Warum ist unser Gast-WiFi so langsam? Diagnose von Netzwerküberlastung
Dieser Leitfaden diagnostiziert die verborgenen Ursachen der Gast-WiFi-Überlastung – Hintergrundtelemetrie, programmatische Werbenetzwerke und automatische OS-Updates –, die zusammen bis zu 40 % der öffentlichen WiFi-Bandbreite verbrauchen, bevor ein Gast überhaupt einen Browser öffnet. Er bietet ein phasenweises, herstellerneutrales Implementierungs-Framework für DNS-Filterung und QoS-Richtlinien, die diese Bandbreite zurückgewinnen, das Gästeerlebnis verbessern und einen messbaren ROI liefern. Zielgruppe sind IT-Direktoren und Betriebsleiter in den Bereichen Gastgewerbe, Einzelhandel, Veranstaltungen und öffentlicher Sektor.
Diesen Leitfaden anhören
Podcast-Transkript ansehen
Zusammenfassung für die Geschäftsleitung
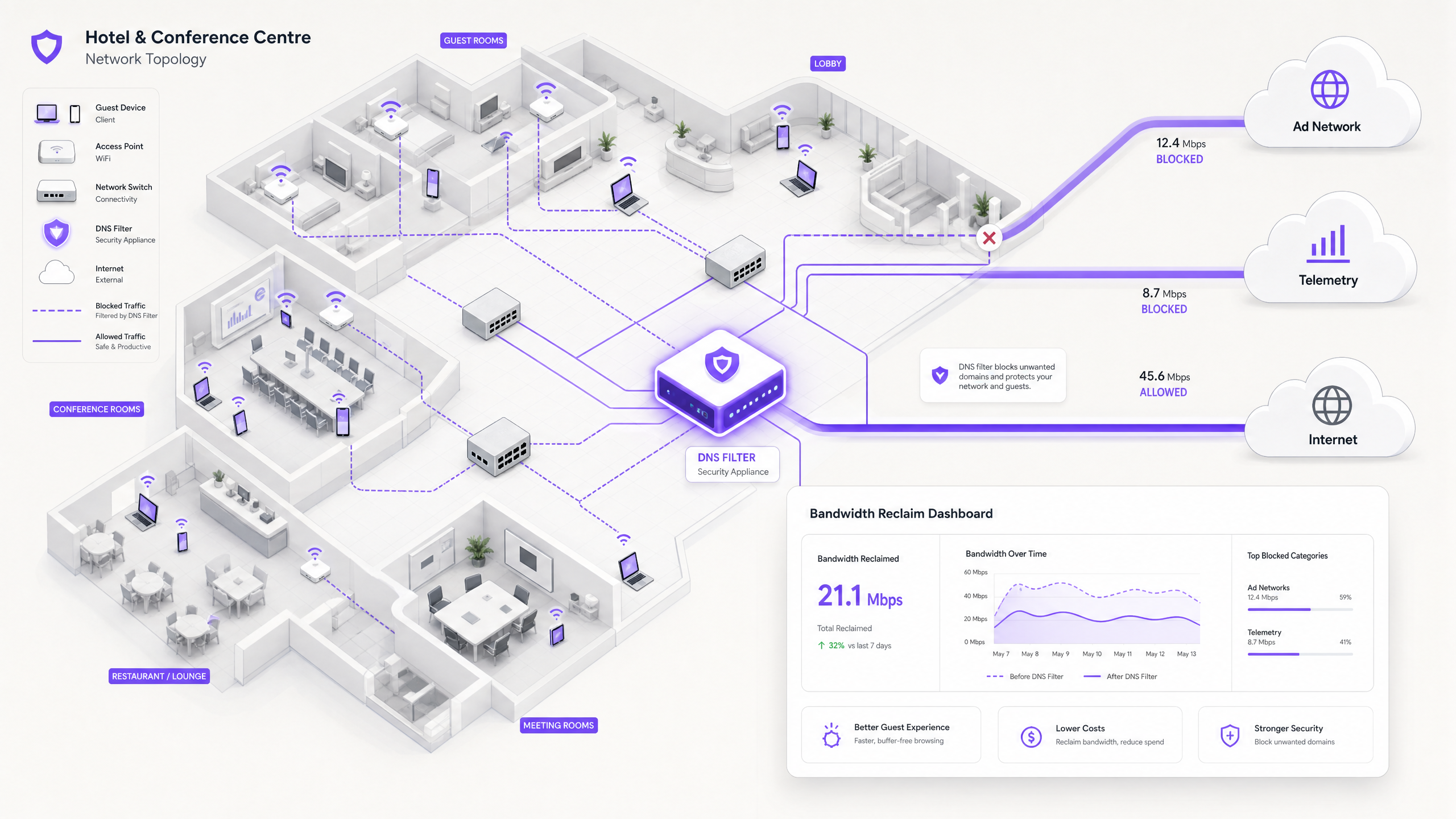
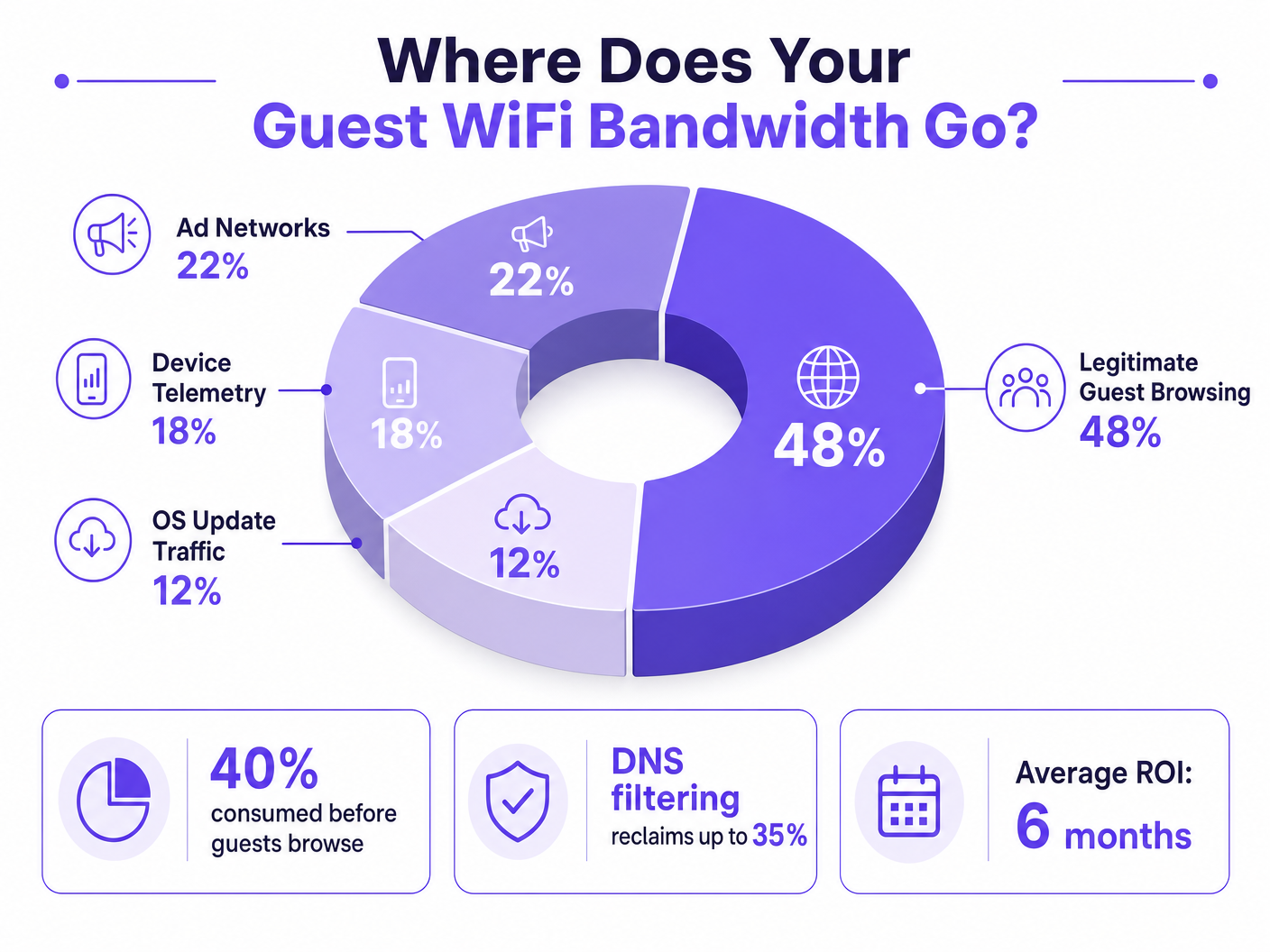
Für IT-Direktoren und Betriebsleiter, die Standorte mit hoher Dichte betreuen, ist die Gewährleistung eines zuverlässigen Guest WiFi -Erlebnisses ein ständiger Kampf gegen Netzwerküberlastung. Während herkömmliche Ansätze sich auf die Erhöhung der Gesamtbandbreite