Why is Our Guest WiFi So Slow? Diagnosing Network Congestion
Ce guide diagnostique les facteurs cachés de la congestion du WiFi invité — télémétrie en arrière-plan, réseaux publicitaires programmatiques et mises à jour automatisées du système d'exploitation — qui consomment collectivement jusqu'à 40 % de la bande passante du WiFi public avant même qu'un invité n'ouvre un navigateur. Il fournit un cadre de mise en œuvre progressif et neutre vis-à-vis des fournisseurs pour le filtrage DNS et les politiques de QoS qui permettent de récupérer cette bande passante, d'améliorer l'expérience des invités et de générer un ROI mesurable. Destiné aux directeurs informatiques et aux responsables des opérations dans les secteurs de l'hôtellerie, du commerce de détail, de l'événementiel et des environnements publics.
Écouter ce guide
Voir la transcription du podcast
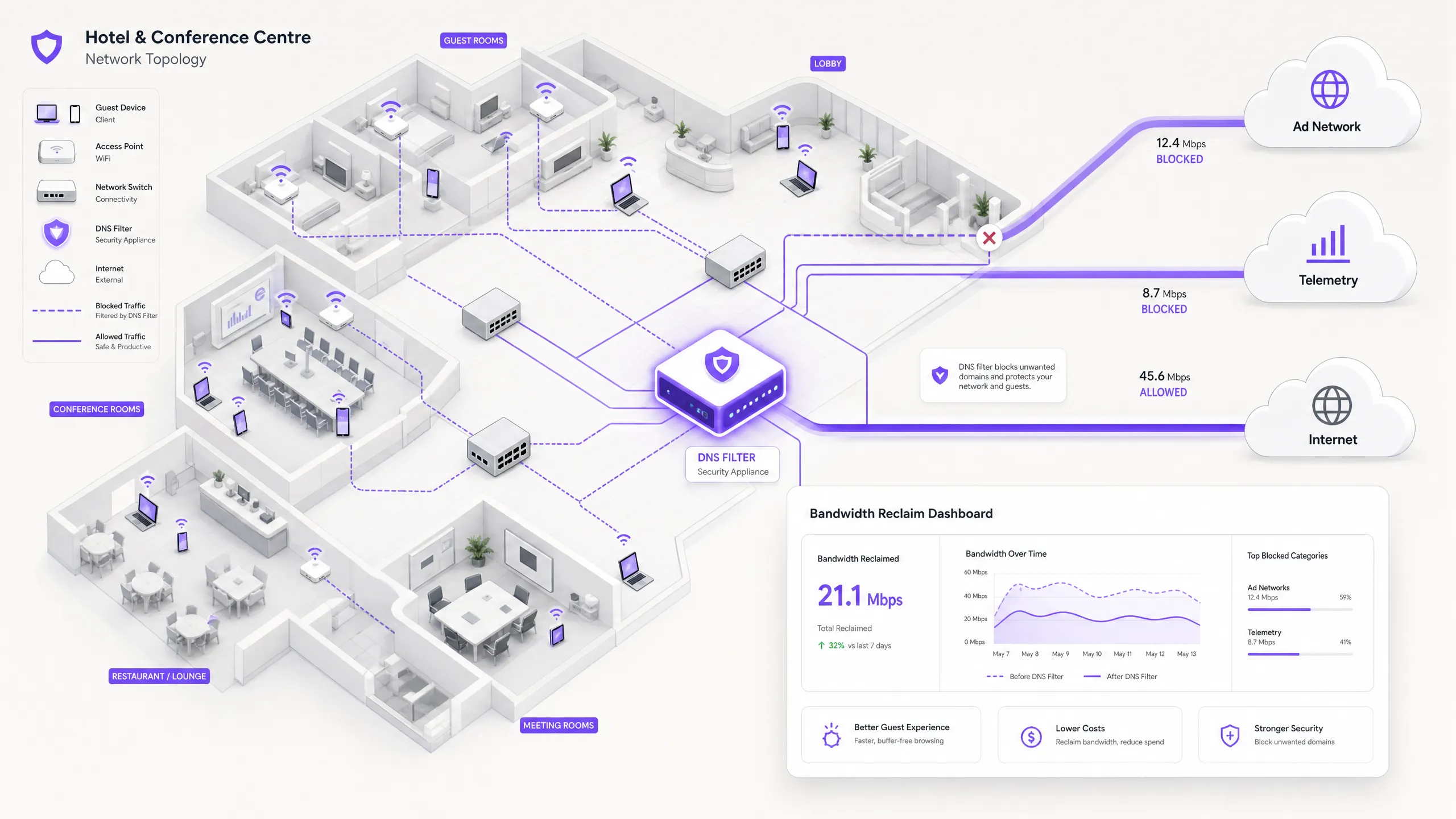
Executive Summary
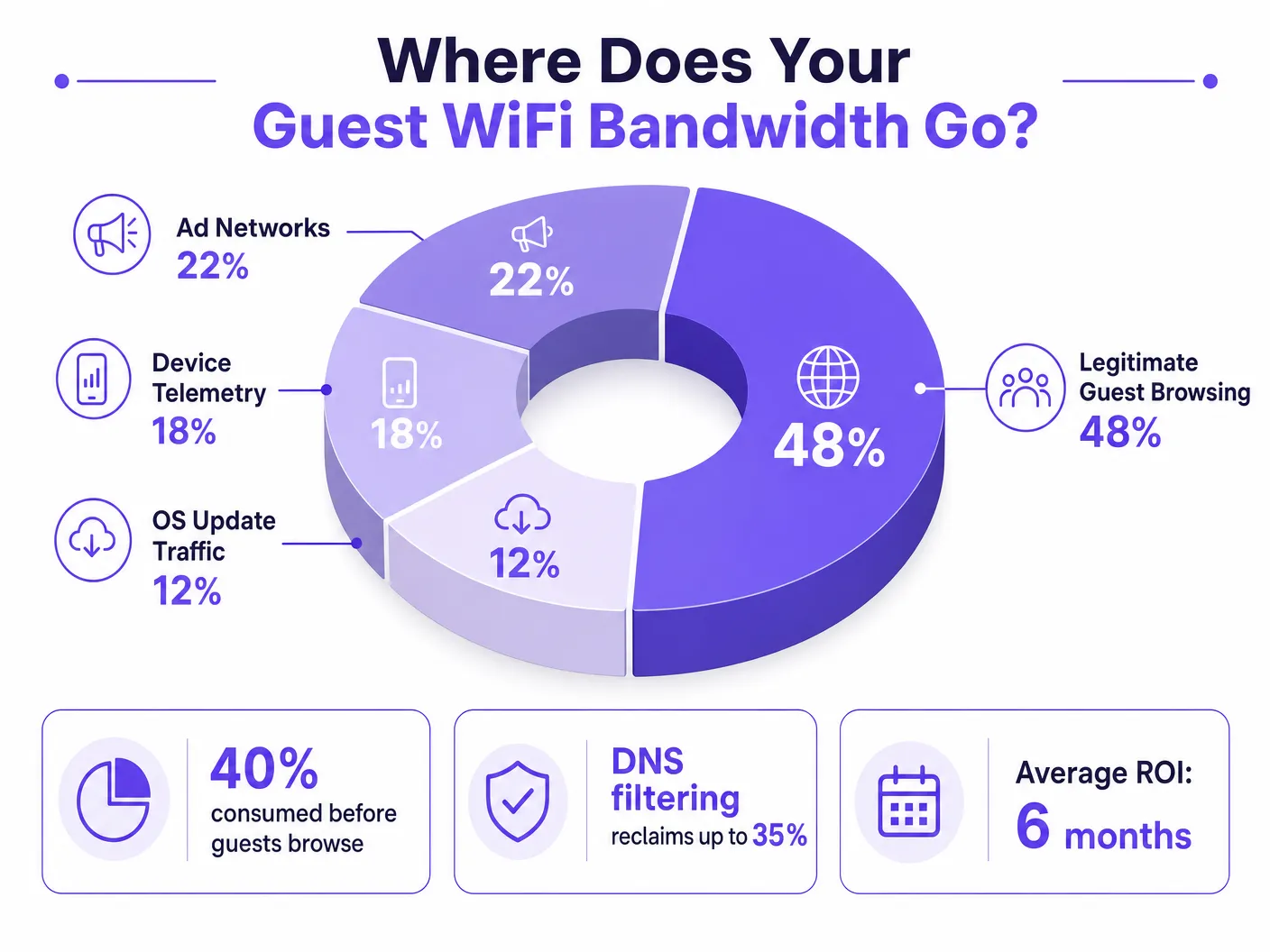
For IT Directors and Operations Managers overseeing high-density venues, ensuring a reliable Guest WiFi experience is a constant battle against network congestion. While legacy approaches focus on increasing overall bandwidth or deploying additional access points, the root cause of slow throughput often lies not in legitimate user traffic, but in the hidden layer of background data. In modern environments — from sprawling Hospitality complexes to high-footfall Retail spaces — up to 40% of public WiFi bandwidth is consumed by device telemetry, programmatic ad networks, and automated OS updates before a guest even opens a browser.
This technical reference guide provides a definitive methodology for diagnosing this congestion and implementing strategic mitigation. By deploying network-level DNS filtering and Response Policy Zones (RPZ), enterprise network architects can reclaim significant bandwidth, reduce latency, and dramatically improve the end-user experience without incurring the capital expenditure of infrastructure upgrades. We will explore the technical architecture of these solutions, real-world implementation case studies, and the measurable ROI of reclaiming your network.
Technical Deep-Dive
The Anatomy of Background Congestion
When a guest device authenticates to a public network, it immediately initiates a barrage of background connections. These connections are primarily driven by three categories of traffic that, in aggregate, constitute what network engineers call the phantom load — bandwidth consumed by the network before any deliberate guest activity occurs.
