RADIUS Server High Availability: Active-Active vs. Active-Passive
Ein maßgeblicher technischer Leitfaden für IT-Manager und Netzwerkarchitekten zur Bewertung von RADIUS-Hochverfügbarkeitsarchitekturen. Er vergleicht Active-Active- und Active-Passive-Bereitstellungen, beschreibt die Anforderungen an die Datenbankreplikation und erklärt, wie Cloud RADIUS die Failover-Latenz für Unternehmensstandorte minimiert.
Diesen Leitfaden anhören
Podcast-Transkript ansehen
📚 Teil unserer Kernserie: Enterprise WiFi Security Guide →

Executive Summary
Für Unternehmensnetzwerke ist die Authentifizierung binär: Entweder sie funktioniert einwandfrei, oder der Geschäftsbetrieb kommt vollständig zum Erliegen. RADIUS (Remote Authentication Dial-In User Service) fungiert als kritischer Gatekeeper für IEEE 802.1X, WPA3 Enterprise und Guest WiFi Implementierungen in modernen Standorten. Im Gegensatz zu Anwendungsdiensten, die bei Überlastung kontrolliert an Leistung verlieren, blockiert ein RADIUS-Ausfall sofort den Netzwerkzugriff für Benutzer, Point-of-Sale-Terminals und betriebliche Geräte.
Dieser technische Leitfaden bewertet die Architekturmodelle für die Bereitstellung hochverfügbarer RADIUS-Infrastrukturen. Insbesondere stellt er traditionelle Active-Passive-Konfigurationen modernen Active-Active-Clustern gegenüber. Für IT-Manager, Netzwerkarchitekten und Betriebsleiter von Standorten, die hochverdichtete Umgebungen wie Retail , Hospitality und Stadien verwalten, ist das Verständnis dieser Failover-Strategien, Load-Balancing-Mechanismen und Datenbank-Replikationsanforderungen unerlässlich.
Darüber hinaus untersucht dieser Leitfaden, wie Cloud RADIUS-Plattformen die Komplexität der Hochverfügbarkeit abstrahieren und automatisches Failover sowie elastische Skalierbarkeit bieten, ohne den betrieblichen Aufwand für die Wartung redundanter On-Premise-Infrastrukturen zu verursachen. Durch die Anwendung dieser herstellerneutralen Best Practices können Engineering-Teams Authentifizierungsarchitekturen entwerfen, die Single Points of Failure eliminieren und strenge Service Level Agreements (SLAs) für die Betriebszeit erfüllen.
Technischer Deep-Dive: RADIUS-Architektur verstehen
RADIUS arbeitet als Client-Server-Protokoll über UDP und nutzt in der Regel Port 1812 für die Authentifizierung und Port 1813 für das Accounting, wie in RFC 2865 und RFC 2866 definiert. Die zustandslose Natur von UDP-Authentifizierungsanfragen ist ein struktureller Vorteil für das Design von Hochverfügbarkeit. Da jedes Access-Request-Paket alle erforderlichen Anmeldedaten und Parameter enthält, kann jeder RADIUS-Server innerhalb eines Clusters jede Anfrage unabhängig verarbeiten, ohne dass eine komplexe Zustandssynchronisierung für die Authentifizierungsphase selbst erforderlich ist.
Active-Passive-Architektur
In einer Active-Passive-Bereitstellung (oder Primary-Standby-Bereitstellung) verarbeitet ein einzelner RADIUS-Server den gesamten eingehenden Authentifizierungs- und Accounting-Verkehr. Ein sekundärer Server bleibt online, aber inaktiv. Er empfängt Datenbank-Replikations-Updates, antwortet jedoch nicht aktiv auf Network Access Devices (NADs) wie Access Points, Switches oder VPN-Gateways.
