Pourquoi le WiFi de votre stade s'effondre (et comment y remédier)
Ce guide technique de référence examine la cause profonde de la congestion du WiFi dans les stades — les communications d'arrière-plan simultanées de 50 000 appareils chargeant des publicités programmatiques et de la télémétrie — et fournit un plan d'architecture détaillé pour déployer le filtrage DNS à la périphérie (edge) comme stratégie principale d'atténuation. Conçu pour les directeurs informatiques, les CTO et les architectes réseau, il offre des conseils de mise en œuvre exploitables, des études de cas réelles et des cadres de ROI mesurables pour aider les exploitants de sites à récupérer de la bande passante et à offrir une connectivité haute performance à grande échelle.
Écouter ce guide
Voir la transcription du podcast
कार्यकारी सारांश
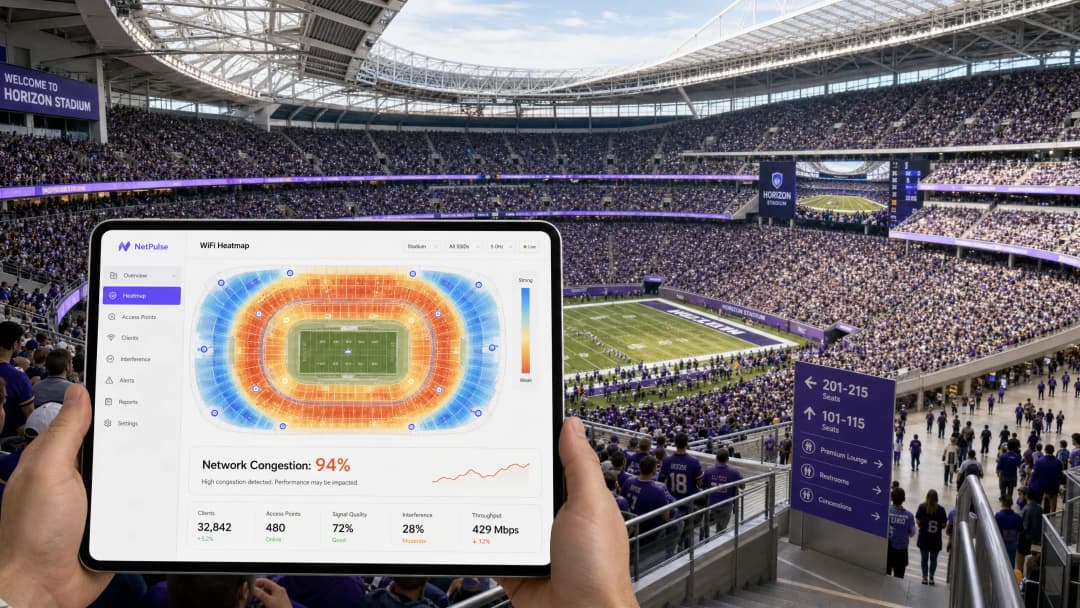
हाई-डेंसिटी वेन्यू का प्रबंधन करने वाले CTO और IT निदेशकों के लिए, stadium WiFi slow (स्टेडियम WiFi का धीमा होना) की घटना एक लगातार और महंगा परिचालन जोखिम है। मल्टी-गीगाबिट बैकहॉल, हाई-डेंसिटी एक्सेस पॉइंट्स और सावधानीपूर्वक RF प्लानिंग पर महत्वपूर्ण पूंजीगत व्यय के बावजूद, जब वेन्यू की क्षमता 80% से अधिक हो जाती है, तो नेटवर्क अक्सर ठप हो जाते हैं। इसका मूल कारण शायद ही कभी हार्डवेयर की सीमा होती है। यह बैकग्राउंड ट्रैफ़िक का अदृश्य एवलांच (हिमस्खलन) है। जब 50,000 डिवाइस एक साथ Guest WiFi नेटवर्क से जुड़ते हैं, तो वे लाखों माइक्रो-ट्रांज़ैक्शन शुरू करते हैं — प्रोग्रैमेटिक विज्ञापन लोड करना, टेलीमेट्री सिंक करना, और बैकग्राउंड SDK कॉल निष्पादित करना। यह "चैटर" किसी एक उपयोगकर्ता के सक्रिय रूप से वेब ब्राउज़ करने से पहले ही उपलब्ध बैंडविड्थ का 60% तक उपभोग कर सकता है, NAT पूल्स को समाप्त कर सकता है और एयरटाइम को सैचुरेट कर सकता है। यह गाइड इस कंजेशन (भीड़) के तकनीकी तंत्र का विवरण देती है, Edge DNS फ़िल्टरिंग को लागू करने के लिए एक वेंडर-न्यूट्रल आर्किटेक्चरल ब्लूप्रिंट प्रदान करती है, और ऐसा करने के ROI को निर्धारित करती है。
तकनीकी डीप-डाइव: हाई-डेंसिटी कंजेशन की शारीरिक रचना
बैकग्राउंड ट्रैफ़िक एवलांच
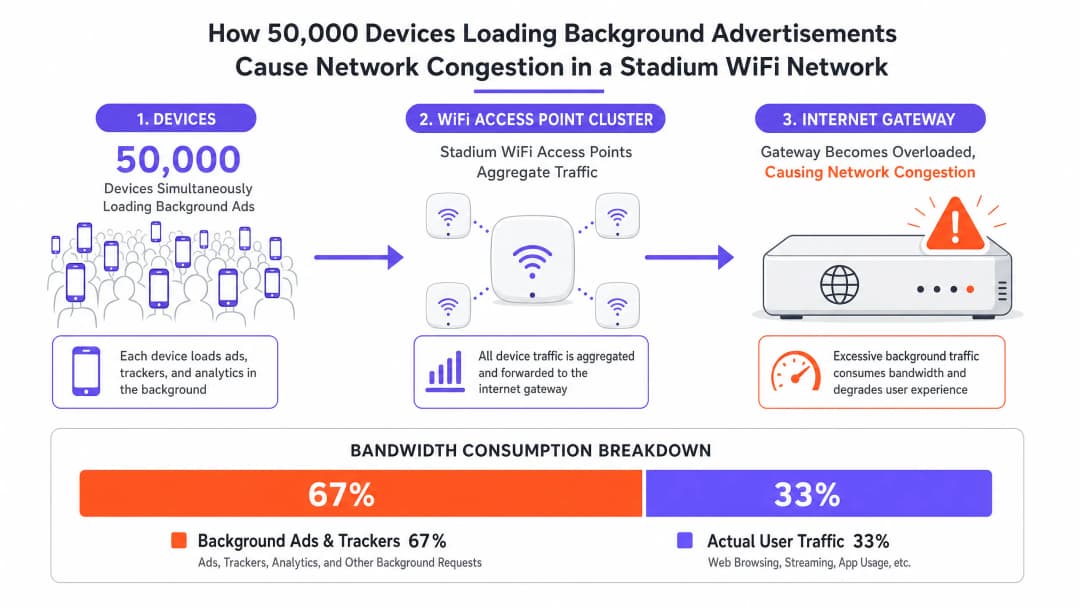
जब कोई डिवाइस गेस्ट WiFi नेटवर्क से जुड़ता है, तो यह तुरंत बैकग्राउंड गतिविधि की एक श्रृंखला शुरू कर देता है जिसका उपयोगकर्ता द्वारा सक्रिय रूप से किए जा रहे कार्य से कोई लेना-देना नहीं होता है। आधुनिक मोबाइल एप्लिकेशन कई थर्ड-पार्टी SDK के साथ एम्बेडेड होते हैं — एनालिटिक्स प्लेटफ़ॉर्म, क्रैश रिपोर्टिंग सेवाओं और प्रोग्रैमेटिक विज्ञापन नेटवर्क के लिए। प्रत्येक SDK स्वतंत्र रूप से काम करता है, अपने स्वयं के शेड्यूल पर अपने स्वयं के सर्वर को पोल करता है। स्टेडियम के माहौल में, एक साथ ये कार्य करने वाले 50,000 डिवाइस एक ट्रैफ़िक प्रोफ़ाइल बनाते हैं जो किसी भी अन्य डिप्लॉयमेंट परिदृश्य से मौलिक रूप से भिन्न होता है।
इस ट्रैफ़िक की विशेषता हाई वॉल्यूम, लो-पेलोड रिक्वेस्ट है: ट्रैकिंग पिक्सल और विज्ञापन क्रिएटिव के लिए छोटे-पैकेट वाले TCP हैंडशेक, DNS क्वेरी और HTTP GET रिक्वेस्ट। हालांकि प्रति डिवाइस स्थानांतरित कुल डेटा अलग से देखने पर नगण्य लग सकता है, लेकिन नेटवर्क की स्पेक्ट्रल एफ़िशिएंसी पर इसका समग्र प्रभाव विनाशकारी होता है। IEEE 802.11 मानक यह निर्धारित करता है कि WiFi एक साझा माध्यम है; किसी भी डिवाइस द्वारा प्रेषित प्रत्येक पैकेट को एयरटाइम के लिए प्रतिस्पर्धा करनी चाहिए। लाखों बैकग्राउंड माइक्रो-ट्रांज़ैक्शन इस साझा माध्यम को सैचुरेट कर देते हैं, जिससे वैध उपयोगकर्ता सत्रों के लिए अपर्याप्त एयरटाइम बचता है।