1. Device Telemetry and Analytics
Modern operating systems (iOS, Android, Windows) and installed applications constantly transmit usage data, location metrics, crash reports, and behavioural analytics to remote servers. In a dense environment such as a Transport hub or conference centre, thousands of devices simultaneously transmitting small but frequent telemetry payloads can exhaust available wireless airtime and overwhelm NAT tables. A single iOS device can generate upwards of 200 distinct background DNS queries within the first 60 seconds of connecting to an unmetered network.
2. Programmatic Ad Networks
Many free applications rely on programmatic advertising ecosystems. The moment a device detects an unmetered WiFi connection, these apps begin pre-fetching video ads, high-resolution display banners, and tracking scripts from ad exchange platforms. This traffic is both high-bandwidth and latency-sensitive, and it will aggressively compete for airtime with legitimate guest browsing. Analysis of public venue networks consistently shows that programmatic ad traffic accounts for 15–22% of total WAN utilisation during peak hours.
3. Automated OS and Application Updates
Without proper traffic shaping, devices will attempt to download large OS patches and application updates as soon as they detect an unmetered WiFi connection. A single iOS major update can be 3–5 GB. In a 500-device environment, a simultaneous update trigger — common when a new OS version is released — can saturate even a 1 Gbps WAN link within minutes.
Why Traditional Approaches Fall Short
The conventional response to guest WiFi congestion is to increase WAN bandwidth or deploy additional access points. While both measures have their place, neither addresses the phantom load. Adding more bandwidth simply provides more capacity for background traffic to consume. Deep Packet Inspection (DPI), the other traditional tool, is increasingly ineffective: the widespread adoption of TLS 1.3 and end-to-end encryption means that the majority of traffic payloads are opaque to inspection engines. You cannot throttle what you cannot classify.
For a broader discussion of how wireless frequencies interact with high-density deployments, see our guide on Wi-Fi Frequencies: A Guide to Wi-Fi Frequencies in 2026 .
DNS Filtering: The Efficient Countermeasure
The modern, scalable solution is DNS filtering at the network edge. Rather than inspecting traffic payloads, DNS filtering operates at the resolution layer — preventing connections from being established in the first place.
When a device requests access to a known ad network or telemetry domain, the DNS resolver checks the request against a Response Policy Zone (RPZ). If the domain appears in the blocklist, the resolver returns an NXDOMAIN (Non-Existent Domain) response, or sinkholes the traffic to a local null IP address. The connection is terminated before the TCP handshake occurs, preserving both wireless airtime and WAN bandwidth. This approach is computationally inexpensive, scales linearly with resolver capacity, and is unaffected by payload encryption.
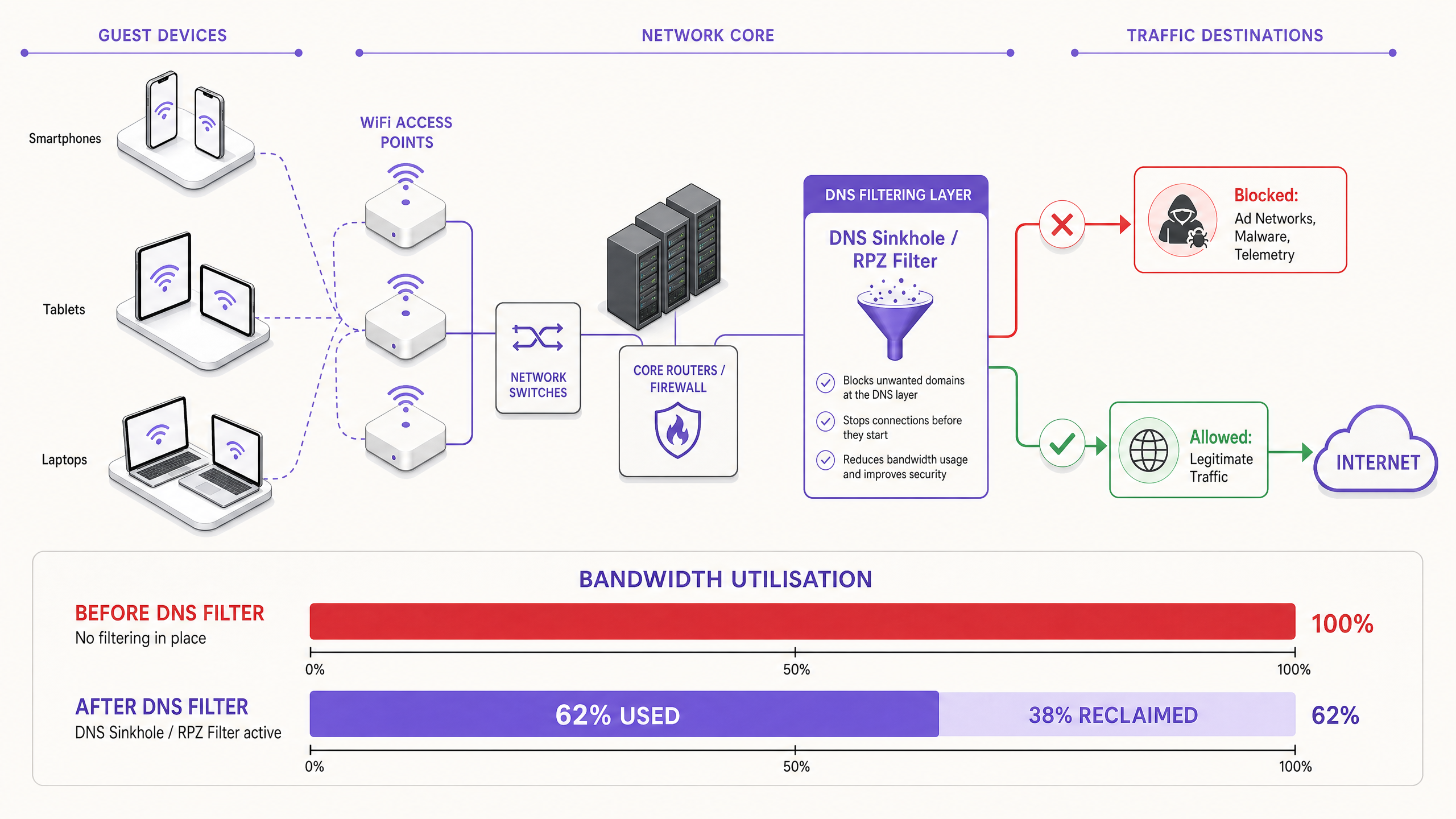
The Security Dimension
DNS filtering delivers a significant secondary benefit: security. By blocking known malware Command and Control (C2) domains, phishing infrastructure, and exploit kit delivery networks at the DNS layer, the guest network becomes substantially more defensible. This is directly relevant to compliance obligations under frameworks such as PCI DSS (which requires network segmentation and monitoring for cardholder data environments) and GDPR (which mandates appropriate technical measures to protect personal data). For a detailed treatment of audit trail requirements in this context, see Explain what is audit trail for IT Security in 2026 .