oder den Einsatz zusätzlicher Access Points konzentrieren, liegt die eigentliche Ursache für langsamen Durchsatz oft nicht im legitimen Benutzerverkehr, sondern in der verborgenen Schicht von Hintergrunddaten. In modernen Umgebungen – von weitläufigen Gastgewerbe -Komplexen bis hin zu stark frequentierten Einzelhandels -Flächen – werden bis zu 40 % der öffentlichen WiFi-Bandbreite durch Gerätetelemetrie, programmatische Werbenetzwerke und automatische OS-Updates verbraucht, bevor ein Gast überhaupt einen Browser öffnet.
Dieser technische Leitfaden bietet eine definitive Methodik zur Diagnose dieser Überlastung und zur Implementierung strategischer Gegenmaßnahmen. Durch den Einsatz von DNS-Filterung auf Netzwerkebene und Response Policy Zones (RPZ) können Netzwerkarchitekten in Unternehmen erhebliche Bandbreite zurückgewinnen, die Latenz reduzieren und das Endbenutzererlebnis drastisch verbessern, ohne die Investitionskosten für Infrastruktur-Upgrades zu verursachen. Wir werden die technische Architektur dieser Lösungen, Fallstudien zur Implementierung in der Praxis und den messbaren ROI der Rückgewinnung Ihres Netzwerks untersuchen.