स्केल पर तीन विफलता मोड (Failure Modes)
हाई-डेंसिटी कंजेशन आमतौर पर तीन अलग-अलग विफलता मोड के माध्यम से प्रकट होता है, जो अक्सर एक साथ होते हैं:
| विफलता मोड (Failure Mode) | तकनीकी कारण | उपयोगकर्ता द्वारा महसूस किया गया लक्षण |
|---|---|---|
| स्टेट टेबल एग्जॉर्शन | फ़ायरवॉल/NAT गेटवे की कनेक्शन ट्रैकिंग मेमोरी खत्म हो जाती है | ड्रॉप किए गए पैकेट, कनेक्शन टाइमआउट, Captive Portal की विफलताएं |
| एयरटाइम सैचुरेशन | बैकग्राउंड माइक्रो-ट्रांज़ैक्शन के कारण साझा RF माध्यम ओवरलोड हो जाता है | कम AP क्लाइंट काउंट के बावजूद हाई लेटेंसी, खराब थ्रूपुट |
| DNS रिज़ॉल्वर ओवरलोड | विज्ञापन नेटवर्क और टेलीमेट्री क्वेरी के कारण स्थानीय रिज़ॉल्वर ओवरलोड हो जाते हैं | धीमे पेज लोड, ऐप विफलताएं, ऑथेंटिकेशन में देरी |
इनमें से स्टेट टेबल एग्जॉर्शन सबसे घातक है। एक सामान्य एंटरप्राइज़ फ़ायरवॉल को 500,000 से 1,000,000 समवर्ती कनेक्शन स्टेट्स को संभालने के लिए आकार दिया जा सकता है। 50,000-डिवाइस वाले स्टेडियम में, जहां प्रत्येक डिवाइस 20 से 30 बैकग्राउंड कनेक्शन बनाए रखता है, किसी भी सक्रिय उपयोगकर्ता ट्रैफ़िक का हिसाब लगाने से पहले ही सैद्धांतिक कनेक्शन स्टेट काउंट दस लाख से अधिक हो जाता है। इसका परिणाम हर जगह ड्रॉप किए गए पैकेट और विफल कनेक्शन होते हैं, जो हर उपयोगकर्ता को प्रभावित करते हैं, चाहे उनका अपना व्यवहार कुछ भी हो।
एयरटाइम सैचुरेशन 802.11 कंटेंशन मैकेनिज्म (CSMA/CA) द्वारा और बढ़ जाता है। ट्रांसमिट करने से पहले हर डिवाइस को सुनना चाहिए, और डिवाइस के घनत्व के साथ टकराव की संभावना तेजी से बढ़ती है। विज्ञापन नेटवर्क और टेलीमेट्री सेवाओं से आने वाला बैकग्राउंड ट्रैफ़िक वैध उपयोगकर्ता ट्रैफ़िक को कतार में लगने के लिए मजबूर करता है, जिससे लेटेंसी बढ़ती है और प्रभावी थ्रूपुट एक्सेस पॉइंट्स की सैद्धांतिक क्षमता से बहुत कम हो जाता है।
DNS रिज़ॉल्वर ओवरलोड को अक्सर अनदेखा कर दिया जाता है। एक सामान्य स्टेडियम डिप्लॉयमेंट में, WiFi Analytics से पता चलता है कि विज्ञापन नेटवर्क डोमेन — जैसे कि प्रमुख प्रोग्रैमेटिक विज्ञापन प्लेटफ़ॉर्म द्वारा संचालित — लगातार शीर्ष पांच सबसे अधिक क्वेरी की जाने वाली DNS प्रविष्टियों में दिखाई देते हैं। प्रत्येक क्वेरी, हालांकि व्यक्तिगत रूप से छोटी होती है, स्थानीय रिज़ॉल्वर पर समग्र लोड में योगदान करती है और डाउनस्ट्रीम TCP कनेक्शन प्रयासों को ट्रिगर करती है जो स्टेट टेबल पर और बोझ डालते हैं।
कार्यान्वयन गाइड: Edge DNS फ़िल्टरिंग आर्किटेक्चर
इस विफलता पैटर्न की रणनीतिक प्रतिक्रिया अधिक हार्डवेयर का प्रावधान करना नहीं है, बल्कि शोर के स्रोत को खत्म करना है। Edge DNS फ़िल्टरिंग प्राथमिक शमन रणनीति है, और जब इसे सही ढंग से तैनात किया जाता है, तो यह 40% तक WAN बैंडविड्थ को पुनः प्राप्त कर सकता है और औसत लेटेंसी को 60ms या उससे अधिक कम कर सकता है।
आर्किटेक्चरल ब्लूप्रिंट
Edge DNS फ़िल्टरिंग नेटवर्क परिधि पर DNS क्वेरी को इंटरसेप्ट करके काम करती है। जब कोई डिवाइस किसी ज्ञात विज्ञापन नेटवर्क, टेलीमेट्री सर्वर, या मैलवेयर डोमेन के IP पते का अनुरोध करता है, तो फ़िल्टर एक नल रूट (null route) के साथ प्रतिक्रिया करता है — या तो 0.0.0.0 या NXDOMAIN प्रतिक्रिया लौटाता है। यह डिवाइस को TCP कनेक्शन स्थापित करने से रोकता है, जिससे संबंधित स्टेट-टेबल ओवरहेड, एयरटाइम खपत और WAN बैंडविड्थ उपयोग समाप्त हो जाता है।