For organisations managing educational environments where ad blocking also serves a safeguarding function, the principles covered in Minimising Student Distractions with Network-Level Ad Blocking are directly applicable.
Implementation Guide
Deploying a robust DNS filtering architecture requires careful planning to avoid disrupting legitimate guest services. The implementation should follow a phased approach.
Phase 1: Baseline Assessment and Visibility
Before implementing any blocks, establish a baseline of current traffic patterns. Utilise WiFi Analytics to identify the top bandwidth-consuming domains and categories over a representative 7–14 day period. This audit phase is critical for understanding the specific traffic profile of your venue and for building the business case for the investment. Key metrics to capture include:
| Metric | Target Baseline | Notes |
|---|---|---|
| Top 20 DNS domains by query volume | Full list | Identify telemetry and ad domains |
| WAN utilisation by category | % split | Quantify the phantom load |
| Peak concurrent device count | Number | Size resolver infrastructure |
| DNS query failure rate | < 0.1% | Establish pre-deployment benchmark |
Phase 2: Staged RPZ Deployment
Begin by deploying the RPZ in log-only mode. This allows you to verify the accuracy of your blocklists without impacting the user experience. Focus on high-confidence categories first:
- Known Malware and C2 Domains: Immediate security benefit with near-zero risk of false positives. Use threat intelligence feeds from reputable providers.
- High-Bandwidth Programmatic Ad Networks: Target the major video ad exchange platforms. These are well-documented and unlikely to host legitimate content.
- Aggressive Telemetry Endpoints: Block non-essential tracking domains. Maintain a careful allow-list for domains required for captive portal authentication flows.
Once log-only mode confirms acceptable false positive rates (target < 0.5% of queries), move to enforcement mode.
Phase 3: Traffic Shaping and QoS Integration
For traffic that cannot be outright blocked (e.g., OS updates from Apple, Microsoft, and Google), implement Quality of Service (QoS) policies. Rate-limit update servers to a defined ceiling — typically 10–15% of total WAN capacity — ensuring that interactive guest traffic (web browsing, VoIP, video conferencing) receives priority queuing. This is particularly important for Healthcare environments where clinical staff may share a network segment with guests.
For guidance on optimising broader network environments, including office and mixed-use deployments, see Office Wi-Fi: Optimize Your Modern Office Wi-Fi Network .
Best Practices
Maintain Explicit Allow-lists for Critical Services. Ensure that domains essential for captive portal authentication, payment gateways (PCI DSS compliance), and core venue operations are explicitly permitted. A misconfigured blocklist that breaks the login flow will generate immediate and significant support load.
Communicate the Policy Transparently. Your Terms of Service should state that network traffic is managed to ensure a high-quality experience for all users. This is both a legal best practice under GDPR and a reasonable expectation-setting measure for guests.
Automate Blocklist Updates. The landscape of ad networks and telemetry domains shifts constantly. Threat intelligence feeds and RPZ lists must be updated dynamically — ideally on a sub-24-hour cycle — to remain effective.
