Top 10 Ursachen für DHCP-Timeouts in High-Density Wireless Networks
Dieser maßgebliche technische Leitfaden identifiziert die zehn Hauptursachen für DHCP-Timeouts in High-Density Wireless Networks und bietet praxisnahe, herstellerneutrale Lösungsstrategien. Entwickelt für IT-Leiter, Netzwerkarchitekten und Betriebsleiter von Veranstaltungsorten, deckt er tiefgehende technische Prinzipien, schrittweise Implementierungs-Workflows und messbare Geschäftsergebnisse ab. Erfahren Sie, wie Sie Verbindungsengpässe beseitigen und Ihre Wireless-Infrastruktur optimieren, um eine nahtlose Konnektivität in anspruchsvollen Enterprise-Umgebungen zu gewährleisten.
Diesen Leitfaden anhören
Podcast-Transkript ansehen
Management Summary
In modernen Unternehmensumgebungen – wie hochfrequentierten Hotels, Einkaufszentren, Verkehrsknotenpunkten und Stadien – ist die drahtlose Konnektivität der Eckpfeiler des geschäftlichen Erfolgs. Doch das Kundenerlebnis scheitert oft schon beim allerersten Schritt des Netzwerkbeitritts: dem Bezug einer IP-Adresse. In High-Density-WLAN-Netzwerken sind DHCP-Timeouts (Dynamic Host Configuration Protocol) eine der häufigsten, aber am seltensten korrekt diagnostizierten Ursachen für Verbindungsfehler. Wenn Hunderte oder Tausende von Geräten gleichzeitig versuchen, eine Verbindung herzustellen, brechen herkömmliche DHCP-Konfigurationen unter dieser extremen Last zusammen. Dies führt dazu, dass Benutzer vor einem unendlich ladenden Bildschirm festsitzen oder nur eine selbst zugewiesene Link-Local-Adresse im Bereich 169.254.x.x erhalten.
Dieser maßgebliche technische Leitfaden untersucht die zehn häufigsten Ursachen für DHCP-Timeouts in High-Density-WLAN-Netzwerken. Er verzichtet auf akademische Theorie und bietet Netzwerkarchitekten, CTOs und Betriebsleitern direkt umsetzbare Optimierungsstrategien. Durch die systematische Optimierung der DHCP-Pool-Größen, die Verkürzung der Lease-Zeiten, die Implementierung robuster Layer-2/3-Konfigurationen und den Einsatz hochverfügbarer Serverarchitekturen können Unternehmen Verbindungslatenzen drastisch reduzieren, Barrieren beim Netzwerkbeitritt abbauen und ihren Markenruf schützen. Die Umsetzung dieser Best Practices steht in direktem Zusammenhang mit einer höheren Kundenzufriedenheit, einer intensiveren Nutzung von Kernprodukten wie Guest WiFi und der Gewinnung wertvollerer Daten über WiFi Analytics .
Technische Tiefenanalyse
Um DHCP-Timeouts zu diagnostizieren und zu beheben, müssen Netzwerkingenieure zunächst die genaue Funktionsweise des vierteiligen DHCP-Handshakes (oft als DORA-Prozess bezeichnet: Discover, Offer, Request, Acknowledge) verstehen [1]. In High-Density-Umgebungen reagiert dieser Prozess äußerst empfindlich auf Paketverluste, Latenzen und Ressourcenengpässe.
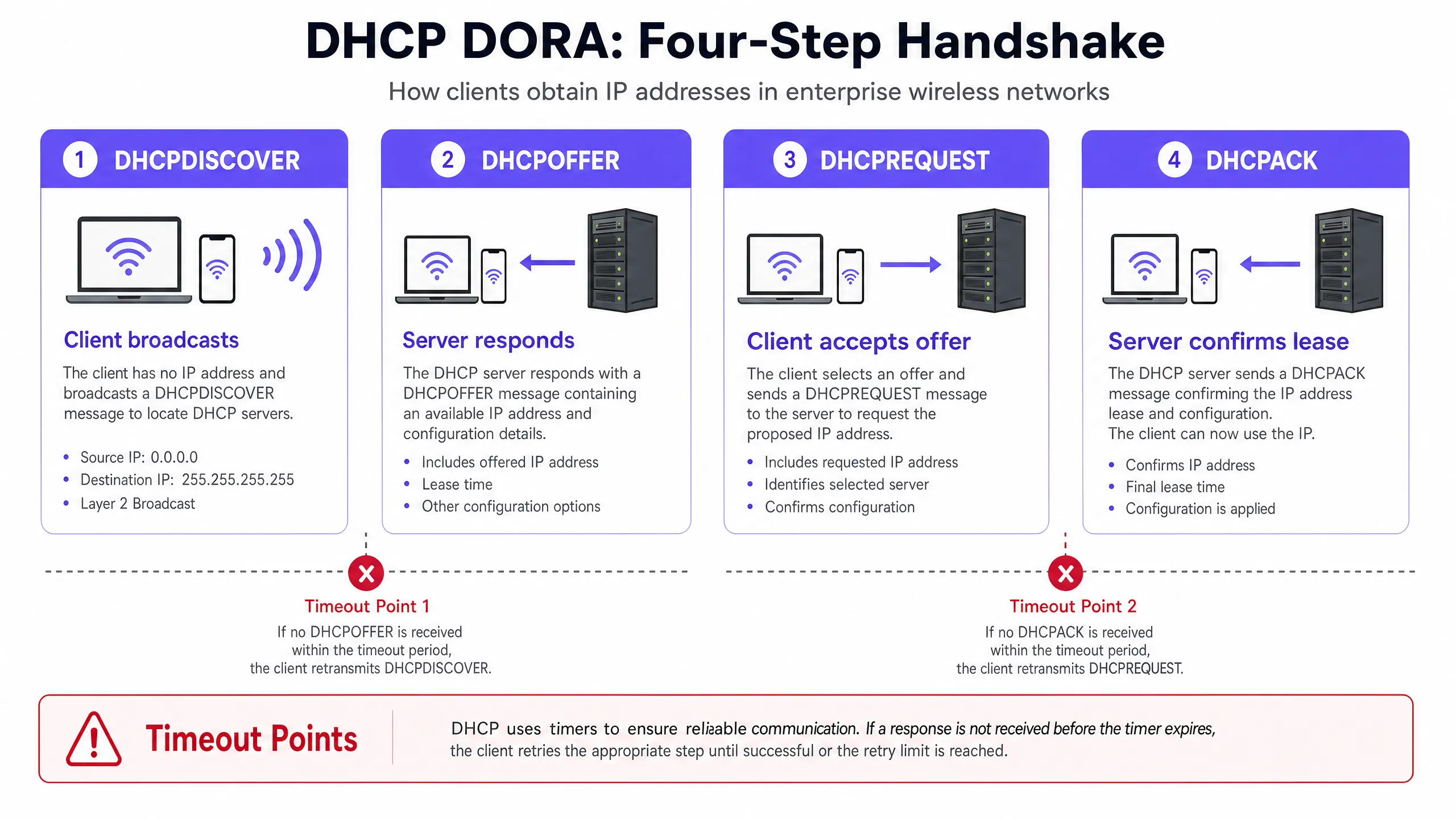
Der DHCP-Handshake (DORA) in High-Density-WLAN-Netzwerken
- DHCPDISCOVER (Broadcast): Der WLAN-Client verbindet sich mit dem Access Point (AP) und sendet ein Broadcast-Paket, um verfügbare DHCP-Server zu finden. In großen Broadcast-Domänen überflutet dieses Paket alle Ports und verbraucht wertvolle WLAN-Airtime.
- DHCPOFFER (Unicast/Broadcast): Jeder aktive DHCP-Server, der die Discover-Nachricht empfängt, reserviert eine IP-Adresse und sendet ein Offer an den Client. Dieses enthält Lease-Parameter, Subnetzmaske, Standard-Gateway und DNS-Server.
- DHCPREQUEST (Broadcast): Der Client wählt eines der Angebote aus (normalerweise das zuerst empfangene) und sendet einen Broadcast-Request, um diese spezifische IP-Adresse zu akzeptieren, wodurch alle anderen Angebote implizit abgelehnt werden.
- DHCPACK (Unicast/Broadcast): Der ausgewählte DHCP-Server trägt den Lease in seine Datenbank ein und sendet eine Bestätigung an den Client, um die IP-Zuweisung und die Lease-Dauer zu bestätigen. Der Client wendet diese Konfiguration anschließend an.
Auswirkungen von WLAN-Overhead und Airtime-Überlastung
Im Gegensatz zu kabelgebundenen Netzwerken, die Layer-2-Broadcasts auf Hardware-Ebene mit Gigabit-Geschwindigkeit verarbeiten, übertragen WLAN-Netzwerke Broadcast- und Multicast-Frames mit der niedrigsten obligatorischen Datenrate (oft 1 Mbps, 6 Mbps oder 11 Mbps, je nach SSID-Konfiguration), um sicherzustellen, dass auch entfernte Clients diese empfangen können [2]. Auf einer High-Density-SSID mit Tausenden aktiven Geräten verbrauchen Broadcast-DHCP-Pakete unverhältnismäßig viel RF-Airtime. Dies führt zu Paketkollisionen, erneuten Übertragungen und letztendlich zu Timeouts. Client-Geräte erwarten in der Regel eine DHCP-Antwort innerhalb von 2 bis 4 Sekunden. Wenn eine Airtime-Überlastung den DORA-Prozess über dieses Zeitfenster hinaus verzögert, bricht der Client die Verbindung ab, trennt sich und versucht es erneut, was eine Kettenreaktion und zusätzliche Last für das Netzwerk auslöst.
