Affluence Prédictive et IA : Prévision des Modèles de Visiteurs à partir des Données WiFi
Ce guide de référence technique faisant autorité détaille comment les équipes IT d'entreprise et les opérateurs de sites peuvent exploiter les données dérivées du WiFi et l'apprentissage automatique pour prévoir l'affluence avec précision. Il couvre l'architecture des données, la sélection des modèles ML, les considérations relatives à la confidentialité et les stratégies de mise en œuvre concrètes pour transformer les tableaux de bord réactifs en intelligence prédictive.
🎧 Écouter ce guide
Voir la transcription

Résumé Exécutif
Pour les équipes IT d'entreprise et les directeurs des opérations de sites, l'infrastructure WiFi existante représente un atout opérationnel inexploité. Alors que les tableaux de bord réactifs fournissent un contexte historique, la véritable valeur des données spatiales réside dans l'analyse prédictive de l'affluence. En appliquant des modèles d'apprentissage automatique aux requêtes de sondage WiFi anonymisées et aux événements d'association, les organisations peuvent prévoir les modèles de visiteurs avec une précision suffisante pour optimiser la dotation en personnel, le réapprovisionnement des stocks et les déclencheurs marketing.
Ce guide fournit un plan technique, neutre vis-à-vis des fournisseurs, pour la mise en œuvre d'analyses prédictives des visiteurs. Il va au-delà de la théorie académique pour aborder les réalités pratiques de la randomisation MAC, des pipelines de données et de la dérive des modèles. Que vous gériez un hôtel de 200 chambres, un grand domaine commercial ou une installation du secteur public, cette référence décrit les exigences architecturales et les flux de travail opérationnels nécessaires pour passer du reporting historique à l'intelligence prédictive.
Approfondissement Technique : L'Architecture du Pipeline de Données
La base de toute initiative de prévision de l'affluence par IA est le pipeline d'ingestion et de prétraitement des données. La précision du modèle d'apprentissage automatique en aval dépend entièrement de la qualité des données spatiales extraites du réseau WiFi.
Ingestion des Données et Traitement du Signal
Les réseaux WiFi d'entreprise modernes, tels que ceux déployés dans des environnements de Commerce de Détail ou d' Hôtellerie , collectent en continu les requêtes de sondage de tout appareil compatible Wi-Fi à portée. Ces événements contiennent des métadonnées critiques, y compris un horodatage, un indicateur de force du signal reçu (RSSI) et un identifiant d'appareil.
Cependant, la mise en œuvre généralisée de la randomisation des adresses MAC par les principaux systèmes d'exploitation mobiles a fondamentalement modifié le suivi des appareils. Les pipelines d'analyse prédictive modernes ne reposent pas sur une identité d'appareil persistante. Au lieu de cela, ils utilisent le comptage basé sur les sessions et les distributions agrégées de temps de séjour. Les données anonymisées et agrégées sont entièrement conformes aux normes GDPR et PCI DSS tout en fournissant le volume nécessaire pour une prévision précise.
