Principais 10 Causas de Timeouts de DHCP em Redes Sem Fio de Alta Densidade
Este guia de referência técnica definitivo identifica as dez principais causas de timeouts de DHCP em redes sem fio de alta densidade e fornece estratégias de remediação práticas e independentes de fornecedor. Projetado para líderes seniores de TI, arquitetos de rede e diretores de operações de locais de grande porte, ele abrange princípios profundos de engenharia, fluxos de trabalho de implementação passo a passo e resultados de negócios mensuráveis. Saiba como eliminar gargalos de conexão e otimizar sua infraestrutura de Wi-Fi para fornecer conectividade contínua em ambientes corporativos exigentes.
Ouça este guia
Ver transcrição do podcast
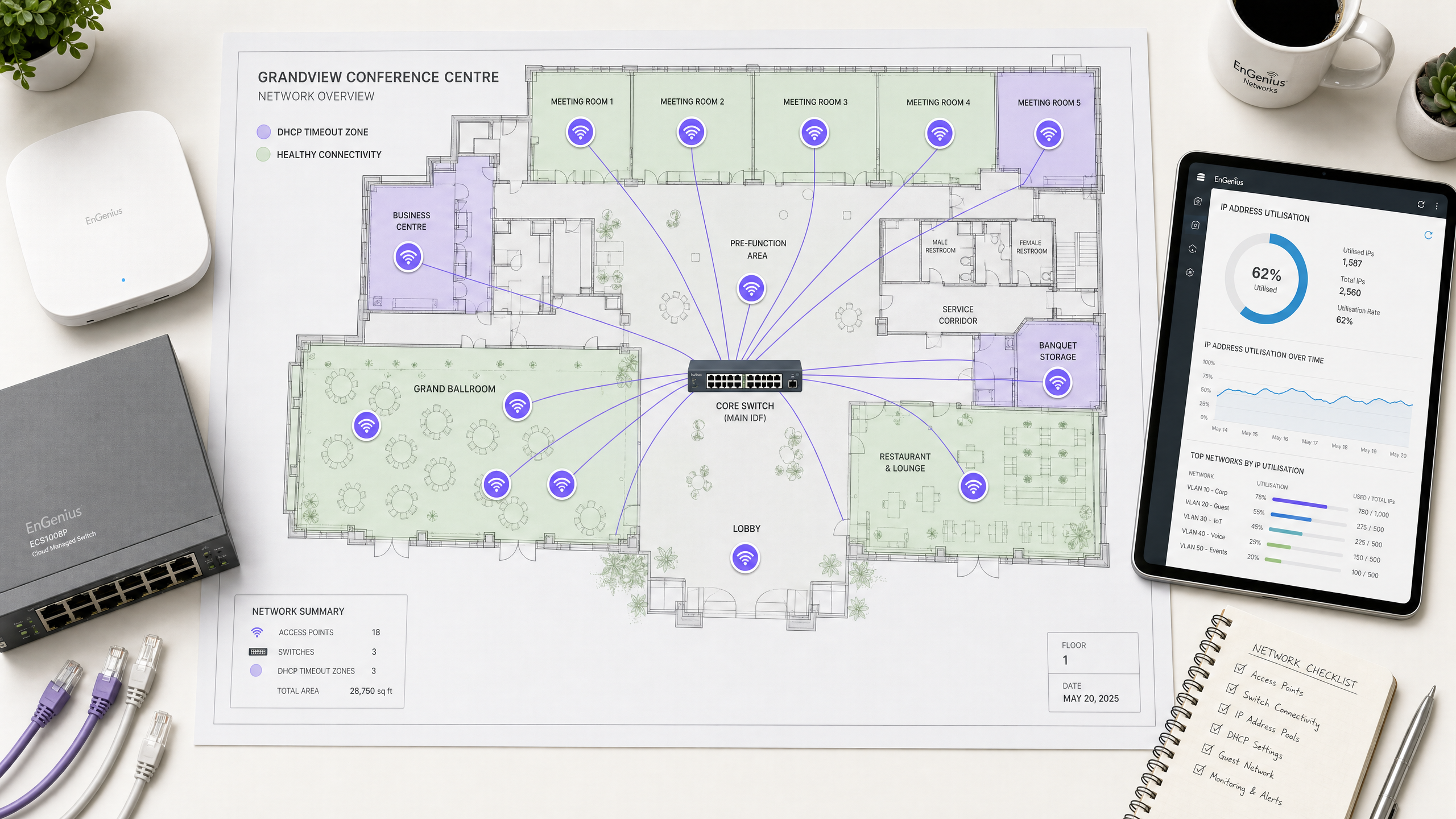
Resumo Executivo
Em ambientes corporativos modernos — como hotéis de alta capacidade, shoppings, hubs de transporte e estádios —, a conectividade sem fio é um motor de negócios fundamental. No entanto, a experiência do convidado frequentemente falha logo na primeira etapa da integração com a rede: a obtenção de um endereço IP. Em redes sem fio de alta densidade, os timeouts de DHCP (Dynamic Host Configuration Protocol) são uma das causas primárias mais comuns e mal diagnosticadas de falhas de integração. Quando centenas ou milhares de dispositivos tentam se conectar simultaneamente, as configurações tradicionais de DHCP falham sob carga, deixando os usuários presos em uma tela de carregamento infinita ou com um endereço link-local 169.254.x.x autoatribuído.
Este guia de referência técnica autoritativo explora as dez principais causas de timeouts de DHCP em redes sem fio de alta densidade. Ele ignora a teoria acadêmica para fornecer a arquitetos de rede seniores, CTOs e diretores de operações de locais estratégias de remediação imediatas e acionáveis. Ao otimizar sistematicamente os tamanhos dos escopos de DHCP, reduzir os tempos de concessão (lease times), implementar configurações robustas de Camada 2/3 e implantar arquiteturas de servidores de alta disponibilidade, as organizações podem reduzir significativamente a latência de conexão, eliminar o atrito na integração e proteger a reputação de suas marcas. A implementação dessas melhores práticas correlaciona-se diretamente com a melhoria da satisfação dos convidados, maior engajamento com produtos essenciais como o Guest WiFi e uma captura de dados mais rica por meio do WiFi Analytics .
Detalhamento Técnico
Para diagnosticar e resolver os timeouts de DHCP, os engenheiros de rede devem primeiro entender a mecânica precisa do handshake DHCP de quatro vias, comumente chamado de processo DORA (Discover, Offer, Request, Acknowledge) [1]. Em ambientes de alta densidade, esse processo é altamente sensível à perda de pacotes, latência e esgotamento de recursos.
