Prädiktive Besucherfrequenz und KI: Prognose von Besuchermustern aus WiFi-Daten
Dieser maßgebliche technische Leitfaden beschreibt, wie IT-Teams von Unternehmen und Betreiber von Veranstaltungsorten WiFi-abgeleitete Daten und maschinelles Lernen nutzen können, um die Besucherfrequenz genau zu prognostizieren. Er behandelt die Datenarchitektur, die Auswahl von ML-Modellen, Datenschutzaspekte und reale Implementierungsstrategien, um reaktive Dashboards in prädiktive Intelligenz zu verwandeln.
🎧 Diesen Leitfaden anhören
Transkript anzeigen

Zusammenfassung für Führungskräfte
Für IT-Teams von Unternehmen und Betriebsleiter von Veranstaltungsorten stellt die bestehende WiFi-Infrastruktur ein ungenutztes operatives Potenzial dar. Während reaktive Dashboards einen historischen Kontext liefern, liegt der wahre Wert räumlicher Daten in der prädiktiven Besucherfrequenzanalyse. Durch die Anwendung von Machine-Learning-Modellen auf anonymisierte WiFi-Probe-Requests und Assoziationsereignisse können Organisationen Besuchermuster mit ausreichender Genauigkeit prognostizieren, um Personalplanung, Bestandsauffüllung und Marketingauslöser zu steuern.
Dieser Leitfaden bietet einen herstellerneutralen, technischen Entwurf für die Implementierung prädiktiver Besucheranalysen. Er geht über die akademische Theorie hinaus und behandelt die praktischen Realitäten von MAC-Randomisierung, Datenpipelines und Modell-Drift. Ob Sie ein Hotel mit 200 Zimmern, eine große Einzelhandelsimmobilie oder eine öffentliche Einrichtung verwalten, diese Referenz skizziert die architektonischen Anforderungen und operativen Arbeitsabläufe, die für den Übergang von der historischen Berichterstattung zu prädiktiver Intelligenz erforderlich sind.
Technischer Deep-Dive: Die Datenpipeline-Architektur
Die Grundlage jeder KI-Initiative zur Besucherfrequenzprognose ist die Datenaufnahme- und Vorverarbeitungspipeline. Die Genauigkeit des nachgeschalteten Machine-Learning-Modells hängt vollständig von der Qualität der aus dem WiFi-Netzwerk extrahierten räumlichen Daten ab.
Datenaufnahme und Signalverarbeitung
Moderne Unternehmens-WiFi-Netzwerke, wie sie in Retail - oder Hospitality -Umgebungen eingesetzt werden, erfassen kontinuierlich Probe-Requests von jedem Wi-Fi-fähigen Gerät in Reichweite. Diese Ereignisse enthalten kritische Metadaten, darunter einen Zeitstempel, einen Received Signal Strength Indicator (RSSI) und eine Gerätekennung.
Die weit verbreitete Implementierung der MAC-Adressen-Randomisierung durch große mobile Betriebssysteme hat jedoch die Geräteverfolgung grundlegend verändert. Moderne prädiktive Analyse-Pipelines verlassen sich nicht auf eine persistente Geräteidentität. Stattdessen nutzen sie sitzungsbasierte Zählungen und aggregierte Verweildauerverteilungen. Anonymisierte, aggregierte Daten sind vollständig konform mit den GDPR- und PCI DSS-Standards und liefern gleichzeitig das notwendige Volumen für eine genaue Prognose.
