Mean time to innocence: come dimostrare che non è colpa del WiFi
Il Mean time to innocence (MTTI) è la metrica fondamentale che definisce quanto tempo i team IT dedicano a dimostrare che un problema di rete non è colpa loro. Questa guida illustra una metodologia di osservabilità in cinque passaggi per eliminare il gioco del barile negli ambienti multi-tenant, sostituendo le accuse reciproche con prove condivise per ridurre il tempo medio di risoluzione (MTTR).
Ascolta questa guida
Visualizza trascrizione del podcast
📚 Part of our core series: WiFi multi-tenant: la guida completa →
Executive Summary
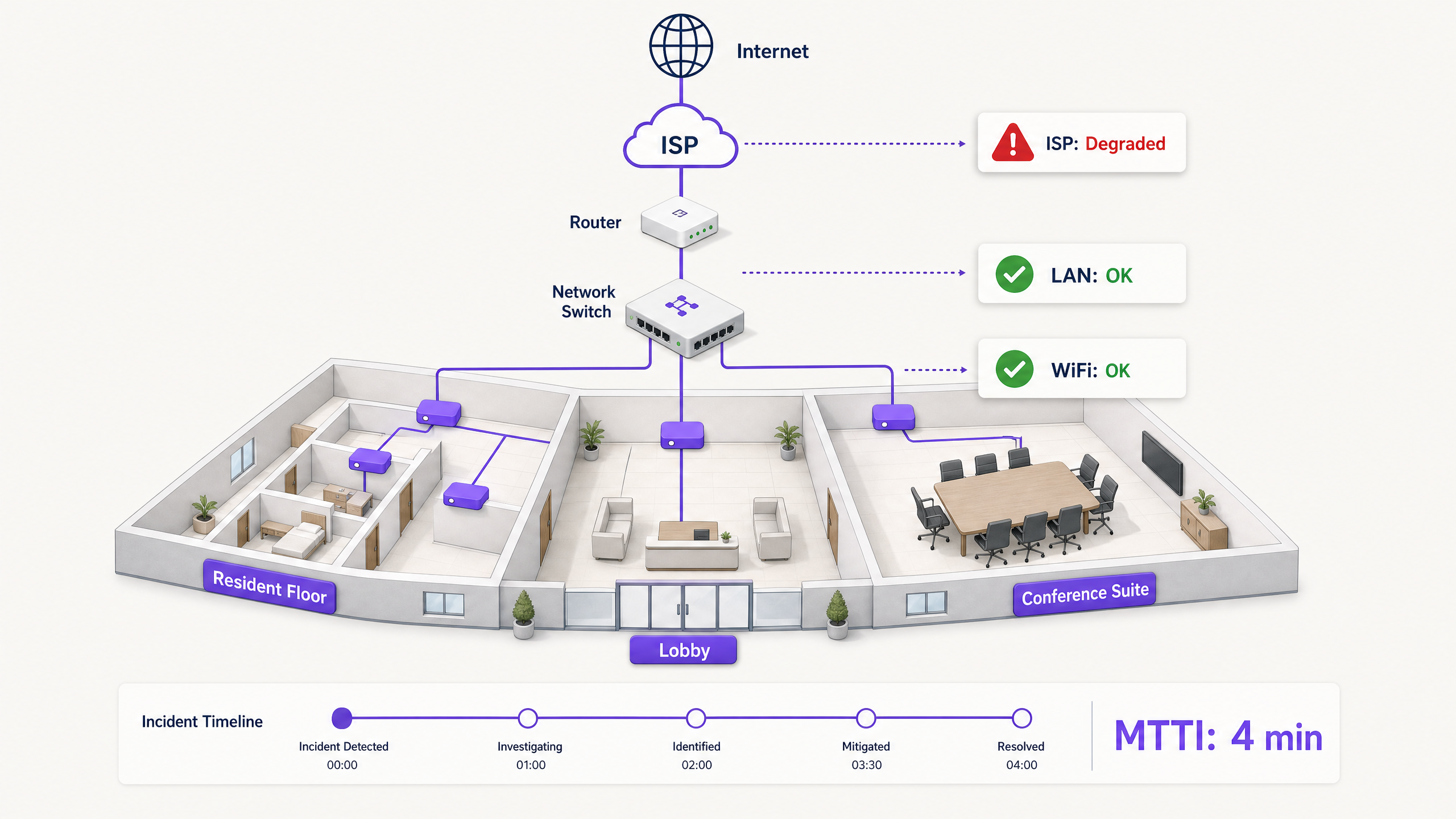
Quando la connettività si interrompe in un ambiente multi-tenant, il Wi-Fi è il primo a essere incolpato. Rappresenta il confine visibile della rete, l'ultimo miglio prima del dispositivo e il bersaglio più facile per gli utenti frustrati. Per i responsabili IT, gli architetti di rete e i direttori operativi delle sedi, ciò si traduce in una costante tassa operativa: il tempo speso a dimostrare la propria innocenza.
