Top 10 des causes de timeouts DHCP sur les réseaux sans fil à haute densité
Ce guide de référence technique de premier plan identifie les dix principales causes de timeouts DHCP sur les réseaux sans fil à haute densité et propose des stratégies de remédiation exploitables et indépendantes des fournisseurs. Conçu pour les décideurs informatiques, les architectes réseau et les directeurs d'exploitation de sites, il détaille des principes d'ingénierie approfondis, des processus de déploiement étape par étape et des résultats commerciaux mesurables. Découvrez comment éliminer les goulots d'étranglement de connexion et optimiser votre infrastructure sans fil pour offrir une connectivité fluide dans les environnements d'entreprise les plus exigeants.
Écouter ce guide
Voir la transcription du podcast
執行摘要
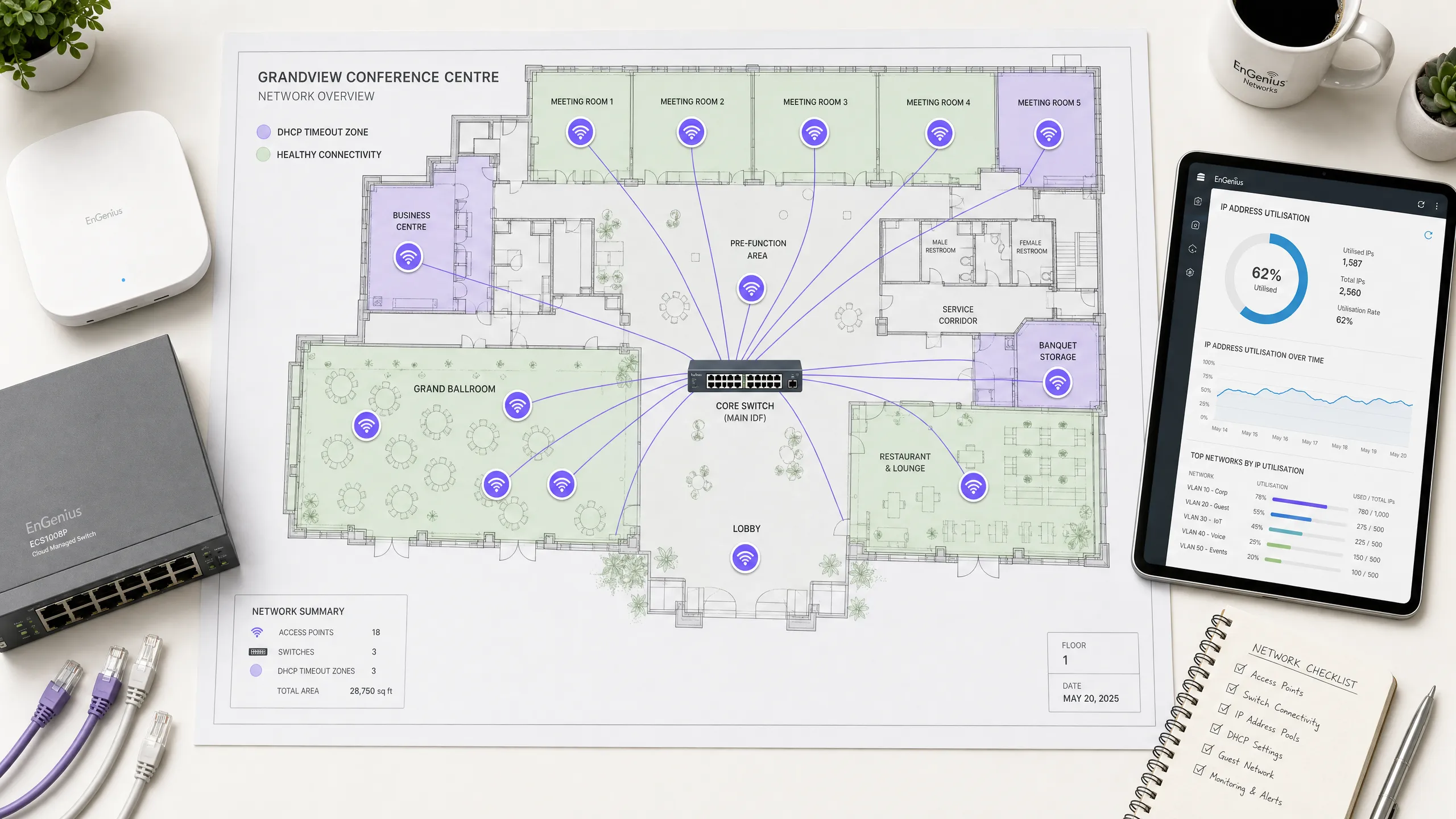
在現代企業環境中(例如高容量的飯店、零售商場、交通樞紐和體育場館),無線連線是推動業務發展的關鍵基石。然而,顧客體驗往往在網路初始上網的第一步就宣告失敗:獲取 IP 位址。在高密度無線網路上,動態主機設定協定(DHCP)逾時是上網失敗最常見卻也最常被誤診的根本原因之一。當數百或數千台裝置同時嘗試連線時,傳統的 DHCP 設定在如此高負載下會崩潰,導致使用者卡在旋轉的載入畫面,或只能取得自行分配的 169.254.x.x 連結本地位址。
本權威技術參考指南深入探討了高密度無線網路上導致 DHCP 逾時的前十大原因。它跳過學術理論,直接為資深網路架構師、CTO 和場館營運總監提供即時、可執行的改善策略。透過系統化地優化 DHCP 領域大小、縮短租約時間、實施強健的 Layer 2/3 設定以及部署高可用性伺服器架構,企業可以顯著降低連線延遲、消除上網阻礙並保護其品牌聲譽。實施這些最佳實踐與提升顧客滿意度、提高對 Guest WiFi 等核心產品的參與度,以及透過 WiFi Analytics 獲取更豐富的數據直接相關。
技術深度剖析
要診斷並解決 DHCP 逾時問題,網路工程師必須首先了解四向 DHCP 握手(通常稱為 DORA 流程:Discover、Offer、Request、Acknowledge)的精確運作機制 [1]。在高密度環境中,此流程對封包遺失、延遲和資源耗盡極為敏感。
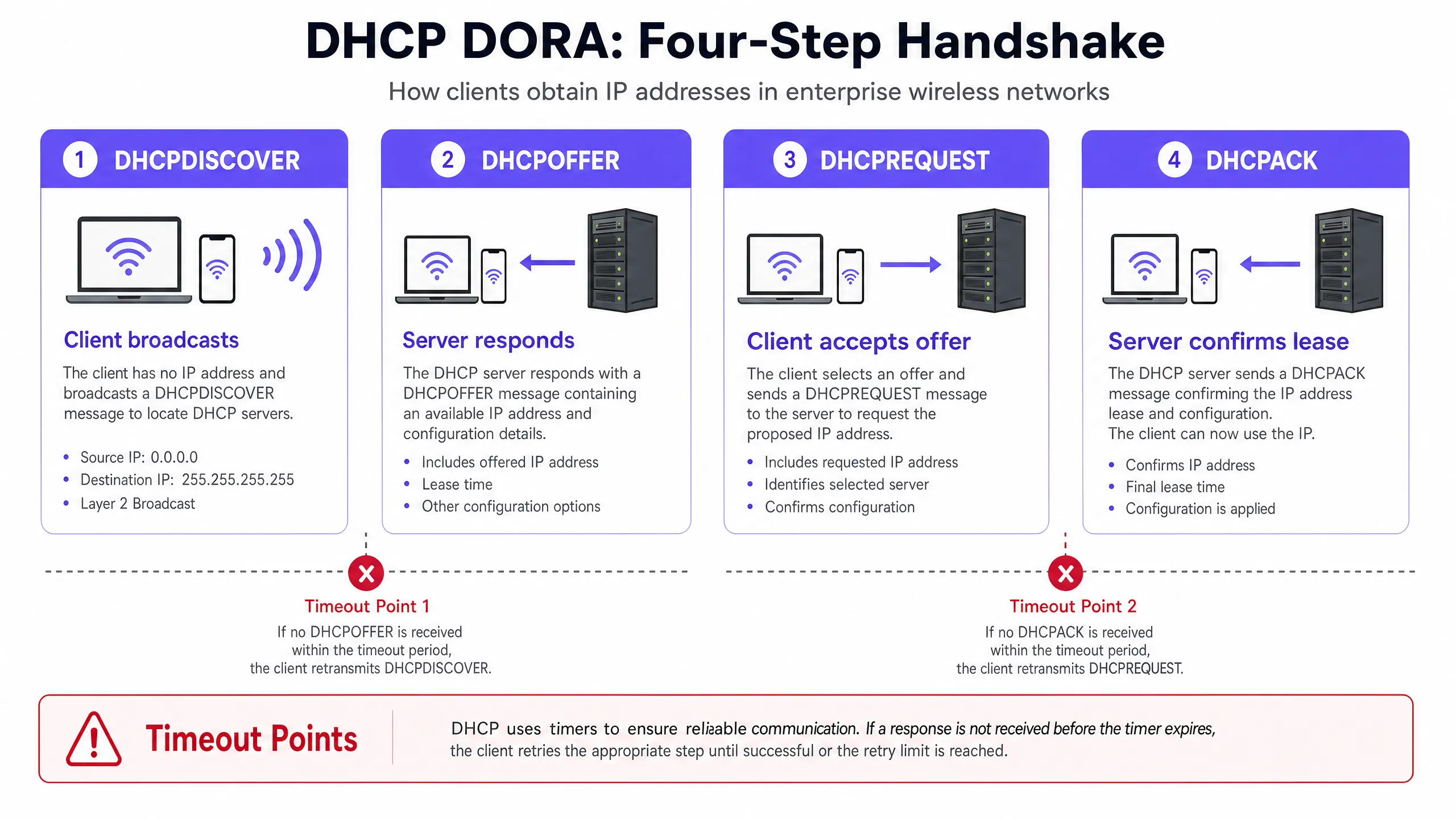
高密度無線網路中的 DHCP 握手(DORA)
- DHCPDISCOVER(廣播):無線用戶端與基地台(AP)建立關聯,並廣播一個封包以尋找可用的 DHCP 伺服器。在大型廣播網域中,此封包會充斥於所有連接埠,消耗寶貴的無線空中時間。
- DHCPOFFER(單播/廣播):收到 discover 訊息的每個作用中 DHCP 伺服器都會保留一個 IP 位址,並向用戶端發送 offer,其中指定了租約參數、子網路遮罩、預設閘道器和 DNS 伺服器。
- DHCPREQUEST(廣播):用戶端選擇其中一個 offer(通常是第一個收到的),並廣播一個 request 以接受該特定 IP 位址,這也隱含拒絕了其他所有 offer。
- DHCPACK (單播/廣播):選定的 DHCP 伺服器將租約寫入其資料庫,並向用戶端發送確認訊息,確認 IP 分配和租約期限。用戶端隨後套用此設定。
無線開銷與空口時間擁塞的影響
有線網路是以千兆速度在硬體層面處理 Layer 2 廣播,但無線網路不同,它會以最低強制資料速率(通常為 1 Mbps、6 Mbps 或 11 Mbps,具體取決於 SSID 設定)傳輸廣播和多播訊框,以確保所有遠端用戶端都能接收 [2]。在擁有數千台活動裝置的高密度 SSID 上,廣播 DHCP 封包會消耗不成比例的射頻空口時間,導致封包衝突、重傳並最終逾時。用戶端裝置通常預期在 2 到 4 秒內收到 DHCP 回應;如果空口時間擁塞將 DORA 流程的任何步驟延遲到此視窗之外,用戶端就會逾時、中斷關聯並重試,從而對網路造成連鎖負載。
DHCP 逾時的 10 大原因
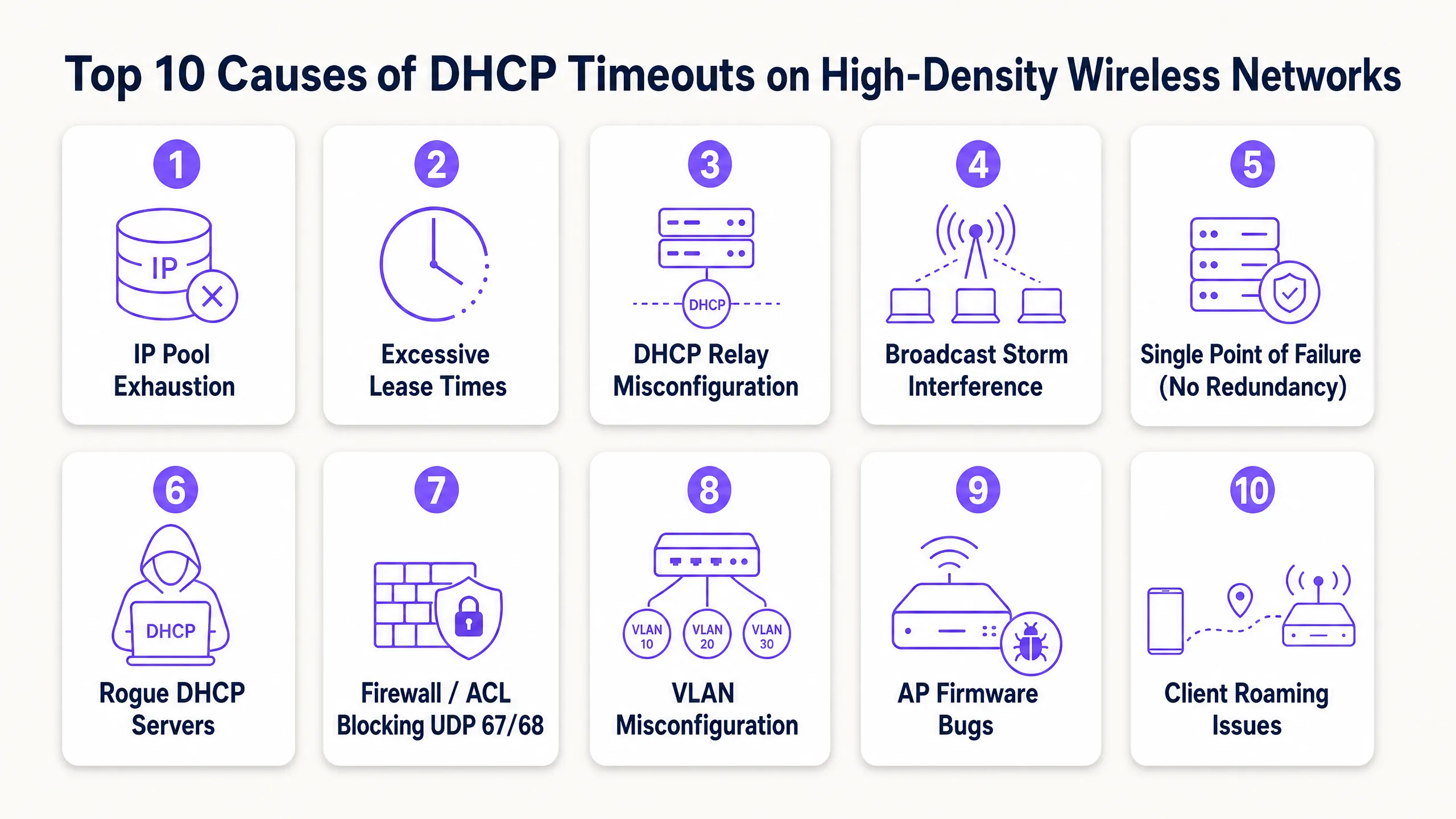
1. DHCP IP 位址池耗盡
機制:DHCP 伺服器的範圍對於暫時性裝置的數量而言太小。當位址池使用率達到 100% 時,伺服器會直接忽略新的 DHCPDISCOVER 封包,因為它沒有可提供的位址。
