Tempo médio para a inocência: como provar que a culpa não é do WiFi
O tempo médio para a inocência (MTTI) é a métrica crítica que define quanto tempo as equipas de TI passam a provar que um problema de rede não é culpa delas. Este guia detalha uma metodologia de observabilidade de cinco passos para eliminar o jogo da culpa em ambientes multi-tenant, substituindo a troca de acusações por provas partilhadas para reduzir o tempo médio de resolução (MTTR).
Ouça este guia
Ver transcrição do podcast
📚 Part of our core series: WiFi multi-tenant: o guia completo →
Resumo Executivo
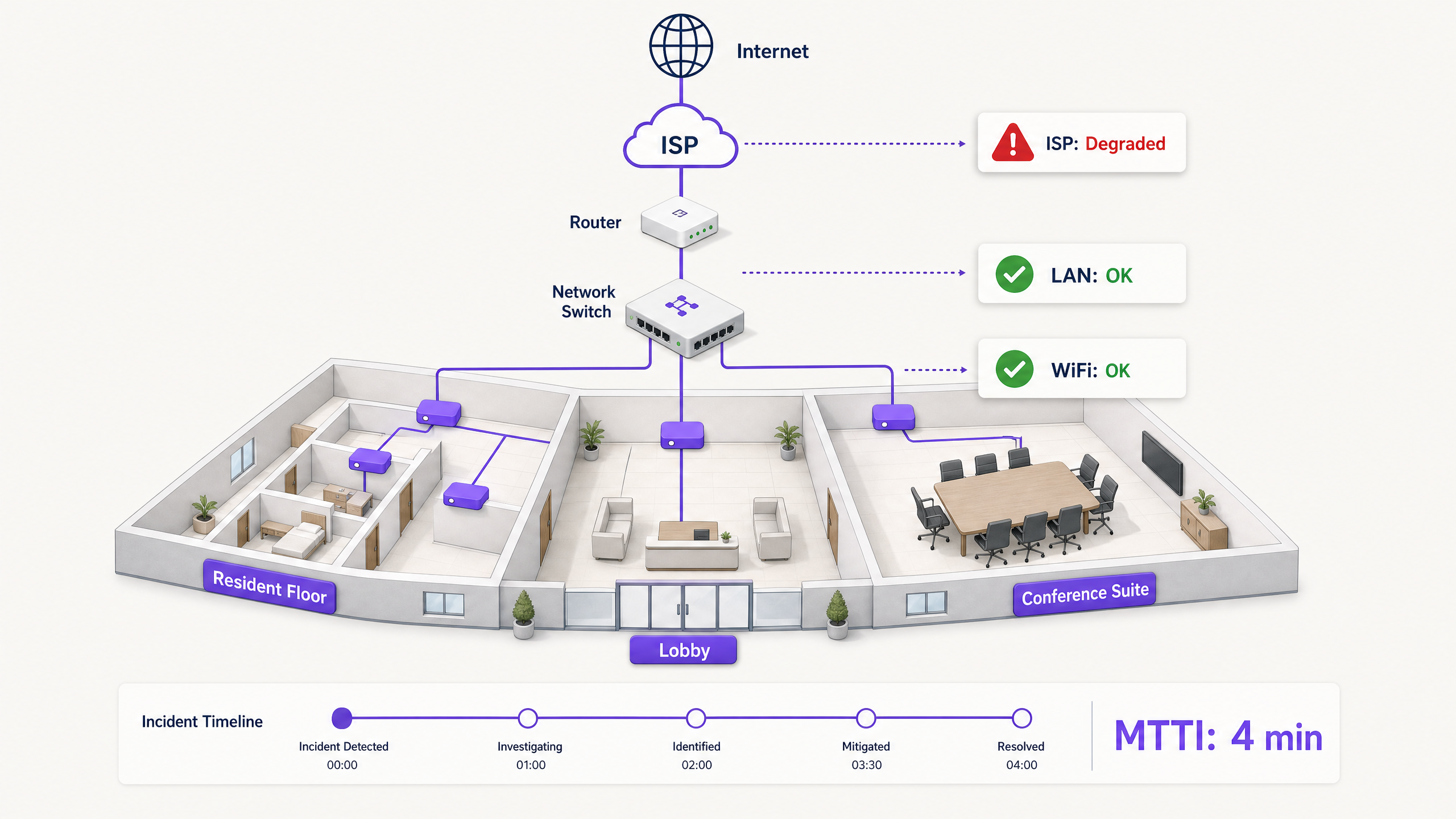
Quando a conectividade falha num ambiente multi-tenant, o WiFi é o primeiro a ser culpado. É a extremidade visível da rede, o último salto antes do dispositivo e o alvo mais fácil para os utilizadores frustrados. Para gestores de TI, arquitetos de rede e diretores de operações de espaços, isto cria uma taxa operacional persistente: o tempo gasto a provar a inocência.