Il Mean Time to Innocence (MTTI) misura il tempo medio trascorso tra la segnalazione di un incidente e la capacità di un team di dimostrare che il proprio dominio non è la causa principale. In ambienti complessi come i complessi build-to-rent (BTR), gli hotel o i centri congressi, la rete è frammentata tra gestori immobiliari, provider di Wi-Fi gestito e internet service provider (ISP). Senza una telemetria definitiva, l'MTTI dilata il Mean Time to Resolution (MTTR) a causa delle discussioni dei team sulle responsabilità, anziché concentrarsi sulla risoluzione del guasto.
Questa guida illustra dettagliatamente una metodologia di osservabilità in cinque fasi per ridurre sistematicamente l'MTTI. Distribuendo controlli sintetici continui, visibilità del percorso hop-by-hop, analisi dei dati di flusso, mappatura della topologia e correlazione degli eventi, è possibile sostituire il rimpallo di responsabilità con prove condivise. L'obiettivo non è vincere più rapidamente la caccia al colpevole, ma porvi fine del tutto.
Analisi Tecnica Approfondita: I Meccanismi dell'MTTI
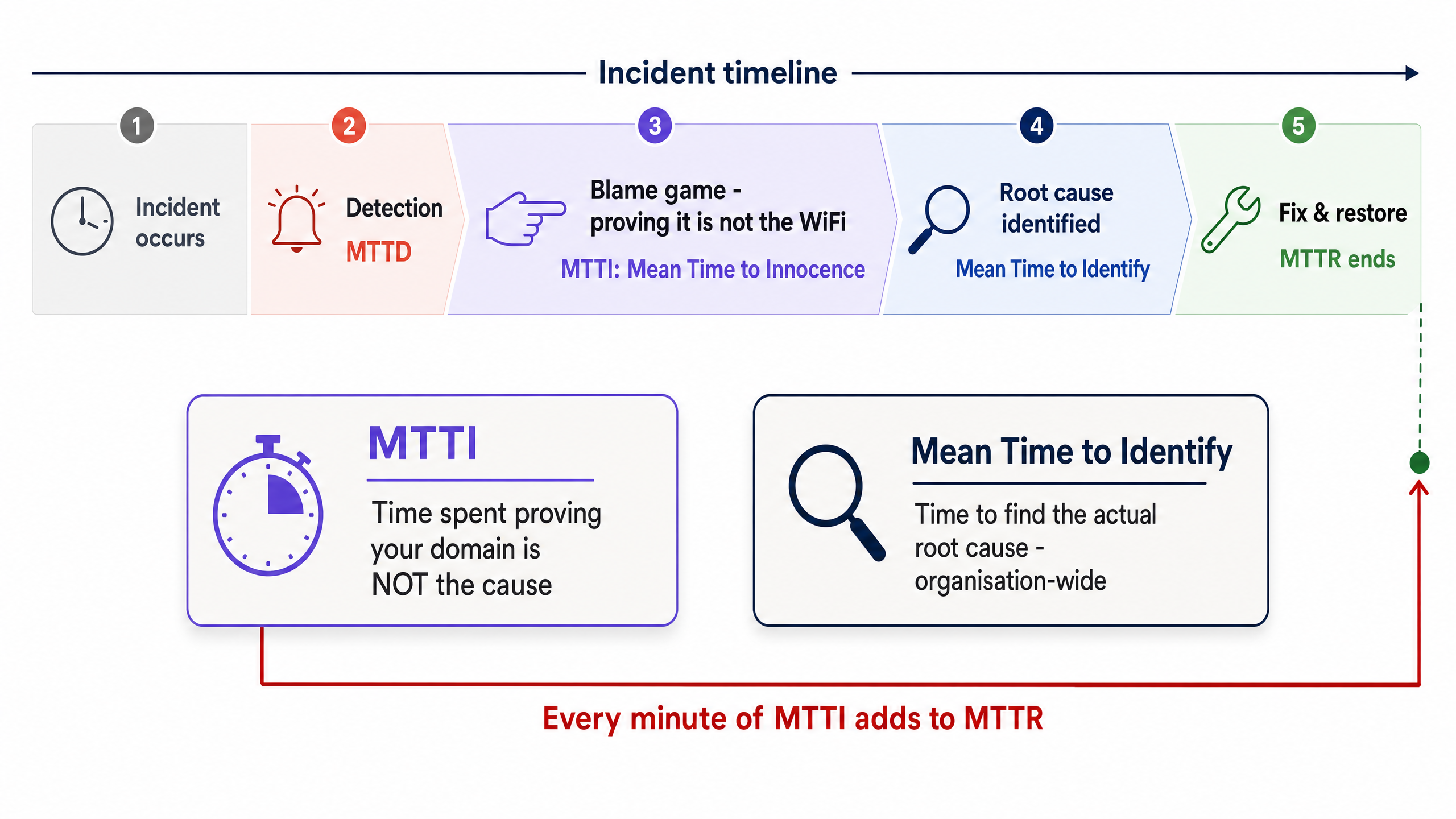
La Differenza tra MTTI e Mean Time to Identify
È fondamentale distinguere l'MTTI dal Mean Time to Identify. Il Mean Time to Identify è una metrica a livello aziendale che tiene traccia del tempo necessario per trovare la reale causa principale di un'interruzione. L'MTTI è una metrica isolata, specifica del dominio, che traccia quanto tempo impiega un singolo team a dimostrare di non essere il colpevole.
