RADIUS Server High Availability: Active-Active vs Active-Passive
Um guia de referência técnica definitivo para gerentes de TI e arquitetos de rede que avaliam arquiteturas de alta disponibilidade RADIUS. Ele contrasta implantações Active-Active e Active-Passive, detalha os requisitos de replicação de banco de dados e explica como o Cloud RADIUS mitiga a latência de failover para locais corporativos.
Ouça este guia
Ver transcrição do podcast
📚 Parte da nossa série principal: Enterprise WiFi Security Guide →

Resumo Executivo
Para redes corporativas, a autenticação é binária: ou funciona perfeitamente, ou as operações de negócios param completamente. O RADIUS (Remote Authentication Dial-In User Service) serve como o guardião crítico para implantações de IEEE 802.1X, WPA3 enterprise e Guest WiFi em locais modernos. Ao contrário dos serviços de aplicativos que se degradam de forma controlada sob carga, uma falha no RADIUS bloqueia imediatamente o acesso de usuários, terminais de ponto de venda e dispositivos operacionais à rede.
Este guia de referência técnica avalia os modelos arquitetônicos para implantar uma infraestrutura RADIUS de alta disponibilidade. Especificamente, ele contrasta as configurações tradicionais Ativo-Passivo com os clusters modernos Ativo-Ativo. Para gerentes de TI, arquitetos de rede e diretores de operações de locais que gerenciam ambientes de alta densidade como Varejo , Hospitalidade e estádios, compreender essas estratégias de failover, a mecânica de balanceamento de carga e os requisitos de replicação de banco de dados é essencial.
Além disso, este guia examina como as plataformas Cloud RADIUS abstraem a complexidade da alta disponibilidade, fornecendo failover automático e escalabilidade elástica sem o fardo operacional de manter uma infraestrutura local redundante. Ao aplicar essas práticas recomendadas neutras em relação a fornecedores, as equipes de engenharia podem projetar arquiteturas de autenticação que eliminam pontos únicos de falha e atendem a rigorosos Acordos de Nível de Serviço (SLAs) de tempo de atividade.
Aprofundamento Técnico: Compreendendo a Arquitetura RADIUS
O RADIUS opera como um protocolo cliente-servidor sobre UDP, normalmente utilizando a porta 1812 para autenticação e a porta 1813 para tarifação (accounting), conforme definido nas RFC 2865 e RFC 2866. A natureza sem estado (stateless) das solicitações de autenticação UDP é uma vantagem estrutural para o design de alta disponibilidade. Como cada pacote Access-Request contém todas as credenciais e parâmetros necessários, qualquer servidor RADIUS dentro de um cluster pode processar qualquer solicitação de forma independente, sem exigir uma sincronização de estado complexa para a fase de autenticação em si.
Arquitetura Ativo-Passivo
Em uma implantação Ativo-Passivo (ou primário-reserva), um único servidor RADIUS processa todo o tráfego de autenticação e tarifação de entrada. Um servidor secundário permanece online, mas ocioso, recebendo atualizações de replicação de banco de dados, mas sem responder ativamente aos Dispositivos de Acesso à Rede (NADs), como pontos de acesso, switches ou gateways de VPN.
Quando o servidor primário falha, o NAD detecta o timeout e redireciona as solicitações subsequentes para o servidor secundário. O tempo de detecção de failover depende inteiramente dos temporizadores de configuração do NAD. Um NAD típico envia uma solicitação RADIUS e aguarda um timeout de pacote padrão (geralmente dois segundos). Se nenhuma resposta for recebida, ele tenta novamente. Com uma configuração padrão de três tentativas por servidor, o NAD pode aguardar até seis segundos antes de declarar o servidor primário inativo e realizar o failover para o secundário. Em ambientes com três servidores configurados, essa janela de failover pode se estender para dezoito segundos. Para um local de Hospitality movimentado ou um ambiente de Retail processando transações, esse atraso representa uma interrupção perceptível no serviço.
Arquitetura Ativo-Ativo
Por outro lado, uma arquitetura Ativo-Ativo distribui a carga de autenticação entre vários servidores RADIUS operacionais simultaneamente. O tráfego é roteado para o cluster por meio de configuração round-robin nos NADs ou através de um balanceador de carga dedicado.