O tempo médio para a inocência (MTTI) mede o tempo médio decorrido entre a sinalização de um incidente e a capacidade de uma equipa demonstrar que o seu domínio não é a causa raiz. Em ambientes complexos, como blocos build-to-rent (BTR), hotéis ou centros de conferências, a rede está fragmentada entre gestores de propriedades, fornecedores de WiFi gerido e fornecedores de serviços de internet (ISPs). Sem uma telemetria definitiva, o MTTI inflaciona o tempo médio de resolução (MTTR), à medida que as equipas discutem sobre a responsabilidade em vez de resolverem a falha.
Este guia detalha uma metodologia de observabilidade de cinco passos para reduzir sistematicamente o MTTI. Ao implementar verificações sintéticas contínuas, visibilidade de caminho salto a salto, análise de dados de fluxo, mapeamento de topologia e correlação de eventos, pode substituir a troca de acusações por provas partilhadas. O objetivo não é ganhar o jogo da culpa mais rapidamente, mas sim acabar com ele de vez.
Análise Técnica Detalhada: A Mecânica do MTTI
A Distinção entre MTTI e Tempo Médio de Identificação
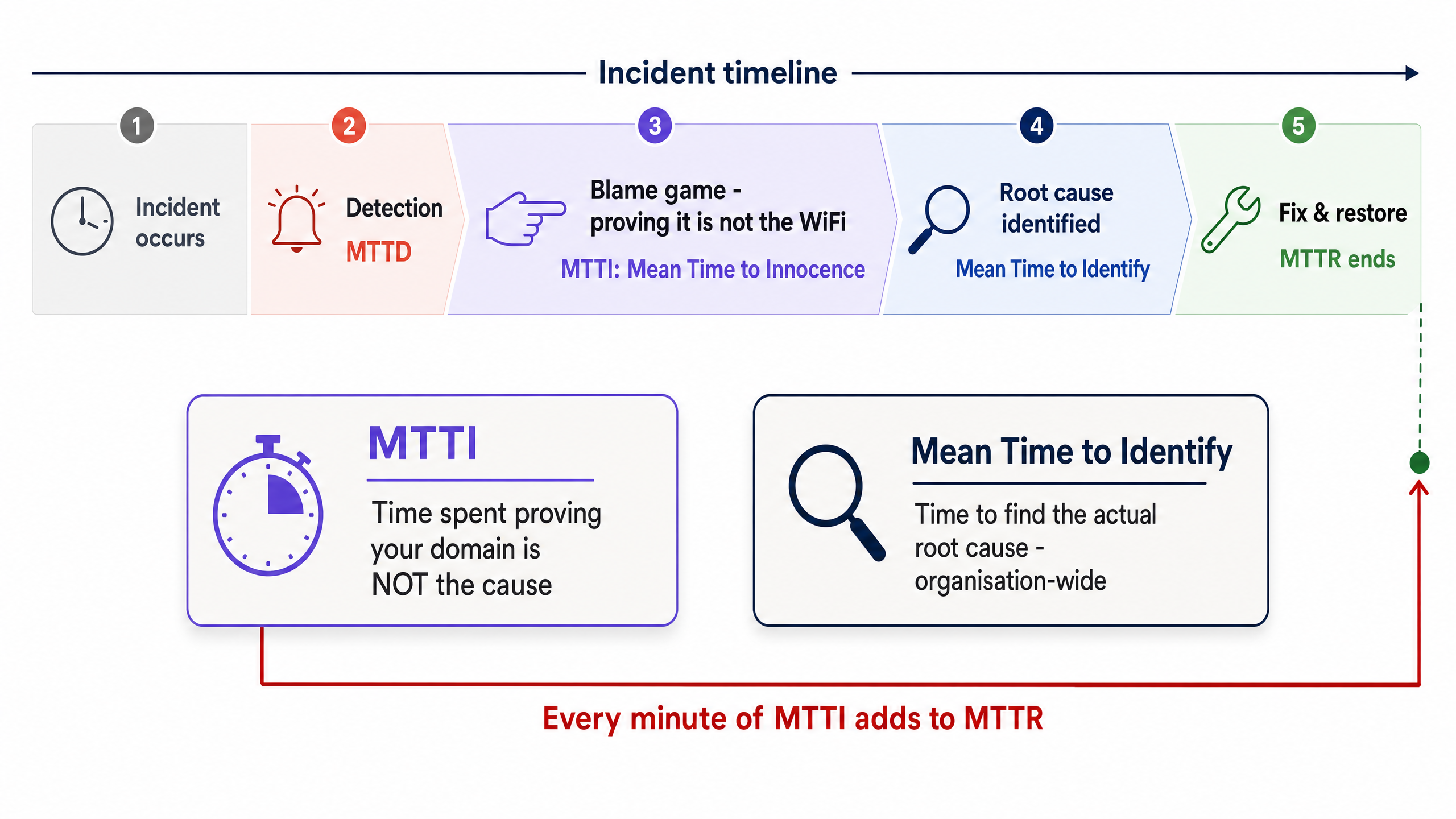
É vital separar o MTTI do tempo médio de identificação. O tempo médio de identificação é uma métrica ao nível de toda a organização que monitoriza quanto tempo demora a encontrar a verdadeira causa raiz de uma interrupção. O MTTI é uma métrica isolada e específica de um domínio que monitoriza quanto tempo uma equipa demora a provar que não é a culpada.
Cada minuto de MTTI soma-se diretamente ao MTTR. Se um fornecedor de WiFi gerido passar 40 minutos a verificar manualmente os pontos de acesso (APs) e os registos do switch antes de concluir que o problema reside no ISP, o MTTR tem uma penalização de 40 minutos incorporada antes sequer de a resolução real começar.
