Pourquoi notre WiFi invité est-il si lent ? Diagnostic de la congestion du réseau
Ce guide diagnostique les causes cachées de la congestion du WiFi invité — télémétrie en arrière-plan, réseaux publicitaires programmatiques et mises à jour automatiques du système d'exploitation — qui consomment collectivement jusqu'à 40 % de la bande passante WiFi publique avant même qu'un invité n'ouvre un navigateur. Il fournit un cadre de mise en œuvre échelonné et indépendant des fournisseurs pour le filtrage DNS et les politiques QoS qui récupèrent cette bande passante, améliorent l'expérience des invités et génèrent un ROI mesurable. Destiné aux directeurs informatiques et aux responsables des opérations dans les secteurs de l'hôtellerie, du commerce de détail, de l'événementiel et des environnements du secteur public.
Écouter ce guide
Voir la transcription du podcast
Résumé Exécutif
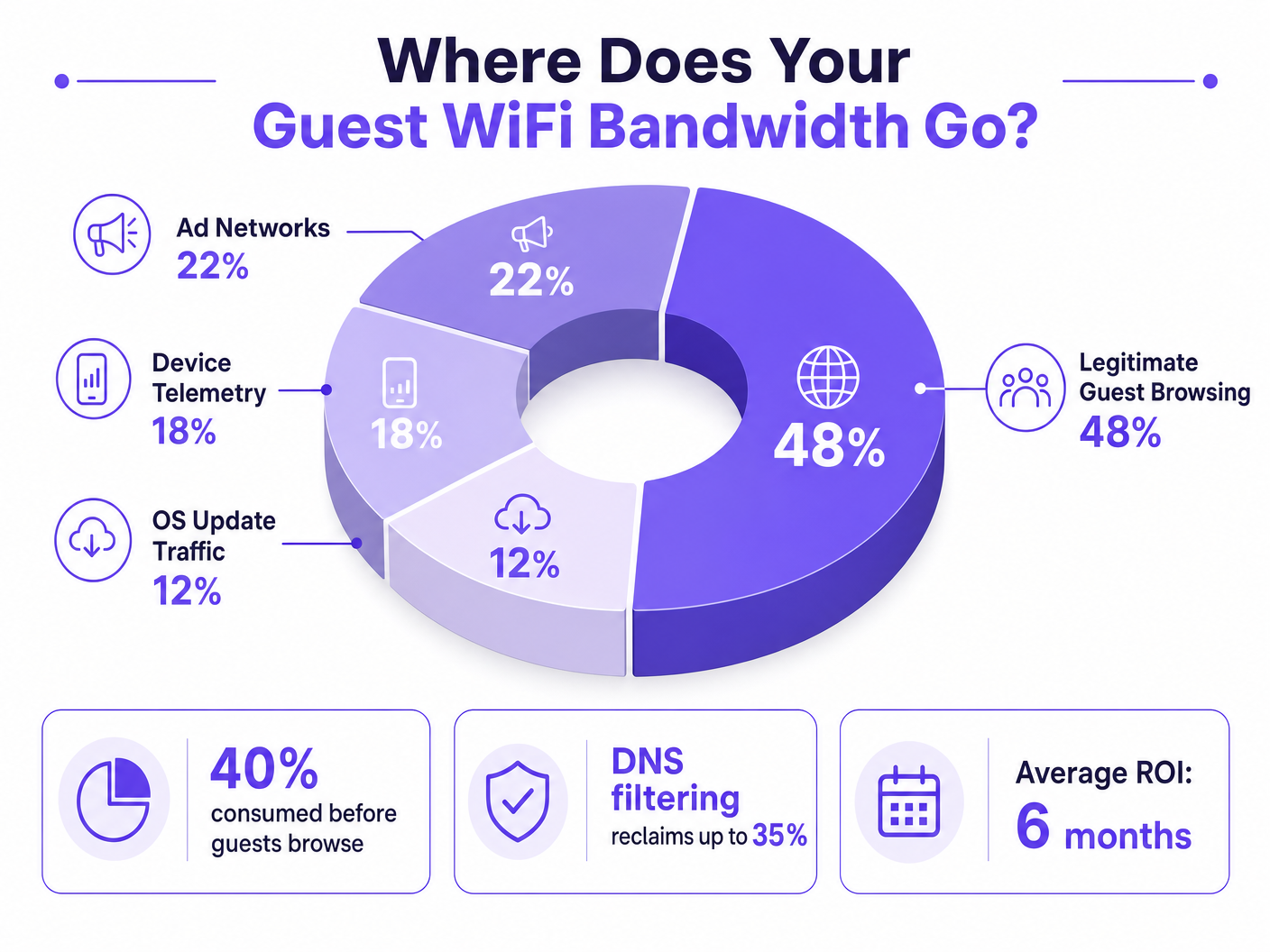
Pour les directeurs informatiques et les responsables des opérations supervisant des lieux à forte densité, garantir une expérience Guest WiFi fiable est une lutte constante contre la congestion du réseau. Alors que les approches traditionnelles se concentrent sur l'augmentation de la bande passante globale ou le déploiement de points d'accès supplémentaires, la cause profonde du faible débit ne réside souvent pas dans le trafic utilisateur légitime, mais dans la couche cachée des données d'arrière-plan. Dans les environnements modernes — des vastes complexes Hospitality aux espaces Retail à forte affluence — jusqu'à 40 % de la bande passante WiFi publique est consommée par la télémétrie des appareils, les réseaux publicitaires programmatiques et les mises à jour automatiques du système d'exploitation avant même qu'un invité n'ouvre un navigateur.