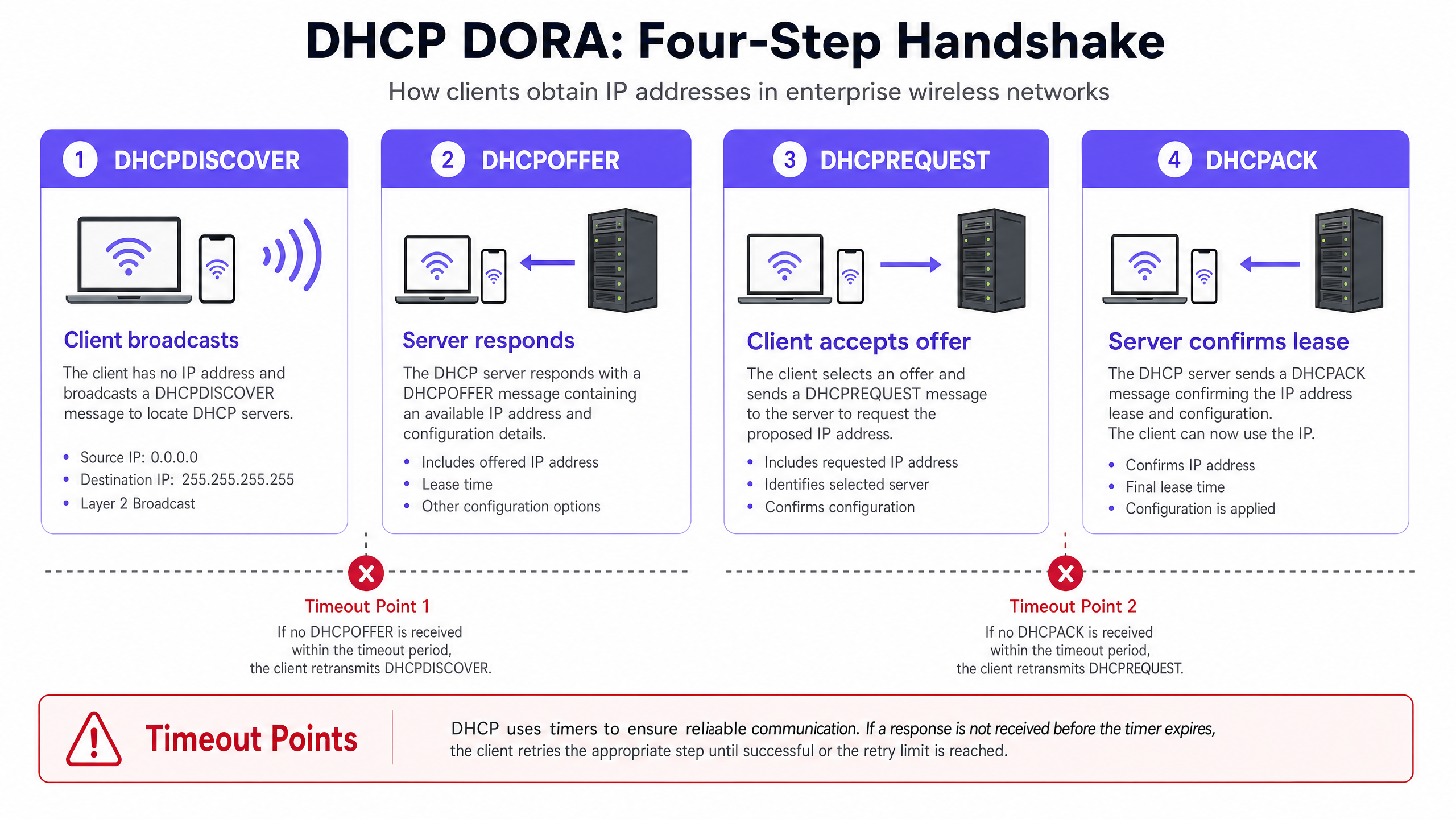
O Handshake DHCP (DORA) em Redes Sem Fio de Alta Densidade
- DHCPDISCOVER (Broadcast): O cliente sem fio associa-se ao Ponto de Acesso (AP) e transmite um pacote em broadcast para localizar os servidores DHCP disponíveis. Em um domínio de broadcast grande, esse pacote é inundado por todas as portas, consumindo um tempo de transmissão sem fio (airtime) valioso.
- DHCPOFFER (Unicast/Broadcast): Cada servidor DHCP ativo que recebe a mensagem de descoberta reserva um endereço IP e envia uma oferta ao cliente, especificando os parâmetros de concessão, máscara de sub-rede, gateway padrão e servidores DNS.
- DHCPREQUEST (Broadcast): O cliente seleciona uma oferta (normalmente a primeira recebida) e transmite um pedido em broadcast para aceitar aquele endereço IP específico, recusando implicitamente quaisquer outras ofertas.
- DHCPACK (Unicast/Broadcast): O servidor DHCP selecionado registra a concessão (lease) em seu banco de dados e envia uma confirmação (acknowledgement) ao cliente, validando a atribuição de IP e o tempo de concessão. O cliente então aplica essa configuração.
O Impacto da Sobrecarga de Wireless e do Congestionamento de Airtime
Ao contrário das redes cabeadas, onde os broadcasts de Camada 2 são tratados por hardware em velocidades gigabit, as redes sem fio transmitem quadros de broadcast e multicast na menor taxa de dados obrigatória (geralmente 1 Mbps, 6 Mbps ou 11 Mbps, dependendo da configuração do SSID) para garantir que todos os clientes distantes possam recebê-los [2]. Em um SSID de alta densidade com milhares de dispositivos ativos, os pacotes DHCP de broadcast consomem uma quantidade desproporcional de airtime de RF, levando a colisões de pacotes, retransmissões e eventuais timeouts. Um dispositivo cliente geralmente espera uma resposta DHCP dentro de 2 a 4 segundos; se o congestionamento de airtime atrasar qualquer etapa do processo DORA além dessa janela, o cliente expira o tempo limite (timeout), desfaz a associação e tenta novamente, gerando uma carga em cascata na rede.
As 10 Principais Causas de Timeouts de DHCP
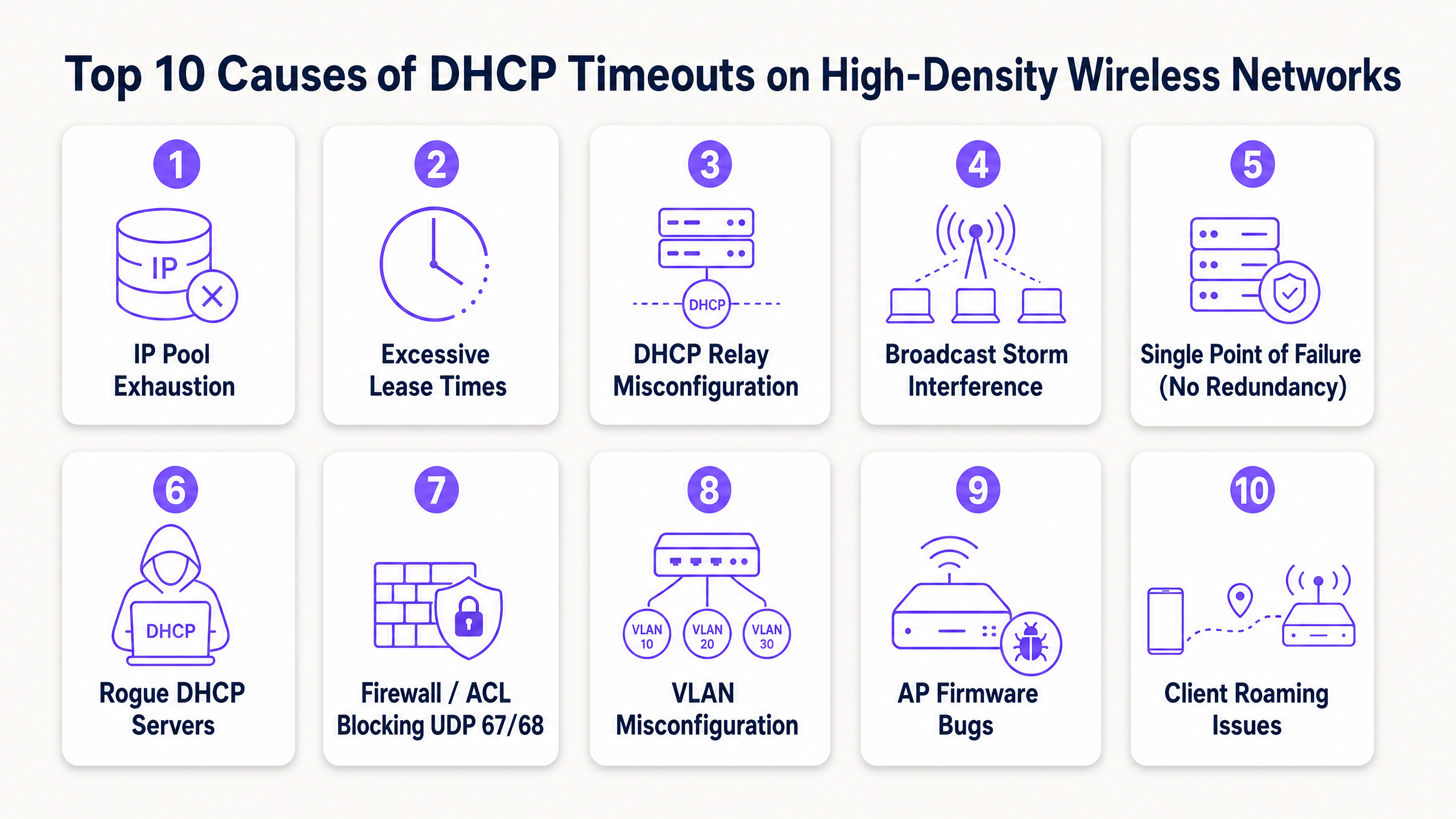
1. Esgotamento do Pool de IPs DHCP
O Mecanismo: O escopo do servidor DHCP é muito pequeno para o volume de dispositivos transitórios. Quando o pool está 100% utilizado, o servidor ignora silenciosamente novos pacotes DHCPDISCOVER porque não possui endereços para oferecer.