Ogni minuto di MTTI si somma direttamente all'MTTR. Se un provider di Wi-Fi gestito impiega 40 minuti a controllare manualmente gli access point (AP) e i log degli switch prima di concludere che il problema risiede nell'ISP, l'MTTR subisce una penalizzazione di 40 minuti ancor prima che inizi la risoluzione effettiva.
Perché il Wi-Fi Viene Sempre Incolpato
In ambienti che servono 350 milioni di utenti unici in oltre 80.000 sedi attive, Purple rileva costantemente lo stesso schema. Il livello Wi-Fi viene incolpato per impostazione predefinita a causa di tre realtà strutturali:
- Pregiudizio di visibilità: l'indicatore del segnale Wi-Fi è l'unico strumento di diagnostica di rete a disposizione dell'utente medio della sede.
- Edge proximity: Come ultimo hop verso il dispositivo client, il WiFi eredita i sintomi di ogni guasto a monte. Un timeout DNS a livello di ISP appare identico a un guasto dell'AP dal punto di vista dell'utente.
- Lacune di telemetria: Storicamente, dimostrare lo stato di salute del wireless richiedeva un intervento manuale. Se non si riesce a mostrare uno stato di salute ottimale per il livello wireless in meno di due minuti, si perde il controllo della situazione.
La complicazione multi-tenant
In un'azienda single-tenant, i team di rete possiedono l'intero stack dall'AP al firewall. Negli ambienti WiFi Multi-Tenant, la proprietà è frazionata.