Address DNS Evasion Proactively. Implement firewall rules to intercept and redirect all outbound port 53 (UDP and TCP) traffic to the local resolver. This prevents clients from bypassing filtering by hardcoding external DNS servers.
Plan for DNS over HTTPS (DoH). As DoH adoption increases, clients may route DNS queries over HTTPS to bypass local resolvers entirely. Evaluate whether to block known DoH providers (e.g., dns.google, cloudflare-dns.com) or to deploy a transparent DoH proxy that enforces local policy.
Align with IEEE 802.1X and WPA3. Ensure that your DNS filtering architecture is compatible with your authentication framework. In environments using IEEE 802.1X with RADIUS-based authentication, DNS filtering policies can be applied per VLAN or per user group, enabling granular control.
Troubleshooting & Risk Mitigation
Common Failure Modes
| Failure Mode | Symptom | Mitigation |
|---|---|---|
| Over-blocking (CDN collision) | Broken webpages, missing images | Granular blocklists; rapid allow-listing process |
| DNS evasion (hardcoded resolvers) | Filtering bypassed by specific apps | Firewall redirect rules for port 53 |
| DoH bypass | Filtering bypassed by modern browsers | Block known DoH providers or deploy DoH proxy |
| Resolver performance bottleneck | Increased DNS latency across all clients | Scale resolver infrastructure; implement anycast |
| Captive portal breakage | Guests cannot authenticate | Explicit allow-list for portal domains and OS detection endpoints |
| Stale blocklists | New ad domains not blocked | Automate feed updates; monitor query logs for new high-volume domains |
Security Incident Response
If a guest device is identified as communicating with a known malware C2 domain (visible in DNS query logs), the RPZ will automatically block further communication. Ensure your incident response process includes a workflow for reviewing these events, as they may indicate a compromised device that requires isolation from the guest VLAN.
ROI & Business Impact
Implementing network-level DNS filtering delivers measurable, quantifiable business outcomes across multiple dimensions.
Bandwidth Reclamation and CapEx Deferral. Venues typically reclaim 20–40% of their total WAN bandwidth. This directly translates to cost savings by deferring the need for expensive circuit upgrades. For a venue currently paying for a 500 Mbps leased line, reclaiming 30% of capacity is equivalent to gaining 150 Mbps of effective throughput at zero additional cost.
Improved Guest Satisfaction and NPS. By eliminating background congestion, the perceived speed and reliability of the Guest WiFi improves dramatically. Reduced latency and consistent throughput lead to higher Net Promoter Scores and fewer operational support escalations.
Enhanced Security and Compliance Posture. Blocking malware and phishing domains at the DNS layer significantly reduces the risk of a security breach originating from the guest network. This directly supports compliance with PCI DSS network segmentation requirements and GDPR's obligation to implement appropriate technical security measures.
Operational Efficiency. Automated DNS filtering reduces the manual workload on network operations teams. Rather than reactively responding to congestion events, the network proactively manages its own traffic profile.
| Outcome | Typical Range | Measurement Method |
|---|---|---|
| Bandwidth reclaimed | 20–40% of WAN capacity | Before/after WAN utilisation monitoring |
| DNS query block rate | 15–35% of all queries | Resolver query logs |
| Guest satisfaction improvement | +8–15 NPS points | Post-stay/post-visit surveys |
| CapEx deferral | 1–3 years on circuit upgrade | Cost modelling |
| Security incident reduction | 40–60% fewer C2 detections | SIEM correlation |
By treating the network not just as a pipe, but as an intelligent, filtered gateway, IT leaders can deliver a superior, secure, and cost-effective connectivity experience — one that scales with venue growth without proportional infrastructure investment.
Définitions clés
Response Policy Zone (RPZ)
Un mécanisme dans les serveurs DNS qui permet de modifier les réponses DNS en fonction d'une politique définie. Lorsqu'un domaine interrogé correspond à une entrée dans la RPZ, le résolveur peut renvoyer une réponse synthétique (par exemple, NXDOMAIN ou une adresse IP de redirection/sinkhole) au lieu de la réponse réelle.
Le principal mécanisme technique pour implémenter le filtrage DNS à l'échelle du réseau. Les équipes informatiques configurent les RPZ sur leurs résolveurs internes pour bloquer les réseaux publicitaires, les domaines de logiciels malveillants et les points de terminaison de télémétrie sans nécessiter de logiciel côté client.
Deep Packet Inspection (DPI)
Une forme de filtrage de paquets réseau qui examine la charge utile des données d'un paquet lorsqu'il passe par un point d'inspection, à la recherche de non-conformités aux protocoles, de contenus spécifiques ou de critères définis.
Traditionnellement utilisé pour la classification et le lissage du trafic. De plus en plus limité par l'adoption généralisée du chiffrement de bout en bout TLS 1.3, qui rend les charges utiles opaques. Le filtrage DNS est l'alternative privilégiée pour les environnements de trafic chiffré.
NXDOMAIN
Un code de réponse DNS (RCODE 3) indiquant que le nom de domaine interrogé n'existe pas dans l'espace de noms DNS.