डिप्लॉयमेंट के चरण
चरण 1: स्थानीय DNS रिज़ॉल्वर तैनात करें वेन्यू के किनारे पर अत्यधिक उपलब्ध स्थानीय DNS रिज़ॉल्वर लागू करें। ये कनेक्टेड डिवाइस आबादी के पूर्ण क्वेरी लोड को संभालने में सक्षम होने चाहिए। केवल अपस्ट्रीम ISP रिज़ॉल्वर पर निर्भर न रहें, क्योंकि यह लेटेंसी पेश करता है और फ़िल्टर करने की आपकी क्षमता को हटा देता है।
चरण 2: थ्रेट इंटेलिजेंस और एड-ब्लॉकिंग फ़ीड्स को एकीकृत करें एंटरप्राइज़-ग्रेड थ्रेट इंटेलिजेंस फ़ीड्स की सदस्यता लें जिनमें ज्ञात विज्ञापन नेटवर्क डोमेन, टेलीमेट्री सर्वर और मैलवेयर इन्फ्रास्ट्रक्चर शामिल हों। इन फ़ीड्स को गतिशील रूप से अपडेट किया जाना चाहिए — आदर्श रूप से हर कुछ घंटों में — ताकि विज्ञापन नेटवर्क द्वारा ब्लॉकिंग से बचने के लिए उपयोग किए जाने वाले नए पंजीकृत डोमेन को पकड़ा जा सके。
चरण 3: DHCP नीति कॉन्फ़िगर करें सभी गेस्ट डिवाइसों को स्थानीय, फ़िल्टर किए गए रिज़ॉल्वर के IP पते वितरित करने के लिए DHCP सर्वर कॉन्फ़िगर करें। यह क्लाइंट DNS ट्रैफ़िक को फ़िल्टर के माध्यम से निर्देशित करने के लिए प्राथमिक प्रवर्तन तंत्र है।
चरण 4: इग्रेस फ़ायरवॉल नियम लागू करें यह चरण महत्वपूर्ण है और अक्सर छोड़ दिया जाता है। स्वीकृत स्थानीय रिज़ॉल्वर के अलावा किसी भी अन्य गंतव्य के लिए सभी आउटबाउंड DNS ट्रैफ़िक (TCP/UDP पोर्ट 53) को ब्लॉक करने के लिए सख्त इग्रेस फ़ायरवॉल नियम लागू करें। यह हार्डकोडेड DNS सेटिंग्स वाले डिवाइसों को फ़िल्टर को बायपास करने से रोकता है।
चरण 5: DNS over HTTPS (DoH) को संबोधित करें जैसा कि DNS Over HTTPS (DoH): Implications for Public WiFi Filtering पर हमारे गाइड में विस्तृत है, आधुनिक ऑपरेटिंग सिस्टम और ब्राउज़र तेजी से DNS क्वेरी को एन्क्रिप्ट करने के लिए DoH का उपयोग करते हैं, उन्हें बाहरी रिज़ॉल्वर पर रूट करते हैं और स्थानीय फ़िल्टरिंग को पूरी तरह से बायपास करते हैं। नेटवर्क प्रशासकों को फ़ायरवॉल स्तर पर ज्ञात DoH प्रदाताओं के IP पतों को स्पष्ट रूप से ब्लॉक करना चाहिए। यह क्लाइंट को मानक, अनएन्क्रिप्टेड DNS पर वापस जाने के लिए मजबूर करता है, जिसे बाद में फ़िल्टर किया जा सकता है। अंतर्राष्ट्रीय डिप्लॉयमेंट के लिए इस मार्गदर्शन का पुर्तगाली-भाषा समकक्ष DNS Over HTTPS (DoH): Implicações para a Filtragem de WiFi Público पर उपलब्ध है।
चरण 6: आइडेंटिटी और एक्सेस मैनेजमेंट के साथ एकीकृत करें अधिकतम प्रभावशीलता के लिए, DNS फ़िल्टरिंग नीतियों को उपयोगकर्ता ऑथेंटिकेशन से लिंक करें। profile-based authentication का लाभ उठाना — जैसा कि पासवर्डलेस एक्सेस पर हमारे 2026 गाइड में खोजा गया है — वेन्यू को उपयोगकर्ता भूमिकाओं के आधार पर विभेदित फ़िल्टरिंग नीतियां लागू करने की अनुमति देता है। सामान्य प्रवेश उपयोगकर्ताओं को आक्रामक फ़िल्टरिंग प्राप्त होती है; प्रेस, कॉर्पोरेट, या VIP उपयोगकर्ताओं को अधिक अनुमेय नीतियां प्राप्त हो सकती हैं जो विशिष्ट व्यावसायिक अनुप्रयोगों की अनुमति देती हैं।
केस स्टडीज़
केस स्टडी 1: 60,000-सीटों वाला फ़ुटबॉल स्टेडियम, UK
एक प्रीमियर लीग फ़ुटबॉल क्लब हाफ़टाइम के दौरान गंभीर नेटवर्क डिग्रेडेशन का अनुभव कर रहा था, जिसमें Captive Portal टाइम आउट हो रहा था और पीक मोमेंट्स पर सोशल मीडिया शेयरिंग विफल हो रही थी। WAN सर्किट एक 10Gbps समर्पित कनेक्शन था, जो घटना के दौरान केवल 28% उपयोग पर काम कर रहा था। हालाँकि, फ़ायरवॉल स्टेट टेबल 97% क्षमता पर था।