Die 10 häufigsten Ursachen für DHCP-Timeouts
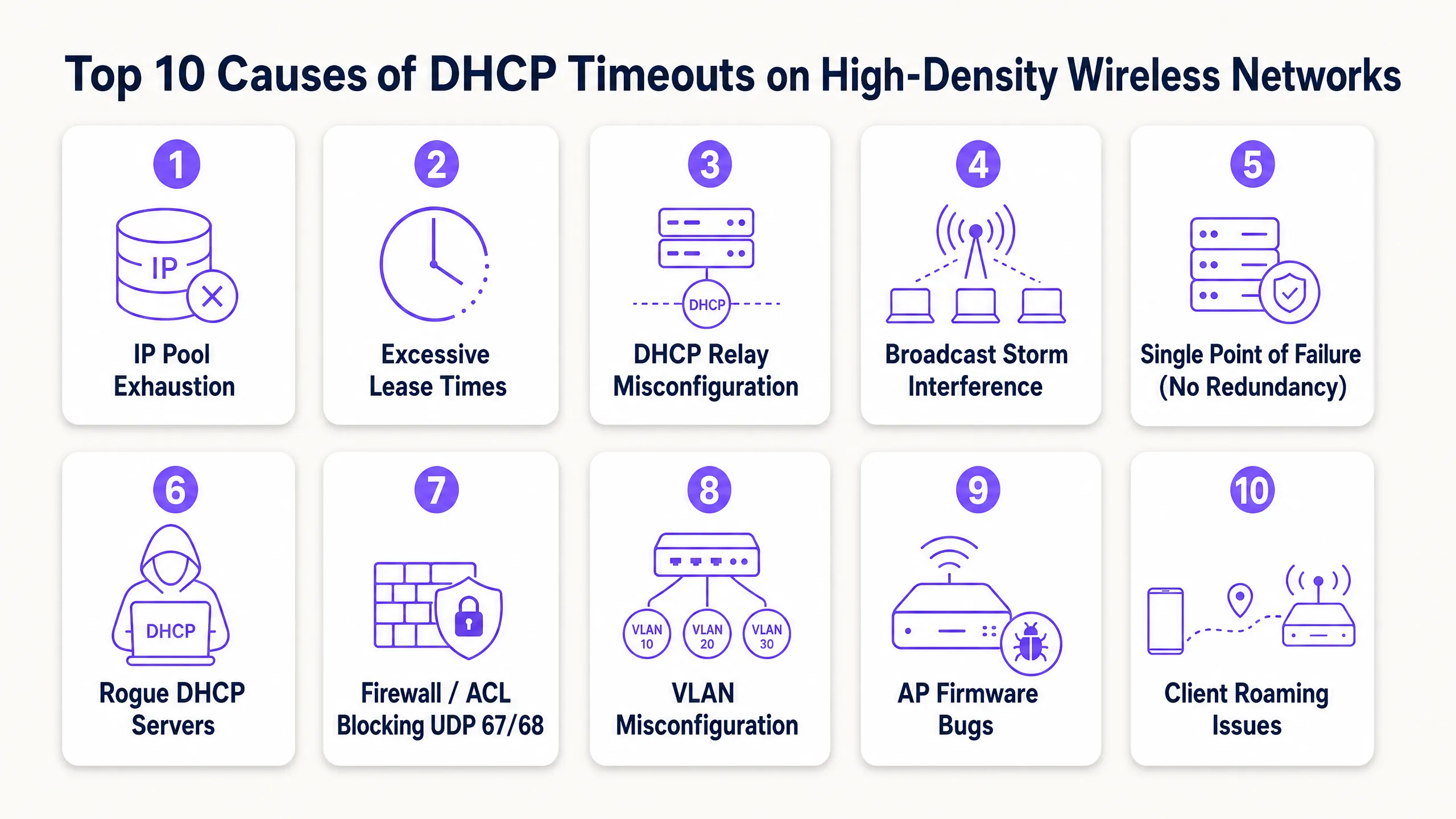
1. Erschöpfung des DHCP-IP-Adresspools
Mechanismus: Der Bereich des DHCP-Servers ist im Verhältnis zur Anzahl der temporären Geräte zu klein. Wenn die Pool-Auslastung 100 % erreicht, ignoriert der Server neue DHCPDISCOVER-Pakete schlichtweg, da er keine Adressen mehr anzubieten hat.
High-Density-Szenario: Ein Standard-Class-C-Subnetz (/24) bietet nur 254 nutzbare IP-Adressen. In einer Hotellobby, an Stadioneingängen oder in Hauptkonferenzsälen kann die Anzahl der gleichzeitig verbundenen Geräte diese Grenze innerhalb weniger Minuten überschreiten. Verschärft wird dies dadurch, dass viele Nutzer mehrere WLAN-fähige Geräte mit sich führen (Smartphones, Smartwatches, Tablets, Laptops), was den IP-Bedarf vervielfacht.
Lösung: Verwenden Sie die klassenlose paketvermittelte Routing-Notation (CIDR), um den Netzwerkbereich anzupassen. Konvertieren Sie High-Density-Client-VLANs in ein /22 (1.022 IPs) oder /21 (2.046 IPs) Subnetz. Stellen Sie sicher, dass Ihre Monitoring-Tools so konfiguriert sind, dass sie bei einer Pool-Auslastung von 80 % alarmieren, um den Bereich vor Spitzenzeiten proaktiv zu erweitern.
2. Zu lange Lease-Zeiten im Gästenetzwerk
Mechanismus: Die Lease-Zeit bestimmt, wie lange ein Client eine IP-Adresse behalten darf, bevor er sie erneuern oder freigeben muss. Ist die Lease-Zeit zu hoch angesetzt, behält der DHCP-Server die Adresse in seiner Datenbank reserviert, selbst wenn das ursprüngliche Gerät den Standort längst verlassen hat, wodurch sie für neue Clients blockiert ist.
High-Density-Szenario: Viele Standard-DHCP-Konfigurationen nutzen eine Lease-Zeit von 24 Stunden oder sogar 8 Tagen. An öffentlichen Orten oder in der Hotellerie mit hoher Fluktuation (z. B. an Bahnhöfen oder in Einkaufszentren) verbleiben Besucher meist nicht länger als zwei Stunden [3]. Bei einer Lease-Zeit von 24 Stunden blockiert ein Besucher, der nur 10 Minuten online war, eine IP-Adresse für einen ganzen Tag. Dies führt zu einer künstlichen Pool-Erschöpfung.
Abhilfe: Passen Sie die Lease-Zeiten an die durchschnittliche Verweildauer der Clients an. Implementieren Sie für Gästenetzwerke kurze Lease-Zeiten von 30 bis 60 Minuten. Für interne Mitarbeiternetzwerke, in denen Geräte während einer gesamten Schicht verbunden bleiben, nutzen Sie Lease-Zeiten von 8 bis 12 Stunden. Dies stellt eine schnelle Wiederverwendung von IP-Adressen abgemeldeter Clients sicher.
3. Fehlkonfigurierte DHCP-Relay-Agents
Funktionsweise: Da DHCP-Discovery-Nachrichten Layer-2-Broadcasts sind, können sie Router-Grenzen (Layer 3) nicht überschreiten. Ein DHCP-Relay-Agent (normalerweise auf Layer-3-Switches oder Security Gateways mit Cisco-ähnlichen Befehlen wie ip helper-address konfiguriert) muss diese Broadcasts abfangen und als Unicast-Pakete an den zentralen DHCP-Server weiterleiten [4]. Wenn der Relay-Agent falsch konfiguriert ist, die Helper-IP fehlerhaft ist oder der Agent in einem neu erstellten VLAN fehlt, wird der DHCP-Verkehr blockiert.
Hintergrund in High-Density-Umgebungen: High-Density-Netzwerke hängen stark von der VLAN-Segmentierung ab, um Broadcast-Domänen einzuschränken. Bei der Bereitstellung einer neuen SSID oder der Erweiterung eines Standorts erstellen Techniker häufig neue Client-VLANs. Wenn die Relay-Agent-Konfigurationen auf den entsprechenden Layer-3-Schnittstellen nicht aktualisiert werden, kommt es bei Clients in diesen VLANs sofort zu DHCP-Timeouts.
Abhilfemaßnahmen: Erstellen Sie strikte Konfigurationsvorlagen für alle Layer-3-Switches. Stellen Sie sicher, dass jede Client-VLAN-Schnittstelle über ein redundantes Paar von DHCP-Helper-Adressen verfügt, die auf Ihre primären und sekundären DHCP-Server verweisen. Überprüfen Sie das End-to-End-Routing zwischen der IP-Adresse der Relay-Schnittstelle (die der DHCP-Server verwendet, um den zuzuweisenden Subnetzbereich zu bestimmen) und dem DHCP-Server selbst.