Renvoyé par un résolveur DNS de filtrage pour bloquer intentionnellement une connexion vers un domaine indésirable. L'application cliente reçoit cette réponse et abandonne la tentative de connexion, évitant ainsi toute consommation de bande passante.
DNS over HTTPS (DoH)
Un protocole permettant d'effectuer une résolution DNS via le protocole HTTPS (RFC 8484), chiffrant les requêtes et les réponses DNS entre le client et un résolveur compatible DoH.
Peut contourner le filtrage DNS du réseau local si les clients sont configurés pour utiliser des fournisseurs DoH externes. Les administrateurs réseau doivent implémenter des règles de pare-feu ou acheminer le trafic DoH via un proxy pour appliquer les politiques RPZ locales.
Quality of Service (QoS)
Un ensemble de mécanismes réseau qui contrôlent la priorisation du trafic, la limitation du débit et la mise en file d'attente pour garantir les performances des applications critiques.
Utilisé en parallèle du filtrage DNS pour gérer le trafic légitime mais gourmand en bande passante (par exemple, les mises à jour de l'OS) qui ne peut pas être bloqué. La QoS garantit que le trafic interactif des invités est prioritaire sur les transferts de masse en arrière-plan.
Telemetry
La collecte et la transmission automatisées de données opérationnelles depuis des appareils vers des serveurs distants à des fins de surveillance, d'analyse et de diagnostic.
Dans le contexte du WiFi invité, la télémétrie des appareils provenant des systèmes d'exploitation mobiles et des applications peut consommer silencieusement 15 à 20 % de la bande passante disponible. C'est une cible principale pour le filtrage DNS dans les déploiements de réseaux publics.
DNS Sinkholing
Une technique dans laquelle un serveur DNS est configuré pour renvoyer une fausse adresse IP (généralement une adresse nulle locale) pour des domaines spécifiques, redirigeant le trafic loin de sa destination prévue.
Utilisé pour neutraliser le trafic C2 de logiciels malveillants et bloquer de manière agressive les réseaux publicitaires à forte consommation de bande passante. Plus définitif que les réponses NXDOMAIN, car il permet au serveur de redirection (sinkhole) d'enregistrer les tentatives de connexion pour une analyse de sécurité.
Airtime Fairness
Une fonctionnalité de réseau sans fil qui attribue un accès égal au support sans fil à tous les clients connectés, quels que soient leurs débits de données individuels.
Crucial dans les environnements à haute densité. Sans airtime fairness, un seul appareil lent (par exemple, un client 802.11g plus ancien) peut consommer de manière disproportionnée le temps d'antenne, dégradant le débit pour tous les autres clients. Le trafic de télémétrie en arrière-plan provenant de nombreux appareils exacerbe cet effet.
Phantom Load
Bande passante consommée par des processus d'arrière-plan automatisés sur les appareils connectés avant qu'une quelconque activité délibérée de l'utilisateur ne se produise.
Le terme collectif désignant la télémétrie, le pré-chargement des réseaux publicitaires et le trafic de mise à jour des OS. Comprendre et quantifier la charge fantôme est la première étape de tout diagnostic de congestion du WiFi invité.
Exemples concrets
Un complexe hôtelier de 400 chambres subit de graves congestions de réseau chaque soir entre 19h00 et 22h00. La liaison WAN de 1 Gbps est saturée, et les clients se plaignent de la lenteur du streaming et de coupures lors des appels VoIP. Le directeur informatique doit identifier la cause profonde et mettre en œuvre une solution sans mettre à niveau le circuit.
Étape 1 — Analyse du trafic : Déployer un analyseur de flux réseau (NetFlow/IPFIX) sur le routeur central et l'exécuter pendant 5 jours sur les périodes de pointe et creuses. Corréler avec les journaux de requêtes DNS du résolveur existant. L'analyse révèle que 35 % du trafic du soir est destiné à des réseaux publicitaires vidéo programmatiques connus (DoubleClick, AppNexus) et à des serveurs de mise à jour automatique d'applications (Apple Software Update, Google Play). La navigation légitime des clients ne représente que 52 % du trafic total.
Étape 2 — Déploiement du filtrage DNS : Configurer le pare-feu central pour rediriger toutes les requêtes DNS du VLAN invité (port UDP/TCP 53) vers un résolveur local compatible RPZ. Importer une liste de blocage ciblée couvrant les réseaux publicitaires et les domaines de télémétrie identifiés. Exécuter en mode journalisation uniquement pendant 48 heures pour valider les taux de faux positifs.
Étape 3 — Application de la politique : Après avoir validé un taux de faux positifs inférieur à 0,3 %, passer en mode application. Simultanément, mettre en œuvre une politique de QoS qui limite le débit des serveurs de mise à jour Apple et Google à un plafond combiné de 80 Mbps pendant la plage horaire de 18h00 à 23h00.
