Why is Our Guest WiFi So Slow? Diagnosing Network Congestion
Este guia diagnostica os fatores ocultos do congestionamento do WiFi de convidados — telemetria em segundo plano, redes de anúncios programáticos e atualizações automáticas de SO — que, coletivamente, consomem até 40% da largura de banda do WiFi público antes mesmo de um convidado abrir um navegador. Fornece uma estrutura de implementação faseada e neutra em termos de fornecedor para filtragem de DNS e políticas de QoS que recuperam essa largura de banda, melhoram a experiência do convidado e proporcionam um ROI mensurável. Destinado a Diretores de TI e Gestores de Operações nos setores da hotelaria, retalho, eventos e ambientes do setor público.
Ouça este guia
Ver transcrição do podcast
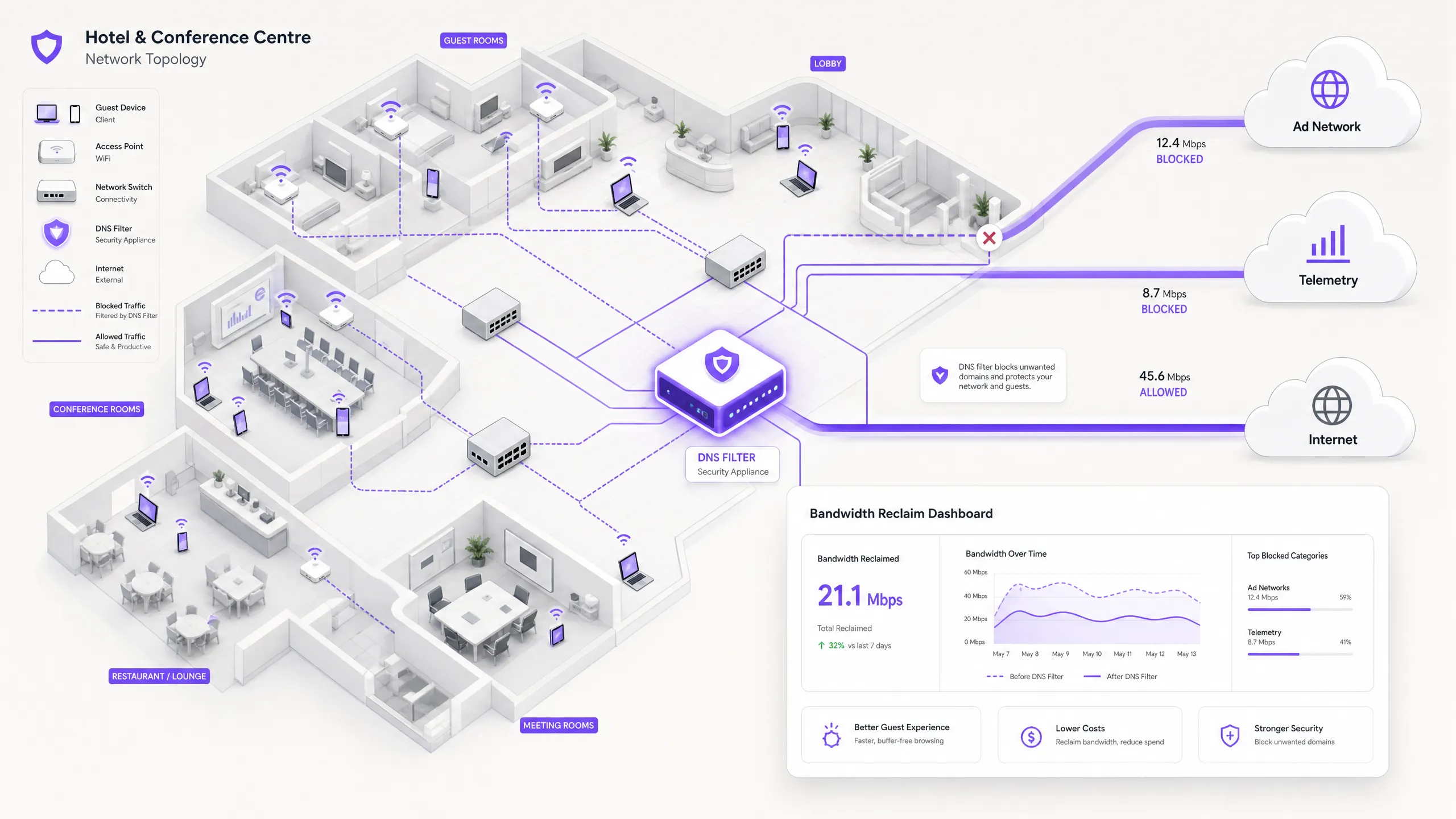
Executive Summary
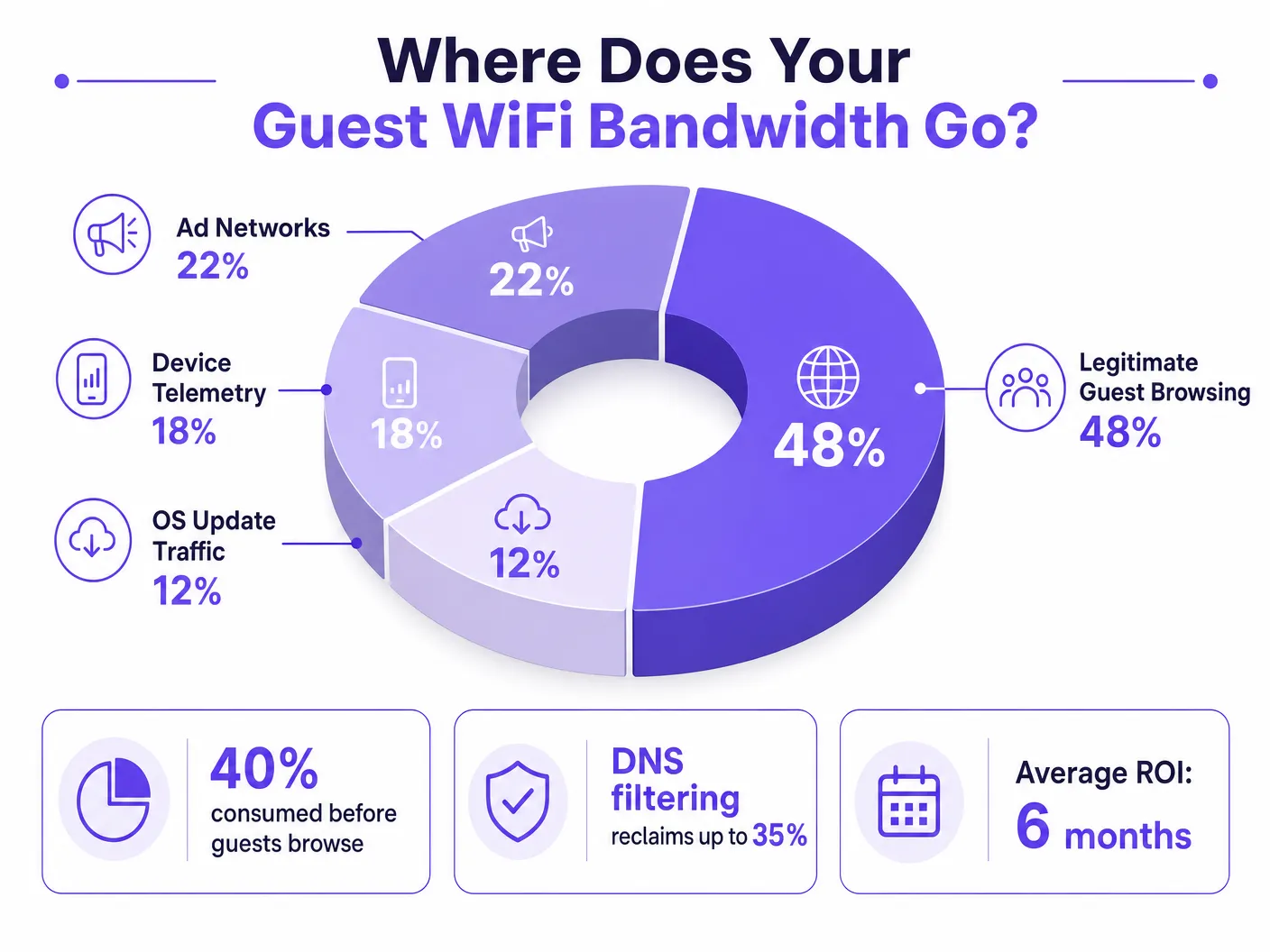
For IT Directors and Operations Managers overseeing high-density venues, ensuring a reliable Guest WiFi experience is a constant battle against network congestion. While legacy approaches focus on increasing overall bandwidth or deploying additional access points, the root cause of slow throughput often lies not in legitimate user traffic, but in the hidden layer of background data. In modern environments — from sprawling Hospitality complexes to high-footfall Retail spaces — up to 40% of public WiFi bandwidth is consumed by device telemetry, programmatic ad networks, and automated OS updates before a guest even opens a browser.
This technical reference guide provides a definitive methodology for diagnosing this congestion and implementing strategic mitigation. By deploying network-level DNS filtering and Response Policy Zones (RPZ), enterprise network architects can reclaim significant bandwidth, reduce latency, and dramatically improve the end-user experience without incurring the capital expenditure of infrastructure upgrades. We will explore the technical architecture of these solutions, real-world implementation case studies, and the measurable ROI of reclaiming your network.
Technical Deep-Dive
The Anatomy of Background Congestion
When a guest device authenticates to a public network, it immediately initiates a barrage of background connections. These connections are primarily driven by three categories of traffic that, in aggregate, constitute what network engineers call the phantom load — bandwidth consumed by the network before any deliberate guest activity occurs.
