database logs on your access switches to identify unauthorized DHCP server activity. Run the following command on your core and access switches to view any detected conflicts or untrusted DHCP packets:
show ip dhcp snooping database show ip dhcp conflictThe conflict database will list the MAC addresses of devices that have responded to ARP probes for IPs that the DHCP server was attempting to assign, or devices that are actively handing out unauthorized leases.
Enable DHCP Snooping Globally and on Client VLANs: To immediately neutralize any rogue DHCP servers, enable DHCP snooping on all switches. Configure all client-facing ports as untrusted, and only trust the specific ports connected to your legitimate DHCP servers or core trunk links. This ensures that any unauthorized
DHCPOFFERorDHCPACKpackets are dropped at the switch port before they can reach other clients.Configure ARP Inspection (DAI): To prevent clients from using spoofed IP addresses or causing IP conflicts, enable Dynamic ARP Inspection (DAI) on the client VLANs. DAI uses the DHCP snooping binding database to validate ARP packets, dropping any packets with invalid MAC-to-IP mappings:
ip arp inspection vlan 10,20,30Exclude Static IPs from the DHCP Pool: Ensure that any static IP addresses assigned to infrastructure devices (such as printers, APs, or digital signage) are explicitly excluded from the DHCP scope range on the server to prevent the server from accidentally offering those IPs to clients.
Deploy Port Security and 802.1X: For wired ports in retail stores or public areas, implement Port Security to limit the number of MAC addresses allowed on a port, or deploy 802.1X authentication to prevent unauthorized devices from connecting to the physical network fabric.
Übungsfragen
Q1. Ein IT-Manager in einem großen Einkaufszentrum stellt fest, dass während der Haupteinkaufszeiten die Gast-WiFi-Verbindungen häufig abbrechen. Das DHCP-Server-Protokoll ist mit der Fehlermeldung "DHCP Scope Full" überlastet. Das aktuelle Gast-VLAN ist mit einer `/23`-Subnetzmaske und einer Standard-Lease-Zeit von 24 Stunden konfiguriert. Welches sind die zwei unmittelbarsten und effektivsten Konfigurationsänderungen, die der Manager zur Behebung dieses Problems vornehmen sollte, und warum?
Hinweis: Berücksichtigen Sie das Verhältnis zwischen Subnetzgröße, Verweildauer der Clients und der Freigabe von IP-Adressen.
Musterlösung anzeigen
Der Manager sollte die folgenden zwei sofortigen Konfigurationsänderungen vornehmen:
Die DHCP-Lease-Zeit verkürzen: Reduzieren Sie die Lease-Zeit von 24 Stunden auf 30 oder 45 Minuten. Da Besucher von Einkaufszentren sehr flüchtig sind (die typische Verweildauer beträgt 1-2 Stunden), führt eine 24-stündige Lease-Zeit dazu, dass der DHCP-Server IP-Adressen noch lange nach dem Verlassen der Gäste blockiert. Eine Verkürzung der Lease-Zeit sorgt dafür, dass IP-Adressen schnell wieder freigegeben und für neue Einkäufer verfügbar gemacht werden. Dadurch wird die Kapazität des bestehenden Adresspools effektiv vervielfacht, ohne dass die Subnetzstruktur geändert werden muss.
Den Subnetzbereich erweitern (CIDR-Größe): Erweitern Sie das Gast-VLAN-Subnetz von einem
/23(bietet 510 nutzbare IP-Adressen) auf ein/21(bietet 2.046 nutzbare IP-Adressen) oder ein/20(bietet 4.094 nutzbare IP-Adressen). Ein/23-Subnetz ist für ein großes Einkaufszentrum während der Stoßzeiten viel zu klein, insbesondere wenn man bedenkt, dass viele Besucher mehrere vernetzte Geräte (Smartphones, Wearables, Tablets) bei sich tragen. Die Erweiterung des Bereichs stellt sicher, dass genügend IP-Adressen zur Verfügung stehen, um die maximale Last der gleichzeitig aktiven Geräte zu bewältigen.
Diese beiden Änderungen greifen ineinander: Die Subnetzerweiterung erhöht die absolute Poolkapazität, während die Verkürzung der Lease-Zeit für maximale Effizienz bei der Wiederverwendung von Adressen sorgt, wodurch "DHCP Scope Full"-Fehler vollständig eliminiert werden.