Wenn der primäre Server ausfällt, erkennt das NAD das Timeout und leitet nachfolgende Anfragen an den sekundären Server weiter. Die Failover-Erkennungszeit hängt vollständig von den Konfigurationstimern des NAD ab. Ein typisches NAD sendet eine RADIUS-Anfrage und wartet auf ein Standard-Paket-Timeout (oft zwei Sekunden). Wenn keine Antwort eingeht, wird ein neuer Versuch unternommen. Bei einer Standardkonfiguration von drei Versuchen pro Server kann das NAD bis zu sechs Sekunden warten, bevor es den primären Server als ausgefallen deklariert und ein Failover auf den sekundären Server durchführt. In Umgebungen mit drei konfigurierten Servern kann sich dieses Failover-Fenster auf bis zu achtzehn Sekunden verlängern. Für einen stark frequentierten Hospitality -Standort oder eine Retail -Umgebung, in der Transaktionen verarbeitet werden, bedeutet diese Verzögerung eine spürbare Serviceunterbrechung.
Active-Active-Architektur
Im Gegensatz dazu verteilt eine Active-Active-Architektur die Authentifizierungslast gleichzeitig auf mehrere betriebsbereite RADIUS-Server. Der Datenverkehr wird entweder über eine Round-Robin-Konfiguration auf den NADs oder über einen dedizierten Load Balancer an den Cluster geleitet.
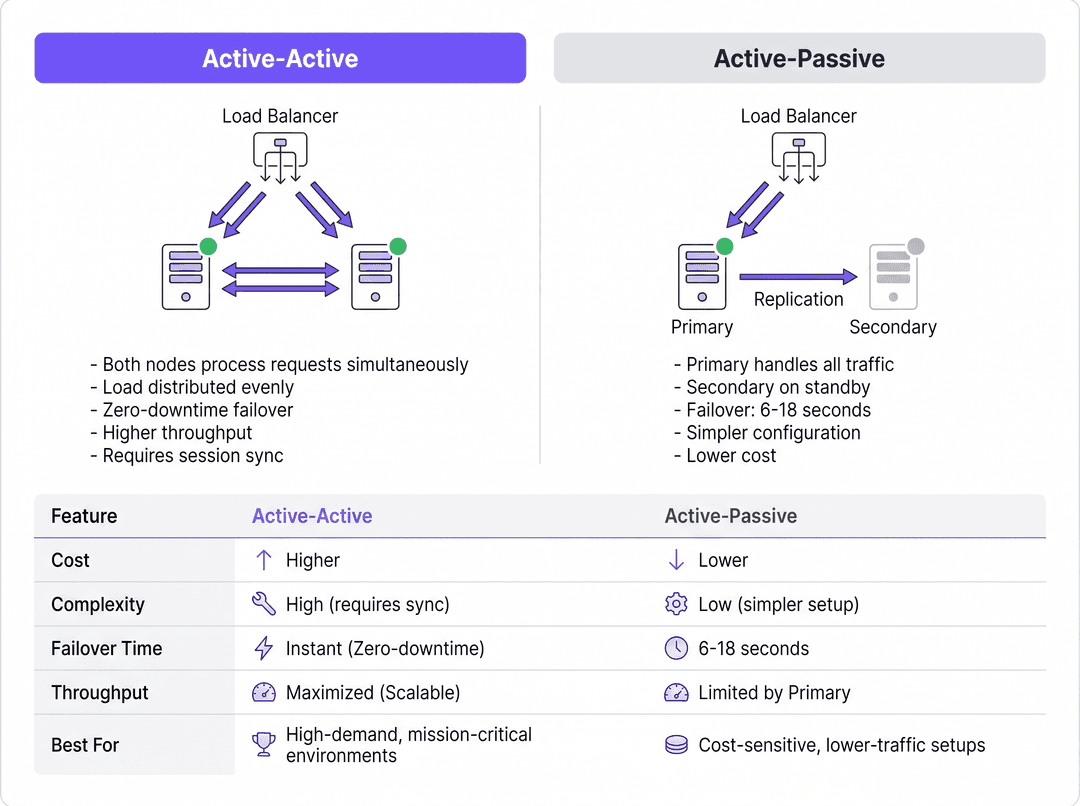
Dieses Modell eliminiert die bei Active-Passive-Setups systembedingte Verzögerung bei der Failover-Erkennung. Wenn ein Knoten ausfällt, leitet der Load Balancer (oder die NADs mittels Round-Robin) den Datenverkehr einfach nicht mehr an den nicht reagierenden Server weiter, in der Regel innerhalb von ein bis zwei Sekunden basierend auf den Health-Check-Intervallen. Die verbleibenden aktiven Knoten übernehmen den Datenverkehr sofort. Darüber hinaus lassen sich Active-Active-Cluster horizontal skalieren; um Kapazitäten für Veranstaltungen mit hoher Dichte hinzuzufügen, müssen lediglich zusätzliche Knoten im Cluster bereitgestellt werden.