1. Device Telemetry and Analytics
Modern operating systems (iOS, Android, Windows) and installed applications constantly transmit usage data, location metrics, crash reports, and behavioural analytics to remote servers. In a dense environment such as a Transport hub or conference centre, thousands of devices simultaneously transmitting small but frequent telemetry payloads can exhaust available wireless airtime and overwhelm NAT tables. A single iOS device can generate upwards of 200 distinct background DNS queries within the first 60 seconds of connecting to an unmetered network.
2. Programmatic Ad Networks
Many free applications rely on programmatic advertising ecosystems. The moment a device detects an unmetered WiFi connection, these apps begin pre-fetching video ads, high-resolution display banners, and tracking scripts from ad exchange platforms. This traffic is both high-bandwidth and latency-sensitive, and it will aggressively compete for airtime with legitimate guest browsing. Analysis of public venue networks consistently shows that programmatic ad traffic accounts for 15–22% of total WAN utilisation during peak hours.
3. Automated OS and Application Updates
Without proper traffic shaping, devices will attempt to download large OS patches and application updates as soon as they detect an unmetered WiFi connection. A single iOS major update can be 3–5 GB. In a 500-device environment, a simultaneous update trigger — common when a new OS version is released — can saturate even a 1 Gbps WAN link within minutes.
Why Traditional Approaches Fall Short
The conventional response to guest WiFi congestion is to increase WAN bandwidth or deploy additional access points. While both measures have their place, neither addresses the phantom load. Adding more bandwidth simply provides more capacity for background traffic to consume. Deep Packet Inspection (DPI), the other traditional tool, is increasingly ineffective: the widespread adoption of TLS 1.3 and end-to-end encryption means that the majority of traffic payloads are opaque to inspection engines. You cannot throttle what you cannot classify.
For a broader discussion of how wireless frequencies interact with high-density deployments, see our guide on Wi-Fi Frequencies: A Guide to Wi-Fi Frequencies in 2026 .
DNS Filtering: The Efficient Countermeasure
The modern, scalable solution is DNS filtering at the network edge. Rather than inspecting traffic payloads, DNS filtering operates at the resolution layer — preventing connections from being established in the first place.
When a device requests access to a known ad network or telemetry domain, the DNS resolver checks the request against a Response Policy Zone (RPZ). If the domain appears in the blocklist, the resolver returns an NXDOMAIN (Non-Existent Domain) response, or sinkholes the traffic to a local null IP address. The connection is terminated before the TCP handshake occurs, preserving both wireless airtime and WAN bandwidth. This approach is computationally inexpensive, scales linearly with resolver capacity, and is unaffected by payload encryption.
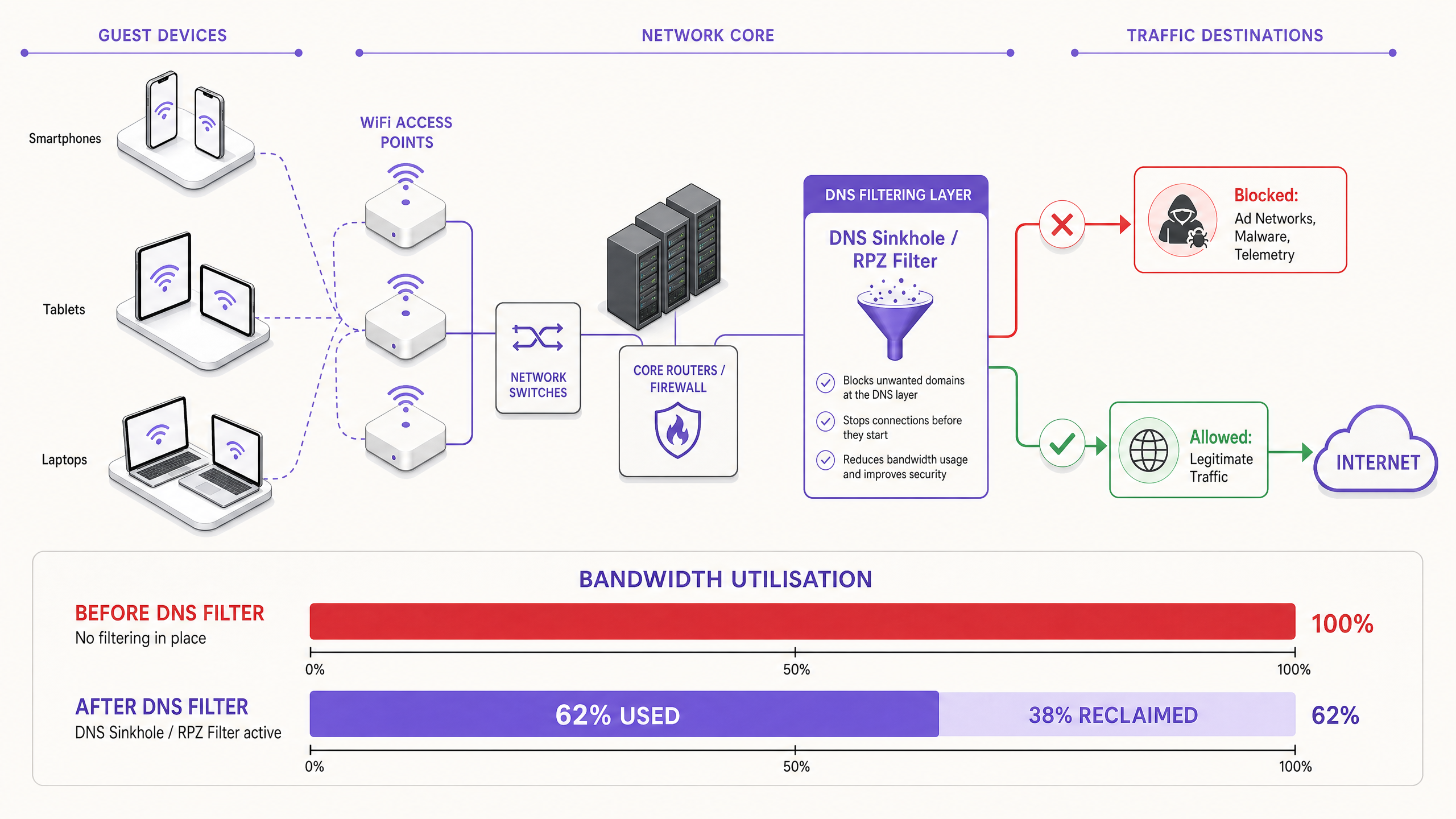
The Security Dimension
