Fluxo de Visitantes Preditivo e IA: Previsão de Padrões de Visitantes a partir de Dados de WiFi
Este guia de referência técnica abrangente detalha como equipes de TI empresariais e operadores de locais podem aproveitar dados derivados de WiFi e aprendizado de máquina para prever o fluxo de visitantes com precisão. Ele aborda a arquitetura de dados, seleção de modelos de ML, considerações de privacidade e estratégias de implementação no mundo real para transformar painéis reativos em inteligência preditiva.
🎧 Ouça este Guia
Ver Transcrição

Resumo Executivo
Para equipes de TI empresariais e diretores de operações de locais, a infraestrutura de WiFi existente representa um ativo operacional inexplorado. Enquanto painéis reativos fornecem contexto histórico, o verdadeiro valor dos dados espaciais reside na análise preditiva de fluxo de visitantes. Ao aplicar modelos de aprendizado de máquina a solicitações de sondagem WiFi anonimizadas e eventos de associação, as organizações podem prever padrões de visitantes com precisão suficiente para impulsionar a alocação de pessoal, o reabastecimento de estoque e gatilhos de marketing.
Este guia fornece um plano técnico e neutro em relação a fornecedores para a implementação de análises preditivas de visitantes. Ele vai além da teoria acadêmica para abordar as realidades práticas da randomização de MAC, pipelines de dados e desvio de modelo. Seja você gerenciando um hotel de 200 quartos, uma grande propriedade de varejo ou uma instalação do setor público, esta referência descreve os requisitos arquitetônicos e os fluxos de trabalho operacionais necessários para fazer a transição de relatórios históricos para inteligência preditiva.
Análise Técnica Aprofundada: A Arquitetura do Pipeline de Dados
A base de qualquer iniciativa de previsão de fluxo de visitantes por IA é o pipeline de ingestão e pré-processamento de dados. A precisão do modelo de aprendizado de máquina subsequente depende inteiramente da qualidade dos dados espaciais extraídos da rede WiFi.
Ingestão de Dados e Processamento de Sinal
Redes WiFi empresariais modernas, como as implantadas em ambientes de Varejo ou Hotelaria , coletam continuamente solicitações de sondagem de qualquer dispositivo habilitado para Wi-Fi dentro do alcance.
Esses eventos carregam metadados críticos, incluindo um carimbo de data/hora, um Indicador de Força de Sinal Recebido (RSSI) e um identificador de dispositivo.
No entanto, a implementação generalizada da randomização de endereço MAC por grandes sistemas operacionais móveis alterou fundamentalmente o rastreamento de dispositivos. Pipelines modernos de análise preditiva não dependem de identidade persistente de dispositivo. Em vez disso, eles utilizam contagem baseada em sessão e distribuições agregadas de tempo de permanência. Dados anonimizados e agregados são totalmente compatíveis com os padrões GDPR e PCI DSS, ao mesmo tempo em que fornecem o volume necessário para uma previsão precisa.