O Contexto de Alta Densidade: Uma sub-rede Classe C padrão (/24) fornece apenas 254 endereços IP utilizáveis. No saguão de um hotel, portão de um estádio ou plenária de uma conferência, o número de dispositivos simultâneos pode facilmente ultrapassar esse limite em minutos. Para piorar, muitos usuários carregam vários dispositivos conectados (celulares, smartwatches, tablets, notebooks), multiplicando a demanda de IP.
Remediação: Redimensione os escopos de sua rede usando a notação CIDR (Classless Inter-Domain Routing). Transicione VLANs de clientes de alta densidade para sub-redes /22 (1.022 IPs) ou /21 (2.046 IPs). Garanta que suas ferramentas de monitoramento estejam configuradas para alertar com 80% de utilização do pool para permitir a expansão proativa do escopo antes de eventos de pico.
2. Tempos de Concessão (Lease Times) Excessivos em Redes de Visitantes
O Mecanismo: O tempo de concessão (lease time) determina por quanto tempo um cliente mantém um endereço IP antes de precisar renová-lo ou liberá-lo. Se o tempo de concessão for muito longo, o servidor DHCP mantém o endereço em seu banco de dados, impedindo que ele seja reatribuído a um novo cliente, mesmo que o dispositivo original já tenha saído do local.
O Contexto de Alta Densidade: Muitas configurações padrão de DHCP especificam um tempo de concessão de 24 horas ou 8 dias. Em ambientes públicos ou de hospitalidade com alta rotatividade — como um terminal de transporte ou shopping center — os visitantes geralmente permanecem por menos de duas horas [3]. Com uma concessão de 24 horas, um visitante que se conecta por 10 minutos consome um endereço IP por um dia inteiro, levando ao esgotamento artificial do pool.
Remediação: Alinhe os tempos de concessão (lease times) com os tempos de permanência dos clientes. Implemente um tempo de concessão de 30 a 60 minutos para redes de convidados. Para redes corporativas de funcionários, onde os dispositivos permanecem conectados por um turno completo, use um tempo de concessão de 8 a 12 horas. Isso garante a rápida recuperação de endereços IP de clientes que já se desconectaram.
3. Configuração Incorreta do DHCP Relay Agent
O Mecanismo: Como as mensagens de descoberta de DHCP são broadcasts de Camada 2, elas não podem ultrapassar as fronteiras do roteador (Camada 3). Um DHCP Relay Agent (geralmente configurado em um switch de Camada 3 ou gateway de segurança usando comandos como o ip helper-address da Cisco) deve interceptar esses broadcasts e encaminhá-los como pacotes unicast para o servidor DHCP central [4]. Se o agente de relay estiver configurado incorretamente, tiver o IP de helper errado ou for omitido de uma VLAN recém-criada, o tráfego DHCP será bloqueado.
O Contexto de Alta Densidade: Redes de alta densidade dependem muito da segmentação de VLAN para limitar os domínios de broadcast. Ao implantar um novo SSID ou expandir um local, os engenheiros geralmente criam novas VLANs de clientes. Se a configuração do agente de relay não for atualizada nas interfaces de Camada 3 correspondentes, os clientes nessas VLANs sofrerão timeouts de DHCP imediatos.
Remediação: Estabeleça modelos de configuração estritos para todos os switches de Camada 3. Certifique-se de que cada interface VLAN de cliente tenha um par redundante de endereços DHCP helper apontando para seus servidores DHCP primário e secundário. Verifique o roteamento de ponta a ponta entre o IP da interface de relay (que o servidor DHCP usa para determinar qual escopo de sub-rede atribuir) e o próprio servidor DHCP.
4. Tempestades de Broadcast e Multicast
O Mecanismo: O tráfego excessivo de broadcast ou multicast em uma VLAN satura o meio sem fio. Como o Wi-Fi é um meio half-duplex compartilhado, os APs e clientes devem esperar que as frequências estejam livres antes de transmitir. Uma tempestade de broadcast — frequentemente causada por loops de comutação, placas de interface de rede com falha ou protocolos peer-to-peer agressivos — preenche o tempo de transmissão aérea, fazendo com que os pacotes DHCP sejam enfileirados, atrasados ou descartados.
O Contexto de Alta Densidade: Em redes Wi-Fi grandes e planas sem o isolamento adequado de Camada 2, o tráfego de broadcast peer-to-peer (como Apple AirPlay, Google Chromecast ou descoberta de rede do Windows) é replicado por todos os APs na VLAN. Em um local com 10.000 usuários, esse "ruído" de fundo pode consumir mais de 50% da largura de banda sem fio disponível, deixando tempo de transmissão insuficiente para os pacotes críticos de handshake do DHCP.
Remediação: Habilite o Isolamento de Cliente (também conhecido como bloqueio peer-to-peer) no controlador sem fio para evitar que os clientes se comuniquem diretamente entre si. Configure a Supressão de Broadcast e Multicast nos APs e switches, limitando o tráfego de broadcast a uma pequena porcentagem da capacidade do link (por exemplo, 100 pacotes por segundo). Onde houver suporte, habilite o DHCP Proxy nos APs para converter ofertas e confirmações de DHCP em broadcast para quadros unicast direcionados especificamente ao cliente solicitante.
5. Ponto Único de Falha (Falta de Redundância de DHCP)
O Mecanismo: Um servidor DHCP único e não redundante representa uma vulnerabilidade crítica. Se o servidor travar, passar por atualizações de sistema ou perder a conectividade de rede, a capacidade de integração de toda a rede é interrompida imediatamente. As concessões existentes permanecem ativas, mas nenhum cliente novo consegue obter um endereço IP, e os clientes em roaming não conseguem renovar suas concessões.
O Contexto de Alta Densidade: Locais de alta densidade operam sob SLAs operacionais rígidos. Um estádio durante uma partida ou um centro de convenções durante uma palestra não podem tolerar sequer cinco minutos de inatividade do DHCP. Confiar em um único roteador ou em uma única máquina virtual para lidar com milhares de solicitações rápidas de concessão é uma arquitetura de alto risco.
Remediação: Implante o DHCP em uma configuração de alta disponibilidade. Use o Windows Server DHCP Failover no modo de Equilíbrio de Carga (divisão de 50/50) ou no modo Hot Standby, ou implemente appliances DHCP redundantes de nível empresarial (como Infoblox ou BlueCat) [5]. Certifique-se de que seus servidores DHCP estejam distribuídos física ou logicamente em diferentes hipervisores e caminhos de rede para eliminar falhas de modo comum.
6. Servidores DHCP Falsos (Rogue DHCP)
O Mecanismo: Um servidor DHCP falso é um dispositivo habilitado para DHCP não autorizado conectado à rede. Ele intercepta as transmissões de DHCPDISCOVER do cliente e responde com seus próprios pacotes DHCPOFFER, muitas vezes distribuindo configurações de IP incorretas, gateways padrão errados ou servidores DNS maliciosos.
O Contexto de Alta Densidade: Em grandes locais de eventos, lojas de varejo ou escritórios do setor público, as portas Ethernet físicas geralmente ficam acessíveis em áreas públicas, ou os usuários podem trazer dispositivos não autorizados (como roteadores de viagem de consumo ou máquinas virtuais executando rede em ponte) e conectá-los na tomada. Isso leva a conflitos de endereço IP, buracos negros de roteamento e sérios riscos de segurança, incluindo ataques man-in-the-middle.
Remediação: Ative o DHCP Snooping em todos os switches de acesso e distribuição [6]. O DHCP snooping designa as portas do switch como "confiáveis" (conectadas a servidores DHCP legítimos ou agentes de retransmissão) ou "não confiáveis" (conectadas a clientes). O switch descartará automaticamente qualquer resposta do servidor DHCP (como DHCPOFFER ou DHCPACK) originada de uma porta não confiável, neutralizando servidores falsos instantaneamente.