Un residente BTR paga il gestore della proprietà. Il gestore della proprietà contratta un fornitore di WiFi gestito. Il fornitore di WiFi gestito si affida a un circuito ISP di terze parti e, spesso, alla rete di distribuzione interna del proprietario dell'edificio. Quando un residente non riesce a riprodurre video in streaming, il fornitore deve scagionare rapidamente l'hardware WiFi (Cisco Meraki, HPE Aruba, Ruckus o Juniper Mist) e isolare il guasto sul dispositivo client, sullo switch dell'edificio o sull'ISP. In caso contrario, si danneggia la relazione commerciale tra il fornitore e il gestore della proprietà.
Guida all'implementazione: La metodologia in 5 passaggi
Per ridurre sistematicamente l'MTTI, implementa questa architettura di osservabilità a cinque livelli.
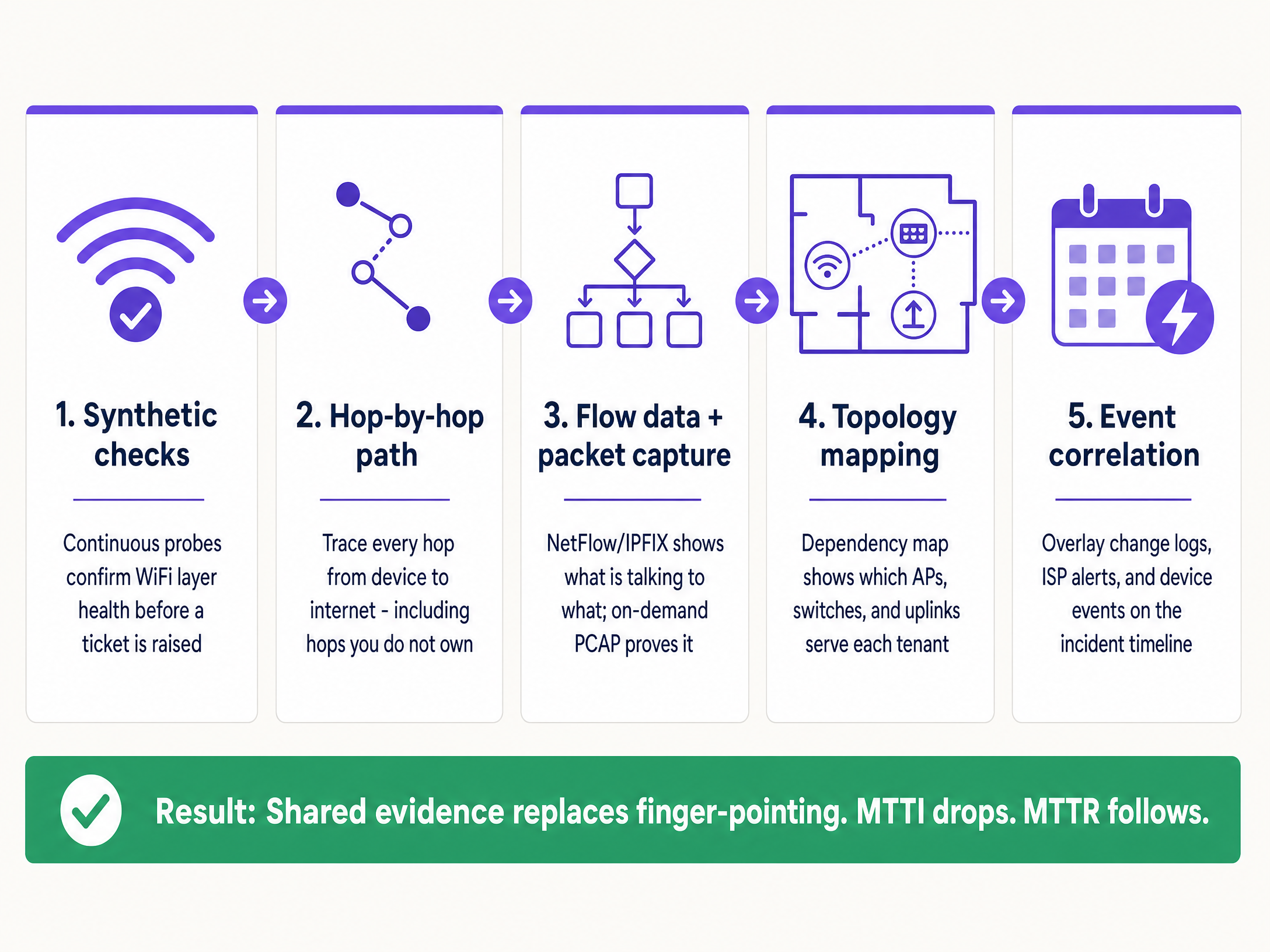
1. Test sintetici continui
Non aspettare che un utente si lamenti. Distribuisci sonde sintetiche automatizzate che emulano continuamente il comportamento degli utenti dall'edge della rete.