DNS filtering delivers a significant secondary benefit: security. By blocking known malware Command and Control (C2) domains, phishing infrastructure, and exploit kit delivery networks at the DNS layer, the guest network becomes substantially more defensible. This is directly relevant to compliance obligations under frameworks such as PCI DSS (which requires network segmentation and monitoring for cardholder data environments) and GDPR (which mandates appropriate technical measures to protect personal data). For a detailed treatment of audit trail requirements in this context, see Explain what is audit trail for IT Security in 2026 .
For organisations managing educational environments where ad blocking also serves a safeguarding function, the principles covered in Minimising Student Distractions with Network-Level Ad Blocking are directly applicable.
Implementation Guide
Deploying a robust DNS filtering architecture requires careful planning to avoid disrupting legitimate guest services. The implementation should follow a phased approach.
Phase 1: Baseline Assessment and Visibility
Before implementing any blocks, establish a baseline of current traffic patterns. Utilise WiFi Analytics to identify the top bandwidth-consuming domains and categories over a representative 7–14 day period. This audit phase is critical for understanding the specific traffic profile of your venue and for building the business case for the investment. Key metrics to capture include:
| Metric | Target Baseline | Notes |
|---|---|---|
| Top 20 DNS domains by query volume | Full list | Identify telemetry and ad domains |
| WAN utilisation by category | % split | Quantify the phantom load |
| Peak concurrent device count | Number | Size resolver infrastructure |
| DNS query failure rate | < 0.1% | Establish pre-deployment benchmark |
Phase 2: Staged RPZ Deployment
Begin by deploying the RPZ in log-only mode. This allows you to verify the accuracy of your blocklists without impacting the user experience. Focus on high-confidence categories first:
- Known Malware and C2 Domains: Immediate security benefit with near-zero risk of false positives. Use threat intelligence feeds from reputable providers.
- High-Bandwidth Programmatic Ad Networks: Target the major video ad exchange platforms. These are well-documented and unlikely to host legitimate content.
- Aggressive Telemetry Endpoints: Block non-essential tracking domains. Maintain a careful allow-list for domains required for captive portal authentication flows.
Once log-only mode confirms acceptable false positive rates (target < 0.5% of queries), move to enforcement mode.
Phase 3: Traffic Shaping and QoS Integration
For traffic that cannot be outright blocked (e.g., OS updates from Apple, Microsoft, and Google), implement Quality of Service (QoS) policies. Rate-limit update servers to a defined ceiling — typically 10–15% of total WAN capacity — ensuring that interactive guest traffic (web browsing, VoIP, video conferencing) receives priority queuing. This is particularly important for Healthcare environments where clinical staff may share a network segment with guests.
For guidance on optimising broader network environments, including office and mixed-use deployments, see Office Wi-Fi: Optimize Your Modern Office Wi-Fi Network .
Best Practices
Maintain Explicit Allow-lists for Critical Services. Ensure that domains essential for captive portal authentication, payment gateways (PCI DSS compliance), and core venue operations are explicitly permitted. A misconfigured blocklist that breaks the login flow will generate immediate and significant support load.