WiFi Analytics का उपयोग करके ट्रैफ़िक ऑडिट के बाद, टीम ने पहचाना कि विज्ञापन नेटवर्क डोमेन सभी DNS क्वेरी का 61% हिस्सा थे। शीर्ष पांच डोमेन सभी प्रोग्रैमेटिक विज्ञापन इन्फ्रास्ट्रक्चर थे। 1.2 मिलियन डोमेन की ब्लॉकलिस्ट के साथ Edge DNS फ़िल्टरिंग तैनात की गई थी, साथ ही पोर्ट 53 और DoH प्रदाता IP को ब्लॉक करने वाले सख्त इग्रेस नियम भी थे।
परिणाम: पीक क्षमता पर स्टेट टेबल का उपयोग गिरकर 34% हो गया, औसत लेटेंसी 280ms से गिरकर 95ms हो गई, और पीक पर WAN बैंडविड्थ उपयोग 28% से गिरकर 17% हो गया — कनेक्टेड डिवाइसों की संख्या में कोई बदलाव न होने के बावजूद खपत की गई बैंडविड्थ में 39% की कमी।
केस स्टडी 2: अंतर्राष्ट्रीय सम्मेलन केंद्र, Hospitality क्षेत्र
15,000-प्रतिनिधियों वाले प्रौद्योगिकी शिखर सम्मेलन की मेजबानी करने वाला एक प्रमुख सम्मेलन केंद्र हाल ही में अपग्रेड किए गए बुनियादी ढांचे के बावजूद धीमे WiFi के बारे में उपस्थित लोगों की शिकायतों का अनुभव कर रहा था। वेन्यू ने 400 एंटरप्राइज़-ग्रेड एक्सेस पॉइंट और 5Gbps WAN सर्किट तैनात किया था।
ट्रैफ़िक विश्लेषण से पता चला कि प्रतिनिधि डिवाइस — मुख्य रूप से कॉर्पोरेट लैपटॉप जिनमें कई एंटरप्राइज़ एप्लिकेशन चल रहे थे — प्रति डिवाइस औसतन 45 बैकग्राउंड कनेक्शन उत्पन्न कर रहे थे। DNS रिज़ॉल्वर प्रति घंटे 2.3 मिलियन क्वेरी प्रोसेस कर रहा था, जिसमें से 68% विज्ञापन नेटवर्क और एनालिटिक्स प्लेटफ़ॉर्म के लिए नियत थे।
सम्मेलन पंजीकरण प्रणाली से जुड़ी नीति एकीकरण के साथ Edge DNS फ़िल्टरिंग डिप्लॉयमेंट के बाद, वेन्यू ने DNS क्वेरी वॉल्यूम में 52% की कमी, फ़ायरवॉल स्टेट टेबल उपयोग में 41% की कमी, और औसत TCP कनेक्शन स्थापना समय में 180ms से 62ms तक औसत दर्जे का सुधार देखा। WiFi गुणवत्ता के लिए प्रतिनिधि संतुष्टि स्कोर 5 में से 3.1 से बढ़कर 4.6 हो गया।
सर्वोत्तम प्रथाएँ और मानक (Best Practices & Standards)
निम्नलिखित वेंडर-न्यूट्रल सर्वोत्तम प्रथाएँ हाई-डेंसिटी WiFi डिप्लॉयमेंट के लिए वर्तमान उद्योग मानकों को दर्शाती हैं:
- IEEE 802.11ax (Wi-Fi 6/6E): Wi-Fi 6 या 6E एक्सेस पॉइंट तैनात करें। OFDMA और BSS कलरिंग सुविधाएँ हाई-डेंसिटी वाले वातावरण में एयरटाइम कंटेंशन को काफी कम करती हैं, जो DNS फ़िल्टरिंग द्वारा प्राप्त ट्रैफ़िक में कमी को पूरक करती हैं।
- WPA3-Enterprise: संवेदनशील डेटा को संभालने वाले किसी भी डिप्लॉयमेंट के लिए IEEE 802.1X ऑथेंटिकेशन के साथ WPA3-Enterprise लागू करें। यह Retail वातावरण में PCI DSS अनुपालन के लिए एक आधारभूत आवश्यकता है और GDPR डेटा न्यूनीकरण सिद्धांतों के साथ संरेखित है।
- GDPR अनुपालन: Captive Portal सेवा की शर्तों में DNS फ़िल्टरिंग सहित नेटवर्क ऑप्टिमाइज़ेशन टूल के उपयोग को पारदर्शी रूप से संप्रेषित करें। उपयोगकर्ताओं को सूचित किया जाना चाहिए कि नेटवर्क प्रबंधन फ़ंक्शन के हिस्से के रूप में DNS क्वेरी को स्थानीय रूप से प्रोसेस किया जाता है।
- निगरानी और एनालिटिक्स: WiFi Analytics का उपयोग करके शीर्ष अनुरोधित डोमेन की लगातार निगरानी करें और तदनुसार फ़िल्टरिंग नीतियों को समायोजित करें। विज्ञापन नेटवर्क ब्लॉकिंग से बचने के लिए नियमित रूप से नए डोमेन पंजीकृत करते हैं; स्थिर ब्लॉकलिस्ट कुछ ही दिनों में पुरानी हो जाती हैं।
- सार्वजनिक क्षेत्र के डिप्लॉयमेंट: सार्वजनिक क्षेत्र और स्मार्ट सिटी WiFi डिप्लॉयमेंट के लिए, जैसा कि Purple's public sector expansion के संदर्भ में चर्चा की गई है, DNS फ़िल्टरिंग एक सुरक्षा कार्य भी करती है, जो स्थानीय प्राधिकरण की आवश्यकताओं के अनुपालन में हानिकारक सामग्री श्रेणियों तक पहुंच को रोकती है।