4. Broadcast- und Multicast-Storms
Funktionsweise: Übermäßiger Broadcast- oder Multicast-Verkehr in einem VLAN kann das drahtlose Medium sättigen. Da WiFi ein gemeinsam genutztes Halbduplex-Medium ist, müssen APs und Clients warten, bis der Kanal frei ist, bevor sie senden. Broadcast-Storms (oft verursacht durch Switching-Schleifen, fehlerhafte Netzwerkkarten oder aggressive Peer-to-Peer-Protokolle) belegen die Sendezeit, was dazu führt, dass DHCP-Pakete in die Warteschlange gestellt, verzögert oder verworfen werden.
Hintergrund in High-Density-Umgebungen: In großen, flachen drahtlosen Netzwerken ohne ordnungsgemäße Layer-2-Isolierung wird Peer-to-Peer-Broadcast-Verkehr (wie Apple AirPlay, Google Chromecast oder Windows-Netzwerkkommunikation) von jedem AP im VLAN repliziert. In einem Veranstaltungsort mit 10.000 Benutzern kann dieses Hintergrundrauschen über 50 % der verfügbaren Funkbandbreite verbrauchen, sodass wichtige DHCP-Handshake-Pakete nicht mehr genügend Sendezeit für die Übertragung haben.
Abhilfemaßnahmen: Aktivieren Sie die Client-Isolierung (auch bekannt als Peer-to-Peer-Blockierung) auf den Wireless-Controllern, um die direkte Kommunikation zwischen Clients zu verhindern. Konfigurieren Sie die Broadcast- und Multicast-Unterdrückung auf APs und Switches, um den Broadcast-Verkehr auf einen kleinen Bruchteil der Verbindungskapazität zu begrenzen (z. B. 100 Pakete pro Sekunde). Aktivieren Sie, sofern unterstützt, DHCP-Proxy auf den APs, um Broadcast-DHCP-Offers und -Acknowledgements in Unicast-Frames umzuwandeln, die speziell an den anfordernden Client gerichtet sind.
5. Single Point of Failure (Fehlende DHCP-Redundanz)
Mechanismus: Ein einzelner, nicht redundanter DHCP-Server stellt eine kritische Schwachstelle dar. Wenn dieser Server ausfällt, ein Systemupdate durchführt oder die Netzwerkkonnektivität verliert, wird die Fähigkeit neuer Benutzer, dem Netzwerk beizutreten, sofort unterbrochen. Bestehende Leases bleiben zwar aktiv, neue Clients können jedoch keine IP-Adresse abrufen, und roamingfähige Clients können ihre Leases nicht erneuern.
High-Density-Szenario: High-Density-Standorte arbeiten unter strengen Betriebs-SLA. In Stadien während eines Spiels oder in Konferenzzentren während einer Keynote ist selbst eine fünfminütige DHCP-Ausfallzeit inakzeptabel. Die Abhängigkeit von einem einzelnen Router oder einer einzelnen virtuellen Maschine zur Verarbeitung von Tausenden von schnellen Lease-Anfragen ist eine hochriskante Architektur.
Lösung: Stellen Sie DHCP in einer hochverfügbaren Konfiguration bereit. Verwenden Sie Windows Server DHCP Failover im Lastverteilungsmodus (50/50-Aufteilung) oder Hot-Standby-Modus, oder implementieren Sie redundante DHCP-Appliances der Enterprise-Klasse (wie Infoblox oder BlueCat) [5]. Stellen Sie sicher, dass Ihre DHCP-Server physisch oder logisch auf verschiedene Hypervisoren und Netzwerkpfade verteilt sind, um Common-Mode-Ausfälle zu eliminieren.
6. Rogue-DHCP-Server
Mechanismus: Ein Rogue-DHCP-Server ist ein unbefugtes, DHCP-fähiges Gerät, das an das Netzwerk angeschlossen ist. Er fängt DHCPDISCOVER-Broadcasts von Clients ab und antwortet mit eigenen DHCPOFFER-Paketen, die häufig falsche IP-Konfigurationen, ein falsches Standard-Gateway oder bösartige DNS-Server enthalten.
High-Density-Szenario: In großen Veranstaltungsorten, Einzelhandelsgeschäften oder Büros des öffentlichen Sektors sind physische Ethernet-Ports oft in öffentlichen Bereichen zugänglich, oder Benutzer bringen nicht autorisierte Geräte (wie Consumer-Reiserouter oder virtuelle Maschinen mit Bridge-Netzwerk) mit und schließen sie an Wandsteckdosen an. Dies führt zu IP-Adressen-Konflikten, Routing-Blackholes und schwerwiegenden Sicherheitsrisiken (einschließlich Man-in-the-Middle-Angriffen).
Lösung: Aktivieren Sie DHCP Snooping auf allen Access- und Distribution-Switches [6]. DHCP Snooping klassifiziert Switch-Ports als „trusted“ (mit legitimen DHCP-Servern oder Relay-Agents verbunden) oder „untrusted“ (mit Clients verbunden). Der Switch verwirft automatisch alle DHCP-Server-Antworten (wie DHCPOFFER oder DHCPACK) von nicht vertrauenswürdigen Ports, wodurch Rogue-Server sofort unschädlich gemacht werden.
7. Firewalls, ACLs und Sicherheitsrichtlinien, die UDP 67/68 blockieren
Mechanismus: DHCP basiert auf UDP-Port 67 (serverseitiges Listening und Client-Ziel) und UDP-Port 68 (clientseitiges Listening und Server-Ziel). Wenn Netzwerk-Firewalls, Access Control Lists (ACLs) auf Switches oder Endpunktsicherheitsrichtlinien diese Ports blockieren, schlägt der DORA-Handshake-Prozess fehl.
Hintergrund in High-Density-Umgebungen: Die Sicherheitsabsicherung hat in Unternehmensnetzwerken höchste Priorität. Zu aggressive Sicherheitsrichtlinien blockieren jedoch oft unbeabsichtigt den DHCP-Verkehr. Beispielsweise können Administratoren während einer Firewall-Migration oder Richtlinienaktualisierung den gesamten UDP-Verkehr in einem Segment blockieren, ohne zu merken, dass sie damit den DHCP-Pfad unterbrochen haben. Ebenso müssen Sicherheitsrichtlinien für Gast-VLANs UDP 67 und 68 explizit zulassen, bevor der Datenverkehr an das Captive Portal umgeleitet wird.
Abhilfemaßnahmen: Überprüfen Sie alle ACLs und Firewall-Regeln auf dem Pfad zwischen drahtlosen Clients, APs, Layer-3-Switches und dem DHCP-Server. Stellen Sie sicher, dass die UDP-Ports 67 und 68 in beiden Richtungen explizit zugelassen sind. Führen Sie bei der Fehlerbehebung Paketaufzeichnungen an der Netzwerkschnittstelle des DHCP-Servers durch, um zu bestätigen, dass die DHCPDISCOVER-Pakete tatsächlich ankommen.
8. VLAN- und Trunking-Fehlkonfigurationen
Funktionsweise: Wenn die SSID eines Clients einem bestimmten VLAN zugeordnet ist, dieses VLAN jedoch in der gesamten Switch-Infrastruktur nicht ordnungsgemäß getaggt oder über Trunks weitergeleitet wird, erreichen die DHCP-Broadcasts des Clients niemals das Standard-Gateway oder den DHCP-Relay-Agenten.
Hintergrund in High-Density-Umgebungen: High-Density-WiFi-Netzwerke nutzen dynamische VLAN-Zuweisung oder Multi-VLAN-Pools, um die Client-Last zu verteilen. Wenn ein einzelner Switch-Trunk-Port auf dem Pfad vom AP zum Core-Switch ein VLAN-Tag in seiner Erlaubnisliste vermissen lässt, tritt bei einer Teilmenge von Clients (speziell denjenigen, die diesem VLAN zugewiesen sind) sofort und dauerhaft ein DHCP-Timeout auf, während andere Clients auf derselben SSID erfolgreich eine Verbindung herstellen können. Dies führt zu extrem unregelmäßigen, schwer zu diagnostizierenden Fehlerszenarien.
Abhilfemaßnahmen: Führen Sie automatisierte Tools für das Konfigurationsmanagement und die Netzwerkvalidierung ein. Verwenden Sie bei der Konfiguration von Switch-Trunk-Ports immer explizite Erlaubnislisten (z. B. switchport trunk allowed vlan 10,20,30), anstatt sich auf die Standardeinstellung „all“ zu verlassen, und stellen Sie sicher, dass das native VLAN auf beiden Seiten der Trunk-Verbindung übereinstimmt, um das Durchsickern von ungetaggtem Verkehr zu verhindern.