- Implementazione: Configura gli AP o i sensori dedicati per eseguire test pianificati per la risposta DHCP, la risoluzione DNS, la raggiungibilità HTTP e i flussi di autenticazione (come l'accesso 802.1X o tramite Captive Portal).
- Risultato: Quando viene aperto un ticket, controlli prima la dashboard sintetica. Se le sonde mostrano una raggiungibilità HTTP pulita nel momento esatto del reclamo, scagioni immediatamente il livello WiFi e il circuito WAN, spostando l'attenzione sul dispositivo client specifico o sull'applicazione di destinazione.
2. Visibilità del percorso Hop-by-Hop
Dimostrare che l'hardware è integro non è sufficiente se non si può provare che il percorso verso Internet è libero.
- Implementazione: Utilizza strumenti di visualizzazione del percorso per tracciare il traffico dal livello di accesso attraverso la LAN, passando per il punto di demarcazione e fino alla rete dell'ISP.
- Risultato: Quando la latenza aumenta, un tracciamento del percorso rivela esattamente quale nodo ha introdotto il ritardo. Se gli hop da uno a quattro (il tuo dominio) mostrano una latenza di 2 ms, e l'hop cinque (il router edge dell'ISP) mostra 150 ms di latenza e il 12% di perdita di pacchetti, hai una prova definitiva da consegnare all'ISP.
3. Dati di flusso e acquisizione pacchetti on-demand
Quando gli utenti segnalano guasti specifici dell'applicazione, è necessaria una visibilità a livello di conversazione.
- Implementazione: Esporta i dati NetFlow o IPFIX dagli switch principali o dai firewall. Assicurati che l'hardware del tuo livello di accesso supporti l'acquisizione di pacchetti (PCAP) remota e on-demand, senza richiedere la presenza di un tecnico in loco.
- Risultato: I dati di flusso dimostrano se il traffico verso un servizio specifico sta lasciando la tua rete in modo pulito. In caso affermativo, la rete è innocente. Se è richiesta una prova forense più approfondita, una PCAP mirata sulla VLAN specifica fornisce prove innegabili di ritrasmissioni TCP o di reset lato server.
4. Mappatura della Topologia e delle Dipendenze
In un ambiente multi-tenant, isolare il raggio d'azione dell'impatto è il modo più rapido per classificare un guasto.
- Implementazione: Mantieni una mappa delle dipendenze dinamica e aggiornata in tempo reale che colleghi ogni AP al relativo switch, uplink e circuito WAN, mappata rispetto alle VLAN dei tenant.
- Risultato: Se un guasto interessa gli AP su più piani ma solo su un singolo switch, il problema è lo switch. Se interessa tutti gli AP ma solo la VLAN di un singolo tenant, si tratta di un problema di configurazione logica. Una rapida definizione dell'ambito previene lo spreco di sforzi nell'analisi di infrastrutture sane.
5. Correlazione degli Eventi
I dati senza contesto prolungano i tempi di indagine.
- Implementazione: Inserisci i log delle modifiche, gli avvisi di manutenzione dell'ISP, gli aggiornamenti del firmware hardware e i ticket degli utenti in un'unica visualizzazione temporale.
- Risultato: Sovrapporre un picco di errori di autenticazione a un evento di scadenza del certificato Microsoft Entra ID verificatosi 10 minuti prima identifica immediatamente la causa radice, bypassando completamente l'hardware di rete.