समस्या निवारण और जोखिम न्यूनीकरण (Troubleshooting & Risk Mitigation)
फ़ॉल्स पॉज़िटिव्स
जोखिम: अत्यधिक आक्रामक फ़िल्टरिंग वैध एप्लिकेशन कार्यक्षमता को ब्लॉक कर सकती है, जैसे टिकटिंग ऐप, वेन्यू नेविगेशन सेवाएं, या कॉर्पोरेट VPN एंडपॉइंट।
शमन (Mitigation): मॉनिटर-ओनली बेसलाइन चरण के दौरान पहचाने गए मिशन-क्रिटिकल डोमेन के लिए एक सख्त अलाउलिस्ट लागू करें। उत्पादन वातावरण में कभी भी सीधे प्रवर्तन (enforcement) मोड में न जाएं। प्रवर्तन से पहले दो सप्ताह की निगरानी अवधि न्यूनतम अनुशंसित बेसलाइन है।
बैकग्राउंड ट्रैफ़िक के माध्यम से Captive Portal बायपास
जोखिम: यदि उपयोगकर्ता द्वारा ब्राउज़र खोलने से पहले बैकग्राउंड ट्रैफ़िक OS के Captive Portal डिटेक्शन मैकेनिज्म (उदा., Apple का captive.apple.com चेक) को संतुष्ट करता है, तो डिवाइस Captive Portal को ट्रिगर करने में विफल हो सकते हैं।
शमन: Captive Portal डिटेक्शन और ऑथेंटिकेशन के लिए आवश्यक विशिष्ट डोमेन को ही अनुमति देने के लिए वॉल्ड गार्डन को सख्त करें। जब तक उपयोगकर्ता पूरी तरह से ऑथेंटिकेट नहीं हो जाता और उनके सत्र पर फ़िल्टरिंग नीति लागू नहीं हो जाती, तब तक अन्य सभी ट्रैफ़िक को ब्लॉक किया जाना चाहिए।
DoH बायपास
जोखिम: DoH का उपयोग करने वाले डिवाइस स्थानीय DNS फ़िल्टरिंग को बायपास कर देंगे, जिससे उन क्लाइंट्स के लिए पूरी रणनीति अप्रभावी हो जाएगी।
शमन: DoH प्रदाता IP पतों की एक अद्यतित ब्लॉकलिस्ट बनाए रखें और उन्हें फ़ायरवॉल पर ब्लॉक करें। यह एक बार का कॉन्फ़िगरेशन नहीं है; नए DoH प्रदाता नियमित रूप से उभरते हैं और उन्हें ट्रैक किया जाना चाहिए।
ऑफ़लाइन मैप और नेविगेशन सेवाएँ
WiFi के साथ इनडोर नेविगेशन तैनात करने वाले वेन्यू के लिए — जैसे कि Purple's Offline Maps Mode का उपयोग करने वाले — सुनिश्चित करें कि मैप टाइल सर्वर और नेविगेशन API स्पष्ट रूप से अलाउलिस्ट किए गए हैं। ये सेवाएँ उपयोगकर्ता अनुभव के लिए महत्वपूर्ण हैं और इन्हें व्यापक विज्ञापन-नेटवर्क फ़िल्टरिंग नियमों में नहीं फंसना चाहिए।
ROI और व्यावसायिक प्रभाव
Edge DNS फ़िल्टरिंग के लिए व्यावसायिक मामला कई आयामों में सम्मोहक है:
| मेट्रिक | विशिष्ट परिणाम | व्यावसायिक प्रभाव |
|---|---|---|
| WAN बैंडविड्थ में कमी | 30–40% | सर्किट अपग्रेड लागत टल गई; बुनियादी ढांचे का जीवनचक्र बढ़ गया |
| लेटेंसी में कमी | 40–70ms औसत | वेन्यू ऐप्स और डिजिटल सेवाओं के साथ उच्च उपयोगकर्ता जुड़ाव |
| स्टेट टेबल उपयोग | पीक पर 50–65% की कमी | फ़ायरवॉल हार्डवेयर रिफ्रेश टल गया; घटना का जोखिम कम हो गया |
| DNS क्वेरी वॉल्यूम | 40–60% की कमी | रिज़ॉल्वर लोड कम हो गया; ऑथेंटिकेशन गति में सुधार |
| उपयोगकर्ता संतुष्टि | मापने योग्य NPS सुधार | उच्च ड्वेल टाइम, F&B खर्च में वृद्धि, बेहतर ब्रांड धारणा |
WAN कनेक्टिविटी पर प्रति वर्ष £80,000 खर्च करने वाले और £200,000 के हार्डवेयर रिफ्रेश चक्र का सामना करने वाले स्टेडियम के लिए, 35% बैंडविड्थ में कमी का मतलब है वार्षिक WAN बचत में लगभग £28,000 और हार्डवेयर रिफ्रेश चक्र का संभावित 18 महीने का विस्तार — इस पैमाने के वेन्यू के लिए आमतौर पर £15,000 से £30,000 की सीमा में कार्यान्वयन लागत के मुकाबले, संयुक्त तीन साल की बचत £100,000 से अधिक है।
तकनीकी ब्रीफिंग सुनें
Définitions clés
Épuisement de la table d'état
Une situation dans laquelle un pare-feu ou une passerelle NAT manque de mémoire allouée pour le suivi des connexions réseau actives, ce qui l'amène à rejeter les nouvelles requêtes de connexion.