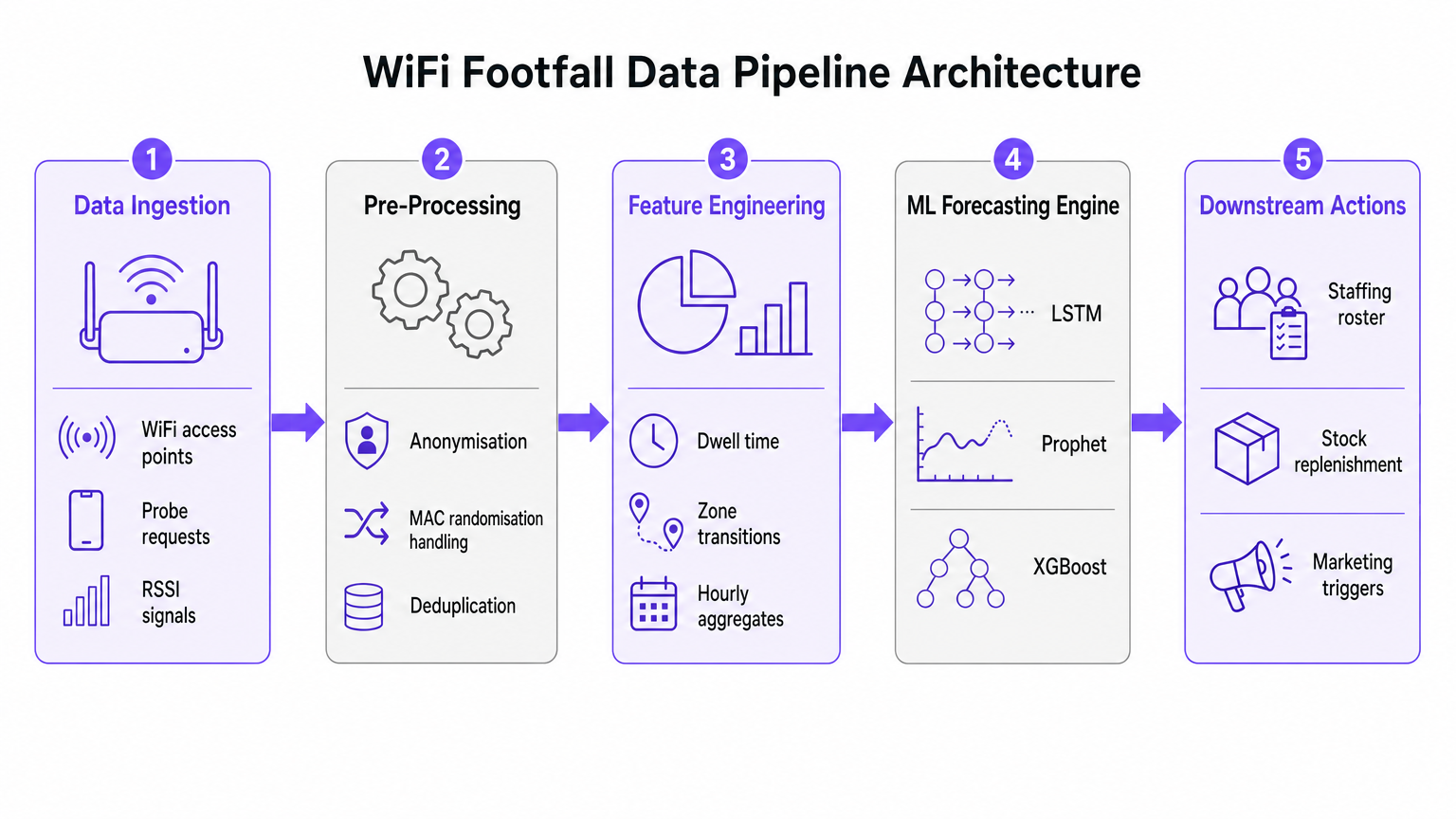
Feature Engineering für maschinelles Lernen
Rohe Probe-Requests sind nicht für die direkte Aufnahme in Prognosemodelle geeignet. Die Vorverarbeitungsschicht muss die Deduplizierung handhaben, da ein einzelnes Gerät zahlreiche Anfragen pro Minute generieren kann. Nach der Deduplizierung und Anonymisierung extrahiert die Feature-Engineering-Phase die Metriken, die das ML-Prognose-Engine speisen.
Wichtige entwickelte Features umfassen:
- Stündliche Besucherzahlen: Aggregiert pro Zone basierend auf RSSI-Triangulation.
- Verweildauerverteilungen: Die Dauer, die Geräte in bestimmten Abdeckungsbereichen verbleiben.
- Zonenübergänge: Die Bewegungsmuster zwischen verschiedenen Bereichen eines Veranstaltungsortes.
- Externe Kovariaten: Entscheidende Kontextdaten wie Wochentag, Feiertage, lokale Veranstaltungen und Wetterbedingungen.
Implementierungsleitfaden: Auswahl des richtigen ML-Modells
Die Auswahl des geeigneten Machine-Learning-Modells wird durch das Volumen der verfügbaren historischen Daten und die spezifischen operativen Entscheidungen bestimmt, die die Prognose unterstützen soll. Die standardmäßige Verwendung komplexer neuronaler Netze ohne ausreichende Daten ist ein häufiger Fehler bei Unternehmensimplementierungen.

