Comment surveiller le trafic réseau WiFi : Un guide pour les équipes informatiques
Ce guide technique propose des stratégies concrètes pour surveiller le trafic WiFi d'entreprise, en se concentrant sur l'architecture, la sécurité et la performance. Il fournit aux équipes informatiques des secteurs de l'hôtellerie, du commerce de détail et des services publics les cadres nécessaires pour déployer des solutions de surveillance réseau évolutives et sécurisées.
🎧 Écouter ce guide
Voir la transcription

Résumé exécutif
Pour les leaders informatiques d'entreprise gérant des réseaux dans les établissements d' Hôtellerie , de Commerce de détail et de Transport , le WiFi n'est plus un simple service de commodité ; c'est une infrastructure critique. La surveillance de ce trafic va bien au-delà de simples vérifications de disponibilité. Une architecture de surveillance robuste exige une visibilité approfondie de l'environnement RF, des flux d'authentification et du trafic de la couche application afin de garantir à la fois la performance et la sécurité. Ce guide décrit les exigences techniques et les considérations architecturales pour le déploiement d'une surveillance WiFi de niveau entreprise. Nous explorons les cinq couches critiques de visibilité réseau, l'intégration de plateformes d'identité et d'analyse comme la solution Guest WiFi de Purple, et les stratégies nécessaires pour atténuer les risques tout en offrant une expérience utilisateur fluide. En adoptant ces cadres, les CTOs et les architectes réseau peuvent passer d'un dépannage réactif à une planification proactive de la capacité et à la détection des menaces.
Analyse technique approfondie
Une surveillance efficace du trafic WiFi nécessite une approche multicouche, capturant les données depuis l'espace physique jusqu'à la couche application. Se fier uniquement à l'interrogation SNMP pour l'état des appareils laisse d'importantes lacunes dans la compréhension du comportement des utilisateurs et de la santé du réseau.