Se produit dans les espaces à forte densité lorsque des dizaines de milliers d'appareils lancent simultanément des micro-connexions vers des réseaux publicitaires et des serveurs de télémétrie. C'est la cause principale du paradoxe du « WiFi lent dans les stades », où le circuit WAN semble sous-utilisé alors que le réseau est concrètement en panne.
Utilisation du temps d'antenne
Le pourcentage de temps pendant lequel le spectre RF sur un canal WiFi donné est activement utilisé pour transmettre des données ou des trames de gestion.
Une forte utilisation du temps d'antenne par les flux d'arrière-plan réduit la capacité disponible pour les sessions utilisateur actives. Dans un stade à forte densité, le trafic d'arrière-plan peut pousser l'utilisation du temps d'antenne au-delà de 80 %, ne laissant pas assez de capacité pour le trafic des utilisateurs légitimes.
Filtrage DNS à la périphérie
La pratique consistant à intercepter les requêtes DNS au périmètre du réseau et à bloquer la résolution des domaines connus comme malveillants, à forte surcharge ou enfreignant les règles en renvoyant une route nulle ou une réponse NXDOMAIN.
La principale mesure d'atténuation architecturale pour la congestion du trafic d'arrière-plan dans les espaces à forte densité. Il empêche les appareils d'établir des connexions avec les réseaux publicitaires et les serveurs de télémétrie, récupérant ainsi de la bande passante et réduisant la charge de la table d'état.
DNS over HTTPS (DoH)
Un protocole permettant d'effectuer une résolution DNS via le protocole HTTPS, de chiffrer la requête DNS et de l'acheminer vers un résolveur externe, contournant ainsi l'infrastructure DNS locale.
Le principal mécanisme de contournement du filtrage DNS à la périphérie. Doit être explicitement bloqué au niveau IP pour garantir que tout le trafic DNS passe par le résolveur local filtré.
Route nulle
Une route réseau qui rejette le trafic destiné à une adresse IP ou à un domaine spécifique, en l'abandonnant purement et simplement sans le rediriger.
Utilisé par les filtres DNS pour répondre aux domaines bloqués — en renvoyant 0.0.0.0 ou NXDOMAIN — ce qui empêche le client d'initier une connexion TCP et élimine la surcharge réseau associée.
Walled Garden
Un environnement réseau restreint qui limite l'accès des appareils à un ensemble prédéfini de ressources, généralement utilisé pour imposer l'authentification par Captive Portal avant d'autoriser un accès complet à Internet.
Doit être rigoureusement configuré pour empêcher le trafic d'arrière-plan de valider les mécanismes de détection de Captive Portal des OS avant que l'utilisateur ne s'authentifie, ce qui permettrait à un trafic d'arrière-plan non restreint de circuler sans qu'aucune politique de filtrage ne soit appliquée.
Authentification basée sur les profils
Une méthode d'authentification qui applique de manière dynamique des politiques réseau spécifiques — y compris des règles de filtrage DNS, des limites de bande passante et des contrôles d'accès — en fonction de l'identité ou du rôle de l'utilisateur authentifié.