Étape 4 — Validation : Surveiller l'utilisation du WAN au cours des 7 jours suivants. L'utilisation de pointe chute de 98 % à 61 %, résolvant ainsi les plaintes des clients. L'hôtel reporte une mise à niveau planifiée du circuit d'environ 18 mois.
Un grand centre de conférences accueille un sommet technologique réunissant 5 000 participants. Pendant la conférence plénière, le réseau WiFi devient totalement inutilisable. L'analyse post-incident montre que des milliers d'appareils ont tenté simultanément de télécharger une mise à jour majeure d'iOS publiée le matin même.
Atténuation immédiate (jour de l'événement) : L'équipe des opérations réseau identifie la surcharge grâce à la surveillance des requêtes DNS en temps réel. Elle redirige immédiatement vers un trou noir (sinkhole) les domaines spécifiques de mise à jour logicielle Apple (mesu.apple.com, appldnld.apple.com, updates.cdn-apple.com) au niveau de la couche DNS. En l'espace de 4 minutes, l'utilisation du WAN chute de 99 % à 68 %, et le réseau se stabilise.
Correction à court terme (même événement) : Une politique de QoS est appliquée pour limiter le débit de tout le trafic de mise à jour restant à 50 Mbps pour la durée de l'événement.
Stratégie à long terme (post-événement) : L'équipe réseau met en œuvre une politique de QoS dynamique qui s'active automatiquement lorsque l'utilisation totale du WAN dépasse 75 %, limitant les serveurs de mise à jour connus à 10 % de la capacité totale. Une liste de contrôle pré-événement est créée, prévoyant la redirection temporaire vers un trou noir des principaux domaines de mise à jour pendant les 2 heures précédant et suivant les sessions à forte affluence. L'équipe s'abonne également aux flux de notification de sortie de mise à jour d'Apple et de Microsoft afin d'anticiper les futurs pics d'activité.
Questions d'entraînement
Q1. Vous êtes le responsable informatique d'une chaîne nationale de vente au détail. Après avoir déployé une solution de filtrage DNS dans 50 magasins, plusieurs directeurs de magasin signalent que la page de connexion du Captive Portal ne se charge pas pour les clients. L'équipe d'assistance reçoit un volume d'appels très élevé. Quelle est la cause la plus probable et quelle est la mesure corrective immédiate ?
Conseil : Considérez la chaîne de dépendance complète d'un flux d'authentification de Captive Portal moderne, y compris les mécanismes de détection de Captive Portal au niveau du système d'exploitation.
Voir la réponse type
La cause la plus probable est un blocage excessif. Le filtre DNS bloque un domaine nécessaire au fonctionnement du Captive Portal. Les systèmes d'exploitation mobiles modernes utilisent des domaines spécifiques pour détecter les Captive Portals (par exemple, captive.apple.com pour iOS, connectivitycheck.gstatic.com pour Android). Si ces domaines sont bloqués, le système d'exploitation ne déclenchera pas le navigateur du Captive Portal et le client ne verra aucune invite de connexion. De plus, le portail lui-même peut dépendre d'un CDN ou d'un fournisseur d'authentification tiers (par exemple, la connexion sociale via Facebook ou Google) dont les domaines sont bloqués par inadvertance.
Correction immédiate : Examinez les journaux de requêtes DNS pour identifier les réponses NXDOMAIN provenant du sous-réseau invité pendant la phase d'authentification. Identifiez tous les domaines bloqués qui sont interrogés avant une connexion réussie. Ajoutez ces domaines à la liste d'autorisation globale. Implémentez un modèle de liste d'autorisation standard pour les déploiements de Captive Portal qui inclut tous les principaux points de terminaison de détection d'OS et les domaines de fournisseurs d'authentification courants.
Q2. Un architecte réseau de stade remarque que malgré la mise en œuvre d'un filtrage DNS agressif, l'utilisation du WAN reste extrêmement élevée pendant les matchs. Une enquête plus approfondie révèle un volume élevé et soutenu de trafic sur le port UDP 443 qui ne correspond à aucun domaine bloqué dans les journaux DNS. Que se passe-t-il et comment y remédier ?
Conseil : Considérez les protocoles de transport modernes et la façon dont ils interagissent avec les contrôles au niveau de la couche DNS.
Voir la réponse type
Le volume élevé de trafic sur le port UDP 443 indique l'utilisation de QUIC (HTTP/3). QUIC est un protocole de transport basé sur UDP utilisé par les grandes plateformes (Google, Meta, YouTube) qui contourne les proxys traditionnels basés sur TCP et les moteurs DPI. Plus important encore, les clients utilisant QUIC peuvent également utiliser le DNS sur HTTPS (DoH) pour résoudre les domaines, contournant ainsi complètement le résolveur RPZ local et rendant le filtrage DNS inefficace pour ces clients.