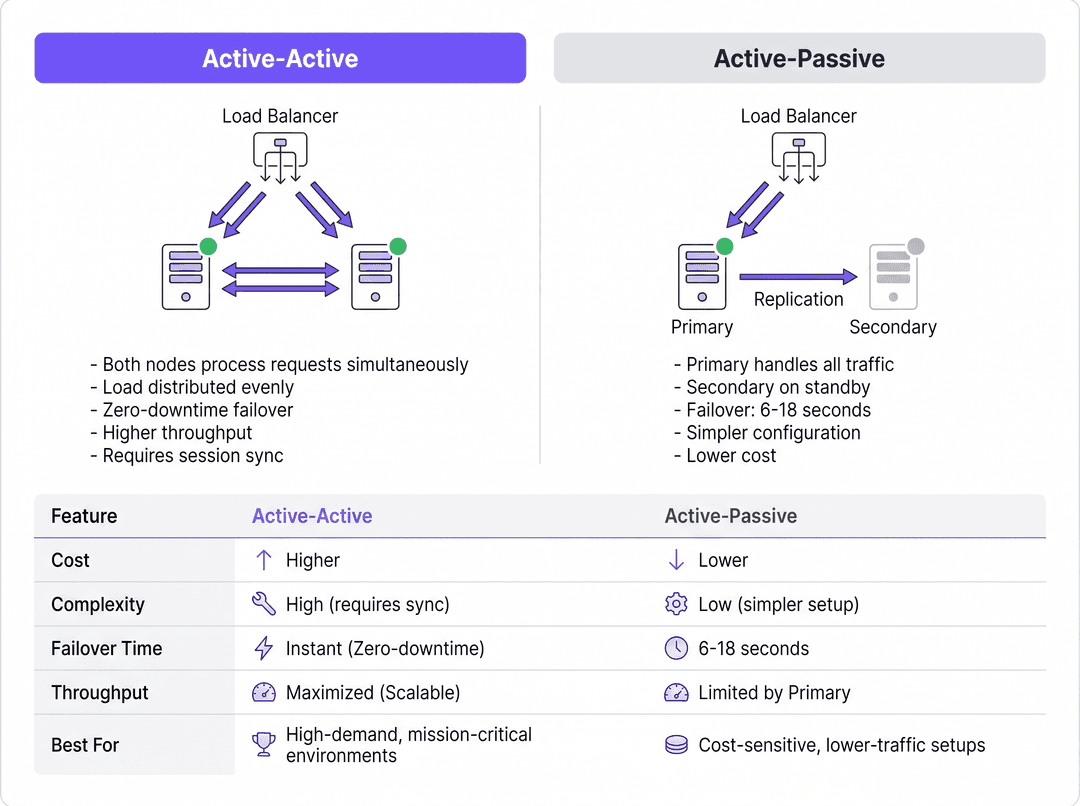
Este modelo elimina o atraso de detecção de failover inerente às configurações Ativo-Passivo. Se um nó falhar, o balanceador de carga (ou os NADs usando round-robin) simplesmente deixa de rotear o tráfego para o servidor que não responde, normalmente dentro de um a dois segundos com base nos intervalos de health-check. Os nós ativos restantes absorvem o tráfego instantaneamente. Além disso, os clusters Ativo-Ativo escalam horizontalmente; adicionar capacidade para eventos de alta densidade requer apenas o provisionamento de nós adicionais ao cluster.
O Desafio da Replicação de Banco de Dados
Embora a autenticação RADIUS seja stateless, a tarifação (accounting) RADIUS é inerentemente stateful. Ela rastreia o início da sessão (Start), o uso contínuo (Interim-Update) e o encerramento (Stop). Para locais que utilizam WiFi Analytics ou sistemas de faturamento, esses dados de tarifação devem permanecer consistentes em todos os nós.
Dar suporte a um cluster RADIUS com um banco de dados replicado (como MySQL ou MariaDB integrado ao FreeRADIUS) é obrigatório para uma alta disponibilidade robusta. Para implantações Ativo-Ativo, a replicação síncrona multi-master — como Galera Cluster ou MySQL NDB Cluster — é necessária. A replicação síncrona garante que um registro de tarifação seja gravado em todos os nós simultaneamente, evitando a perda de dados se um nó falhar. A replicação assíncrona tradicional, frequentemente usada em configurações Ativo-Passivo, introduz atraso de replicação. Se o nó primário falhar antes que o secundário receba a atualização, os dados da sessão ativa são perdidos permanentemente, o que pode violar frameworks de conformidade como o PCI DSS.