Les cinq couches de visibilité
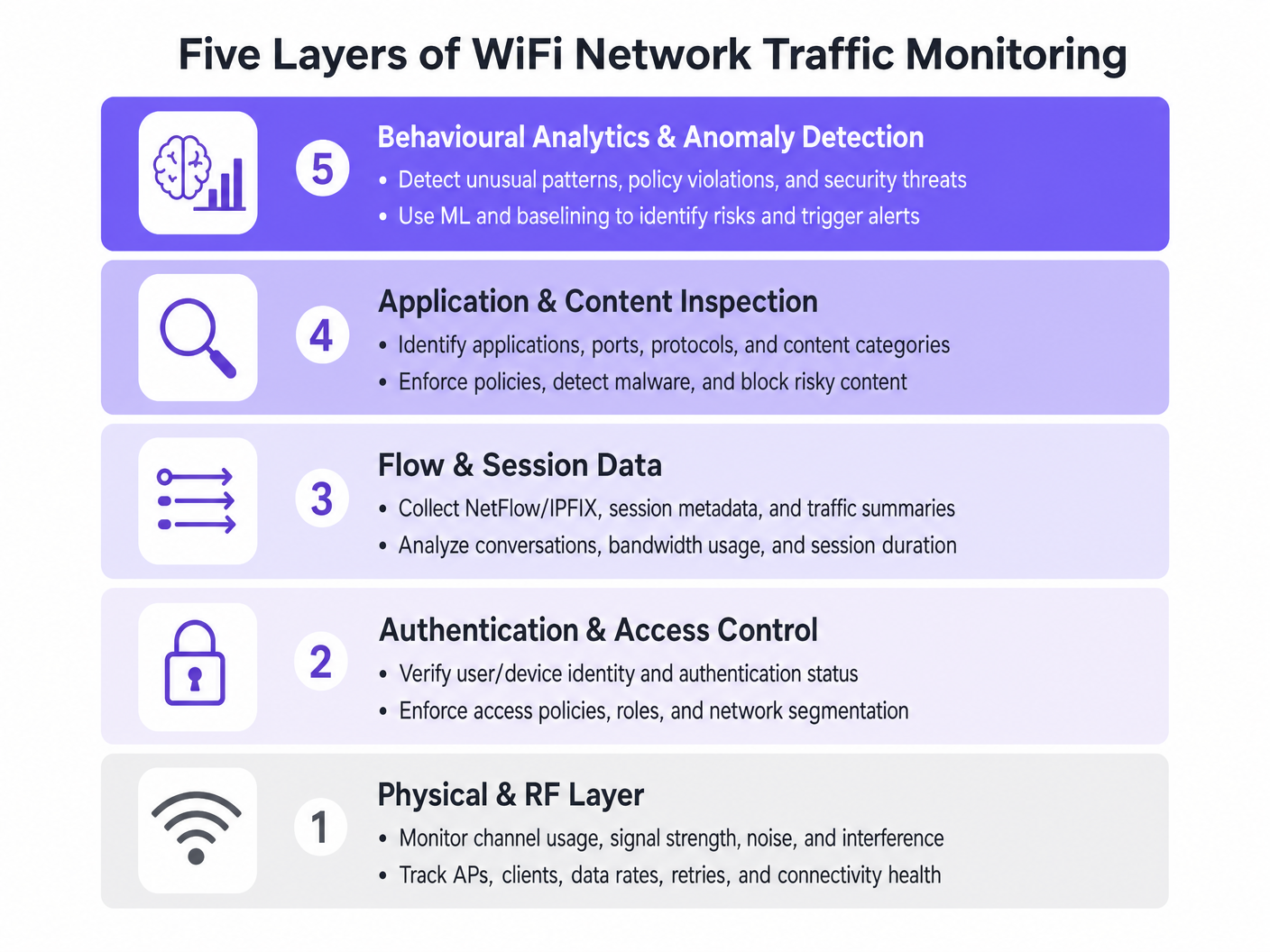
- Couche physique et RF : Cette couche fondamentale implique la surveillance de l'utilisation des canaux, des rapports signal/bruit (SNR) et des interférences de co-canal. Les outils doivent suivre les débits de données des clients et les pourcentages de réessai. Des taux de réessai élevés indiquent souvent des problèmes RF bien avant que la saturation de la bande passante ne se produise.
- Authentification et contrôle d'accès : La surveillance des journaux RADIUS et des transactions 802.1X est critique. En analysant la latence d'authentification et les taux d'échec, les équipes peuvent isoler les problèmes au service d'annuaire ou à l'infrastructure sans fil. Ceci est particulièrement pertinent lors de la mise en œuvre de Sécurité WiFi BYOD : Comment autoriser les appareils personnels sur votre réseau en toute sécurité .
- Données de flux et de session : L'utilisation de protocoles comme NetFlow, IPFIX et sFlow fournit des métadonnées sur les conversations réseau sans la surcharge d'une capture complète de paquets. Ces données révèlent les principaux émetteurs, les tendances de consommation de bande passante et les modèles de trafic inhabituels.
- Inspection des applications et du contenu : L'inspection approfondie des paquets (DPI) au niveau du contrôleur LAN sans fil ou du pare-feu permet aux équipes informatiques d'identifier des applications spécifiques (par exemple, distinguer la VoIP d'entreprise du streaming vidéo grand public). Cette visibilité est essentielle pour l'application des politiques de Qualité de Service (QoS).
- Analyse comportementale et détection d'anomalies : La couche la plus avancée utilise l'apprentissage automatique pour établir une ligne de base du comportement réseau normal. Lorsqu'un appareil s'écarte de sa ligne de base — comme un appareil IoT transmettant soudainement de grands volumes de données — le système déclenche une alerte, facilitant une réponse rapide aux incidents.