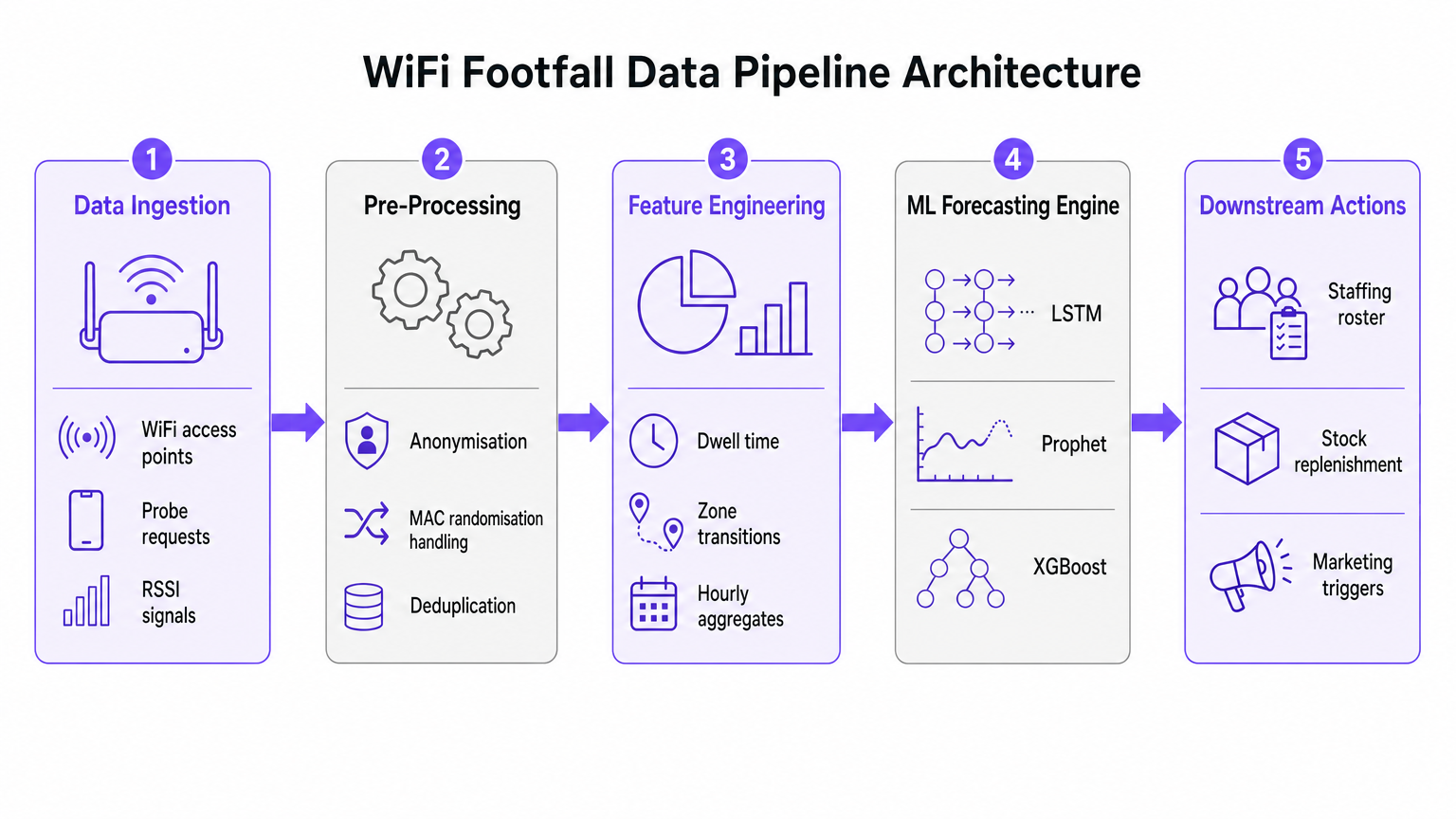
Engenharia de Recursos para Aprendizado de Máquina
Solicitações de sondagem brutas não são adequadas para ingestão direta em modelos de previsão. A camada de pré-processamento deve lidar com a deduplicação, pois um único dispositivo pode gerar inúmeras solicitações por minuto. Uma vez deduplicados e anonimizados, o estágio de engenharia de recursos extrai as métricas que alimentam o motor de previsão de ML.
Os principais recursos projetados incluem:
- Contagens Horárias de Visitantes: Agregadas por zona com base na triangulação RSSI.
- Distribuições de Tempo de Permanência: A duração em que os dispositivos permanecem dentro de áreas de cobertura específicas.
- Transições de Zona: Os padrões de movimento entre diferentes áreas de um local.
- Covariáveis Externas: Dados contextuais cruciais, como dia da semana, feriados, eventos locais e condições climáticas.