Best Practice
- Standardizza lo Stack Hardware: Limita le distribuzioni ai vendor enterprise canonici (Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme, Fortinet) che espongono API per test sintetici e PCAP remoti.
- Automatizza le Prove: Configura la tua piattaforma di monitoraggio per allegare automaticamente i risultati dei test sintetici e i tracciamenti dei percorsi ai ticket ITSM nel momento stesso in cui vengono creati.
- Condividi la Dashboard: Fornisci ai property manager l'accesso in sola lettura a una dashboard di integrità di alto livello. La trasparenza previene il gioco delle colpe.
- Monitora il MTTI in Modo Formale: Misura il tempo che intercorre tra la creazione del ticket e il momento in cui il tuo team fornisce la prova di innocenza. Trattalo come un KPI primario insieme al MTTR.
Risoluzione dei Problemi e Mitigazione dei Rischi
- Rischio: Il Loop del 'Nessun Errore Rilevato': Gli utenti segnalano problemi, ma i controlli sintetici mostrano semaforo verde.
- Mitigazione: Il problema è probabilmente specifico del dispositivo o correlato a interferenze RF (interferenza co-canale o ostruzione fisica). Utilizza l'analisi lato client per verificare l'RSSI del dispositivo specifico e la cronologia di roaming.
- Rischio: Rifiuto dell'ISP: L'ISP si rifiuta di accettare il guasto nonostante le tue prove.
- Mitigazione: Fornisci tracciamenti del percorso hop-by-hop che mostrino l'indirizzo IP esatto in cui inizia la perdita di pacchetti. Condividi i PCAP che dimostrano un'uscita pulita dal tuo punto di demarcazione. I dati concreti costringono a un'escalation oltre il supporto di Livello 1.
- Rischio: malfunzionamento del Captive Portal: gli utenti attribuiscono la colpa al WiFi quando il portale non si carica.
- Mitigazione: isolare l'identity provider. Verificare lo stato dell'integrazione (Microsoft Entra ID, Okta, Google Workspace). Se la rete consente il traffico di pre-autenticazione ma l'IdP va in timeout, la rete non ha alcuna colpa.
ROI e impatto sul business
La riduzione del MTTI offre un valore aziendale tangibile che va ben oltre il semplice risparmio di ore di lavoro degli ingegneri.
- Riduzione del MTTR: eliminare 40 minuti di rimpalli di responsabilità da un incidente riduce direttamente i tempi di inattività, tutelando i ricavi nei settori del retail e dell' hospitality .
- Conformità agli SLA: una risoluzione più rapida delle controversie evita che vengano applicate penali ingiuste al fornitore di WiFi gestito quando il guasto dipende dall'ISP o dall'infrastruttura dell'edificio.
- Fidelizzazione dei clienti: nel settore del WiFi multi-tenant, i gestori immobiliari rinnovano i contratti con i fornitori che offrono trasparenza e risposte rapide. Le prove condivise creano fiducia, le argomentazioni difensive la distruggono.
- Ottimizzazione delle risorse: gli ingegneri di rete di livello 3, altamente qualificati, possono dedicare il proprio tempo alla progettazione di soluzioni invece di dover dimostrare manualmente che la rete funzioni correttamente.
Definizioni chiave
Mean Time to Innocence (MTTI)
Il tempo medio necessario a un team IT specifico per dimostrare, utilizzando dati oggettivi, che il proprio dominio o la propria infrastruttura non costituisce la causa principale di un incidente segnalato.
Cruciale per i provider di WiFi gestiti che devono difendere il proprio servizio nei confronti di property manager e ISP.
Mean Time to Identify
La metrica a livello aziendale che monitora il tempo totale trascorso dal rilevamento dell'incidente alla scoperta della reale causa principale.
L'MTTI è un sottoinsieme di questa metrica. Ridurre l'MTTI riduce direttamente il tempo complessivo di identificazione.
Synthetic Checks
Test automatizzati e continui che emulano il traffico degli utenti (es. query DNS, richieste HTTP) per monitorare proattivamente lo stato di salute della rete.