Technischer Einblick
Die Anatomie der Hintergrundüberlastung
Wenn sich ein Gastgerät an einem öffentlichen Netzwerk authentifiziert, initiiert es sofort eine Flut von Hintergrundverbindungen. Diese Verbindungen werden hauptsächlich durch drei Verkehrskategorien angetrieben, die in ihrer Gesamtheit das bilden, was Netzwerktechniker als Phantomlast bezeichnen – Bandbreite, die vom Netzwerk verbraucht wird, bevor eine bewusste Gastaktivität stattfindet.
1. Gerätetelemetrie und -analyse
Moderne Betriebssysteme (iOS, Android, Windows) und installierte Anwendungen übertragen ständig Nutzungsdaten, Standortmetriken, Absturzberichte und Verhaltensanalysen an entfernte Server. In einer dichten Umgebung wie einem Transport -Knotenpunkt oder Konferenzzentrum können Tausende von Geräten, die gleichzeitig kleine, aber häufige Telemetrie-Payloads übertragen, die verfügbare drahtlose Sendezeit erschöpfen und NAT-Tabellen überlasten. Ein einzelnes iOS-Gerät kann innerhalb der ersten 60 Sekunden nach der Verbindung mit einem unbegrenzten Netzwerk über 200 verschiedene Hintergrund-DNS-Anfragen generieren.
2. Programmatische Werbenetzwerke
Viele kostenlose Anwendungen basieren auf programmatischen Werbeökosystemen. Sobald ein Gerät eine unbegrenzte WiFi-Verbindung erkennt, beginnen diese Apps mit dem Vorabruf von Videoanzeigen, hochauflösenden Display-Bannern und Tracking-Skripten von Ad-Exchange-Plattformen. Dieser Datenverkehr ist sowohl bandbreitenintensiv als auch latenzempfindlich und konkurriert aggressiv mit dem legitimen Gast-Browsing um Sendezeit. Analysen von Netzwerken an öffentlichen Orten zeigen durchweg, dass programmatischer Werbeverkehr in Spitzenzeiten 15–22 % der gesamten WAN-Auslastung ausmacht.
3. Automatisierte OS- und Anwendungs-Updates
Ohne ordnungsgemäße Traffic-Shaping-Maßnahmen versuchen Geräte, große OS-Patches und Anwendungs-Updates herunterzuladen, sobald sie eine unbegrenzte WiFi-Verbindung erkennen. Ein einzelnes großes iOS-Update kann 3–5 GB groß sein. In einer Umgebung mit 500 Geräten kann ein gleichzeitiger Update-Trigger – häufig bei der Veröffentlichung einer neuen OS-Version – selbst eine 1-Gbit/s-WAN-Verbindung innerhalb von Minuten sättigen.
Warum traditionelle Ansätze versagen
Die herkömmliche Reaktion auf Gast-WiFi-Überlastung besteht darin, die WAN-Bandbreite zu erhöhen oder zusätzliche Access Points bereitzustellen. Obwohl beide Maßnahmen ihre Berechtigung haben, adressiert keine von ihnen die Phantomlast. Das Hinzufügen von mehr Bandbreite bietet lediglich mehr Kapazität für den Hintergrundverkehr zum Verbrauch. Deep Packet Inspection (DPI), das andere traditionelle Werkzeug, wird zunehmend ineffektiv: Die weit verbreitete Einführung von TLS 1.3 und End-to-End-Verschlüsselung bedeutet, dass die Mehrheit der Datenverkehrs-Payloads für Inspektions-Engines undurchsichtig ist. Man kann nicht drosseln, was man nicht klassifizieren kann.
Für eine umfassendere Diskussion darüber, wie drahtlose Frequenzen mit High-Density-Bereitstellungen interagieren, siehe unseren Leitfaden zu Wi-Fi Frequencies: A Guide to Wi-Fi Frequencies in 2026 .