高密度場景:標準的 Class C 子網路(/24)僅提供 254 個可用 IP 位址。在飯店大廳、體育場入口或會議主會場,同時連線的裝置數量很容易在幾分鐘內超過此限制。更嚴重的是,許多使用者攜帶多個連網裝置(手機、智慧手錶、平板電腦、筆記型電腦),使 IP 需求倍增。
解決方案:使用無類別域間路由(CIDR)標記法來調整網路範圍。將高密度用戶端 VLAN 轉換為 /22(1,022 個 IP)或 /21(2,046 個 IP)子網路。確保您的監控工具設定為在位址池使用率達到 80% 時發出警報,以便在高峰活動前主動擴展範圍。
2. 訪客網路上的租約時間過長
機制:租約時間決定了用戶端在必須更新或釋放 IP 位址之前可以保留該位址多久。如果租約時間過長,DHCP 伺服器會將該位址保留在資料庫中,即使原始裝置已離開場地,也無法將其重新分配給新用戶端。
高密度場景:許多預設的 DHCP 設定指定了 24 小時或 8 天的租約時間。在人員流動率高的公共場所或餐旅環境中(例如交通轉運站或購物中心),訪客通常停留不超過兩小時 [3]。在 24 小時租約的情況下,連線 10 分鐘的訪客會佔用一個 IP 位址一整天,從而導致人為的位址池耗盡。 補救措施:將租約時間與用戶端停留時間保持一致。針對訪客網路實施 30 至 60 分鐘的租約時間。對於裝置在整個班次期間都保持連線的企業員工網路,則使用 8 至 12 小時的租約時間。這可確保快速回收已離開用戶端的 IP 位址。
3. DHCP 中繼代理程式(Relay Agent)設定錯誤
運作機制:由於 DHCP 探索訊息屬於 Layer 2 廣播,因此無法跨越路由器(Layer 3)邊界。DHCP 中繼代理程式(通常在 Layer 3 交換器或安全閘道器上使用類似 Cisco 的 ip helper-address 指令進行設定)必須攔截這些廣播,並將其作為單播封包轉發給中央 DHCP 伺服器 [4]。如果中繼代理程式設定錯誤、Helper IP 不正確,或在新建的 VLAN 中遺漏了該代理程式,DHCP 流量將會被阻擋。
高密度環境背景:高密度網路極度依賴 VLAN 切割來限制廣播網域。在部署新 SSID 或擴大場地時,工程師通常會建立新的用戶端 VLAN。如果對應的 Layer 3 介面上未更新中繼代理程式設定,這些 VLAN 上的用戶端將會立即遇到 DHCP 逾時。
補救措施:為所有 Layer 3 交換器建立嚴格的設定範本。確保每個用戶端 VLAN 介面都有一對備援的 DHCP Helper 位址,指向您的主要和次要 DHCP 伺服器。驗證中繼介面 IP(DHCP 伺服器用來確定要分配哪個子網路範圍)與 DHCP 伺服器本身之間的端到端路由。
4. 廣播與多播風暴
運作機制:VLAN 上過多的廣播或多播流量會使無線介質飽和。由於無線網路是共享的半雙工介質,AP 和用戶端在傳輸前必須等待空中通道空閒。廣播風暴(通常由交換迴圈、故障的網路卡或具侵略性的點對點協定引起)會佔滿空中時間,導致 DHCP 封包被排隊、延遲或丟棄。
高密度環境背景:在沒有適當 Layer 2 隔離的大型扁平無線網路中,點對點廣播流量(例如 Apple AirPlay、Google Chromecast 或 Windows 網路探索)會被 VLAN 上的每個 AP 複製。在擁有 10,000 名使用者的場地中,這種背景「雜音」可能會消耗超過 50% 的可用無線頻寬,導致關鍵的 DHCP 握手封包沒有足夠的空中時間進行傳輸。
補救措施:在無線控制器上啟用用戶端隔離(Client Isolation,也稱為點對點阻擋),以防止用戶端之間直接通訊。在 AP 和交換器上設定廣播與多播抑制,將廣播流量限制在鏈路容量的一小部分(例如每秒 100 個封包)。在支援的情況下,在 AP 上啟用 DHCP Proxy,將廣播的 DHCP Offer 和 Acknowledgement 轉換為專門針對請求用戶端的單播訊框。
5. 單一故障點(缺乏 DHCP 備援)
機制:單一、無備援的 DHCP 伺服器代表著關鍵的脆弱性。如果該伺服器當機、進行系統更新或失去網路連線,整個網路的用戶上線能力將立即中斷。現有的租約仍保持作用,但新用戶端無法取得 IP 位址,且漫遊用戶端也無法更新其租約。
高密度情境:高密度場域在嚴格的營運 SLA 下運作。比賽期間的體育場或進行主題演講的會議中心,連五分鐘的 DHCP 停機時間都無法容忍。依賴單一路由器或單一虛擬機器來處理數千個快速的租約請求,是一種高風險的架構。
解決方案:以高可用性配置部署 DHCP。在負載平衡模式(50/50 分流)或熱備援模式下使用 Windows Server DHCP Failover,或部署備援的企業級 DHCP 設備(例如 Infoblox 或 BlueCat)[5]。確保您的 DHCP 伺服器在物理或邏輯上分散在不同的虛擬化管理程序(hypervisors)和網路路徑中,以消除共模故障。
6. 惡意 DHCP 伺服器
機制:惡意 DHCP 伺服器是指連接到網路的未授權、已啟用 DHCP 的裝置。它會攔截用戶端的 DHCPDISCOVER 廣播,並以其自身的 DHCPOFFER 封包進行回應,通常會發送錯誤的 IP 配置、錯誤的預設閘道或惡意的 DNS 伺服器。