Utilizzati per dimostrare che il livello WiFi funzionava correttamente nell'esatto momento in cui un utente ha inviato una segnalazione.
Hop-by-Hop Path Visibility
Telemetria che traccia il traffico di rete nodo per nodo dal client alla destinazione, misurando la latenza e la perdita di pacchetti su ogni specifico router o switch.
Essenziale per dimostrare che un guasto risiede nella rete di un ISP o nello switch di distribuzione del proprietario dell'immobile, piuttosto che nell'hardware WiFi gestito.
Flow Data (NetFlow/IPFIX)
Dati del protocollo di rete che forniscono un riepilogo delle conversazioni di traffico, mostrando origine, destinazione, protocollo e volume.
Utilizzato per dimostrare che il traffico di un'applicazione specifica sta lasciando con successo la rete locale.
On-Demand Packet Capture (PCAP)
La capacità di registrare in modalità remota il traffico di rete grezzo da un access point o switch per l'analisi forense.
La prova definitiva utilizzata per dimostrare errori lato server o comportamenti anomali del dispositivo client.
Blast Radius
La portata dell'impatto di uno specifico incidente (es. un singolo utente, un AP, uno switch, un tenant o l'intero edificio).
Determinare il blast radius tramite la mappatura della topologia è il modo più rapido per escludere l'infrastruttura sana da un'indagine.
Event Correlation
La pratica di sovrapporre diversi flussi di dati (log, avvisi, aggiornamenti) su un'unica timeline per identificare causa ed effetto.
Utilizzata per dimostrare che un'interruzione di rete è stata causata da una modifica di terze parti, come una finestra di manutenzione non annunciata dell'ISP.
Esempi pratici
Un hotel da 350 camere segnala che il WiFi in camera è lento in tutta la struttura. La reception incolpa il provider del WiFi gestito. Come si scagiona la rete e come si individua la causa principale?
- Verificare i probe sintetici: i test di raggiungibilità DNS e HTTP mostrano che gli AP hanno una connessione pulita a Internet. 2. Esaminare la mappa della topologia: il problema interessa tutti gli AP su tutti gli switch, escludendo l'hardware di rete perimetrale. 3. Eseguire un tracciamento del percorso: il tracciamento mostra una latenza di 2 ms all'interno della LAN dell'hotel, ma di 180 ms al terzo hop (il router di aggregazione dell'ISP). 4. Esportare le prove: inviare lo screenshot del tracciamento del percorso al direttore dell'hotel e all'ISP.
Un rivenditore nazionale segnala che i terminali dei punti vendita (POS) in una determinata area geografica perdono la connessione con il processore di pagamento. Il team di rete viene accusato di un'errata configurazione del firewall o del routing.
- Isolare il raggio d'azione dell'impatto: confermare che solo i terminali POS (VLAN specifica) sono interessati, mentre il WiFi ospiti e i sistemi di back-office funzionano correttamente. 2. Analizzare i dati di flusso: NetFlow conferma che il traffico destinato all'intervallo IP del processore di pagamento esce correttamente dai router del punto vendita. 3. Acquisire i pacchetti: un PCAP on-demand sulla VLAN del POS rivela che il server del processore di pagamento sta inviando dei reset TCP (RST). 4. Condividere il PCAP con il team di supporto del processore di pagamento.
Domande di esercitazione
Q1. Un tenant in uno spazio di coworking si lamenta di non riuscire ad accedere alla VPN aziendale. Gli altri tenant navigano su internet senza problemi. Qual è il modo più efficiente per dimostrare che la rete WiFi non è la causa del problema?
Suggerimento: Considera il raggio di impatto (blast radius) e il tipo specifico di traffico interessato dall'interruzione.
Visualizza risposta modello
In primo luogo, utilizza la mappa della topologia per confermare che il raggio di impatto è limitato a un singolo utente o a un servizio specifico, escludendo così un guasto generale dell'AP o dello switch. In secondo luogo, analizza i dati di flusso (NetFlow/IPFIX) per l'indirizzo IP di quel client. Se i dati di flusso mostrano che il traffico VPN (ad es. UDP 500 o TCP 443) esce correttamente dalla rete, il WiFi e la LAN non hanno colpe. Il problema risiede nella configurazione della VPN del client o nel firewall aziendale che blocca la connessione.