Guia de Implementação: Selecionando o Modelo de ML Correto
A seleção do modelo de aprendizado de máquina apropriado é ditada pelo volume de dados históricos disponíveis e pelas decisões operacionais específicas que a previsão se destina a apoiar. Optar por redes neurais complexas sem dados suficientes é um modo de falha comum em implantações empresariais.

Abordagens Estatísticas: SARIMA
Para locais com pelo menos seis meses de dados horários limpos e padrões sazonais relativamente estáveis, o modelo Seasonal AutoRegressive Integrated Moving Average (SARIMA) fornece uma linha de base robusta. O SARIMA é altamente eficaz para capturar ritmos semanais em ambientes como varejo voltado para passageiros ou escritórios corporativos. Ele geralmente entrega um Erro Percentual Absoluto Médio (MAPE) na faixa de 8-12% para um horizonte de previsão de 7 dias, o que é suficiente para a otimização básica da equipe.
Lidando com Picos Irregulares: Prophet
Quando os dados históricos se estendem por doze meses ou mais, e o local experimenta picos irregulares devido a feriados ou eventos promocionais, o modelo Prophet do Facebook é um forte candidato. O Prophet lida nativamente com pontos de mudança e efeitos de feriados. Além disso, sua natureza interpretável permite que as equipes de operações compreendam os fatores subjacentes de um aumento previsto, tornando-o altamente adequado para centros de Transporte e grandes locais públicos.
Ambientes Ricos em Recursos: Gradient Boosting (XGBoost)
Em ambientes de varejo complexos, onde a previsão deve incorporar calendários promocionais, atividade da concorrência e dados de uma plataforma de Guest WiFi , modelos de gradient boosting como o XGBoost superam consistentemente as abordagens puramente estatísticas. Com doze meses de dados de treinamento e engenharia de recursos sofisticada, o XGBoost pode atingir um MAPE de 3-6%. Este nível de precisão permite gatilhos automatizados para sistemas de cadeia de suprimentos e reabastecimento de estoque.
Aprendizado Profundo: Redes LSTM
Redes neurais Long Short-Term Memory (LSTM) são poderosas para capturar dependências temporais de longo alcance. No entanto, elas exigem um mínimo de dezoito meses de dados de alta qualidade para treinar de forma confiável e são computacionalmente caras para manter. Os modelos LSTM são mais bem reservados para implantações em larga escala, como cadeias de varejo multi-siteoperadores de arenas ou estádios, onde os recursos de engenharia estão disponíveis para gerenciar a infraestrutura.
Melhores Práticas para Implantação
A implantação bem-sucedida de análises preditivas de fluxo de pessoas exige adesão rigorosa às melhores práticas da indústria, indo além do algoritmo para focar na infraestrutura subjacente e na integração operacional.
Calibração da Infraestrutura
Uma distinção crítica deve ser feita entre uma contagem de visitantes conectados via WiFi e uma contagem real de fluxo de pessoas. As taxas de captura variam significativamente dependendo do tipo de local. Um restaurante de serviço rápido pode ter uma taxa de captura de 30%, enquanto o lobby de um hotel que oferece uma experiência de WiFi Analytics perfeita pode exceder 80%.
Para estabelecer precisão absoluta, as contagens derivadas do WiFi devem ser calibradas em relação a uma fonte de verdade, como contadores de porta físicos ou volumes de transações de Ponto de Venda (POS). Embora os padrões relativos identificados pelos dados de WiFi sejam imediatamente confiáveis, a previsão numérica absoluta requer esta camada de calibração.
Densidade e Posicionamento de Access Points
Para granularidade de fluxo de pessoas em nível de zona, a densidade de access points é primordial. Os access points devem ser implantados a não mais de 15 metros de distância, garantindo células de cobertura sobrepostas. Essa densidade é necessária não apenas para o throughput (por exemplo, desempenho IEEE 802.11ax), mas para a precisão de triangulação necessária para a camada de posicionamento. Para mais detalhes técnicos sobre tecnologias de posicionamento, consulte o Indoor Positioning System: UWB, BLE, & WiFi Guide .