Die Herausforderung der Datenbankreplikation
Während die RADIUS-Authentifizierung zustandslos ist, ist das RADIUS-Accounting von Natur aus zustandsbehaftet. Es verfolgt den Sitzungsstart (Start), die laufende Nutzung (Interim-Update) und die Beendigung (Stop). Für Standorte, die WiFi Analytics oder Abrechnungssysteme nutzen, müssen diese Accounting-Daten über alle Knoten hinweg konsistent bleiben.
Die Absicherung eines RADIUS-Clusters mit einer replizierten Datenbank (wie MySQL oder MariaDB integriert mit FreeRADIUS) ist für eine robuste Hochverfügbarkeit zwingend erforderlich. Für Active-Active-Bereitstellungen ist eine synchrone Multi-Master-Replikation – wie Galera Cluster oder MySQL NDB Cluster – erforderlich. Die synchrone Replikation stellt sicher, dass ein Accounting-Datensatz gleichzeitig auf allen Knoten geschrieben wird, was Datenverlust bei Ausfall eines Knotens verhindert. Die traditionelle asynchrone Replikation, die häufig in Active-Passive-Setups verwendet wird, führt zu Replikationsverzögerungen. Wenn der primäre Knoten ausfällt, bevor der sekundäre das Update erhält, gehen aktive Sitzungsdaten dauerhaft verloren, was gegen Compliance-Frameworks wie PCI DSS verstoßen kann.
Implementierungsleitfaden: Cloud vs. On-Premise
Die architektonische Entscheidung geht über die Frage hinaus, wie Server geclustert werden sollen; sie betrifft auch den Standort dieser Server. Für Betreiber mit mehreren Standorten führt das Backhauling des Authentifizierungsverkehrs zu einem zentralisierten On-Premise-Rechenzentrum zu WAN-Latenzzeiten und schafft einen Single Point of Failure an der WAN-Verbindung.
Cloud-RADIUS-Plattformen
Cloud-RADIUS-Dienste lösen geografische Verteilungsprobleme, indem sie die Authentifizierungsinfrastruktur über mehrere globale Verfügbarkeitszonen hinweg hosten. Wenn sich ein Benutzer an einem Filialstandort verbindet, wird die Anfrage an den nächstgelegenen Cloud-Edge-Knoten weitergeleitet, was die Latenz minimiert.