Guia de Implementação: Nuvem vs Local (On-Premise)
A decisão arquitetônica vai além de como agrupar servidores; ela envolve onde esses servidores residem. Para operadores multi-site, o backhaul do tráfego de autenticação para um data center local centralizado introduz latência de WAN e cria um ponto único de falha no link de WAN.
Plataformas Cloud RADIUS
Os serviços Cloud RADIUS resolvem os desafios de distribuição geográfica hospedando a infraestrutura de autenticação em várias zonas de disponibilidade globais. Quando um usuário se conecta em uma filial, a solicitação é roteada para o nó de borda de nuvem mais próximo, minimizando a latência.
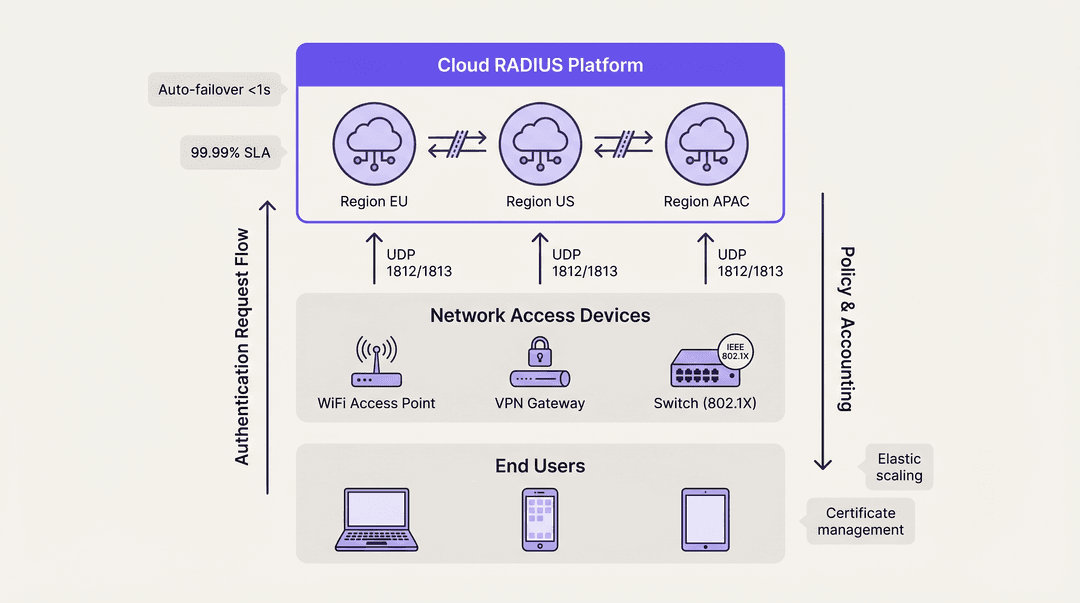
As plataformas de nuvem utilizam inerentemente arquiteturas Ativo-Ativo. O failover entre zonas de disponibilidade é gerenciado automaticamente pelo balanceamento de carga interno do provedor, abstraindo totalmente a complexidade da equipe de engenharia do cliente. Esse modelo normalmente oferece SLAs de 99,99% de tempo de atividade e elimina a necessidade de gerenciamento manual de certificados, aplicação de patches no sistema operacional e ajuste de replicação de banco de dados. Para organizações que implantam Wayfinding ou Sensors em campi distribuídos, a autenticação hospedada na nuvem garante a aplicação consistente de políticas sem dependências de hardware local.
Considerações sobre Implantação Local (On-Premise)
Organizações que operam em setores altamente regulamentados — como ambientes específicos de Saúde ou governamentais — podem exigir implantações locais devido a mandatos rígidos de soberania de dados. Nesses cenários, a implantação de um cluster FreeRADIUS Ativo-Ativo com replicação síncrona Galera oferece o mais alto nível de resiliência.
No entanto, as equipes de engenharia devem considerar a sobrecarga operacional. O gerenciamento de certificados TLS em vários nós, a garantia de consistência de configuração e o monitoramento ativo da integridade da replicação do banco de dados exigem recursos administrativos dedicados. Os balanceadores de carga de hardware devem ser configurados especificamente para suportar tráfego UDP com verificações de integridade de RADIUS apropriadas, pois muitos balanceadores de carga padrão são otimizados exclusivamente para tráfego TCP HTTP/HTTPS.