高密度情境:在大型場館、零售店面或公共部門辦公室中,實體乙太網路連接埠通常暴露在公共區域,或者使用者可能會攜帶未授權的裝置(例如消費級旅行路由器或執行橋接網路的虛擬機器)並將其插到牆上插座。這會導致 IP 位址衝突、路由黑洞以及嚴重的安全性風險(包括中間人攻擊)。
解決方案:在所有存取和分發交換器上啟用 DHCP Snooping [6]。DHCP snooping 將交換器連接埠指定為「受信任」(連接到合法的 DHCP 伺服器或中繼代理)或「不受信任」(連接到用戶端)。交換器會自動丟棄來自不受信任連接埠的任何 DHCP 伺服器回應(例如 DHCPOFFER 或 DHCPACK),從而立即瓦解惡意伺服器。
7. 防火牆、ACL 和阻擋 UDP 67/68 的安全性原則
機制:DHCP 依賴 UDP 連接埠 67(伺服器端監聽和用戶端目的地)和 UDP 連接埠 68(用戶端監聽和伺服器端目的地)。如果網路防火牆、交換器存取控制清單 (ACL) 或端點安全性原則阻擋了這些連接埠,DORA 握手程序將無法完成。
高密度環境背景:安全性強化是企業網路的首要任務。然而,過於激進的安全策略往往會無意中阻擋 DHCP 流量。例如,在進行防火牆移轉或策略更新期間,管理員可能會阻擋某個網段上的所有 UDP 流量,卻未意識到他們已經中斷了 DHCP 路徑。同樣地,訪客 VLAN 安全策略在將流量重導向至 Captive Portal 之前,必須明確允許 UDP 67 和 68。
補救措施:稽核無線用戶端、AP、Layer 3 交換器和 DHCP 伺服器之間路徑上的所有 ACL 和防火牆規則。確保雙向皆明確允許 UDP 連接埠 67 和 68。進行疑難排解時,請在 DHCP 伺服器的網路介面進行封包擷取,以確認 DHCPDISCOVER 封包確實有送達。
8. VLAN 與 Trunking 設定錯誤
運作機制:如果用戶端的 SSID 對應到特定的 VLAN,但該 VLAN 在整個交換器基礎架構中未被正確標記(tagged)或建立 Trunk 連結,則用戶端的 DHCP 廣播將永遠無法到達預設閘道或 DHCP 中繼代理程式。
高密度環境背景:高密度無線網路使用動態 VLAN 分配或多 VLAN 資源池來分流用戶端負載。如果從 AP 到核心交換器路徑上的單一交換器 Trunk 連接埠在其允許清單中遺漏了某個 VLAN 標記,則用戶端子集(特別是被分配到該 VLAN 的用戶端)將會立即且持續遇到 DHCP 逾時,而同一 SSID 上的其他用戶端卻能成功連線。這會造成極度斷續、難以診斷的疑難排解情境。
補救措施:導入自動化網路設定管理與驗證工具。設定交換器 Trunk 連接埠時,請務必使用明確的允許清單(例如 switchport trunk allowed vlan 10,20,30),而不是依賴預設的「全部」設定,並驗證 Trunk 連結兩端的 Native VLAN 是否相符,以防止未標記的流量外洩。
9. 存取點(Access Point)韌體與驅動程式錯誤
運作機制:存取點韌體負責將 802.11 無線訊框橋接至 802.3 有線乙太網路。AP 無線驅動程式或橋接引擎中的軟體錯誤(Bug)可能會導致 AP 丟棄 DHCP 封包,特別是在高 CPU 或記憶體負載下。
高密度環境背景:高密度網路會將 AP 硬體和軟體推向極限。在 10 個用戶端的輕度負載下保持休眠的錯誤,當 AP 處理 100 個並行作用中用戶端時,可能會引發災難性的故障。例如,2026 年初在某些 WiFi 7 AP 上記錄到的一個已知錯誤,會導致 AP 斷續丟棄三次握手的第三個封包(DHCPREQUEST),使用戶端永遠無法收到其 DHCPACK 並完成上線流程。
補救措施:針對 AP 韌體維持嚴格的生命週期管理政策。避免將「最新、未經充分測試」的韌體版本直接部署到生產環境。建立一個模擬高密度環境的測試環境,並密切關注廠商的發行說明和社群論壇,以掌握已知的 DHCP 相關錯誤。如果排障過程中發現用戶端已發送 DHCPDISCOVER 封包,但 AP 的有線上行連接埠卻從未收到,則應懷疑是 AP 橋接錯誤。
10. 頻繁的用戶端漫遊與 Layer 3 邊界
機制:當無線用戶端從一個 AP 移動(漫遊)到另一個 AP 時,必須維持其網路工作階段。如果漫遊跨越了 Layer 3 邊界(將用戶端移至不同的子網路),用戶端必須取得新的 IP 位址。如果用戶端的作業系統或無線網路無法順暢處理此轉換,用戶端將會嘗試在新的子網路中使用舊的 IP 位址,進而導致連線逾時和 DHCP 重新協商失敗。
高密度情境:高密度場域需要數百個 AP 才能提供足夠的覆蓋範圍。用戶端處於持續移動的狀態——例如,飯店房客從客房走向會議廳,或零售商場中的顧客四處走動 [7]。如果網路架構將場域的不同實體區域對應到不同的子網路,將會產生大量的 Layer 3 漫遊,進而以頻繁的釋放(release)和請求(request)事件使 DHCP 伺服器過載。
補救措施:在整個用戶端 SSID 採用扁平化 Layer 2 架構來設計高密度無線網路,或實作基於無線控制器的通道技術(例如 GRE 或 CAPWAP)[8]。通道技術可確保用戶端的流量始終錨定回其原始的主控制器和 VLAN,無論其漫遊到哪個實體 AP,從而完全消除 Layer 3 漫遊事件及相關的 DHCP 開銷。
實作指南
若要系統性地消除 DHCP 逾時,網路架構師必須從被動排障轉變為主動、標準化的架構。請遵循此逐步部署指南來強化您的 DHCP 基礎架構。
步驟 1:子網路規劃與 CIDR 架構