7. Firewalls, ACLs e Políticas de Segurança Bloqueando UDP 67/68
O Mecanismo: O DHCP depende da porta UDP 67 (escuta do lado do servidor e destino do lado do cliente) e da porta UDP 68 (escuta do lado do cliente e destino do lado do servidor). Se firewalls de rede, Listas de Controle de Acesso (ACLs) do switch ou políticas de segurança de endpoint bloquearem essas portas, o handshake DORA não poderá ser concluído. O Contexto de Alta Densidade: O endurecimento da segurança é uma prioridade para redes corporativas. No entanto, políticas de segurança excessivamente agressivas costumam bloquear inadvertidamente o tráfego DHCP. Por exemplo, durante uma migração de firewall ou uma atualização de política, um administrador pode bloquear todo o tráfego UDP em um segmento sem perceber que quebrou o caminho do DHCP. Da mesma forma, as políticas de segurança de VLAN de visitantes devem permitir explicitamente as portas UDP 67 e 68 antes de redirecionar o tráfego para um Captive Portal.
Correção: Audite todas as ACLs e regras de firewall ao longo do caminho entre os clientes sem fio, os APs, os switches de Camada 3 e os servidores DHCP. Certifique-se de que as portas UDP 67 e 68 estejam explicitamente permitidas em ambas as direções. Ao solucionar problemas, realize uma captura de pacotes na interface de rede do servidor DHCP para confirmar se os pacotes DHCPDISCOVER estão realmente chegando.
8. Erros de Configuração de VLAN e Trunking
O Mecanismo: Se o SSID de um cliente mapeia para uma VLAN específica, mas essa VLAN não está marcada (tagged) ou em trunking corretamente de ponta a ponta na infraestrutura de switching, as transmissões DHCP do cliente nunca chegarão ao gateway padrão ou ao agente de relay DHCP.
O Contexto de Alta Densidade: Redes WiFi de alta densidade usam atribuição dinâmica de VLAN ou pooling multi-VLAN para distribuir a carga dos clientes. Se uma única porta de trunk de switch ao longo do caminho do AP ao switch core estiver sem uma tag de VLAN em sua lista de permissões, um subconjunto de clientes — especificamente aqueles atribuídos àquela VLAN — sofrerá timeouts de DHCP imediatos e persistentes, enquanto outros clientes no mesmo SSID se conectarão com sucesso. Isso cria cenários de suporte altamente intermitentes e difíceis de diagnosticar.
Correção: Implemente ferramentas automatizadas de gerenciamento e validação de configuração de rede. Ao configurar portas de trunk de switch, sempre use listas de permissões explícitas (por exemplo, switchport trunk allowed vlan 10,20,30) em vez de depender das configurações padrão "all", e verifique se a VLAN nativa coincide em ambas as extremidades do link de trunk para evitar vazamentos de tráfego não marcado.
9. Bugs de Firmware e Driver de Access Point
O Mecanismo: O firmware do access point é responsável por fazer a ponte entre os frames sem fio 802.11 e a rede ethernet cabeada 802.3. Um bug de software no driver sem fio do AP ou no mecanismo de bridging pode fazer com que o AP descarte pacotes DHCP, principalmente sob alta carga de CPU ou memória.
O Contexto de Alta Densidade: Redes de alta densidade levam o hardware e o software dos APs ao limite. Um bug que permanece dormente sob uma carga leve de 10 clientes pode desencadear falhas catastróficas quando o AP está lidando com 100 clientes ativos simultâneos. Por exemplo, um bug documentado no início de 2026 em determinados APs WiFi 7 fazia com que o AP descartasse de forma intermitente o terceiro pacote do handshake (o DHCPREQUEST), impedindo que o cliente recebesse seu DHCPACK e concluísse a integração.
Remediação: Mantenha uma política rigorosa de gerenciamento de ciclo de vida para o firmware dos APs. Evite implantar versões de firmware "de ponta" diretamente em ambientes de produção. Estabeleça um ambiente de homologação que simule condições de alta densidade e monitore de perto as notas de lançamento dos fabricantes e os fóruns da comunidade para identificar bugs conhecidos relacionados ao DHCP. Se o diagnóstico revelar que os pacotes DHCPDISCOVER são enviados pelo cliente, mas nunca vistos na porta de uplink cabeada do AP, suspeite de um bug de bridging no AP.
10. Roaming de Cliente Agressivo e Limites de Camada 3
O Mecanismo: Quando um cliente sem fio se move (roaming) de um AP para outro, ele deve manter sua sessão de rede. Se o roaming cruzar um limite de Camada 3 (movendo o cliente para uma sub-rede diferente), o cliente deve obter um novo endereço IP. Se o sistema operacional do cliente ou a rede sem fio não conseguirem lidar com essa transição de forma suave, o cliente tentará usar seu endereço IP antigo na nova sub-rede, levando a timeouts de conexão e falhas de renegociação DHCP.
O Contexto de Alta Densidade: Locais de alta densidade exigem centenas de APs para fornecer cobertura adequada. Os clientes estão constantemente em movimento — por exemplo, hóspedes de hotéis caminhando de seus quartos para o salão de conferências, ou clientes de varejo se deslocando por um shopping [7]. Se a arquitetura de rede mapear diferentes áreas físicas do local para diferentes sub-redes, ocorrerá um alto volume de roamings de Camada 3, sobrecarregando o servidor DHCP com eventos rápidos de liberação e solicitação.
Remediação: Projete redes sem fio de alta densidade usando uma arquitetura plana de Camada 2 em todo o SSID do cliente ou implemente tunelamento baseado em controladora sem fio (como GRE ou CAPWAP) [8]. O tunelamento garante que o tráfego de um cliente seja sempre ancorado de volta à sua controladora de origem e VLAN originais, independentemente de para qual AP físico ele faça o roaming, eliminando completamente os eventos de roaming de Camada 3 e o overhead de DHCP associado.
Guia de Implementação
Para eliminar sistematicamente os timeouts de DHCP, os arquitetos de rede devem fazer a transição de um diagnóstico reativo para uma arquitetura proativa e padronizada. Siga este guia de implantação passo a passo para robustecer sua infraestrutura DHCP.
Passo 1: Dimensionamento de Sub-rede e Arquitetura CIDR
Nunca use sub-redes /24 padrão para redes de convidados de alta densidade. Calcule seus requisitos de IP com base na capacidade de pico mais uma margem de segurança de 50% para acomodar usuários com vários dispositivos e rotatividade transitória.
| Máscara de Sub-rede | CIDR | Endereços IP Usáveis | Melhor Caso de Uso |
|---|---|---|---|
255.255.255.0 |
/24 |
254 | Equipe administrativa, impressoras, IoT de back-of-house |
255.255.254.0 |
/23 |
510 | Pequenos hotéis boutique, lojas de varejo localizadas |
255.255.252.0 |
/22 |
1.022 | Grandes hotéis, salas de conferência de alta densidade, campi universitários |
255.255.248.0 |
/21 |
2.046 | Grandes pavilhões de exposição, shoppings, praças públicas |
255.255.240.0 |
/20 |
4.094 | Estádios, arenas, centros de convenções massivos |
Passo 2: Otimizando Tempos de Lease DHCP
Configure seu servidor DHCP para impor tempos de lease com base no comportamento do usuário do segmento de rede específico:
Guest WiFi SSID (Alta Rotatividade) -> Tempo de Lease: 30 a 60 Minutos
Corporate Staff SSID (Estável) -> Tempo de Lease: 8 a 12 Horas
Venue IoT & Infraestrutura -> Tempo de Lease: 7 Dias (ou Reserva Estática)
Nota: Reduzir os tempos de lease aumenta a frequência das solicitações de renovação de DHCP (que ocorrem em 50% da duração do lease, conhecido como T1) [9]. Certifique-se de que o hardware do seu servidor DHCP tenha desempenho de CPU e I/O suficiente para lidar com a taxa de solicitação elevada.