9. Access Point-Firmware- und Treiberfehler
Funktionsweise: Die Access Point-Firmware ist dafür verantwortlich, 802.11 Wireless-Frames auf das kabelgebundene 802.3-Ethernet zu brücken. Softwarefehler (Bugs) im AP-Wireless-Treiber oder in der Bridging-Engine können dazu führen, dass der AP DHCP-Pakete verwirft, insbesondere unter hoher CPU- oder Speicherauslastung.
Hintergrund bei High-Density-Umgebungen: High-Density-Netzwerke treiben AP-Hardware und -Software an ihre Grenzen. Ein Bug, der bei einer geringen Last von 10 Clients inaktiv bleibt, kann bei der Verarbeitung von 100 parallel aktiven Clients durch den AP katastrophale Ausfälle auslösen. Beispielsweise führte ein bekannter, Anfang 2026 bei bestimmten WiFi 7 APs dokumentierter Bug dazu, dass der AP sporadisch das dritte Paket des Drei-Wege-Handshakes (DHCPREQUEST) verwarf, wodurch der Client sein DHCPACK nie erhielt und den Onboarding-Prozess nicht abschließen konnte.
Fehlerbehebung: Halten Sie eine strenge Lifecycle-Management-Richtlinie für die AP-Firmware ein. Vermeiden Sie es, „brandneue, unzureichend getestete“ Firmware-Versionen direkt in der Produktionsumgebung bereitzustellen. Richten Sie eine Testumgebung ein, die High-Density-Bedingungen simuliert, und verfolgen Sie die Versionshinweise der Hersteller sowie Community-Foren genau, um bekannte DHCP-bezogene Bugs zu identifizieren. Wenn Sie bei der Fehlersuche feststellen, dass ein Client ein DHCPDISCOVER-Paket gesendet hat, dieses aber am kabelgebundenen Uplink-Port des APs nie ankam, sollten Sie einen AP-Bridging-Fehler vermuten.
10. Häufiges Client-Roaming und Layer-3-Grenzen
Mechanismus: Wenn sich ein Wireless-Client von einem AP zu einem anderen bewegt (Roaming), muss seine Netzwerksitzung aufrechterhalten werden. Wenn das Roaming eine Layer-3-Grenze überschreitet (wodurch der Client in ein anderes Subnetz verschoben wird), muss der Client eine neue IP-Adresse beziehen. Wenn das Betriebssystem des Clients oder das Wireless-Netzwerk diesen Übergang nicht nahtlos bewältigen kann, versucht der Client, die alte IP-Adresse im neuen Subnetz zu verwenden, was zu Verbindungs-Timeouts und fehlgeschlagenen DHCP-Neuverhandlungen führt.
High-Density-Szenario: High-Density-Bereiche erfordern Hunderte von APs, um eine ausreichende Abdeckung zu gewährleisten. Clients befinden sich in ständiger Bewegung – beispielsweise Hotelgäste, die von den Zimmern zu den Konferenzsälen gehen, oder Kunden in Einkaufszentren, die sich frei bewegen [7]. Wenn die Netzwerkarchitektur verschiedene physische Bereiche des Standorts unterschiedlichen Subnetzen zuordnet, entsteht eine enorme Anzahl von Layer-3-Roaming-Vorgängen, was den DHCP-Server mit häufigen Freigabe- (release) und Anforderungsereignissen (request) überlastet.
Fehlerbehebung: Entwerfen Sie High-Density-Wireless-Netzwerke mit einer flachen Layer-2-Architektur für die gesamte Client-SSID oder implementieren Sie Wireless-Controller-basiertes Tunneling (wie GRE oder CAPWAP) [8]. Tunneling stellt sicher, dass der Datenverkehr des Clients immer an seinen ursprünglichen Anchor-Controller und sein ursprüngliches VLAN zurückgebunden wird, unabhängig davon, zu welchem physischen AP er wechselt. Dies eliminiert Layer-3-Roaming-Ereignisse und den damit verbundenen DHCP-Overhead vollständig.
Implementierungshandbuch
Um DHCP-Timeouts systematisch zu eliminieren, müssen Netzwerkarchitekten von der reaktiven Fehlersuche zu einer proaktiven, standardisierten Architektur übergehen. Befolgen Sie diesen schrittweisen Bereitstellungsleitfaden, um Ihre DHCP-Infrastruktur zu härten.
Schritt 1: Subnetzplanung und CIDR-Architektur
Verwenden Sie in High-Density-Gastnetzwerken niemals standardmäßige /24-Subnetze. Berechnen Sie Ihren IP-Bedarf basierend auf der Spitzenkapazität zuzüglich eines Puffers von 50 %, um Benutzer mit mehreren Geräten und temporäre Besucherströme abzufangen.
| Subnetzmaske | CIDR | Verfügbare IP-Adressen | Optimaler Anwendungsfall |
|---|---|---|---|
255.255.255.0 |
/24 |
254 | Verwaltung, Drucker, Backoffice IoT |
255.255.254.0 |
/23 |
510 | Kleine Boutique-Hotels, lokale Einzelhandelsgeschäfte |
255.255.252.0 |
/22 |
1.022 | Große Hotels, High-Density-Konferenzräume, Schulcampus |
255.255.248.0 |
/21 |
2.046 | Große Messehallen, Einkaufszentren, öffentliche Plätze |
255.255.240.0 |
/20 |
4.094 | Stadien, Arenen, große Kongresszentren |
Schritt 2: Optimierung der DHCP-Lease-Time
Konfigurieren Sie Ihren DHCP-Server so, dass er die Lease-Zeiten basierend auf dem Benutzerverhalten im jeweiligen Netzwerksegment anpasst:
Gast-WiFi-SSID (hohe Fluktuation) -> Lease-Time: 30 bis 60 Minuten
Mitarbeiter-SSID (stabil) -> Lease-Time: 8 bis 12 Stunden
Standort-IoT & Infrastruktur -> Lease-Time: 7 Tage (oder statische Reservierung)
Hinweis: Eine Verkürzung der Lease-Time erhöht die Frequenz von DHCP-Erneuerungsanfragen (die bei 50 % der Lease-Time auftreten, bekannt als T1) [9]. Stellen Sie sicher, dass Ihre DHCP-Server-Hardware über ausreichend CPU- und I/O-Leistung verfügt, um die erhöhte Anfragerate zu bewältigen.
Schritt 3: Konfiguration von DHCP Relay Agents auf Layer-3-Switchen
Achten Sie bei der Konfiguration von DHCP Relay Agents darauf, redundante Helper-Adressen anzugeben, die auf unabhängige DHCP-Server verweisen. Unten finden Sie eine herstellerneutrale Standardkonfiguration für ein Cisco iOS Layer-3-Switch-Interface:
interface Vlan30
description High_Density_Guest_WiFi
ip address 192.168.30.1 255.255.252.0
ip helper-address 10.10.10.10 # Primärer DHCP-Server
ip helper-address 10.10.10.11 # Sekundärer DHCP-Server
ip dhcp relay information option # Option 82 für Standortverfolgung einfügen
no shutdown
Schritt 4: Härten der Layer-2-Sicherheit mit DHCP Snooping
Verhindern Sie rogue DHCP-Server und mindern Sie DHCP-Starvation-Angriffe, indem Sie DHCP Snooping in Ihrer gesamten Switch-Infrastruktur aktivieren. Hier ist ein Konfigurationsbeispiel für Edge-Access-Switche:
# DHCP Snooping global aktivieren
ip dhcp snooping
# DHCP Snooping für spezifische Client-VLANs aktivieren
ip dhcp snooping vlan 10,20,30
# Den Uplink-Port zum Core-Switch/DHCP-Server als vertrauenswürdig (TRUSTED) konfigurieren
interface GigabitEthernet1/0/48
description UPLINK_TO_CORE
ip dhcp snooping trust
# Clientseitige Ports als nicht vertrauenswürdig (UNTRUSTED) konfigurieren und die DHCP-Paketrate begrenzen, um Starvation-Angriffe zu verhindern
interface range GigabitEthernet1/0/1 - 47
description CLIENT_ACCESS_PORTS
ip dhcp snooping limit rate 15
Best Practices
Um ein belastbares und leistungsstarkes Wireless-Netzwerk aufrechtzuerhalten, sollten Sie diese branchenüblichen Best Practices in Ihre Betriebsabläufe integrieren:
1. Implementierung von DHCP Option 82 (Relay Agent Information Option)
DHCP-Option 82 ermöglicht es einem Relay-Agenten, spezifische Leitungsinformationen (wie die Switch-Port-ID oder die AP-MAC-Adresse) in eine DHCP-Anfrage einzufügen, bevor er sie an den Server weiterleitet [10]. Dies ermöglicht dem DHCP-Server die Implementierung hochgradig granularer IP-Zuweisungsrichtlinien basierend auf dem physischen Standort des Clients innerhalb des Standorts. Beispielsweise kann ein Hotel Clients im Konferenzzentrum andere IP-Adresspools oder DNS-Einstellungen zuweisen als Clients auf den Zimmern, wodurch die Auslastung des Adresspools optimiert wird.