Statistische Ansätze: SARIMA
Für Veranstaltungsorte mit mindestens sechs Monaten sauberer Stundendaten und relativ stabilen saisonalen Mustern bietet das Seasonal AutoRegressive Integrated Moving Average (SARIMA)-Modell eine robuste Basislinie. SARIMA ist hochwirksam, um wöchentliche Rhythmen in Umgebungen wie pendlerorientiertem Einzelhandel oder Firmenbüros zu erfassen. Es liefert typischerweise einen mittleren absoluten prozentualen Fehler (MAPE) im Bereich von 8-12% für einen 7-Tage-Prognosehorizont, was für die grundlegende Personaloptimierung ausreicht.
Umgang mit unregelmäßigen Spitzen: Prophet
Wenn historische Daten zwölf Monate oder länger zurückreichen und der Veranstaltungsort unregelmäßige Spitzen aufgrund von Feiertagen oder Werbeaktionen erlebt, ist Facebooks Prophet-Modell ein starker Kandidat. Prophet verarbeitet nativ Änderungszeitpunkte und Feiertagseffekte. Darüber hinaus ermöglicht seine interpretierbare Natur den Betriebsteams, die zugrunde liegenden Treiber eines vorhergesagten Anstiegs zu verstehen, was es für Transport -Knotenpunkte und große öffentliche Veranstaltungsorte sehr geeignet macht.
Feature-reiche Umgebungen: Gradient Boosting (XGBoost)
In komplexen Einzelhandelsumgebungen, in denen die Prognose Werbekalender, Wettbewerbsaktivitäten und Daten von einer Guest WiFi -Plattform berücksichtigen muss, übertreffen Gradient-Boosting-Modelle wie XGBoost durchweg rein statistische Ansätze. Mit zwölf Monaten Trainingsdaten und ausgeklügeltem Feature Engineering kann XGBoost einen MAPE von 3-6% erreichen. Dieses Genauigkeitsniveau ermöglicht automatisierte Auslöser für Lieferketten- und Bestandsauffüllungssysteme.
Deep Learning: LSTM-Netzwerke
Long Short-Term Memory (LSTM)-neuronale Netze sind leistungsstark, um langfristige zeitliche Abhängigkeiten zu erfassen. Sie erfordern jedoch mindestens achtzehn Monate hochwertige Daten, um zuverlässig trainiert zu werden, und sind im Unterhalt rechenintensiv. LSTM-Modelle sind am besten für große Implementierungen reserviert, wie z. B. Einzelhandelsketten mit mehreren Standorten.Betreiber von Innenbereichen oder Stadien, bei denen die technischen Ressourcen zur Verwaltung der Infrastruktur vorhanden sind.
Best Practices für die Bereitstellung
Die erfolgreiche Bereitstellung von prädiktiver Besucherfrequenzanalyse erfordert die strikte Einhaltung von Branchen-Best Practices, wobei der Fokus über den Algorithmus hinaus auf die zugrunde liegende Infrastruktur und die operationale Integration gelegt wird.
Infrastrukturkalibrierung
Es muss eine kritische Unterscheidung zwischen einer über WiFi verbundenen Besucherzählung und einer echten Besucherfrequenzzählung getroffen werden. Die Erfassungsraten variieren erheblich je nach Veranstaltungsort. Ein Schnellrestaurant kann eine Erfassungsrate von 30 % aufweisen, während eine Hotellobby, die ein nahtloses WiFi Analytics Erlebnis bietet, 80 % überschreiten kann.
Um absolute Genauigkeit zu gewährleisten, müssen die aus WiFi abgeleiteten Zählungen mit einer Ground-Truth-Quelle kalibriert werden, wie z.B. physischen Türzählern oder Point of Sale (POS) Transaktionsvolumen. Während die relativen Muster, die durch die WiFi-Daten identifiziert werden, sofort zuverlässig sind, erfordert die absolute numerische Prognose diese Kalibrierungsschicht.