Por que razão o WiFi leva a Culpa
Em ambientes que servem 350 milhões de utilizadores únicos em mais de 80.000 locais ativos, a Purple vê o mesmo padrão repetidamente. A camada de WiFi é culpada por predefinição devido a três realidades estruturais:
- Viés de visibilidade: O indicador de sinal de WiFi é a única ferramenta de diagnóstico de rede disponível para o utilizador comum do espaço.
- Proximidade da extremidade: Sendo o último salto para o dispositivo do cliente, o WiFi herda os sintomas de todas as falhas a montante. Um timeout de DNS no ISP parece idêntico a uma falha de AP do ponto de vista do utilizador.
- Lacunas de telemetria: Historicamente, provar o bom funcionamento da rede sem fios exigia intervenção manual. Se não conseguir demonstrar o bom estado de funcionamento da camada sem fios em menos de dois minutos, perde o controlo da narrativa.
A Complicação Multi-Tenant
Numa empresa single-tenant, as equipas de rede controlam toda a infraestrutura, desde o AP até à firewall. Em ambientes de WiFi Multi-Tenant, a propriedade é fracionada.
Um residente de BTR paga ao gestor da propriedade. O gestor da propriedade contrata um fornecedor de WiFi gerido. O fornecedor de WiFi gerido depende de um circuito de ISP de terceiros e, frequentemente, da rede de distribuição interna do edifício do proprietário. Quando um residente não consegue transmitir vídeo, o fornecedor deve desculpar rapidamente o hardware de WiFi (Cisco Meraki, HPE Aruba, Ruckus ou Juniper Mist) e isolar a falha no dispositivo do cliente, no switch do edifício ou no ISP. A incapacidade de o fazer prejudica a relação comercial entre o fornecedor e o gestor da propriedade.