Q2. Ein Netzwerktechniker behebt Fehler bei einer neu bereitgestellten Gast-SSID in einem Hotel. Wireless-Clients verbinden sich erfolgreich mit dem AP, erhalten jedoch keine IP-Adresse und laufen nach einigen Sekunden in ein Timeout. Ein Packet Capture am Switch-Port des APs zeigt, dass `DHCPDISCOVER`-Broadcasts in den Switch eingehen, aber ein Capture an der Netzwerkschnittstelle des zentralen DHCP-Servers zeigt keine eingehenden Pakete aus dem Gast-Subnetz des Hotels. Der DHCP-Server befindet sich in einem anderen Subnetz (10.10.10.0/24) als die drahtlosen Gast-Clients (192.168.50.0/22). Welche Konfiguration fehlt, auf welchem Gerät muss sie angewendet werden und wie lautet der genaue Befehl dafür?
Hinweis: Da sich der DHCP-Server in einem anderen Subnetz als die Clients befindet, muss ein Layer-3-Gerät den Broadcast-Traffic weiterleiten.
Musterlösung anzeigen
Die fehlende Konfiguration ist der DHCP Relay Agent (IP Helper). Da es sich bei DHCP-Discovery-Nachrichten um Layer-2-Broadcasts handelt, können sie den Router oder die Layer-3-Grenze zwischen dem Client-Gast-Subnetz (192.168.50.0/22) und dem DHCP-Server-Subnetz (10.10.10.0/24) nicht überschreiten. Ohne einen Relay Agent verwirft der Switch oder Router die Broadcast-Pakete, sodass sie den Server nicht erreichen.
Diese Konfiguration muss auf dem Layer-3-Switch oder Security Gateway angewendet werden, der als Standard-Gateway für das Gast-VLAN (VLAN 50) fungiert.
Ausgehend von einem Cisco IOS Layer-3-Switch muss der Techniker den Befehl ip helper-address auf der Schnittstelle des VLAN 50 anwenden und auf die IP-Adresse des zentralen DHCP-Servers verweisen (z. B. 10.10.10.10):
interface Vlan50
description Guest_WiFi_Gateway
ip address 192.168.50.1 255.255.252.0
ip helper-address 10.10.10.10
no shutdown
Dieser Befehl weist den Switch an, DHCP-Broadcasts auf VLAN 50 abzufangen, sie in Layer-3-Unicast-Pakete mit der Quell-IP des VLAN-50-Gateways (192.168.50.1) umzuwandeln und sie direkt an den DHCP-Server unter 10.10.10.10 weiterzuleiten. Der Server verwendet dann die Gateway-IP, um den richtigen Bereich auszuwählen und eine IP anzubieten.
Q3. Ein Stadion-Netzwerkarchitekt entwirft ein Wireless-Netzwerk für 50.000 gleichzeitige Fans. Um den Broadcast-Traffic und die Belegung der RF-Sendezeit zu minimieren, möchte der Architekt eine Broadcast-Unterdrückung implementieren und DHCP-Broadcasts in Unicast umwandeln. Einige Nachwuchsingenieure äußern jedoch die Besorgnis, dass die Umwandlung von DHCP-Broadcasts in Unicast das DHCP-Protokoll beeinträchtigt, da die Clients noch keine IP-Adresse besitzen, um Unicast-Pakete zu empfangen. Wie sollte der Architekt den technischen Mechanismus der Broadcast-zu-Unicast-Konvertierung erklären, um diese Bedenken auszuräumen?
Hinweis: Überlegen Sie, wie der Access Point Layer-2-Frames überbrückt und wie die MAC-Adresse des Clients im 802.11-Header verwendet wird.
Musterlösung anzeigen
Der Architekt sollte erklären, dass die Konvertierung von DHCP-Broadcasts in Unicast das DHCP-Protokoll nicht beeinträchtigt, da der Access Point (AP) auf Layer 2 arbeitet und Frames direkt an die physische MAC-Adresse des Clients richten kann, selbst wenn der Client noch keine IP-Adresse besitzt.
Hier ist der technische Ablauf:
Die MAC-Adresse des Clients ist bekannt: Während der ersten Verbindungsphase stellt der Client eine sichere Layer-2-Verbindung mit dem AP her. Der AP kennt die eindeutige MAC-Adresse des Clients und ordnet sie einem bestimmten virtuellen Port und einer Funkschnittstelle zu.
Der AP fängt den Broadcast ab: Wenn der DHCP-Server ein
DHCPOFFERoderDHCPACKals Layer-2-Broadcast (Ziel-MACFF:FF:FF:FF:FF:FF) sendet, fängt der AP dieses Paket an seiner kabelgebundenen Schnittstelle ab.Konvertierung in Unicast: Anstatt das Paket als Broadcast-Frame über die Luft zu übertragen (was alle Clients auf dem Kanal dazu zwingen würde, aufzuwachen und das Paket mit der niedrigsten vorgeschriebenen Datenrate zu verarbeiten), modifiziert der AP den 802.11 MAC-Header. Er ändert die Ziel-MAC-Adresse von der Broadcast-Adresse in die spezifische Unicast-MAC-Adresse des Clients (die er aus dem Hardware-Adressfeld des Clients im DHCP-Paket,
chaddr, extrahiert hat).Hochgeschwindigkeitsübertragung: Da es sich bei dem Frame nun um einen Unicast-Frame handelt, kann der AP ihn mit der maximal unterstützten Datenrate des Clients übertragen (unter Nutzung von Beamforming, MIMO und höherwertiger Modulation wie QAM). Er profitiert zudem von 802.11-Layer-2-Bestätigungen (ACKs), was eine zuverlässige Zustellung garantiert.