2. Aktivieren Sie die ARP- und DHCP-Broadcast-zu-Unicast-Konvertierung
Konfigurieren Sie Ihren Wireless-LAN-Controller (WLC) oder Ihre Cloud-verwalteten APs so, dass sie Layer-2-Broadcast-ARP- und DHCP-Pakete abfangen und diese vor der Übertragung über Funk in Unicast-Frames konvertieren. Da Unicast-Frames mit der maximal vom Client unterstützten Datenrate (und nicht mit der minimalen obligatorischen Broadcast-Rate) übertragen werden, reduziert diese einfache Konfigurationsänderung den RF-Airtime-Verbrauch erheblich und verbessert die DHCP-Zuverlässigkeit in Umgebungen mit hoher Dichte.
3. Richten Sie eine proaktive DHCP-Überwachung und -Alarmierung ein
Warten Sie nicht darauf, dass Benutzer Verbindungsfehler melden. Konfigurieren Sie Ihr Netzwerkmanagementsystem (NMS) oder Ihre DHCP-Server-Überwachungstools, um wichtige Kennzahlen zu verfolgen und Echtzeit-Alarme auszulösen:
- Pool-Auslastung: Lösen Sie bei einer Auslastung von 75 % einen Warnalarm und bei 85 % einen kritischen Alarm aus.
- DHCP-Anfragerate: Überwachen Sie plötzliche Spitzen bei den Anfragen, die auf einen Broadcast-Sturm, Roaming-Schleifen oder einen DHCP-Erschöpfungsangriff hinweisen können.
- Verteilung des Lease-Ablaufs: Stellen Sie sicher, dass Leases reibungslos ablaufen und die Datenbank IP-Adressen aktiv zurückfordert.
Fehlerbehebung und Risikominderung
Wenn ein DHCP-Timeout vermutet wird, befolgen Sie diesen systematischen Diagnose-Workflow, um die Fehlerquelle schnell zu isolieren und Betriebsunterbrechungen zu minimieren.
[Client verbindet sich mit AP]
│
▼
[Paketaufzeichnung am Client] ───► Wird DHCPDISCOVER gesendet?
│ ├── Nein: Problem mit Client-Betriebssystem/Treiber.
│ └── Ja
▼
[Paketaufzeichnung am Switch] ───► Kommt DHCPDISCOVER am Switch an?
│ ├── Nein: AP-Bridging-/VLAN-Tagging-Problem.
│ └── Ja
▼
[Paketaufzeichnung am Server] ───► Kommt DHCPDISCOVER am Server an?
│ ├── Nein: Problem mit Relay-Agent / Routing / Firewall.
│ └── Ja
▼
[Server-Logs prüfen] ───────────► Wird DHCPOFFER gesendet?
├── Nein: Pool erschöpft / Bereich nicht aktiv.
└── Ja: Rückweg blockiert (VLAN/Routing).
Wichtige Befehle zur Fehlerbehebung
Verwenden Sie die folgenden Befehle, um den DHCP-Status auf physischen Netzwerkgeräten zu überprüfen und Fehler zu diagnostizieren:
Cisco IOS (DHCP-Server oder Relay)
# DHCP-Pool-Auslastung und verfügbare Adressen anzeigen
show ip dhcp pool
# Aktive IP-Adressbindungen anzeigen
show ip dhcp binding
# DHCP-Serverstatistiken überwachen (Anzahl der Discover, Request, Ack)
show ip dhcp server statistics
# DHCP-Konfliktdatenbank anzeigen (IPs, die aufgrund von Konflikten als beschädigt markiert sind)
show ip dhcp conflict
Linux (DHCP-Server oder Client)
# Echtzeit-DHCP-Client-Lease-Anfragen auf einem Linux-Client anzeigen
sudo dhclient -v wlan0
# DHCP-Traffic auf einer bestimmten Schnittstelle erfassen (UDP-Ports 67 und 68)
sudo tcpdump -i eth0 -n -vv 'udp and (port 67 or port 68)'
# dnsmasq DHCP-Lease-Datenbank prüfen
cat /var/lib/misc/dnsmasq.leases
Windows (DHCP-Client)
# Aktuelle IP-Adresse freigeben
ipconfig /release
# IP-Adresse neu anfordern (neuen DHCP-Handshake initiieren)
ipconfig /renew
ROI und geschäftliche Auswirkungen
Die Investition in eine hochgradig belastbare, gut strukturierte DHCP-Infrastruktur ist nicht nur eine technische Notwendigkeit, sondern ein entscheidender geschäftlicher Faktor, der sich direkt auf die Rentabilität und die betriebliche Effizienz auswirkt.
Quantifizierung des geschäftlichen Nutzens einer nahtlosen Anmeldung
- Verbesserung des Kundenerlebnisses und der Markenloyalität: In der Hotellerie und Veranstaltungsbranche ist die WiFi-Konnektivität ein Haupttreiber für die Kundenzufriedenheit. Kunden, die auf Hindernisse beim Online-Zugang stoßen, hinterlassen mit hoher Wahrscheinlichkeit negative Bewertungen, was sich direkt auf die Buchungsraten auswirkt. Die Eliminierung von DHCP-Timeouts sorgt für einen reibungslosen ersten Eindruck.
- Maximierung des ROI von Gäste-WiFi-Marketing: Für Einzelhandels- und Unterhaltungsstandorte ist Guest WiFi ein leistungsstarker Marketingkanal. Durch die Gewährleistung einer 100%igen Erfolgsquote bei der Anmeldung können Marketingteams über WiFi Analytics mehr First-Party-Daten (wie E-Mails, demografische Daten und Besuchermuster) sammeln, was hochgradig personalisierte Interaktionskampagnen ermöglicht und den Customer Lifetime Value steigert.
- Reduzierung der IT-Support-Kosten: DHCP-bezogene Tickets („Verbindung zum WiFi nicht möglich“, „falsche IP-Adresse“) gehören zu den häufigsten und zeitaufwendigsten Anfragen an IT-Helpdesks. Durch die Implementierung von DHCP-Redundanz, die Anpassung der Pool-Größe und die Bereitstellung von DHCP Snooping können Unternehmen bis zu 40 % der WiFi-bezogenen Support-Tickets einsparen, sodass sich das IT-Personal auf strategische Initiativen statt auf grundlegende Fehlerbehebung konzentrieren kann.
- Sicherstellung von Compliance und Sicherheit: Die Implementierung von DHCP Snooping und der Schutz vor Rogue-DHCP-Servern unterstützen direkt die Einhaltung wichtiger Sicherheitsstandards wie PCI DSS (für Zahlungsumgebungen im Einzelhandel) und DSGVO (durch den Schutz von Kundendaten-Netzwerken). Eine sichere und gut dokumentierte DHCP-Architektur minimiert das Risiko kostspieliger Datenpannen und aufsichtsrechtlicher Strafen.
Tabelle zur Zusammenfassung der geschäftlichen Auswirkungen
| Kennzahl | Vor der Optimierung | Nach der Optimierung | Geschäftliche Auswirkung |
|---|---|---|---|
| DHCP-Timeout-Rate | 8,5 % (zu Spitzenzeiten) | < 0,1 % | Nahtloses Benutzererlebnis bei der Anmeldung, Eliminierung von Verbindungsbeschwerden |
| Mittlere Reparaturzeit (MTTR) | 45 Minuten | < 5 Minuten | Schnelle Fehlerbehebung durch gut dokumentierte VLAN/Bereichs-Zuordnung |
| WiFi-Zustimmungsrate für Marketing | 62% | 88% | Beschleunigt das Wachstum der Marketingdatenbank und sammelt umfassendere Daten |
| Anzahl der IT-Support-Tickets | Hoch (DHCP/IP-Fehler) | Minimal | Reduziert Service-Desk-Tickets im Zusammenhang mit Wireless-Netzwerken um 40 % |
Referenzen
- IETF RFC 2131 - Dynamic Host Configuration Protocol
- IEEE 802.11-2020 - Wireless LAN Medium Access Control and Physical Layer Specifications
- Optimieren der WiFi DHCP-Lease-Zeit für Mobilgeräte
- IETF RFC 3046 - DHCP Relay Agent Information Option
- IETF RFC 8156 - DHCPv4 Failover Protocol
- Cisco Systems - Konfigurieren von DHCP Snooping
- Warum Stadion-WiFi ins Stocken gerät (und wie man es behebt)
- HPE Aruba Networking - Wi-Fi Design and Deployment Guide for Large Public Venues
- Fehlerbehebung bei DHCP-Problemen in WiFi-Netzwerken
- IETF RFC 3993 - Subscriber-ID Suboption für die DHCP Relay Agent Information Option
Schlüsseldefinitionen
DHCP (Dynamic Host Configuration Protocol)
Ein Netzwerkverwaltungsprotokoll für Internet-Protokoll-Netzwerke (IP), bei dem ein DHCP-Server jedem Gerät in einem Netzwerk dynamisch eine IP-Adresse und andere Netzwerkkonfigurationsparameter zuweist, damit diese mit anderen IP-Netzwerken kommunizieren können.
DHCP ist der entscheidende erste Schritt beim Wireless-Onboarding; schlägt er fehl, können Clients auf keine Netzwerkressourcen zugreifen, einschließlich der Captive Portals.