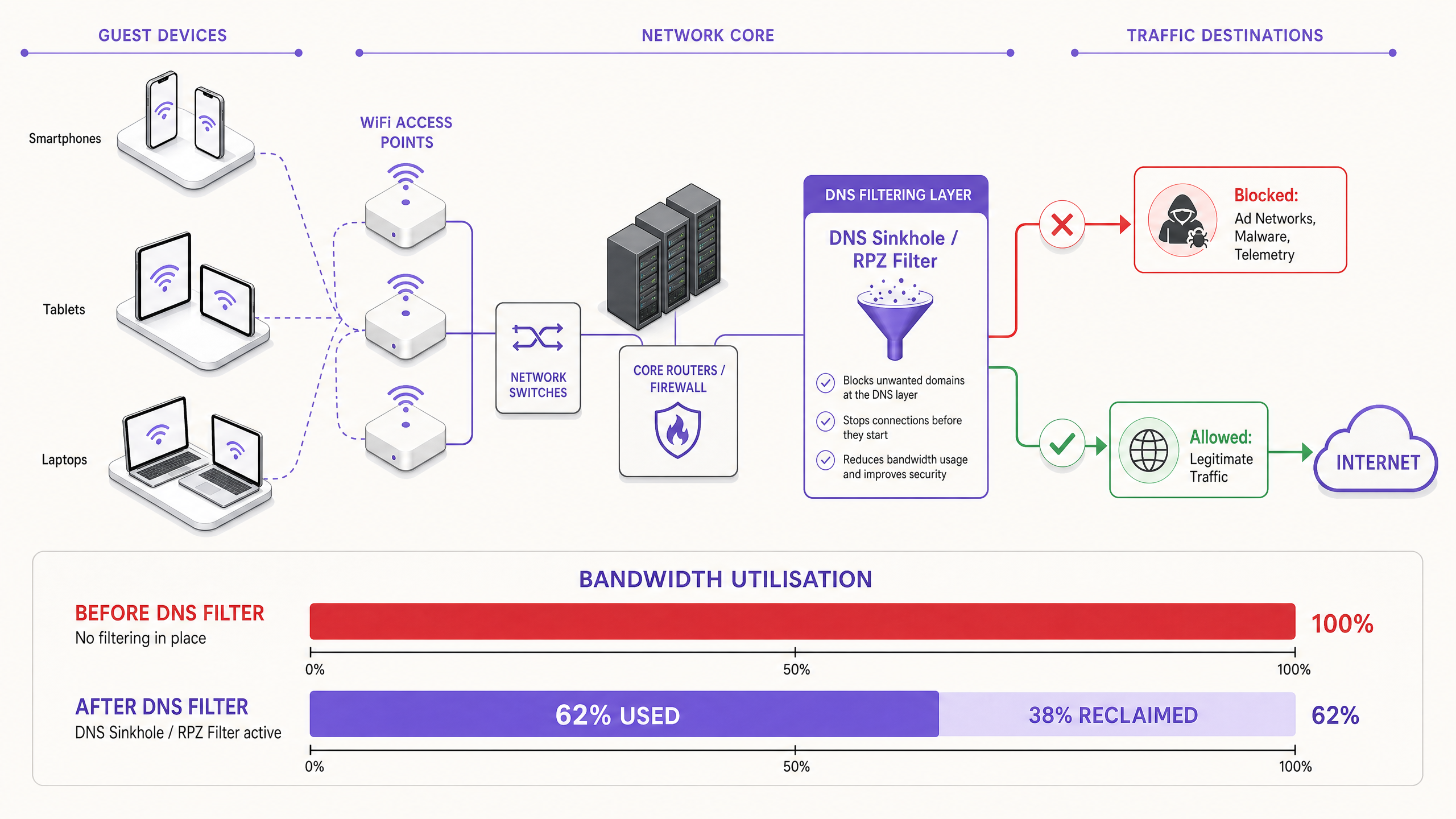
DNS-Filterung: Die effiziente Gegenmaßnahme
Die moderne, skalierbare Lösung ist die DNS-Filterung am Netzwerkrand. Anstatt Datenverkehrs-Payloads zu inspizieren, arbeitet die DNS-Filterung auf der Auflösungsebene – sie verhindert, dass Verbindungen überhaupt erst hergestellt werden.
Wenn ein Gerät den Zugriff auf ein bekanntes Werbenetzwerk oder eine Telemetrie-Domain anfordert, überprüft der DNS-Resolver die Anfrage anhand einer Response Policy Zone (RPZ). Erscheint die Domain in der Blockierliste, gibt der Resolver eine NXDOMAIN (Non-Existent Domain)-Antwort zurück oder leitet den Datenverkehr an eine lokale Null-IP-Adresse um. Die Verbindung wird beendet, bevor der TCP-Handshake stattfindet, wodurch sowohl die drahtlose Sendezeit als auch die WAN-Bandbreite erhalten bleiben. Dieser Ansatz ist rechnerisch kostengünstig, skaliert linear mit der Resolver-Kapazität und wird durch Payload-Verschlüsselung nicht beeinträchtigt.
Die Sicherheitsdimension
Die DNS-Filterung bietet einen erheblichen sekundären Vorteil: Sicherheit. Durch das Blockieren bekannter Malware-Command-and-Control (C2)-Domains, Phishing-Infrastrukturen und Exploit-Kit-Bereitstellungsnetzwerke auf der DNS-Ebene wird das Gastnetzwerk wesentlich besser geschützt.sibel. Dies ist direkt relevant für Compliance-Verpflichtungen im Rahmen von Frameworks wie PCI DSS (das Netzsegmentierung und Überwachung für Umgebungen mit Kartendaten erfordert) und der GDPR (die angemessene technische Maßnahmen zum Schutz personenbezogener Daten vorschreibt). Eine detaillierte Behandlung der Anforderungen an Audit-Trails in diesem Kontext finden Sie unter Explain what is audit trail for IT Security in 2026 .
Für Organisationen, die Bildungseinrichtungen verwalten, in denen Ad-Blocking auch eine Schutzfunktion erfüllt, sind die in Minimising Student Distractions with Network-Level Ad Blocking behandelten Prinzipien direkt anwendbar.