Guia de Implementação: A Metodologia de 5 Passos
Para reduzir sistematicamente o MTTI, implemente esta arquitetura de observabilidade de cinco camadas.
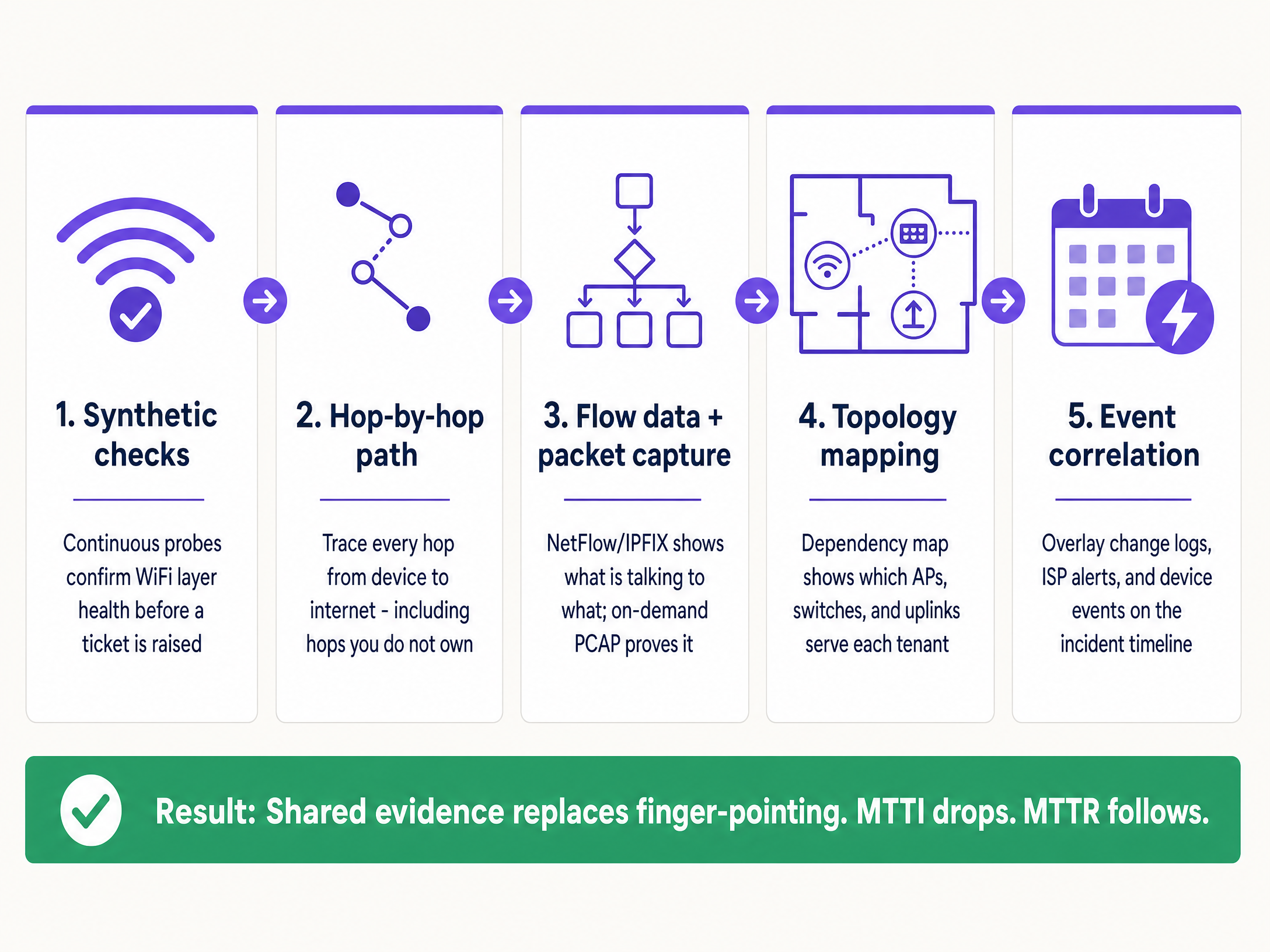
1. Verificações Sintéticas Contínuas
Não espere que um utilizador se queixe. Implemente sondas sintéticas automatizadas que emulam continuamente o comportamento do utilizador a partir da extremidade da rede.