DORA-Prozess
Die standardmäßige vierstufige Abfolge von Nachrichten, die zwischen einem DHCP-Client und einem DHCP-Server ausgetauscht werden, um das Leasing einer IP-Adresse auszuhandeln: DHCPDISCOVER, DHCPOFFER, DHCPREQUEST und DHCPACK.
Das Verständnis der DORA-Sequenz ist unerlässlich, um bei der Netzwerk-Fehlerbehebung zu diagnostizieren, an welcher Stelle ein DHCP-Handshake fehlschlägt.
DHCP-Relay-Agent
Jeder Host oder jedes Netzwerkgerät (typischerweise ein Layer-3-Switch oder Router), der DHCP-Pakete zwischen Clients und Servern weiterleitet, wenn sich diese in verschiedenen Subnetzen oder VLANs befinden.
Relay-Agenten sind in segmentierten Enterprise-Netzwerken erforderlich, um DHCP-Dienste zu zentralisieren und zu verhindern, dass Broadcast-Traffic Router-Grenzen überschreitet.
DHCP-Snooping
Eine in Managed Switches integrierte Layer-2-Sicherheitsfunktion, die nicht vertrauenswürdige DHCP-Nachrichten filtert und eine Bindungsdatenbank mit vertrauenswürdigen MAC-zu-IP-Zuordnungen aufbaut.
DHCP-Snooping ist der primäre Schutz gegen Rogue DHCP-Server und Man-in-the-Middle-Angriffe in Enterprise-Drahtlosnetzwerken.
Erschöpfung des IP-Pools
Ein Zustand, der eintritt, wenn alle verfügbaren IP-Adressen innerhalb des konfigurierten Bereichs eines DHCP-Servers verleast wurden, sodass für neue Clients keine Adressen mehr zur Verfügung stehen.
Die Erschöpfung des IP-Pools ist die Hauptursache für DHCP-Timeouts an Standorten mit hoher Benutzerdichte und wird durch eine angemessene Dimensionierung der Scopes oder eine Verkürzung der Lease-Zeiten behoben.
DHCP-Lease-Zeit
Die Zeitspanne, für die ein DHCP-Server einem bestimmten Client-Gerät eine IP-Adresse zuweist, bevor der Client eine Lease-Verlängerung anfordern muss.
Die Optimierung der Lease-Zeiten basierend auf dem Benutzerverhalten (kurz für Gastnetzwerke, länger für Mitarbeiter) ist entscheidend für die Effizienz des IP-Pools.
Rogue DHCP-Server
Ein unautorisierter DHCP-Server, der an ein Netzwerk angeschlossen ist und ungültige oder böswillige IP-Konfigurationen an Clients verteilt, was zu Verbindungsproblemen und Sicherheitsrisiken führt.
Rogue-Server kommen häufig an offenen, öffentlichen Standorten vor und werden durch die Aktivierung von DHCP-Snooping auf Access-Switches neutralisiert.
Broadcast-Unterdrückung
Eine Netzwerkkonfigurationstechnik, die die Rate von Broadcast- und Multicast-Traffic auf einem VLAN oder Switch-Port begrenzt, um Netzwerküberlastungen und Broadcast-Storms zu verhindern.
Die Broadcast-Unterdrückung ist in Drahtlosnetzwerken mit hoher Benutzerdichte von entscheidender Bedeutung, um die RF-Sendezeit zu schonen und sicherzustellen, dass wichtige DHCP-Pakete nicht verzögert werden.
Ausgearbeitete Beispiele
Ein hochfrequentiertes Konferenzzentrum mit einem Hauptplenarsaal für 2.500 Teilnehmer verzeichnet während der Eröffnungs-Keynote massive Fehler beim WiFi-Onboarding. Teilnehmer berichten, dass ihre Geräte minutenlang bei „IP-Adresse wird abgerufen“ hängen bleiben, und diejenigen, die eine Verbindung herstellen können, werden beim Wechsel zwischen dem Plenarsaal und dem Ausstellungsbereich häufig getrennt. Die aktuelle Netzwerkkonfiguration verwendet ein einzelnes Client-VLAN, das einem Standard-`/24`-Subnetz mit einer 24-stündigen DHCP-Lease-Time zugeordnet ist und von einem einzelnen Core-Router bedient wird. Wie sollte dieses Netzwerk neu strukturiert werden, um diese Fehler zu beheben?
Um diese Onboarding-Fehler zu beheben, muss die Netzwerkarchitektur neu konzipiert werden, um das transiente Client-Verhalten bei hoher Dichte zu bewältigen. Befolgen Sie diesen mehrstufigen Behebungs-Workflow:
Erweiterung des IP-Adressraums (Subnetz-Dimensionierung): Ersetzen Sie das Standard-
/24-Subnetz (das nur 254 IP-Adressen bietet) durch ein/21-Subnetz (das 2.046 nutzbare IP-Adressen bietet) oder implementieren Sie einen Multi-VLAN-Pool. Dies stellt sicher, dass der IP-Pool ausreichend dimensioniert ist, um 2.500 gleichzeitige Teilnehmer zu bedienen, von denen viele mehrere verbundene Geräte mit sich führen (Durchschnitt von 1,5 Geräten pro Teilnehmer = 3.750 erforderliche IPs). Wenn ein einzelnes flaches/20-Subnetz (4.094 IPs) verwendet wird, kann die gesamte Event-Kapazität problemlos abgedeckt werden.DHCP-Lease-Times optimieren: Verkürzen Sie die DHCP-Lease-Time im Guest-WiFi-Netzwerk von 24 Stunden auf 45 Minuten. Da Konferenzteilnehmer sehr mobil sind und sich ständig in den Plenarsaal hinein- und herausbewegen, stellt eine kurze Lease-Time sicher, dass IP-Adressen von Geräten, die den Bereich verlassen haben, schnell wieder freigegeben werden, was eine künstliche Erschöpfung des Adresspools verhindert.
Redundante DHCP-Server bereitstellen: Beseitigen Sie den Single Point of Failure, indem Sie ein redundantes DHCP-Server-Paar bereitstellen. Konfigurieren Sie das Windows Server DHCP Failover im Lastausgleichsmodus (50/50 Split) über zwei unabhängige virtuelle Maschinen oder verwenden Sie eine dedizierte hochverfügbare DHCP-Appliance. Dies stellt sicher, dass bei Ausfall eines Servers oder Netzwerkpfads der verbleibende Server die gesamte Anfragelast bewältigen kann.
Layer 2 Broadcast-Unterdrückung und DHCP Proxy implementieren: Aktivieren Sie die Broadcast-Unterdrückung auf dem Wireless-Controller, um den Broadcast-Traffic auf 100 Pakete pro Sekunde zu begrenzen. Aktivieren Sie DHCP Proxy auf den Access Points, um Broadcast-
DHCPOFFER- und-DHCPACK`-Nachrichten in Unicast-Frames umzuwandeln. Dies reduziert den Airtime-Verbrauch im WiFi drastisch und verhindert Paketkollisionen.DHCP Snooping und ARP-Validierung konfigurieren: Aktivieren Sie DHCP Snooping auf allen Access-Switches, um das Netzwerk vor Rogue-DHCP-Servern zu schützen und DHCP-Starvation-Angriffe zu verhindern. Begrenzen Sie die DHCP-Paketrate an clientseitigen Ports auf 15 Pakete pro Sekunde.
Ein Luxushotel mit 500 Zimmern stellt eine neue Gäste-SSID auf dem gesamten Gelände bereit. Das Netzwerkteam hat ein neues Gäste-VLAN (VLAN 50) erstellt und einen zentralen Windows DHCP-Server mit einem entsprechenden `/22`-Bereich konfiguriert. Bei Tests schlagen jedoch Verbindungsversuche von Geräten fehl, die mit der Gäste-SSID in den Hotelzimmern verbunden sind (sie erhalten keine IP-Adresse und laufen in ein Timeout), während Geräte, die direkt an die kabelgebundenen Ports in den Verwaltungsbüros (VLAN 10) angeschlossen sind, sofort IP-Adressen erhalten. Was ist die wahrscheinlichste Ursache für dieses Problem und wie sollte es diagnostiziert und behoben werden?