切勿在高密度訪客網路中使用標準的 /24 子網路。請根據尖峰容量加上 50% 的緩衝來計算您的 IP 需求,以容納擁有多個裝置的用戶和暫時性的人流變動。
| 子網路遮罩 | CIDR | 可用 IP 位址 | 最佳使用案例 |
|---|---|---|---|
255.255.255.0 |
/24 |
254 | 行政人員、印表機、後勤 IoT |
255.255.254.0 |
/23 |
510 | 小型精品飯店、局部零售店面 |
255.255.252.0 |
/22 |
1,022 | 大型飯店、高密度會議室、學校校園 |
255.255.248.0 |
/21 |
2,046 | 大型展覽館、購物中心、公共廣場 |
255.255.240.0 |
/20 |
4,094 | 體育館、競技場、大型會議中心 |
步驟 2:最佳化 DHCP 租期
根據特定網路區段的使用者行為,設定您的 DHCP 伺服器以強制執行租期時間:
訪客 WiFi SSID (高流動率) -> 租期時間:30 到 60 分鐘
企業員工 SSID (穩定) -> 租期時間:8 到 12 小時
場域 IoT 與基礎設施 -> 租期時間:7 天 (或靜態保留)
注意:縮短租期時間會增加 DHCP 更新請求的頻率 (發生在租期時間的 50%,稱為 T1) [9]。請確保您的 DHCP 伺服器硬體具有足夠的 CPU 和 I/O 效能,以處理提升的請求率。
步驟 3:在 Layer 3 交換器上設定 DHCP 中繼代理 (Relay Agents)
設定 DHCP 中繼代理時,請務必指定指向獨立 DHCP 伺服器的備援協助器位址 (helper addresses)。以下是 Cisco iOS Layer 3 交換器介面的標準、與廠商無關的設定範本:
interface Vlan30
description High_Density_Guest_WiFi
ip address 192.168.30.1 255.255.252.0
ip helper-address 10.10.10.10 # 主要 DHCP 伺服器
ip helper-address 10.10.10.11 # 次要 DHCP 伺服器
ip dhcp relay information option # 插入 Option 82 以進行位置追蹤
no shutdown
步驟 4:使用 DHCP 監聽 (Snooping) 強化 Layer 2 安全性
透過在整個交換器架構中啟用 DHCP 監聽,防止惡意 DHCP 伺服器並減輕 DHCP 耗盡攻擊。以下是邊緣存取交換器的設定範本:
# 全域啟用 DHCP 監聽
ip dhcp snooping
# 針對特定用戶端 VLAN 啟用 DHCP 監聽
ip dhcp snooping vlan 10,20,30
# 將連接到核心交換器/DHCP 伺服器的上行連接埠設定為「信任 (TRUSTED)」
interface GigabitEthernet1/0/48
description UPLINK_TO_CORE
ip dhcp snooping trust
# 將面向用戶端的連接埠設定為「非信任 (UNTRUSTED)」,並限制 DHCP 封包速率以防止耗盡攻擊
interface range GigabitEthernet1/0/1 - 47
description CLIENT_ACCESS_PORTS
ip dhcp snooping limit rate 15
最佳實踐
為了維持具備彈性且高效能的無線網路,請將這些業界標準的最佳實踐納入您的營運手冊中:
1. 實作 DHCP Option 82 (中繼代理資訊選項)
DHCP Option 82 允許中繼代理在將 DHCP 請求轉發到伺服器之前,將特定線路資訊 (例如交換器連接埠 ID 或 AP MAC 位址) 插入其中 [10]。這使 DHCP 伺服器能夠根據用戶端在場域內的實體位置,執行高度精細的 IP 分配原則。例如,飯店可以為會議中心的用戶端與客房內的用戶端分配不同的 IP 位址池或 DNS 設定,從而最佳化位址池的利用率。
2. 啟用 ARP 與 DHCP 廣播轉單播 (Broadcast-to-Unicast) 轉換
設定您的無線區域網路控制器 (WLC) 或雲端管理 AP,以攔截 Layer 2 廣播 ARP 和 DHCP 封包,並在透過無線電傳輸之前將其轉換為單播(unicast)訊框。由於單播訊框是以用戶端支援的最大資料速率(而非最低強制廣播速率)進行傳輸,因此這項簡單的設定變更可大幅減少 RF 空中時間(airtime)消耗,並提高高密度環境中的 DHCP 可靠性。
3. 建立主動式 DHCP 監控與警報
不要等待使用者回報連線失敗。設定您的網路管理系統 (NMS) 或 DHCP 伺服器監控工具,以追蹤關鍵指標並觸發即時警報:
- 位址池利用率:在利用率達到 75% 時觸發警告警報,在 85% 時觸發緊急警報。
- DHCP 請求速率:監控請求是否突然激增,這可能表示存在廣播風暴、漫遊迴圈或 DHCP 耗盡攻擊。
- 租約到期分佈:確保租約順利到期,且資料庫正在主動回收 IP 位址。
疑難排解與風險緩釋
當懷疑發生 DHCP 逾時,請遵循此系統化診斷工作流程,以快速隔離故障點並將業務中斷降至最低。
[用戶端關聯至 AP]
│
▼
[在用戶端擷取封包] ───► 是否傳送 DHCPDISCOVER?