Access Point Dichte und Positionierung
Für die Granularität der Besucherfrequenz auf Zonenebene ist die Access Point Dichte von größter Bedeutung. Access Points sollten nicht mehr als 15 Meter voneinander entfernt installiert werden, um überlappende Abdeckungszellen zu gewährleisten. Diese Dichte ist nicht nur für den Durchsatz (z.B. IEEE 802.11ax Leistung) erforderlich, sondern auch für die Triangulationsgenauigkeit, die für die Positionierungsschicht notwendig ist. Weitere technische Details zu Positionierungstechnologien finden Sie im Indoor Positioning System: UWB, BLE, & WiFi Guide .
Fehlerbehebung & Risikominderung
Das größte Risiko bei der Bereitstellung von prädiktiven Analysen ist die Modelldrift. Das Besucherverhalten ist nicht statisch; es ändert sich als Reaktion auf makroökonomische Faktoren, lokale Infrastrukturänderungen oder Renovierungen von Veranstaltungsorten.
Umgang mit Modelldrift
Modelle, die mit Daten vor Änderungen trainiert wurden, werden unweigerlich an Leistung verlieren. Um dieses Risiko zu mindern, müssen IT-Teams einen strukturierten Umschulungszyklus implementieren. Für die meisten Unternehmensstandorte ist ein monatlicher Umschulungszyklus ausreichend. In Umgebungen mit hoher Volatilität, wie z.B. Veranstaltungsräumen oder Verkehrsknotenpunkten, kann jedoch eine wöchentliche Umschulung erforderlich sein, um die Genauigkeitstoleranzen aufrechtzuerhalten.
Datenschutz und Compliance
Die Risikominderung erstreckt sich auch auf den Datenschutz. Wenn ordnungsgemäß anonymisiert und aggregiert, stellen aus WiFi abgeleitete Besucherfrequenzdaten keine personenbezogenen Daten gemäß GDPR dar. Die Compliance erfordert jedoch, dass der Anonymisierungsprozess am Edge oder unmittelbar nach der Erfassung erfolgt, bevor die Daten in die persistente Speicherschicht gelangen, die für das Modelltraining verwendet wird.
ROI & Geschäftsauswirkungen
Das ultimative Maß für den Erfolg einer prädiktiven Besucherfrequenz-Bereitstellung ist deren Integration in operative Arbeitsabläufe. Die Prognose muss mit einer spezifischen nachgelagerten Aktion verbunden sein.
Nachweisbare Ergebnisse
Organisationen, die diese Modelle erfolgreich implementieren, sehen typischerweise einen Return on Investment innerhalb des ersten Quartals der Bereitstellung. Wichtige Geschäftsauswirkungen sind:
- Personalplanungseffizienz: Abstimmung der Personalpläne mit prognostizierten Nachfragespitzen, wodurch unnötige Arbeitskosten reduziert und gleichzeitig eine ausreichende Abdeckung während Spitzenzeiten gewährleistet wird.
- Bestandsoptimierung: Integration von Prognosen in Lieferkettensysteme, um Just-in-Time-Nachschub auszulösen, Abfall bei verderblichen Waren zu reduzieren und Fehlbestände zu vermeiden.
- Marketing-Trigger: Zeitliche Abstimmung von Werbeaktionen oder Updates digitaler Beschilderungen, um mit prognostizierten Hochverweilzeiten zusammenzufallen. Für fortgeschrittene Implementierungen mit generativer AI, siehe Generative AI for Captive Portal Copy and Creative .
Indem das WiFi-Netzwerk als strategisches Sensor-Array behandelt und robuste Machine-Learning-Praktiken angewendet werden, können IT-Teams von Unternehmen einen messbaren operativen Wert weit über die grundlegende Konnektivität hinaus liefern.
Schlüsselbegriffe & Definitionen
MAC Randomisation
A privacy feature in modern mobile OSs that periodically changes the device's MAC address to prevent long-term tracking.
Forces IT teams to rely on session-based counting and aggregated analytics rather than persistent individual device tracking for footfall forecasting.
RSSI (Received Signal Strength Indicator)
A measurement of the power present in a received radio signal.
Used in the data pipeline to triangulate device position and determine zone transitions, forming the basis of spatial analytics.
Feature Engineering
The process of transforming raw data (like probe requests) into meaningful inputs (features) that a machine learning model can understand.
The critical step where IT teams convert raw network logs into actionable metrics like 'hourly dwell time' or 'zone entry rate'.
Model Drift
The degradation of a machine learning model's predictive accuracy over time due to changes in the underlying data patterns.