Die Tatsache, dass kabelgebundene Clients in VLAN 10 IP-Adressen erhalten, während bei Wireless-Clients in VLAN 50 Timeouts auftreten, deutet darauf hin, dass das Problem spezifisch für den Pfad oder die Konfiguration von VLAN 50 ist. Die wahrscheinlichste Ursache ist ein fehlender oder falsch konfigurierter DHCP Relay Agent (IP Helper) auf dem Layer-3-Switch-Interface für VLAN 50 oder ein fehlendes VLAN-Tag auf dem Trunk-Pfad zwischen den Access Points und dem Core-Switch. Befolgen Sie diesen Diagnose- und Behebungs-Workflow:
Konfiguration des DHCP Relay Agents überprüfen: Melden Sie sich am Core-Layer-3-Switch (oder Gateway) an und überprüfen Sie die Konfiguration für das VLAN 50-Interface. Stellen Sie sicher, dass der Befehl
ip helper-addressvorhanden ist und auf die korrekte IP-Adresse des Windows DHCP-Servers verweist. Wenn der Befehl fehlt, leitet der Switch die Broadcast-DHCPDISCOVER-Pakete des Clients nicht an den DHCP-Server weiter.VLAN-Trunking End-to-End prüfen: Stellen Sie sicher, dass VLAN 50 auf allen Switch-Ports entlang des Pfads von den APs zum Core-Switch getaggt ist. Verwenden Sie Befehle wie
show interfaces trunkauf Cisco-Switches, um zu bestätigen, dass VLAN 50 auf allen Trunk-Verbindungen zulässig und aktiv ist. Wenn VLAN 50 auch nur an einem einzigen Trunk-Port fehlt, werden die DHCP-Broadcasts der Clients verworfen, bevor sie den Layer-3-Switch erreichen.Paketerfassung durchführen: Um die Fehlerstelle zu isolieren, führen Sie gleichzeitige Paketerfassungen an drei Standorten durch:
- Auf dem Wireless-Client (mit Wireshark oder nativen OS-Tools), um zu bestätigen, dass
DHCPDISCOVER-Broadcasts gesendet werden. - Auf dem Layer-3-Switch-Interface für VLAN 50, um zu bestätigen, dass der Switch die Broadcasts empfängt.
- Auf der Netzwerkschnittstelle des DHCP-Servers, um zu bestätigen, dass die weitergeleiteten Unicast-DHCP-Pakete ankommen.
- Auf dem Wireless-Client (mit Wireshark oder nativen OS-Tools), um zu bestätigen, dass
Aktivierung des DHCP-Serverbereichs überprüfen: Stellen Sie sicher, dass der DHCP-Bereich für das VLAN 50-Subnetz (z. B. 192.168.50.0/22) vollständig erstellt, aktiviert ist und über einen aktiven Bereich von IP-Adressen verfügt, der sich nicht mit statischen Zuweisungen überschneidet.
Konfigurationsfehler beheben: Wenden Sie auf dem Core-Layer-3-Switch die korrekte IP-Helper-Konfiguration an:
interface Vlan50 description Guest_WiFi_VLAN ip address 192.168.50.1 255.255.252.0 ip helper-address 10.10.10.10 # Windows DHCP Server IP no shutdown
In einem großen Einkaufszentrum mit über 150 Einzelhandelsgeschäften kommt es zu sehr unregelmäßigen Verbindungsabbrüchen beim WiFi. Das IT-Team berichtet, dass sich einige Besucher sofort verbinden und problemlos surfen können, während andere am selben Ort bei "IP-Adresse wird abgerufen" hängen bleiben oder eine Warnung "Keine Internetverbindung" erhalten. Eine Überprüfung der DHCP-Server-Protokolle zeigt Tausende von aktiven Leases, aber auch eine hohe Anzahl von "DHCP-Konflikt"-Fehlern und mehrere Fälle, in denen der Server Clients mit einem `DHCPNAK` (Negative Acknowledgement) antwortet. Wie sollte dieses Problem untersucht und gelöst werden?
Das Vorhandensein von "DHCP-Konflikt"-Fehlern und DHCPNAK-Antworten in den Server-Protokollen deutet stark auf einen Rogue-DHCP-Server im Netzwerk oder einen IP-Adressenkonflikt hin, der durch statische Zuweisungen innerhalb des DHCP-Bereichs verursacht wird. Folgen Sie diesem systematischen Untersuchungs- und Behebungs-Workflow:
Den Rogue-DHCP-Server isolieren und erkennen: Verwenden Sie die DHCP-Snooping-Datenbankprotokolle auf Ihren Access-Switches, um unautorisierte DHCP-Serveraktivitäten zu identifizieren. Führen Sie den folgenden Befehl auf Ihren Core- und Access-Switches aus, um erkannte Konflikte oder nicht vertrauenswürdige DHCP-Pakete anzuzeigen:
show ip dhcp snooping database show ip dhcp conflictDie Konfliktdatenbank listet die MAC-Adressen der Geräte auf, die auf ARP-Probes für IPs geantwortet haben, die der DHCP-Server zuzuweisen versuchte, oder Geräte, die aktiv unautorisierte Leases verteilen.
DHCP-Snooping global und auf Client-VLANs aktivieren: Um alle Rogue-DHCP-Server sofort zu neutralisieren, aktivieren Sie DHCP-Snooping auf allen Switches. Konfigurieren Sie alle clientseitigen Ports als nicht vertrauenswürdig (untrusted) und vertrauen Sie nur den spezifischen Ports, die mit Ihren legitimen DHCP-Servern oder Core-Trunk-Verbindungen verbunden sind. Dies stellt sicher, dass alle unautorisierten
DHCPOFFER- oderDHCPACK-Pakete am Switch-Port verworfen werden, bevor sie andere Clients erreichen können.ARP-Inspektion (DAI) konfigurieren: Um zu verhindern, dass Clients gefälschte IP-Adressen verwenden oder IP-Konflikte verursachen, aktivieren Sie Dynamic ARP Inspection (DAI) auf den Client-VLANs. DAI verwendet die DHCP-Snooping-Binding-Datenbank, um ARP-Pakete zu validieren, und verwirft alle Pakete mit ungültigen MAC-zu-IP-Zuordnungen:
ip arp inspection vlan 10,20,30Statische IPs aus dem DHCP-Pool ausschließen: Stellen Sie sicher, dass alle statischen IP-Adressen, die Infrastrukturgeräten (wie Druckern, APs oder Digital Signage) zugewiesen sind, explizit aus dem DHCP-Bereich auf dem Server ausgeschlossen werden, um zu verhindern, dass der Server diese IPs versehentlich an Clients anbietet.
Port-Security und 802.1X bereitstellen: Implementieren Sie für kabelgebundene Ports in Einzelhandelsgeschäften oder öffentlichen Bereichen Port-Security, um die Anzahl der an einem Port zulässigen MAC-Adressen zu begrenzen, oder stellen Sie eine 802.1X-Authentifizierung bereit, um zu verhindern, dass sich unbefugte Geräte mit der physischen Netzwerkstruktur verbinden.
Übungsfragen
Q1. Ein IT-Manager in einem großen Einkaufszentrum stellt fest, dass während der Hauptverkehrszeiten im Weihnachtsgeschäft die Gast-WiFi-Verbindungen häufig fehlschlagen. Das DHCP-Serverprotokoll ist mit der Fehlermeldung "DHCP Scope Full" überlastet. Das aktuelle Gast-VLAN ist mit einer `/23`-Subnetzmaske und einer standardmäßigen Lease-Zeit von 24 Stunden konfiguriert. Welche zwei unmittelbarsten und effektivsten Konfigurationsänderungen sollte der Manager implementieren, um dieses Problem zu lösen, und warum?
Hinweis: Berücksichtigen Sie die Beziehung zwischen Subnetzgröße, Verweildauer der Clients und der Freigabe von IP-Adressen.
Musterlösung anzeigen
Der Manager sollte die folgenden zwei sofortigen Konfigurationsänderungen implementieren:
DHCP-Lease-Time verkürzen: Reduzieren Sie die Lease-Time von 24 Stunden auf 30 oder 45 Minuten. Da Besucher von Einkaufszentren sehr transient sind (typische Verweildauer beträgt 1-2 Stunden), führt eine 24-stündige Lease-Time dazu, dass der DHCP-Server IP-Adressen noch lange nach der Abreise der Gäste blockiert. Die Reduzierung der Lease-Time stellt sicher, dass IP-Adressen schnell wieder freigegeben und für neue Käufer verfügbar gemacht werden, wodurch die Kapazität des vorhandenen Pools effektiv vervielfacht wird, ohne dass die Subnetzstruktur geändert werden muss.
Subnetzbereich erweitern (CIDR-Sizing): Erweitern Sie das Gäste-VLAN-Subnetz von einem
/23(bietet 510 nutzbare IP-Adressen) auf ein/21(bietet 2.046 nutzbare IP-Adressen) oder ein/20(bietet 4.094 nutzbare IP-Adressen). Ein/23-Subnetz ist für ein großes Einkaufszentrum während der Stoßzeiten viel zu klein, insbesondere wenn man bedenkt, dass viele Besucher mehrere verbundene Geräte (Telefone, Wearables, Tablets) bei sich tragen. Die Erweiterung des Bereichs stellt sicher, dass genügend IP-Adressen zur Verfügung stehen, um die Spitzenlast der gleichzeitigen Geräte zu bewältigen.
Diese beiden Änderungen greifen ineinander: Die Subnetzerweiterung erhöht die absolute Poolkapazität, während die Reduzierung der Lease-Time maximale Effizienz bei der Wiederverwendung von Adressen gewährleistet, wodurch Fehler vom Typ "DHCP Scope Full" vollständig vermieden werden.