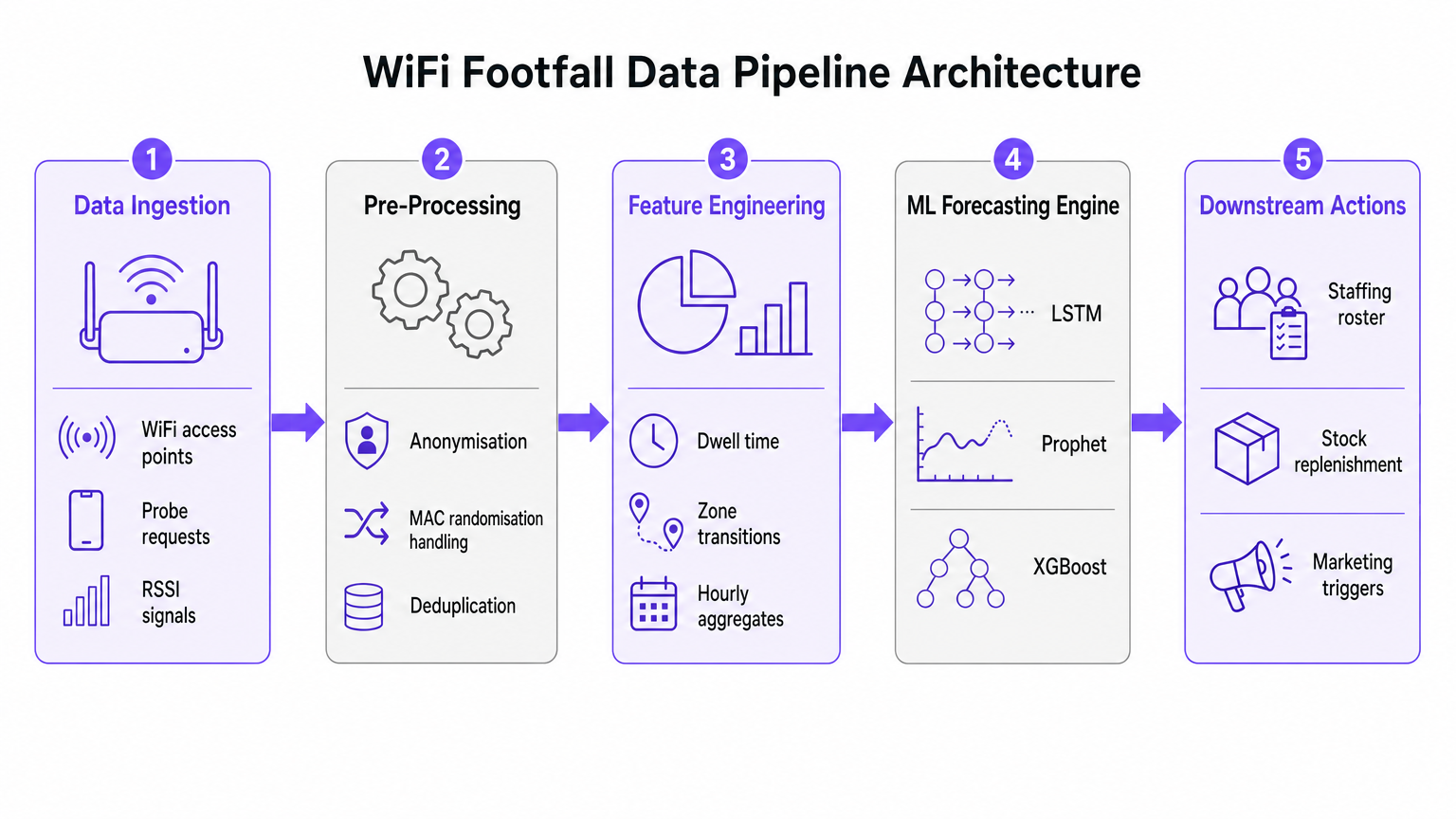
Ingénierie des Fonctionnalités pour l'Apprentissage Automatique
Les requêtes de sondage brutes ne sont pas adaptées à une ingestion directe dans les modèles de prévision. La couche de prétraitement doit gérer la déduplication, car un seul appareil peut générer de nombreuses requêtes par minute. Une fois dédupliquées et anonymisées, l'étape d'ingénierie des fonctionnalités extrait les métriques qui alimentent le moteur de prévision ML.
Les principales fonctionnalités conçues incluent :
- Comptes de Visiteurs Horaires : Agrégés par zone en fonction de la triangulation RSSI.
- Distributions du Temps de Séjour : La durée pendant laquelle les appareils restent dans des zones de couverture spécifiques.
- Transitions de Zone : Les modèles de mouvement entre différentes zones d'un site.
- Covariables Externes : Données contextuelles cruciales telles que le jour de la semaine, les jours fériés, les événements locaux et les conditions météorologiques.