Ce guide de référence technique fournit une méthodologie définitive pour diagnostiquer cette congestion et mettre en œuvre une atténuation stratégique. En déployant le filtrage DNS au niveau du réseau et les Response Policy Zones (RPZ), les architectes de réseaux d'entreprise peuvent récupérer une bande passante significative, réduire la latence et améliorer considérablement l'expérience de l'utilisateur final sans engager de dépenses d'investissement pour des mises à niveau d'infrastructure. Nous explorerons l'architecture technique de ces solutions, des études de cas de mise en œuvre réelles et le ROI mesurable de la récupération de votre réseau.
Approfondissement Technique
L'Anatomie de la Congestion en Arrière-plan
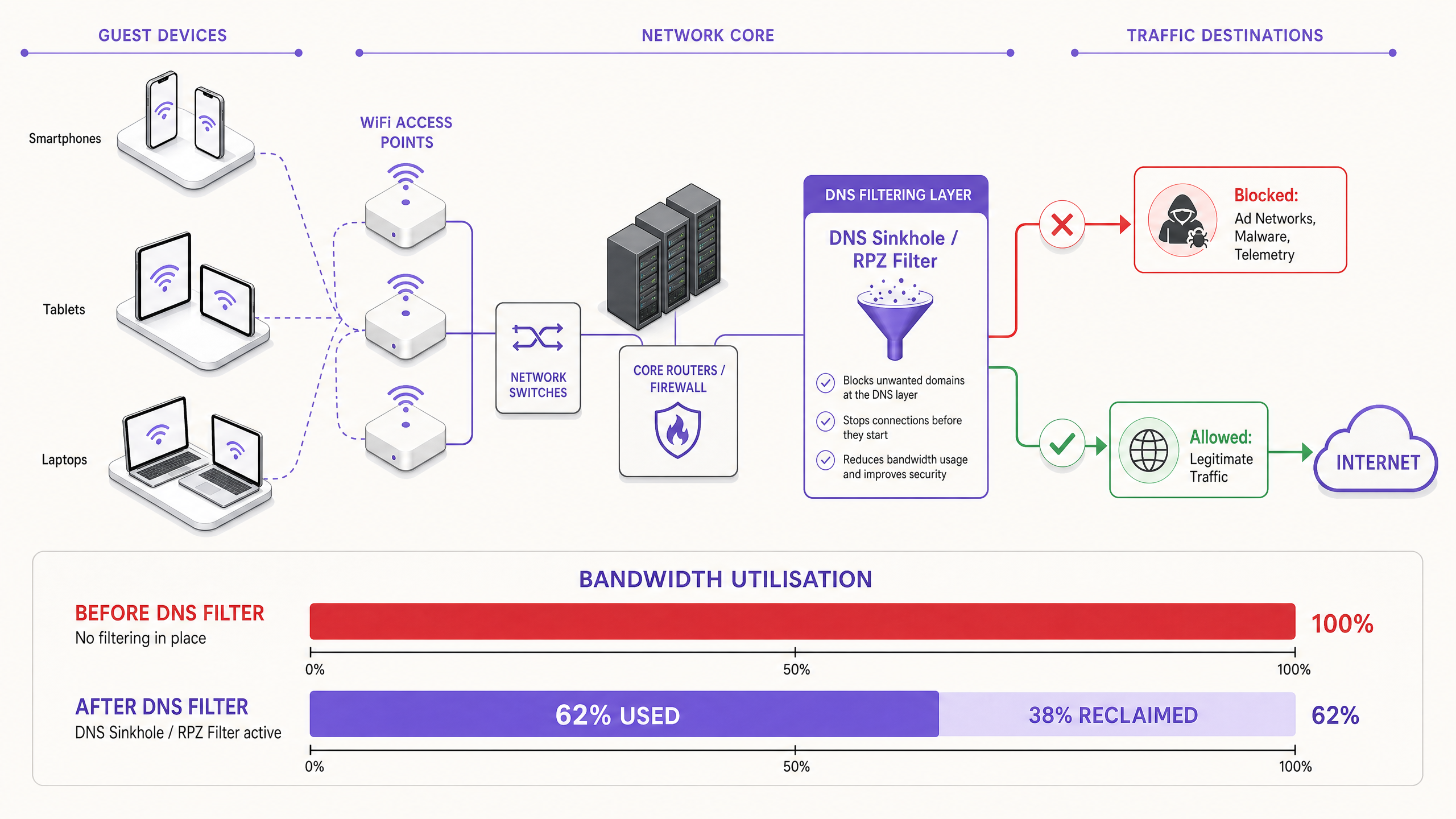
Lorsqu'un appareil invité s'authentifie sur un réseau public, il initie immédiatement un barrage de connexions en arrière-plan. Ces connexions sont principalement générées par trois catégories de trafic qui, globalement, constituent ce que les ingénieurs réseau appellent la charge fantôme — la bande passante consommée par le réseau avant toute activité délibérée de l'invité.