Passo 3: Configurando Agentes de Relay DHCP em Switches Layer 3
Ao configurar agentes de relay DHCP, sempre especifique endereços auxiliares redundantes apontando para servidores DHCP independentes. Abaixo está um modelo de configuração padrão e independente de fornecedor para uma interface de switch Cisco iOS Layer 3:
interface Vlan30
description High_Density_Guest_WiFi
ip address 192.168.30.1 255.255.252.0
ip helper-address 10.10.10.10 # Servidor DHCP Primário
ip helper-address 10.10.10.11 # Servidor DHCP Secundário
ip dhcp relay information option # Insere a Opção 82 para rastreamento de localização
no shutdown
Passo 4: Reforçando a Segurança de Layer 2 com DHCP Snooping
Evite servidores DHCP não autorizados e mitigue ataques de esgotamento de DHCP (DHCP starvation) ativando o DHCP snooping em toda a sua estrutura de switching. Abaixo está um modelo de configuração para um switch de acesso de borda:
# Ativar DHCP snooping globalmente
ip dhcp snooping
# Ativar DHCP snooping para VLANs de clientes específicas
ip dhcp snooping vlan 10,20,30
# Configurar a porta de uplink para o switch core/servidor DHCP como CONFIÁVEL (TRUSTED)
interface GigabitEthernet1/0/48
description UPLINK_TO_CORE
ip dhcp snooping trust
# Configurar portas voltadas para o cliente como NÃO CONFIÁVEIS e limitar a taxa de pacotes DHCP para evitar ataques de esgotamento
interface range GigabitEthernet1/0/1 - 47
description CLIENT_ACCESS_PORTS
ip dhcp snooping limit rate 15
Melhores Práticas
Para manter uma rede sem fio resiliente e de alto desempenho, incorpore estas melhores práticas padrão do setor em seus manuais operacionais:
1. Implementar a Opção 82 do DHCP (Relay Agent Information Option)
A Opção 82 do DHCP permite que o agente de relay insira informações específicas do circuito (como o ID da porta do switch ou o endereço MAC do AP) na solicitação DHCP antes de encaminhá-la para o servidor [10]. Isso permite que o servidor DHCP imponha políticas de alocação de IP altamente granulares com base na localização física do cliente dentro do local. Por exemplo, um hotel pode atribuir pools de IP ou configurações de DNS diferentes para clientes no centro de convenções em comparação com os dos quartos de hóspedes, otimizando a utilização do pool.
2. Ativar a Conversão de Broadcast-para-Unicast de ARP e DHCP
Configure seu controlador de LAN sem fio (WLC) ou APs gerenciados em nuvem para interceptar pacotes ARP e DHCP de broadcast da Camada 2 e convertê-los em quadros unicast antes de transmiti-los pelo ar. Como os quadros unicast são transmitidos na taxa de dados máxima suportada pelo cliente (em vez da taxa de broadcast obrigatória mais baixa), essa alteração simples de configuração reduz drasticamente o consumo de tempo de transmissão de RF e melhora a confiabilidade do DHCP em ambientes de alta densidade.
3. Estabeleça Monitoramento e Alertas Proativos de DHCP
Não espere que os usuários relatem falhas de conexão. Configure seu Sistema de Gerenciamento de Rede (NMS) ou ferramentas de monitoramento do servidor DHCP para rastrear métricas fundamentais e disparar alertas imediatos:
- Utilização do Pool: Dispare um alerta de aviso com 75% de utilização e um alerta crítico com 85%.
- Taxa de Solicitações DHCP: Monitore picos repentinos de solicitações, que podem indicar uma tempestade de broadcast, um loop de roaming ou um ataque de esgotamento de DHCP (DHCP starvation).
- Distribuição de Expiração de Concessão (Lease): Garanta que as concessões estejam expirando de forma gradual e que o banco de dados esteja recuperando ativamente os endereços IP.
Solução de Problemas e Mitigação de Riscos
Quando houver suspeita de timeout de DHCP, siga este fluxo de trabalho de diagnóstico sistemático para isolar o ponto de falha rapidamente e minimizar as interrupções nos negócios.
[Cliente se Associa ao AP]
│
▼
[Capturar Pacotes no Cliente] ───► O DHCPDISCOVER foi enviado?
│ ├── NÃO: Problema de SO/Driver do Cliente.
│ └── SIM
▼
[Capturar Pacotes no Switch] ───► O DHCPDISCOVER chega ao Switch?
│ ├── NÃO: Problema de Bridging do AP/Tagging de VLAN.
│ └── SIM
▼
[Capturar Pacotes no Servidor] ──► O DHCPDISCOVER chega ao Servidor?
│ ├── NÃO: Problema de Agente de Retransmissão / Roteamento / Firewall.
│ └── SIM
▼
[Verificar Logs do Servidor] ───► O DHCPOFFER foi enviado?
├── NÃO: Pool Esgotado / Escopo Inativo.
└── SIM: Caminho de retorno bloqueado (VLAN/Roteamento).
Comandos Principais para Solução de Problemas
Para verificar o status do DHCP e diagnosticar falhas em equipamentos de rede em produção, use os seguintes comandos:
Cisco IOS (Servidor DHCP ou Relay)
# Visualizar a utilização do pool DHCP e endereços livres
show ip dhcp pool
# Visualizar vinculações ativas de endereços IP
show ip dhcp binding
# Monitorar estatísticas do servidor DHCP (contagens de discover, request, ack)
show ip dhcp server statistics
# Visualizar o banco de dados de conflitos DHCP (IPs marcados como ruins devido a conflitos)
show ip dhcp conflict
Linux (Servidor ou Cliente DHCP)
# Visualizar solicitações de concessão de cliente DHCP em tempo real em um cliente Linux
sudo dhclient -v wlan0
# Capturar tráfego DHCP (portas UDP 67 e 68) em uma interface específica
sudo tcpdump -i eth0 -n -vv 'udp and (port 67 or port 68)'
# Verificar o banco de dados de concessões DHCP do dnsmasq
cat /var/lib/misc/dnsmasq.leases
Windows (Cliente DHCP)
# Release current IP address
ipconfig /release
# Renew IP address (initiates a new DHCP handshake)
ipconfig /renew
ROI e Impacto nos Negócios
Investir em uma infraestrutura DHCP altamente resiliente e bem arquitetada não é apenas uma necessidade técnica — é um habilitador de negócios crítico que impacta diretamente o resultado final e a eficiência operacional.
Quantificando o Valor de Negócio de um Onboarding Sem Fricção
- Melhoria da Experiência do Hóspede e Fidelidade à Marca: Nos setores de hotelaria e eventos, a conectividade sem fio é um dos principais impulsionadores da satisfação dos hóspedes. Um hóspede que encontra fricção no onboarding tem grande probabilidade de deixar avaliações negativas, impactando diretamente as taxas de reserva. A eliminação dos timeouts de DHCP garante uma primeira impressão sem fricção.
- Maximizando o ROI do Marketing de Guest WiFi: Para locais de varejo e entretenimento, o Guest WiFi é um canal de marketing poderoso. Ao garantir uma taxa de sucesso de onboarding de 100%, as equipes de marketing podem capturar mais dados primários (como e-mails, dados demográficos e padrões de tráfego de pedestres) por meio do WiFi Analytics , impulsionando campanhas de engajamento altamente direcionadas e aumentando o valor do tempo de vida do cliente (LTV).
- Redução de Custos de Suporte de TI: Os chamados relacionados a DHCP ("Não é possível conectar ao WiFi", "Erro de Endereço IP") estão entre as solicitações mais frequentes e demoradas para as equipes de suporte de TI. Ao implementar redundância de DHCP, dimensionar os pools corretamente e implantar o DHCP snooping, as organizações podem reduzir os chamados de suporte relacionados a redes sem fio em até 40%, permitindo que a equipe de TI se concentre em iniciativas estratégicas em vez de resolução de problemas básicos.
- Garantindo Segurança e Conformidade Regulatória: A implementação do DHCP snooping e a mitigação de servidores DHCP invasores apoiam diretamente a conformidade com os principais padrões de segurança, como PCI DSS (para ambientes de pagamento de varejo) e GDPR (ao proteger as redes de dados de convidados). Uma arquitetura DHCP segura e bem documentada mitiga o risco de violações de dados dispendiosas e multas regulatórias.