Solução de Problemas e Mitigação de Riscos
O risco mais significativo para as implantações de análises preditivas é o model drift. O comportamento do visitante não é estático; ele muda em resposta a fatores macroeconômicos, mudanças na infraestrutura local ou reformas do local.
Gerenciando o Model Drift
Modelos treinados com dados pré-mudança irão inevitavelmente degradar o desempenho. Para mitigar esse risco, as equipes de IT devem implementar uma cadência de retreinamento estruturada. Para a maioria dos locais corporativos, um ciclo de retreinamento mensal é suficiente. No entanto, em ambientes de alta volatilidade, como espaços para eventos ou centros de transporte, o retreinamento semanal pode ser necessário para manter as tolerâncias de precisão.
Privacidade e Conformidade
A mitigação de riscos também se estende à privacidade dos dados. Quando devidamente anonimizados e agregados, os dados de fluxo de pessoas derivados do WiFi não constituem dados pessoais sob o GDPR. No entanto, a conformidade exige que o processo de anonimização ocorra na borda ou imediatamente após a ingestão, antes que os dados entrem na camada de armazenamento persistente usada para o treinamento do modelo.
ROI e Impacto nos Negócios
A medida final de sucesso para uma implantação preditiva de fluxo de pessoas é sua integração nos fluxos de trabalho operacionais. A previsão deve estar conectada a uma ação downstream específica.
Resultados Demonstráveis
Organizações que implementam com sucesso esses modelos geralmente veem um retorno sobre o investimento no primeiro trimestre de implantação. Os principais impactos nos negócios incluem:
- Eficiência de Pessoal: Alinhar as escalas de pessoal com os picos de demanda previstos, reduzindo custos de mão de obra desnecessários e garantindo cobertura adequada durante os aumentos.
- Otimização de Estoque: Integrar previsões com sistemas de cadeia de suprimentos para acionar o reabastecimento just-in-time, reduzindo o desperdício de produtos perecíveis e evitando rupturas de estoque.
- Gatilhos de Marketing: Cronometrar campanhas promocionais ou atualizações de sinalização digital para coincidir com períodos previstos de alta permanência. Para implementações avançadas envolvendo IA generativa, consulte Generative AI for Captive Portal Copy and Creative .
Ao tratar a rede WiFi como um conjunto estratégico de sensores e aplicar práticas robustas de machine learning, as equipes de IT corporativas podem entregar valor operacional mensurável muito além da conectividade básica.
Termos-Chave e Definições
MAC Randomisation
A privacy feature in modern mobile OSs that periodically changes the device's MAC address to prevent long-term tracking.
Forces IT teams to rely on session-based counting and aggregated analytics rather than persistent individual device tracking for footfall forecasting.
RSSI (Received Signal Strength Indicator)
A measurement of the power present in a received radio signal.
Used in the data pipeline to triangulate device position and determine zone transitions, forming the basis of spatial analytics.
Feature Engineering
The process of transforming raw data (like probe requests) into meaningful inputs (features) that a machine learning model can understand.
The critical step where IT teams convert raw network logs into actionable metrics like 'hourly dwell time' or 'zone entry rate'.
Model Drift
The degradation of a machine learning model's predictive accuracy over time due to changes in the underlying data patterns.
Requires IT teams to implement a structured retraining schedule to ensure forecasts remain reliable as venue layouts or visitor behaviors change.
SARIMA
Seasonal AutoRegressive Integrated Moving Average; a statistical model used for forecasting time series data with recurring patterns.
The recommended baseline model for venues with stable weekly rhythms and limited historical data (6-12 months).