Q2. Ein Netzwerkingenieur führt eine Fehlerbehebung bei einer neu bereitgestellten Gäste-SSID in einem Hotel durch. Drahtlose Clients verbinden sich erfolgreich mit dem AP, erhalten jedoch keine IP-Adresse und brechen nach einigen Sekunden mit einem Timeout ab. Eine Paketerfassung am Switch-Port, der mit dem AP verbunden ist, zeigt, dass `DHCPDISCOVER`-Broadcasts in den Switch eingehen, eine Erfassung an der Netzwerkschnittstelle des zentralen DHCP-Servers zeigt jedoch keine eingehenden Pakete aus dem Gäste-Subnetz des Hotels. Der DHCP-Server befindet sich in einem anderen Subnetz (10.10.10.0/24) als die drahtlosen Gäste-Clients (192.168.50.0/22). Welche Konfiguration fehlt, auf welchem Gerät muss sie angewendet werden und wie lautet der genaue Befehl dafür?
Hinweis: Da sich der DHCP-Server in einem anderen Subnetz als die Clients befindet, muss ein Layer-3-Gerät den Broadcast-Traffic weiterleiten.
Musterlösung anzeigen
Die fehlende Konfiguration ist der DHCP-Relay-Agent (IP-Helper). Da es sich bei DHCP-Discovery-Nachrichten um Layer-2-Broadcasts handelt, können sie die Router- oder Layer-3-Grenze zwischen dem Client-Gäste-Subnetz (192.168.50.0/22) und dem DHCP-Server-Subnetz (10.10.10.0/24) nicht überschreiten. Ohne einen Relay-Agenten verwirft der Switch oder Router die Broadcast-Pakete, sodass sie den Server nicht erreichen.
Diese Konfiguration muss auf dem Layer-3-Switch oder Security Gateway angewendet werden, der als Standard-Gateway für das Gäste-WLAN-VLAN (VLAN 50) fungiert.
Unter der Annahme eines Cisco IOS Layer-3-Switches muss der Ingenieur den Befehl ip helper-address auf der VLAN 50-Schnittstelle anwenden und auf die IP-Adresse des zentralen DHCP-Servers verweisen (z. B. 10.10.10.10):
interface Vlan50
description Guest_WiFi_Gateway
ip address 192.168.50.1 255.255.252.0
ip helper-address 10.10.10.10
no shutdown
Dieser Befehl weist den Switch an, DHCP-Broadcasts auf VLAN 50 abzufangen, sie in Layer-3-Unicast-Pakete mit einer Quell-IP des VLAN 50-Gateways (192.168.50.1) umzuwandeln und sie direkt an den DHCP-Server unter 10.10.10.10 weiterzuleiten. Der Server verwendet dann die Gateway-IP, um den richtigen Bereich auszuwählen und ein Angebot zurückzusenden.
Q3. Ein Netzwerkarchitekt für ein Stadion entwirft ein drahtloses Netzwerk zur Unterstützung von 50.000 gleichzeitigen Fans. Um den Broadcast-Traffic und den Verbrauch von RF-Sendezeit zu minimieren, möchte der Architekt eine Broadcast-Unterdrückung implementieren und DHCP-Broadcasts in Unicast umwandeln. Einige Nachwuchsingenieure äußern jedoch die Besorgnis, dass die Umwandlung von DHCP-Broadcasts in Unicast das DHCP-Protokoll beschädigen wird, da Clients noch keine IP-Adresse haben, um Unicast-Pakete zu empfangen. Wie sollte der Architekt den technischen Mechanismus der Broadcast-zu-Unicast-Konvertierung erklären, um diese Bedenken auszuräumen?
Hinweis: Überlegen Sie, wie der Access Point Layer-2-Frames überbrückt und wie die MAC-Adresse des Clients im 802.11-Header verwendet wird.
Musterlösung anzeigen
Der Architekt sollte erklären, dass die Umwandlung von DHCP-Broadcasts in Unicast das DHCP-Protokoll nicht beeinträchtigt, da der Access Point (AP) auf Layer 2 arbeitet und Frames direkt an die physische MAC-Adresse des Clients senden kann, selbst wenn der Client noch keine IP-Adresse besitzt.
Hier ist der technische Mechanismus:
Die MAC-Adresse des Clients ist bekannt: Während der initialen Assoziierungsphase stellt der Client eine sichere Layer-2-Verbindung mit dem AP her. Der AP kennt die eindeutige MAC-Adresse des Clients und ordnet sie einem bestimmten virtuellen Port und einer Funkschnittstelle zu.
Der AP fängt den Broadcast ab: Wenn der DHCP-Server ein
DHCPOFFERoderDHCPACKals Layer-2-Broadcast (Ziel-MACFF:FF:FF:FF:FF:FF) sendet, fängt der AP dieses Paket auf seiner kabelgebundenen Schnittstelle ab.Umwandlung in Unicast: Anstatt das Paket als Broadcast-Frame über die Luft zu übertragen (was alle Clients auf dem Kanal zwingen würde, aufzuwachen und es mit der niedrigsten vorgeschriebenen Datenrate zu verarbeiten), modifiziert der AP den 802.11 MAC-Header. Er ändert die Ziel-MAC-Adresse von der Broadcast-Adresse in die spezifische Unicast-MAC-Adresse des Clients (die er aus dem Hardware-Adressfeld des Clients im DHCP-Paket,
chaddr, extrahiert hat).Hochgeschwindigkeitsübertragung: Da es sich nun um einen Unicast-Frame handelt, kann der AP ihn mit der maximal unterstützten Datenrate des Clients übertragen (unter Nutzung von Beamforming, MIMO und höherwertiger Modulation wie QAM). Zudem profitiert die Übertragung von 802.11 Layer-2-Bestätigungen (ACKs), was eine zuverlässige Zustellung gewährleistet.
Client-Verarbeitung: Die Wireless-Karte des Clients empfängt den Unicast-Frame, erkennt die eigene MAC-Adresse im 802.11-Header und leitet die Payload (das DHCP-Angebot oder -Ack) im Netzwerk-Stack nach oben weiter. Das Betriebssystem des Clients verarbeitet die DHCP-Payload ganz normal, völlig ohne zu wissen, dass der Frame über die Luft von Broadcast in Unicast umgewandelt wurde.
Diese Erklärung zeigt, dass die Broadcast-to-Unicast-Konvertierung eine Layer-2-Optimierung ist, die den 802.11-MAC-Layer nutzt, um die RF-Sendezeit zu schonen, ohne die Layer-3-DHCP-Protokolldaten zu verändern.
Weiterlesen in dieser Reihe
Fehlerbehebung bei öffentlichem WiFi: Behebung von „Verbunden, kein Internet“ und Fehlern bei der Splash-Page-Weiterleitung
Dieser maßgebliche technische Leitfaden erklärt die grundlegenden Mechanismen der Erkennung von Captive Portals und beschreibt detailliert die sechs primären Fehlermodi, die eine Verbindung mit dem Gäste-WiFi verhindern. Er bietet IT-Managern und Netzwerkarchitekten ein praktisches Framework zur Fehlerbehebung bei HTTP-Weiterleitungsproblemen, DNS-Konflikten und Herausforderungen bei der MAC-Randomisierung.
Verwendung von Packet Capture (PCAP) zur Diagnose langsamer WiFi-Leistung
Dieser technische Leitfaden bietet IT-Managern, Netzwerkarchitekten und Leitern des Standortbetriebs eine strukturierte Methodik auf Paketebene zur Diagnose und Behebung langsamer WiFi-Leistung in Unternehmen mithilfe der Packet Capture (PCAP)-Analyse. Durch die Analyse von rohen 802.11-Frames – einschließlich Retransmissionsraten, Airtime-Auslastung und Metadaten der physikalischen Schicht – können Teams Engpässe auf der HF-Schicht präzise von kabelgebundenen oder anwendungsspezifischen Problemen isolieren. Dieser Leitfaden ist für hochfrequentierte Standorte wie Hotels, Einzelhandelsketten, Stadien und Konferenzzentren geeignet und bietet direkt umsetzbare Diagnose-Workflows, Fallstudien aus der Praxis sowie Schritte zur Konfigurationsbehebung, um Netzwerkkapazitäten zurückzugewinnen und das Gästeerlebnis zu sichern.
Fehlerbehebung bei 802.1X-Authentifizierungsfehlern (RADIUS/EAP)
Dieser Leitfaden bietet IT-Managern, Netzwerkarchitekten und Leitern des Standortbetriebs eine umfassende, praxisnahe Referenz zur Diagnose und Behebung von 802.1X-Authentifizierungsfehlern in der RADIUS- und EAP-Infrastruktur. Er deckt die gesamte Authentifizierungskette ab – von der Fehlkonfiguration des Supplicants und dem Ablauf von Zertifikaten bis hin zu nicht übereinstimmenden RADIUS Shared Secrets und Fragmentierung bei der Netzwerkübertragung – ergänzt durch Praxis-Fallbeispiele aus dem Hotel- und Gastgewerbe sowie dem Einzelhandel. Teams, die für PCI-DSS-Compliance, WPA3-Enterprise-Bereitstellungen und standortübergreifende Netzwerkzugriffskontrolle verantwortlich sind, finden hier strukturierte Diagnose-Frameworks, Implementierungs-Checklisten und Strategien zur Risikominderung, die direkt auf ihren Betrieb anwendbar sind.