- Implementação: Configure APs ou sensores dedicados para executar testes agendados de resposta DHCP, resolução de DNS, acessibilidade HTTP e fluxos de autenticação (como 802.1X ou inícios de sessão em Captive Portal).
- Resultado: Quando um pedido de suporte é criado, verifica primeiro o painel sintético. Se as sondas mostrarem uma acessibilidade HTTP limpa no momento exato da queixa, iliba imediatamente a camada de WiFi e o circuito WAN, desviando o foco para o dispositivo de cliente específico ou para a aplicação de destino.
2. Visibilidade de Caminho Salto a Salto
Provar que o seu hardware está operacional é insuficiente se não conseguir provar que o caminho para a internet está desimpedido.
- Implementação: Utilize ferramentas de visualização de caminhos para rastrear o tráfego desde a camada de acesso através da LAN, passando pelo ponto de demarcação e entrando na rede do ISP.
- Resultado: Quando ocorrem picos de latência, um rastreio de caminho revela exatamente qual o nó que introduziu o atraso. Se os saltos de um a quatro (o seu domínio) mostrarem 2 ms de latência, e o salto cinco (o router de extremidade do ISP) mostrar 150 ms de latência e 12% de perda de pacotes, tem uma prova definitiva para apresentar ao ISP.
3. Dados de Fluxo e Captura de Pacotes Sob Procura
Quando os utilizadores reportam falhas específicas de aplicações, necessita de visibilidade ao nível da conversação.
- Implementação: Exporte dados NetFlow ou IPFIX dos seus switches centrais ou firewalls. Certifique-se de que o hardware da sua camada de acesso suporta a captura remota de pacotes sob procura (PCAP) sem necessitar de um engenheiro no local.
- Resultado: Os dados de fluxo provam se o tráfego para um serviço específico está a sair da sua rede de forma limpa. Se estiver, a rede está inocente. Se dSe for necessária uma prova forense mais aprofundada, um PCAP direcionado na VLAN específica fornece provas inegáveis de retransmissões TCP ou resets do lado do servidor.
4. Mapeamento de Topologia e Dependências
Num ambiente multi-tenant, isolar o raio de impacto é a forma mais rápida de categorizar uma falha.
- Implementação: Mantenha um mapa de dependências ativo e atualizado dinamicamente, ligando cada AP ao seu switch, uplink e circuito WAN, mapeado em relação às VLANs dos inquilinos.
- Resultado: Se uma falha afetar APs em vários pisos, mas apenas num único switch, o problema é do switch. Se afetar todos os APs, mas apenas a VLAN de um inquilino, trata-se de um problema de configuração lógica. A definição rápida do âmbito evita o desperdício de esforços na investigação de infraestruturas operacionais.
5. Correlação de Eventos
Dados sem contexto prolongam as investigações.
- Implementação: Introduza registos de alterações, alertas de manutenção do ISP, atualizações de firmware de hardware e pedidos de suporte dos utilizadores numa única vista de linha do tempo.
- Resultado: Sobrepor um pico de falhas de autenticação com um evento de expiração de certificado do Microsoft Entra ID que ocorreu 10 minutos antes identifica imediatamente a causa raiz, contornando totalmente o hardware de rede.
Boas Práticas
- Padronize o Stack de Hardware: Limite as implementações a fornecedores empresariais de referência (Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme, Fortinet) que disponibilizam APIs para testes sintéticos e PCAP remoto.
- Automatize as Provas: Configure a sua plataforma de monitorização para anexar automaticamente resultados de testes sintéticos e rastreios de caminhos a pedidos de suporte ITSM no momento em que são criados.
- Partilhe o Painel: Forneça aos gestores de propriedades acesso de leitura a um painel de estado geral de alto nível. A transparência evita o jogo das culpas.
- Monitorize o MTTI Formalmente: Meça o tempo entre a criação do pedido de suporte e o momento em que a sua equipa apresenta provas de inocência. Trate-o como um KPI principal, a par do MTTR.