Implementierungsleitfaden
Der Einsatz einer robusten DNS-Filterarchitektur erfordert eine sorgfältige Planung, um die Unterbrechung legitimer Gastdienste zu vermeiden. Die Implementierung sollte schrittweise erfolgen.
Phase 1: Basisbewertung und Transparenz
Bevor Sie Sperren implementieren, erstellen Sie eine Basislinie der aktuellen Datenverkehrsmuster. Nutzen Sie WiFi Analytics , um die Top-Domains und -Kategorien mit dem höchsten Bandbreitenverbrauch über einen repräsentativen Zeitraum von 7–14 Tagen zu identifizieren. Diese Audit-Phase ist entscheidend, um das spezifische Datenverkehrsprofil Ihres Standorts zu verstehen und die Geschäftsgrundlage für die Investition zu schaffen. Wichtige zu erfassende Metriken sind:
| Metrik | Ziel-Basislinie | Anmerkungen |
|---|---|---|
| Top 20 DNS-Domains nach Abfragevolumen | Vollständige Liste | Telemetrie- und Ad-Domains identifizieren |
| WAN-Auslastung nach Kategorie | % Aufteilung | Phantomlast quantifizieren |
| Maximale Anzahl gleichzeitiger Geräte | Anzahl | Resolver-Infrastruktur dimensionieren |
| DNS-Abfragefehlerrate | < 0,1% | Benchmark vor der Bereitstellung festlegen |
Phase 2: Gestaffelte RPZ-Bereitstellung
Beginnen Sie mit der Bereitstellung der RPZ im Nur-Protokoll-Modus. Dies ermöglicht Ihnen, die Genauigkeit Ihrer Blocklisten zu überprüfen, ohne die Benutzererfahrung zu beeinträchtigen. Konzentrieren Sie sich zuerst auf Kategorien mit hoher Sicherheit:
- Bekannte Malware- und C2-Domains: Sofortiger Sicherheitsvorteil mit nahezu null Risiko von Fehlalarmen. Nutzen Sie Threat-Intelligence-Feeds von seriösen Anbietern.
- Bandbreitenintensive Programmatic Ad Networks: Zielen Sie auf die großen Video-Ad-Exchange-Plattformen ab. Diese sind gut dokumentiert und hosten unwahrscheinlich legitime Inhalte.
- Aggressive Telemetrie-Endpunkte: Blockieren Sie nicht-essentielle Tracking-Domains. Pflegen Sie eine sorgfältige Positivliste für Domains, die für Captive Portal-Authentifizierungsabläufe erforderlich sind.
Sobald der Nur-Protokoll-Modus akzeptable Fehlalarmraten (Ziel < 0,5% der Abfragen) bestätigt, wechseln Sie in den Erzwingungsmodus.
Phase 3: Traffic Shaping und QoS-Integration
Für Datenverkehr, der nicht vollständig blockiert werden kann (z.B. OS-Updates von Apple, Microsoft und Google), implementieren Sie Quality of Service (QoS)-Richtlinien. Begrenzen Sie die Rate von Update-Servern auf eine definierte Obergrenze – typischerweise 10–15% der gesamten WAN-Kapazität – um sicherzustellen, dass interaktiver Gastverkehr (Web-Browsing, VoIP, Videokonferenzen) eine priorisierte Warteschlange erhält. Dies ist besonders wichtig für Healthcare -Umgebungen, in denen klinisches Personal ein Netzwerksegment mit Gästen teilen kann.
Für Anleitungen zur Optimierung breiterer Netzwerkumgebungen, einschließlich Büro- und Mischnutzungsbereitstellungen, siehe Office Wi-Fi: Optimize Your Modern Office Wi-Fi Network .
Bewährte Verfahren
Explizite Positivlisten für kritische Dienste pflegen. Stellen Sie sicher, dass Domains, die für die Captive Portal-Authentifizierung, Zahlungsgateways (PCI DSS-Konformität) und den Kernbetrieb des Veranstaltungsortes unerlässlich sind, explizit zugelassen werden. Eine falsch konfigurierte Blockliste, die den Anmeldevorgang unterbricht, führt zu einer sofortigen und erheblichen Belastung des Supports.
Die Richtlinie transparent kommunizieren. Ihre Nutzungsbedingungen sollten festhalten, dass der Netzwerkverkehr verwaltet wird, um allen Benutzern ein qualitativ hochwertiges Erlebnis zu gewährleisten. Dies ist sowohl eine bewährte rechtliche Praxis unter der GDPR als auch eine angemessene Maßnahme zur Erwartungsbildung für Gäste.
Blocklisten-Updates automatisieren. Die Landschaft der Ad Networks und Telemetrie-Domains ändert sich ständig. Threat-Intelligence-Feeds und RPZ-Listen müssen dynamisch – idealerweise in einem Zyklus von weniger als 24 Stunden – aktualisiert werden, um wirksam zu bleiben.
DNS-Umgehung proaktiv angehen. Implementieren Sie Firewall-Regeln, um den gesamten ausgehenden Port 53 (UDP und TCP)-Verkehr abzufangen und an den lokalen Resolver umzuleiten. Dies verhindert, dass Clients die Filterung durch hartkodierte externe DNS-Server umgehen.