Boas Práticas para Alta Disponibilidade de RADIUS
- Distribuir em Vez de Duplicar: Para implantações que excedem 500 usuários simultâneos, priorize arquiteturas Ativo-Ativo em vez de configurações Ativo-Passivo para maximizar a taxa de transferência e minimizar a latência de failover.
- Implementar Replicação Síncrona: Proteja os dados de bilhetagem (accounting) com estado utilizando replicação síncrona de banco de dados multi-master (por exemplo, Galera Cluster) em vez de modelos assíncronos de réplica primária.
- Padronizar a Confiança do Certificado: Em um cluster Ativo-Ativo, certifique-se de que todos os nós apresentem o certificado de servidor idêntico ou certificados da exata mesma cadeia de Autoridade Certificadora (CA). Divergências farão com que os handshakes EAP-TLS e PEAP falhem durante a rotação de nós.
- Ajustar Timers do NAD: Otimize os timers de tentativa e timeout do RADIUS em seus Dispositivos de Acesso à Rede (NAD). Um timeout de dois segundos com duas tentativas oferece um equilíbrio entre a detecção rápida de failover e a prevenção de failover prematuro durante pequenos congestionamentos de rede.
- Testar Cenários de Falha: Trate os nós secundários como sistemas de produção. Simule regularmente falhas de nós, dessincronização de banco de dados e quedas de link WAN para validar se os mecanismos de failover automatizados funcionam conforme projetado.
Solução de Problemas e Mitigação de Riscos
O modo de falha mais comum em alta disponibilidade RADIUS é o desvio de configuração. Em configurações Ativo-Passivo, os administradores frequentemente atualizam políticas ou renovam certificados no nó primário, mas negligenciam o secundário. Quando ocorre um evento de failover, o nó secundário rejeita o tráfego legítimo devido a credenciais expiradas ou políticas desatualizadas.
Para mitigar esse risco, implemente ferramentas de gerenciamento de configuração (como Ansible ou Terraform) para implantar alterações simetricamente em todos os nós. Para o gerenciamento de certificados, utilize protocolos de renovação automatizados (como ACME) configurados para distribuir o certificado atualizado simultaneamente por todo o cluster.
Outro risco significativo é a configuração incorreta do balanceador de carga. Se um balanceador de carga não realizar verificações de integridade (health checks) na camada de aplicação (especificamente verificando a capacidade de resposta da porta UDP 1812), ele poderá continuar roteando o tráfego para um nó onde o sistema operacional está em execução, mas o daemon do RADIUS travou. Certifique-se de que as verificações de integridade validem explicitamente a disponibilidade do serviço RADIUS.
ROI e Impacto nos Negócios
O retorno sobre o investimento para uma alta disponibilidade RADIUS robusta é medido principalmente por meio da mitigação de riscos e da eficiência operacional. Interrupções de autenticação resultam em perdas imediatas de produtividade para os funcionários e graves danos à reputação de locais públicos.
Ao fazer a transição de implantações manuais em um único servidor para arquiteturas Ativo-Ativo automatizadas (particularmente via Cloud RADIUS), as organizações recuperam horas significativas de engenharia anteriormente dedicadas à manutenção de rotina. Essa eficiência operacional permite que as equipes de rede se concentrem em iniciativas estratégicas, como implantar Os Principais Benefícios do SD WAN para Empresas Modernas ou otimizar a cobertura de alta densidade, em vez de combater falhas de autenticação. Em última análise, uma autenticação confiável é a camada fundamental sobre a qual todos os serviços de rede subsequentes dependem.
Definições principais
Arquitetura Ativo-Ativo
Um design de alta disponibilidade onde múltiplos servidores RADIUS processam solicitações de autenticação simultaneamente, distribuindo a carga e fornecendo failover instantâneo sem atrasos de detecção.
Essencial para locais de alta densidade (estádios, grandes varejos) onde um único servidor não consegue lidar com picos de autenticação.
Arquitetura Ativo-Passivo
Um modelo de redundância onde um servidor primário lida com todo o tráfego e um servidor secundário permanece inativo em espera até que o primário falhe.
Adequado para implantações menores e sensíveis a custos, mas introduz um atraso de failover de 6 a 18 segundos enquanto o dispositivo de acesso à rede detecta a falha.