Resolução de Problemas e Mitigação de Riscos
- Risco: O Ciclo 'Nenhuma Falha Detetada': Os utilizadores comunicam problemas, mas as verificações sintéticas aparecem a verde.
- Mitigação: O problema é provavelmente específico do dispositivo ou está relacionado com interferência de RF (interferência de canal partilhado ou obstrução física). Utilize análises do lado do cliente para verificar o RSSI e o histórico de roaming do dispositivo específico.
- Risco: Negação do ISP: O ISP recusa aceitar a falha, apesar das suas provas.
- Mitigação: Forneça rastreios de caminhos salto a salto que mostrem o endereço IP exato onde a perda de pacotes começa. Partilhe PCAPs que demonstrem uma saída limpa do seu ponto de demarcação. Dados concretos forçam a escalada para além do suporte de Nível 1.
- Risco: Falhas no Captive Portal: Os utilizadores culpam o WiFi quando o portal não carrega.
- Mitigação: Isole o fornecedor de identidade. Verifique o estado da integração (Microsoft Entra ID, Okta, Google Workspace). Se a rede permitir tráfego de pré-autenticação mas o IdP exceder o tempo limite, a rede está inocente.
ROI e Impacto no Negócio
Reduzir o MTTI proporciona um valor de negócio mensurável que vai além da simples poupança de horas de engenharia.
- MTTR Reduzido: Eliminar 40 minutos de troca de acusações num incidente reduz diretamente o tempo de inatividade, protegendo as receitas em ambientes de retalho e hotelaria .
- Conformidade com SLA: Uma exoneração mais rápida evita que sejam aplicadas penalizações injustas ao fornecedor de WiFi gerido quando a falha reside no ISP ou na infraestrutura do edifício.
- Retenção de Clientes: No setor de WiFi Multi-Tenant, os gestores de propriedades renovam contratos com fornecedores que oferecem transparência e respostas rápidas. Provas partilhadas geram confiança; argumentos defensivos destroem-na.
- Otimização de Recursos: Engenheiros de rede de Nível 3 altamente remunerados passam o seu tempo a conceber soluções, em vez de provarem manualmente que a rede está a funcionar corretamente.
Definições Principais
Mean Time to Innocence (MTTI)
The average time required for a specific IT team to prove, using objective data, that their domain or infrastructure is not the root cause of a reported incident.
Critical for managed WiFi providers who must defend their service against property managers and ISPs.
Mean Time to Identify
The organisation-wide metric tracking the total time elapsed from incident detection to the discovery of the actual root cause.
MTTI is a subset of this metric. Reducing MTTI directly reduces the overall time to identify.
Synthetic Checks
Automated, continuous tests that emulate user traffic (e.g., DNS lookups, HTTP requests) to proactively monitor network health.
Used to prove the WiFi layer was functioning correctly at the exact moment a user complained.
Hop-by-Hop Path Visibility
Telemetry that traces network traffic node-by-node from the client to the destination, measuring latency and loss at each specific router or switch.
Essential for proving a fault lies in an ISP network or a landlord's distribution switch, rather than the managed WiFi hardware.
Flow Data (NetFlow/IPFIX)
Network protocol data that provides a summary of traffic conversations, showing source, destination, protocol, and volume.
Used to prove that specific application traffic is successfully leaving the local network.
On-Demand Packet Capture (PCAP)
The ability to remotely record raw network traffic from an access point or switch for forensic analysis.
The ultimate proof used to demonstrate server-side errors or client device misbehaviour.
Blast Radius
The scope of impact of a specific incident (e.g., one user, one AP, one switch, one tenant, or the entire building).
Determining the blast radius via topology mapping is the fastest way to exclude healthy infrastructure from an investigation.
Event Correlation
The practice of overlaying different data streams (logs, alerts, updates) on a single timeline to identify cause and effect.
Used to prove that a network outage was caused by a third-party change, such as an unannounced ISP maintenance window.
Exemplos Práticos
A 350-room hotel reports that in-room WiFi is slow across the entire property. The front desk blames the managed WiFi provider. How do you exonerate the network and find the root cause?