Communicate the Policy Transparently. Your Terms of Service should state that network traffic is managed to ensure a high-quality experience for all users. This is both a legal best practice under GDPR and a reasonable expectation-setting measure for guests.
Automate Blocklist Updates. The landscape of ad networks and telemetry domains shifts constantly. Threat intelligence feeds and RPZ lists must be updated dynamically — ideally on a sub-24-hour cycle — to remain effective.
Address DNS Evasion Proactively. Implement firewall rules to intercept and redirect all outbound port 53 (UDP and TCP) traffic to the local resolver. This prevents clients from bypassing filtering by hardcoding external DNS servers.
Plan for DNS over HTTPS (DoH). As DoH adoption increases, clients may route DNS queries over HTTPS to bypass local resolvers entirely. Evaluate whether to block known DoH providers (e.g., dns.google, cloudflare-dns.com) or to deploy a transparent DoH proxy that enforces local policy.
Align with IEEE 802.1X and WPA3. Ensure that your DNS filtering architecture is compatible with your authentication framework. In environments using IEEE 802.1X with RADIUS-based authentication, DNS filtering policies can be applied per VLAN or per user group, enabling granular control.
Troubleshooting & Risk Mitigation
Common Failure Modes
| Failure Mode | Symptom | Mitigation |
|---|---|---|
| Over-blocking (CDN collision) | Broken webpages, missing images | Granular blocklists; rapid allow-listing process |
| DNS evasion (hardcoded resolvers) | Filtering bypassed by specific apps | Firewall redirect rules for port 53 |
| DoH bypass | Filtering bypassed by modern browsers | Block known DoH providers or deploy DoH proxy |
| Resolver performance bottleneck | Increased DNS latency across all clients | Scale resolver infrastructure; implement anycast |
| Captive portal breakage | Guests cannot authenticate | Explicit allow-list for portal domains and OS detection endpoints |
| Stale blocklists | New ad domains not blocked | Automate feed updates; monitor query logs for new high-volume domains |
Security Incident Response
If a guest device is identified as communicating with a known malware C2 domain (visible in DNS query logs), the RPZ will automatically block further communication. Ensure your incident response process includes a workflow for reviewing these events, as they may indicate a compromised device that requires isolation from the guest VLAN.
ROI & Business Impact
Implementing network-level DNS filtering delivers measurable, quantifiable business outcomes across multiple dimensions.
Bandwidth Reclamation and CapEx Deferral. Venues typically reclaim 20–40% of their total WAN bandwidth. This directly translates to cost savings by deferring the need for expensive circuit upgrades. For a venue currently paying for a 500 Mbps leased line, reclaiming 30% of capacity is equivalent to gaining 150 Mbps of effective throughput at zero additional cost.
Improved Guest Satisfaction and NPS. By eliminating background congestion, the perceived speed and reliability of the Guest WiFi improves dramatically. Reduced latency and consistent throughput lead to higher Net Promoter Scores and fewer operational support escalations.
Enhanced Security and Compliance Posture. Blocking malware and phishing domains at the DNS layer significantly reduces the risk of a security breach originating from the guest network. This directly supports compliance with PCI DSS network segmentation requirements and GDPR's obligation to implement appropriate technical security measures.
Operational Efficiency. Automated DNS filtering reduces the manual workload on network operations teams. Rather than reactively responding to congestion events, the network proactively manages its own traffic profile.
| Outcome | Typical Range | Measurement Method |
|---|---|---|
| Bandwidth reclaimed | 20–40% of WAN capacity | Before/after WAN utilisation monitoring |
| DNS query block rate | 15–35% of all queries | Resolver query logs |
| Guest satisfaction improvement | +8–15 NPS points | Post-stay/post-visit surveys |
| CapEx deferral | 1–3 years on circuit upgrade | Cost modelling |
| Security incident reduction | 40–60% fewer C2 detections | SIEM correlation |
By treating the network not just as a pipe, but as an intelligent, filtered gateway, IT leaders can deliver a superior, secure, and cost-effective connectivity experience — one that scales with venue growth without proportional infrastructure investment.
Definições Principais
Response Policy Zone (RPZ)
Um mecanismo em servidores DNS que permite a modificação de respostas DNS com base numa política definida. Quando um domínio consultado corresponde a uma entrada na RPZ, o resolver pode retornar uma resposta sintética (ex.: NXDOMAIN ou um IP de sinkhole) em vez da resposta real.
O principal mecanismo técnico para implementar a filtragem de DNS em toda a rede. As equipas de TI configuram as RPZs nos seus resolvers internos para bloquear redes de anúncios, domínios de malware e endpoints de telemetria sem necessidade de software do lado do cliente.
Deep Packet Inspection (DPI)
Uma forma de filtragem de pacotes de rede que examina o payload de dados de um pacote à medida que este passa por um ponto de inspeção, procurando a não conformidade com protocolos, conteúdos específicos ou critérios definidos.