Guide d'Implémentation : Sélection du Bon Modèle ML
La sélection du modèle d'apprentissage automatique approprié est dictée par le volume de données historiques disponibles et les décisions opérationnelles spécifiques que la prévision est censée soutenir. Opter par défaut pour des réseaux neuronaux complexes sans données suffisantes est un mode d'échec courant dans les déploiements d'entreprise.

Approches Statistiques : SARIMA
Pour les sites disposant d'au moins six mois de données horaires propres et de modèles saisonniers relativement stables, le modèle SARIMA (Seasonal AutoRegressive Integrated Moving Average) fournit une base solide. SARIMA est très efficace pour capturer les rythmes hebdomadaires dans des environnements tels que le commerce de détail axé sur les navetteurs ou les bureaux d'entreprise. Il offre généralement une erreur de pourcentage absolue moyenne (MAPE) de l'ordre de 8 à 12 % pour un horizon de prévision de 7 jours, ce qui est suffisant pour l'optimisation de la dotation en personnel de base.
Gestion des Pics Irréguliers : Prophet
Lorsque les données historiques s'étendent sur douze mois ou plus, et que le site connaît des pics irréguliers dus aux jours fériés ou aux événements promotionnels, le modèle Prophet de Facebook est un candidat solide. Prophet gère nativement les points de changement et les effets des jours fériés. De plus, sa nature interprétable permet aux équipes opérationnelles de comprendre les facteurs sous-jacents d'une augmentation prévue, ce qui le rend très adapté aux pôles de Transport et aux grands lieux publics.
Environnements Riches en Fonctionnalités : Gradient Boosting (XGBoost)
Dans les environnements de commerce de détail complexes où la prévision doit intégrer les calendriers promotionnels, l'activité des concurrents et les données d'une plateforme Guest WiFi , les modèles de gradient boosting comme XGBoost surpassent systématiquement les approches purement statistiques. Avec douze mois de données d'entraînement et une ingénierie des fonctionnalités sophistiquée, XGBoost peut atteindre un MAPE de 3 à 6 %. Ce niveau de précision permet des déclencheurs automatisés pour la chaîne d'approvisionnement et les systèmes de réapprovisionnement des stocks.
Apprentissage Profond : Réseaux LSTM
Les réseaux neuronaux LSTM (Long Short-Term Memory) sont puissants pour capturer les dépendances temporelles à long terme. Cependant, ils nécessitent un minimum de dix-huit mois de données de haute qualité pour être entraînés de manière fiable et sont coûteux en calcul à maintenir. Les modèles LSTM sont mieux réservés aux déploiements à grande échelle, tels que les chaînes de commerce de détail multi-sites.exploitants de stades ou d'installations, où les ressources d'ingénierie sont disponibles pour gérer l'infrastructure.
Bonnes pratiques de déploiement
Le déploiement réussi d'analyses prédictives de l'affluence nécessite une adhésion rigoureuse aux meilleures pratiques de l'industrie, allant au-delà de l'algorithme pour se concentrer sur l'infrastructure sous-jacente et l'intégration opérationnelle.
Calibrage de l'infrastructure
Une distinction essentielle doit être faite entre un décompte de visiteurs connectés au WiFi et un véritable décompte d'affluence. Les taux de capture varient considérablement selon le type de lieu. Un restaurant rapide peut observer un taux de capture de 30 %, tandis qu'un hall d'hôtel offrant une expérience WiFi Analytics fluide peut dépasser 80 %.
Pour établir une précision absolue, les décomptes dérivés du WiFi doivent être calibrés par rapport à une source de vérité terrain, telle que des compteurs de portes physiques ou des volumes de transactions au Point de Vente (POS). Bien que les schémas relatifs identifiés par les données WiFi soient immédiatement fiables, la prévision numérique absolue nécessite cette couche de calibrage.