Tabela de Resumo de Impacto nos Negócios
| Métrica | Antes da Otimização | Após a Otimização | Impacto nos Negócios |
|---|---|---|---|
| Taxa de Timeout de DHCP | 8,5% (Durante horários de pico) | < 0,1% | Onboarding de usuários sem fricção, eliminação de reclamações de conexão |
| Tempo Médio de Resolução (MTTR) | 45 Minutos | < 5 Minutos | Resolução rápida de problemas por meio do mapeamento documentado de VLAN/escopo |
| Taxa de Opt-In do Guest WiFi | 62% | 88% | Maior crescimento da base de dados de marketing, captura de dados mais ricos |
| Volume de Chamados de Suporte de TI | Alto (Erros de DHCP/IP) | Negligível | Redução de 40% nos chamados de helpdesk relacionados a redes sem fio |
Referências
- IETF RFC 2131 - Dynamic Host Configuration Protocol
- IEEE 802.11-2020 - Wireless LAN Medium Access Control and Physical Layer Specifications
- Otimizando tempos de concessão (Lease Times) de DHCP de WiFi para dispositivos móveis
- IETF RFC 3046 - Opção de Informações do Agente de Relé DHCP
- IETF RFC 8156 - Protocolo de Failover DHCPv4
- Cisco Systems - Configurando DHCP Snooping
- Por que o WiFi de estádios desacelera (e como corrigir isso)
- HPE Aruba Networking - Guia de Projeto e Implantação de Wi-Fi em Grandes Locais Públicos
- Como solucionar problemas de DHCP em redes WiFi
- IETF RFC 3993 - Sub-opção de ID do Assinante para Opção de Informações do Agente de Relé DHCP
Definições principais
DHCP (Dynamic Host Configuration Protocol)
Um protocolo de gerenciamento de rede usado em redes de Protocolo de Internet (IP) pelo qual um servidor DHCP atribui dinamicamente um endereço IP e outros parâmetros de configuração de rede a cada dispositivo em uma rede, para que eles possam se comunicar com outras redes IP.
O DHCP é a primeira etapa crítica na integração sem fio; se ele falhar, os clientes não conseguirão acessar nenhum recurso da rede, incluindo os portais de convidados.
Processo DORA
A sequência padrão de quatro etapas de mensagens trocadas entre um cliente DHCP e um servidor para negociar o aluguel de um endereço IP: DHCPDISCOVER, DHCPOFFER, DHCPREQUEST e DHCPACK.
Compreender a sequência DORA é essencial para diagnosticar onde um handshake DHCP está falhando durante a resolução de problemas de rede.
Agente de Relay DHCP
Qualquer host ou dispositivo de rede (normalmente um switch ou roteador de Camada 3) que encaminha pacotes DHCP entre clientes e servidores quando eles residem em diferentes sub-redes ou VLANs.
Os agentes de relay são necessários em redes corporativas segmentadas para centralizar os serviços DHCP e evitar que o tráfego de broadcast atravesse os limites do roteador.
DHCP Snooping
Um recurso de segurança de Camada 2 integrado a switches gerenciados que filtra mensagens DHCP não confiáveis e cria um banco de dados de vinculação de mapeamentos confiáveis de MAC para IP.
O DHCP snooping é a principal defesa contra servidores DHCP não autorizados e ataques man-in-the-middle em redes corporativas sem fio.
Esgotamento do Pool de IP
Uma condição que ocorre quando todos os endereços IP disponíveis dentro do escopo configurado de um servidor DHCP foram concedidos, não deixando endereços disponíveis para novos clientes.
O esgotamento do pool é a principal causa de timeouts de DHCP em locais de alta densidade e é resolvido ajustando o tamanho dos escopos ou reduzindo o tempo de concessão (lease).
Tempo de Concessão DHCP (DHCP Lease Time)
A duração de tempo pela qual um servidor DHCP aloca um endereço IP a um dispositivo cliente específico antes que o cliente precise solicitar a renovação da concessão.
Otimizar os tempos de concessão com base no comportamento do usuário (curto para redes de convidados, mais longo para funcionários) é crítico para manter a eficiência do pool de IP.
Servidor DHCP Não Autorizado (Rogue DHCP Server)
Um servidor DHCP não autorizado conectado a uma rede que distribui configurações de IP inválidas ou maliciosas para os clientes, levando a problemas de conectividade e vulnerabilidades de segurança.
Servidores não autorizados são comuns em locais públicos abertos e são neutralizados habilitando o DHCP snooping nos switches de acesso.
Supressão de Broadcast
Uma técnica de configuração de rede que limita a taxa de tráfego de broadcast e multicast em uma VLAN ou porta de switch para evitar congestionamento de rede e tempestades de broadcast.
A supressão de broadcast é crítica em redes sem fio de alta densidade para proteger o tempo de transmissão de RF (RF airtime) e garantir que pacotes DHCP críticos não sofram atrasos.
Exemplos práticos
Um centro de conferências de alta densidade com um auditório plenário principal projetado para acomodar 2.500 participantes está enfrentando falhas massivas de integração ao WiFi durante a palestra de abertura. Os participantes relatam que seus dispositivos ficam travados em "Obtendo endereço IP" por vários minutos, e aqueles que conseguem se conectar são frequentemente desconectados ao se moverem entre o auditório plenário e a área de exposição. A configuração de rede atual usa uma única VLAN de cliente mapeada para uma sub-rede `/24` padrão com um tempo de concessão DHCP de 24 horas, servida por um único roteador principal. Como essa rede deve ser rearquiteta para eliminar essas falhas?
Para resolver essas falhas de integração, a arquitetura de rede deve ser redesenhada para lidar com o comportamento de clientes transitórios de alta densidade. Siga este fluxo de trabalho de remediação em várias etapas:
Expandir o Espaço de Endereço IP (Dimensionamento de Sub-rede): Substitua a sub-rede
/24padrão (que fornece apenas 254 endereços IP) por uma sub-rede/21(fornecendo 2.046 endereços IP utilizáveis) ou implemente um pool multi-VLAN. Isso garante que o pool de IPs seja dimensionado de forma suficiente para lidar com 2.500 participantes simultâneos, muitos dos quais carregarão vários dispositivos conectados (média de 1,5 dispositivos por participante = 3.750 IPs necessários). Se uma única sub-rede/20plana (4.094 IPs) for usada, ela acomodará facilmente toda a capacidade do evento.Otimizar os Tempos de Concessão DHCP: Reduza o tempo de concessão DHCP de 24 horas para 45 minutos na rede sem fio de convidados. Como os participantes da conferência são altamente transitórios e entram e saem do auditório plenário, um tempo de concessão curto garante que os endereços IP sejam rapidamente recuperados de dispositivos que deixaram a área, evitando o esgotamento artificial do pool.
Implantar Servidores DHCP Redundantes: Elimine o ponto único de falha implantando um par de servidores DHCP redundantes. Configure o failover de DHCP do Windows Server no modo de Compartilhamento de Carga (divisão 50/50) em duas máquinas virtuais independentes ou use um dispositivo DHCP dedicado de alta disponibilidade. Isso garante que, se um servidor ou caminho de rede falhar, o servidor restante possa lidar com toda a carga de solicitações.
Implementar Supressão de Broadcast de Camada 2 e DHCP Proxy: Ative a supressão de broadcast na controladora sem fio, limitando o tráfego de broadcast a 100 pacotes por segundo. Ative o DHCP Proxy nos pontos de acesso para converter mensagens broadcast
DHCPOFFEReDHCPACKem quadros unicast. Isso reduz drasticamente o consumo de tempo de transmissão sem fio e evita colisões de pacotes.Configurar DHCP Snooping e Validação ARP: Ative o DHCP snooping em todos os switches de acesso para proteger a rede contra servidores DHCP não autorizados e evitar ataques de esgotamento de DHCP. Limite a taxa de pacotes DHCP nas portas voltadas para o cliente a 15 pacotes por segundo.