Q2. Il tuo pannello di monitoraggio mostra che un AP è andato offline, ma il gestore della struttura insiste che il WiFi non funziona a causa di un disservizio dell'ISP. Come dimostri che il problema è l'alimentazione interna e non l'ISP?
Suggerimento: Cerca una correlazione tra lo stato dell'infrastruttura ed eventi esterni.
Visualizza risposta modello
Utilizza la correlazione degli eventi e la mappatura della topologia. Se la mappa mostra che un solo AP è offline mentre gli altri sullo stesso switch funzionano regolarmente, il circuito dell'ISP è chiaramente attivo. La correlazione degli eventi potrebbe mostrare un log di errore PoE (Power over Ethernet) dalla porta dello switch collegata a quel footprint specifico dell'AP. Questo prova che il problema riguarda l'hardware locale o il cablaggio, non il circuito WAN.
Q3. Un direttore delle operazioni di uno stadio sostiene che il WiFi ha smesso di funzionare durante l'intervallo perché i lettori di biglietti hanno smesso di rispondere. Devi scagionare la rete in meno di due minuti. Quale telemetria utilizzi?
Suggerimento: Hai bisogno di una prova storica dello stato di salute della rete nell'esatto momento del disservizio segnalato.
Visualizza risposta modello
Estrai i dati storici dai test sintetici continui. Mostra al direttore delle operazioni la dashboard che conferma come, esattamente durante la finestra di 15 minuti dell'intervallo, gli AP stessero risolvendo correttamente il DNS e raggiungendo l'indirizzo IP del server di biglietteria con una bassa latenza. Questo dimostra immediatamente che la rete wireless era integra, spostando l'indagine sui server dell'applicazione di biglietteria, che probabilmente sono andati in sovraccarico a causa del picco improvviso.
Continua a leggere questa serie
Progettazione di reti WiFi per edifici per uffici multi-tenant
Questa guida fornisce a IT manager, architetti di rete e CTO un modello indipendente dal fornitore per la progettazione di reti WiFi scalabili, sicure e isolate in edifici per uffici multi-tenant. Copre la segmentazione VLAN secondo lo standard IEEE 802.1Q, l'assegnazione dinamica delle VLAN tramite 802.1X e RADIUS, la pianificazione RF per ambienti ad alta densità e le considerazioni sulla conformità ai sensi del GDPR e PCI DSS. Gli operatori delle strutture e i gestori degli edifici troveranno linee guida sull'architettura pronte all'uso, casi di studio reali ed errori di configurazione da evitare prima dell'implementazione.
Requisiti legali e di conformità per l'infrastruttura WiFi condivisa
Questa guida tecnica di riferimento delinea i requisiti legali, normativi e architetturali critici per l'implementazione e la gestione di un'infrastruttura WiFi condivisa. Fornisce a IT manager, architetti di rete e gestori di sedi operative framework pratici per garantire una solida protezione dei dati, una rigorosa conformità alla sicurezza dei pagamenti e un isolamento dei tenant ad alte prestazioni utilizzando standard aziendali.
Best practice di segmentazione VLAN per ambienti multi-tenant
Questa guida offre a IT manager, network architect, CTO e direttori operativi delle location un modello autorevole e neutrale rispetto ai fornitori per implementare la segmentazione VLAN in ambienti WiFi multi-tenant. Copre lo standard IEEE 802.1Q, l'assegnazione dinamica delle VLAN tramite 802.1X e RADIUS, e una guida passo-passo alla distribuzione per i settori dell'ospitalità, del retail, degli stadi e del settore pubblico. Una corretta segmentazione VLAN rappresenta il controllo fondamentale per la conformità PCI DSS e GDPR, la prevenzione dei movimenti laterali e l'erogazione di connettività wireless ad alte prestazioni su infrastrutture fisiche condivise.