Densité et positionnement des points d'accès
Pour une granularité de l'affluence au niveau de la zone, la densité des points d'accès est primordiale. Les points d'accès doivent être déployés à pas plus de 15 mètres les uns des autres, assurant des cellules de couverture qui se chevauchent. Cette densité est requise non seulement pour le débit (par exemple, la performance IEEE 802.11ax), mais aussi pour la précision de triangulation nécessaire à la couche de positionnement. Pour plus de détails techniques sur les technologies de positionnement, consultez le Indoor Positioning System: UWB, BLE, & WiFi Guide .
Dépannage et atténuation des risques
Le risque le plus important pour les déploiements d'analyses prédictives est la dérive du modèle. Le comportement des visiteurs n'est pas statique ; il évolue en réponse à des facteurs macroéconomiques, des changements d'infrastructure locaux ou des rénovations de lieux.
Gestion de la dérive du modèle
Les modèles entraînés sur des données antérieures aux changements se dégraderont inévitablement en termes de performances. Pour atténuer ce risque, les équipes informatiques doivent mettre en œuvre une cadence de réentraînement structurée. Pour la plupart des sites d'entreprise, un cycle de réentraînement mensuel est suffisant. Cependant, dans des environnements à forte volatilité tels que les espaces événementiels ou les centres de transport, un réentraînement hebdomadaire peut être nécessaire pour maintenir les tolérances de précision.
Confidentialité et conformité
L'atténuation des risques s'étend également à la confidentialité des données. Lorsqu'elles sont correctement anonymisées et agrégées, les données d'affluence dérivées du WiFi ne constituent pas des données personnelles au sens du GDPR. Cependant, la conformité exige que le processus d'anonymisation se produise en périphérie ou immédiatement après l'ingestion, avant que les données n'entrent dans la couche de stockage persistant utilisée pour l'entraînement du modèle.
ROI et impact commercial
La mesure ultime du succès d'un déploiement d'affluence prédictive est son intégration dans les flux de travail opérationnels. La prévision doit être liée à une action en aval spécifique.
Résultats démontrables
Les organisations qui implémentent avec succès ces modèles constatent généralement un retour sur investissement au cours du premier trimestre de déploiement. Les principaux impacts commerciaux incluent :
- Efficacité du personnel : Aligner les plannings du personnel avec les pics de demande prévus, réduisant les coûts de main-d'œuvre inutiles tout en assurant une couverture adéquate pendant les périodes de forte affluence.
- Optimisation des stocks : Intégrer les prévisions aux systèmes de chaîne d'approvisionnement pour déclencher un réapprovisionnement juste-à-temps, réduisant le gaspillage de produits périssables et prévenant les ruptures de stock.
- Déclencheurs marketing : Synchroniser les campagnes promotionnelles ou les mises à jour d'affichage numérique pour coïncider avec les périodes de forte affluence prévues. Pour les implémentations avancées impliquant l'IA générative, consultez Generative AI for Captive Portal Copy and Creative .
En traitant le réseau WiFi comme un ensemble de capteurs stratégiques et en appliquant des pratiques robustes d'apprentissage automatique, les équipes informatiques d'entreprise peuvent offrir une valeur opérationnelle mesurable bien au-delà de la connectivité de base.
Termes clés et définitions
MAC Randomisation
A privacy feature in modern mobile OSs that periodically changes the device's MAC address to prevent long-term tracking.
Forces IT teams to rely on session-based counting and aggregated analytics rather than persistent individual device tracking for footfall forecasting.
RSSI (Received Signal Strength Indicator)
A measurement of the power present in a received radio signal.
Used in the data pipeline to triangulate device position and determine zone transitions, forming the basis of spatial analytics.
Feature Engineering
The process of transforming raw data (like probe requests) into meaningful inputs (features) that a machine learning model can understand.
The critical step where IT teams convert raw network logs into actionable metrics like 'hourly dwell time' or 'zone entry rate'.
Model Drift
The degradation of a machine learning model's predictive accuracy over time due to changes in the underlying data patterns.
Requires IT teams to implement a structured retraining schedule to ensure forecasts remain reliable as venue layouts or visitor behaviors change.
SARIMA
Seasonal AutoRegressive Integrated Moving Average; a statistical model used for forecasting time series data with recurring patterns.