Intégration architecturale
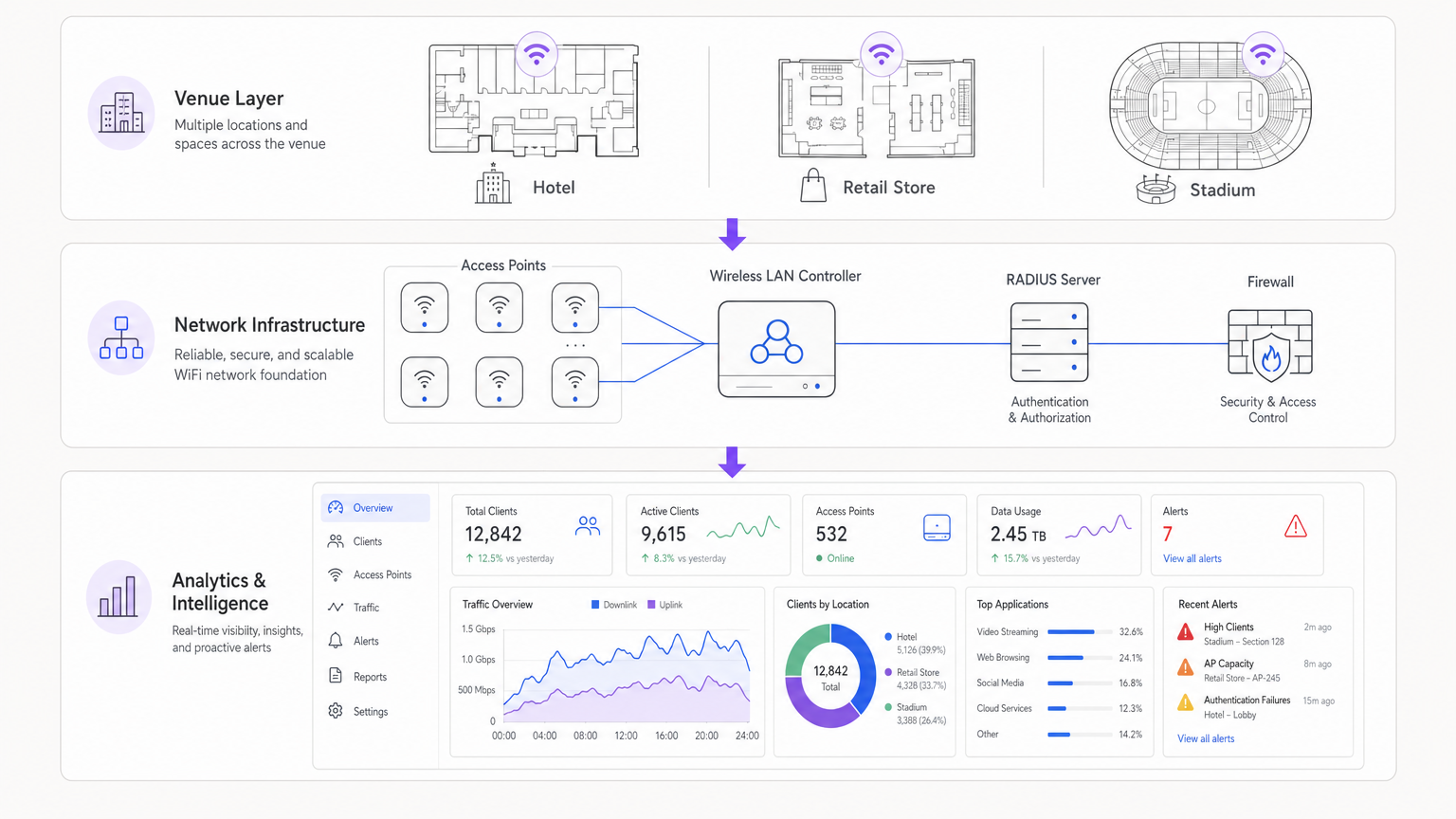
Les architectures modernes centralisent les données de télémétrie provenant de points d'accès distribués. Qu'il s'agisse d'une solution gérée dans le cloud ou d'un contrôleur sur site, l'agrégation des journaux dans un SIEM (Security Information and Event Management) ou une plateforme d'analyse dédiée est cruciale. L'intégration de fournisseurs d'identité, tels que WiFi Analytics de Purple, enrichit les données réseau brutes avec le contexte utilisateur, transformant une adresse IP en un profil utilisateur exploitable.
Guide d'implémentation
Le déploiement d'une solution de surveillance complète nécessite une planification minutieuse pour éviter de surcharger les ressources réseau ou de générer une fatigue d'alerte.
Étape 1 : Définir les exigences de télémétrie
Déterminez les protocoles pris en charge par votre infrastructure. Activez NetFlow/IPFIX sur les commutateurs centraux et les pare-feu, et configurez les points d'accès pour qu'ils transmettent les journaux syslog et les métriques RF à un collecteur central.
Étape 2 : Implémenter la segmentation réseau
Isolez le trafic dans des VLAN distincts : Entreprise, Invité et IoT. Appliquez des profils de surveillance différents à chacun. Par exemple, l'inspection approfondie des paquets pourrait être fortement appliquée au réseau Invité pour faire respecter les politiques d'utilisation acceptable, tandis que les données de flux suffisent pour le segment IoT.