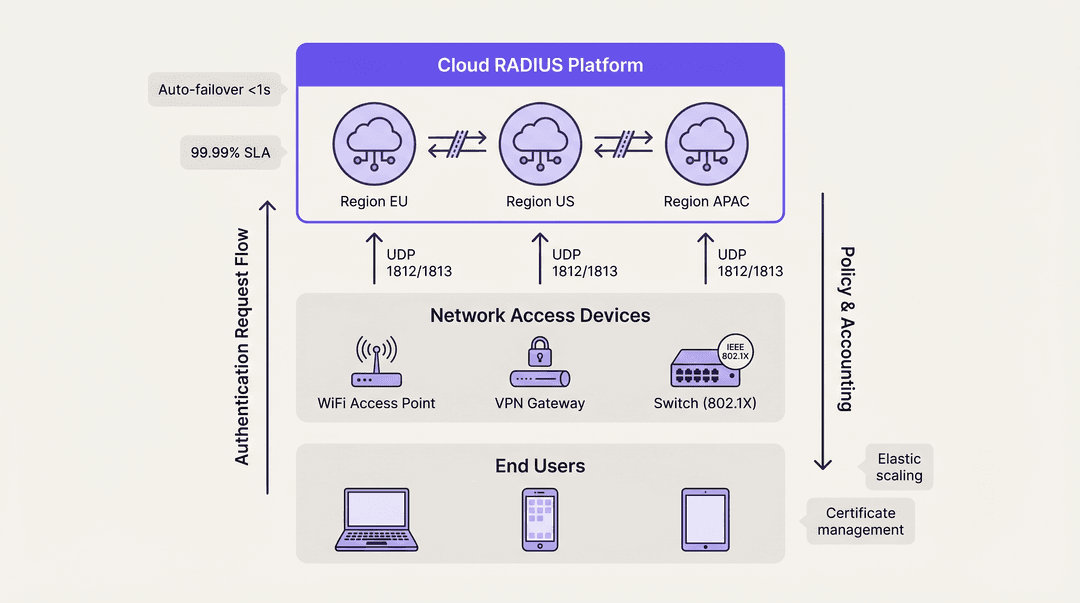
Cloud-Plattformen nutzen von Natur aus Active-Active-Architekturen. Das Failover zwischen Verfügbarkeitszonen wird automatisch durch das interne Load Balancing des Anbieters abgewickelt, wodurch die Komplexität vollständig vom Engineering-Team des Kunden ferngehalten wird. Dieses Modell bietet in der Regel SLAs von 99,99 % Betriebszeit und macht manuelle Zertifikatsverwaltung, Betriebssystem-Patching und Datenbank-Replikations-Tuning überflüssig. Für Organisationen, die Wayfinding oder Sensors über verteilte Campusse hinweg bereitstellen, gewährleistet die in der Cloud gehostete Authentifizierung eine konsistente Richtliniendurchsetzung ohne lokale Hardware-Abhängigkeiten.
Überlegungen zur On-Premise-Bereitstellung
Organisationen, die in stark regulierten Sektoren tätig sind – wie z. B. in bestimmten Bereichen des Healthcare -Sektors oder in Behördenumgebungen –, benötigen aufgrund strenger Datensouveränitätsvorgaben unter Umständen On-Premise-Bereitstellungen. In diesen Szenarien bietet die Bereitstellung eines Active-Active FreeRADIUS-Clusters mit synchroner Galera-Replikation das höchste Maß an Ausfallsicherheit.
Engineering-Teams müssen jedoch den betrieblichen Aufwand berücksichtigen. Die Verwaltung von TLS-Zertifikaten über mehrere Knoten hinweg, die Gewährleistung der Konfigurationskonsistenz und die aktive Überwachung des Zustands der Datenbankreplikation erfordern dedizierte administrative Ressourcen. Hardware-Load-Balancer müssen speziell für die Unterstützung von UDP-Verkehr mit entsprechenden RADIUS-Health-Checks konfiguriert werden, da viele Standard-Load-Balancer ausschließlich für TCP-HTTP/HTTPS-Verkehr optimiert sind.
Best Practices für RADIUS-Hochverfügbarkeit
- Verteilen statt Duplizieren: Bei Bereitstellungen mit mehr als 500 gleichzeitigen Benutzern sollten Active-Active-Architekturen gegenüber Active-Passive-Setups bevorzugt werden, um den Durchsatz zu maximieren und die Failover-Latenz zu minimieren.
- Synchrone Replikation implementieren: Schützen Sie zustandsbehaftete Accounting-Daten, indem Sie eine synchrone Multi-Master-Datenbankreplikation (z. B. Galera Cluster) anstelle von asynchronen Primary-Replica-Modellen verwenden.