│ ├── 否:用戶端作業系統/驅動程式問題。
│ └── 是
▼
[在交換器擷取封包] ───► DHCPDISCOVER 是否到達交換器?
│ ├── 否:AP 橋接/VLAN 標記問題。
│ └── 是
▼
[在伺服器擷取封包] ───► DHCPDISCOVER 是否到達伺服器?
│ ├── 否:中繼代理程式 (Relay Agent) / 路由 / 防火牆問題。
│ └── 是
▼
[檢查伺服器記錄] ───────────► 是否傳送 DHCPOFFER?
├── 否:位址池已耗盡 / 範圍未啟用。
└── 是:回傳路徑受阻 (VLAN/路由)。
關鍵疑難排解指令
若要驗證實體網路設備上的 DHCP 狀態並診斷故障,請使用以下指令:
Cisco IOS (DHCP 伺服器或中繼)
# 檢視 DHCP 位址池利用率與可用位址
show ip dhcp pool
# 檢視作用中的 IP 位址繫結
show ip dhcp binding
# 監控 DHCP 伺服器統計資料 (discover、request、ack 計數)
show ip dhcp server statistics
# 檢視 DHCP 衝突資料庫 (因衝突而被標記為損壞的 IP)
show ip dhcp conflict
Linux (DHCP 伺服器或用戶端)
# 在 Linux 用戶端上檢視即時 DHCP 用戶端租約請求
sudo dhclient -v wlan0
# 在特定介面上擷取 DHCP 流量 (UDP 連接埠 67 和 68)
sudo tcpdump -i eth0 -n -vv 'udp and (port 67 or port 68)'
# 檢查 dnsmasq DHCP 租約資料庫
cat /var/lib/misc/dnsmasq.leases
Windows (DHCP 用戶端)
# 釋放目前的 IP 位址
ipconfig /release
# 重新取得 IP 位址(啟動新的 DHCP 握手)
ipconfig /renew
投資報酬率與業務影響
投資於高彈性、架構完善的 DHCP 基礎設施不僅僅是技術上的必要性,更是直接影響獲利與營運效率的關鍵業務推動力。
量化無縫上網的商業價值
- 提升顧客體驗與品牌忠誠度:在旅宿與活動產業中,無線網路連線是顧客滿意度的主要驅動力。遇到上網阻礙的顧客極有可能留下負面評價,直接影響預訂率。消除 DHCP 逾時可確保無摩擦的第一印象。
- 最大化顧客 WiFi 行銷投資報酬率:對於零售和娛樂場所, Guest WiFi 是一個強大的行銷管道。透過確保 100% 的成功上網率,行銷團隊可以透過 WiFi Analytics 收集更多第一方數據(例如電子郵件、人口統計資料和人流量模式),從而推動高度精準的互動行銷活動並提升客戶終身價值。
- 降低 IT 支援開銷:與 DHCP 相關的工單(「無法連線至 WiFi」、「IP 位址錯誤」)是 IT 服務台最常見且最耗時的請求。透過實施 DHCP 備援、調整位址池大小以及部署 DHCP snooping,企業可以減少高達 40% 的無線網路相關支援工單,讓 IT 人員能夠專注於策略性計畫,而非基本疑難排解。
- 確保法規遵循與安全性:實施 DHCP snooping 並防範惡意 DHCP 伺服器,能直接支援符合關鍵安全標準,例如 PCI DSS(適用於零售支付環境)和 GDPR(透過保護顧客數據網路)。安全且記錄完善的 DHCP 架構可降低代價高昂的數據洩漏和監管罰款風險。
業務影響摘要表
| 指標 | 優化前 | 優化後 | 業務影響 |
|---|---|---|---|
| DHCP 逾時率 | 8.5%(尖峰時段) | < 0.1% | 無縫的使用者上網體驗,消除連線投訴 |
| 平均修復時間 (MTTR) | 45 分鐘 | < 5 分鐘 | 透過記錄完善的 VLAN/範圍對應進行快速疑難排解 |
| 顧客 WiFi 同意訂閱率 | 62% | 88% | 增加行銷資料庫成長,收集更豐富的數據 |
| IT 支援工單量 | 高(DHCP/IP 錯誤) | 微乎其微 | 減少 40% 的無線網路相關服務台工單 |
參考資料
- IETF RFC 2131 - Dynamic Host Configuration Protocol
- IEEE 802.11-2020 - Wireless LAN Medium Access Control and Physical Layer Specifications
- 針對行動裝置優化 WiFi DHCP 租期
- IETF RFC 3046 - DHCP 中繼代理資訊選項
- IETF RFC 8156 - DHCPv4 容錯移轉協定
- Cisco Systems - 設定 DHCP 窺探 (DHCP Snooping)
- 為什麼體育場 WiFi 會陷入停頓(以及如何解決)
- HPE Aruba Networking - 大型公共場所 Wi-Fi 設計與部署指南
- 如何排查 WiFi 網路上的 DHCP 問題
- IETF RFC 3993 - DHCP 中繼代理資訊選項的訂戶 ID 子選項
Définitions clés
DHCP (Dynamic Host Configuration Protocol)
Un protocole de gestion de réseau utilisé sur les réseaux IP (Internet Protocol) par lequel un serveur DHCP attribue dynamiquement une adresse IP et d'autres paramètres de configuration réseau à chaque appareil sur un réseau afin qu'ils puissent communiquer avec d'autres réseaux IP.
Le DHCP est la première étape cruciale du processus de connexion au réseau sans fil ; s'il échoue, les clients ne peuvent accéder à aucune ressource réseau, y compris les portails invités.