Prophet
An open-source forecasting tool developed by Facebook, designed to handle time series data with strong seasonal effects and irregular holidays.
Ideal for event spaces or hospitality venues where irregular spikes (like concerts or bank holidays) disrupt standard seasonal patterns.
XGBoost
Extreme Gradient Boosting; a highly efficient and scalable machine learning algorithm that excels with structured, multi-variable data.
The model of choice for complex retail environments where forecasts must incorporate numerous external variables like weather and promotions.
MAPE (Mean Absolute Percentage Error)
A statistical measure of how accurate a forecast system is, representing the average absolute percent error for each time period.
The primary metric IT directors should use to evaluate model performance and set acceptable accuracy tolerances for operational decisions.
Estudos de Caso
A 200-room hotel with a large conference facility needs to optimize its food and beverage staffing. The current approach relies on historical averages, resulting in understaffing during unexpected conference breakouts and overstaffing on quiet afternoons. They have 14 months of clean WiFi data but limited IT resources.
The IT team should implement a Prophet model rather than a complex LSTM. The data pipeline should aggregate hourly dwell times in the specific zones covering the conference lobby and restaurants. The Prophet model is ideal here because it natively handles the irregular spikes caused by the event calendar (which can be fed in as external regressors). The model output should be integrated directly into the workforce management system, providing a 7-day forecast with a MAPE tolerance of 10%.
A national retail chain wants to automate stock replenishment for high-margin perishable goods across 50 locations. They have 24 months of rich data, including WiFi analytics, POS data, and local weather feeds. They require a highly accurate 3-day forecast.
Given the rich feature set and the requirement for high accuracy (low MAPE) to drive automated supply chain decisions, an XGBoost (Gradient Boosting) model is the optimal choice. The data pipeline must first calibrate the WiFi-derived counts against the POS transaction data to establish a ground-truth baseline. The model will be trained on the 24-month dataset, incorporating weather and promotional calendars as key features. Due to the dynamic nature of retail, an automated weekly retraining cadence must be established to prevent model drift.
Análise de Cenário
Q1. A stadium IT director is planning to deploy predictive footfall analytics to manage security staffing at various gates. They have 2 years of historical WiFi data. The venue experiences massive, irregular spikes in attendance based on the event schedule, which changes frequently. Which ML model should they prioritize and why?
💡 Dica:Consider the impact of irregular, schedule-driven spikes on standard statistical models.
Mostrar Abordagem Recomendada
They should prioritize the Prophet model (or potentially a well-engineered XGBoost model if integrating many external features). Prophet is specifically designed to handle irregular spikes and changepoints driven by known events (like a match day schedule). While they have enough data for an LSTM, Prophet's interpretability and native handling of holiday/event effects make it more suitable for managing discrete, scheduled surges.
Q2. A retail operations manager complains that the new WiFi-based predictive footfall dashboard is consistently forecasting 40% fewer visitors than the physical door counters report, leading to understaffing. What is the most likely architectural failure in the deployment?
💡 Dica:Think about the difference between a connected device and a human being.
Mostrar Abordagem Recomendada
The deployment failed to implement a calibration layer. The system is accurately forecasting the number of WiFi-connected devices (the capture rate), but it has not been calibrated against a ground-truth source (the door counters) to establish the ratio of connected devices to total physical visitors. The IT team must apply a calibration multiplier to the raw forecast.
Q3. Six months after a successful deployment of a predictive staffing model in a large shopping centre, the MAPE (Mean Absolute Percentage Error) has degraded from 5% to 14%. No changes have been made to the code or the infrastructure. What is occurring and how should it be resolved?
💡 Dica:Data patterns change over time, rendering old training data less relevant.
Mostrar Abordagem Recomendada
The system is experiencing model drift. Visitor behavior or external factors have changed since the model was initially trained. The IT team must implement a structured retraining cadence, feeding the most recent data back into the model to update its weights and capture the new behavioral patterns.