Étape 3 : Configurer l'intégration d'identité
Reliez vos outils de surveillance réseau à votre backend d'authentification. Lors de la gestion de déploiements complexes comme Le WiFi dans les hôpitaux : Un guide pour des réseaux cliniques sécurisés , la corrélation d'une adresse MAC avec un rôle utilisateur spécifique (par exemple, clinicien vs. patient) est essentielle pour un dépannage rapide.
Étape 4 : Ajuster les seuils d'alerte
Évitez les seuils statiques qui déclenchent de faux positifs pendant les heures de pointe. Mettez en œuvre une ligne de base dynamique lorsque cela est possible. Commencez par les alertes critiques (par exemple, contrôleur hors ligne, échecs d'authentification massifs) et introduisez progressivement des alertes basées sur la performance (par exemple, utilisation élevée des canaux) à mesure que vous comprenez la ligne de base de votre réseau.
Bonnes pratiques
- Privilégier les données de flux à la capture de paquets : La capture complète de paquets est gourmande en ressources et souvent inutile pour la surveillance de routine. Fiez-vous à NetFlow/IPFIX pour 90 % de vos besoins en visibilité.
- Appliquer le contrôle d'accès basé sur les rôles (RBAC) : Assurez-vous que seul le personnel autorisé a accès aux tableaux de bord de surveillance sensibles, en particulier ceux affichant les données d'identité des utilisateurs.
- Examiner régulièrement les signatures DPI : Les signatures d'application changent fréquemment. Assurez-vous que vos moteurs DPI sont automatiquement mis à jour pour maintenir un trafic précisclassification IC.
- Considérez le matériel : Lors de la sélection de l'infrastructure, comme décrit dans Your Guide to a Wireless Access Point Ruckus , assurez-vous que les points d'accès (AP) disposent de la puissance de traitement nécessaire pour gérer l'inspection du trafic local sans dégrader les performances des clients.
Dépannage et atténuation des risques
Modes de défaillance courants
- Fatigue d'alerte : Lorsque les systèmes de surveillance génèrent trop de bruit, les alertes critiques sont manquées. Atténuation : Mettre en œuvre des moteurs de corrélation d'alertes pour regrouper les événements connexes.
- Angles morts dans le trafic chiffré : À mesure que le trafic se déplace vers HTTPS et TLS 1.3, l'inspection de la charge utile devient difficile. Atténuation : S'appuyer sur le routage SNI (Server Name Indication), les requêtes DNS et les métadonnées de flux pour déduire l'utilisation des applications.
- Épuisement des ressources : L'activation du DPI sur des contrôleurs sous-provisionnés peut entraîner des pics de CPU et des paquets perdus. Atténuation : Dimensionner le matériel de manière appropriée ou décharger l'inspection vers des appliances de sécurité dédiées.
ROI et impact commercial
Le retour sur investissement d'une surveillance WiFi robuste se mesure en réduction des risques et en efficacité opérationnelle. En identifiant et en résolvant les problèmes RF avant qu'ils n'affectent les utilisateurs, les sites réduisent les tickets d'assistance et protègent les flux de revenus. De plus, l'intégration de la surveillance réseau avec des plateformes comme Purple permet aux entreprises de tirer parti de leur infrastructure pour des informations marketing et opérationnelles, transformant l'informatique d'un centre de coûts en un atout stratégique. Que ce soit pour un déploiement dans un magasin de détail ou pour explorer Your Guide to Enterprise In Car Wi Fi Solutions , la visibilité est la clé de la performance.
Écouter le briefing
Termes clés et définitions
NetFlow / IPFIX
Network protocols used to collect IP traffic information and monitor network flow. They provide metadata about conversations (source, destination, ports) without capturing the payload.
Essential for identifying top talkers and bandwidth consumption trends without the overhead of full packet capture.
Deep Packet Inspection (DPI)
A form of computer network packet filtering that examines the data part of a packet as it passes an inspection point, searching for protocol non-compliance, viruses, spam, intrusions, or predefined criteria.
Used to identify specific applications (e.g., Netflix vs. Zoom) to enforce granular QoS policies on guest networks.