- Zertifikatsvertrauen standardisieren: Stellen Sie in einem Active-Active-Cluster sicher, dass alle Knoten das identische Serverzertifikat oder Zertifikate aus exakt derselben Certificate Authority (CA)-Kette vorweisen. Abweichungen führen dazu, dass EAP-TLS- und PEAP-Handshakes während der Knotenrotation fehlschlagen.
- NAD-Timer anpassen: Optimieren Sie die RADIUS-Wiederholungs- und Timeout-Timer auf Ihren Network Access Devices. Ein Timeout von zwei Sekunden mit zwei Wiederholungsversuchen bietet ein ausgewogenes Verhältnis zwischen schneller Failover-Erkennung und der Vermeidung vorzeitiger Failovers bei geringfügigen Netzwerkengpässen.
- Ausfallszenarien testen: Behandeln Sie sekundäre Knoten wie Produktivsysteme. Simulieren Sie regelmäßig Knotenausfälle, Datenbank-Desynchronisationen und WAN-Verbindungsabbrüche, um sicherzustellen, dass automatisierte Failover-Mechanismen wie geplant funktionieren.
Fehlerbehebung & Risikominimierung
Das häufigste Ausfallszenario bei RADIUS-Hochverfügbarkeit ist die Konfigurationsabweichung (Configuration Drift). In Active-Passive-Setups aktualisieren Administratoren häufig Richtlinien oder erneuern Zertifikate auf dem primären Knoten, vernachlässigen jedoch den sekundären. Tritt ein Failover-Ereignis ein, lehnt der sekundäre Knoten legitimen Datenverkehr aufgrund abgelaufener Anmeldedaten oder veralteter Richtlinien ab.
Um dieses Risiko zu minimieren, sollten Sie Konfigurationsmanagement-Tools (wie Ansible oder Terraform) implementieren, um Änderungen symmetrisch auf allen Knoten bereitzustellen. Nutzen Sie für das Zertifikatsmanagement automatisierte Erneuerungsprotokolle (wie ACME), die so konfiguriert sind, dass sie das aktualisierte Zertifikat gleichzeitig im gesamten Cluster verteilen.
Ein weiteres erhebliches Risiko ist die Fehlkonfiguration von Load Balancern. Wenn ein Load Balancer keine Health-Checks auf Anwendungsebene durchführt (insbesondere die Überprüfung der Reaktionsfähigkeit des UDP-Ports 1812), leitet er möglicherweise weiterhin Datenverkehr an einen Knoten weiter, auf dem das Betriebssystem zwar läuft, der RADIUS-Daemon jedoch abgestürzt ist. Stellen Sie sicher, dass Health-Checks die Verfügbarkeit des RADIUS-Dienstes explizit validieren.
ROI & geschäftliche Auswirkungen
Der Return on Investment für eine robuste RADIUS-Hochverfügbarkeit bemisst sich in erster Linie an der Risikominimierung und der betrieblichen Effizienz. Authentifizierungsausfälle führen zu sofortigen Produktivitätsverlusten für Mitarbeiter und schweren Reputationsschäden bei öffentlich zugänglichen Standorten.
Durch den Übergang von manuellen Single-Server-Bereitstellungen zu automatisierten Active-Active-Architekturen (insbesondere über Cloud RADIUS) gewinnen Unternehmen erhebliche Engineering-Stunden zurück, die zuvor für die routinemäßige Wartung aufgewendet wurden. Diese betriebliche Effizienz ermöglicht es Netzwerkteams, sich auf strategische Initiativen zu konzentrieren – wie die Bereitstellung von The Core SD WAN Benefits for Modern Businesses oder die Optimierung der High-Density-Abdeckung –, anstatt Authentifizierungsfehler zu bekämpfen. Letztendlich ist eine zuverlässige Authentifizierung das Fundament, auf dem alle nachfolgenden Netzwerkdienste aufbauen.