Replicação Síncrona
Um método de replicação de banco de dados onde os dados são gravados em todos os nós de um cluster simultaneamente antes que a transação seja considerada concluída.
Obrigatório para bancos de dados de contabilidade RADIUS Ativo-Ativo (como Galera Cluster) para evitar perda de dados e garantir a conformidade.
Replicação Assíncrona
Um método de replicação de banco de dados onde o nó primário grava os dados e, posteriormente, os copia para os nós secundários, introduzindo um pequeno atraso (lag).
Frequentemente usada em configurações Ativo-Passivo, mas traz o risco de perda de registros contábeis recentes se o nó primário falhar abruptamente.
Dispositivo de Acesso à Rede (NAD)
O componente de hardware (como um ponto de acesso WiFi, switch ou gateway VPN) que solicita autenticação ao servidor RADIUS em nome do usuário.
Os temporizadores internos de nova tentativa e timeout do NAD ditam a rapidez com que ocorre um failover Ativo-Passivo.
Protocolo Stateless
Um protocolo de comunicação que trata cada solicitação como uma transação independente, sem relação com qualquer solicitação anterior.
A autenticação RADIUS sobre UDP é stateless, permitindo que os balanceadores de carga roteiem qualquer solicitação para qualquer servidor ativo de forma integrada.
Desvio de Configuração
O fenômeno em que servidores secundários ou de backup ficam dessincronizados com o servidor primário em relação a políticas, atualizações ou certificados ao longo do tempo.
A principal causa de falha em implantações RADIUS Ativo-Passivo quando o nó secundário é forçado a assumir o controle.
Cloud RADIUS
Um serviço de autenticação gerenciado hospedado em uma infraestrutura de nuvem distribuída globalmente, fornecendo redundância Ativo-Ativo integrada e escalabilidade automática.
Substitui a necessidade de as equipes de TI criarem, corrigirem e monitorarem manualmente servidores RADIUS locais redundantes.
Exemplos práticos
Um grupo hoteleiro europeu gerencia 45 propriedades em seis países. Atualmente, eles executam máquinas virtuais FreeRADIUS independentes em cada propriedade. Um certificado TLS expirado recentemente em um dos locais causou uma interrupção completa do WiFi dos hóspedes durante uma grande conferência. Como eles devem reprojetar sua arquitetura de autenticação para evitar interrupções localizadas e reduzir os custos de manutenção?
O grupo hoteleiro deve migrar de instâncias FreeRADIUS locais de nó único para uma plataforma Cloud RADIUS centralizada que utiliza uma arquitetura Active-Active. Ao aproveitar um provedor de nuvem com nós de borda distribuídos geograficamente, as solicitações de autenticação de cada propriedade são roteadas para o nó regional mais próximo, minimizando a latência. O gerenciamento centralizado de políticas permite que a equipe de TI defina regras de autenticação uma única vez e as aplique globalmente. O provedor de nuvem lida automaticamente com a rotação de certificados TLS, patches do sistema operacional e replicação de banco de dados.
Um estádio nacional de esportes está se preparando para um evento de 60.000 participantes. Sua configuração atual do RADIUS é Active-Passive. Durante os testes de carga, o servidor primário ficou saturado processando 8.000 solicitações de autenticação por minuto quando os portões abriram, causando graves atrasos na conexão, enquanto o servidor secundário permaneceu completamente ocioso. Como eles podem otimizar essa implantação?
A equipe de engenharia de rede deve converter a implantação de Active-Passive para Active-Active. Primeiro, eles devem reconfigurar os Dispositivos de Acesso à Rede (NADs) do estádio para utilizar o balanceamento de carga round-robin em ambos os servidores RADIUS, duplicando instantaneamente a capacidade de processamento de autenticação. Em segundo lugar, eles devem provisionar um terceiro nó RADIUS para fornecer a margem de segurança necessária para picos de demanda. Finalmente, para garantir que os dados de bilhetagem (accounting) permaneçam consistentes em todos os três nós ativos, eles devem implementar uma solução de replicação de banco de dados multi-master síncrona, como o Galera Cluster.
Questões práticas
Q1. Seu cliente de varejo corporativo exige uma solução RADIUS de alta disponibilidade para seus terminais de ponto de venda. Eles têm requisitos rígidos de conformidade PCI DSS que determinam que absolutamente nenhum dado de sessão de contabilidade (accounting) pode ser perdido durante um failover de servidor. Qual estratégia de replicação de banco de dados você deve implementar para o backend do RADIUS?