DNS over HTTPS (DoH) planen. Mit zunehmender DoH-Akzeptanz können Clients DNS-Abfragen über HTTPS routen, um lokale Resolver vollständig zu umgehen. Bewerten Sie, ob bekannte DoH-Anbieter (z.B. dns.google, cloudflare-dns.com) blockiert oder ein transparenter DoH-Proxy eingesetzt werden soll, der die lokale Richtlinie durchsetzt.
An IEEE 802.1X und WPA3 ausrichten. Stellen Sie sicher, dass Ihre DNS-Filterarchitektur mit Ihrem Authentifizierungs-Framework kompatibel ist. In Umgebungen, die IEEE 802.1X mit RADIUS-basierter Authentifizierung verwenden, können DNS-Filterrichtlinien pro VLAN oder pro Benutzergruppe angewendet werden, was eine granulare Kontrolle ermöglicht.
Fehlerbehebung & Risikominderung
Häufige Fehlerursachen
| Fehlerursache | Symptom | Abhilfe |
|---|---|---|
| Überblockierung (CDN-Kollision) | Kaputte Webseiten, fehlende Bilder | Granulare Blocklisten; schneller Positivlisten-Prozess |
| DNS-Umgehung (hartkodierte Resolver) | Filterung durch bestimmte Apps umgangen | Firewall-Umleitungsregeln für Port 53 |
| DoH-Umgehung | Filterung durch moderne Browser umgangen | Bekannte DoH-Anbieter blockieren oder DoH-Proxy bereitstellen |
| Resolver-Leistungsengpass | Erhöhte DNS-Latenz bei allen Clients | Resolver-Infrastruktur skalieren; Anycast implementieren |
| Captive Portal-Ausfall | Gäste können sich nicht authentifizieren | Explizite Positivliste für Portal-Domains und OS-Erkennungsendpunkte |
| Veraltete Blocklisten | Neue Ad-Domains nicht blockiert | Feed-Updates automatisieren; Abfrageprotokolle auf neue Domains mit hohem Volumen überwachen |
Reaktion auf Sicherheitsvorfälle
Wird ein Gastgerät identifiziert, das mit einer bekannten Malware-C2-Domain kommuniziert (sichtbar in den DNS-Abfrageprotokollen), blockiert die RPZ automatisch die weitere Kommunikation. Stellen Sie sicher, dass Ihr Incident-Response-Prozess einen Workflow zur Überprüfung dieser Ereignisse umfasst, da sie auf ein kompromittiertes Gerät hinweisen könnten, das von der Gast-VLAN isoliert werden muss.
ROI & Geschäftsauswirkungen
Die Implementierung von DNS-Filterung auf Netzwerkebene liefert messbare, quantifizierbare Geschäftsergebnisse in verschiedenen Dimensionen.
Bandbreitenrückgewinnung und CapEx-Aufschub. Veranstaltungsorte gewinnen typischerweise 20–40 % ihrer gesamten WAN-Bandbreite zurück. Dies führt direkt zu Kosteneinsparungen, indem die Notwendigkeit teurer Leitungs-Upgrades aufgeschoben wird. Für einen Veranstaltungsort, der derzeit für eine 500-Mbit/s-Standleitung bezahlt, entspricht die Rückgewinnung von 30 % der Kapazität einem Gewinn von 150 Mbit/s effektivem Durchsatz ohne zusätzliche Kosten.
Verbesserte Gästezufriedenheit und NPS. Durch die Eliminierung von Hintergrundüberlastung verbessern sich die wahrgenommene Geschwindigkeit und Zuverlässigkeit des Gast-WiFi dramatisch. Reduzierte Latenz und konsistenter Durchsatz führen zu höheren Net Promoter Scores und weniger Eskalationen im operativen Support.
Verbesserte Sicherheits- und Compliance-Position. Das Blockieren von Malware- und Phishing-Domains auf der DNS-Ebene reduziert das Risiko einer Sicherheitsverletzung, die vom Gastnetzwerk ausgeht, erheblich. Dies unterstützt direkt die Einhaltung der PCI DSS-Netzwerksegmentierungsanforderungen und der GDPR-Verpflichtung zur Implementierung geeigneter technischer Sicherheitsmaßnahmen.
Operative Effizienz. Automatisierte DNS-Filterung reduziert den manuellen Arbeitsaufwand für Netzwerkbetriebsteams. Anstatt reaktiv auf Überlastungsereignisse zu reagieren, verwaltet das Netzwerk proaktiv sein eigenes Verkehrsprofil.
| Ergebnis | Typischer Bereich | Messmethode |
|---|---|---|
| Zurückgewonnene Bandbreite | 20–40% der WAN-Kapazität | Überwachung der WAN-Auslastung vor/nachher |
| DNS-Abfrage-Blockierungsrate | 15–35% aller Abfragen | Resolver-Abfrageprotokolle |
| Verbesserung der Gästezufriedenheit | +8–15 NPS-Punkte | Umfragen nach Aufenthalt/Besuch |
| CapEx-Aufschub | 1–3 Jahre bei Leitungs-Upgrade | Kostenmodellierung |
| Reduzierung von Sicherheitsvorfällen | 40–60% weniger C2-Erkennungen | SIEM-Korrelation |
Indem IT-Verantwortliche das Netzwerk nicht nur als Leitung, sondern als intelligentes, gefiltertes Gateway betrachten, können sie ein überragendes, sicheres und kosteneffizientes Konnektivitätserlebnis bieten – eines, das mit dem Wachstum des Veranstaltungsortes skaliert, ohne proportionale Infrastrukturinvestitionen zu erfordern.