Processus DORA
La séquence standard en quatre étapes de messages échangés entre un client DHCP et un serveur pour négocier un bail d'adresse IP : DHCPDISCOVER, DHCPOFFER, DHCPREQUEST et DHCPACK.
Comprendre la séquence DORA est essentiel pour diagnostiquer l'origine de l'échec d'un handshake DHCP lors du dépannage réseau.
Agent relais DHCP (DHCP Relay Agent)
Tout hôte ou appareil réseau (généralement un commutateur de couche 3 ou un routeur) qui transfère les paquets DHCP entre les clients et les serveurs lorsqu'ils résident sur des sous-réseaux ou des VLAN différents.
Les agents relais sont requis dans les réseaux d'entreprise segmentés pour centraliser les services DHCP et empêcher le trafic de diffusion (broadcast) de franchir les limites des routeurs.
DHCP Snooping
Une fonctionnalité de sécurité de niveau 2 intégrée aux commutateurs managés qui filtre les messages DHCP non approuvés et construit une base de données de liaison des mappages MAC-à-IP de confiance.
Le DHCP snooping est la principale défense contre les serveurs DHCP non autorisés et les attaques de l'homme du milieu (man-in-the-middle) sur les réseaux sans fil d'entreprise.
Épuisement de la plage d'adresses IP (IP Pool Exhaustion)
Une condition qui se produit lorsque toutes les adresses IP disponibles dans l'étendue configurée d'un serveur DHCP ont été allouées, ne laissant plus d'adresses disponibles pour les nouveaux clients.
L'épuisement de la plage est la cause principale des expirations de délai DHCP dans les espaces à haute densité, et se résout en dimensionnant correctement les étendues ou en réduisant les durées de bail.
Durée du bail DHCP (DHCP Lease Time)
La durée pendant laquelle un serveur DHCP alloue une adresse IP à un appareil client spécifique avant que ce client ne doive demander un renouvellement de bail.
L'optimisation des durées de bail en fonction du comportement des utilisateurs (courte pour les réseaux d'invités, plus longue pour le personnel) est essentielle pour maintenir l'efficacité de la plage d'adresses IP.
Serveur DHCP non autorisé (Rogue DHCP Server)
Un serveur DHCP non autorisé connecté à un réseau, qui distribue des configurations IP non valides ou malveillantes aux clients, entraînant des problèmes de connectivité et des vulnérabilités de sécurité.
Les serveurs non autorisés sont courants dans les espaces publics ouverts et sont neutralisés en activant le DHCP snooping sur les commutateurs d'accès.
Suppression de la diffusion (Broadcast Suppression)
Une technique de configuration réseau qui limite le débit du trafic de diffusion (broadcast) et de multidiffusion (multicast) sur un VLAN ou un port de commutateur afin d'éviter la congestion du réseau et les tempêtes de diffusion.
La suppression de la diffusion est essentielle dans les réseaux sans fil à haute densité pour protéger le temps d'antenne RF et garantir que les paquets DHCP critiques ne soient pas retardés.
Exemples concrets
Un centre de conférence à haute densité doté d'une salle plénière principale conçue pour accueillir 2 500 personnes rencontre des problèmes massifs de connexion WiFi lors du discours d'ouverture. Les participants signalent que leurs appareils restent bloqués sur "Obtention de l'adresse IP" pendant plusieurs minutes, et ceux qui parviennent à se connecter sont fréquemment déconnectés lorsqu'ils se déplacent entre la salle plénière et la zone d'exposition. La configuration réseau actuelle utilise un seul VLAN client mappé sur un sous-réseau "/24" standard avec une durée de bail DHCP de 24 heures, desservi par un seul routeur principal. Comment ce réseau doit-il être réarchitecturé pour éliminer ces défaillances ?
Pour résoudre ces échecs de connexion, l'architecture réseau doit être repensée pour gérer le comportement des clients temporaires à haute densité. Suivez ce flux de travail de remédiation en plusieurs étapes :
Étendre l'espace d'adressage IP (dimensionnement du sous-réseau) : Remplacez le sous-réseau "/24" standard (qui ne fournit que 254 adresses IP) par un sous-réseau "/21" (fournissant 2 046 adresses IP utilisables) ou implémentez un pool multi-VLAN. Cela garantit que le pool d'adresses IP est suffisamment dimensionné pour gérer 2 500 participants simultanés, dont beaucoup porteront plusieurs appareils connectés (moyenne de 1,5 appareil par participant = 3 750 IP requises). Si un seul sous-réseau plat "/20" (4 094 IP) est utilisé, il s'adaptera facilement à la capacité totale de l'événement.
Optimiser les durées de bail DHCP : Réduisez la durée du bail DHCP de 24 heures à 45 minutes sur le réseau sans fil invité. Étant donné que les participants à la conférence sont très mobiles et entrent et sortent de la salle plénière, une durée de bail courte garantit que les adresses IP sont rapidement récupérées sur les appareils qui ont quitté la zone, évitant ainsi l'épuisement artificiel du pool.
Déployer des serveurs DHCP redondants : Éliminez le point de défaillance unique en déployant une paire de serveurs DHCP redondants. Configurez le basculement DHCP de Windows Server en mode d'équilibrage de charge (répartition 50/50) sur deux machines virtuelles indépendantes, ou utilisez un équipement DHCP dédié à haute disponibilité. Cela garantit que si un serveur ou un chemin réseau tombe en panne, le serveur restant peut gérer l'intégralité de la charge de requêtes.
Implémenter la suppression de la diffusion de couche 2 et le proxy DHCP : Activez la suppression de la diffusion sur le contrôleur sans fil, en limitant le trafic de diffusion à 100 paquets par seconde. Activez le proxy DHCP sur les points d'accès pour convertir les messages de diffusion "DHCPOFFER" et "DHCPACK" en trames unicast. Cela réduit considérablement la consommation de temps d'antenne sans fil et évite les collisions de paquets.
Configurer le DHCP Snooping et la validation ARP : Activez le DHCP snooping sur tous les commutateurs d'accès pour protéger le réseau contre les serveurs DHCP indésirables et prévenir les attaques par épuisement DHCP. Limitez le débit des paquets DHCP sur les ports orientés vers les clients à 15 paquets par seconde.
Un hôtel de luxe de 500 chambres déploie un nouveau SSID invité sur l'ensemble de sa propriété. L'équipe réseau a créé un nouveau VLAN invité (VLAN 50) et configuré un serveur DHCP Windows central avec une étendue "/22" correspondante. Cependant, lors des tests, les appareils associés au SSID invité dans les chambres d'hôtel ne parviennent pas à obtenir une adresse IP et expirent, tandis que les appareils connectés directement aux ports câblés des bureaux administratifs (VLAN 10) obtiennent des adresses IP instantanément. Quelle est la cause la plus probable de ce problème, et comment doit-il être diagnostiqué et résolu ?
Le fait que les clients câblés sur le VLAN 10 obtiennent des adresses IP alors que les clients sans fil sur le VLAN 50 expirent indique que le problème est spécifique au chemin ou à la configuration du VLAN 50. La cause la plus probable est un agent de relais DHCP (IP Helper) manquant ou mal configuré sur l'interface du commutateur de couche 3 pour le VLAN 50, ou un tag VLAN manquant le long du chemin de jonction (trunk) entre les points d'accès et le commutateur principal. Suivez ce flux de travail de diagnostic et de résolution :
Vérifier la configuration de l'agent de relais DHCP : Connectez-vous au commutateur de couche 3 principal (ou à la passerelle) et inspectez la configuration de l'interface du VLAN 50. Assurez-vous que la commande "ip helper-address" est présente et pointe vers l'adresse IP correcte du serveur DHCP Windows. Si la commande est manquante, le commutateur ne transmettra pas les paquets de diffusion "DHCPDISCOVER" du client au serveur DHCP.