Dica: Considere a diferença entre dados sendo gravados simultaneamente versus dados sendo copiados após o fato.
Ver resposta modelo
Você deve implementar a Replicação Síncrona (como um Galera Cluster ou MySQL NDB Cluster). A replicação síncrona garante que o registro de contabilidade seja confirmado em todos os nós simultaneamente antes de reconhecer a transação. Se você usasse a replicação assíncrona, uma falha no nó poderia resultar na perda de transações recentes que ainda não haviam sido copiadas para o banco de dados secundário, violando o rígido requisito de conformidade.
Q2. Uma rede de campus universitário usa uma configuração RADIUS Ativo-Passivo. Os alunos reclamam que, quando o servidor primário passa por manutenção, leva quase 20 segundos para que seus laptops se conectem ao WiFi. Os pontos de acesso estão configurados com um timeout de RADIUS de 3 segundos e 5 tentativas. Como você pode reduzir o atraso de failover sem alterar a arquitetura do servidor?
Dica: Calcule o tempo máximo de espera com base nos temporizadores do NAD antes que ele tente o servidor secundário.
Ver resposta modelo
Você deve ajustar os temporizadores nos Dispositivos de Acesso à Rede (pontos de acesso). Atualmente, o AP aguarda 3 segundos e tenta novamente 5 vezes, resultando em um atraso de 18 segundos (3 segundos × 6 tentativas no total) antes de fazer o failover para o servidor passivo. Ao reduzir a configuração para um timeout de 2 segundos e 2 tentativas, o tempo de detecção de failover cai para 6 segundos, melhorando significativamente a experiência do usuário durante as janelas de manutenção.
Q3. Você está migrando uma rede corporativa de vários locais de um servidor RADIUS local Ativo-Passivo para uma plataforma Cloud RADIUS Ativo-Ativo. Durante a fase piloto, os dispositivos se autenticam com sucesso no Cloud Node A, mas quando o balanceador de carga os direciona para o Cloud Node B, os handshakes EAP-TLS falham. Qual é o erro de configuração mais provável?
Dica: Considere o que o dispositivo cliente verifica ao estabelecer um túnel EAP seguro com um novo servidor.
Ver resposta modelo
O problema mais provável é uma incompatibilidade de Confiança de Certificado (Certificate Trust). Em um cluster Ativo-Ativo, todos os nós RADIUS devem apresentar exatamente o mesmo certificado de servidor (ou certificados emitidos exatamente pela mesma cadeia de CA confiável). Se o Cloud Node B estiver apresentando um certificado diferente no qual os dispositivos clientes não confiam, o handshake EAP-TLS será rejeitado pelo cliente, fazendo com que a autenticação falhe, apesar de o servidor estar funcionando corretamente.
Continue a ler esta série
Configurando Autenticação RADIUS para Redes WiFi de Convidados e Funcionários
Este guia de referência técnica descreve a arquitetura, configuração e implantação da autenticação RADIUS para redes WiFi corporativas de convidados e funcionários. Ele fornece aos arquitetos de rede e gerentes de TI os protocolos exatos, padrões de segurança e metodologias de solução de problemas necessários para criar sistemas de controle de acesso sem fio seguros e escaláveis.
Passpoint and OpenRoaming: Complete Guide
Este guia de referência técnica fornece uma análise abrangente das estruturas Passpoint (Hotspot 2.0) e WBA OpenRoaming em redes WiFi corporativas. Ele detalha os protocolos de autenticação subjacentes, componentes de arquitetura e estratégias de implantação necessárias para estabelecer uma conectividade de visitantes segura e sem atrito. Arquitetos de rede e líderes de TI aprenderão como projetar, implementar e solucionar problemas desses padrões para eliminar as barreiras de login manual, mantendo a segurança de nível empresarial.
Como Implementar SCEP para BYOD Seguro e Registro de Rede no Ensino Superior
Este guia técnico fornece aos arquitetos de rede e gerentes de TI um modelo neutro de fornecedor para implantar o registro de certificados baseado em SCEP para proteger redes de campus de ensino superior. Ele detalha como migrar do PEAP baseado em senha para o 802.1X EAP-TLS, automatizar a integração de BYOD e aplicar uma segmentação robusta de VLAN.