Schlüsseldefinitionen
Response Policy Zone (RPZ)
A mechanism in DNS servers that allows the modification of DNS responses based on a defined policy. When a queried domain matches an entry in the RPZ, the resolver can return a synthetic response (e.g., NXDOMAIN or a sinkhole IP) instead of the real answer.
The primary technical mechanism for implementing network-wide DNS filtering. IT teams configure RPZs on their internal resolvers to block ad networks, malware domains, and telemetry endpoints without requiring client-side software.
Deep Packet Inspection (DPI)
A form of network packet filtering that examines the data payload of a packet as it passes an inspection point, searching for protocol non-compliance, specific content, or defined criteria.
Traditionally used for traffic classification and shaping. Increasingly limited by the widespread adoption of TLS 1.3 end-to-end encryption, which renders payloads opaque. DNS filtering is the preferred alternative for encrypted traffic environments.
NXDOMAIN
A DNS response code (RCODE 3) indicating that the queried domain name does not exist in the DNS namespace.
Returned by a filtering DNS resolver to intentionally block a connection to an unwanted domain. The client application receives this response and abandons the connection attempt, preventing any bandwidth from being consumed.
DNS over HTTPS (DoH)
A protocol for performing DNS resolution via the HTTPS protocol (RFC 8484), encrypting DNS queries and responses between the client and a DoH-capable resolver.
Can bypass local network DNS filtering if clients are configured to use external DoH providers. Network administrators must implement firewall rules or proxy DoH traffic to enforce local RPZ policies.
Quality of Service (QoS)
A set of network mechanisms that control traffic prioritisation, rate-limiting, and queuing to ensure the performance of critical applications.
Used alongside DNS filtering to manage legitimate but high-bandwidth traffic (e.g., OS updates) that cannot be blocked. QoS ensures that interactive guest traffic receives priority over background bulk transfers.
Telemetry
The automated collection and transmission of operational data from devices to remote servers for monitoring, analytics, and diagnostics.
In the context of guest WiFi, device telemetry from mobile operating systems and applications can silently consume 15–20% of available bandwidth. It is a primary target for DNS filtering in public network deployments.
DNS Sinkholing
A technique in which a DNS server is configured to return a false IP address (typically a local null address) for specific domains, redirecting traffic away from its intended destination.
Used to neutralise malware C2 traffic and aggressively block high-bandwidth ad networks. More definitive than NXDOMAIN responses, as it allows the sinkhole server to log connection attempts for security analysis.
Airtime Fairness
A wireless network feature that allocates equal access to the wireless medium across all connected clients, regardless of their individual data rates.
Critical in high-density environments. Without airtime fairness, a single slow device (e.g., an older 802.11g client) can disproportionately consume airtime, degrading throughput for all other clients. Background telemetry traffic from many devices exacerbates this effect.
Phantom Load
Bandwidth consumed by automated background processes on connected devices before any deliberate user activity occurs.
The collective term for telemetry, ad network pre-fetching, and OS update traffic. Understanding and quantifying the phantom load is the first step in any guest WiFi congestion diagnosis.
Ausgearbeitete Beispiele
A 400-room resort hotel is experiencing severe network congestion every evening between 7:00 PM and 10:00 PM. The 1 Gbps WAN link is saturated, and guests are complaining about slow streaming and dropped VoIP calls. The IT Director needs to identify the root cause and implement a solution without upgrading the circuit.
Step 1 — Traffic Analysis: Deploy a network flow analyser (NetFlow/IPFIX) on the core router and run it for 5 days across peak and off-peak periods. Correlate with DNS query logs from the existing resolver. The analysis reveals that 35% of evening traffic is destined for known programmatic video ad networks (DoubleClick, AppNexus) and automated app update servers (Apple Software Update, Google Play). Legitimate guest browsing accounts for only 52% of total traffic.
Step 2 — DNS Filtering Deployment: Configure the core firewall to redirect all guest VLAN DNS queries (UDP/TCP port 53) to a locally hosted RPZ-enabled resolver. Import a curated blocklist covering the identified ad networks and telemetry domains. Run in log-only mode for 48 hours to validate false positive rates.
Step 3 — Policy Enforcement: After validating a false positive rate below 0.3%, switch to enforcement mode. Simultaneously, implement a QoS policy that rate-limits Apple and Google update servers to a combined ceiling of 80 Mbps during the 6 PM–11 PM window.
Step 4 — Validation: Monitor WAN utilisation over the following 7 days. Peak utilisation drops from 98% to 61%, resolving guest complaints. The hotel defers a planned circuit upgrade by an estimated 18 months.
A large conference centre is hosting a technology summit with 5,000 attendees. During the keynote, the WiFi network becomes completely unusable. Post-incident analysis shows that thousands of devices simultaneously attempted to download a major iOS update that was released that morning.