1. Télémétrie et Analyses des Appareils
Les systèmes d'exploitation modernes (iOS, Android, Windows) et les applications installées transmettent constamment des données d'utilisation, des métriques de localisation, des rapports d'erreur et des analyses comportementales à des serveurs distants. Dans un environnement dense tel qu'un hub de Transport ou un centre de conférence, des milliers d'appareils transmettant simultanément de petites mais fréquentes charges utiles de télémétrie peuvent épuiser le temps d'antenne sans fil disponible et submerger les tables NAT. Un seul appareil iOS peut générer plus de 200 requêtes DNS distinctes en arrière-plan au cours des 60 premières secondes de connexion à un réseau non mesuré.
2. Réseaux Publicitaires Programmatiques
De nombreuses applications gratuites s'appuient sur des écosystèmes de publicité programmatique. Dès qu'un appareil détecte une connexion WiFi non mesurée, ces applications commencent à pré-charger des publicités vidéo, des bannières d'affichage haute résolution et des scripts de suivi à partir de plateformes d'échange publicitaire. Ce trafic est à la fois à forte bande passante et sensible à la latence, et il concurrencera agressivement le temps d'antenne avec la navigation légitime des invités. L'analyse des réseaux de lieux publics montre constamment que le trafic publicitaire programmatique représente 15 à 22 % de l'utilisation totale du WAN pendant les heures de pointe.
3. Mises à Jour Automatisées du Système d'Exploitation et des Applications
Sans une gestion appropriée du trafic, les appareils tenteront de télécharger de gros correctifs de système d'exploitation et des mises à jour d'applications dès qu'ils détecteront une connexion WiFi non mesurée. Une seule mise à jour majeure d'iOS peut représenter 3 à 5 Go. Dans un environnement de 500 appareils, un déclenchement de mise à jour simultané — courant lors de la sortie d'une nouvelle version du système d'exploitation — peut saturer même un lien WAN de 1 Gbps en quelques minutes.
Pourquoi les Approches Traditionnelles Échouent
La réponse conventionnelle à la congestion du WiFi invité est d'augmenter la bande passante WAN ou de déployer des points d'accès supplémentaires. Bien que ces deux mesures aient leur place, aucune ne s'attaque à la charge fantôme. L'ajout de bande passante ne fait que fournir plus de capacité au trafic d'arrière-plan à consommer. L'inspection approfondie des paquets (DPI), l'autre outil traditionnel, est de plus en plus inefficace : l'adoption généralisée de TLS 1.3 et du chiffrement de bout en bout signifie que la majorité des charges utiles de trafic sont opaques aux moteurs d'inspection. Vous ne pouvez pas limiter ce que vous ne pouvez pas classer.
Pour une discussion plus large sur la façon dont les fréquences sans fil interagissent avec les déploiements à haute densité, consultez notre guide sur Wi-Fi Frequencies: A Guide to Wi-Fi Frequencies in 2026 .