Requires IT teams to implement a structured retraining schedule to ensure forecasts remain reliable as venue layouts or visitor behaviors change.
SARIMA
Seasonal AutoRegressive Integrated Moving Average; a statistical model used for forecasting time series data with recurring patterns.
The recommended baseline model for venues with stable weekly rhythms and limited historical data (6-12 months).
Prophet
An open-source forecasting tool developed by Facebook, designed to handle time series data with strong seasonal effects and irregular holidays.
Ideal for event spaces or hospitality venues where irregular spikes (like concerts or bank holidays) disrupt standard seasonal patterns.
XGBoost
Extreme Gradient Boosting; a highly efficient and scalable machine learning algorithm that excels with structured, multi-variable data.
The model of choice for complex retail environments where forecasts must incorporate numerous external variables like weather and promotions.
MAPE (Mean Absolute Percentage Error)
A statistical measure of how accurate a forecast system is, representing the average absolute percent error for each time period.
The primary metric IT directors should use to evaluate model performance and set acceptable accuracy tolerances for operational decisions.
Fallstudien
A 200-room hotel with a large conference facility needs to optimize its food and beverage staffing. The current approach relies on historical averages, resulting in understaffing during unexpected conference breakouts and overstaffing on quiet afternoons. They have 14 months of clean WiFi data but limited IT resources.
The IT team should implement a Prophet model rather than a complex LSTM. The data pipeline should aggregate hourly dwell times in the specific zones covering the conference lobby and restaurants. The Prophet model is ideal here because it natively handles the irregular spikes caused by the event calendar (which can be fed in as external regressors). The model output should be integrated directly into the workforce management system, providing a 7-day forecast with a MAPE tolerance of 10%.
A national retail chain wants to automate stock replenishment for high-margin perishable goods across 50 locations. They have 24 months of rich data, including WiFi analytics, POS data, and local weather feeds. They require a highly accurate 3-day forecast.
Given the rich feature set and the requirement for high accuracy (low MAPE) to drive automated supply chain decisions, an XGBoost (Gradient Boosting) model is the optimal choice. The data pipeline must first calibrate the WiFi-derived counts against the POS transaction data to establish a ground-truth baseline. The model will be trained on the 24-month dataset, incorporating weather and promotional calendars as key features. Due to the dynamic nature of retail, an automated weekly retraining cadence must be established to prevent model drift.
Szenarioanalyse
Q1. A stadium IT director is planning to deploy predictive footfall analytics to manage security staffing at various gates. They have 2 years of historical WiFi data. The venue experiences massive, irregular spikes in attendance based on the event schedule, which changes frequently. Which ML model should they prioritize and why?
💡 Hinweis:Consider the impact of irregular, schedule-driven spikes on standard statistical models.
Empfohlenen Ansatz anzeigen
They should prioritize the Prophet model (or potentially a well-engineered XGBoost model if integrating many external features). Prophet is specifically designed to handle irregular spikes and changepoints driven by known events (like a match day schedule). While they have enough data for an LSTM, Prophet's interpretability and native handling of holiday/event effects make it more suitable for managing discrete, scheduled surges.
Q2. A retail operations manager complains that the new WiFi-based predictive footfall dashboard is consistently forecasting 40% fewer visitors than the physical door counters report, leading to understaffing. What is the most likely architectural failure in the deployment?
💡 Hinweis:Think about the difference between a connected device and a human being.
Empfohlenen Ansatz anzeigen
The deployment failed to implement a calibration layer. The system is accurately forecasting the number of WiFi-connected devices (the capture rate), but it has not been calibrated against a ground-truth source (the door counters) to establish the ratio of connected devices to total physical visitors. The IT team must apply a calibration multiplier to the raw forecast.
Q3. Six months after a successful deployment of a predictive staffing model in a large shopping centre, the MAPE (Mean Absolute Percentage Error) has degraded from 5% to 14%. No changes have been made to the code or the infrastructure. What is occurring and how should it be resolved?
💡 Hinweis:Data patterns change over time, rendering old training data less relevant.
Empfohlenen Ansatz anzeigen
The system is experiencing model drift. Visitor behavior or external factors have changed since the model was initially trained. The IT team must implement a structured retraining cadence, feeding the most recent data back into the model to update its weights and capture the new behavioral patterns.