Immediate Mitigation (Day of Event): The network operations team identifies the surge via real-time DNS query monitoring. They immediately sinkhole the specific Apple software update domains (mesu.apple.com, appldnld.apple.com, updates.cdn-apple.com) at the DNS layer. Within 4 minutes, WAN utilisation drops from 99% to 68%, and the network stabilises.
Short-Term Fix (Same Event): A QoS policy is applied to rate-limit all remaining update traffic to 50 Mbps for the duration of the event.
Long-Term Strategy (Post-Event): The network team implements a dynamic QoS policy that automatically activates when total WAN utilisation exceeds 75%, throttling known update servers to 10% of total capacity. A pre-event checklist is created that includes temporarily sinkholes of major update domains during the 2 hours before and after high-profile sessions. The team also subscribes to Apple's and Microsoft's update release notification feeds to anticipate future surge events.
Übungsfragen
Q1. You are the IT Manager for a national retail chain. After deploying a DNS filtering solution across 50 stores, several store managers report that the captive portal login page is failing to load for guests. The support team is receiving high call volumes. What is the most likely cause, and what is the immediate remediation step?
Hinweis: Consider the full dependency chain of a modern captive portal authentication flow, including OS-level captive portal detection mechanisms.
Musterlösung anzeigen
The most likely cause is over-blocking. The DNS filter is blocking a domain required for the captive portal to function. Modern mobile operating systems use specific domains to detect captive portals (e.g., captive.apple.com for iOS, connectivitycheck.gstatic.com for Android). If these are blocked, the OS will not trigger the captive portal browser, and the guest will see no login prompt. Additionally, the portal itself may depend on a CDN or third-party authentication provider (e.g., social login via Facebook or Google) whose domains are inadvertently blocked.
Immediate remediation: Review the DNS query logs for NXDOMAIN responses originating from the guest subnet during the authentication phase. Identify all blocked domains that are queried before a successful login. Add these domains to the global allow-list. Implement a standard allow-list template for captive portal deployments that includes all major OS detection endpoints and common authentication provider domains.
Q2. A stadium network architect notices that despite implementing aggressive DNS filtering, WAN utilisation remains critically high during matches. Further investigation reveals a sustained high volume of UDP port 443 traffic that does not correlate with any blocked domains in the DNS logs. What is happening, and how should it be addressed?
Hinweis: Consider modern transport protocols and how they interact with DNS-layer controls.
Musterlösung anzeigen
The high volume of UDP 443 traffic indicates the use of QUIC (HTTP/3). QUIC is a UDP-based transport protocol used by major platforms (Google, Meta, YouTube) that bypasses traditional TCP-based proxies and DPI engines. More critically, clients using QUIC may also be using DNS over HTTPS (DoH) to resolve domains, completely bypassing the local RPZ resolver and rendering DNS filtering ineffective for those clients.
To address this: First, implement firewall rules to block outbound DoH traffic to known public DoH providers (Google, Cloudflare, NextDNS) on TCP/UDP port 443 by destination IP, forcing clients to fall back to the local resolver. Second, evaluate blocking outbound UDP 443 entirely (or rate-limiting it aggressively) to force QUIC clients to fall back to TCP-based HTTP/2, which is subject to existing traffic management policies. Third, review whether a transparent DoH proxy can be deployed to intercept and inspect DoH queries while enforcing local RPZ policies.
Q3. You are designing a QoS policy for a large public hospital's guest WiFi network. The network is shared between patient entertainment devices, visitor personal devices, and a small number of clinical staff using VoIP softphones on their personal mobiles. Prioritise the following traffic types: VoIP (SIP/RTP), Guest Web Browsing (HTTP/HTTPS), Windows/iOS Updates, and Streaming Video (Netflix/YouTube).
Hinweis: Consider both latency sensitivity and the business/clinical impact of each traffic type. Also consider the regulatory context of a healthcare environment.
Musterlösung anzeigen
Priority 1 — VoIP (SIP/RTP): Strict Priority Queuing (Expedited Forwarding, DSCP EF). VoIP is highly sensitive to latency (target < 150ms one-way) and jitter (target < 30ms). Packet loss above 1% causes audible degradation. In a clinical context, a dropped call could have patient safety implications.
Priority 2 — Guest Web Browsing (HTTP/HTTPS): Assured Forwarding (AF31). This is the primary expected use case for both patients and visitors. It requires reasonable responsiveness but is tolerant of moderate latency.
Priority 3 — Streaming Video (Netflix/YouTube): Rate-limited per client (e.g., 3–5 Mbps cap) with Assured Forwarding (AF21). While important for patient experience during long stays, uncapped streaming will saturate the link. A per-client cap ensures equitable access. Consider time-of-day policies that relax limits during off-peak hours.
Priority 4 — OS/App Updates (Scavenger Class, DSCP CS1): Lowest priority, best-effort queuing, with an aggregate rate limit (e.g., 50 Mbps total across all update traffic). These are background tasks with no latency sensitivity. They should only consume spare capacity. In a healthcare environment, also consider whether the guest network is fully isolated from clinical systems — if not, update traffic management becomes a security concern as well as a bandwidth one.