RADIUS
Remote Authentication Dial-In User Service. A networking protocol that provides centralised Authentication, Authorization, and Accounting (AAA) management.
RADIUS logs are the first place IT teams look when troubleshooting 802.1X authentication failures or latency issues.
Co-Channel Interference (CCI)
Interference caused when two or more access points are operating on the same frequency channel within range of each other, forcing them to share the airtime.
A primary cause of poor WiFi performance in dense deployments like stadiums or conference centres.
Band Steering
A feature in wireless networks that encourages dual-band clients to connect to the less congested 5GHz or 6GHz bands rather than the crowded 2.4GHz band.
Crucial for optimising RF performance and ensuring a better user experience in high-density environments.
VLAN Segmentation
The practice of dividing a physical network into multiple logical networks to isolate traffic for security and performance reasons.
Fundamental for separating secure corporate or POS traffic from untrusted guest WiFi traffic.
Quality of Service (QoS)
Technologies that manage data traffic to reduce packet loss, latency and jitter on the network, prioritising specific types of data.
Used to ensure business-critical applications (like VoIP or POS transactions) perform reliably even when the network is congested.
Alert Fatigue
The phenomenon where IT staff become desensitised to safety alerts because they are exposed to a large number of frequent alarms.
A major risk in network monitoring; mitigated by tuning thresholds and correlating events.
Études de cas
A 200-room hotel is experiencing intermittent connectivity issues during peak evening hours. The basic dashboard shows all APs are online, but guests report slow speeds.
- Check RF Layer: Analyse channel utilisation and co-channel interference on the 2.4GHz and 5GHz bands. High utilisation on 2.4GHz is common; ensure band steering is forcing capable clients to 5GHz.
- Review Flow Data: Identify top talkers. In this scenario, flow data reveals a small number of devices consuming 70% of the bandwidth via peer-to-peer file sharing.
- Apply Policy: Implement an application control policy via the WLAN controller to throttle P2P traffic, immediately freeing up bandwidth for other guests.
A large retail chain needs to ensure its point-of-sale (POS) terminals have priority over guest WiFi traffic during a major sales event.
- Network Segmentation: Ensure POS terminals and guest traffic are on separate VLANs and SSIDs.
- Quality of Service (QoS): Configure QoS policies on the wireless controller and upstream switches to prioritise traffic originating from the POS VLAN.
- Application Inspection: Implement DPI on the guest network to block bandwidth-heavy applications like 4K video streaming during the event.
- Monitoring: Set up specific dashboards to monitor the latency and packet loss specifically for the POS subnet.
Analyse de scénario
Q1. Your network monitoring dashboard alerts you to a sudden, massive spike in bandwidth utilisation on the guest network at a retail location. The traffic is entirely encrypted (HTTPS). How do you determine the nature of the traffic?
💡 Astuce :Consider what metadata is available even when the payload is encrypted.
Afficher l'approche recommandée
While the payload is encrypted, you can use flow data (NetFlow/IPFIX) to identify the destination IP addresses and ports. Correlating this with DNS query logs or using Server Name Indication (SNI) data from the firewall will reveal the domain names being accessed, allowing you to determine if the traffic is legitimate (e.g., a large OS update) or unauthorized.
Q2. A stadium deployment is experiencing poor performance during events. The dashboard shows high channel utilisation on the 2.4GHz band, but relatively low utilisation on the 5GHz band. What is the most appropriate configuration change?
💡 Astuce :Think about how to balance the load across available frequencies.
Afficher l'approche recommandée
Implement and aggressively tune Band Steering on the wireless LAN controllers. This will force dual-band capable client devices to connect to the less congested 5GHz band, freeing up airtime on the 2.4GHz band for legacy devices that only support 2.4GHz.
Q3. You are deploying a new monitoring solution and want to avoid alert fatigue for the network operations centre (NOC). How should you approach configuring alerts for AP offline events?
💡 Astuce :Consider the impact of a single AP failing versus multiple APs.
Afficher l'approche recommandée
Instead of alerting on every single AP that goes offline (which might happen briefly due to PoE resets or minor switch issues), configure the system to alert based on density or critical areas. For example, trigger an alert only if multiple APs in the same zone go offline simultaneously, or if a specifically tagged 'critical' AP (e.g., covering the main lobby) drops.