- Check the synthetic probes: DNS and HTTP reachability tests show the APs have a clean connection to the internet. 2. Review the topology map: The issue affects all APs across all switches, ruling out edge hardware. 3. Execute a path trace: The trace shows 2ms latency within the hotel LAN, but 180ms latency at the third hop (the ISP's aggregation router). 4. Export the evidence: Send the path trace screenshot to the hotel manager and the ISP.
A national retailer reports point-of-sale (POS) terminals in one region are dropping connections to the payment processor. The network team is blamed for a firewall or routing misconfiguration.
- Isolate the blast radius: Confirm only POS terminals (specific VLAN) are affected; guest WiFi and back-office systems are healthy. 2. Analyse flow data: NetFlow confirms traffic destined for the payment processor's IP range is successfully leaving the store routers. 3. Capture packets: An on-demand PCAP on the POS VLAN reveals the payment processor's server is sending TCP resets (RST). 4. Share the PCAP with the payment processor's support team.
Perguntas de Prática
Q1. A tenant in a coworking space complains they cannot access their corporate VPN. Other tenants are browsing the internet without issue. What is the most efficient way to prove the WiFi network is not at fault?
Dica: Consider the blast radius and the specific type of traffic failing.
Ver resposta modelo
First, use the topology map to confirm the blast radius is limited to one user or one specific service, ruling out a general AP or switch failure. Second, analyse flow data (NetFlow/IPFIX) for that client's IP address. If the flow data shows the VPN traffic (e.g., UDP 500 or TCP 443) is leaving the network cleanly, the WiFi and LAN are innocent. The issue is either the client's VPN configuration or the corporate firewall blocking the connection.
Q2. Your monitoring dashboard shows an AP has gone offline, but the property manager insists the WiFi is broken because the ISP is down. How do you prove the issue is internal power, not the ISP?
Dica: Look for correlation between infrastructure state and external events.
Ver resposta modelo
Use event correlation and topology mapping. If the topology map shows only one AP is offline while others on the same switch are functioning, the ISP circuit is clearly active. Event correlation might show a PoE (Power over Ethernet) failure log from the switch port connected to that specific AP. This proves the issue is local hardware or cabling, not the WAN circuit.
Q3. A stadium operations director claims the WiFi failed during halftime because ticket scanners stopped working. You need to exonerate the network in under two minutes. What telemetry do you use?
Dica: You need historical proof of health at the exact moment of the reported failure.
Ver resposta modelo
Pull the historical data from the continuous synthetic checks. Show the operations director the dashboard confirming that during the exact 15-minute halftime window, the APs were successfully resolving DNS and reaching the ticketing server's IP address with low latency. This immediately proves the wireless network was healthy and shifts the investigation to the ticketing application servers, which likely buckled under the sudden load.
Continue a ler esta série
O Guia Empresarial do SCEP: Implementar o Simple Certificate Enrollment Protocol para Segurança Automatizada de WiFi em Campus
Este guia de referência técnica fornece um modelo de arquitetura definitivo e uma estratégia de implementação passo a passo para a implementação de certificados de WiFi empresariais utilizando SCEP. Abrange as diferenças críticas entre SCEP e PKCS, a sequência exata de implementação necessária para o sucesso e estratégias reais de mitigação de riscos para líderes de TI.
Porque é que o meu WiFi de Convidados Não se Liga? Resolução de Problemas de Captive Portal
Este guia de referência técnica de autoridade explica o funcionamento subjacente da deteção de Captive Portal e detalha os seis principais modos de falha que impedem a ligação do WiFi de convidados. Fornece aos gestores de TI e arquitetos de rede uma estrutura prática de resolução de problemas para resolver problemas de redirecionamento HTTP, conflitos de DNS e desafios de randomização de MAC.
Como Implementar SCEP para Registo Automatizado de Certificados WiFi
Este guia explica como implementar o SCEP (Simple Certificate Enrollment Protocol) para o registo automatizado de certificados WiFi em espaços empresariais. Abrange o plano arquitetónico completo - desde o design de PKI e integração de MDM até à sequência obrigatória de implementação em três etapas - e mostra aos gestores de TI e arquitetos de rede como eliminar credenciais partilhadas, automatizar a gestão do ciclo de vida dos certificados e cumprir os requisitos de PCI DSS e GDPR em escala.