Um hotel de luxo com 500 quartos está implantando um novo SSID de convidados em toda a sua propriedade. A equipe de rede criou uma nova VLAN de convidados (VLAN 50) e configurou um servidor DHCP Windows central com um escopo `/22` correspondente. No entanto, durante os testes, os dispositivos associados ao SSID de convidados nos quartos do hotel estão falhando em obter um endereço IP e apresentando timeout, enquanto os dispositivos conectados diretamente às portas cabeadas nos escritórios administrativos (VLAN 10) estão obtendo endereços IP instantaneamente. Qual é a causa mais provável desse problema e como ele deve ser diagnosticado e resolvido?
O fato de os clientes cabeados na VLAN 10 estarem obtendo endereços IP enquanto os clientes sem fio na VLAN 50 estão apresentando timeout indica que o problema é específico do caminho ou da configuração da VLAN 50. A causa mais provável é a ausência ou má configuração de um Agente de Retransmissão DHCP (IP Helper) na interface do switch de Camada 3 para a VLAN 50, ou uma tag de VLAN ausente ao longo do caminho de tronco entre os pontos de acesso e o switch principal. Siga este fluxo de trabalho de diagnóstico e resolução:
Verificar a Configuração do Agente de Retransmissão DHCP: Faça login no switch de Camada 3 principal (ou gateway) e inspecione a configuração da interface da VLAN 50. Certifique-se de que o comando
ip helper-addressestá presente e aponta para o endereço IP correto do servidor DHCP Windows. Se o comando estiver ausente, o switch não encaminhará os pacotes broadcastDHCPDISCOVERdo cliente para o servidor DHCP.Verificar o Trunking de VLAN Ponta a Ponta: Verifique se a VLAN 50 está tagueada em todas as portas de switch ao longo do caminho dos APs até o switch principal. Use comandos como
show interfaces trunkem switches Cisco para confirmar que a VLAN 50 é permitida e está ativa em todos os links de tronco. Se a VLAN 50 estiver ausente de apenas uma porta de tronco, os broadcasts de DHCP do cliente serão descartados antes de chegarem ao switch de Camada 3.Realizar Capturas de Pacotes: Para isolar o ponto de falha, realize capturas de pacotes simultâneas em três locais:
- No cliente sem fio (usando Wireshark ou ferramentas nativas do SO) para confirmar que os broadcasts
DHCPDISCOVERestão sendo enviados. - Na interface do switch de Camada 3 para a VLAN 50 para confirmar que o switch está recebendo os broadcasts.
- Na interface de rede do servidor DHCP para confirmar que os pacotes DHCP unicast encaminhados estão chegando.
- No cliente sem fio (usando Wireshark ou ferramentas nativas do SO) para confirmar que os broadcasts
Verificar a Ativação do Escopo do Servidor DHCP: Certifique-se de que o escopo DHCP para a sub-rede da VLAN 50 (por exemplo, 192.168.50.0/22) está totalmente criado, ativado e possui um intervalo ativo de endereços IP que não conflite com nenhuma atribuição estática.
Aplicar a Correção de Configuração: No switch de Camada 3 principal, aplique a configuração correta do endereço do helper:
interface Vlan50 description Guest_WiFi_VLAN ip address 192.168.50.1 255.255.252.0 ip helper-address 10.10.10.10 # Windows DHCP Server IP no shutdown
Um grande shopping center com mais de 150 lojas de varejo está enfrentando quedas de conexão WiFi altamente intermitentes. A equipe de TI relata que alguns clientes se conectam instantaneamente e navegam sem problemas, enquanto outros no mesmo local ficam travados em "Obtendo endereço IP" ou recebem um aviso de "Sem Conexão com a Internet". Uma revisão dos logs do servidor DHCP mostra milhares de concessões ativas, mas também um alto volume de erros de "Conflito de DHCP" e várias instâncias em que o servidor está respondendo aos clientes com um `DHCPNAK` (Confirmação Negativa). Como esse problema deve ser investigado e resolvido?
A presença de erros de "Conflito de DHCP" e respostas DHCPNAK nos logs do servidor sugere fortemente a presença de um servidor DHCP não autorizado na rede ou um conflito de endereço IP causado por atribuições estáticas dentro do intervalo DHCP. Siga este fluxo de trabalho sistemático de investigação e remediação:
Isolar e Detectar o Servidor DHCP Não Autorizado: Use os logs do banco de dados de DHCP snooping nos switches de acesso para identificar atividades não autorizadas de servidores DHCP. Execute o seguinte comando em seus switches principais e de acesso para visualizar quaisquer conflitos detectados ou pacotes DHCP não confiáveis:
show ip dhcp snooping database show ip dhcp conflictO banco de dados de conflitos listará os endereços MAC dos dispositivos que responderam às investigações ARP para IPs que o servidor DHCP estava tentando atribuir, ou dispositivos que estão distribuindo ativamente concessões não autorizadas.
Ativar o DHCP Snooping Globalmente e nas VLANs de Clientes: Para neutralizar imediatamente quaisquer servidores DHCP não autorizados, ative o DHCP snooping em todos os switches. Configure todas as portas voltadas para o cliente como não confiáveis e confie apenas nas portas específicas conectadas aos seus servidores DHCP legítimos ou links de tronco principais. Isso garante que quaisquer pacotes
DHCPOFFERouDHCPACKnão autorizados sejam descartados na porta do switch antes que possam alcançar outros clientes.Configurar Inspeção ARP (DAI): Para evitar que os clientes usem endereços IP falsificados ou causem conflitos de IP, ative a Inspeção ARP Dinâmica (DAI) nas VLANs de clientes. A DAI usa o banco de dados de vinculação do DHCP snooping para validar os pacotes ARP, descartando quaisquer pacotes com mapeamentos MAC-para-IP inválidos:
ip arp inspection vlan 10,20,30Excluir IPs Estáticos do Pool DHCP: Certifique-se de que quaisquer endereços IP estáticos atribuídos a dispositivos de infraestrutura (como impressoras, APs ou sinalização digital) sejam explicitamente excluídos do intervalo do escopo DHCP no servidor para evitar que o servidor ofereça acidentalmente esses IPs aos clientes.
Implantar Segurança de Porta e 802.1X: Para portas cabeadas em lojas de varejo ou áreas públicas, implemente a Segurança de Porta para limitar o número de endereços MAC permitidos em uma porta, ou implante a autenticação 802.1X para impedir que dispositivos não autorizados se conectem à estrutura de rede física.
Questões práticas
Q1. Um gerente de TI em um grande shopping center percebe que, durante as horas de pico de compras de fim de ano, as conexões de WiFi para convidados falham frequentemente. O log do servidor DHCP está inundado com erros "DHCP Scope Full". A VLAN de convidados atual está configurada com uma máscara de sub-rede `/23` e um tempo de concessão (lease time) padrão de 24 horas. Quais são as duas alterações de configuração mais imediatas e eficazes que o gerente deve implementar para resolver esse problema e por quê?
Dica: Considere a relação entre o tamanho da sub-rede, o tempo de permanência do cliente e a recuperação de endereços IP.
Ver resposta modelo
O gerente deve implementar as seguintes duas alterações imediatas de configuração:
Reduzir o DHCP Lease Time: Diminuir o tempo de concessão de 24 horas para 30 ou 45 minutos. Como os visitantes do shopping são altamente transitórios (o tempo de permanência típico é de 1 a 2 horas), uma concessão de 24 horas faz com que o servidor DHCP retenha os endereços IP muito tempo depois que os convidados já foram embora. A redução do lease time garante que os endereços IP sejam rapidamente recuperados e disponibilizados para novos clientes, multiplicando efetivamente a capacidade do pool existente sem alterar a estrutura da sub-rede.
Expandir o Escopo da Sub-rede (Dimensionamento CIDR): Expandir a sub-rede da VLAN de convidados de um
/23(fornecendo 510 endereços IP utilizáveis) para um/21(fornecendo 2.046 endereços IP utilizáveis) ou um/20(fornecendo 4.094 endereços IP utilizáveis). Uma sub-rede/23é muito pequena para um grande shopping center durante as horas de pico, especialmente considerando que muitos clientes carregam múltiplos dispositivos conectados (telefones, wearables, tablets). A expansão do escopo garante que haja bastantes endereços IP disponíveis para lidar com a carga de pico de dispositivos simultâneos.