Verarbeitung durch den Client: Die Wireless-Karte des Clients empfängt den Unicast-Frame, erkennt die eigene MAC-Adresse im 802.11-Header und leitet die Nutzdaten (das DHCP-Angebot oder -ACK) im Netzwerk-Stack weiter. Das Betriebssystem des Clients verarbeitet die DHCP-Nutzdaten ganz normal und merkt nicht, dass der Frame in der Luft von Broadcast in Unicast umgewandelt wurde.
Diese Erklärung verdeutlicht, dass die Broadcast-zu-Unicast-Konvertierung eine Layer-2-Optimierung ist, die die 802.11-MAC-Schicht nutzt, um RF-Sendezeit zu sparen, ohne die Layer-3-Nutzdaten des DHCP-Protokolls zu verändern.
Weiterlesen in dieser Reihe
Verwendung von Packet Capture (PCAP) zur Diagnose langsamer WiFi-Leistung
Dieser technische Leitfaden bietet IT-Managern, Netzwerkarchitekten und Leitern des Standortbetriebs eine strukturierte Methodik auf Paketebene zur Diagnose und Behebung langsamer WiFi-Leistung in Unternehmen mithilfe der Packet Capture (PCAP)-Analyse. Durch die Analyse von rohen 802.11-Frames – einschließlich Retransmissionsraten, Airtime-Auslastung und Metadaten der physikalischen Schicht – können Teams Engpässe auf der HF-Schicht präzise von kabelgebundenen oder anwendungsspezifischen Problemen isolieren. Dieser Leitfaden ist für hochfrequentierte Standorte wie Hotels, Einzelhandelsketten, Stadien und Konferenzzentren geeignet und bietet direkt umsetzbare Diagnose-Workflows, Fallstudien aus der Praxis sowie Schritte zur Konfigurationsbehebung, um Netzwerkkapazitäten zurückzugewinnen und das Gästeerlebnis zu sichern.
Fehlerbehebung bei 802.1X-Authentifizierungsfehlern (RADIUS/EAP)
Dieser Leitfaden bietet IT-Managern, Netzwerkarchitekten und Leitern des Standortbetriebs eine umfassende, praxisnahe Referenz zur Diagnose und Behebung von 802.1X-Authentifizierungsfehlern in der RADIUS- und EAP-Infrastruktur. Er deckt die gesamte Authentifizierungskette ab – von der Fehlkonfiguration des Supplicants und dem Ablauf von Zertifikaten bis hin zu nicht übereinstimmenden RADIUS Shared Secrets und Fragmentierung bei der Netzwerkübertragung – ergänzt durch Praxis-Fallbeispiele aus dem Hotel- und Gastgewerbe sowie dem Einzelhandel. Teams, die für PCI-DSS-Compliance, WPA3-Enterprise-Bereitstellungen und standortübergreifende Netzwerkzugriffskontrolle verantwortlich sind, finden hier strukturierte Diagnose-Frameworks, Implementierungs-Checklisten und Strategien zur Risikominderung, die direkt auf ihren Betrieb anwendbar sind.
Identifikation und Behebung von Co-Channel-Interferenzen (CCI)
Co-Channel-Interferenzen (CCI) sind die Hauptursache für verringerten Durchsatz und erhöhte Latenzzeiten in hochverdichteten Enterprise-WiFi-Umgebungen. Sie treten auf, wenn mehrere Access Points denselben Frequenzkanal nutzen und in den CSMA/CA-Konflikt gezwungen werden. Dieser Leitfaden bietet Netzwerkarchitekten, IT-Managern und Betriebsleitern von Veranstaltungsorten ein strukturiertes, herstellerneutrales Framework zur Identifizierung von CCI durch RF-Diagnose und -Analysen sowie zur Behebung durch Kanalplanung, Sendeleistungsoptimierung, Datenratenmanagement und physische AP-Platzierung. Die Behebung von CCI ist eine Grundvoraussetzung für die Bereitstellung von zuverlässigem Gäste-WiFi, betrieblicher Konnektivität und messbarem ROI in Hotels, Einzelhandelsketten, Stadien und öffentlichen Einrichtungen.