Schlüsseldefinitionen
Aktiv-Aktiv-Architektur
Ein Hochverfügbarkeitsdesign, bei dem mehrere RADIUS-Server Authentifizierungsanfragen gleichzeitig verarbeiten, wodurch die Last verteilt und ein sofortiges Failover ohne Erkennungsverzögerungen ermöglicht wird.
Unerlässlich für hochfrequentierte Standorte (Stadien, große Einzelhandelsflächen), an denen ein einzelner Server Spitzen bei den Authentifizierungsanfragen nicht bewältigen kann.
Aktiv-Passiv-Architektur
Ein Redundanzmodell, bei dem ein primärer Server den gesamten Datenverkehr abwickelt und ein sekundärer Server im Standby-Modus inaktiv bleibt, bis der primäre Server ausfällt.
Geeignet für kleinere, kostenbewusste Implementierungen, führt jedoch zu einer Failover-Verzögerung von 6 bis 18 Sekunden, während das Network Access Device den Ausfall erkennt.
Synchrone Replikation
Eine Methode der Datenbankreplikation, bei der Daten gleichzeitig auf alle Knoten in einem Cluster geschrieben werden, bevor die Transaktion als abgeschlossen gilt.
Zwingend erforderlich für Aktiv-Aktiv-RADIUS-Accounting-Datenbanken (wie Galera Cluster), um Datenverlust zu verhindern und Compliance zu gewährleisten.
Asynchrone Replikation
Eine Methode der Datenbankreplikation, bei der der primäre Knoten die Daten aufzeichnet und sie erst später auf sekundäre Knoten kopiert, was zu einer geringfügigen Verzögerung (Lag) führt.
Wird häufig in Aktiv-Passiv-Setups verwendet, birgt jedoch das Risiko, dass kürzlich erfasste Accounting-Daten verloren gehen, wenn der primäre Knoten abrupt ausfällt.
Network Access Device (NAD)
Die Hardwarekomponente (wie ein WiFi-Access-Point, Switch oder VPN-Gateway), die im Namen des Benutzers die Authentifizierung beim RADIUS-Server anfordert.
Die internen Wiederholungs- und Timeout-Timer des NAD bestimmen, wie schnell ein Aktiv-Passiv-Failover erfolgt.
Stateless-Protokoll
Ein Kommunikationsprotokoll, das jede Anfrage als unabhängige Transaktion behandelt, die in keiner Beziehung zu vorherigen Anfragen steht.
Die RADIUS-Authentifizierung über UDP ist stateless, sodass Load Balancer jede Anfrage nahtlos an jeden aktiven Server weiterleiten können.
Konfigurationsdrift
Das Phänomen, bei dem sekundäre oder Backup-Server im Laufe der Zeit in Bezug auf Richtlinien, Updates oder Zertifikate nicht mehr mit dem primären Server synchron sind.
Die Hauptursache für Ausfälle bei Aktiv-Passiv-RADIUS-Bereitstellungen, wenn der sekundäre Knoten gezwungen ist, die Kontrolle zu übernehmen.
Cloud RADIUS
Ein verwalteter Authentifizierungsdienst, der auf einer global verteilten Cloud-Infrastruktur gehostet wird und integrierte Aktiv-Aktiv-Redundanz sowie automatische Skalierung bietet.
Ersetzt die Notwendigkeit für IT-Teams, redundante On-Premise-RADIUS-Server manuell aufzubauen, zu patchen und zu überwachen.
Ausgearbeitete Beispiele
Eine europäische Hotelgruppe verwaltet 45 Standorte in sechs Ländern. Derzeit betreibt sie an jedem Standort unabhängige virtuelle FreeRADIUS-Maschinen. Ein kürzlich abgelaufenes TLS-Zertifikat an einem Standort führte während einer großen Konferenz zu einem vollständigen Ausfall des Gäste-WiFi. Wie sollte die Authentifizierungsarchitektur neu gestaltet werden, um lokale Ausfälle zu verhindern und den Wartungsaufwand zu reduzieren?