Pour y remédier : Tout d'abord, implémentez des règles de pare-feu pour bloquer le trafic DoH sortant vers les fournisseurs de DoH publics connus (Google, Cloudflare, NextDNS) sur le port TCP/UDP 443 par IP de destination, forçant ainsi les clients à se rabattre sur le résolveur local. Deuxièmement, évaluez le blocage complet du trafic sortant UDP 443 (ou limitez son débit de manière agressive) pour forcer les clients QUIC à se rabattre sur HTTP/2 basé sur TCP, qui est soumis aux politiques de gestion du trafic existantes. Troisièmement, examinez si un proxy DoH transparent peut être déployé pour intercepter et inspecter les requêtes DoH tout en appliquant les politiques RPZ locales.
Q3. Vous concevez une politique de QoS pour le réseau WiFi invité d'un grand hôpital public. Le réseau est partagé entre les appareils de divertissement des patients, les appareils personnels des visiteurs et un petit nombre de membres du personnel clinique utilisant des softphones VoIP sur leurs mobiles personnels. Priorisez les types de trafic suivants : VoIP (SIP/RTP), navigation web des invités (HTTP/HTTPS), mises à jour Windows/iOS et streaming vidéo (Netflix/YouTube).
Conseil : Considérez à la fois la sensibilité à la latence et l'impact commercial/clinique de chaque type de trafic. Considérez également le contexte réglementaire d'un environnement de santé.
Voir la réponse type
Priorité 1 — VoIP (SIP/RTP) : File d'attente à priorité stricte (Expedited Forwarding, DSCP EF). La VoIP est très sensible à la latence (cible < 150 ms aller simple) et à la gigue (cible < 30 ms). Une perte de paquets supérieure à 1 % entraîne une dégradation audible. Dans un contexte clinique, un appel interrompu pourrait avoir des conséquences sur la sécurité des patients.
Priorité 2 — Navigation web des invités (HTTP/HTTPS) : Assured Forwarding (AF31). Il s'agit du principal cas d'utilisation attendu pour les patients et les visiteurs. Il nécessite une réactivité raisonnable mais tolère une latence modérée.
Priorité 3 — Streaming vidéo (Netflix/YouTube) : Débit limité par client (par exemple, limite de 3 à 5 Mbps) avec Assured Forwarding (AF21). Bien qu'important pour l'expérience des patients lors de longs séjours, un streaming non limité saturera la liaison. Une limite par client garantit un accès équitable. Envisagez des politiques horaires qui assouplissent les limites pendant les heures creuses.
Priorité 4 — Mises à jour OS/applications (Scavenger Class, DSCP CS1) : Priorité la plus basse, file d'attente au mieux (best-effort), avec une limite de débit globale (par exemple, 50 Mbps au total pour l'ensemble du trafic de mise à jour). Il s'agit de tâches d'arrière-plan sans sensibilité à la latence. Elles ne doivent consommer que la capacité excédentaire. Dans un environnement de santé, déterminez également si le réseau invité est totalement isolé des systèmes cliniques — si ce n'est pas le cas, la gestion du trafic de mise à jour devient un problème de sécurité autant que de bande passante.
Continuer la lecture de cette série
Dépannage des redirections de Captive Portal : Résoudre les échecs de connexion WiFi invité
Lorsque les invités se connectent à votre WiFi mais ne peuvent pas accéder à Internet, la cause est presque toujours une mauvaise configuration de la redirection du Captive Portal - et non une défaillance matérielle. Ce guide fournit une référence technique approfondie pour les responsables informatiques, les architectes réseau et les directeurs de la technologie afin de diagnostiquer et de résoudre l'ensemble de la chaîne de défaillances : des sondes de connectivité au niveau du système d'exploitation et des conflits de certificats HSTS jusqu'aux écarts d'autorisation RADIUS et à l'épuisement du DHCP. Il associe chaque mode de défaillance à un correctif concret et montre comment la solution cloud agnostique de Purple élimine ces problèmes sur les déploiements Cisco Meraki, HPE Aruba, Ruckus, Juniper Mist, Ubiquiti UniFi, Cambium, Extreme Networks et Fortinet.
Dépannage du WiFi public : résoudre les erreurs « Connecté, pas d'Internet » et les échecs de redirection vers la page d'accueil
Ce guide de référence technique officiel explique les mécanismes sous-jacents de la détection de Captive Portal et détaille les six principaux modes de défaillance qui empêchent le WiFi invité de se connecter. Il fournit aux responsables informatiques et aux architectes réseau un cadre de dépannage pratique pour résoudre les problèmes de redirection HTTP, les conflits DNS et les défis liés à la randomisation des adresses MAC.
Top 10 des causes de timeouts DHCP sur les réseaux sans fil à haute densité
Ce guide de référence technique de premier plan identifie les dix principales causes de timeouts DHCP sur les réseaux sans fil à haute densité et propose des stratégies de remédiation exploitables et indépendantes des fournisseurs. Conçu pour les décideurs informatiques, les architectes réseau et les directeurs d'exploitation de sites, il détaille des principes d'ingénierie approfondis, des processus de déploiement étape par étape et des résultats commerciaux mesurables. Découvrez comment éliminer les goulots d'étranglement de connexion et optimiser votre infrastructure sans fil pour offrir une connectivité fluide dans les environnements d'entreprise les plus exigeants.