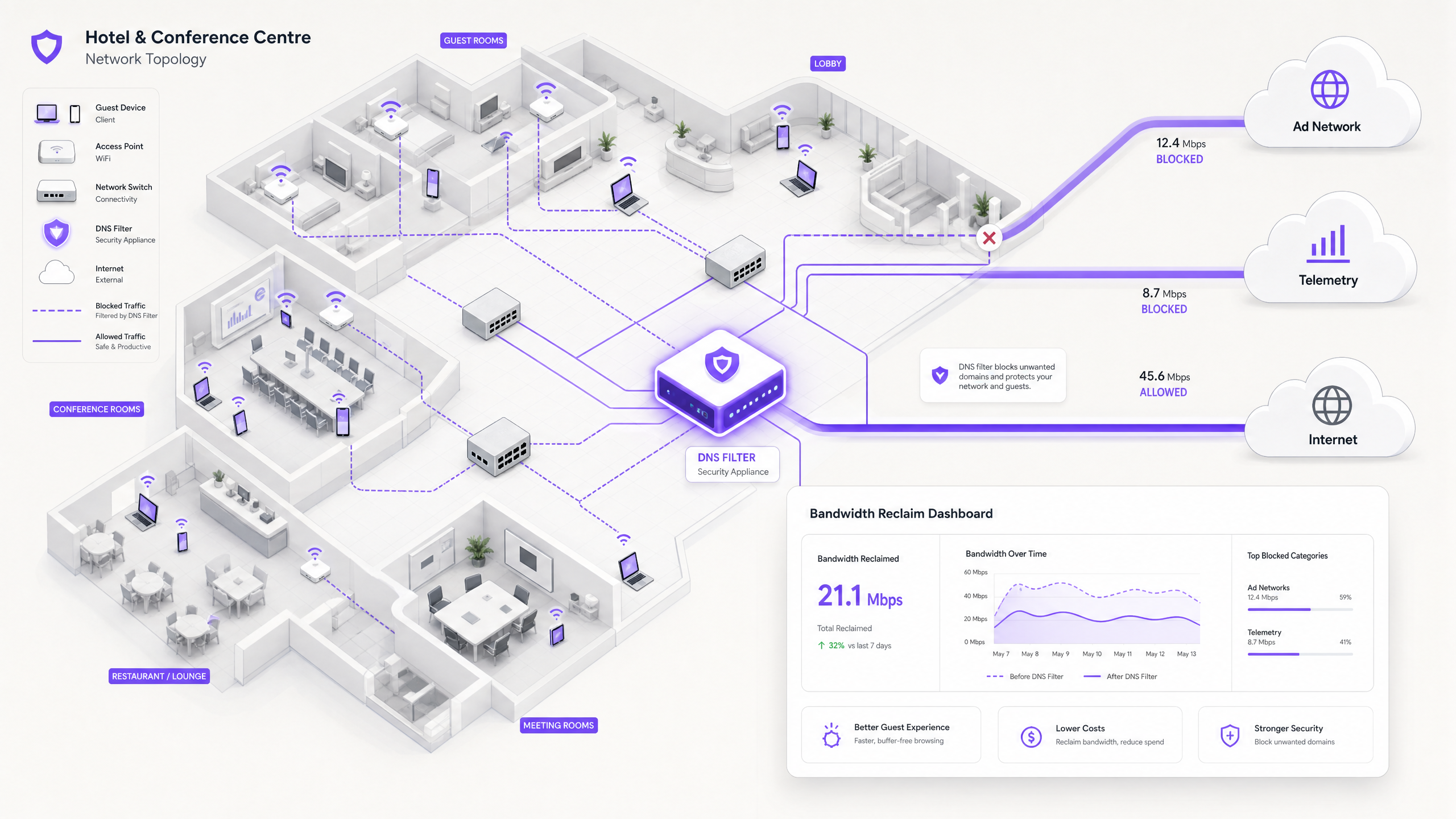
Filtrage DNS : La Contre-mesure Efficace
La solution moderne et évolutive est le filtrage DNS en périphérie du réseau. Plutôt que d'inspecter les charges utiles de trafic, le filtrage DNS opère au niveau de la résolution — empêchant les connexions d'être établies dès le départ.
Lorsqu'un appareil demande l'accès à un réseau publicitaire connu ou à un domaine de télémétrie, le résolveur DNS vérifie la requête par rapport à une Response Policy Zone (RPZ). Si le domaine apparaît dans la liste de blocage, le résolveur renvoie une réponse NXDOMAIN (Domaine Non Existant), ou redirige le trafic vers une adresse IP nulle locale. La connexion est terminée avant que la poignée de main TCP ne se produise, préservant à la fois le temps d'antenne sans fil et la bande passante WAN. Cette approche est peu coûteuse en calcul, évolue linéairement avec la capacité du résolveur et n'est pas affectée par le chiffrement de la charge utile.
La Dimension Sécurité
Le filtrage DNS offre un avantage secondaire significatif : la sécurité. En bloquant les domaines de commande et contrôle (C2) de logiciels malveillants connus, l'infrastructure de phishing et les réseaux de livraison de kits d'exploitation au niveau DNS, le réseau invité devient considérablement plus sécurisé.sible. Ceci est directement pertinent pour les obligations de conformité dans le cadre de référentiels tels que PCI DSS (qui exige la segmentation et la surveillance du réseau pour les environnements de données de titulaires de carte) et le GDPR (qui impose des mesures techniques appropriées pour protéger les données personnelles). Pour un traitement détaillé des exigences en matière de piste d'audit dans ce contexte, voir Expliquer ce qu'est une piste d'audit pour la sécurité informatique en 2026 .