Die Hotelgruppe sollte von lokalen FreeRADIUS-Instanzen mit nur einem Knoten auf eine zentralisierte Cloud RADIUS-Plattform mit einer Active-Active-Architektur umsteigen. Durch die Nutzung eines Cloud-Anbieters mit geografisch verteilten Edge-Knoten werden Authentifizierungsanfragen von jedem Standort an den nächstgelegenen regionalen Knoten weitergeleitet, was die Latenz minimiert. Ein zentralisiertes Richtlinienmanagement ermöglicht es dem IT-Team, Authentifizierungsregeln einmal zu definieren und global anzuwenden. Der Cloud-Anbieter übernimmt automatisch die Rotation von TLS-Zertifikaten, das Einspielen von Betriebssystem-Patches und die Datenbankreplikation.
Ein nationales Sportstadion bereitet sich auf eine Veranstaltung mit 60.000 Besuchern vor. Das aktuelle RADIUS-Setup ist eine Active-Passive-Konfiguration. Während eines Lasttests war der primäre Server bei der Verarbeitung von 8.000 Authentifizierungsanfragen pro Minute bei der Stadionöffnung völlig überlastet, was zu massiven Verbindungsverzögerungen führte, während der sekundäre Server komplett im Leerlauf blieb. Wie lässt sich diese Bereitstellung optimieren?
Das Netzwerk-Engineering-Team muss die Bereitstellung von Active-Passive auf Active-Active umstellen. Zuerst sollten die Network Access Devices (NADs) des Stadions so konfiguriert werden, dass sie ein Round-Robin-Load-Balancing über beide RADIUS-Server hinweg nutzen, was den Authentifizierungsdurchsatz sofort verdoppelt. Zweitens sollten sie einen dritten RADIUS-Knoten bereitstellen, um den nötigen Spielraum für Spitzenlasten zu schaffen. Um schließlich sicherzustellen, dass die Accounting-Daten auf allen drei aktiven Knoten konsistent bleiben, müssen sie eine synchrone Multi-Master-Datenbankreplikationslösung wie Galera Cluster implementieren.
Übungsfragen
Q1. Ihr Enterprise-Retail-Kunde benötigt eine hochverfügbare RADIUS-Lösung für seine Point-of-Sale-Terminals. Er hat strenge PCI DSS-Compliance-Anforderungen, die vorschreiben, dass bei einem Server-Failover absolut keine Accounting-Sitzungsdaten verloren gehen dürfen. Welche Datenbank-Replikationsstrategie müssen Sie für das RADIUS-Backend implementieren?
Hinweis: Berücksichtigen Sie den Unterschied zwischen Daten, die gleichzeitig geschrieben werden, und Daten, die nachträglich kopiert werden.
Musterlösung anzeigen
Sie müssen eine synchrone Replikation (wie einen Galera Cluster oder MySQL NDB Cluster) implementieren. Die synchrone Replikation stellt sicher, dass der Accounting-Datensatz gleichzeitig auf allen Knoten festgeschrieben wird, bevor die Transaktion bestätigt wird. Wenn Sie eine asynchrone Replikation verwenden würden, könnte ein Knotenausfall zum Verlust der jüngsten Transaktionen führen, die noch nicht in die sekundäre Datenbank kopiert wurden, was gegen die strengen Compliance-Anforderungen verstoßen würde.
Q2. Ein Universitäts-Campusnetzwerk nutzt ein Active-Passive-RADIUS-Setup. Studenten beschweren sich, dass es fast 20 Sekunden dauert, bis sich ihre Laptops mit dem WiFi verbinden, wenn der primäre Server gewartet wird. Die Access Points sind mit einem RADIUS-Timeout von 3 Sekunden und 5 Wiederholungsversuchen konfiguriert. Wie können Sie die Failover-Verzögerung reduzieren, ohne die Serverarchitektur zu ändern?
Hinweis: Berechnen Sie die maximale Wartezeit basierend auf den NAD-Timern, bevor ein Versuch auf dem sekundären Server gestartet wird.