Permet aux espaces de proposer des expériences réseau différenciées, en appliquant un filtrage agressif aux utilisateurs de l'accès général tout en offrant des politiques plus permissives aux VIP, à la presse ou aux invités d'entreprise.
OFDMA (Orthogonal Frequency Division Multiple Access)
Une version multi-utilisateur de l'OFDM qui permet de diviser une transmission Wi-Fi 6 (802.11ax) unique entre plusieurs utilisateurs simultanément, réduisant ainsi les conflits et améliorant l'efficacité spectrale.
Une fonctionnalité clé du Wi-Fi 6 qui répond directement aux conflits de temps d'antenne dans les déploiements à forte densité. Fonctionne en conjonction avec le filtrage DNS pour maximiser la capacité utile de chaque point d'accès.
Efficacité spectrale
La quantité de données utiles qui peuvent être transmises sur une bande passante donnée dans un système de communication spécifique.
Réduite par les micro-transactions en arrière-plan qui consomment du temps d'antenne sans apporter de valeur aux utilisateurs finaux. Le filtrage à la périphérie et les fonctionnalités du Wi-Fi 6 comme l'OFDMA fonctionnent ensemble pour maximiser l'efficacité spectrale.
Exemples concrets
Un stade de 50 000 places subit une dégradation importante du réseau pendant la mi-temps. L'équipe informatique a vérifié que le circuit WAN de 10 Gbps n'est utilisé qu'à 30 %, mais les points d'accès (AP) signalent une utilisation élevée du temps d'antenne (airtime) et la table d'état du pare-feu est saturée à 95 %. L'ajout d'AP supplémentaires n'a pas amélioré les performances.
Le problème ne vient pas de la bande passante brute ou de la densité des AP, mais de l'épuisement de la table d'état des connexions causé par les communications en arrière-plan des applications. La solution nécessite le déploiement d'un filtre DNS Edge selon une approche progressive. Étape 1 : Déployer des résolveurs DNS locaux et les configurer en mode surveillance uniquement pendant deux semaines. Analyser les 100 domaines les plus consultés. Étape 2 : Configurer le DHCP pour diriger tous les clients invités vers les résolveurs locaux. Mettre en œuvre des règles de pare-feu de sortie bloquant les ports TCP/UDP 53 vers toutes les adresses IP externes. Étape 3 : Bloquer les adresses IP des fournisseurs DoH connus (Cloudflare 1.1.1.1, Google 8.8.8.8, etc.) au niveau du pare-feu. Étape 4 : Activer le mode de blocage sur le filtre DNS avec une liste de blocage ciblant les réseaux publicitaires et les domaines de télémétrie identifiés. Étape 5 : Surveiller l'utilisation de la table d'état et les métriques de temps d'antenne lors des trois événements suivants pour valider l'amélioration.
Un grand centre de transport souhaite mettre en œuvre un filtrage DNS sur 12 terminaux afin d'améliorer les performances réseau pour 80 000 passagers quotidiens. Ils craignent de perturber les applications de billetterie des compagnies aériennes et les systèmes opérationnels de l'aéroport.
Mettre en œuvre une plateforme de filtrage DNS centralisée et gérée dans le cloud avec des redirecteurs locaux dans chaque terminal. Étape 1 : Déployer des redirecteurs locaux dans les 12 terminaux, connectés à un plan de gestion centralisé. Étape 2 : Exécuter en mode surveillance uniquement pendant 30 jours simultanément dans tous les terminaux. Utiliser les analyses pour concevoir une liste d'autorisation exhaustive des domaines de billetterie des compagnies aériennes, des API d'exploitation de l'aéroport et des points de terminaison des systèmes d'assistance en escale. Étape 3 : Segmenter le réseau en VLAN pour le WiFi invités et en VLAN pour les technologies opérationnelles (OT). Appliquer un filtrage strict au WiFi invités ; appliquer une politique de liste d'autorisation stricte et exclusive aux VLAN OT. Étape 4 : Activer le filtrage sur le WiFi invités. Étape 5 : Mettre en œuvre une gestion automatisée de la liste d'autorisation — lorsqu'une nouvelle compagnie aérienne commence ses activités dans le terminal, ses domaines requis sont ajoutés à la liste d'autorisation via un processus de gestion du changement.
Questions d'entraînement
Q1. Vous avez déployé un filtre DNS Edge et configuré le DHCP pour orienter tous les clients vers le résolveur local. Après le premier événement majeur, vous constatez que l'utilisation de la bande passante n'a diminué que de 5 %, et l'analyse du trafic montre que de nombreux appareils parviennent encore à résoudre les domaines des régies publicitaires. Quel est le manquement architectural le plus probable et quelle est la solution ?
Conseil : Considérez la manière dont les navigateurs et les systèmes d'exploitation modernes gèrent la résolution DNS par défaut, et ce qui se passe lorsqu'un appareil a un serveur DNS codé en dur.
Voir la réponse type
Il y a deux causes probables. Premièrement, le réseau ne parvient pas à bloquer le trafic DNS over HTTPS (DoH). Les navigateurs modernes tentent d'utiliser le DoH, acheminant les requêtes DNS chiffrées vers des résolveurs externes comme Cloudflare ou Google, contournant ainsi complètement le filtre local. La solution consiste à implémenter des règles de pare-feu de sortie bloquant les adresses IP des fournisseurs de DoH connus. Deuxièmement, certains appareils peuvent avoir des adresses de serveur DNS codées en dur (par exemple, 8.8.8.8) dans leur configuration réseau, contournant les résolveurs attribués par DHCP. La solution consiste à implémenter des règles de pare-feu de sortie bloquant tout trafic sortant TCP/UDP sur le port 53 vers toute destination autre que les résolveurs locaux, forçant ainsi tout le trafic DNS à passer par le filtre, quelle que soit la configuration du client.