Pour les organisations gérant des environnements éducatifs où le blocage des publicités sert également une fonction de protection, les principes abordés dans Minimiser les distractions des étudiants avec le blocage des publicités au niveau du réseau sont directement applicables.
Guide d'implémentation
Le déploiement d'une architecture de filtrage DNS robuste nécessite une planification minutieuse pour éviter de perturber les services légitimes des invités. L'implémentation doit suivre une approche par phases.
Phase 1 : Évaluation de la ligne de base et visibilité
Avant d'implémenter tout blocage, établissez une ligne de base des modèles de trafic actuels. Utilisez WiFi Analytics pour identifier les domaines et catégories les plus consommateurs de bande passante sur une période représentative de 7 à 14 jours. Cette phase d'audit est essentielle pour comprendre le profil de trafic spécifique de votre site et pour élaborer l'analyse de rentabilisation de l'investissement. Les métriques clés à capturer incluent :
| Métrique | Ligne de base cible | Notes |
|---|---|---|
| Top 20 des domaines DNS par volume de requêtes | Liste complète | Identifier les domaines de télémétrie et de publicité |
| Utilisation WAN par catégorie | % de répartition | Quantifier la charge fantôme |
| Nombre maximal d'appareils simultanés | Nombre | Dimensionner l'infrastructure du résolveur |
| Taux d'échec des requêtes DNS | < 0,1 % | Établir une référence avant le déploiement |
Phase 2 : Déploiement RPZ échelonné
Commencez par déployer le RPZ en mode journalisation uniquement. Cela vous permet de vérifier l'exactitude de vos listes de blocage sans impacter l'expérience utilisateur. Concentrez-vous d'abord sur les catégories à haute confiance :
- Domaines de logiciels malveillants connus et de C2 : Bénéfice de sécurité immédiat avec un risque quasi nul de faux positifs. Utilisez des flux de renseignements sur les menaces provenant de fournisseurs réputés.
- Réseaux publicitaires programmatiques à forte bande passante : Ciblez les principales plateformes d'échange de publicités vidéo. Celles-ci sont bien documentées et peu susceptibles d'héberger du contenu légitime.
- Points de terminaison de télémétrie agressifs : Bloquez les domaines de suivi non essentiels. Maintenez une liste d'autorisation minutieuse pour les domaines requis pour les flux d'authentification du Captive Portal.
Une fois que le mode journalisation uniquement confirme des taux de faux positifs acceptables (cible < 0,5 % des requêtes), passez en mode d'application.
Phase 3 : Façonnage du trafic et intégration QoS
Pour le trafic qui ne peut pas être bloqué purement et simplement (par exemple, les mises à jour du système d'exploitation d'Apple, Microsoft et Google), implémentez des politiques de Qualité de Service (QoS). Limitez le débit des serveurs de mise à jour à un plafond défini — généralement 10 à 15 % de la capacité WAN totale — en veillant à ce que le trafic interactif des invités (navigation web, VoIP, vidéoconférence) reçoive une mise en file d'attente prioritaire. Ceci est particulièrement important pour les environnements Santé où le personnel clinique peut partager un segment de réseau avec les invités.
Pour des conseils sur l'optimisation des environnements réseau plus larges, y compris les déploiements de bureaux et à usage mixte, voir Wi-Fi de bureau : Optimisez votre réseau Wi-Fi de bureau moderne .
Bonnes pratiques
Maintenez des listes d'autorisation explicites pour les services critiques. Assurez-vous que les domaines essentiels pour l'authentification du Captive Portal, les passerelles de paiement (conformité PCI DSS) et les opérations principales du site sont explicitement autorisés. Une liste de blocage mal configurée qui interrompt le flux de connexion générera une charge de support immédiate et significative.
Communiquez la politique de manière transparente. Vos Conditions Générales de Service doivent stipuler que le trafic réseau est géré pour assurer une expérience de haute qualité à tous les utilisateurs. C'est à la fois une bonne pratique juridique en vertu du GDPR et une mesure raisonnable de gestion des attentes pour les invités.
Automatisez les mises à jour des listes de blocage. Le paysage des réseaux publicitaires et des domaines de télémétrie évolue constamment. Les flux de renseignements sur les menaces et les listes RPZ doivent être mis à jour dynamiquement — idéalement sur un cycle de moins de 24 heures — pour rester efficaces.
Traitez l'évasion DNS de manière proactive. Implémentez des règles de pare-feu pour intercepter et rediriger tout le trafic sortant du port 53 (UDP et TCP) vers le résolveur local. Cela empêche les clients de contourner le filtrage en codant en dur des serveurs DNS externes.
Préparez-vous au DNS sur HTTPS (DoH). À mesure que l'adoption du DoH augmente, les clients peuvent acheminer les requêtes DNS via HTTPS pour contourner entièrement les résolveurs locaux. Évaluez s'il faut bloquer les fournisseurs DoH connus (par exemple, dns.google, cloudflare-dns.com) ou déployer un proxy DoH transparent qui applique la politique locale.