Musterlösung anzeigen
Sie sollten die Timer auf den Network Access Devices (Access Points) anpassen. Derzeit wartet der AP 3 Sekunden und versucht es 5 Mal erneut, was zu einer Verzögerung von 18 Sekunden (3 Sekunden × 6 Versuche insgesamt) führt, bevor ein Failover auf den passiven Server erfolgt. Durch die Reduzierung der Konfiguration auf ein Timeout von 2 Sekunden und 2 Wiederholungsversuche sinkt die Failover-Erkennungszeit auf 6 Sekunden, was die Benutzererfahrung während der Wartungsfenster erheblich verbessert.
Q3. Sie migrieren ein standortübergreifendes Unternehmensnetzwerk von einem Active-Passive On-Premise-RADIUS-Server auf eine Active-Active Cloud-RADIUS-Plattform. Während der Pilotphase authentifizieren sich die Geräte erfolgreich an Cloud-Knoten A. Wenn der Load Balancer sie jedoch an Cloud-Knoten B weiterleitet, schlagen die EAP-TLS-Handshakes fehl. Was ist der wahrscheinlichste Konfigurationsfehler?
Hinweis: Überlegen Sie, was das Client-Gerät überprüft, wenn es einen sicheren EAP-Tunnel mit einem neuen Server aufbaut.
Musterlösung anzeigen
Das wahrscheinlichste Problem ist eine Diskrepanz beim Zertifikats-Trust. In einem Active-Active-Cluster müssen alle RADIUS-Knoten exakt dasselbe Serverzertifikat vorweisen (oder Zertifikate, die von exakt derselben vertrauenswürdigen CA-Kette ausgestellt wurden). Wenn Cloud-Knoten B ein anderes Zertifikat vorweist, dem die Client-Geräte nicht vertrauen, wird der EAP-TLS-Handshake vom Client abgelehnt, was dazu führt, dass die Authentifizierung fehlschlägt, obwohl der Server ordnungsgemäß funktioniert.
Weiterlesen in dieser Reihe
Konfigurieren von RADIUS-Authentifizierung für Gäste- und Mitarbeiter-WiFi-Netzwerke
Dieses technische Referenzhandbuch beschreibt die Architektur, Konfiguration und Bereitstellung der RADIUS-Authentifizierung für WiFi-Netzwerke von Unternehmen für Gäste und Mitarbeiter. Es bietet Netzwerkarchitekten und IT-Managern die genauen Protokolle, Sicherheitsstandards und Fehlerbehebungsmethoden, die für den Aufbau sicherer, skalierbarer drahtloser Zugriffskontrollsysteme erforderlich sind.
Passpoint und OpenRoaming: Das vollständige Handbuch
Dieses technische Referenzhandbuch bietet eine umfassende Analyse der Passpoint (Hotspot 2.0) und WBA OpenRoaming Frameworks in Enterprise WiFi Netzwerken. Es beschreibt detailliert die zugrundeliegenden Authentifizierungsprotokolle, Architekturkomponenten und Bereitstellungsstrategien, die für den Aufbau einer sicheren, reibungslosen Gastkonnektivität erforderlich sind. Netzwerkarchitekten und IT-Leiter erfahren, wie sie diese Standards entwerfen, implementieren und Fehler beheben, um manuelle Anmeldebarrieren zu beseitigen und gleichzeitig die Sicherheit auf Enterprise-Niveau aufrechtzuerhalten.
Implementierung von SCEP für sichere BYOD- und Netzwerkanmeldung im Hochschulbereich
Dieser technische Leitfaden bietet Netzwerkarchitekten und IT-Managern ein herstellerunabhängiges Konzept für die Bereitstellung von SCEP-basierten Zertifikatsanmeldungen zur Sicherung von Campusnetzwerken an Hochschulen. Er beschreibt im Detail die Migration von passwortbasiertem PEAP zu 802.1X EAP-TLS, die Automatisierung des BYOD-Onboardings und die Durchsetzung einer robusten VLAN-Segmentierung.