Tradicionalmente utilizado para classificação e modelação de tráfego. Cada vez mais limitado pela adoção generalizada da encriptação de ponta a ponta TLS 1.3, que torna os payloads opacos. A filtragem de DNS é a alternativa preferida para ambientes de tráfego encriptado.
NXDOMAIN
Um código de resposta DNS (RCODE 3) que indica que o nome de domínio consultado não existe no namespace do DNS.
Retornado por um resolver de DNS de filtragem para bloquear intencionalmente uma ligação a um domínio indesejado. A aplicação cliente recebe esta resposta e abandona a tentativa de ligação, evitando o consumo de qualquer largura de banda.
DNS over HTTPS (DoH)
Um protocolo para realizar a resolução de DNS através do protocolo HTTPS (RFC 8484), encriptando as consultas e respostas de DNS entre o cliente e um resolver compatível com DoH.
Pode contornar a filtragem de DNS da rede local se os clientes estiverem configurados para utilizar fornecedores de DoH externos. Os administradores de rede devem implementar regras de firewall ou tráfego DoH proxy para aplicar as políticas de RPZ locais.
Quality of Service (QoS)
Um conjunto de mecanismos de rede que controlam a priorização de tráfego, limitação de taxa e enfileiramento para garantir o desempenho de aplicações críticas.
Utilizado em conjunto com a filtragem de DNS para gerir tráfego legítimo mas de elevada largura de banda (ex.: atualizações de SO) que não pode ser bloqueado. O QoS garante que o tráfego interativo de convidados receba prioridade sobre as transferências em massa em segundo plano.
Telemetry
A recolha e transmissão automatizada de dados operacionais de dispositivos para servidores remotos para monitorização, análise e diagnóstico.
No contexto de WiFi de convidados, a telemetria de dispositivos de sistemas operativos móveis e aplicações pode consumir silenciosamente 15–20% da largura de banda disponível. É um alvo prioritário para a filtragem de DNS em implementações de redes públicas.
DNS Sinkholing
Uma técnica na qual um servidor DNS é configurado para retornar um endereço IP falso (normalmente um endereço nulo local) para domínios específicos, redirecionando o tráfego para longe do seu destino pretendido.
Utilizado para neutralizar o tráfego C2 de malware e bloquear agressivamente redes de anúncios de elevada largura de banda. Mais definitivo do que as respostas NXDOMAIN, pois permite que o servidor de sinkhole registe as tentativas de ligação para análise de segurança.
Airtime Fairness
Uma funcionalidade de rede sem fios que aloca acesso igual ao meio sem fios a todos os clientes ligados, independentemente das suas taxas de dados individuais.
Crítico em ambientes de alta densidade. Sem o airtime fairness, um único dispositivo lento (ex.: um cliente 802.11g mais antigo) pode consumir desproporcionalmente o tempo de antena, degradando o rendimento de todos os outros clientes. O tráfego de telemetria em segundo plano de muitos dispositivos agrava este efeito.
Phantom Load
Largura de banda consumida por processos automatizados em segundo plano nos dispositivos ligados antes que ocorra qualquer atividade deliberada do utilizador.
O termo coletivo para telemetria, pré-carregamento de redes de anúncios e tráfego de atualização de SO. Compreender e quantificar o phantom load é o primeiro passo em qualquer diagnóstico de congestionamento de WiFi de convidados.
Exemplos Práticos
Um resort de 400 quartos está a registar uma forte congestão de rede todas as noites, entre as 19:00 e as 22:00. A ligação WAN de 1 Gbps fica saturada e os hóspedes queixam-se de streaming lento e de chamadas VoIP que caem. O Diretor de TI precisa de identificar a causa raiz e implementar uma solução sem atualizar o circuito.
Passo 1 — Análise de Tráfego: Implementar um analisador de fluxo de rede (NetFlow/IPFIX) no router principal e executá-lo durante 5 dias, abrangendo períodos de pico e fora de pico. Correlacionar com os registos de consultas DNS do resolvedor existente. A análise revela que 35% do tráfego noturno se destina a redes de anúncios de vídeo programáticos conhecidas (DoubleClick, AppNexus) e a servidores de atualização automática de aplicações (Apple Software Update, Google Play). A navegação legítima dos hóspedes representa apenas 52% do tráfego total.
Passo 2 — Implementação de Filtragem DNS: Configurar a firewall principal para redirecionar todas as consultas DNS da VLAN de hóspedes (porta UDP/TCP 53) para um resolvedor local com RPZ ativado. Importar uma lista de bloqueio selecionada que cubra as redes de anúncios e os domínios de telemetria identificados. Executar em modo apenas de registo (log-only) durante 48 horas para validar as taxas de falsos positivos.