Alignez-vous avec IEEE 802.1X et WPA3. Assurez-vous que votre architecture de filtrage DNS est compatible avec votre cadre d'authentification. Dans les environnements utilisant IEEE 802.1X avec une authentification basée sur RADIUS, les politiques de filtrage DNS peuvent être appliquées par VLAN ou par groupe d'utilisateurs, permettant un contrôle granulaire.
Dépannage et atténuation des risques
Modes de défaillance courants
| Mode de défaillance | Symptôme | Atténuation |
|---|---|---|
| Sur-blocage (collision CDN) | Pages web cassées, images manquantes | Listes de blocage granulaires ; processus rapide de liste d'autorisation |
| Évasion DNS (résolveurs codés en dur) | Filtrage contourné par des applications spécifiques | Règles de redirection de pare-feu pour le port 53 |
| Contournement DoH | Filtrage contourné par les navigateurs modernes | Bloquer les fournisseurs DoH connus ou déployer un proxy DoH |
| Goulot d'étranglement des performances du résolveur | Latence DNS accrue pour tous les clients | Mettre à l'échelle l'infrastructure du résolveur ; implémenter l'anycast |
| Rupture du Captive Portal | Les invités ne peuvent pas s'authentifier | Liste d'autorisation explicite pour les domaines du portail et les points de terminaison de détection du système d'exploitation |
| Listes de blocage obsolètes | Nouveaux domaines publicitaires non bloqués | Automatiser les mises à jour des flux ; surveiller les journaux de requêtes pour les nouveaux domaines à volume élevé |
Réponse aux incidents de sécurité
Si un appareil invité est identifié comme communiquant avec un domaine C2 de logiciel malveillant connu (visible dans les journaux de requêtes DNS), le RPZ bloquera automatiquement toute communication ultérieure. Assurez-vous que votre processus de réponse aux incidents inclut un flux de travail pour l'examen de ces événements, car ils peuvent indiquer un appareil compromis nécessitant une isolation du VLAN invité.
ROI et Impact Commercial
La mise en œuvre du filtrage DNS au niveau du réseau offre des résultats commerciaux mesurables et quantifiables sur plusieurs dimensions.
Récupération de la bande passante et report des dépenses d'investissement (CapEx). Les établissements récupèrent généralement 20 à 40 % de leur bande passante WAN totale. Cela se traduit directement par des économies en reportant la nécessité de coûteuses mises à niveau de circuits. Pour un établissement payant actuellement une ligne louée de 500 Mbps, récupérer 30 % de capacité équivaut à obtenir 150 Mbps de débit effectif sans coût additionnel.
Amélioration de la satisfaction des invités et du NPS. En éliminant la congestion de fond, la vitesse perçue et la fiabilité du WiFi invité s'améliorent considérablement. Une latence réduite et un débit constant entraînent des scores Net Promoter plus élevés et moins d'escalades de support opérationnel.
Posture de sécurité et de conformité renforcée. Le blocage des domaines de logiciels malveillants et de phishing au niveau DNS réduit considérablement le risque de violation de sécurité provenant du réseau invité. Cela soutient directement la conformité aux exigences de segmentation réseau PCI DSS et à l'obligation du GDPR de mettre en œuvre des mesures de sécurité techniques appropriées.
Efficacité opérationnelle. Le filtrage DNS automatisé réduit la charge de travail manuelle des équipes d'opérations réseau. Plutôt que de répondre de manière réactive aux événements de congestion, le réseau gère de manière proactive son propre profil de trafic.
| Résultat | Plage typique | Méthode de mesure |
|---|---|---|
| Bande passante récupérée | 20–40 % de la capacité WAN | Surveillance de l'utilisation WAN avant/après |
| Taux de blocage des requêtes DNS | 15–35 % de toutes les requêtes | Journaux de requêtes du résolveur |
| Amélioration de la satisfaction des invités | +8–15 points NPS | Enquêtes post-séjour/post-visite |
| Report des CapEx | 1–3 ans sur la mise à niveau du circuit | Modélisation des coûts |
| Réduction des incidents de sécurité | 40–60 % de détections C2 en moins | Corrélation SIEM |
En traitant le réseau non pas comme un simple tuyau, mais comme une passerelle intelligente et filtrée, les leaders informatiques peuvent offrir une expérience de connectivité supérieure, sécurisée et rentable — une expérience qui évolue avec la croissance de l'établissement sans investissement proportionnel dans l'infrastructure.
Définitions clés
Response Policy Zone (RPZ)
A mechanism in DNS servers that allows the modification of DNS responses based on a defined policy. When a queried domain matches an entry in the RPZ, the resolver can return a synthetic response (e.g., NXDOMAIN or a sinkhole IP) instead of the real answer.