Essas duas alterações funcionam em conjunto: a expansão da sub-rede aumenta a capacidade absoluta do pool, enquanto a redução do lease time garante a máxima eficiência no reuso de endereços, eliminando completamente os erros "DHCP Scope Full".
Q2. Um engenheiro de rede está solucionando problemas em um SSID de convidados recém-implantado em um hotel. Os clientes sem fio se associam ao AP com sucesso, mas não conseguem obter um endereço IP, expirando após vários segundos. Uma captura de pacotes na porta do switch conectada ao AP mostra broadcasts `DHCPDISCOVER` entrando no switch, mas uma captura na interface de rede do servidor DHCP central não mostra pacotes recebidos vindos da sub-rede de convidados do hotel. O servidor DHCP está localizado em uma sub-rede diferente (10.10.10.0/24) da dos clientes sem fio de convidados (192.168.50.0/22). Qual configuração está faltando, em qual dispositivo ela deve ser aplicada e qual é o comando exato para aplicá-la?
Dica: Como o servidor DHCP está em uma sub-rede diferente da dos clientes, um dispositivo de Camada 3 deve encaminhar o tráfego de broadcast.
Ver resposta modelo
A configuração que está faltando é o Agente de Retransmissão DHCP (IP Helper). Como as mensagens de descoberta de DHCP são broadcasts de Camada 2, elas não podem cruzar o roteador ou o limite de Camada 3 entre a sub-rede de convidados do cliente (192.168.50.0/22) e a sub-rede do servidor DHCP (10.10.10.0/24). Sem um agente de retransmissão, o switch ou roteador descartará os pacotes de broadcast, impedindo que cheguem ao servidor.
Esta configuração deve ser aplicada no Switch de Camada 3 ou Gateway de Segurança que atua como o gateway padrão para a VLAN sem fio de convidados (VLAN 50).
Assumindo um switch Cisco IOS de Camada 3, o engenheiro deve aplicar o comando ip helper-address à interface da VLAN 50, apontando para o endereço IP do servidor DHCP central (ex: 10.10.10.10):
interface Vlan50
description Guest_WiFi_Gateway
ip address 192.168.50.1 255.255.252.0
ip helper-address 10.10.10.10
no shutdown
Este comando instrui o switch a interceptar os broadcasts DHCP na VLAN 50, convertê-los em pacotes unicast de Camada 3 com o IP de origem do gateway da VLAN 50 (192.168.50.1) e encaminhá-los diretamente para o servidor DHCP em 10.10.10.10. O servidor usará então o IP do gateway para selecionar o escopo correto e retornar uma oferta.
Q3. Um arquiteto de rede de estádio está projetando uma rede sem fio para suportar 50.000 torcedores simultâneos. Para minimizar o tráfego de broadcast e o consumo de tempo de transmissão de RF (airtime), o arquiteto quer implementar a supressão de broadcast e converter os broadcasts DHCP em unicast. No entanto, alguns engenheiros juniores expressam preocupação de que a conversão de broadcasts DHCP para unicast quebre o protocolo DHCP, já que os clientes ainda não possuem um endereço IP para receber pacotes unicast. Como o arquiteto deve explicar o mecanismo técnico da conversão de broadcast para unicast para sanar essas preocupações?
Dica: Considere como o Access Point faz a ponte dos frames de Camada 2 e como o endereço MAC do cliente é usado no cabeçalho 802.11.
Ver resposta modelo
O arquiteto deve explicar que a conversão de broadcasts DHCP para unicast não quebra o protocolo DHCP porque o Access Point (AP) opera na Camada 2 e pode direcionar frames diretamente para o endereço MAC físico do cliente, mesmo que o cliente ainda não possua um endereço IP.
Aqui está o mecanismo técnico:
O Endereço MAC do Cliente é Conhecido: Durante a fase inicial de associação, o cliente estabelece uma conexão de Camada 2 segura com o AP. O AP conhece o endereço MAC exclusivo do cliente e o associa a uma porta virtual e interface de rádio específicas.
O AP Intercepta o Broadcast: Quando o servidor DHCP envia um
DHCPOFFERouDHCPACKcomo um broadcast de Camada 2 (MAC de destinoFF:FF:FF:FF:FF:FF), o AP intercepta este pacote em sua interface cabeada.Conversão para Unicast: Em vez de transmitir o pacote pelo ar como um frame de broadcast (o que forçaria todos os clientes no canal a acordar e processá-lo na menor taxa de dados obrigatória), o AP modifica o cabeçalho MAC 802.11. Ele altera o endereço MAC de destino do endereço de broadcast para o endereço MAC unicast específico do cliente (que ele extraiu do campo de endereço de hardware do cliente no pacote DHCP,
chaddr).Transmissão de Alta Velocidade: Como o frame agora é um frame unicast, o AP pode transmiti-lo usando a taxa de dados máxima suportada pelo cliente (usando beamforming, MIMO e modulação de alta ordem como QAM). Ele também se beneficia das confirmações de recebimento (ACKs) de Camada 2 do 802.11, garantindo uma entrega confiável.
Processamento do Cliente: A placa sem fio do cliente recebe o frame unicast, reconhece seu próprio endereço MAC no cabeçalho 802.11 e passa o payload (a oferta ou confirmação DHCP) para cima na pilha de rede. O sistema operacional do cliente processa o payload DHCP normalmente, sem saber que o frame foi convertido de broadcast para unicast pelo ar.
Esta explicação demonstra que a conversão de broadcast para unicast é uma otimização de Camada 2 que aproveita a camada MAC do 802.11 para proteger o airtime de RF, sem alterar o payload do protocolo DHCP de Camada 3.
Continue a ler esta série
Usando Packet Capture (PCAP) para Diagnosticar Desempenho Lento de WiFi
Este guia de referência técnica fornece a gerentes de TI, arquitetos de rede e diretores de operações de locais um método estruturado em nível de pacote para diagnosticar e resolver o desempenho lento de WiFi corporativo usando a análise de Packet Capture (PCAP). Ao dissecar frames 802.11 brutos — incluindo taxas de retransmissão, utilização de tempo de antena (airtime) e metadados da camada física —, as equipes podem isolar gargalos da camada de RF de problemas de rede cabeada ou de aplicações com precisão. Aplicável a locais de alta densidade, incluindo hotéis, redes de varejo, estádios e centros de convenções, este guia oferece fluxos de trabalho de diagnóstico práticos, estudos de caso reais e etapas de correção de configuração para recuperar a capacidade da rede e proteger a experiência do convidado.
Resolução de Problemas de Falhas de Autenticação 802.1X (RADIUS/EAP)
Este guia fornece uma referência abrangente e prática para gerentes de TI, arquitetos de rede e diretores de operações de locais sobre como diagnosticar e resolver falhas de autenticação 802.1X em infraestruturas RADIUS e EAP. Ele abrange toda a cadeia de autenticação — desde a configuração incorreta do Supplicant e expiração de certificados até incompatibilidades de segredos compartilhados do RADIUS e fragmentação de trânsito de rede — com estudos de caso reais de ambientes de hotelaria e varejo. Equipes responsáveis pela conformidade com o PCI DSS, implantações do WPA3-Enterprise e controle de acesso à rede em vários locais encontrarão estruturas de diagnóstico estruturadas, checklists de implementação e estratégias de mitigação de riscos diretamente aplicáveis às suas operações.
Como identificar e resolver a Interferência Co-canal (CCI)
A interferência co-canal (CCI) é a principal causa de degradação do throughput e aumento de latência em implantações de WiFi empresarial de alta densidade, ocorrendo quando múltiplos pontos de acesso compartilham o mesmo canal de frequência e são forçados a entrar em contenção CSMA/CA. Este guia fornece a arquitetos de rede, gerentes de TI e diretores de operações de instalações um framework estruturado e independente de fornecedor para identificar a CCI por meio de diagnósticos e análises de RF, e resolvê-la por meio de planejamento de canais, otimização de potência de transmissão, gerenciamento de taxa de dados e posicionamento físico dos APs. Dominar a resolução de CCI é um pré-requisito para fornecer WiFi de visitantes confiável, conectividade operacional e ROI mensurável em hotéis, redes de varejo, estádios e instalações do setor público.