Vérifier le Trunking VLAN de bout en bout : Vérifiez que le VLAN 50 est taggué sur tous les ports de commutateur le long du chemin menant des points d'accès au commutateur principal. Utilisez des commandes telles que "show interfaces trunk" sur les commutateurs Cisco pour confirmer que le VLAN 50 est autorisé et actif sur toutes les liaisons de jonction. Si le VLAN 50 est manquant sur un seul port de jonction, les diffusions DHCP des clients seront abandonnées avant d'atteindre le commutateur de couche 3.
Effectuer des captures de paquets : Pour isoler le point de défaillance, effectuez des captures de paquets simultanées à trois emplacements :
- Sur le client sans fil (à l'aide de Wireshark ou d'outils natifs du système d'exploitation) pour confirmer que les diffusions "DHCPDISCOVER" sont bien envoyées.
- Sur l'interface du commutateur de couche 3 pour le VLAN 50 pour confirmer que le commutateur reçoit les diffusions.
- Sur l'interface réseau du serveur DHCP pour confirmer que les paquets DHCP unicast transférés arrivent bien.
Vérifier l'activation de l'étendue du serveur DHCP : Assurez-vous que l'étendue DHCP pour le sous-réseau du VLAN 50 (par exemple, 192.168.50.0/22) est entièrement créée, activée et dispose d'une plage active d'adresses IP qui n'entre pas en conflit avec des attributions statiques.
Appliquer la correction de configuration : Sur le commutateur de couche 3 principal, appliquez la configuration correcte de l'adresse d'assistance :
interface Vlan50 description Guest_WiFi_VLAN ip address 192.168.50.1 255.255.252.0 ip helper-address 10.10.10.10 # Windows DHCP Server IP no shutdown
Un grand centre commercial comptant plus de 150 boutiques subit des interruptions de connexion WiFi très intermittentes. L'équipe informatique signale que certains clients se connectent instantanément et naviguent sans problème, tandis que d'autres au même endroit restent bloqués sur "Obtention de l'adresse IP" ou reçoivent un avertissement "Pas de connexion Internet". Un examen des journaux du serveur DHCP montre des milliers de baux actifs, mais aussi un volume élevé d'erreurs "DHCP Conflict" et plusieurs cas où le serveur répond aux clients par un "DHCPNAK" (accusé de réception négatif). Comment ce problème doit-il être étudié et résolu ?
La présence d'erreurs "DHCP Conflict" et de réponses "DHCPNAK" dans les journaux du serveur suggère fortement la présence d'un serveur DHCP indésirable (rogue) sur le réseau ou d'un conflit d'adresses IP causé par des attributions statiques dans la plage DHCP. Suivez ce flux de travail d'investigation et de remédiation systématique :
Isoler et détecter le serveur DHCP indésirable : Utilisez les journaux de la base de données de DHCP snooping sur vos commutateurs d'accès pour identifier l'activité de serveurs DHCP non autorisés. Exécutez la commande suivante sur vos commutateurs principaux et d'accès pour afficher les conflits détectés ou les paquets DHCP non approuvés :
show ip dhcp snooping database show ip dhcp conflictLa base de données des conflits listera les adresses MAC des appareils ayant répondu aux sondes ARP pour des IP que le serveur DHCP tentait d'attribuer, ou des appareils qui distribuent activement des baux non autorisés.
Activer le DHCP Snooping globalement et sur les VLANs clients : Pour neutraliser immédiatement tout serveur DHCP indésirable, activez le DHCP snooping sur tous les commutateurs. Configurez tous les ports orientés vers les clients comme non approuvés (untrusted), et n'accordez votre confiance qu'aux ports spécifiques connectés à vos serveurs DHCP légitimes ou aux liaisons de jonction principales. Cela garantit que tous les paquets "DHCPOFFER" ou "DHCPACK" non autorisés sont abandonnés au niveau du port du commutateur avant d'atteindre d'autres clients.
Configurer l'inspection ARP (DAI) : Pour empêcher les clients d'utiliser des adresses IP usurpées ou de provoquer des conflits d'IP, activez l'inspection ARP dynamique (DAI) sur les VLANs clients. DAI utilise la base de données de liaison du DHCP snooping pour valider les paquets ARP, en rejetant tous les paquets présentant des mappages MAC-à-IP invalides :
ip arp inspection vlan 10,20,30Exclure les adresses IP statiques du pool DHCP : Assurez-vous que toutes les adresses IP statiques attribuées aux appareils d'infrastructure (tels que les imprimantes, les points d'accès ou la signalisation numérique) sont explicitement exclues de la plage d'étendue DHCP sur le serveur pour éviter que celui-ci ne propose accidentellement ces adresses IP aux clients.
Déployer la sécurité des ports et le 802.1X : Pour les ports câblés dans les magasins de détail ou les espaces publics, implémentez la sécurité des ports (Port Security) afin de limiter le nombre d'adresses MAC autorisées sur un port, ou déployez l'authentification 802.1X pour empêcher les appareils non autorisés de se connecter à l'infrastructure physique du réseau.
Questions d'entraînement
Q1. Un responsable informatique dans un grand centre commercial constate que pendant les heures de pointe des fêtes, les connexions WiFi des visiteurs échouent fréquemment. Le journal du serveur DHCP est inondé d'erreurs "DHCP Scope Full". Le VLAN invité actuel est configuré avec un masque de sous-réseau `/23` et une durée de bail par défaut de 24 heures. Quelles sont les deux modifications de configuration les plus immédiates et les plus efficaces que le responsable devrait mettre en œuvre pour résoudre ce problème, et pourquoi ?
Conseil : Prenez en compte la relation entre la taille du sous-réseau, le temps de présence des clients et la récupération des adresses IP.
Voir la réponse type
Le responsable doit mettre en œuvre les deux modifications de configuration immédiates suivantes :
Réduire la durée du bail DHCP (Lease Time) : Réduire la durée du bail de 24 heures à 30 ou 45 minutes. Les visiteurs d'un centre commercial étant très éphémères (temps de présence typique de 1 à 2 heures), un bail de 24 heures oblige le serveur DHCP à conserver les adresses IP bien après le départ des visiteurs. La réduction de la durée du bail garantit que les adresses IP sont rapidement récupérées et mises à la disposition des nouveaux clients, multipliant ainsi l'efficacité de la capacité du pool existant sans modifier la structure du sous-réseau.
Élargir la plage du sous-réseau (dimensionnement CIDR) : Passer le sous-réseau du VLAN invité d'un
/23(fournissant 510 adresses IP utilisables) à un/21(fournissant 2 046 adresses IP utilisables) ou un/20(fournissant 4 094 adresses IP utilisables). Un sous-réseau/23est beaucoup trop petit pour un grand centre commercial pendant les heures de pointe, d'autant plus que de nombreux clients possèdent plusieurs appareils connectés (téléphones, montres connectées, tablettes). L'élargissement de la plage garantit qu'il y a suffisamment d'adresses IP disponibles pour gérer la charge maximale d'appareils simultanés.
Ces deux modifications fonctionnent en tandem : l'extension du sous-réseau augmente la capacité absolue du pool, tandis que la réduction de la durée du bail garantit une efficacité maximale dans la réutilisation des adresses, éliminant complètement les erreurs "DHCP Scope Full".