The primary technical mechanism for implementing network-wide DNS filtering. IT teams configure RPZs on their internal resolvers to block ad networks, malware domains, and telemetry endpoints without requiring client-side software.
Deep Packet Inspection (DPI)
A form of network packet filtering that examines the data payload of a packet as it passes an inspection point, searching for protocol non-compliance, specific content, or defined criteria.
Traditionally used for traffic classification and shaping. Increasingly limited by the widespread adoption of TLS 1.3 end-to-end encryption, which renders payloads opaque. DNS filtering is the preferred alternative for encrypted traffic environments.
NXDOMAIN
A DNS response code (RCODE 3) indicating that the queried domain name does not exist in the DNS namespace.
Returned by a filtering DNS resolver to intentionally block a connection to an unwanted domain. The client application receives this response and abandons the connection attempt, preventing any bandwidth from being consumed.
DNS over HTTPS (DoH)
A protocol for performing DNS resolution via the HTTPS protocol (RFC 8484), encrypting DNS queries and responses between the client and a DoH-capable resolver.
Can bypass local network DNS filtering if clients are configured to use external DoH providers. Network administrators must implement firewall rules or proxy DoH traffic to enforce local RPZ policies.
Quality of Service (QoS)
A set of network mechanisms that control traffic prioritisation, rate-limiting, and queuing to ensure the performance of critical applications.
Used alongside DNS filtering to manage legitimate but high-bandwidth traffic (e.g., OS updates) that cannot be blocked. QoS ensures that interactive guest traffic receives priority over background bulk transfers.
Telemetry
The automated collection and transmission of operational data from devices to remote servers for monitoring, analytics, and diagnostics.
In the context of guest WiFi, device telemetry from mobile operating systems and applications can silently consume 15–20% of available bandwidth. It is a primary target for DNS filtering in public network deployments.
DNS Sinkholing
A technique in which a DNS server is configured to return a false IP address (typically a local null address) for specific domains, redirecting traffic away from its intended destination.
Used to neutralise malware C2 traffic and aggressively block high-bandwidth ad networks. More definitive than NXDOMAIN responses, as it allows the sinkhole server to log connection attempts for security analysis.
Airtime Fairness
A wireless network feature that allocates equal access to the wireless medium across all connected clients, regardless of their individual data rates.
Critical in high-density environments. Without airtime fairness, a single slow device (e.g., an older 802.11g client) can disproportionately consume airtime, degrading throughput for all other clients. Background telemetry traffic from many devices exacerbates this effect.
Phantom Load
Bandwidth consumed by automated background processes on connected devices before any deliberate user activity occurs.
The collective term for telemetry, ad network pre-fetching, and OS update traffic. Understanding and quantifying the phantom load is the first step in any guest WiFi congestion diagnosis.
Exemples concrets
A 400-room resort hotel is experiencing severe network congestion every evening between 7:00 PM and 10:00 PM. The 1 Gbps WAN link is saturated, and guests are complaining about slow streaming and dropped VoIP calls. The IT Director needs to identify the root cause and implement a solution without upgrading the circuit.
Step 1 — Traffic Analysis: Deploy a network flow analyser (NetFlow/IPFIX) on the core router and run it for 5 days across peak and off-peak periods. Correlate with DNS query logs from the existing resolver. The analysis reveals that 35% of evening traffic is destined for known programmatic video ad networks (DoubleClick, AppNexus) and automated app update servers (Apple Software Update, Google Play). Legitimate guest browsing accounts for only 52% of total traffic.
Step 2 — DNS Filtering Deployment: Configure the core firewall to redirect all guest VLAN DNS queries (UDP/TCP port 53) to a locally hosted RPZ-enabled resolver. Import a curated blocklist covering the identified ad networks and telemetry domains. Run in log-only mode for 48 hours to validate false positive rates.
Step 3 — Policy Enforcement: After validating a false positive rate below 0.3%, switch to enforcement mode. Simultaneously, implement a QoS policy that rate-limits Apple and Google update servers to a combined ceiling of 80 Mbps during the 6 PM–11 PM window.
Step 4 — Validation: Monitor WAN utilisation over the following 7 days. Peak utilisation drops from 98% to 61%, resolving guest complaints. The hotel defers a planned circuit upgrade by an estimated 18 months.
A large conference centre is hosting a technology summit with 5,000 attendees. During the keynote, the WiFi network becomes completely unusable. Post-incident analysis shows that thousands of devices simultaneously attempted to download a major iOS update that was released that morning.
Immediate Mitigation (Day of Event): The network operations team identifies the surge via real-time DNS query monitoring. They immediately sinkhole the specific Apple software update domains (mesu.apple.com, appldnld.apple.com, updates.cdn-apple.com) at the DNS layer. Within 4 minutes, WAN utilisation drops from 99% to 68%, and the network stabilises.