The recommended baseline model for venues with stable weekly rhythms and limited historical data (6-12 months).
Prophet
An open-source forecasting tool developed by Facebook, designed to handle time series data with strong seasonal effects and irregular holidays.
Ideal for event spaces or hospitality venues where irregular spikes (like concerts or bank holidays) disrupt standard seasonal patterns.
XGBoost
Extreme Gradient Boosting; a highly efficient and scalable machine learning algorithm that excels with structured, multi-variable data.
The model of choice for complex retail environments where forecasts must incorporate numerous external variables like weather and promotions.
MAPE (Mean Absolute Percentage Error)
A statistical measure of how accurate a forecast system is, representing the average absolute percent error for each time period.
The primary metric IT directors should use to evaluate model performance and set acceptable accuracy tolerances for operational decisions.
Études de cas
A 200-room hotel with a large conference facility needs to optimize its food and beverage staffing. The current approach relies on historical averages, resulting in understaffing during unexpected conference breakouts and overstaffing on quiet afternoons. They have 14 months of clean WiFi data but limited IT resources.
The IT team should implement a Prophet model rather than a complex LSTM. The data pipeline should aggregate hourly dwell times in the specific zones covering the conference lobby and restaurants. The Prophet model is ideal here because it natively handles the irregular spikes caused by the event calendar (which can be fed in as external regressors). The model output should be integrated directly into the workforce management system, providing a 7-day forecast with a MAPE tolerance of 10%.
A national retail chain wants to automate stock replenishment for high-margin perishable goods across 50 locations. They have 24 months of rich data, including WiFi analytics, POS data, and local weather feeds. They require a highly accurate 3-day forecast.
Given the rich feature set and the requirement for high accuracy (low MAPE) to drive automated supply chain decisions, an XGBoost (Gradient Boosting) model is the optimal choice. The data pipeline must first calibrate the WiFi-derived counts against the POS transaction data to establish a ground-truth baseline. The model will be trained on the 24-month dataset, incorporating weather and promotional calendars as key features. Due to the dynamic nature of retail, an automated weekly retraining cadence must be established to prevent model drift.
Analyse de scénario
Q1. A stadium IT director is planning to deploy predictive footfall analytics to manage security staffing at various gates. They have 2 years of historical WiFi data. The venue experiences massive, irregular spikes in attendance based on the event schedule, which changes frequently. Which ML model should they prioritize and why?
💡 Astuce :Consider the impact of irregular, schedule-driven spikes on standard statistical models.
Afficher l'approche recommandée
They should prioritize the Prophet model (or potentially a well-engineered XGBoost model if integrating many external features). Prophet is specifically designed to handle irregular spikes and changepoints driven by known events (like a match day schedule). While they have enough data for an LSTM, Prophet's interpretability and native handling of holiday/event effects make it more suitable for managing discrete, scheduled surges.
Q2. A retail operations manager complains that the new WiFi-based predictive footfall dashboard is consistently forecasting 40% fewer visitors than the physical door counters report, leading to understaffing. What is the most likely architectural failure in the deployment?
💡 Astuce :Think about the difference between a connected device and a human being.
Afficher l'approche recommandée
The deployment failed to implement a calibration layer. The system is accurately forecasting the number of WiFi-connected devices (the capture rate), but it has not been calibrated against a ground-truth source (the door counters) to establish the ratio of connected devices to total physical visitors. The IT team must apply a calibration multiplier to the raw forecast.
Q3. Six months after a successful deployment of a predictive staffing model in a large shopping centre, the MAPE (Mean Absolute Percentage Error) has degraded from 5% to 14%. No changes have been made to the code or the infrastructure. What is occurring and how should it be resolved?
💡 Astuce :Data patterns change over time, rendering old training data less relevant.
Afficher l'approche recommandée
The system is experiencing model drift. Visitor behavior or external factors have changed since the model was initially trained. The IT team must implement a structured retraining cadence, feeding the most recent data back into the model to update its weights and capture the new behavioral patterns.