Q2. Un ingénieur réseau dépanne un SSID invité nouvellement déployé dans un hôtel. Les clients sans fil s'associent avec succès à l'AP mais ne parviennent pas à obtenir d'adresse IP, ce qui entraîne un dépassement de délai après plusieurs secondes. Une capture de paquets sur le port du commutateur connecté à l'AP montre des diffusions `DHCPDISCOVER` entrant dans le commutateur, mais une capture sur l'interface réseau du serveur DHCP central ne montre aucun paquet entrant provenant du sous-réseau invité de l'hôtel. Le serveur DHCP est situé sur un sous-réseau différent (10.10.10.0/24) de celui des clients sans fil invités (192.168.50.0/22). Quelle configuration est manquante, sur quel équipement doit-elle être appliquée et quelle est la commande exacte pour l'appliquer ?
Conseil : Le serveur DHCP étant sur un sous-réseau différent de celui des clients, un équipement de niveau 3 doit relayer le trafic de diffusion (broadcast).
Voir la réponse type
La configuration manquante est l'Agent de relais DHCP (IP Helper). Les messages de découverte DHCP étant des diffusions de niveau 2 (Layer 2 broadcasts), ils ne peuvent pas franchir le routeur ou la frontière de niveau 3 entre le sous-réseau invité du client (192.168.50.0/22) et le sous-réseau du serveur DHCP (10.10.10.0/24). Sans agent de relais, le commutateur ou le routeur rejette les paquets de diffusion, les empêchant d'atteindre le serveur.
Cette configuration doit être appliquée sur le commutateur de niveau 3 ou la passerelle de sécurité (Security Gateway) qui sert de passerelle par défaut pour le VLAN sans fil invité (VLAN 50).
Dans le cas d'un commutateur de niveau 3 Cisco IOS, l'ingénieur doit appliquer la commande ip helper-address sur l'interface VLAN 50, en pointant vers l'adresse IP du serveur DHCP central (par exemple, 10.10.10.10) :
interface Vlan50
description Guest_WiFi_Gateway
ip address 192.168.50.1 255.255.252.0
ip helper-address 10.10.10.10
no shutdown
Cette commande indique au commutateur d'intercepter les diffusions DHCP sur le VLAN 50, de les convertir en paquets unicast de niveau 3 avec l'IP source de la passerelle du VLAN 50 (192.168.50.1), et de les envoyer directement au serveur DHCP à l'adresse 10.10.10.10. Le serveur utilisera ensuite l'IP de la passerelle pour sélectionner la plage correcte et renvoyer une offre.
Q3. Un architecte réseau de stade conçoit un réseau sans fil pour supporter 50 000 supporters simultanés. Pour minimiser le trafic de diffusion et la consommation de temps d'antenne RF, l'architecte souhaite implémenter la suppression du broadcast et convertir les diffusions DHCP en unicast. Cependant, certains ingénieurs juniors craignent que la conversion des diffusions DHCP en unicast ne perturbe le protocole DHCP, car les clients n'ont pas encore d'adresse IP pour recevoir des paquets unicast. Comment l'architecte doit-il expliquer le mécanisme technique de la conversion broadcast-to-unicast pour répondre à ces préoccupations ?
Conseil : Considérez comment l'Access Point ponte les trames de niveau 2 et comment l'adresse MAC du client est utilisée dans l'en-tête 802.11.
Voir la réponse type
L'architecte doit expliquer que la conversion des diffusions DHCP en unicast ne perturbe pas le protocole DHCP car l'Access Point (AP) fonctionne au niveau 2 (Layer 2) et peut cibler les trames directement vers l'adresse MAC physique du client, même si celui-ci ne dispose pas encore d'une adresse IP.
Voici le mécanisme technique :
L'adresse MAC du client est connue : Lors de la phase d'association initiale, le client établit une connexion sécurisée de niveau 2 avec l'AP. L'AP connaît l'adresse MAC unique du client et l'associe à un port virtuel et une interface radio spécifiques.
L'AP intercepte la diffusion : Lorsque le serveur DHCP envoie un
DHCPOFFERou unDHCPACKsous forme de diffusion de niveau 2 (MAC de destinationFF:FF:FF:FF:FF:FF), l'AP intercepte ce paquet sur son interface filaire.Conversion en Unicast : Au lieu de transmettre le paquet dans les airs sous forme de trame de diffusion (ce qui obligerait tous les clients du canal à se réveiller et à le traiter au débit de données obligatoire le plus bas), l'AP modifie l'en-tête MAC 802.11. Il remplace l'adresse MAC de diffusion par l'adresse MAC unicast spécifique du client (qu'il a extraite du champ d'adresse matérielle client du paquet DHCP,
chaddr).Transmission à haut débit : La trame étant désormais une trame unicast, l'AP peut la transmettre en utilisant le débit de données maximal pris en charge par le client (via le beamforming, le MIMO et des modulations d'ordre supérieur comme la QAM). Elle bénéficie également des accusés de réception (ACK) de niveau 2 de la norme 802.11, garantissant une livraison fiable.
Traitement par le client : La carte sans fil du client reçoit la trame unicast, reconnaît sa propre adresse MAC dans l'en-tête 802.11 et transmet la charge utile (l'offre ou l'accusé de réception DHCP) à la pile réseau. Le système d'exploitation du client traite la charge utile DHCP normalement, sans se rendre compte que la trame a été convertie de broadcast en unicast dans les airs.
Cette explication démontre que la conversion broadcast-to-unicast est une optimisation de niveau 2 qui exploite la couche MAC 802.11 pour préserver le temps d'antenne RF, sans modifier la charge utile du protocole DHCP de niveau 3.
Continuer la lecture de cette série
Dépannage du WiFi public : résoudre les erreurs « Connecté, pas d'Internet » et les échecs de redirection vers la page d'accueil
Ce guide de référence technique officiel explique les mécanismes sous-jacents de la détection de Captive Portal et détaille les six principaux modes de défaillance qui empêchent le WiFi invité de se connecter. Il fournit aux responsables informatiques et aux architectes réseau un cadre de dépannage pratique pour résoudre les problèmes de redirection HTTP, les conflits DNS et les défis liés à la randomisation des adresses MAC.
Utiliser la capture de paquets (PCAP) pour diagnostiquer les lenteurs de performance WiFi
Ce guide de référence technique fournit aux responsables informatiques, architectes réseau et directeurs d'exploitation de sites une méthodologie structurée au niveau des paquets pour diagnostiquer et résoudre les lenteurs de performance des réseaux WiFi d'entreprise grâce à l'analyse de capture de paquets (PCAP). En décortiquant les trames 802.11 brutes — y compris les taux de retransmission, l'utilisation du temps d'antenne et les métadonnées de la couche physique — les équipes peuvent isoler avec précision les goulots d'étranglement de la couche RF des problèmes filaires ou applicatifs. Applicable aux sites à haute densité tels que les hôtels, les chaînes de magasins, les stades et les centres de conférence, ce guide propose des flux de diagnostic exploitables, des études de cas réels et des étapes de remédiation de configuration pour récupérer de la capacité réseau et préserver l'expérience client.
Résolution des échecs d'authentification 802.1X (RADIUS/EAP)
Ce guide fournit une référence complète et exploitable pour les responsables informatiques, les architectes réseau et les directeurs d'exploitation de sites sur le diagnostic et la résolution des échecs d'authentification 802.1X au sein des infrastructures RADIUS et EAP. Il couvre l'ensemble de la chaîne d'authentification — de la mauvaise configuration du supplicant et de l'expiration des certificats aux discordances de clés secrètes partagées RADIUS et à la fragmentation du transit réseau — avec des études de cas réelles issues des secteurs de l'hôtellerie et de la vente au détail. Les équipes responsables de la conformité PCI DSS, des déploiements WPA3-Enterprise et du contrôle d'accès réseau multi-sites y trouveront des cadres de diagnostic structurés, des listes de contrôle de mise en œuvre et des stratégies de atténuation des risques directement applicables à leurs opérations.