Short-Term Fix (Same Event): A QoS policy is applied to rate-limit all remaining update traffic to 50 Mbps for the duration of the event.
Long-Term Strategy (Post-Event): The network team implements a dynamic QoS policy that automatically activates when total WAN utilisation exceeds 75%, throttling known update servers to 10% of total capacity. A pre-event checklist is created that includes temporarily sinkholes of major update domains during the 2 hours before and after high-profile sessions. The team also subscribes to Apple's and Microsoft's update release notification feeds to anticipate future surge events.
Questions d'entraînement
Q1. You are the IT Manager for a national retail chain. After deploying a DNS filtering solution across 50 stores, several store managers report that the captive portal login page is failing to load for guests. The support team is receiving high call volumes. What is the most likely cause, and what is the immediate remediation step?
Conseil : Consider the full dependency chain of a modern captive portal authentication flow, including OS-level captive portal detection mechanisms.
Voir la réponse type
The most likely cause is over-blocking. The DNS filter is blocking a domain required for the captive portal to function. Modern mobile operating systems use specific domains to detect captive portals (e.g., captive.apple.com for iOS, connectivitycheck.gstatic.com for Android). If these are blocked, the OS will not trigger the captive portal browser, and the guest will see no login prompt. Additionally, the portal itself may depend on a CDN or third-party authentication provider (e.g., social login via Facebook or Google) whose domains are inadvertently blocked.
Immediate remediation: Review the DNS query logs for NXDOMAIN responses originating from the guest subnet during the authentication phase. Identify all blocked domains that are queried before a successful login. Add these domains to the global allow-list. Implement a standard allow-list template for captive portal deployments that includes all major OS detection endpoints and common authentication provider domains.
Q2. A stadium network architect notices that despite implementing aggressive DNS filtering, WAN utilisation remains critically high during matches. Further investigation reveals a sustained high volume of UDP port 443 traffic that does not correlate with any blocked domains in the DNS logs. What is happening, and how should it be addressed?
Conseil : Consider modern transport protocols and how they interact with DNS-layer controls.
Voir la réponse type
The high volume of UDP 443 traffic indicates the use of QUIC (HTTP/3). QUIC is a UDP-based transport protocol used by major platforms (Google, Meta, YouTube) that bypasses traditional TCP-based proxies and DPI engines. More critically, clients using QUIC may also be using DNS over HTTPS (DoH) to resolve domains, completely bypassing the local RPZ resolver and rendering DNS filtering ineffective for those clients.
To address this: First, implement firewall rules to block outbound DoH traffic to known public DoH providers (Google, Cloudflare, NextDNS) on TCP/UDP port 443 by destination IP, forcing clients to fall back to the local resolver. Second, evaluate blocking outbound UDP 443 entirely (or rate-limiting it aggressively) to force QUIC clients to fall back to TCP-based HTTP/2, which is subject to existing traffic management policies. Third, review whether a transparent DoH proxy can be deployed to intercept and inspect DoH queries while enforcing local RPZ policies.
Q3. You are designing a QoS policy for a large public hospital's guest WiFi network. The network is shared between patient entertainment devices, visitor personal devices, and a small number of clinical staff using VoIP softphones on their personal mobiles. Prioritise the following traffic types: VoIP (SIP/RTP), Guest Web Browsing (HTTP/HTTPS), Windows/iOS Updates, and Streaming Video (Netflix/YouTube).
Conseil : Consider both latency sensitivity and the business/clinical impact of each traffic type. Also consider the regulatory context of a healthcare environment.
Voir la réponse type
Priority 1 — VoIP (SIP/RTP): Strict Priority Queuing (Expedited Forwarding, DSCP EF). VoIP is highly sensitive to latency (target < 150ms one-way) and jitter (target < 30ms). Packet loss above 1% causes audible degradation. In a clinical context, a dropped call could have patient safety implications.
Priority 2 — Guest Web Browsing (HTTP/HTTPS): Assured Forwarding (AF31). This is the primary expected use case for both patients and visitors. It requires reasonable responsiveness but is tolerant of moderate latency.
Priority 3 — Streaming Video (Netflix/YouTube): Rate-limited per client (e.g., 3–5 Mbps cap) with Assured Forwarding (AF21). While important for patient experience during long stays, uncapped streaming will saturate the link. A per-client cap ensures equitable access. Consider time-of-day policies that relax limits during off-peak hours.
Priority 4 — OS/App Updates (Scavenger Class, DSCP CS1): Lowest priority, best-effort queuing, with an aggregate rate limit (e.g., 50 Mbps total across all update traffic). These are background tasks with no latency sensitivity. They should only consume spare capacity. In a healthcare environment, also consider whether the guest network is fully isolated from clinical systems — if not, update traffic management becomes a security concern as well as a bandwidth one.