Q2. Lors d'un événement majeur, le Captive Portal subit des dépassements de délai d'attente (timeouts) pour les utilisateurs qui tentent de se connecter, alors même que les AP affichent un nombre de clients relativement faible (seulement 40 % de la capacité). Le circuit WAN est à 15 % d'utilisation. Quelle est la cause probable et quels changements architecturaux permettraient d'éviter cela lors du prochain événement ?
Conseil : Pensez à ce qui arrive au trafic des appareils durant la période comprise entre l'association WiFi et l'authentification sur le Captive Portal, et quelle ressource réseau est la plus susceptible d'être épuisée.
Voir la réponse type
La table d'état du pare-feu est probablement saturée par le trafic de fond des appareils qui se sont associés à l'AP mais ne se sont pas encore authentifiés via le Captive Portal. À l'état non authentifié, si le walled garden est trop permissif, le trafic de fond circule librement, générant des milliers d'entrées d'état de connexion par appareil. Avec 40 % des 50 000 places occupées (20 000 appareils), même une courte fenêtre de trafic de fond non restreint peut épuiser la table d'état avant que les utilisateurs ne tentent de s'authentifier. La correction architecturale nécessite deux changements : Premièrement, restreindre le walled garden pour n'autoriser que le trafic minimal requis — DHCP (UDP 67/68), DNS vers le résolveur local uniquement, et HTTP/HTTPS vers l'IP du Captive Portal. Bloquez tout autre trafic jusqu'à ce que l'authentification soit terminée. Deuxièmement, envisagez de déployer une ACL sans état (stateless) dédiée au niveau de l'AP ou du commutateur pour rejeter le trafic de fond à l'état de pré-authentification, l'empêchant ainsi d'atteindre le pare-feu d'état (stateful).
Q3. Une chaîne de vente au détail comptant 500 points de vente souhaite mettre en œuvre un filtrage DNS pour améliorer la fiabilité du système POS et réduire les coûts WAN. Elle a besoin d'une application uniforme des politiques, mais doit également veiller à ce que de nouveaux fournisseurs de logiciels de point de vente puissent être intégrés sans provoquer d'interruptions de service. Quelle approche architecturale convient-il d'adopter et quel processus opérationnel doit l'accompagner ?
Conseil : Considérez la tension entre la gestion centralisée des politiques et l'agilité opérationnelle nécessaire pour soutenir un écosystème technologique de vente au détail dynamique.
Voir la réponse type
Déployez une solution de filtrage DNS gérée dans le cloud avec des redirecteurs locaux sur chaque site. Le plan de gestion centralisé permet de définir des politiques uniformes et de mettre à jour les flux de menaces simultanément sur les 500 sites, tandis que les redirecteurs locaux garantissent une résolution à faible latence et une résilience face à la dégradation de la liaison WAN. Pour l'agilité opérationnelle, mettez en œuvre un processus de gestion des listes d'autorisation à plusieurs niveaux : une liste d'autorisation permanente pour les domaines de traitement des paiements et du POS principal (qui doivent être traités comme une infrastructure soumise au contrôle des changements), une liste d'autorisation temporaire pour l'intégration de nouveaux fournisseurs (avec un cycle d'examen de 90 jours), et un processus de demande en libre-service pour que les directeurs de magasin puissent signaler les faux positifs. De plus, l'exigence PCI DSS en matière de segmentation du réseau impose d'isoler le VLAN du POS de celui du WiFi invité, avec des politiques de filtrage distinctes appliquées à chacun. La politique du WiFi invité peut être agressive ; celle du POS doit être configurée exclusivement en liste d'autorisation, en ne permettant que les domaines de mise à jour logicielle et de traitement des paiements explicitement approuvés.
Continuer la lecture de cette série
Dépannage des redirections de Captive Portal : Résoudre les échecs de connexion WiFi invité
Lorsque les invités se connectent à votre WiFi mais ne peuvent pas accéder à Internet, la cause est presque toujours une mauvaise configuration de la redirection du Captive Portal - et non une défaillance matérielle. Ce guide fournit une référence technique approfondie pour les responsables informatiques, les architectes réseau et les directeurs de la technologie afin de diagnostiquer et de résoudre l'ensemble de la chaîne de défaillances : des sondes de connectivité au niveau du système d'exploitation et des conflits de certificats HSTS jusqu'aux écarts d'autorisation RADIUS et à l'épuisement du DHCP. Il associe chaque mode de défaillance à un correctif concret et montre comment la solution cloud agnostique de Purple élimine ces problèmes sur les déploiements Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme Networks et Fortinet.
Dépannage du WiFi public : résoudre l'erreur « Connecté, pas d'internet » et les échecs de redirection vers la page de connexion
Ce guide de référence technique explique les mécanismes sous-jacents de la détection de Captive Portal et détaille les six principaux modes de défaillance qui empêchent le WiFi invité de se connecter. Il fournit aux responsables informatiques et aux architectes réseau un cadre de dépannage pratique pour résoudre les problèmes de redirection HTTP, les conflits DNS et les défis liés à la randomisation des adresses MAC.
Top 10 des causes d'expiration de délai DHCP sur les réseaux WiFi à haute densité
Ce guide de référence technique identifie les dix principales causes d'expiration de délai DHCP sur les réseaux WiFi à haute densité et propose des stratégies de remédiation concrètes et indépendantes des fournisseurs. Conçu pour les directeurs informatiques, les architectes réseau et les directeurs d'exploitation de sites, il couvre des principes d'ingénierie approfondis, des flux de travail de mise en œuvre étape par étape et des résultats commerciaux mesurables. Apprenez à éliminer les goulots d'étranglement de connexion et à optimiser votre infrastructure sans fil pour offrir une connectivité transparente dans les environnements d'entreprise exigeants.