Passo 3 — Aplicação de Políticas: Após validar uma taxa de falsos positivos inferior a 0,3%, mudar para o modo de aplicação. Em simultâneo, implementar uma política de QoS que limite a largura de banda dos servidores de atualização da Apple e da Google a um teto combinado de 80 Mbps durante a janela das 18:00 às 23:00.
Passo 4 — Validação: Monitorizar a utilização da WAN nos 7 dias seguintes. A utilização de pico desce de 98% para 61%, resolvendo as reclamações dos hóspedes. O hotel adia uma atualização de circuito planeada por um período estimado de 18 meses.
Um grande centro de conferências está a acolher uma cimeira tecnológica com 5.000 participantes. Durante a apresentação principal, a rede WiFi fica completamente inutilizável. A análise pós-incidente mostra que milhares de dispositivos tentaram descarregar simultaneamente uma grande atualização do iOS que tinha sido lançada nessa manhã.
Mitigação Imediata (Dia do Evento): A equipa de operações de rede identifica o pico através da monitorização de consultas DNS em tempo real. Bloqueiam imediatamente (sinkhole) os domínios específicos de atualização de software da Apple (mesu.apple.com, appldnld.apple.com, updates.cdn-apple.com) ao nível do DNS. Em 4 minutos, a utilização da WAN desce de 99% para 68% e a rede estabiliza.
Correção a Curto Prazo (Mesmo Evento): É aplicada uma política de QoS para limitar todo o tráfego de atualização restante a 50 Mbps durante o resto do evento.
Estratégia a Longo Prazo (Pós-Evento): A equipa de rede implementa uma política de QoS dinâmica que se ativa automaticamente quando a utilização total da WAN excede 75%, limitando os servidores de atualização conhecidos a 10% da capacidade total. É criada uma lista de verificação pré-evento que inclui o bloqueio temporário (sinkhole) dos principais domínios de atualização durante as 2 horas anteriores e posteriores a sessões de grande visibilidade. A equipa também subscreve os canais de notificação de lançamentos de atualizações da Apple e da Microsoft para antecipar futuros picos de tráfego.
Perguntas de Prática
Q1. É o Gestor de TI de uma cadeia de retalho nacional. Após implementar uma solução de filtragem de DNS em 50 lojas, vários gerentes de loja relatam que a página de login do Captive Portal não carrega para os convidados. A equipa de suporte está a receber um elevado volume de chamadas. Qual é a causa mais provável e qual é o passo de resolução imediata?
Dica: Considere a cadeia de dependência completa de um fluxo de autenticação de Captive Portal moderno, incluindo os mecanismos de deteção de Captive Portal ao nível do SO.
Ver resposta modelo
A causa mais provável é o bloqueio excessivo. O filtro de DNS está a bloquear um domínio necessário para o funcionamento do Captive Portal. Os sistemas operativos móveis modernos utilizam domínios específicos para detetar Captive Portals (ex.: captive.apple.com para iOS, connectivitycheck.gstatic.com para Android). Se estes estiverem bloqueados, o SO não irá acionar o browser do Captive Portal e o convidado não verá qualquer aviso de login. Adicionalmente, o próprio portal pode depender de uma CDN ou de um fornecedor de autenticação de terceiros (ex.: login social via Facebook ou Google) cujos domínios estão inadvertidamente bloqueados.
Resolução imediata: Reveja os registos de consultas DNS para respostas NXDOMAIN com origem na sub-rede de convidados durante a fase de autenticação. Identifique todos os domínios bloqueados que são consultados antes de um login bem-sucedido. Adicione estes domínios à lista de permissões global. Implemente um modelo padrão de lista de permissões para implementações de Captive Portal que inclua todos os principais endpoints de deteção de SO e domínios comuns de fornecedores de autenticação.
Q2. Um arquiteto de rede de um estádio nota que, apesar de implementar uma filtragem de DNS agressiva, a utilização da WAN permanece criticamente elevada durante os jogos. Uma investigação mais aprofundada revela um volume elevado e sustentado de tráfego na porta UDP 443 que não se correlaciona com quaisquer domínios bloqueados nos registos de DNS. O que está a acontecer e como deve ser abordado?
Dica: Considere os protocolos de transporte modernos e a forma como interagem com os controlos ao nível do DNS.
Ver resposta modelo
O elevado volume de tráfego na porta UDP 443 indica a utilização de QUIC (HTTP/3). O QUIC é um protocolo de transporte baseado em UDP utilizado pelas principais plataformas (Google, Meta, YouTube) que contorna os proxies tradicionais baseados em TCP e os motores DPI. Mais criticamente, os clientes que utilizam QUIC também podem estar a utilizar DNS over HTTPS (DoH) para resolver domínios, contornando completamente o resolvedor RPZ local e tornando a filtragem de DNS ineficaz para esses clientes.
Para resolver isto: Primeiro, implemente regras de firewall para bloquear o tráfego DoH de saída para fornecedores públicos de DoH conhecidos (Google, Cloudflare, NextDNS) na porta TCP/UDP 443 por IP de destino, forçando os clientes a recorrer ao resolvedor local. Segundo, avalie o bloqueio total do tráfego de saída na porta UDP 443 (ou limite-o agressivamente) para forçar os clientes QUIC a recorrer ao HTTP/2 baseado em TCP, que está sujeito às políticas de gestão de tráfego existentes. Terceiro, analise se um proxy DoH transparente pode ser implementado para intercetar e inspecionar consultas DoH enquanto aplica as políticas RPZ locais.
Q3. Está a desenhar uma política de QoS para a rede WiFi de convidados de um grande hospital público. A rede é partilhada entre dispositivos de entretenimento de doentes, dispositivos pessoais de visitantes e um pequeno número de profissionais de saúde que utilizam softphones VoIP nos seus telemóveis pessoais. Priorize os seguintes tipos de tráfego: VoIP (SIP/RTP), Navegação Web de Convidados (HTTP/HTTPS), Atualizações de Windows/iOS e Streaming de Vídeo (Netflix/YouTube).
Dica: Considere tanto a sensibilidade à latência como o impacto comercial/clínico de cada tipo de tráfego. Considere também o contexto regulamentar de um ambiente de saúde.
Ver resposta modelo
Prioridade 1 — VoIP (SIP/RTP): Strict Priority Queuing (Expedited Forwarding, DSCP EF). O VoIP é altamente sensível à latência (meta < 150ms unidirecional) e ao jitter (meta < 30ms). A perda de pacotes acima de 1% causa degradação audível. Num contexto clínico, uma chamada interrompida pode ter implicações na segurança do doente.
Prioridade 2 — Navegação Web de Convidados (HTTP/HTTPS): Assured Forwarding (AF31). Este é o principal caso de utilização previsto tanto para doentes como para visitantes. Requer uma capacidade de resposta razoável, mas é tolerante a uma latência moderada.
Prioridade 3 — Streaming de Vídeo (Netflix/YouTube): Limitado por cliente (ex.: limite de 3–5 Mbps) com Assured Forwarding (AF21). Embora seja importante para a experiência do doente durante estadias longas, o streaming sem limites irá saturar a ligação. Um limite por cliente garante um acesso equitativo. Considere políticas de horário que flexibilizem os limites fora das horas de ponta.
Prioridade 4 — Atualizações de OS/Aplicações (Scavenger Class, DSCP CS1): Prioridade mais baixa, best-effort queuing, com um limite de taxa agregado (ex.: 50 Mbps no total para todo o tráfego de atualização). Estas são tarefas em segundo plano sem sensibilidade à latência. Devem apenas consumir capacidade disponível. Num ambiente de saúde, considere também se a rede de convidados está totalmente isolada dos sistemas clínicos — caso contrário, a gestão do tráfego de atualização torna-se uma preocupação de segurança, bem como de largura de banda.
Continue a ler esta série
Resolução de Problemas de Redirecionamento de Captive Portal: Como Resolver Falhas de Ligação de WiFi de Convidados
Quando os convidados se ligam ao seu WiFi mas não conseguem aceder à internet, a causa é quase sempre um captive portal mal configurado - e não uma falha de hardware. Este guia fornece uma referência técnica aprofundada para gestores de TI, arquitetos de rede e CTOs para diagnosticar e resolver toda a cadeia de falhas: desde sondas de conectividade ao nível do SO e conflitos de certificados HSTS até falhas de autorização RADIUS e exaustão de DHCP. Mapeia cada modo de falha para uma correção concreta e mostra como a plataforma de cloud agnóstica de hardware da Purple elimina estes problemas em implementações Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme e Fortinet.
Resolução de Problemas em WiFi Público: Como Corrigir 'Ligado, Sem Internet' e Falhas de Redirecionamento da Página Splash
Este guia de referência técnica autorizado explica o funcionamento subjacente da deteção de Captive Portal e detalha os seis principais modos de falha que impedem o WiFi de convidados de se ligar. Fornece aos gestores de TI e arquitetos de rede uma metodologia prática de resolução de problemas para resolver falhas de redirecionamento HTTP, conflitos de DNS e desafios de randomização de MAC.
As 10 Principais Causas de DHCP Timeouts em Redes Sem Fios de Alta Densidade
Este guia de referência técnica autoritário identifica as dez principais causas de DHCP timeouts em redes sem fios de alta densidade e fornece estratégias de remediação acionáveis e neutras em relação ao fabricante. Concebido para líderes seniores de TI, arquitetos de rede e diretores de operações de espaços, abrange princípios de engenharia aprofundados, fluxos de trabalho de implementação passo a passo e resultados de negócio mensuráveis. Saiba como eliminar estrangulamentos de ligação e otimizar a sua infraestrutura sem fios para fornecer uma conectividade contínua em ambientes empresariais exigentes.